Classification of Very-High-Spatial-Resolution Aerial Images Based on Multiscale Features with Limited Semantic Information


Abstract
:1. Introduction
- Integrate a new multiscale input strategy and the object-based CNN approach for VHR remote sensing image classification at subdecimeter resolution with limited samples.
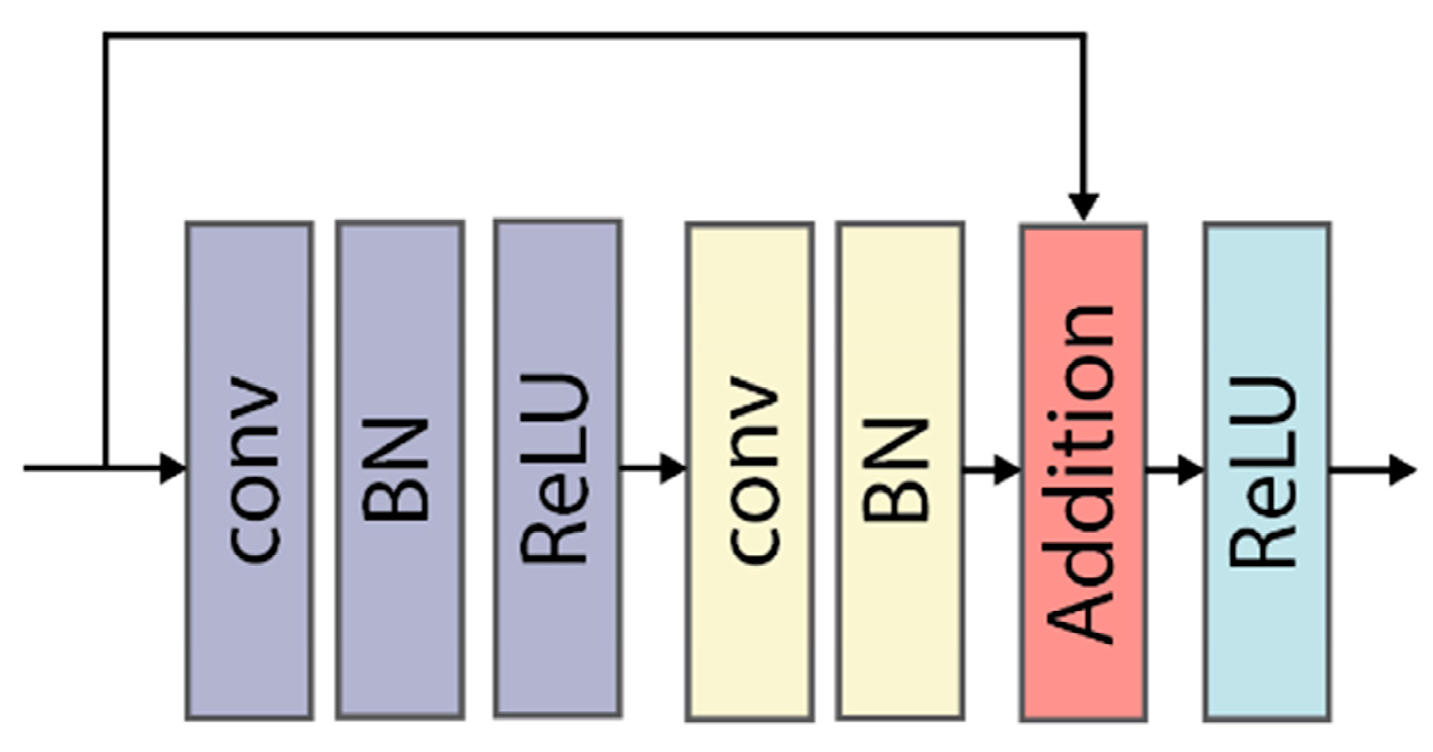
- Design a multibranch neural network structure for obtaining multiscale fusion features. Each branch is composed of residual modules with different depths that act as backbone for feature extracting.
- Develop a weak labeled UAV image dataset of rural landscape for land cover classification to verify the practical feasibility of the proposed approach under various scenarios.
