
MRA-SNet: Siamese Networks of Multiscale Residual and Attention for Change Detection in High-Resolution Remote Sensing Images


Abstract
:
1. Introduction
- We propose a new end-to-end CNN network architecture, MRA-SNet, for remote sensing image CD, which uses Multi-Res blocks to extract feature information at different scales of images and improve the accuracy of CD.
- We use the difference absolute value feature of the Siamese network in the encoder to better extract the change features between the bitemporal images. Additionally, we introduce Attention Gates to better focus on the change information before the skip connection of the encoder and decoder.
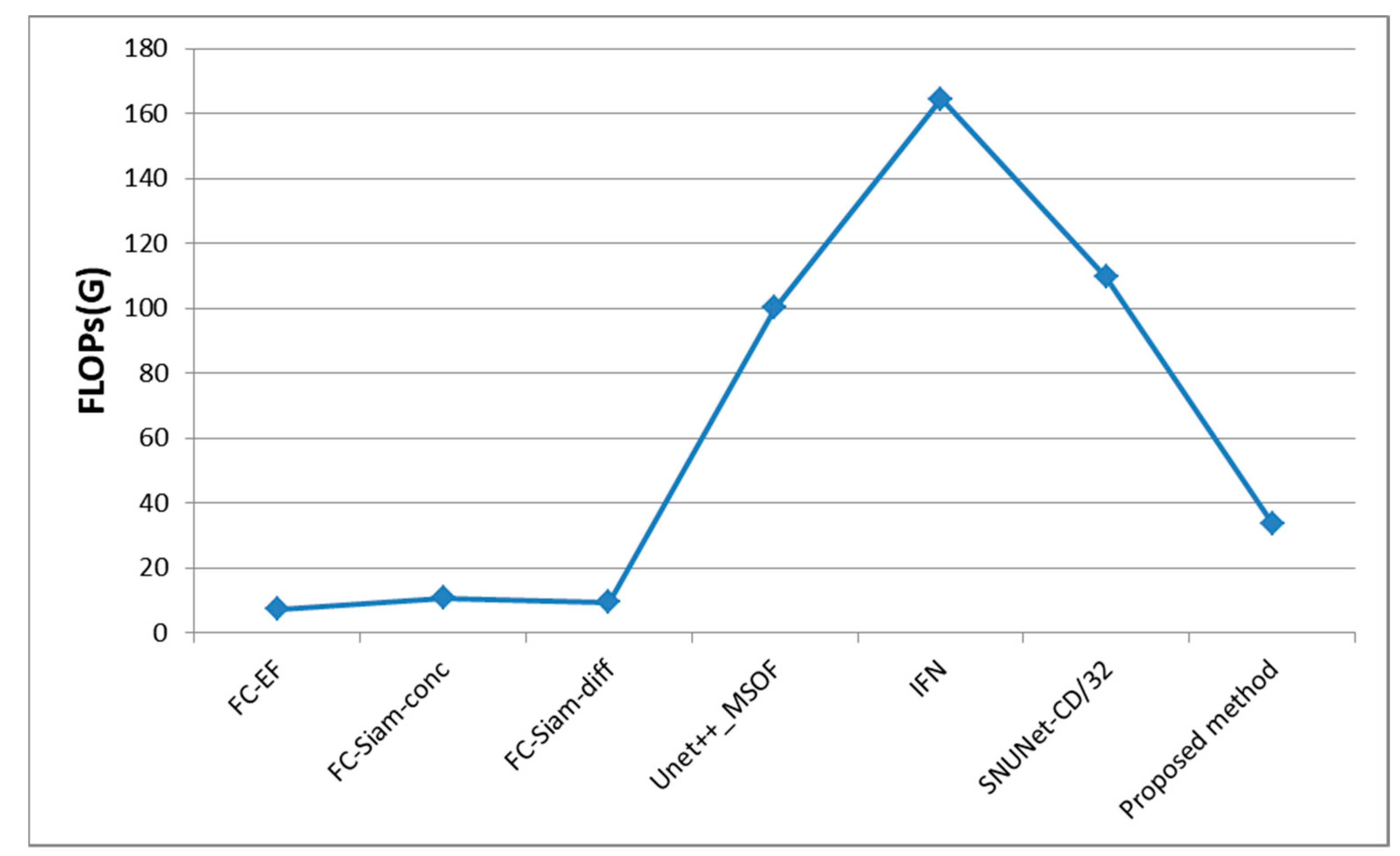
- A series of experimental comparisons show that our method performs better than the other SOTA methods in terms of metrics such as F1 score and OA on the remote sensing image change detection dataset (CDD) [55]. Meanwhile, our method achieves a suitable balance between network performance and number of parameters.
