
Stratiform and Convective Rain Classification Using Machine Learning Models and Micro Rain Radar
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. PARSIVEL2 Disdrometer
2.2. MRR
2.3. Pre-Classification
2.4. Data Preparation
- 1.
- Data quality adjustments using path integrated attenuation (PIA): The PIA value is calculated for each cell containing liquid water and provides information on how reliable the received radar signal is. Attenuation correction using PIA was applied according to Garcia-Benadí et al. [28] and cases where attenuation exceeds 10 dB were flagged. Higher values signal bad data quality and hence we excluded all measurements for cells that contain the highest possible PIA value (10 dB) and all measurements for higher heights of the same minute.
- 2.
- Imputation and feature engineering: To identify the separation level and extract the relevant features to be used in building the classification model, a moving five-minute window was used. This temporal window includes two minutes before and after the target time step. The following processing steps have been applied within each five-minute temporal window:
- If more than 70% of all measurements of the data within the five-minute temporal window are missing, then the respective minute is removed from the dataset.
- If the highest height (3100 m) for a parameter (Z, W, SW) contains only missing measurements for the entire five-minute temporal window, then the height (3100 m) for this five-minute temporal window is excluded for the further processing of the parameter’s measurements. This step is iteratively repeated for the following heights (3000 m, then 2900 m, etc.) until a height is reached where at least one non-missing value for the regarded five-minute temporal window is available.
- Other missing measurements within the five-minute temporal window were imputed. Therefore, for each of the parameters Z, W, and SW, missing measurements were replaced by the arithmetic mean of surrounding measurements. Surrounding measurements are defined by +/− 1 min intervals and +/− 100 m of height from the observation that needs to be imputed.
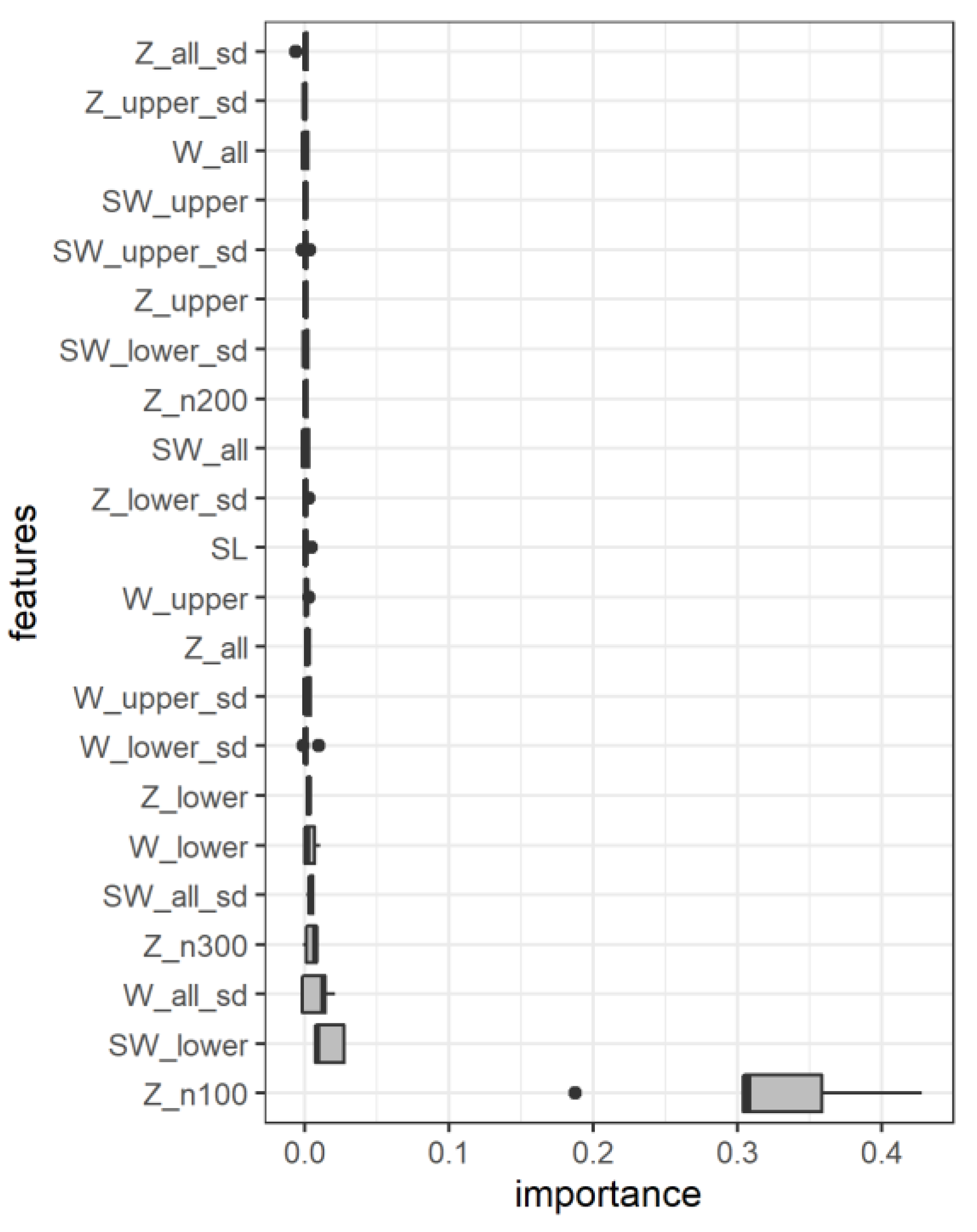
- Feature engineering: For each minute, the layer with the highest increase in W value is identified. The five heights within the five-minute temporal window are then averaged to identify the height of the SL (Figure 2c). For the area above the SL (the upper region), the area below it (the lower region), and for the entire column (containing both the region and the SL), the arithmetic means and standard deviations of the parameters Z, W, and SW were calculated. These are 18 features in total. Additionally, the values of Z at the lowest three levels (heights 100 m, 200 m, and 300 m), and the height of the calculated SL were added to yield 22 selected features (Table A1).
- 3.
