
Mapping Surficial Soil Particle Size Fractions in Alpine Permafrost Regions of the Qinghai–Tibet Plateau

 , ,
, ,
Abstract
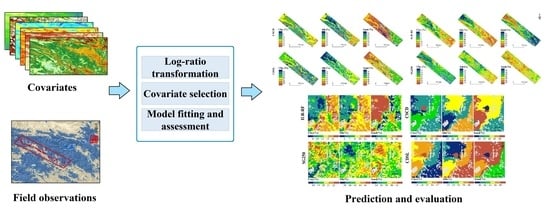
:
1. Introduction
2. Materials and Methods
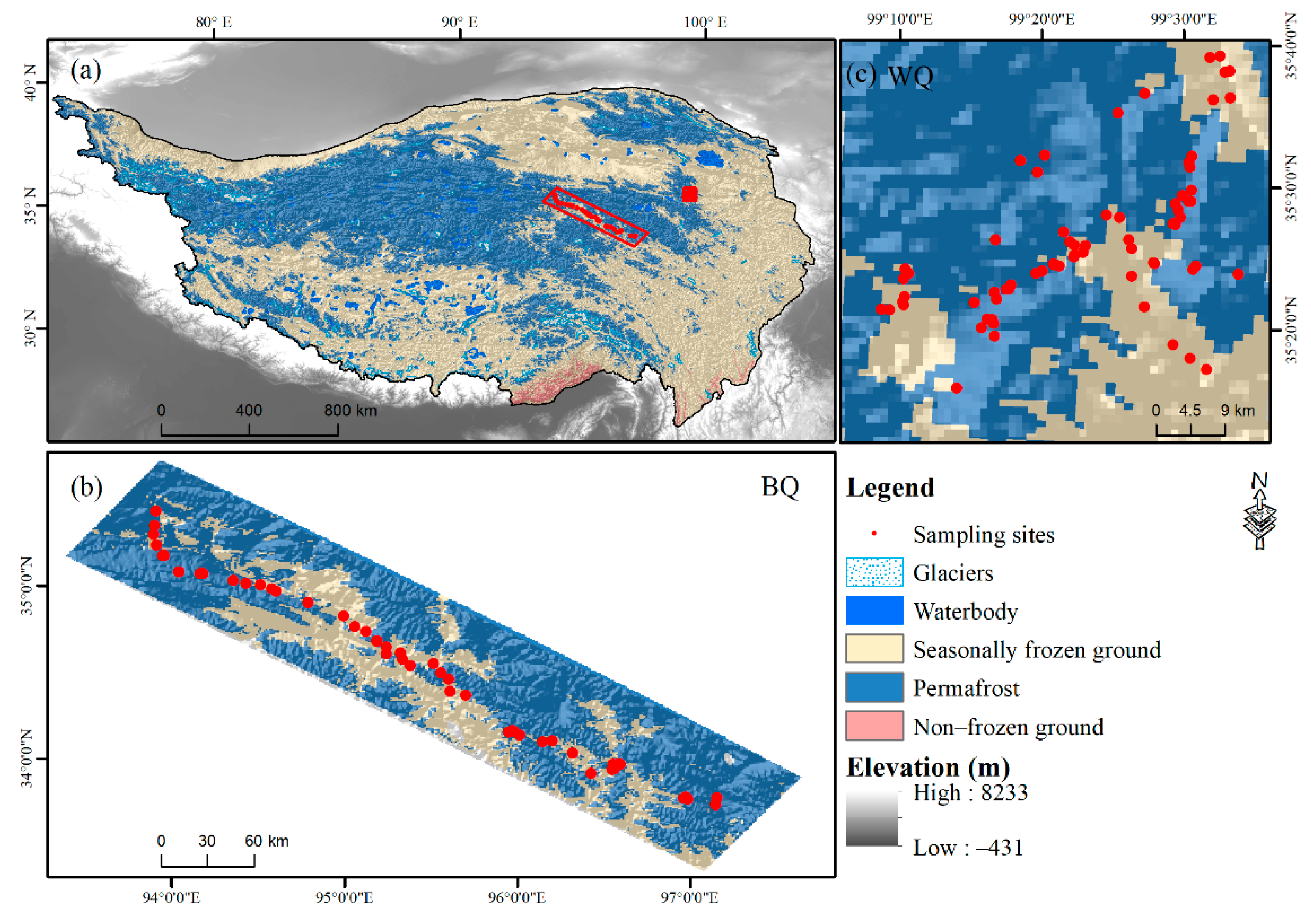
2.1. Study Area
2.2. Data Sources
2.2.1. Soil Sampling
2.2.2. The Environmental Covariates
2.2.3. Existing Datasets of Soil PSFs
2.3. Compositional Data and Transformation
2.3.1. Conversion of PSFs in the Surface Layer
2.3.2. Transformation of Compositional Data
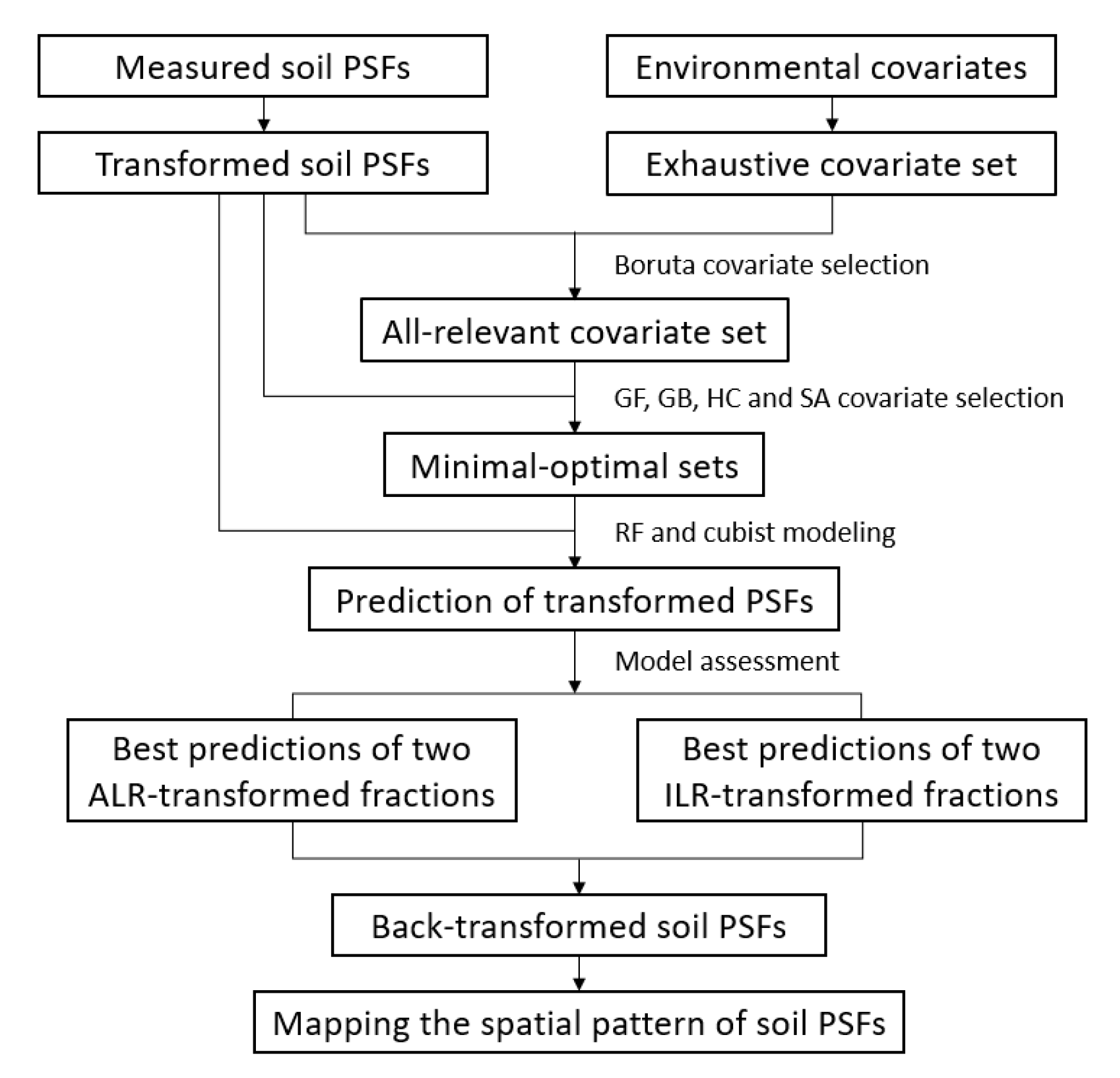
2.4. Covariate Selection Techniques
2.5. Development and Assessment of Predictive Models
3. Results
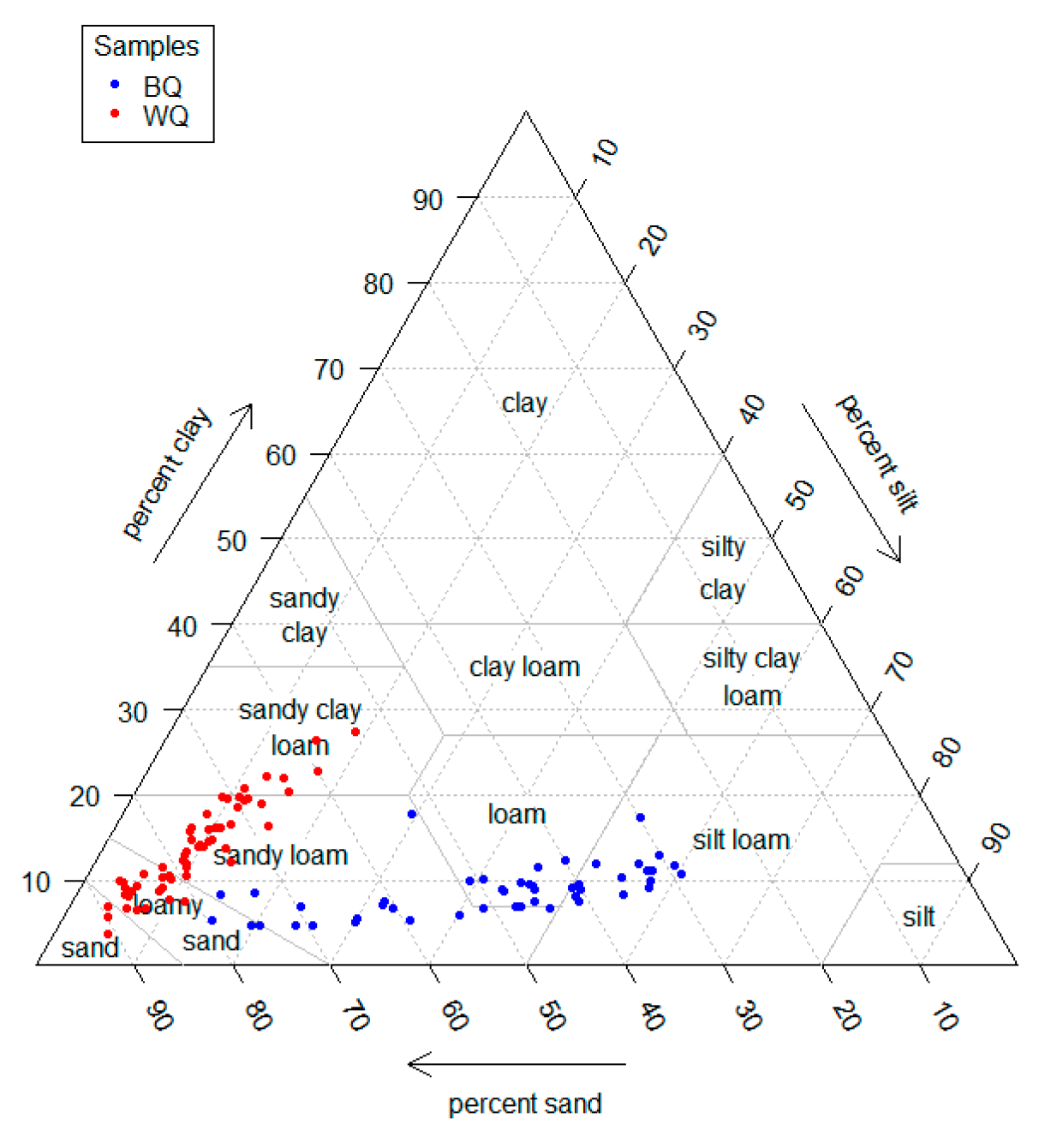
3.1. Descriptive Statistics of Observations
3.2. Covariate Sets
3.2.1. All-Relevant Variable Set
3.2.2. Minimal-Optimal Variable Set
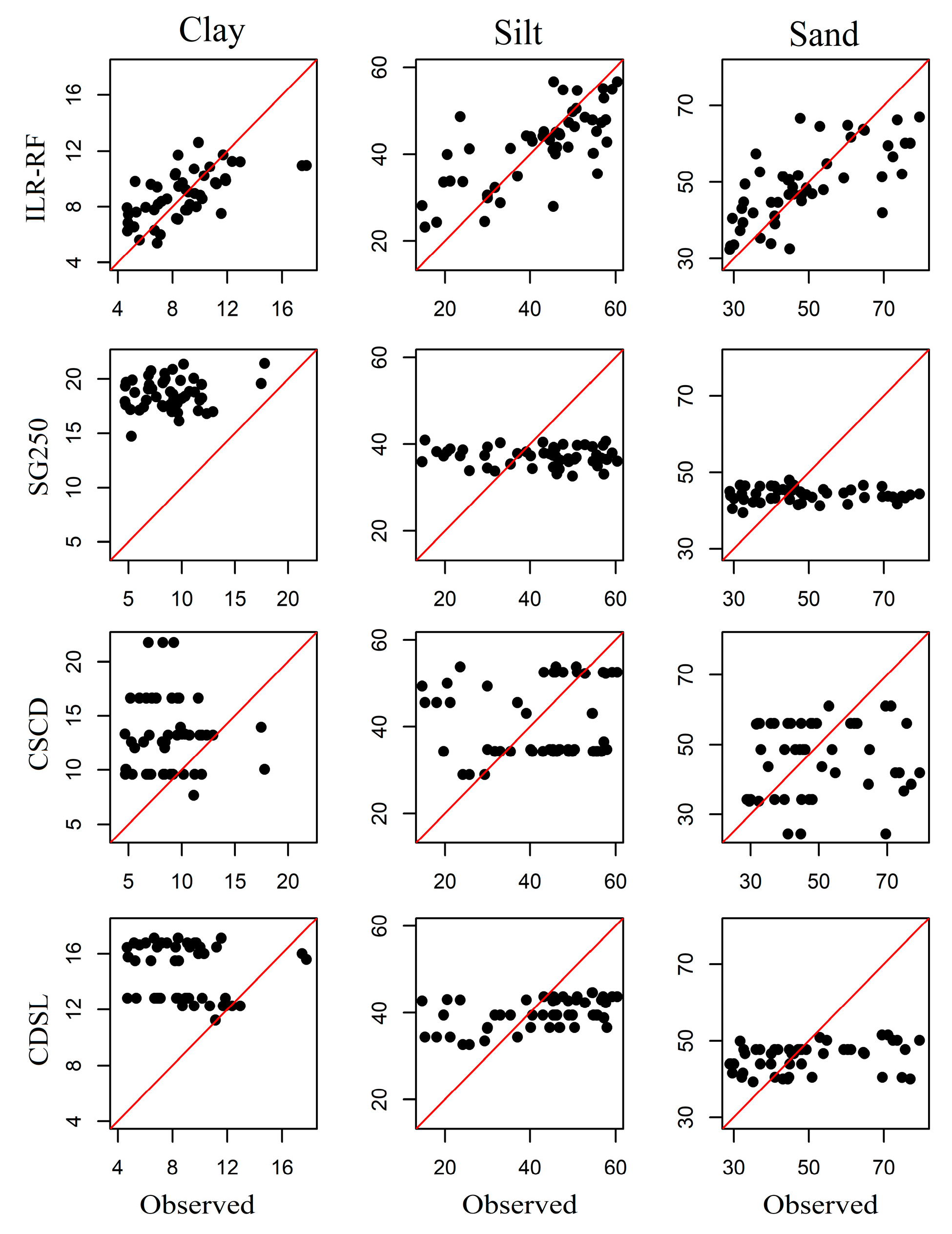
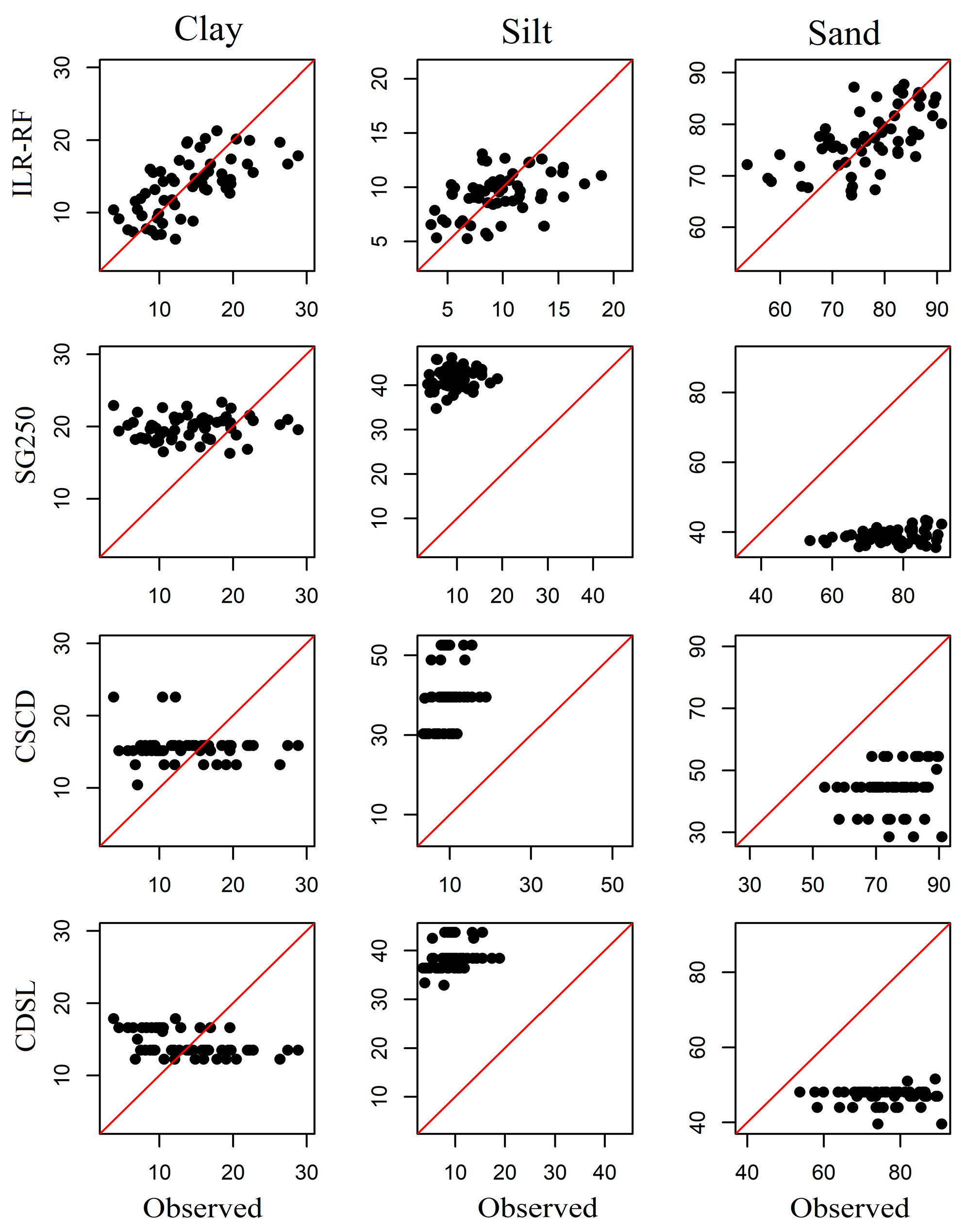