2. Methodology
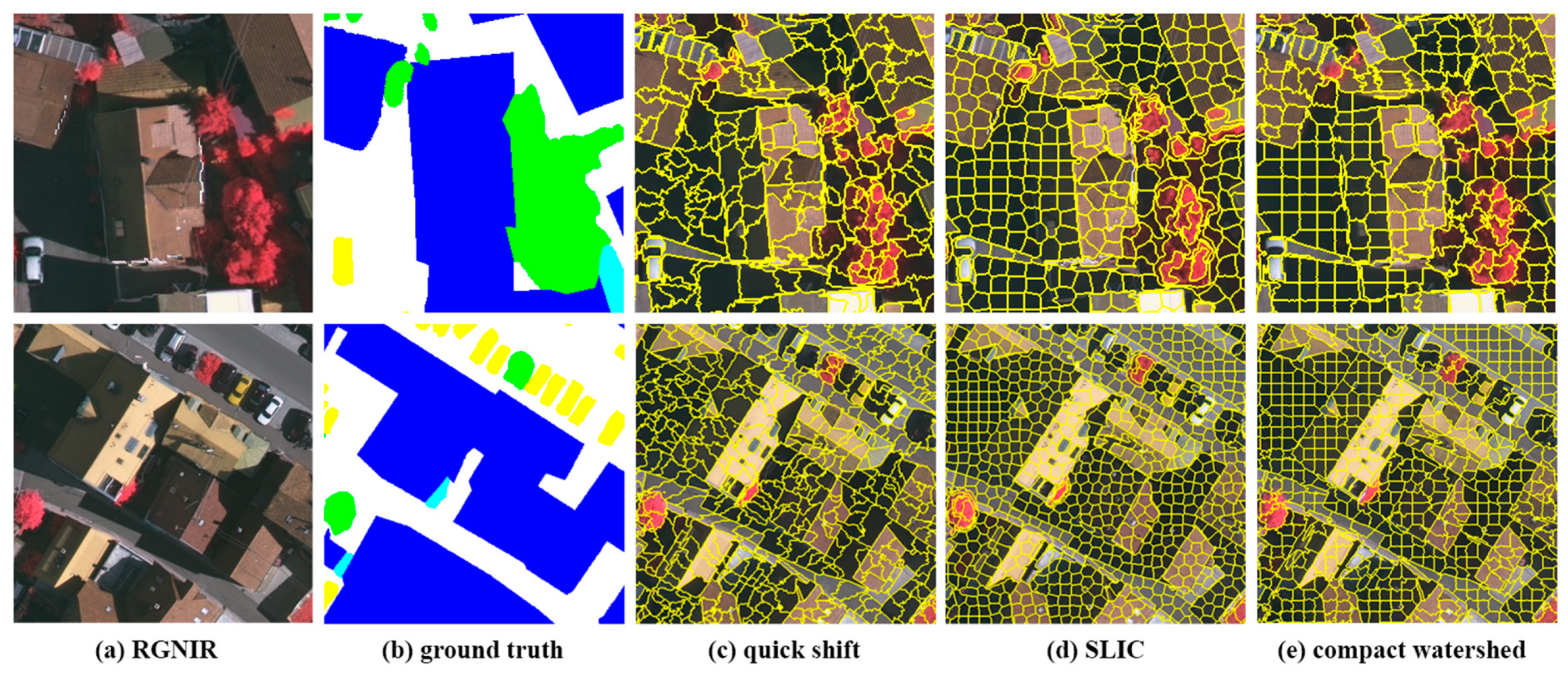
2.1. Presegmentation
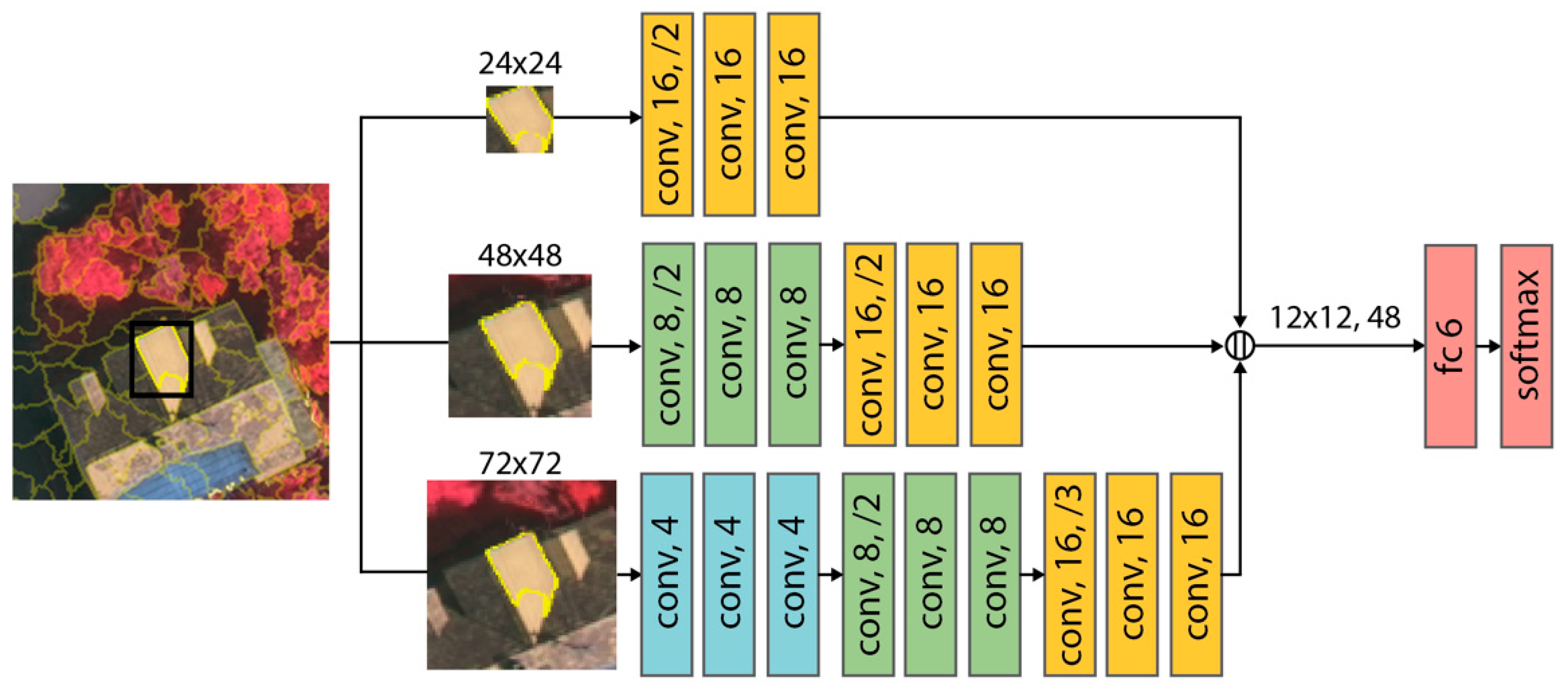
2.2. Framework of MONet
2.3. Boundary Refinement
3. Experiments
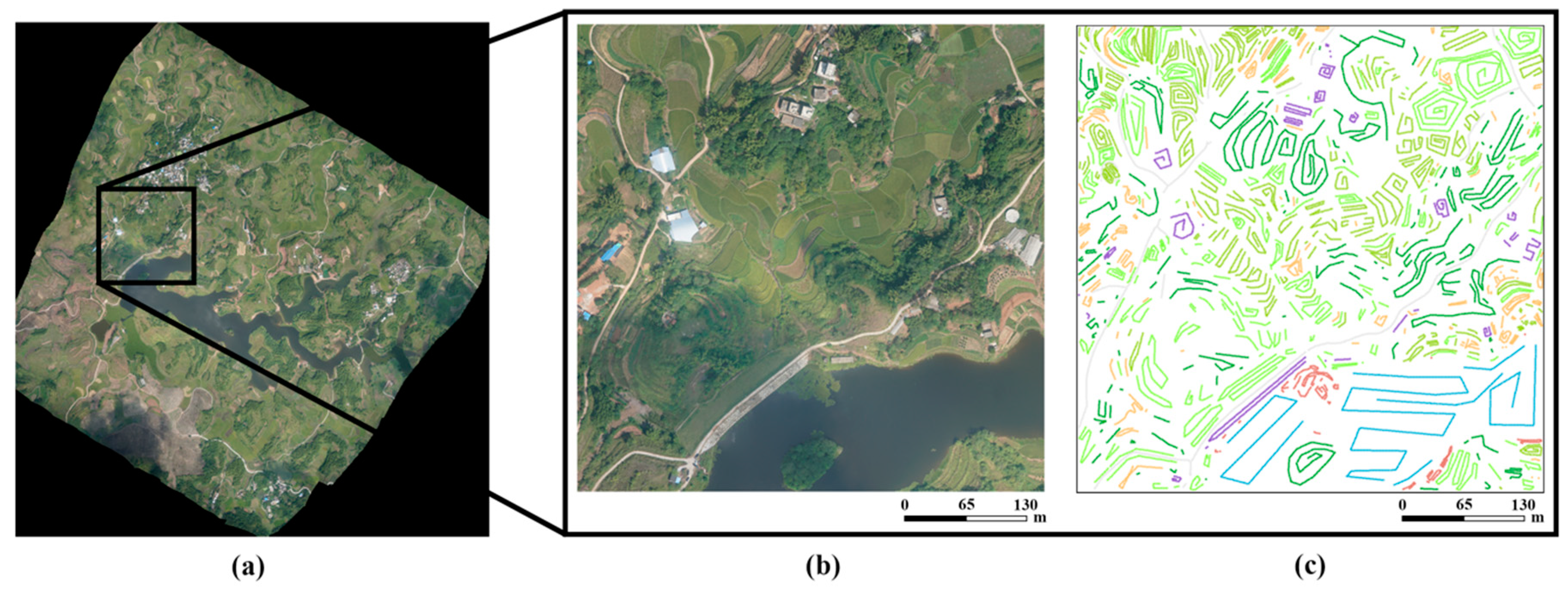
3.1. Dataset Description
3.2. Training Procedure
3.3. Evaluation Metrics
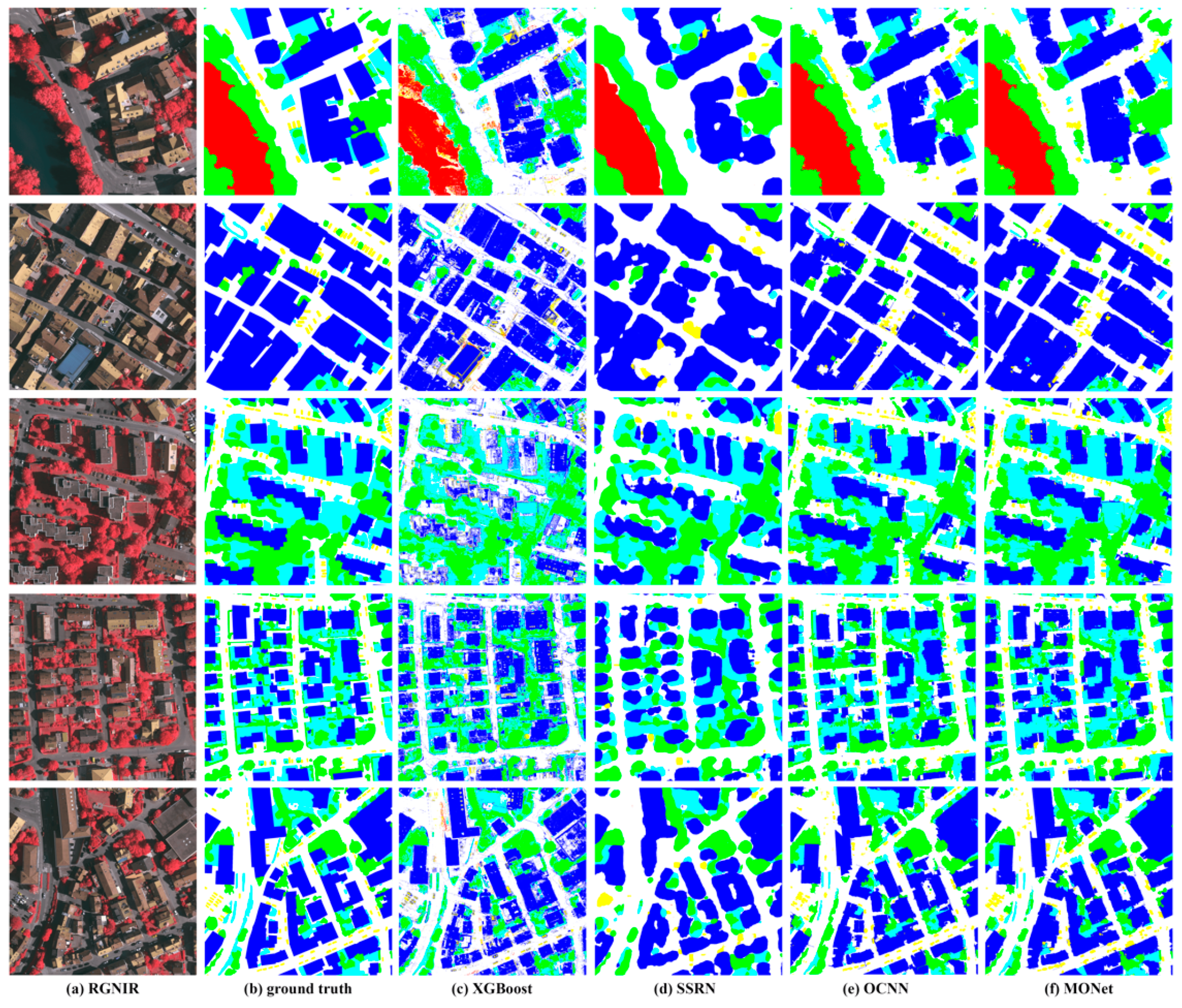
3.4. Method Comparison
4. Discussion
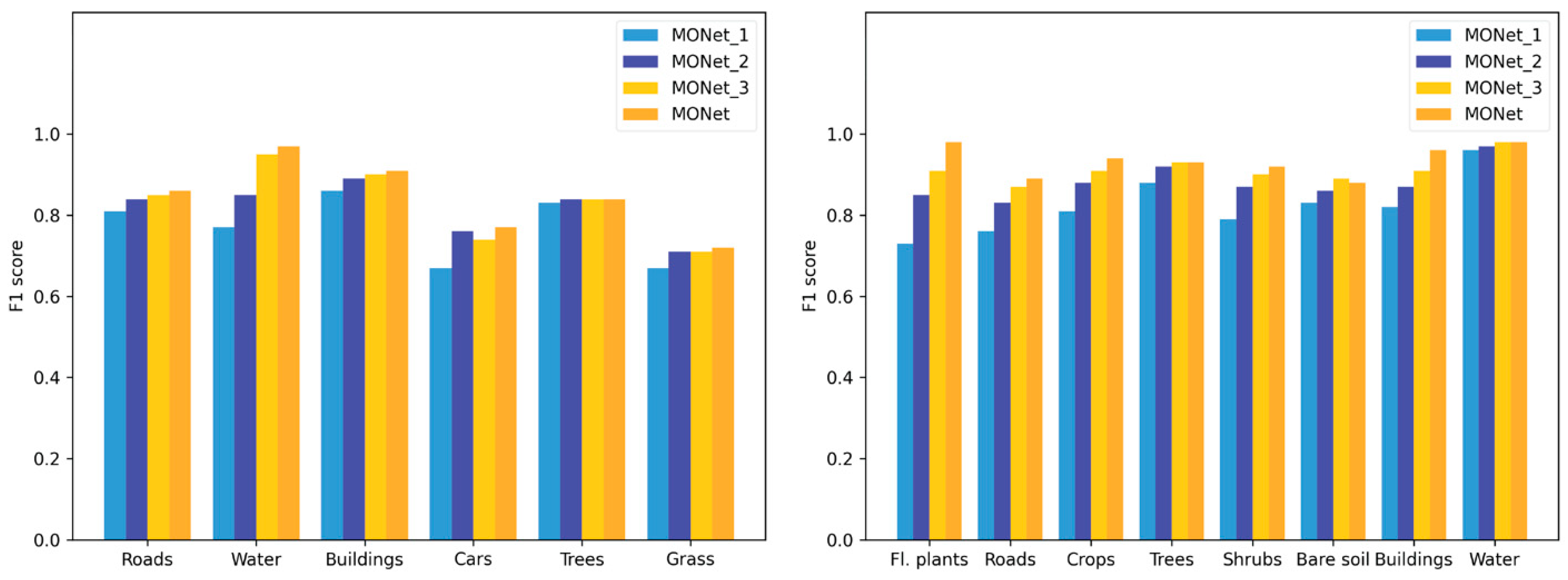
4.1. Effects of MONet and the Multiscale Strategy
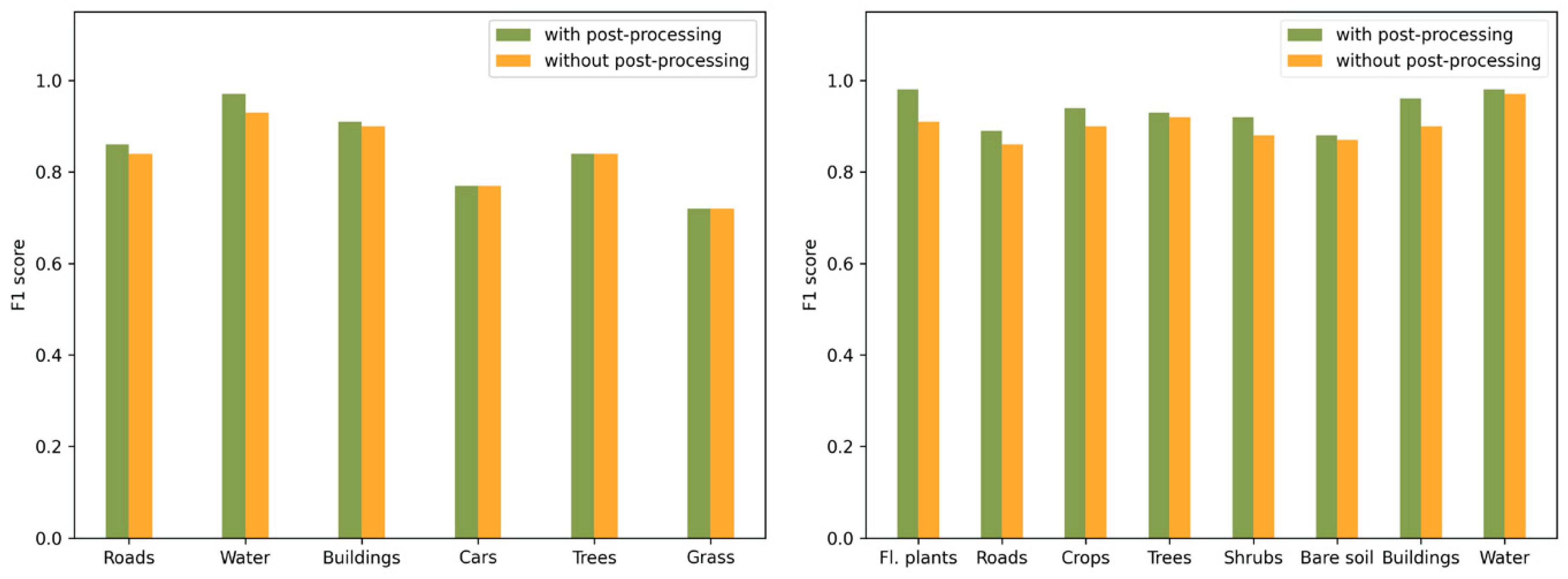
4.2. Effects of Boundary Refinement
4.3. Advantages and Limitations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Huang, B.; Zhao, B.; Song, Y. Urban Land-Use Mapping Using a Deep Convolutional Neural Network with High Spatial Resolution Multispectral Remote Sensing Imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Leotta, M.J.; Long, C.; Jacquet, B.; Zins, M.; Lipsa, D.; Shan, J.; Xu, B.; Li, Z.; Zhang, X.; Chang, S.-F.; et al. Urban Semantic 3D Reconstruction From Multiview Satellite Imagery. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 1451–1460. [Google Scholar]
- Liu, T.; Abd-Elrahman, A. Deep Convolutional Neural Network Training Enrichment Using Multi-View Object-Based Analysis of Unmanned Aerial Systems Imagery for Wetlands Classification. ISPRS J. Photogramm. Remote Sens. 2018, 139, 154–170. [Google Scholar] [CrossRef]
- Colomina, I.; Molina, P. Unmanned Aerial Systems for Photogrammetry and Remote Sensing: A Review. ISPRS J. Photogramm. Remote Sens. 2014, 92, 79–97. [Google Scholar] [CrossRef] [Green Version]
- Ban, Y.; Gong, P.; Giri, C. Global Land Cover Mapping Using Earth Observation Satellite Data: Recent Progresses and Challenges. ISPRS J. Photogramm. Remote Sens. 2015, 103, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very High Resolution Urban Remote Sensing with Multimodal Deep Networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Martins, V.S.; Kaleita, A.L.; Gelder, B.K.; da Silveira, H.L.F.; Abe, C.A. Exploring Multiscale Object-Based Convolutional Neural Network (Multi-OCNN) for Remote Sensing Image Classification at High Spatial Resolution. ISPRS J. Photogramm. Remote Sens. 2020, 168, 56–73. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in Very High Resolution Remote Sensing Imagery Using Deep Learning and Guided Filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep Learning in Remote Sensing Applications: A Meta-Analysis and Review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Li, M.; Zang, S.; Zhang, B.; Li, S.; Wu, C. A Review of Remote Sensing Image Classification Techniques: The Role of Spatio-Contextual Information. Eur. J. Remote Sens. 2014, 47, 389–411. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A Meta-Analysis of Remote Sensing Research on Supervised Pixel-Based Land-Cover Image Classification Processes: General Guidelines for Practitioners and Future Research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Weng, Q. A Survey of Image Classification Methods and Techniques for Improving Classification Performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support Vector Machines in Remote Sensing: A Review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A Review of Supervised Object-Based Land-Cover Image Classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a New Paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [Green Version]
- Hay, G.; Castilla, G. Geographic Object-Based Image Analysis (GEOBIA): A New Name for A New Discipline. In Object-Based Image Analysis—Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Springer: Berlin/Heidelberg, Germany, 2008; pp. 75–89. ISBN 978-3-540-77057-2. [Google Scholar]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-Pixel vs. Object-Based Classification of Urban Land Cover Extraction Using High Spatial Resolution Imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. A Comparison of Pixel-Based and Object-Based Image Analysis with Selected Machine Learning Algorithms for the Classification of Agricultural Landscapes Using SPOT-5 HRG Imagery. Remote Sens. Environ. 2012, 118, 259–272. [Google Scholar] [CrossRef]