2. Materials and Methods
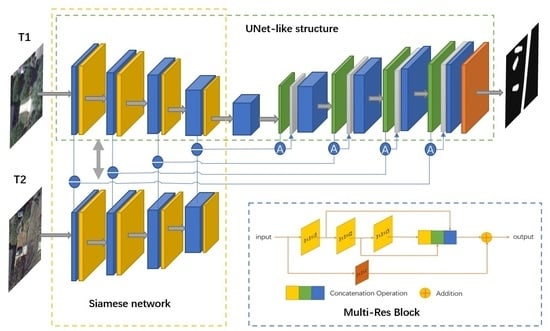
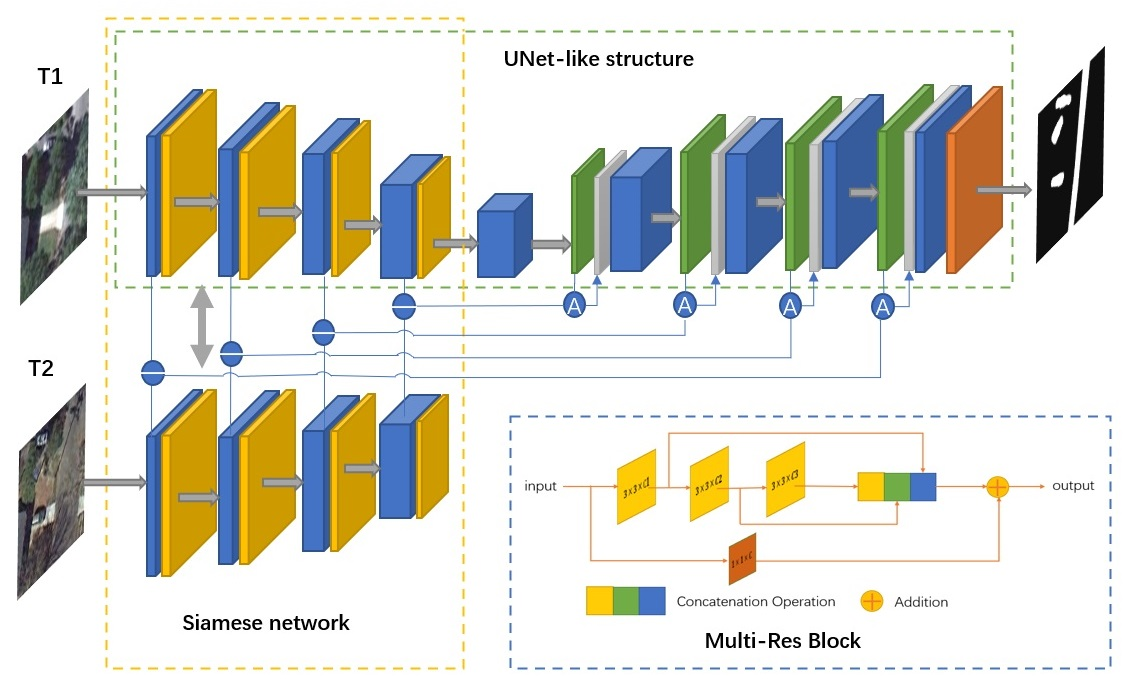
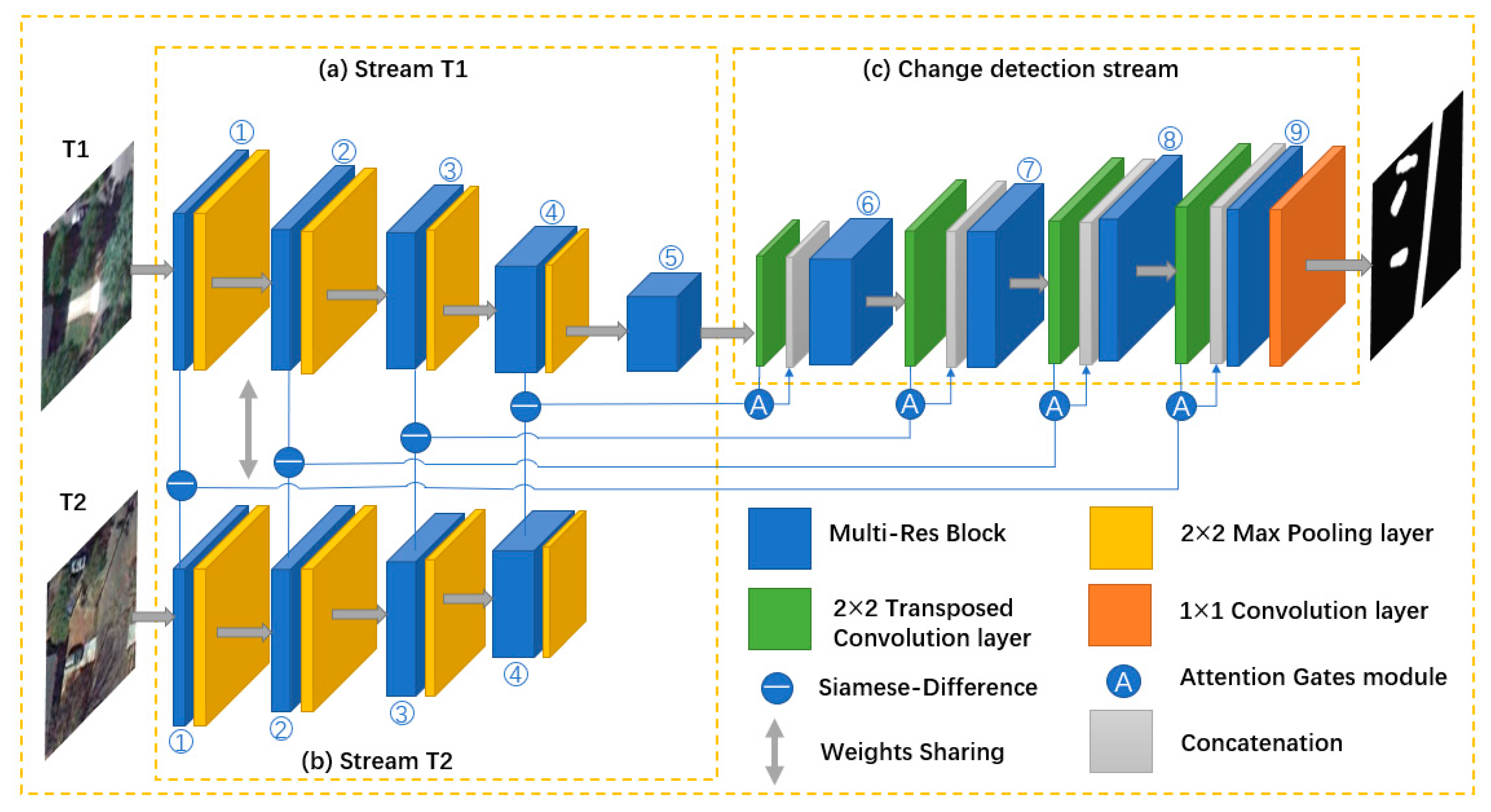
2.1. The Proposed MRA-SNet Network
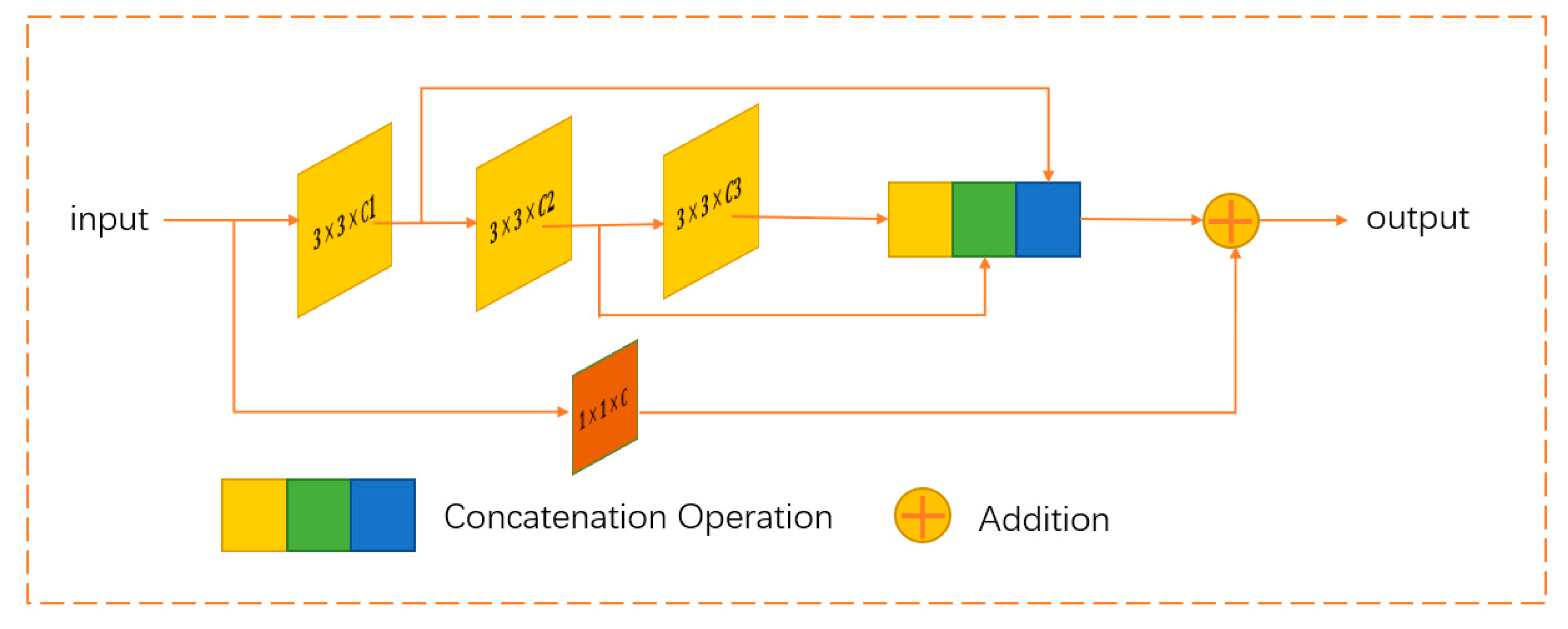
2.2. Multi-Res Block