- Excluding observations without a label for the classification task: Out of the remaining 11,725 min, 1295 (i.e., around 11%) have no disdrometer measurements. This is expected when raindrops evaporate before reaching the ground and being detected by the disdrometer. In such a case, no true label can be derived for those observations. Since we are facing a classification task, we can only include labeled observations and hence we exclude those without disdrometer measurements. Since this step leads to gaps within events and hinders the imputation of the MRR parameters, it must be executed after all other pre-processing steps.
2.5. Modeling and Evaluation
2.6. Model Interpretation
3. Results
3.1. Overall Model Performance
3.2. Model Interpretation
3.3. Model Results for Specific Events
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Definition |
|---|---|
| Z_all | Average reflectivity over a five-minute window including all elevations |
| Z_all_sd | Standard deviation of reflectivity over a five-minute window including all elevations |
| Z_upper | Average reflectivity over a five-minute window limited to elevations above SL |
| Z_upper_sd | Standard deviation of reflectivity over a five-minute window limited to elevations above SL |
| Z_lower | Average reflectivity over a five-minute window limited to elevations below SL |
| Z_lower_sd | Standard deviation of reflectivity over a five-minute window limited to elevations below SL |
| W_all | Average Doppler velocity over a five-minute window including all elevations |
| W_all_sd | Standard deviation of Doppler velocity over a five-minute window including all elevations |
| W_upper | Average Doppler velocity over a five-minute window limited to elevations above SL |
| W_upper_sd | Standard deviation of Doppler velocity over a five-minute window limited to elevations above SL |
| W_lower | Average Doppler velocity over a five-minute window limited to elevations below SL |
| W_lower_sd | Standard deviation of Doppler velocity over a five-minute window limited to elevations below SL |
| SW_all | Average spectral width over a five-minute window including all elevations |
| SW_all_sd | Standard deviation of spectral width over a five-minute window including all elevations |
| SW_upper | Average spectral width over a five-minute window limited to elevations above SL |
| SW_upper_sd | Standard deviation of spectral width over a five-minute window limited to elevations above SL |
| SW_lower | Average spectral width over a five-minute window limited to elevations below SL |
| SW_lower_sd | Standard deviation of spectral width over a five-minute window limited to elevations below SL |
| SL | Separation level: height above the ground of the region where the maximum change in reflectivity occurs. It corresponds with the melting layer in stratiform rain. See Section 2.2 and Figure 2 for more details |
| Z_n100 | Reflectivity value as measured by the MRR for the first level (100–199 m a.g.l.) |
| Z_n200 | Reflectivity value as measured by the MRR for the second level (200–299 m a.g.l.) |
| Z_n300 | Reflectivity value as measured by the MRR for the third level (300–399 m a.g.l.) |