- Li, M.; Ma, L.; Blaschke, T.; Cheng, L.; Tiede, D. A Systematic Comparison of Different Object-Based Classification Techniques Using High Spatial Resolution Imagery in Agricultural Environments. Int. J. Appl. Earth Obs. Geoinf. 2016, 49, 87–98. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebuv, M.N. A Comparative Assessment between Object and Pixel-Based Classification Approaches for Land Use/Land Cover Mapping Using SPOT 5 Imagery. Geocarto Int. 2014, 29, 351–369. [Google Scholar] [CrossRef]
- Arvor, D.; Durieux, L.; Andrés, S.; Laporte, M.-A. Advances in Geographic Object-Based Image Analysis with Ontologies: A Review of Main Contributions and Limitations from a Remote Sensing Perspective. ISPRS J. Photogramm. Remote Sens. 2013, 82, 125–137. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S.; Emery, W.J. Object-Based Convolutional Neural Network for High-Resolution Imagery Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3386–3396. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning Hierarchical Features for Scene Labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Ben Hamida, A.; Benoit, A.; Lambert, P.; Ben Amar, C. 3-D Deep Learning Approach for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Y.; Han, X.; Zhang, L. Multi-Class Geospatial Object Detection Based on a Position-Sensitive Balancing Framework for High Spatial Resolution Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2018, 138, 281–294. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A Deeply Supervised Image Fusion Network for Change Detection in High Resolution Bi-Temporal Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Ji, S.; Shen, Y.; Lu, M.; Zhang, Y. Building Instance Change Detection from Large-Scale Aerial Images Using Convolutional Neural Networks and Simulated Samples. Remote Sens. 2019, 11, 1343. [Google Scholar] [CrossRef] [Green Version]
- Bejiga, M.B.; Melgani, F. Gan-Based Domain Adaptation for Object Classification. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1264–1267. [Google Scholar]
