
Unsupervised Radar Target Detection under Complex Clutter Background Based on Mixture Variational Autoencoder


Abstract
:
1. Introduction
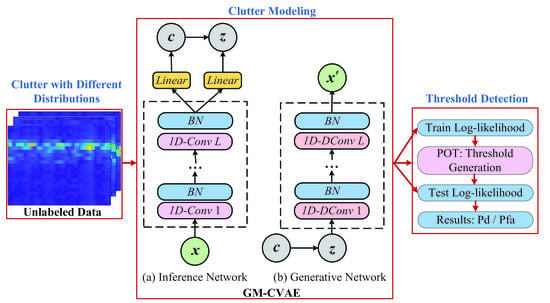
- In order to solve the problem of complex and changeable clutter in the radar scanning range in the actual environment, we propose a GM-CVAE framework to realize refined modeling of clutter.
- Considering that it is difficult to obtain the true labels of the data and the imbalance of clutter and target samples, we develop an unsupervised narrow-band radar target detection strategy based on reconstructed likelihood.
- Experiments are used to evaluate our approach on simulated complex clutter datasets. These demonstrate the superiority of our method compared to the baselines.
2. Preliminaries
2.1. Ground Clutter Characteristics
2.2. Target Characteristics
2.3. Variational Autoencoder
3. Method
3.1. Overview of the Framework
3.2. Network Architecture
3.3. Offline Training Process
| Algorithm 1: GM-CVAE Training Algorithm |
| input: The pre-processed R-D spectrum training set ; number of components K; batch-size M. |
| output: The encoder parameters and the decoder parameters ; reconstruction probability vector for all samples (see Equation (22)); , ← Initialize parameters. |
| repeat |
| Select a mini-batch training subset randomly; |
| Draw random noise from uniform distribution for generating samples according to Equation (14); |
| Draw random noise from normal distribution for generating latent variable according Equation (16); |
| Calculate according to Equations (18)–(21), and update parameters of the two sub-nets jointly; |
| until convergence |
| return model parameters and , as well as . |
4. Target Detection Strategy
| Algorithm 2: GM-CVAE Detection Algorithm |
| input: The pre-processed R-D spectrum test set ; |
| output: reconstruction probability vector for all samples (see Equation (22)) and labels . |
| , , ← Trained GM-CVAE network. |
| Similar to the loop body of Algorithm 1, reconstruction probability vector is obtained; |
| Feed as the initial threshold to the POT algorithm to generate the final threshold vector ; |
| Element-wise comparison of and : |
| if , then then |
| is a target, label = 1 |
| else |
| is a clutter, label = 0 |
| end if |
5. Numerical Examples
5.1. Experiment Setup
5.2. Performance Comparison
5.2.1. Data Pre-Processing with MTI or AMTI
5.2.2. Data Pre-Processing without MTI or AMTI
5.3. Qualitative Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANMF | Adaptive normalized matched filter |
| ASD | Adaptive subspace detector |
| CFAR | Constant false alarm rate |
| CA-CFAR | Cell-averaging CFAR |
| GO-CFAR | The greatest of selection CFAR |
| OS-CFAR | The order statistic CFAR |
| CUT | Cell under test |
| CNN | Convolutional neural network |
| GMM | Gaussian mixture model |
| VAE | Variational autoencoder |
| CVAE | Variational autoencoder with 1D-CNN |
| GM-CVAE | Gaussian mixture variational autoencoder with 1D-CNN |
| EVT | Extreme value theory |
| POT | Peaks over threshold |
References
- Yan, J.; Liu, H.; Pu, W.; Liu, H.; Liu, Z.; Bao, Z. Joint Threshold Adjustment and Power Allocation for Cognitive Target Tracking in Asynchronous Radar Network. IEEE Trans. Signal Process. 2017, 65, 3094–3106. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, W.; Shi, J.; Fei, T.; Zong, B. Joint Detection Threshold Optimization and Illumination Time Allocation Strategy for Cognitive Tracking in a Networked Radar System. IEEE Trans. Signal Proc. 2022, 126, 1–15. [Google Scholar] [CrossRef]
- Finn, H.M. Adaptive Detection Mode with Threshold Control as A Function of Spatially Sampled Clutter Level Estimates. RCA Rev. 1968, 29, 414–465. [Google Scholar] [CrossRef]
- Weiss, M. Analysis of Some Modified Cell-Averaging CFAR Processors in Multiple-target Situations. IEEE Trans. Aeros. Electron. Syst. 1982, 18, 102–114. [Google Scholar] [CrossRef]