References
- Dolan, B.; Fuchs, B.; Rutledge, S.A.; Barnes, E.A.; Thompson, E.J. Primary Modes of Global Drop Size Distributions. J. Atmos. Sci. 2018, 75, 1453–1476. [Google Scholar] [CrossRef]
- Sreekanth, T.S.; Varikoden, H.; Resmi, E.A.; Mohan Kumar, G. Classification and seasonal distribution of rain types based on surface and radar observations over a tropical coastal station. Atmos. Res. 2019, 218, 90–98. [Google Scholar] [CrossRef]
- Wen, L.; Zhao, K.; Wang, M.; Zhang, G. Seasonal Variations of Observed Raindrop Size Distribution in East China. Adv. Atmos. Sci. 2019, 36, 346–362. [Google Scholar] [CrossRef]
- Dai, A. Global Precipitation and Thunderstorm Frequencies. Part I: Seasonal and Interannual Variations. J. Clim. 2001, 14, 1092–1111. [Google Scholar] [CrossRef]
- Chernokulsky, A.; Kozlov, F.; Zolina, O.; Bulygina, O.; Mokhov, I.I.; Semenov, V.A. Observed changes in convective and stratiform precipitation in Northern Eurasia over the last five decades. Environ. Res. Lett. 2019, 14, 45001. [Google Scholar] [CrossRef]
- Ghada, W.; Buras, A.; Lüpke, M.; Schunk, C.; Menzel, A. Rain Microstructure Parameters Vary with Large-Scale Weather Conditions in Lausanne, Switzerland. Remote Sens. 2018, 10, 811. [Google Scholar] [CrossRef]
- Arulraj, M.; Barros, A.P. Improving quantitative precipitation estimates in mountainous regions by modelling low-level seeder-feeder interactions constrained by Global Precipitation Measurement Dual-frequency Precipitation Radar measurements. Remote Sens. Environ. 2019, 231, 111213. [Google Scholar] [CrossRef]
- Kühnlein, M.; Appelhans, T.; Thies, B.; Nauss, T. Improving the accuracy of rainfall rates from optical satellite sensors with machine learning—A random forests-based approach applied to MSG SEVIRI. Remote Sens. Environ. 2014, 141, 129–143. [Google Scholar] [CrossRef]
- Steiner, M.; Houze, R.A. Sensitivity of the Estimated Monthly Convective Rain Fraction to the Choice of Z—R Relation. J. Appl. Meteor. 1997, 36, 452–462. [Google Scholar] [CrossRef]
- Thompson, E.J.; Rutledge, S.A.; Dolan, B.; Thurai, M. Drop Size Distributions and Radar Observations of Convective and Stratiform Rain over the Equatorial Indian and West Pacific Oceans. J. Atmos. Sci. 2015, 72, 4091–4125. [Google Scholar] [CrossRef]
- Berg, P.; Moseley, C.; Haerter, J.O. Strong increase in convective precipitation in response to higher temperatures. Nat. Geosci. 2013, 6, 181–185. [Google Scholar] [CrossRef]
- Langer, I.; Reimer, E. Separation of convective and stratiform precipitation for a precipitation analysis of the local model of the German Weather Service. Adv. Geosci. 2007, 10, 159–165. [Google Scholar] [CrossRef]
- Llasat, M.-C. An objective classification of rainfall events on the basis of their convective features: Application to rainfall intensity in the northeast of spain. Int. J. Climatol. 2001, 21, 1385–1400. [Google Scholar] [CrossRef]