3.3. Assessment of Model Performance
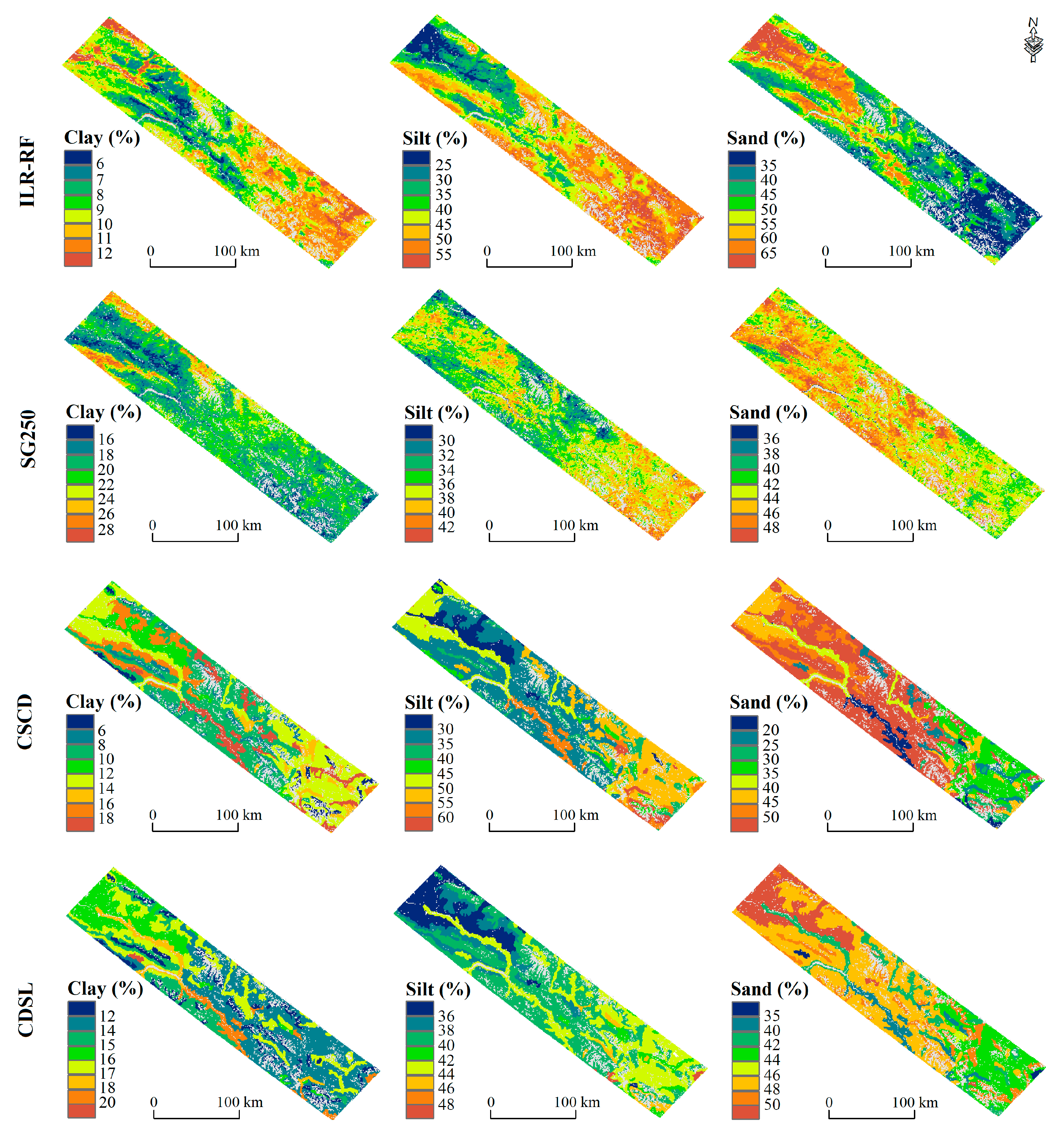
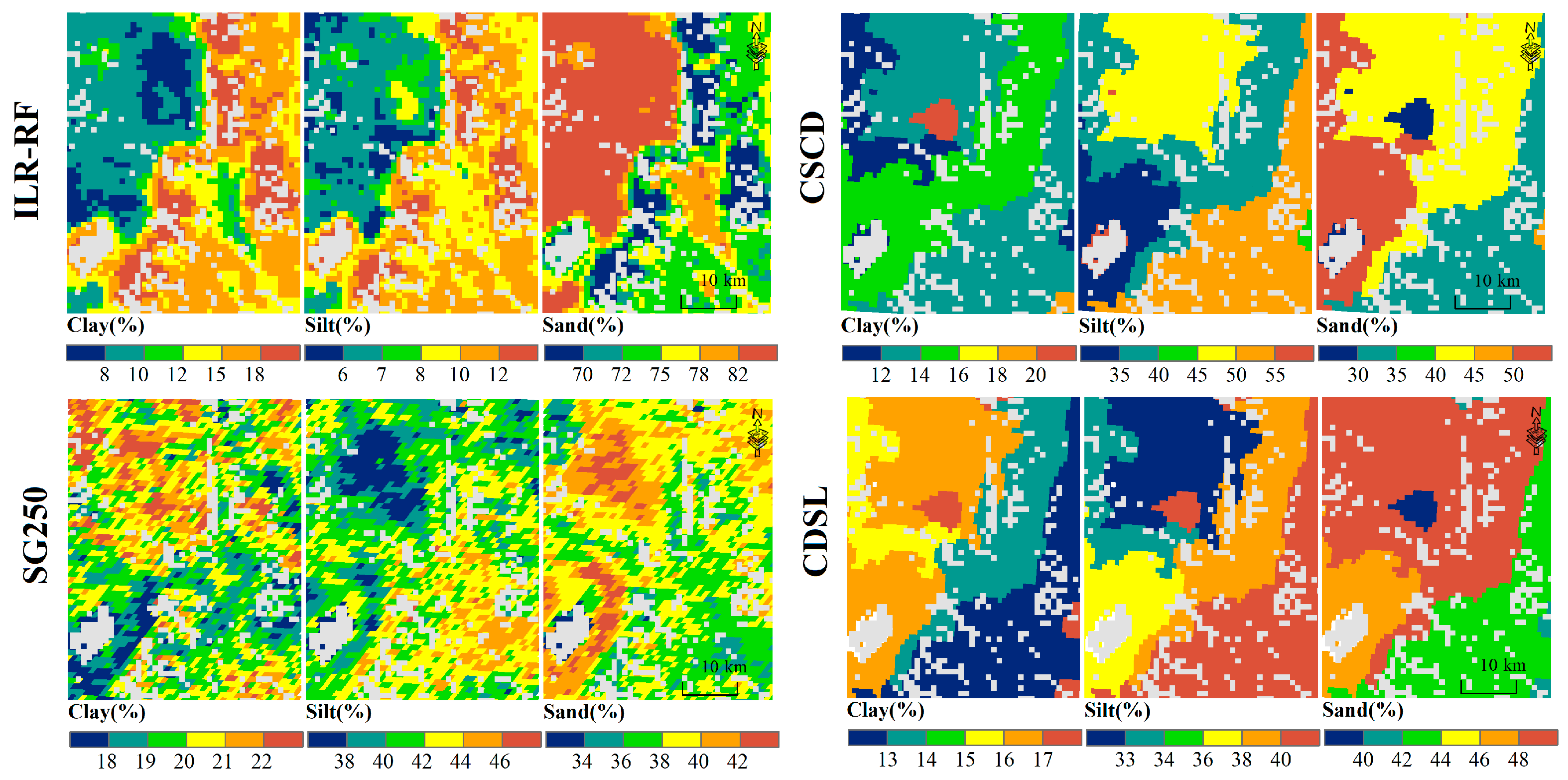
3.4. Spatial Distribution of the Predicted Soil PSFs
4. Discussion
4.1. Covariates Most Relevant to Soil PSF Mapping
4.2. Prediction Models
4.3. Spatial Distribution
4.4. Comparison with Existing Maps
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Amirian-Chakan, A.; Minasny, B.; Taghizadeh-Mehrjardi, R.; Akbarifazli, R.; Darvishpasand, Z.; Khordehbin, S. Some practical aspects of predicting texture data in digital soil mapping. Soil Tillage Res. 2019, 194, 104289. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B. Regression rules as a tool for predicting soil properties from infrared reflectance spectroscopy. Chemom. Intell. Lab. Syst. 2008, 94, 72–79. [Google Scholar] [CrossRef]