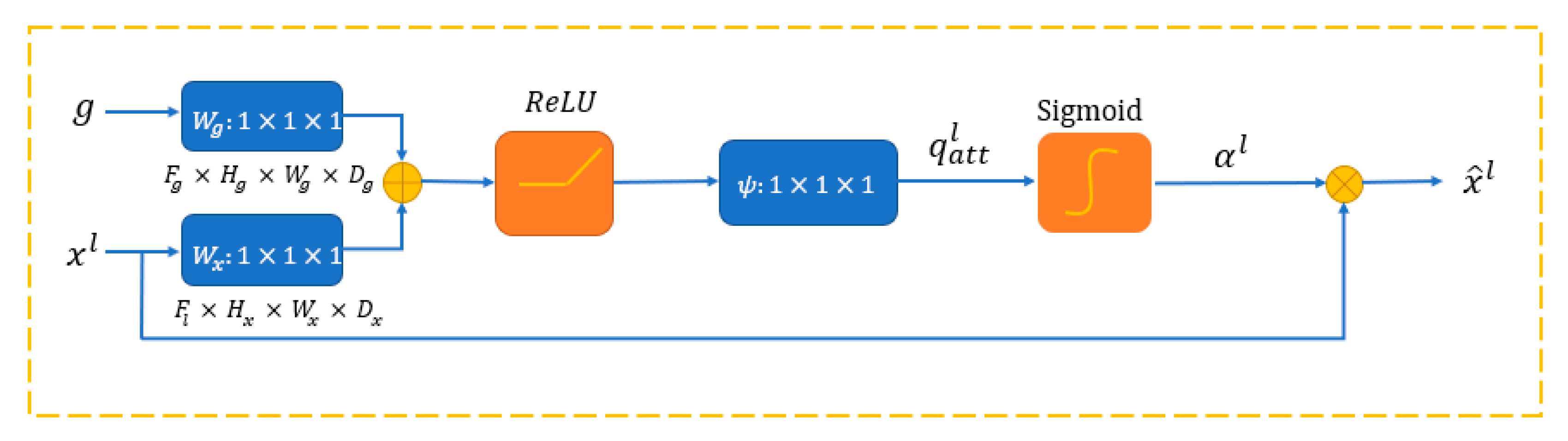
2.3. Attention Gates Module
2.4. Loss Function Details
2.4.1. Binary Cross-Entropy Loss
2.4.2. Dice Coefficient Loss
3. Experiments and Results
3.1. Datasets and Evaluation Metrics
3.2. Comparison Methods
- 4.