- Bringi, V.N.; Chandrasekar, V.; Hubbert, J.; Gorgucci, E.; Randeu, W.L.; Schoenhuber, M. Raindrop Size Distribution in Different Climatic Regimes from Disdrometer and Dual-Polarized Radar Analysis. J. Atmos. Sci. 2003, 60, 354–365. [Google Scholar] [CrossRef]
- Testud, J.; Oury, S.; Amayenc, P. The concept of “normalized” distribution to describe raindrop spectra: A tool for hydrometeor remote sensing. Phys. Chem. Earth Part B Hydrol. Ocean. Atmos. 2000, 25, 897–902. [Google Scholar] [CrossRef]
- Hachani, S.; Boudevillain, B.; Delrieu, G.; Bargaoui, Z. Drop Size Distribution Climatology in Cévennes-Vivarais Region, France. Atmosphere 2017, 8, 233. [Google Scholar] [CrossRef]
- Ghada, W.; Bech, J.; Estrella, N.; Hamann, A.; Menzel, A. Weather Types Affect Rain Microstructure: Implications for Estimating Rain Rate. Remote Sens. 2020, 12, 3572. [Google Scholar] [CrossRef]
- Tokay, A.; Short, D.A. Evidence from Tropical Raindrop Spectra of the Origin of Rain from Stratiform versus Convective Clouds. J. Appl. Meteor. 1996, 35, 355–371. [Google Scholar] [CrossRef]
- Caracciolo, C.; Porcù, F.; Prodi, F. Precipitation classification at mid-latitudes in terms of drop size distribution parameters. Adv. Geosci. 2008, 16, 11–17. [Google Scholar] [CrossRef]
- Bringi, V.N.; Williams, C.R.; Thurai, M.; May, P.T. Using Dual-Polarized Radar and Dual-Frequency Profiler for DSD Characterization: A Case Study from Darwin, Australia. J. Atmos. Oceanic Technol. 2009, 26, 2107–2122. [Google Scholar] [CrossRef]
- Steiner, M.; Houze, R.A.; Yuter, S.E. Climatological Characterization of Three-Dimensional Storm Structure from Operational Radar and Rain Gauge Data. J. Appl. Meteor. 1995, 34, 1978–2007. [Google Scholar] [CrossRef]
- Churchill, D.D.; Houze, R.A. Development and Structure of Winter Monsoon Cloud Clusters On 10 December 1978. J. Atmos. Sci. 1984, 41, 933–960. [Google Scholar] [CrossRef]
- Berendes, T.A.; Mecikalski, J.R.; MacKenzie, W.M.; Bedka, K.M.; Nair, U.S. Convective cloud identification and classification in daytime satellite imagery using standard deviation limited adaptive clustering. J. Geophys. Res. 2008, 113, D20207. [Google Scholar] [CrossRef]
- Anagnostou, E.N.; Kummerow, C. Stratiform and Convective Classification of Rainfall Using SSM/I 85-GHz Brightness Temperature Observations. J. Atmos. Oceanic Technol. 1997, 14, 570–575. [Google Scholar] [CrossRef]
- Adler, R.F.; Negri, A.J. A Satellite Infrared Technique to Estimate Tropical Convective and Stratiform Rainfall. J. Appl. Meteor. 1988, 27, 30–51. [Google Scholar] [CrossRef]
- Fabry, F.; Zawadzki, I. Long-Term Radar Observations of the Melting Layer of Precipitation and Their Interpretation. J. Atmos. Sci. 1995, 52, 838–851. [Google Scholar] [CrossRef]
- Garcia-Benadi, A.; Bech, J.; Gonzalez, S.; Udina, M.; Codina, B.; Georgis, J.-F. Precipitation Type Classification of Micro Rain Radar Data Using an Improved Doppler Spectral Processing Methodology. Remote Sens. 2020, 12, 4113. [Google Scholar] [CrossRef]