- Van Looy, K.; Bouma, J.; Herbst, M.; Koestel, J.; Minasny, B.; Mishra, U.; Montzka, C.; Nemes, A.; Pachepsky, Y.A.; Padarian, J.; et al. Pedotransfer Functions in Earth System Science: Challenges and Perspectives. Rev. Geophys. 2017, 55, 1199–1256. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Xiao, J.; Li, X.; Cheng, G.; Ma, M.; Che, T.; Dai, L.; Wang, S.; Wu, J. No Consistent Evidence for Advancing or Delaying Trends in Spring Phenology on the Tibetan Plateau. J. Geophys. Res. Biogeosci. 2017, 122, 3288–3305. [Google Scholar] [CrossRef]
- Ran, Y.; Li, X.; Cheng, G.; Nan, Z.; Che, J.; Sheng, Y.; Wu, Q.; Jin, H.; Luo, D.; Tang, Z.; et al. Mapping the permafrost stability on the Tibetan Plateau for 2005–2015. Sci. China Earth Sci. 2020, 1–18. [Google Scholar] [CrossRef]
- Zhao, L.; Zou, D.; Hu, G.; Du, E.; Pang, Q.; Xiao, Y.; Li, R.; Sheng, Y.; Wu, X.; Sun, Z.; et al. Changing climate and the permafrost environment on the Qinghai–Tibet (Xizang) plateau. Permafr. Periglac. Process. 2020, 31, 396–405. [Google Scholar] [CrossRef]
- Sun, Z.; Zhao, L.; Hu, G.; Qiao, Y.; Du, E.; Zou, D.; Xie, C. Modeling permafrost changes on the Qinghai–Tibetan plateau from 1966 to 2100: A case study from two boreholes along the Qinghai–Tibet engineering corridor. Permafr. Periglac. Process. 2020, 31, 156–171. [Google Scholar] [CrossRef]
- Hengl, T.; De Jesus, J.M.; Heuvelink, G.B.M.; Gonzalez, M.R.; Kilibarda, M.; Blagotić, A.; Shangguan, W.; Wright, M.N.; Geng, X.; Bauer-Marschallinger, B.; et al. SoilGrids250m: Global gridded soil information based on machine learning. PLoS ONE 2017, 12, 1–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- FAO; CAS; IIASA; ISRIC; JRC. Harmonized World Soil Database (HWSD v 1.21). Available online: https://iiasa.ac.at/web/home/research/researchPrograms/water/HWSD.html (accessed on 31 March 2021).