- Gandhi, P.; Kassam, S. Analysis of CFAR Processors in Nonhomogeneous Background. IEEE Trans. Aerosp. Electron. Syst. 1988, 24, 427–445. [Google Scholar] [CrossRef]
- Hansen, V.G. Constant False Alarm Rate Processing in Search Radars. In Proceedings of the IEE Conference on Radar-Present and Future, London, UK, 23–25 October 1973; pp. 325–332. [Google Scholar]
- Hansen, V.G.; Sawyers, J.H. Detectability Loss Due to “Greatest Of” Selection in a Cell-Averaging CFAR. IEEE Trans. Aeros. Electron. Syst. 1980, 16, 115–118. [Google Scholar] [CrossRef]
- Rohling, H. Radar CFAR Thresholding in Clutter and Multiple Target Situations. IEEE Trans. Aerosp. Electron. Syst. 1983, 19, 608–621. [Google Scholar] [CrossRef]
- Elias Fusté, A.; de Mercado, G.G.; de los Reyes, E. Analysis of Some Modified Ordered Statistic CFAR: OSGO and OSSO CFAR. IEEE Trans. Aerosp. Electron. Syst. 1990, 26, 197–202. [Google Scholar] [CrossRef]
- Pourmottaghi, A.; Taban, M.; Gazor, S. A CFAR Detector in A Nonhomogenous Weibull Clutter. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 1747–1758. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, R.; Sheng, W.; Ma, X.; Han, Y.; Cui, J.; Kong, F. Intelligent CFAR Detector for Non-homogeneous Weibull Clutter Environment Based on Skewness. In Proceedings of the 2018 IEEE Radar Conference (RadarConf18), Oklahoma City, OK, USA, 23–27 April 2018. [Google Scholar] [CrossRef]
- Roy, L.; Kumar, R. Accurate K-distributed Clutter Model for Scanning Radar Application. IET Radar Sonar Navig. 2010, 4, 158–167. [Google Scholar] [CrossRef]
- Yang, Y.; Xiao, S.p.; Feng, D.j.; Zhang, W.m. Modelling and Simulation of Spatial-temporal Correlated K Distributed Clutter for Coherent Radar Seeker. IET Radar Sonar Navig. 2014, 8, 1–8. [Google Scholar] [CrossRef]
- Conte, E.; Longo, M. Characterisation of Radar Clutter as A Spherically Invariant Random Process. IEE Proc. Part F 1987, 134, 191–197. [Google Scholar] [CrossRef]
- Sangston, K.J.; Gini, F.; Greco, M.V.; Farina, A. Structures for Radar Detection in Compound Gaussian Clutter. IEEE Trans. Aerosp. Electron. Syst. 1999, 35, 445–458. [Google Scholar] [CrossRef]
- Gini, F.; Farina, A. Vector Subspace Detection in Compound-Gaussian Clutter. Part I: Survey and New Results. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 1295–1311. [Google Scholar] [CrossRef]
- Gini, F.; Farina, A.; Montanari, M. Vector Subspace Detection in Compound-Gaussian Clutter. Part II: Performance Analysis. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 1312–1323. [Google Scholar] [CrossRef]
- Xu, S.W.; Shui, P.L.; Cao, Y.H. Adaptive Range-spread Maneuvering Target Detection in Compound-Gaussian Clutter. Digit. Signal Process. 2015, 36, 46–56. [Google Scholar] [CrossRef]
- Conte, E.; Lops, M.; Ricci, G. Adaptive Detection Schemes in Compound-Gaussian Clutter. IEEE Trans. Aerosp. Electron. Syst. 1998, 34, 1058–1069. [Google Scholar] [CrossRef]
- Chen, B.; Varshney, P.K.; Michels, J.H. Adaptive CFAR Detection for Clutter-edge Heterogeneity using Bayesian Inference. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1462–1470. [Google Scholar] [CrossRef]
- Zaimbashi, A. An Adaptive Cell Averaging-based CFAR Detector for Interfering Targets and Clutter-edge Situations. Digit. Signal Process. 2014, 31, 59–68. [Google Scholar] [CrossRef]
- Doyuran, U.C.; Tanik, Y. Expectation Maximization-based Detection in Range-heterogeneous Weibull Clutter. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 3156–3166. [Google Scholar] [CrossRef]
- Meng, X. Rank Sum Nonparametric CFAR Detector in Nonhomogeneous Background. IEEE Trans. Aerosp. Electron. Syst. 2020, 57, 397–403. [Google Scholar] [CrossRef]
- Hua, X.; Ono, Y.; Peng, L.; Xu, Y. Unsupervised Learning Discriminative MIG Detectors in Nonhomogeneous Clutter. IEEE Trans. Commun. 2022, 70, 4107–4120. [Google Scholar] [CrossRef]