- Garcia-Benadí, A.; Bech, J.; Gonzalez, S.; Udina, M.; Codina, B. A New Methodology to Characterise the Radar Bright Band Using Doppler Spectral Moments from Vertically Pointing Radar Observations. Remote Sens. 2021, 13, 4323. [Google Scholar] [CrossRef]
- Williams, C.R.; Ecklund, W.L.; Gage, K.S. Classification of Precipitating Clouds in the Tropics Using 915-MHz Wind Profilers. J. Atmos. Oceanic Technol. 1995, 12, 996–1012. [Google Scholar] [CrossRef]
- White, A.B.; Neiman, P.J.; Ralph, F.M.; Kingsmill, D.E.; Persson, P.O.G. Coastal Orographic Rainfall Processes Observed by Radar during the California Land-Falling Jets Experiment. J. Hydrometeor. 2003, 4, 264–282. [Google Scholar] [CrossRef]
- Cha, J.-W.; Chang, K.-H.; Yum, S.S.; Choi, Y.-J. Comparison of the bright band characteristics measured by Micro Rain Radar (MRR) at a mountain and a coastal site in South Korea. Adv. Atmos. Sci. 2009, 26, 211–221. [Google Scholar] [CrossRef]
- Thurai, M.; Gatlin, P.N.; Bringi, V.N. Separating stratiform and convective rain types based on the drop size distribution characteristics using 2D video disdrometer data. Atmos. Res. 2016, 169, 416–423. [Google Scholar] [CrossRef]
- Massmann, A.K.; Minder, J.R.; Garreaud, R.D.; Kingsmill, D.E.; Valenzuela, R.A.; Montecinos, A.; Fults, S.L.; Snider, J.R. The Chilean Coastal Orographic Precipitation Experiment: Observing the Influence of Microphysical Rain Regimes on Coastal Orographic Precipitation. J. Hydrometeor. 2017, 18, 2723–2743. [Google Scholar] [CrossRef]
- Gil-de-Vergara, N.; Riera, J.M.; Pérez-Peña, S.; Garcia-Rubia, J.; Benarroch, A. Classification of rainfall events and evaluation of drop size distributions using a k-band doppler radar. In Proceedings of the 12th European Conference on Antennas and Propagation (EuCAP 2018), 9–13 April 2018; Institution of Engineering and Technology: London, UK, 2018; p. 829, ISBN 978-1-78561-816-1. [Google Scholar]
- Seidel, J.; Trachte, K.; Orellana-Alvear, J.; Figueroa, R.; Célleri, R.; Bendix, J.; Fernandez, C.; Huggel, C. Precipitation Characteristics at Two Locations in the Tropical Andes by Means of Vertically Pointing Micro-Rain Radar Observations. Remote Sens. 2019, 11, 2985. [Google Scholar] [CrossRef]
- Rajasekharan Nair, H. Discernment of near-oceanic precipitating clouds into convective or stratiform based on Z–R model over an Asian monsoon tropical site. Meteorol. Atmos. Phys. 2020, 132, 377–390. [Google Scholar] [CrossRef]
- Foth, A.; Zimmer, J.; Lauermann, F.; Kalesse-Los, H. Evaluation of micro rain radar-based precipitation classification algorithms to discriminate between stratiform and convective precipitation. Atmos. Meas. Tech. 2021, 14, 4565–4574. [Google Scholar] [CrossRef]
- Thurai, M.; Bringi, V.; Wolff, D.; Marks, D.; Pabla, C. Testing the Drop-Size Distribution-Based Separation of Stratiform and Convective Rain Using Radar and Disdrometer Data from a Mid-Latitude Coastal Region. Atmosphere 2021, 12, 392. [Google Scholar] [CrossRef]
- Thurai, M.; Bringi, V.N.; May, P.T. CPOL Radar-Derived Drop Size Distribution Statistics of Stratiform and Convective Rain for Two Regimes in Darwin, Australia. J. Atmos. Oceanic Technol. 2010, 27, 932–942. [Google Scholar] [CrossRef]