- Fully convolutional early fusion (FC-EF) [38] was proposed for satellite image CD. Dual temporal images were concatenated together as input images. A skip connection is used between the encoder and decoder to supplement the local spatial details after encoding.
- 5.
- Fully convolutional Siamese concatenation (FC-Siam-conc) [38] is a Siamese extension of the FC-EF network. The encoder of the network is divided into two parallel structure streams with shared weights. The bitemporal images are input to the structured stream separately for extracting deep features of the images, and then the extracted features are input to the decoder for CD.
- 6.
- Fully convolutional Siamese difference (FC-Siam-diff) [38] shares a similar network structure with FC-Siam-conc; the only difference is that FC-Siam-diff concatenates the absolute values of the differences between the two parallel structure streams of the encoder, and finally, the decoder outputs CMs.
- 7.
- UNet++_MSOF [40] is proposed for end-to-end VHR satellite image CD based on the UNet++ [41] architecture. The network learns feature maps at different semantic levels through dense connections and residual connections, while an MSOF strategy is employed to combine the multiscale lateral output feature maps.
- 8.
- IFN [42] is a deeply supervised image fusion network that is used for VHR remote sensing image CD. The network feeds bitemporal images into two streams of the same convolutional structure for extracting their respective depth features and then feeds the extracted deep features into a deeply supervised difference discrimination network (DDN) for CD.
- 9.
- SNUNet-CD [43] is a recently proposed densely connected Siamese network that is used for remote sensing image CD. The network can reduce the loss of image information and improve the network image feature extraction capability by dense connection. The network also uses the ECAM module to extract the most representative features in the image, and the experimental results are better. We selected the SNUNet-CD method with a channel size of 32 for comparison.
3.3. Implementation Details
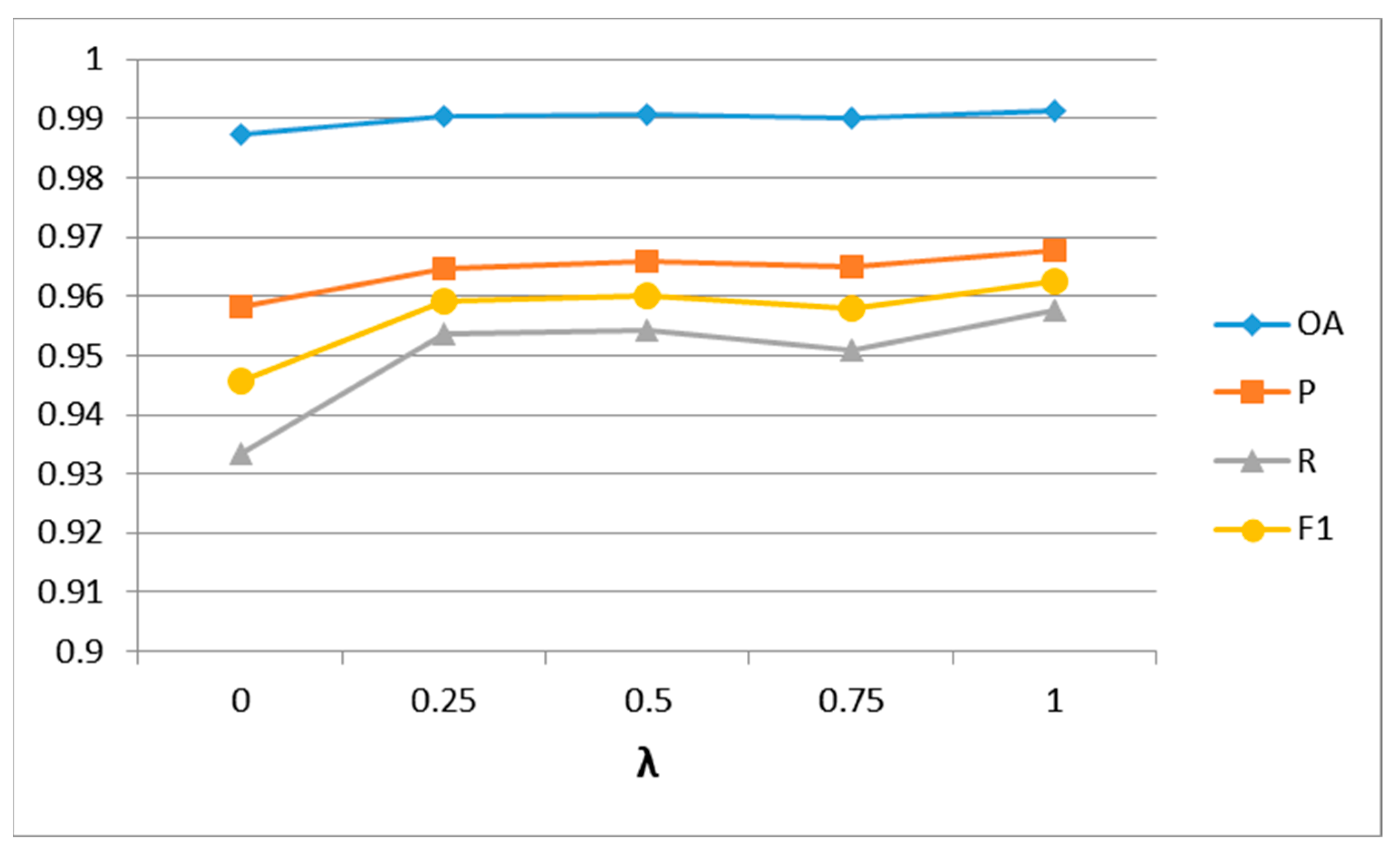
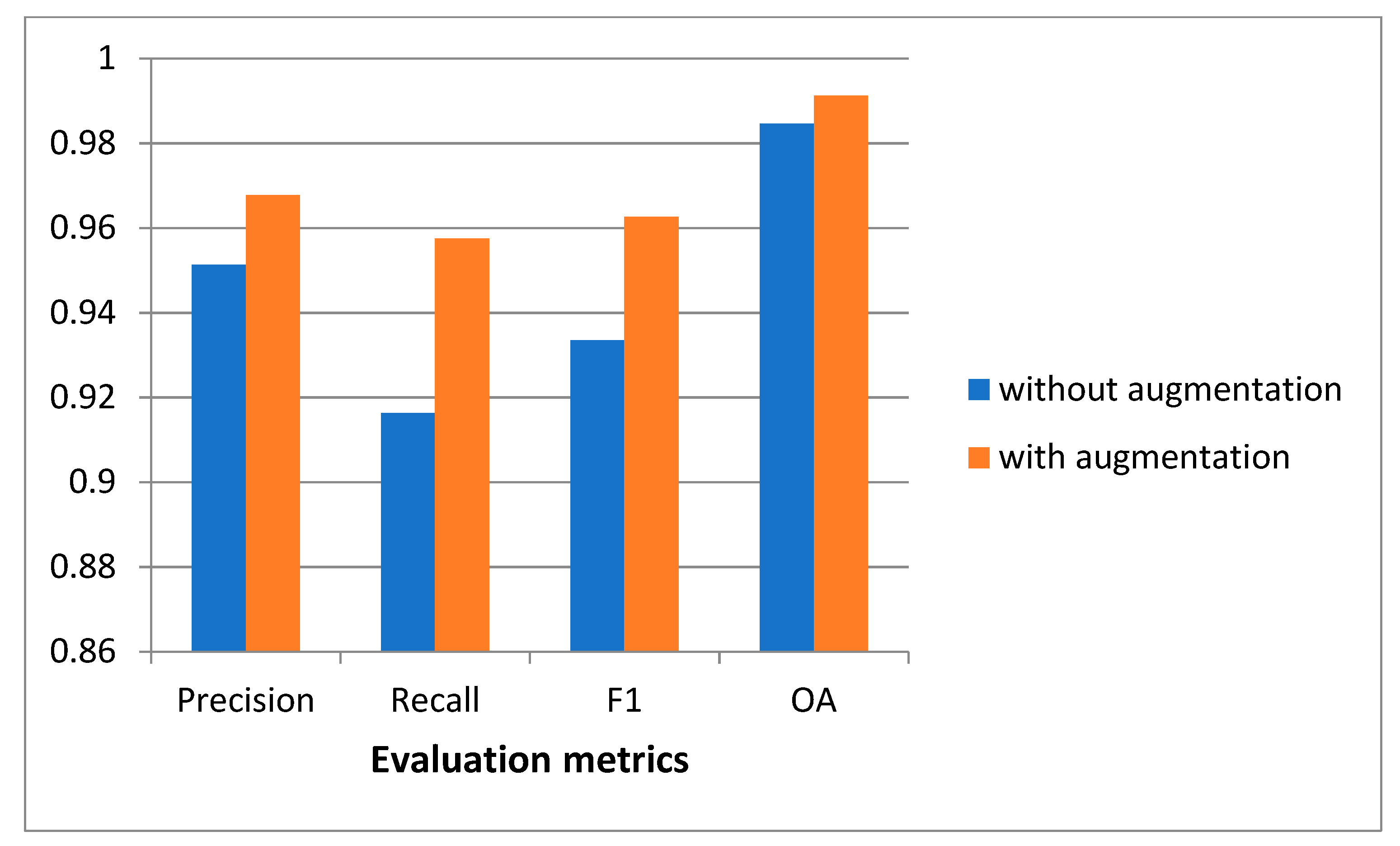
3.4. Ablation Study for the Proposed MRA-SNet
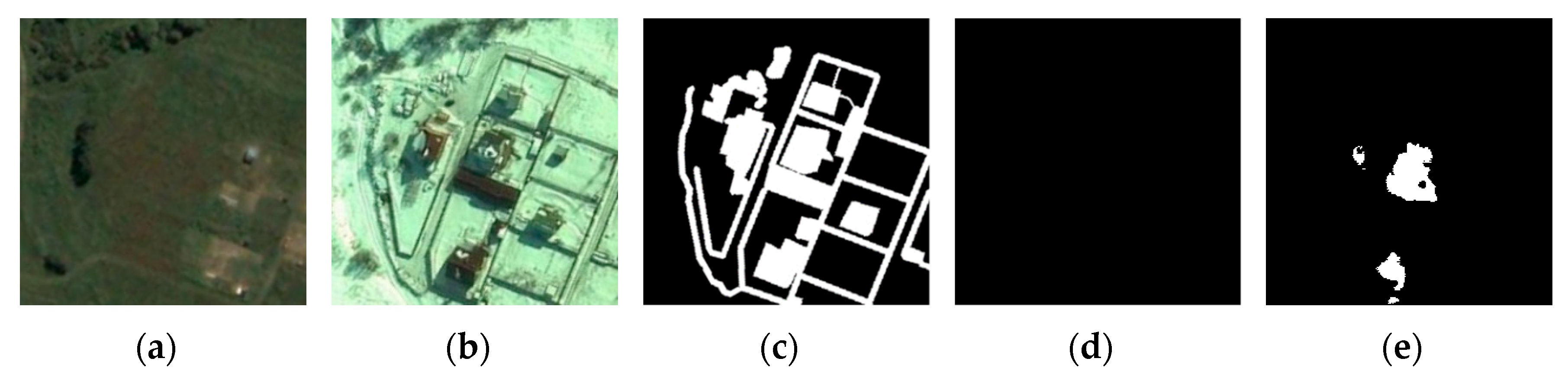
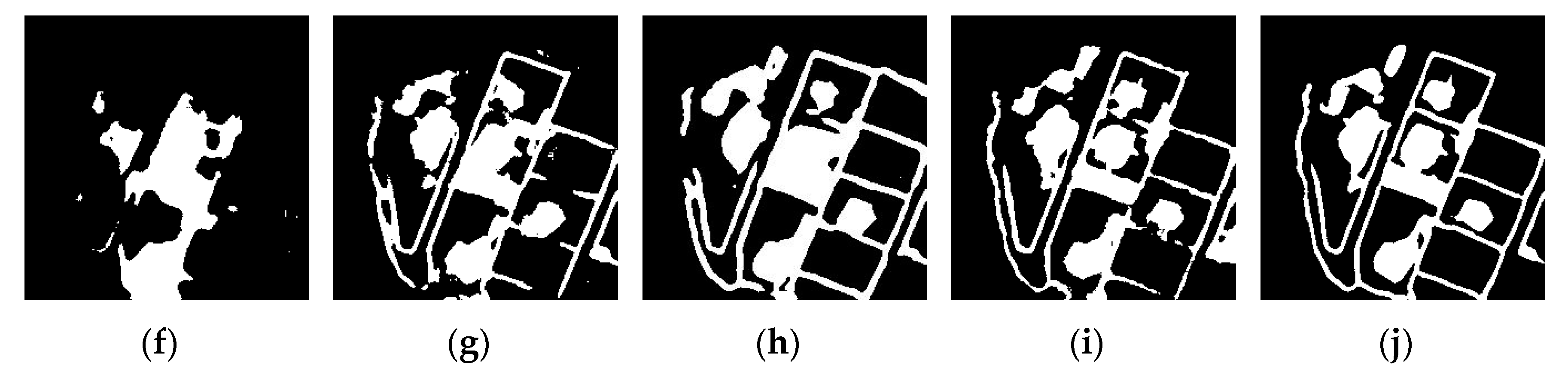
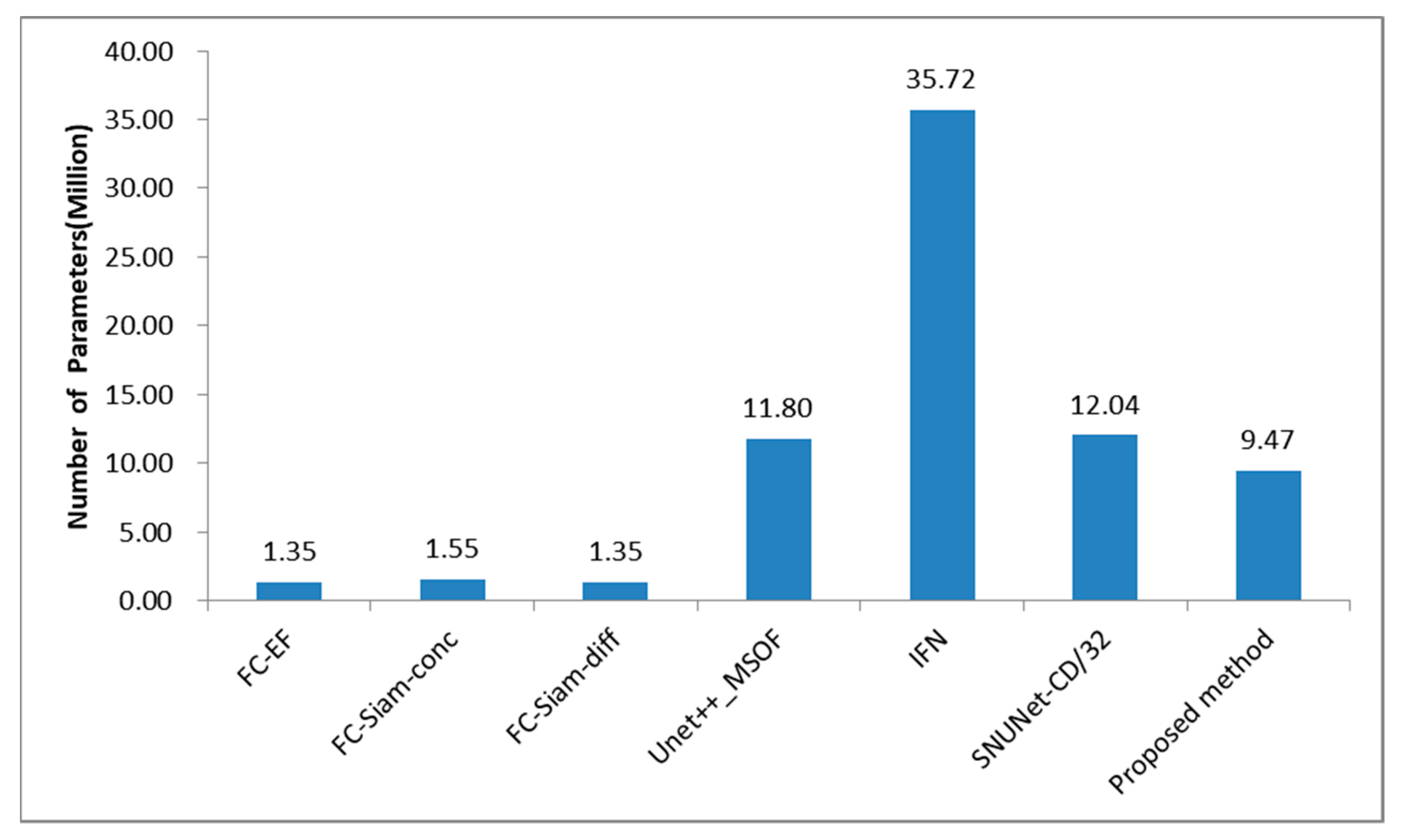
3.5. Comparison Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CD | change detection |
| HR | high-resolution |
| SOTA | state-of-the-art |
| PBCD | pixel-based change detection |
| OBCD | object-based change detection |
| CVA | change vector analysis |