- Aubry, A.; De Maio, A.; Pallotta, L.; Farina, A. Covariance Matrix Estimation via Geometric Barycenters and Its Application to Radar Training Data Selection. IET Radar Sonar Navig. 2013, 7, 600–614. [Google Scholar] [CrossRef]
- Wang, Z.; Li, G.; Chen, H. Adaptive Persymmetric Subspace Detectors in the Partially Homogeneous Environment. IEEE Trans. Signal Process. 2020, 68, 5178–5187. [Google Scholar] [CrossRef]
- Kraut, S.; Scharf, L.; McWhorter, L. Adaptive Subspace Detectors. IEEE Trans. Signal Process. 2001, 49, 1–16. [Google Scholar] [CrossRef]
- Liu, J.; Sun, S.; Liu, W. One-Step Persymmetric GLRT for Subspace Signals. IEEE Trans. Signal Process. 2019, 67, 3639–3648. [Google Scholar] [CrossRef]
- Bidart, R.; Wong, A. Affine Variational Autoencoders. In Proceedings of the International Conference on Image Analysis and Recognition, Waterloo, ON, Canada, 27–29 August 2019; pp. 461–472. [Google Scholar]
- Cai, F.; Ozdagli, A.I.; Koutsoukos, X. Detection of Dataset Shifts in Learning-Enabled Cyber-Physical Systems using Variational Autoencoder for Regression. In Proceedings of the 2021 4th IEEE International Conference on Industrial Cyber-Physical Systems (ICPS), Victoria, BC, Canada, 10–12 May 2021; pp. 104–111. [Google Scholar] [CrossRef]
- Liu, N.; Xu, Y.; Ding, H.; Xue, Y.; Guan, J. High-dimensional Feature Extraction of Sea Clutter and Target Signal for Intelligent Maritime Monitoring Network. Comput. Commun. 2019, 147, 76–84. [Google Scholar] [CrossRef]
- Lopez-Risueno, G.; Grajal, J.; Diaz-Oliver, R. Target Detection in Sea Clutter using Convolutional Neural Networks. In Proceedings of the 2003 IEEE Radar Conference (Cat. No. 03CH37474), Huntsville, AL, USA, 5–8 May 2003; pp. 321–328. [Google Scholar] [CrossRef]
- Jing, H.; Cheng, Y.; Wu, H.; Wang, H. Adaptive Network Detector for Radar Target in Changing Scenes. Remote Sens. 2021, 13, 3743. [Google Scholar] [CrossRef]
- Wang, L.; Tang, J.; Liao, Q. A Study on Radar Target Detection Based on Deep Neural Networks. IEEE Sens. Lett. 2019, 3, 1–4. [Google Scholar] [CrossRef]
- Xie, Y.; Tang, J.; Wang, L. Radar Target Detection using Convolutional Neutral Network in Clutter. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Kan, M.; Shan, S.; Chen, X. Bi-shifting Auto-encoder for Unsupervised Domain Adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3846–3854. [Google Scholar] [CrossRef]
- Rostami, M. Lifelong Domain Adaptation via Consolidated Internal Distribution. Adv. Neural Inf. Process. Syst. 2021, 34, 11172–11183. [Google Scholar] [CrossRef]
- Lasloum, T.; Alhichri, H.; Bazi, Y.; Alajlan, N. SSDAN: Multi-Source Semi-Supervised Domain Adaptation Network for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 3861. [Google Scholar] [CrossRef]
- Zhang, Y.; Shen, D.; Wang, G.; Gan, Z.; Henao, R.; Carin, L. Deconvolutional paragraph representation learning. arXiv 2017, arXiv:1708.04729. [Google Scholar]
- Xie, R.; Sun, Z.; Wang, H.; Li, P.; Rui, Y.; Wang, L.; Bian, C. Low-Resolution Ground Surveillance Radar Target Classification Based on 1D-CNN. In Proceedings of the Eleventh International Conference on Signal Processing Systems, Chengdu, China, 15–17 November 2019; Volume 11384, pp. 199–204. [Google Scholar] [CrossRef]
- Xie, R.; Dong, B.; Li, P.; Rui, Y.; Wang, X.; Wei, J. Automatic Target Recognition Method For Low-Resolution Ground Surveillance Radar Based on 1D-CNN. In Proceedings of the Twelfth International Conference on Signal Processing Systems, Xi’an, China, 23–26 July 2021; Volume 11719, pp. 48–55. [Google Scholar] [CrossRef]
- Su, Y.; Zhao, Y.; Sun, M.; Zhang, S.; Wen, X.; Zhang, Y.; Liu, X.; Liu, X.; Tang, J.; Wu, W.; et al. Detecting Outlier Machine Instances Through Gaussian Mixture Variational Autoencoder with One Dimensional CNN. IEEE Trans. Comput. 2022, 71, 892–905. [Google Scholar] [CrossRef]
- Greco, M.S.; Watts, S. Radar Clutter Modeling and Analysis. In Academic Press Library in Signal Processing; Elsevier: Amsterdam, The Netherlands, 2014; Volume 2, pp. 513–594. [Google Scholar] [CrossRef]