- Shangguan, W.; Dai, Y.; Liu, B.; Zhu, A.; Duan, Q.; Wu, L.; Ji, D.; Ye, A.; Yuan, H.; Zhang, Q.; et al. A China data set of soil properties for land surface modeling. J. Adv. Model. Earth Syst. 2013, 5, 212–224. [Google Scholar] [CrossRef]
- Odeh, I.O.A.; Todd, A.J.; Triantafilis, J. Spatial prediction of soil particle-size fractions as compositional data. Soil Sci. 2003, 168, 501–515. [Google Scholar] [CrossRef] [Green Version]
- Aitchison, J. The Statistical Analysis of Compositional Data. J. R. Stat. Soc. Ser. B 1982, 44, 139–177. [Google Scholar] [CrossRef]
- Pawlowsky, V.; Olea, R.A.; Davis, J.C. Estimation of regionalized compositions: A comparison of three methods. Math. Geol. 1995, 27, 105–127. [Google Scholar] [CrossRef]
- Sun, X.L.; Wu, Y.J.; Wang, H.L.; Zhao, Y.G.; Zhang, G.L. Mapping Soil Particle Size Fractions Using Compositional Kriging, Cokriging and Additive Log-ratio Cokriging in Two Case Studies. Math. Geosci. 2014, 46, 429–443. [Google Scholar] [CrossRef]
- Egozcue, J.J.; Pawlowsky-Glahn, V.; Mateu-Figueras, G.; Barceló-Vidal, C. Isometric Logratio Transformations for Compositional Data Analysis. Math. Geol. 2003, 35, 279–300. [Google Scholar] [CrossRef]
- McBratney, A.B.; De Gruijter, J.J.; Brus, D.J. Spacial prediction and mapping of continuous soil classes. Geoderma 1992, 54, 39–64. [Google Scholar] [CrossRef]
- Wang, Z.; Shi, W.; Zhou, W.; Li, X.; Yue, T. Comparison of additive and isometric log-ratio transformations combined with machine learning and regression kriging models for mapping soil particle size fractions. Geoderma 2020, 365, 114214. [Google Scholar] [CrossRef]
- McBratney, A.B.; Mendonça Santos, M.L.; Minasny, B. On digital soil mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Wadoux, A.M.J.C.; Minasny, B.; McBratney, A.B. Machine learning for digital soil mapping: Applications, challenges and suggested solutions. Earth-Sci. Rev. 2020, 210, 103359. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B.; Malone, B.P.; Wheeler, I. Digital Mapping of Soil Carbon. Adv. Agron. 2013, 118, 1–47. [Google Scholar] [CrossRef]
- Xiong, X.; Grunwald, S.; Myers, D.B.; Kim, J.; Harris, W.G.; Comerford, N.B. Holistic environmental soil-landscape modeling of soil organic carbon. Environ. Model. Softw. 2014, 57, 202–215. [Google Scholar] [CrossRef]
- Liu, F.; Zhang, G.L.; Song, X.; Li, D.; Zhao, Y.; Yang, J.; Wu, H.; Yang, F. High-resolution and three-dimensional mapping of soil texture of China. Geoderma 2020, 361, 114061. [Google Scholar] [CrossRef]
- Li, W.; Zhao, L.; Wu, X.; Wang, S.; Sheng, Y.; Ping, C.L.; Zhao, Y.; Fang, H.; Shi, W. Soil distribution modeling using inductive learning in the eastern part of permafrost regions in Qinghai-Xizang (Tibetan) Plateau. Catena 2015, 126, 98–104. [Google Scholar] [CrossRef]
- Khaledian, Y.; Miller, B.A. Selecting appropriate machine learning methods for digital soil mapping. Appl. Math. Model. 2020, 81, 401–418. [Google Scholar] [CrossRef]
- Lu, Y.Y.; Liu, F.; Zhao, Y.G.; Song, X.D.; Zhang, G.L. An integrated method of selecting environmental covariates for predictive soil depth mapping. J. Integr. Agric. 2019, 18, 301–315. [Google Scholar] [CrossRef]
- Liang, P.; Qin, C.; Zhu, A.; Hou, Z.; Fan, N.; Wang, Y. A case-based method of selecting covariates for digital soil mapping. J. Integr. Agric. 2020, 19, 2127–2136. [Google Scholar] [CrossRef]
- Iguyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Nilsson, R.; Peña, J.M.; Björkegren, J.; Tegnér, J. Consistent feature selection for pattern recognition in polynomial time. J. Mach. Learn. Res. 2007, 8, 589–612. [Google Scholar]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Yue, G.; Zhao, L.; Wang, Z.; Zhang, L.; Zou, D.; Niu, L.; Zhao, Y.; Qiao, Y. Spatial Variation in Biomass and Its Relationships to Soil Properties in the Permafrost Regions Along the Qinghai-Tibet Railway. Environ. Eng. Sci. 2017, 34, 130–137. [Google Scholar] [CrossRef]
- Zhao, L.; Wu, X.; Wang, Z.; Sheng, Y.; Fang, H.; Zhao, Y.; Hu, G.; Li, W.; Pang, Q.; Shi, J.; et al. Soil organic carbon and total nitrogen pools in permafrost zones of the Qinghai-Tibetan Plateau. Sci. Rep. 2018, 8, 1–9. [Google Scholar] [CrossRef]
- Cao, Z.; Cheng, T.; Ma, X.; Tian, Y.; Zhu, Y.; Yao, X.; Chen, Q.; Liu, S.; Guo, Z.; Zhen, Q.; et al. A new three-band spectral index for mitigating the saturation in the estimation of leaf area index in wheat. Int. J. Remote Sens. 2017, 38, 3865–3885. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, K.; Tang, W.; Qin, J.; Zhao, L. Parameterizing soil organic carbon’s impacts on soil porosity and thermal parameters for Eastern Tibet grasslands. Sci. China Earth Sci. 2012, 55, 1001–1011. [Google Scholar] [CrossRef]