| PCA | principal component analysis |
| MAD | multivariate alteration detection |
| CRF | conditional random field |
| MRF | Markov random field |
| DL | deep learning |
| CNN | convolutional neural network |
| FC-EF | fully convolutional early fusion |
| FC-Siam-conc | fully convolutional Siamese concatenation |
| FC-Siam-diff | fully convolutional Siamese difference |
| IFN | image fusion network |
| ECAM | ensemble channel attention module |
| CM | change map |
| CMs | change maps |
| CDD | change detection dataset |
| DDN | difference discrimination network |
References
- Ball, J.; Anderson, D.; Chan, C.S., Sr. A Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS-J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Singh, A. Review Article Digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef] [Green Version]
- Xian, G.; Homer, C.; Fry, J. Updating the 2001 National Land Cover Database land cover classification to 2006 by using Landsat imagery change detection methods. Remote Sens. Environ. 2009, 113, 1133–1147. [Google Scholar] [CrossRef] [Green Version]
- Lv, Z.Y.; Shi, W.; Zhang, X.; Benediktsson, J.A. Landslide inventory mapping from bitemporal high-resolution remote sensing images using change detection and multiscale segmentation. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 1520–1532. [Google Scholar] [CrossRef]
- Sofina, N.; Ehlers, M. Building change detection using high resolution remotely sensed data and GIS. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2016, 9, 3430–3438. [Google Scholar] [CrossRef]
- Coppin, P.; Jonckheere, I.; Nackaerts, K.; Muys, B.; Lambin, E. Review ArticleDigital change detection methods in ecosystem monitoring: A review. Int. J. Remote Sens. 2004, 25, 1565–1596. [Google Scholar] [CrossRef]
- Fichera, C.R.; Modica, G.; Pollino, M. Land Cover classification and change-detection analysis using multi-temporal remote sensed imagery and landscape metrics. Eur. J. Remote Sens. 2012, 45, 1–18. [Google Scholar] [CrossRef]
- Luo, H.; Liu, C.; Wu, C.; Guo, X. Urban change detection based on Dempster–Shafer theory for multitemporal very high-resolution imagery. Remote Sens. 2018, 10, 980. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Mausel, P.; Brondizio, E.; Moran, E. Change detection techniques. Int. J. Remote Sens. 2004, 25, 2365–2401. [Google Scholar] [CrossRef]