- Udina, M.; Bech, J.; Gonzalez, S.; Soler, M.R.; Paci, A.; Miró, J.R.; Trapero, L.; Donier, J.M.; Douffet, T.; Codina, B.; et al. Multi-sensor observations of an elevated rotor during a mountain wave event in the Eastern Pyrenees. Atmos. Res. 2020, 234, 104698. [Google Scholar] [CrossRef]
- Cerro, C.; Codina, B.; Bech, J.; Lorente, J. Modeling Raindrop Size Distribution and Z (R) Relations in the Western Mediterranean Area. J. Appl. Meteor. 1997, 36, 1470–1479. [Google Scholar] [CrossRef]
- Cerro, C.; Bech, J.; Codina, B.; Lorente, J. Modeling Rain Erosivity Using Disdrometric Techniques. Soil Sci. Soc. Am. J. 1998, 62, 731–735. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 12 July 2022).
- Löffler-Mang, M.; Joss, J. An Optical Disdrometer for Measuring Size and Velocity of Hydrometeors. J. Atmos. Oceanic Technol. 2000, 17, 130–139. [Google Scholar] [CrossRef]
- Friedrich, K.; Kalina, E.A.; Masters, F.J.; Lopez, C.R. Drop-Size Distributions in Thunderstorms Measured by Optical Disdrometers during VORTEX2. Mon. Wea. Rev. 2013, 141, 1182–1203. [Google Scholar] [CrossRef]
- Löffler-Mang, M.; Kunz, M.; Schmid, W. On the Performance of a Low-Cost K-Band Doppler Radar for Quantitative Rain Measurements. J. Atmos. Oceanic Technol. 1999, 16, 379–387. [Google Scholar] [CrossRef]
- Gonzalez, S.; Bech, J.; Udina, M.; Codina, B.; Paci, A.; Trapero, L. Decoupling between Precipitation Processes and Mountain Wave Induced Circulations Observed with a Vertically Pointing K-Band Doppler Radar. Remote Sens. 2019, 11, 1034. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inform. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Statist. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K. Xgboost: Extreme gradient boosting. R Package Version 0.4-2. 2015, Volume 1, pp. 1–4. Available online: https://cran.microsoft.com/snapshot/2017-12-11/web/packages/xgboost/vignettes/xgboost.pdf (accessed on 12 July 2022).
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Bischl, B.; Binder, M.; Lang, M.; Pielok, T.; Richter, J.; Coors, S.; Thomas, J.; Ullmann, T.; Becker, M.; Boulesteix, A.-L.; et al. Hyperparameter Optimization: Foundations, Algorithms, Best Practices and Open Challenges. 2021. Available online: https://arxiv.org/pdf/2107.05847 (accessed on 12 July 2022).
- Varma, S.; Simon, R. Bias in error estimation when using cross-validation for model selection. BMC Bioinform. 2006, 7, 91. [Google Scholar] [CrossRef] [Green Version]
- López-Ibáñez, M.; Dubois-Lacoste, J.; Pérez Cáceres, L.; Birattari, M.; Stützle, T. The irace package: Iterated racing for automatic algorithm configuration. Oper. Res. Perspect. 2016, 3, 43–58. [Google Scholar] [CrossRef]
- Becker, M.; Binder, M.; Bischl, B.; Foss, N.; Kotthoff, L.; Lan, M.; Pfisterer, F.; Reich, N.G.; Richter, J.; Schratz, P.; et al. mlr3book. Available online: https://mlr3book.mlr-org.com (accessed on 1 September 2022).