- Bi, H.; Ma, J.; Zheng, W.; Zeng, J. Comparison of soil moisture in GLDAS model simulations and in situ observations over the Tibetan Plateau. J. Geophys. Res. Atmos. 2016, 121, 2658–2678. [Google Scholar] [CrossRef] [Green Version]
- Zheng, G.; Yang, Y.; Yang, D.; Dafflon, B.; Yi, Y.; Zhang, S.; Chen, D.; Gao, B.; Wang, T.; Shi, R.; et al. Remote sensing spatiotemporal patterns of frozen soil and the environmental controls over the Tibetan Plateau during 2002–2016. Remote Sens. Environ. 2020, 247, 111927. [Google Scholar] [CrossRef]
- Fang, H.; Zhao, L.; Wu, X.; Zhao, Y.; Zhao, Y.; Hu, G. Soil taxonomy and distribution characteristics of the permafrost region in the Qinghai-Tibet Plateau, China. J. Mt. Sci. 2015, 12, 1448–1459. [Google Scholar] [CrossRef]
- Zou, D.; Zhao, L.; Sheng, Y.; Chen, J.; Hu, G.; Wu, T.; Wu, J.; Xie, C.; Wu, X.; Pang, Q.; et al. A new map of permafrost distribution on the Tibetan Plateau. Cryosph. 2017, 11, 2527–2542. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Zhao, L.; Wu, X.; Zhao, Y.; Fang, H.; Shi, W. Distribution of soils and landform relationships in the permafrost regions of Qinghai-Xizang (Tibetan) Plateau. Chinese Sci. Bull. 2015, 60, 2216–2226. [Google Scholar] [CrossRef]
- Schoeneberger, P.J.; Wysocki, D.A.; Benham, E.C.; Staff, S.S. Field Book for Describing and Sampling Soils Version 3.0; National Resources Conservation Service, National Soil Survey Center: Lincoln, NE, USA, 2012; ISBN 1782664092. [Google Scholar]
- Zhang, Y.; Ji, W.; Saurette, D.D.; Easher, T.H.; Li, H.; Shi, Z.; Adamchuk, V.I.; Biswas, A. Three-dimensional digital soil mapping of multiple soil properties at a field-scale using regression kriging. Geoderma 2020, 366, 114253. [Google Scholar] [CrossRef]
- Zhang, G.; Gong, Z. Soil Survey Laboratory Methods; Science Press: Beijing, China, 2012. [Google Scholar]
- Peng, S.; Ding, Y.; Liu, W.; Li, Z. 1 km monthly temperature and precipitation dataset for China from 1901 to 2017. Earth Syst. Sci. Data 2019, 11, 1931–1946. [Google Scholar] [CrossRef] [Green Version]
- NASA LAADS DAAC. Available online: https://ladsweb.modaps.eosdis.nasa.gov/search/ (accessed on 31 March 2021).
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1-km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Yan, C.; Chang, C.; Xie, J. Land Cover Data Sets in Northwestern China from 1990 to 2010. Available online: http://www.crensed.ac.cn/portal/metadata/215ea67d-cfa5-4636-8a12-dec526332224 (accessed on 31 March 2021).
- Shangguan, W.; Dai, Y.; Liu, B.; Ye, A.; Yuan, H. A soil particle-size distribution dataset for regional land and climate modelling in China. Geoderma 2012, 171–172, 85–91. [Google Scholar] [CrossRef]
- Filzmoser, P.; Hron, K. Outlier detection for compositional data using robust methods. Math. Geosci. 2008, 40, 233–248. [Google Scholar] [CrossRef]
- Van den Boogaart, K.G.; Tolosana-Delgado, R. “compositions”: A unified R package to analyze compositional data. Comput. Geosci. 2008, 34, 320–338. [Google Scholar] [CrossRef]
- Grunwald, S. Environmental Soil-Landscape Modeling: Geographic Information Technologies and Pedometrics; CRC Press/Taylor & Francis Group: Boca Rotan, FL, USA, 2006; ISBN 0-8247-2389-9 (HB). [Google Scholar]
- Wehrens, R.; Wehrens, R. Variable Selection. In Chemometrics with R; Springer: Berlin/Heidelberg, Germany, 2011; pp. 205–232. [Google Scholar]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef] [Green Version]
- Lin, S.W.; Lee, Z.J.; Chen, S.C.; Tseng, T.Y. Parameter determination of support vector machine and feature selection using simulated annealing approach. Appl. Soft Comput. J. 2008, 8, 1505–1512. [Google Scholar] [CrossRef]
- Therneau, T.; Atkinson, B. rpart: Recursive Partitioning and Regression Trees. Available online: https://cran.r-project.org/package=rpart (accessed on 31 March 2021).
- Kuhn, M. Caret: Classification and Regression Training. Available online: https://cran.r-project.org/package=caret (accessed on 31 March 2021).
- Romanski, P.; Kotthoff, L.; Maintainer, P.S. FSelector: Selecting Attributes. R Package Version 0.31. Available online: https://cran.r-project.org/package=FSelector (accessed on 31 March 2021).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Kuhn, M.; Quinlan, R. Rule- And Instance-Based Regression Modeling. Available online: https://cran.r-project.org/web/packages/Cubist/Cubist.pdf (accessed on 31 March 2021).