- Zhang, S.; Wu, R.; Xu, K.; Wang, J.; Sun, W. R-CNN-Based Ship Detection from High Resolution Remote Sensing Imagery. Remote Sens. 2019, 11, 631. [Google Scholar] [CrossRef] [Green Version]
- Xu, S.; Mu, X.; Chai, D.; Zhang, X. Remote Sensing Image Scene Classification Based on Generative Adversarial Networks. Remote Sens. Lett. 2018, 9, 617–626. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Tuia, D.; Flamary, R.; Courty, N. Multiclass Feature Learning for Hyperspectral Image Classification: Sparse and Hierarchical Solutions. ISPRS J. Photogramm. Remote Sens. 2015, 105, 272–285. [Google Scholar] [CrossRef] [Green Version]
- Sharma, A.; Liu, X.; Yang, X.; Shi, D. A Patch-Based Convolutional Neural Network for Remote Sensing Image Classification. Neural Netw. 2017, 95, 19–28. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Learning Multiscale and Deep Representations for Classifying Remotely Sensed Imagery. ISPRS J. Photogramm. Remote Sens. 2016, 113, 155–165. [Google Scholar] [CrossRef]
- Li, P.; Ren, P.; Zhang, X.; Wang, Q.; Zhu, X.; Wang, L. Region-Wise Deep Feature Representation for Remote Sensing Images. Remote Sens. 2018, 10, 871. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Du, S.; Wang, Q.; Emery, W.J. Contextually Guided Very-High-Resolution Imagery Classification with Semantic Segments. ISPRS J. Photogramm. Remote Sens. 2017, 132, 48–60. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Vakalopoulou, M.; Karantzalos, K. A Novel Object-Based Deep Learning Framework for Semantic Segmentation of Very High-Resolution Remote Sensing Data: Comparison with Convolutional and Fully Convolutional Networks. Remote Sens. 2019, 11, 684. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Saux, B.L.; Lefèvre, S. Semantic Segmentation of Earth Observation Data Using Multimodal and Multi-Scale Deep Networks. arXiv 2016, arXiv:1609.06846. [Google Scholar]