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, 2nd ed.; Lulu: Morisville, NC, USA, 2022; Available online: https://christophm.github.io/interpretable-ml-book (accessed on 12 July 2022).
- Fisher, A.; Rudin, C.; Dominici, F. All Models are Wrong, but Many are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously. J. Mach. Learn. Res. 2019, 20, 1–81. [Google Scholar]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking Inside the Black Box: Visualizing Statistical Learning with Plots of Individual Conditional Expectation. J. Comput. Graph. Stat. 2015, 24, 44–65. [Google Scholar] [CrossRef]
- Shapley, L.S. 17. A Value for n-Person Games. In Contributions to the Theory of Games (AM-28), Volume II; Kuhn, H.W., Tucker, A.W., Eds.; Princeton University Press: Princeton, NJ, USA, 1953; pp. 307–318. ISBN 9781400881970. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems; 2017; pp. 4768–4777. Available online: https://arxiv.org/pdf/1705.07874 (accessed on 1 September 2022).
- Au, Q.; Herbinger, J.; Stachl, C.; Bischl, B.; Casalicchio, G. Grouped feature importance and combined features effect plot. Data Min. Knowl. Disc. 2022, 36, 1401–1450. [Google Scholar] [CrossRef]
- Upadhyaya, S.A.; Kirstetter, P.-E.; Kuligowski, R.J.; Searls, M. Classifying precipitation from GEO satellite observations: Diagnostic model. Q. J. R. Meteorol. Soc. 2021, 147, 3318–3334. [Google Scholar] [CrossRef]
- Ouallouche, F.; Lazri, M.; Ameur, S. Improvement of rainfall estimation from MSG data using Random Forests classification and regression. Atmos. Res. 2018, 211, 62–72. [Google Scholar] [CrossRef]
- Song, J.J.; Innerst, M.; Shin, K.; Ye, B.-Y.; Kim, M.; Yeom, D.; Lee, G. Estimation of Precipitation Area Using S-Band Dual-Polarization Radar Measurements. Remote Sens. 2021, 13, 2039. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, P.; Yang, Y. Convective/Stratiform Precipitation Classification Using Ground-Based Doppler Radar Data Based on the K-Nearest Neighbor Algorithm. Remote Sens. 2019, 11, 2277. [Google Scholar] [CrossRef]
- Wang, J.; Wong, R.K.W.; Jun, M.; Schumacher, C.; Saravanan, R.; Sun, C. Statistical and machine learning methods applied to the prediction of different tropical rainfall types. Environ. Res. Commun. 2021, 3, 111001. [Google Scholar] [CrossRef] [PubMed]
- Seo, B.-C. A Data-Driven Approach for Winter Precipitation Classification Using Weather Radar and NWP Data. Atmosphere 2020, 11, 701. [Google Scholar] [CrossRef]
- Tokay, A.; Short, D.A.; Williams, C.R.; Ecklund, W.L.; Gage, K.S. Tropical Rainfall Associated with Convective and Stratiform Clouds: Intercomparison of Disdrometer and Profiler Measurements. J. Appl. Meteor. 1999, 38, 302–320. [Google Scholar] [CrossRef]
- Das, S.; Shukla, A.K.; Maitra, A. Investigation of vertical profile of rain microstructure at Ahmedabad in Indian tropical region. Adv. Space Res. 2010, 45, 1235–1243. [Google Scholar] [CrossRef]
- Das, S.; Maitra, A. Vertical profile of rain: Ka band radar observations at tropical locations. J. Hydrol. 2016, 534, 31–41. [Google Scholar] [CrossRef]
- Urgilés, G.; Célleri, R.; Trachte, K.; Bendix, J.; Orellana-Alvear, J. Clustering of Rainfall Types Using Micro Rain Radar and Laser Disdrometer Observations in the Tropical Andes. Remote Sens. 2021, 13, 991. [Google Scholar] [CrossRef]








| Study | Classification Method | Classes | Instrument | Temporal Resolution | Classifiers |