- Jin, X.Y.; Jin, H.J.; Iwahana, G.; Marchenko, S.S.; Luo, D.L.; Li, X.Y.; Liang, S.H. Impacts of climate-induced permafrost degradation on vegetation: A review. Adv. Clim. Chang. Res. 2020. [Google Scholar] [CrossRef]
- Wei, S.; Cui, H.; Zhu, Y.; Lu, Z.; Pang, S.; Zhang, S.; Dong, H.; Su, X. Shifts of methanogenic communities in response to permafrost thaw results in rising methane emissions and soil property changes. Extremophiles 2018, 22, 447–459. [Google Scholar] [CrossRef]
- Yang, Z.P.; Gao, J.X.; Zhao, L.; Xu, X.L.; Ouyang, H. Linking thaw depth with soil moisture and plant community composition: Effects of permafrost degradation on alpine ecosystems on the Qinghai-Tibet Plateau. Plant Soil 2013, 367, 687–700. [Google Scholar] [CrossRef]
- Tang, L.; Dong, S.; Sherman, R.; Liu, S.; Liu, Q.; Wang, X.; Su, X.; Zhang, Y.; Li, Y.; Wu, Y.; et al. Changes in vegetation composition and plant diversity with rangeland degradation in the alpine region of Qinghai-Tibet Plateau. Rangel. J. 2015, 37, 107. [Google Scholar] [CrossRef]
- Guo, Z.; Niu, F.; Zhan, H.; Wu, Q. Changes of grassland ecosystem due to degradation of permafrost frozen soil in the Qinghai-Tibet Plateau. Acta Ecol. Sin. 2007, 27, 3294–3301. [Google Scholar]
- Sutter, J.M.; Kalivas, J.H. Comparison of Forward Selection, Backward Elimination, and Generalized Simulated Annealing for Variable Selection. Microchem. J. 1993, 47, 60–66. [Google Scholar] [CrossRef]
- Akpa, S.I.C.; Odeh, I.O.A.; Bishop, T.F.A.; Hartemink, A.E. Digital Mapping of Soil Particle-Size Fractions for Nigeria. Soil Sci. Soc. Am. J. 2014, 78, 1953. [Google Scholar] [CrossRef] [Green Version]
- Wadoux, A.M.J.C.; Samuel-Rosa, A.; Poggio, L.; Mulder, V.L. A note on knowledge discovery and machine learning in digital soil mapping. Eur. J. Soil Sci. 2020, 71, 133–136. [Google Scholar] [CrossRef]
- Fourcade, Y.; Besnard, A.G.; Secondi, J. Paintings predict the distribution of species, or the challenge of selecting environmental predictors and evaluation statistics. Glob. Ecol. Biogeogr. 2018, 27, 245–256. [Google Scholar] [CrossRef]
- Behrens, T.; Viscarra Rossel, R.A.; Kerry, R.; MacMillan, R.; Schmidt, K.; Lee, J.; Scholten, T.; Zhu, A.X. The relevant range of scales for multi-scale contextual spatial modelling. Sci. Rep. 2019, 9, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Behrens, T.; Viscarra Rossel, R.A. On the interpretability of predictors in spatial data science: The information horizon. Sci. Rep. 2020, 10, 16737. [Google Scholar] [CrossRef] [PubMed]
- Qin, C.Z.; Wu, X.W.; Jiang, J.C.; Zhu, A.X. Case-based knowledge formalization and reasoning method for digital terrain analysis—Application to extracting drainage networks. Hydrol. Earth Syst. Sci. 2016, 20, 3379–3392. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.; Minasny, B.; Malone, B.P.; Mcbratney, A.B. Pedology and digital soil mapping (DSM). Eur. J. Soil Sci. 2019, 70, 216–235. [Google Scholar] [CrossRef]
- Ballabio, C.; Panagos, P.; Monatanarella, L. Mapping topsoil physical properties at European scale using the LUCAS database. Geoderma 2016, 261, 110–123. [Google Scholar] [CrossRef]
- Tóth, G.; Jones, A.; Montanarella, L. The LUCAS topsoil database and derived information on the regional variability of cropland topsoil properties in the European Union. Environ. Monit. Assess. 2013, 185, 7409–7425. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Shi, W. Mapping soil particle-size fractions: A comparison of compositional kriging and log-ratio kriging. J. Hydrol. 2017, 546, 526–541. [Google Scholar] [CrossRef]
- Dai, Y.; Shangguan, W.; Wei, N.; Xin, Q.; Yuan, H.; Zhang, S.; Liu, S. A review of the global soil property maps for Earth system models. Soil 2019, 5, 137–158. [Google Scholar] [CrossRef] [Green Version]
- Libohova, Z. GlobalSoilMap: Basis of the Global Spatial Soil Information System. Soil Sci. Soc. Am. J. 2015, 79, 1519. [Google Scholar] [CrossRef]
- Arrouays, D.; Poggio, L.; Salazar Guerrero, O.A.; Mulder, V.L. Digital soil mapping and GlobalSoilMap. Main advances and ways forward. Geoderma Reg. 2020, 21, e00265. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Covariate 1 | Variable Abbreviation | N2 | Resolution |
|---|---|---|---|---|
| Vegetation | Enhanced vegetation index of the sampling year and the multiyear average | EVI_1/9 | 2 | 1 km |
| Normalized difference vegetation index of the sampling year and the multiyear average | NDVI_1/9 | 2 | 1 km | |
| Gross primary productivity of the sampling year and the multiyear average | GPP_1/9 | 2 | 500 m | |
| Terrain | Aspect | asp | 1 | 1 km |
| general curvature | curva | 1 | 1 km | |
| Elevation | dem | 1 | 1 km | |
| Flow path length | FPL | 1 | 1 km | |
| Multi-resolution Ridge Top Flatness | MRRTF | 1 | 1 km | |
| Multi-resolution Valley Bottom Flatness | MRVBF | 1 | 1 km | |
| Slope | Slp | 1 | 1 km | |
| Slope height | SlpHeight | 1 | 1 km | |
| Slope length | SlpLength | 1 | 1 km | |
| Stream Power Index | SPI | 1 | 1 km | |
| SAGA Wetness Index | SWI | 1 | 1 km | |
| Terrain Ruggedness Index | TRI | 1 | 1 km | |
| Topographic Wetness Index | TWI | 1 | 1 km | |
| Vector Ruggedness Measure | VRM | 1 | 1 km | |
| Land surface temperature (LST) | Annual minimum, maximum, mean of daytime LST of the sampling year and the multiyear average | yr_d_i_1/9, yr_d_a_1/9, yr_d_e_1/9 | 6 | 1 km |
| Annual minimum, maximum, mean of nighttime LST of the sampling year and the multiyear average | yr_n_i_1/9, yr_n_a_1/9, yr_n_e_1/9 | 6 | 1 km | |
| Annual minimum, maximum, mean of day/night LST differential of the sampling year and the multiyear average | yr_df_i_1/9; yr_df_a_1/9; yr_df_e_1/9 | 6 | 1 km | |
| Annual mean of day/night LST average of the sampling year and the multiyear average | yr_dn_e_1/9 | 2 | 1 km | |