- Brunner, D.; Lemoine, G.; Bruzzone, L. Earthquake damage assessment of buildings using VHR optical and SAR imagery. IEEE Trans. Geosci. Remote Sensing 2010, 48, 2403–2420. [Google Scholar] [CrossRef] [Green Version]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS-J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Bruzzone, L.; Prieto, D.F. Automatic analysis of the difference image for unsupervised change detection. IEEE Trans. Geosci. Remote Sens. 2000, 38, 1171–1182. [Google Scholar] [CrossRef] [Green Version]
- Celik, T. Unsupervised change detection in satellite images using principal component analysis and k-means clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Deng, J.S.; Wang, K.; Deng, Y.H.; Qi, G.J. PCA-based land-use change detection and analysis using multitemporal and multisensor satellite data. Int. J. Remote Sens. 2008, 29, 4823–4838. [Google Scholar] [CrossRef]
- Nielsen, A.A.; Conradsen, K.; Simpson, J.J. Multivariate alteration detection (MAD) and MAF postprocessing in multispectral, bitemporal image data: New approaches to change detection studies. Remote Sens. Environ. 1998, 64, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, A.A. The regularized iteratively reweighted MAD method for change detection in multi-and hyperspectral data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, C.; Du, B.; Cui, X.; Zhang, L. A post-classification change detection method based on iterative slow feature analysis and Bayesian soft fusion. Remote Sens. Environ. 2017, 199, 241–255. [Google Scholar] [CrossRef]
- Huang, C.; Song, K.; Kim, S.; Townshend, J.R.; Davis, P.; Masek, J.G.; Goward, S.N. Use of a dark object concept and support vector machines to automate forest cover change analysis. Remote Sens. Environ. 2008, 112, 970–985. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D.; Bovolo, F.; Kanevski, M.; Bruzzone, L. Supervised change detection in VHR images using contextual information and support vector machines. Int. J. Appl. Earth Obs. Geoinf. 2013, 20, 77–85. [Google Scholar] [CrossRef]
- Cao, G.; Li, Y.; Liu, Y.; Shang, Y. Automatic change detection in high-resolution remote-sensing images by means of level set evolution and support vector machine classification. Int. J. Remote Sens. 2014, 35, 6255–6270. [Google Scholar] [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning (ICML), Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Li, S.Z. Markov random field models in computer vision. In Proceedings of the European Conference on Computer Vision (ECCV), Stockholm, Sweden, 2–6 May 1994; pp. 361–370. [Google Scholar]
- Benedek, C.; Szirányi, T. Change detection in optical aerial images by a multilayer conditional mixed Markov model. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3416–3430. [Google Scholar] [CrossRef] [Green Version]