- Li, W.; He, C.; Fang, J.; Zheng, J.; Fu, H.; Yu, L. Semantic Segmentation-Based Building Footprint Extraction Using Very High-Resolution Satellite Images and Multi-Source GIS Data. Remote Sens. 2019, 11, 403. [Google Scholar] [CrossRef] [Green Version]
- Ghazouani, F.; Farah, I.R.; Solaiman, B. Semantic Remote Sensing Scenes Interpretation. In Ontology in Information Science; Thomas, C., Ed.; InTech: London, UK, 2018; ISBN 978-953-51-3887-7. [Google Scholar]
- Huang, B.; Lu, K.; Audeberr, N.; Khalel, A.; Tarabalka, Y.; Malof, J.; Boulch, A.; Le Saux, B.; Collins, L.; Bradbury, K.; et al. Large-Scale Semantic Classification: Outcome of the First Year of Inria Aerial Image Labeling Benchmark. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 6947–6950. [Google Scholar]
- Yao, X.; Han, J.; Cheng, G.; Qian, X.; Guo, L. Semantic Annotation of High-Resolution Satellite Images via Weakly Supervised Learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3660–3671. [Google Scholar] [CrossRef]
- Liu, Y.; Piramanayagam, S.; Monteiro, S.T.; Saber, E. Dense Semantic Labeling of Very-High-Resolution Aerial Imagery and LiDAR with Fully-Convolutional Neural Networks and Higher-Order CRFs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1561–1570. [Google Scholar]
- Yang, Z.; Jiang, W.; Xu, B.; Zhu, Q.; Jiang, S.; Huang, W. A Convolutional Neural Network-Based 3D Semantic Labeling Method for ALS Point Clouds. Remote Sens. 2017, 9, 936. [Google Scholar] [CrossRef] [Green Version]
- Lateef, F.; Ruichek, Y. Survey on Semantic Segmentation Using Deep Learning Techniques. Neurocomputing 2019, 338, 321–348. [Google Scholar] [CrossRef]
- Vedaldi, A.; Soatto, S. Quick Shift and Kernel Methods for Mode Seeking. In Proceedings of the Computer Vision—ECCV 2008, Marseille, France, 12–18 October 2008; Forsyth, D., Torr, P., Zisserman, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 705–718. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Neubert, P.; Protzel, P. Compact Watershed and Preemptive SLIC: On Improving Trade-offs of Superpixel Segmentation Algorithms. In Proceedings of the 2014 22nd International Conference on Pattern Recognition (ICPR 2014), Stockholm, Sweden, 24–28 August 2014; pp. 996–1001. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer: Cham, Switzerland, 2015; Volume 9351, p. 241. ISBN 978-3-319-24573-7. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Baatz, M.; Schäpe, A. Multiresolution Segmentation: An Optimization Approach for High Quality Multi-Scale Image Segmentation. J. Geosci. Geomat. 2018, 6, 103–123. [Google Scholar]
- Gao, H.; Tang, Y.; Jing, L.; Li, H.; Ding, H. A Novel Unsupervised Segmentation Quality Evaluation Method for Remote Sensing Images. Sensors 2017, 17, 2427. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. arXiv 2012, arXiv:1210.5644. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; p. 794. [Google Scholar]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Legend | Training | Test |
|---|---|---|---|
| Roads |  | 18,856 | 6375 |
| Water |  | 595 | 197 |
| Buildings |  | 20,015 | 6671 |
| Cars |  | 3125 | 975 |
| Trees |  | 11,228 | 3717 |
| Grass |  | 8377 | 2797 |
| Total | \ | 62,196 | 20,732 |
| Class | Legend | Training | Test |
|---|---|---|---|
| Floating plants |  | 2674 | 911 |
| Roads |  | 3779 | 1196 |
| Crops |  | 14,979 | 4922 |
| Trees |  | 14,350 | 4749 |
| Shrubs |  | 18,252 | 6248 |
| Bare soil |  | 8095 | 2726 |
| Buildings |  | 1464 | 454 |
| Water |  | 4485 | 1480 |
| Total | \ | 68,078 | 22,686 |
| True Condition | |||
|---|---|---|---|
| Condition Positive | Condition Negative | ||
| Predicted condition | Predicted condition positive | TP | FP |
| Predicted condition negative | FN | TN | |
| XGBoost | SSRN | OCNN | MONet_1 | MONet_2 | MONet_3 | MONet | |
|---|---|---|---|---|---|---|---|
| Roads | 0.701 | 0.728 | 0.829 | 0.792 | 0.817 | 0.840 | 0.848 |
| Water | 0.728 | 0.919 | 0.882 | 0.848 | 0.903 | 0.978 | 0.965 |
| Buildings | 0.822 | 0.847 | 0.910 | 0.851 | 0.894 | 0.885 | 0.912 |
| Cars | 0.669 | 0.614 | 0.848 | 0.714 | 0.797 | 0.787 | 0.796 |
| Trees | 0.778 | 0.790 | 0.818 | 0.831 | 0.839 | 0.828 | 0.845 |
| Grass | 0.570 | 0.718 | 0.738 | 0.699 | 0.733 | 0.754 | 0.734 |