| Seasonal minimum, maximum, mean of daytime LST of the sampling year and the multiyear average | s1_d_i_1/9, …, s4_d_i_1/9; s1_d_a_1/9, …, s4_d_a_1/9; s1_d_e_1/9, …, s4_d_e_1/9 | 24 | 1 km | |
| Seasonal minimum, maximum, mean of nighttime LST of the sampling year and the multiyear average | s1_n_i_1/9, …, s4_n_i_1/9; s1_n_a_1/9, …, s4_n_a_1/9; s1_n_e_1/9, …, s4_n_e_1/9 | 24 | 1 km | |
| Seasonal minimum, maximum, mean of day/night LST differential of the sampling year and the multiyear average | s1_df_i_1/9, …, s4_df_i_1/9; s1_df_a_1/9, …, s4_df_a_1/9; s1_df_e_1/9, …, s4_df_e_1/9 | 24 | 1 km | |
| Seasonal day/night LST average of the sampling year and the multiyear average | s1_dn_e_1/9, …,s4_dn_e_1/9 | 8 | 1 km | |
| Precipitation | Annual precipitation of the sampling year and multiyear mean | pre_1/9 | 2 | 1 km |
| Seasonal precipitation of the sampling year and the multiyear average | pre_s1_1/9, …, pre_s4_1/9 | 8 | 1 km | |
| Air temperature | Annual minimum, maximum, mean temperature of the sampling year and the multiyear average | tmn_yr_1/9, tmx_yr_1/9, tmp_yr_1/9 | 6 | 1 km |
| Seasonal minimum, maximum, mean temperature of the sampling year and the multiyear average | tmn_s1_1/9, …, tmn_s4_1/9;tmx_s1_1/9, …, tmx_s4_1/9;tmp_s1_1/9, …, tmp_s4_1/9 | 24 | 1 km |
| Region | N | PSF | Mean (%) | SD (%) 1 | Min (%) 1 | Max (%) 1 | Range (%) | Skew | Kurtosis |
|---|---|---|---|---|---|---|---|---|---|
| BQ | 49 | Clay | 8.8 | 2.9 | 4.7 | 17.8 | 13.1 | 0.9 | 1.3 |
| Silt | 42.0 | 13.1 | 14.6 | 60.4 | 45.8 | −0.6 | −0.9 | ||
| Sand | 49.2 | 14.9 | 28.9 | 79.5 | 50.6 | 0.5 | −1.0 | ||
| WQ | 59 | Clay | 14.0 | 5.7 | 3.8 | 28.8 | 25.1 | 0.5 | −0.3 |
| Silt | 9.5 | 3.4 | 3.5 | 18.9 | 15.4 | 0.5 | −0.1 | ||
| Sand | 76.5 | 8.7 | 53.7 | 90.8 | 37.2 | −0.5 | −0.3 |
| Region | PSF | Trans 1 | Random Forest | Cubist | ||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | Bias | R2 | RMSE | Bias | |||
| BQ | clay | ALR | 0.462 | 0.023 | 0.001 | 0.468 | 0.025 | −0.002 |
| silt | 0.474 | 0.093 | −0.005 | 0.449 | 0.102 | 0.014 | ||
| sand | 0.512 | 0.104 | 0.004 | 0.446 | 0.114 | −0.011 | ||
| clay | ILR | 0.495 | 0.021 | 0.000 | 0.467 | 0.026 | 0.002 | |
| silt | 0.561 | 0.086 | 0.001 | 0.456 | 0.097 | 0.004 | ||
| sand | 0.564 | 0.100 | −0.001 | 0.386 | 0.115 | −0.007 | ||
| WQ | clay | ALR | 0.405 | 0.047 | −0.003 | 0.457 | 0.044 | 0.000 |
| silt | 0.315 | 0.029 | −0.003 | 0.382 | 0.030 | 0.000 | ||
| sand | 0.385 | 0.070 | 0.006 | 0.436 | 0.068 | 0.000 | ||
| clay | ILR | 0.500 | 0.043 | −0.004 | 0.467 | 0.044 | −0.004 | |
| silt | 0.358 | 0.029 | −0.002 | 0.435 | 0.029 | −0.003 | ||
| sand | 0.458 | 0.067 | 0.005 | 0.454 | 0.069 | 0.007 | ||
| Region | Source 1 | PSF | Mean (%) | SD (%)2 | Min (%)2 | Max (%) 2 | Skew | Kurtosis |
|---|---|---|---|---|---|---|---|---|
| BQ | CDSL | clay | 14.7 | 2.0 | 11.3 | 17.1 | −0.14 | −1.79 |
| silt | 39.6 | 3.5 | 32.7 | 44.7 | −0.36 | −1.07 | ||
| sand | 45.7 | 3.5 | 39.3 | 51.5 | −0.33 | −1.11 | ||
| CSCD | clay | 13.0 | 3.4 | 7.7 | 21.8 | 0.86 | 0.24 | |
| silt | 41.2 | 8.6 | 28.9 | 53.9 | 0.31 | −1.62 | ||
| sand | 45.8 | 10.5 | 24.4 | 61.0 | −0.35 | −1.09 | ||
| SG250 | clay | 18.6 | 1.4 | 14.7 | 21.5 | −0.09 | −0.24 | |
| silt | 37.2 | 2.1 | 32.7 | 40.9 | −0.26 | −0.81 | ||
| sand | 44.2 | 1.8 | 39.5 | 48.0 | −0.33 | −0.34 | ||
| ILR-RF | clay | 8.8 | 1.7 | 5.4 | 12.6 | 0.03 | −0.79 | |
| silt | 41.9 | 9.0 | 23.2 | 56.7 | −0.34 | −0.73 | ||
| sand | 49.3 | 9.9 | 32.5 | 67.0 | 0.14 | −0.93 | ||
| WQ | CDSL | clay | 14.4 | 1.7 | 12.3 | 17.9 | 0.56 | −1.24 |
| silt | 38.6 | 2.6 | 32.9 | 43.7 | 0.73 | 0.04 | ||
| sand | 47.0 | 2.1 | 39.6 | 51.6 | −1.47 | 3.07 | ||
| CSCD | clay | 15.6 | 2.0 | 10.4 | 22.6 | 1.79 | 6.37 | |
| silt | 39.3 | 7.2 | 30.3 | 52.6 | 0.46 | −0.56 | ||
| sand | 45.2 | 7.4 | 28.6 | 54.5 | −0.45 | −0.44 | ||
| SG250 | clay | 19.8 | 1.6 | 16.3 | 23.4 | −0.01 | −0.55 | |
| silt | 41.5 | 2.3 | 34.8 | 46.3 | −0.23 | 0.01 | ||
| sand | 38.7 | 1.9 | 35.5 | 43.4 | 0.47 | −0.30 | ||
| ILR-RF | clay | 13.6 | 4.0 | 6.3 | 21.3 | −0.03 | −0.93 | |
| silt | 9.3 | 2.0 | 5.3 | 13.1 | −0.23 | −0.61 | ||
| sand | 77.0 | 5.8 | 66.3 | 87.8 | 0.06 | −0.88 |
| Dataset | Region | PSF | R2 | RMSE | Bias |
|---|---|---|---|---|---|
| SG250 | BQ | clay | 0.028 | 0.102 | 0.098 |
| silt | 0.008 | 0.142 | −0.048 | ||
| sand | 0.000 | 0.157 | −0.051 | ||
| WQ | clay | 0.017 | 0.082 | 0.058 | |
| silt | 0.014 | 0.322 | 0.320 | ||
| sand | 0.049 | 0.387 | −0.378 | ||
| CDSL | BQ | clay | 0.027 | 0.069 | 0.059 |
| silt | 0.205 | 0.121 | −0.023 | ||
| sand | 0.087 | 0.145 | −0.035 | ||
| WQ | clay | 0.230 | 0.067 | 0.004 | |
| silt | 0.117 | 0.293 | 0.291 | ||
| sand | 0.000 | 0.308 | −0.295 | ||
| CSCD | BQ | clay | 0.001 | 0.062 | 0.042 |
| silt | 0.004 | 0.151 | −0.007 | ||
| sand | 0.008 | 0.176 | −0.035 | ||
| WQ | clay | 0.012 | 0.064 | 0.016 | |
| silt | 0.113 | 0.305 | 0.297 | ||
| sand | 0.074 | 0.328 | −0.313 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Zhao, L.; Fang, H.; Wang, L.; Xing, Z.; Zou, D.; Hu, G.; Wu, X.; Zhao, Y.; Sheng, Y.; et al. Mapping Surficial Soil Particle Size Fractions in Alpine Permafrost Regions of the Qinghai–Tibet Plateau. Remote Sens. 2021, 13, 1392. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13071392
Wang C, Zhao L, Fang H, Wang L, Xing Z, Zou D, Hu G, Wu X, Zhao Y, Sheng Y, et al. Mapping Surficial Soil Particle Size Fractions in Alpine Permafrost Regions of the Qinghai–Tibet Plateau. Remote Sensing. 2021; 13(7):1392. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13071392
Chicago/Turabian StyleWang, Chong, Lin Zhao, Hongbing Fang, Lingxiao Wang, Zanpin Xing, Defu Zou, Guojie Hu, Xiaodong Wu, Yonghua Zhao, Yu Sheng, and et al. 2021. "Mapping Surficial Soil Particle Size Fractions in Alpine Permafrost Regions of the Qinghai–Tibet Plateau" Remote Sensing 13, no. 7: 1392. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13071392