- Moser, G.; Angiati, E.; Serpico, S.B. Multiscale unsupervised change detection on optical images by Markov random fields and wavelets. IEEE Geosci. Remote Sens. Lett. 2011, 8, 725–729. [Google Scholar] [CrossRef]
- Hoberg, T.; Rottensteiner, F.; Feitosa, R.Q.; Heipke, C. Conditional random fields for multitemporal and multiscale classification of optical satellite imagery. IEEE Trans. Geosci. Remote Sens. 2014, 53, 659–673. [Google Scholar] [CrossRef]
- Zhou, L.; Cao, G.; Li, Y.; Shang, Y. Change detection based on conditional random field with region connection constraints in high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2016, 9, 3478–3488. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Blaschke, T.; Ma, X.; Tiede, D.; Cheng, L.; Chen, D. Object-based change detection in urban areas: The effects of segmentation strategy, scale, and feature space on unsupervised methods. Remote Sens. 2016, 8, 761. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Peng, D.; Huang, X. Object-based change detection for VHR images based on multiscale uncertainty analysis. IEEE Geosci. Remote Sens. Lett. 2017, 15, 13–17. [Google Scholar] [CrossRef]
- Zhang, C.; Li, G.; Cui, W. High-resolution remote sensing image change detection by statistical-object-based method. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 2440–2447. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Noda, K.; Yamaguchi, Y.; Nakadai, K.; Okuno, H.G.; Ogata, T. Audio-visual speech recognition using deep learning. Appl. Intell. 2015, 42, 722–737. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar]
- Li, X.; Du, Z.; Huang, Y.; Tan, Z. A deep translation (GAN) based change detection network for optical and SAR remote sensing images. ISPRS-J. Photogramm. Remote Sens. 2021, 179, 14–34. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Peng, D.; Zhang, Y.; Guan, H. End-to-end change detection for high resolution satellite images using improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS-J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. Available online: https://0-doi-org.brum.beds.ac.uk/10.1109/LGRS.2021.3056416 (accessed on 17 February 2021).
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. In Proceedings of the Thirty-fifth Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Twenty-eighth Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Lee, C.Y.; Osindero, S. Recursive recurrent nets with attention modeling for ocr in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2231–2239. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef] [PubMed]