- Billingsley, J.B. Low-Angle Radar Land Clutter: Measurements and Empirical Models; United States of America by William Andrew Publishing: Norwich, NY, USA, 2002. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. (CSUR) 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep Learning for Anomaly Detection: A Survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Jing, H.; Cheng, Y.; Wu, H.; Wang, H. Radar Target Detection with Multi-Task Learning in Heterogeneous Environment. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Chung, J.; Kastner, K.; Dinh, L.; Goel, K.; Courville, A.C.; Bengio, Y. A Recurrent Latent Variable Model for Sequential Data. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Guo, Y.; Liao, W.; Wang, Q.; Yu, L.; Ji, T.; Li, P. Multidimensional Time Series Anomaly Detection: A GRU-based Gaussian Mixture Variational Autoencoder Approach. In Proceedings of the ACML 2018: The 10th Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018. [Google Scholar] [CrossRef]
- Blei, D.M.; Jordan, M.I. Variational Inference for Dirichlet Process Mixtures. Bayesian Anal. 2006, 1, 121–143. [Google Scholar] [CrossRef]
- Jang, E.; Gu, S.; Poole, B. Categorical Reparameterization with Gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Shi, W.; Zhou, H.; Miao, N.; Zhao, S.; Li, L. Fixing Gaussian Mixture VAEs for Interpretable Text Generation. arXiv 2019, arXiv:1906.06719. [Google Scholar]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust Anomaly Detection for Multivariate Time Series Through Stochastic Recurrent Neural Network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2828–2837. [Google Scholar] [CrossRef]
- Xu, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z.; Liu, Y.; Zhao, Y.; Pei, D.; Feng, Y.; et al. Unsupervised Anomaly Detection via Variational Auto-encoder for Seasonal KPIs in Web Applications. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 187–196. [Google Scholar] [CrossRef]
- Siffer, A.; Fouque, P.A.; Termier, A.; Largouet, C. Anomaly Detection in Streams with Extreme Value Theory. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1067–1075. [Google Scholar] [CrossRef]
- Basu, S. Analyzing Alzheimer’s Disease Progression from Sequential Magnetic Resonance Imaging Scans using Deep Convolutional Neural Networks. Master’s Thesis, McGill University, Montreal, QC, Canada, 2019. [Google Scholar] [CrossRef]
- Van Der Maaten, L. Accelerating t-SNE using Tree-based Algorithms. J. Mach. Learn. Res. 2014, 15, 3221–3245. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type-2 (dB) | Type-1 → 2 (dB) | Type-2 → 3 (dB) | Type-1 → 2 → 3 (dB) | |
|---|---|---|---|---|---|
| case A | GO-CFAR | +0.8 | −1.7 | −2.4 | +2.4 |
| OS-CFAR | −0.7 | −2.5 | −3.0 | 0.0 | |
| ANMF | +11 | +8 | +6.4 | +5.1 | |
| ASD | +12 | +9 | +7.5 | +6.3 | |
| CVAE | +13.7 | +14 | +13.4 | +14.3 | |
| GO-CFAR | 0.0 | −1.8 | −2.0 | +1.8 | |
| OS-CFAR | −0.1 | −2.6 | −1.4 | +1.0 | |
| ANMF | +10.5 | +9 | +7.7 | +8 | |
| ASD | +11.5 | +10 | +8.8 | +9 | |
| GM-CVAE | +14.0 | +16.0 | +15.3 | +18.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, X.; Chen, B.; Chen, W.; Wang, P.; Liu, H. Unsupervised Radar Target Detection under Complex Clutter Background Based on Mixture Variational Autoencoder. Remote Sens. 2022, 14, 4449. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14184449
Liang X, Chen B, Chen W, Wang P, Liu H. Unsupervised Radar Target Detection under Complex Clutter Background Based on Mixture Variational Autoencoder. Remote Sensing. 2022; 14(18):4449. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14184449
Chicago/Turabian StyleLiang, Xueling, Bo Chen, Wenchao Chen, Penghui Wang, and Hongwei Liu. 2022. "Unsupervised Radar Target Detection under Complex Clutter Background Based on Mixture Variational Autoencoder" Remote Sensing 14, no. 18: 4449. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14184449