| F1 | 0.730 | 0.780 | 0.840 | 0.800 | 0.830 | 0.840 | 0.850 |
| OA | 0.732 | 0.779 | 0.843 | 0.804 | 0.835 | 0.841 | 0.852 |
| # of parameters | \ | 47,518 | 181,854 | 28,918 | 31,150 | 31,686 | 91,742 |
| XGBoost | SSRN | OCNN | MONet_1 | MONet_2 | MONet_3 | MONet | |
|---|---|---|---|---|---|---|---|
| Fl. plants | 0.553 | 0.875 | 0.945 | 0.676 | 0.787 | 0.850 | 0.970 |
| Roads | 0.776 | 0.860 | 0.942 | 0.774 | 0.842 | 0.883 | 0.957 |
| Crops | 0.482 | 0.877 | 0.956 | 0.813 | 0.881 | 0.916 | 0.947 |
| Trees | 0.601 | 0.890 | 0.903 | 0.850 | 0.891 | 0.901 | 0.919 |
| Shrubs | 0.569 | 0.862 | 0.917 | 0.830 | 0.904 | 0.924 | 0.908 |
| Bare soil | 0.707 | 0.800 | 0.828 | 0.825 | 0.869 | 0.891 | 0.871 |
| Buildings | 0.756 | 0.778 | 0.959 | 0.821 | 0.888 | 0.927 | 0.975 |
| Water | 0.809 | 0.920 | 0.985 | 0.947 | 0.962 | 0.978 | 0.987 |
| F1 | 0.610 | 0.870 | 0.920 | 0.830 | 0.890 | 0.910 | 0.930 |
| OA | 0.607 | 0.866 | 0.918 | 0.828 | 0.887 | 0.911 | 0.925 |
| # of parameters | \ | 47,593 | 182,253 | 35,833 | 38,065 | 38,601 | 112,481 |
| XGBoost | SSRN | OCNN | MONet_1 | MONet_2 | MONet_3 | MONet | |
|---|---|---|---|---|---|---|---|
| Time (s) | 4.3 | 634.7 | 192.2 | 8.8 | 9.3 | 10.0 | 11.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, H.; Guo, J.; Guo, P.; Chen, X. Classification of Very-High-Spatial-Resolution Aerial Images Based on Multiscale Features with Limited Semantic Information. Remote Sens. 2021, 13, 364. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13030364
Gao H, Guo J, Guo P, Chen X. Classification of Very-High-Spatial-Resolution Aerial Images Based on Multiscale Features with Limited Semantic Information. Remote Sensing. 2021; 13(3):364. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13030364
Chicago/Turabian StyleGao, Han, Jinhui Guo, Peng Guo, and Xiuwan Chen. 2021. "Classification of Very-High-Spatial-Resolution Aerial Images Based on Multiscale Features with Limited Semantic Information" Remote Sensing 13, no. 3: 364. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13030364