- Lebedev, M.; Vizilter, Y.V.; Vygolov, O.; Knyaz, V.; Rubis, A.Y. Change detection in remote sensing images using conditional adversarial networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 565–571. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Size | Parameter Setting | Layer | Output Size | Parameter Setting |
|---|---|---|---|---|---|
| Multi-Res Block ① | 256 × 256 | Multi-Res Block ⑥ | 32 × 32 | ||
| Max Pooling | 128 × 128 | 2 × 2, stride = 2 | Transposed Convolution | 64 × 64 | 2 × 2, 212, stride = 2 |
| Multi-Res Block ② | 128 × 128 | Multi-Res Block ⑦ | 64 × 64 | ||
| Max Pooling | 64 × 64 | 2 × 2, stride = 2 | Transposed Convolution | 128 × 128 | 2 × 2, 105, stride = 2 |
| Multi-Res Block ③ | 64 ×64 | Multi-Res Block ⑧ | 128 × 128 | ||
| Max Pooling | 32 × 32 | 2 × 2, stride = 2 | Transposed Convolution | 256 × 256 | 2 × 2, 51, stride = 2 |
| Multi-Res Block ④ | 32 × 32 | Multi-Res Block ⑨ | 256 × 6 | ||
| Max Pooling | 16 × 16 | 2 × 2, stride = 2 | Output Layer | 256 × 256 | 1 × 1, 2, stride = 1 |
| Multi-Res Block ⑤ | 16 × 16 | ||||
| Transposed Convolution | 32 × 32 | 2 × 2, 426, stride = 2 |
| Methods | Multi-Res Block | Attention Gates | Precision | Recall | F1 Score | OA |
|---|---|---|---|---|---|---|
| Siamese UNet | × | × | 0.9519 | 0.9150 | 0.9331 | 0.9845 |
| MRA-SNet | × | 0.9645 | 0.9527 | 0.9586 | 0.9903 | |
| MRA-SNet | × | 0.9586 | 0.9371 | 0.9477 | 0.9878 | |
| MRA-SNet | 0.9677 | 0.9575 | 0.9626 | 0.9912 |
| Methods | Precision | Recall | F1 Score | OA |
|---|---|---|---|---|
| FC-EF | 0.8153 | 0.5424 | 0.6514 | 0.9315 |
| FC-Siam-conc | 0.7972 | 0.6118 | 0.6923 | 0.9358 |
| FC-Siam-diff | 0.8697 | 0.5960 | 0.7073 | 0.9418 |
| UNet++_MSOF | 0.8954 | 0.8711 | 0.8756 | 0.9673 |
| IFN | 0.9496 | 0.8608 | 0.9030 | 0.9771 |
| SNUNet-CD/32 | 0.9555 | 0.9483 | 0.9519 | 0.9887 |
| Proposed method | 0.9677 | 0.9575 | 0.9626 | 0.9912 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Hu, L.; Zhang, Y.; Li, Y. MRA-SNet: Siamese Networks of Multiscale Residual and Attention for Change Detection in High-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 4528. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13224528
Yang X, Hu L, Zhang Y, Li Y. MRA-SNet: Siamese Networks of Multiscale Residual and Attention for Change Detection in High-Resolution Remote Sensing Images. Remote Sensing. 2021; 13(22):4528. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13224528
Chicago/Turabian StyleYang, Xin, Lei Hu, Yongmei Zhang, and Yunqing Li. 2021. "MRA-SNet: Siamese Networks of Multiscale Residual and Attention for Change Detection in High-Resolution Remote Sensing Images" Remote Sensing 13, no. 22: 4528. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13224528