|---|---|---|---|---|---|
| Williams et al. [29] | Detection of a melting layer between 3.5 and 5 km height, and turbulences or hydrometeors above 7 km height by using SW and DV. | Stratiform, mixed, shallow convection, deep convection | 915 MHZ wind profiler | 30 s aggregated over rain events | SW: Spectral width DV: Doppler velocity |
| White et al. [30] | Presence of a bright band; its detection is based on a simultaneous decrease in Z and an increase in DV. | Bright band rain, non-bright band rain, and hybrid | Vertically pointing S-band radar (S-PROF) | 30 min | Z: Radar reflectivity DV: Doppler velocity |
| Cha et al. [31] | Presence of a bright band; it exists when Hb < Hpeak < Htand sharpness > 0. | Low-level rain, rain with a bright band convective rain | MRR | 1 min | Hpeak: Height of maximum Z Hb: Height of maximum increase in Z Ht: Height of maximum decrease in Z Sharpness: gradient of Z within the bright band |
| Thurai et al. [32] | Presence of a bright band. It is detected when the following conditions are met: (peak Z—mean Z below BB) > 1 dB, Peak Z > (2+ Z at 2 km above BB), and Peak Z > max Z below BB. | Stratiform and convective | Vertically pointing X-band Doppler radar, VertiX | 1 min | Z: Radar reflectivity |
| Massmann et al. [33] | Presence of a bright band; it exists when a threshold of increase in the DV is exceeded at least 35% of the time within half an hour. | Ice initiated and warm rain | MRR | 1 min | DV: Doppler velocity |
| Gil-de-Vergara et al. [34] | Presence of a bright band. Its detection is based on a threshold of increase in the DV. | Stratiform and convective | MRR | 1 min | DV: Doppler velocity |
| Seidel et al. [35] | Specific values of mean fall velocities at different heights and a rain rate threshold. | Stratiform and convective | MRR | 5 min | Mean fall velocity Rain rate |
| Rajasekharan Nair [36] | Presence of a bright band; it exists when an abrupt enhancement of at least >1000 mm6 m−3 is detected in the Z factor at any particular height. | BB and non-BB | MRR | 1 min | Z: Radar reflectivity |
| Foth et al. [37] | Artificial neural network (ANN) with 2 hidden layers using Zmax, DV max, and σDVmax. | Stratiform, convective, inconclusive | MRR | 1 min | Zmax: Maximum of reflectivity DVmax: Maximum of the mean Doppler velocity σDVmax: Maximum of the temporal standard deviation (±15 min) of the mean Doppler velocity |
| Model | Hyperparameter | Lower | Upper | Values | Transformation |
|---|---|---|---|---|---|
| knn | K: #1 of neighbors considered | - | - | 3:15 | - |
| rf | num.trees: # of trees | - | - | 400, 600, 800, 1000 | - |
| mtry: # of variables to split in each node | - | - | 4, 5, 6 | - | |
| xgboost | nrounds: max. # of iterations | 50 | 500 | - | - |
| eta: learning rate | 0.05 | 0.30 | - | - | |
| lambda: L2 regulation | 0 | 1 | - | - | |
| Max.depth: max. # splits for each tree | 1 | 10 | - | - | |
| svm | Kernel: | - | - | radial basis kernel | - |
| C: cost of constraint violation | −2 | 5 | - | 2x | |
| Sigma: inverse kernel width | −7.42 | −4.30 | - | 2x |
| Observed Values Based on BR09 | |||
|---|---|---|---|
| Positives | Negatives | ||
| Predicted values | Positives | True positives (TPs) | False positives (FPs) |
| Negatives | False negatives (FNs) | True negatives (TNs) | |
| Model | AUC | BAC | F1 | Recall | Precision | |
|---|---|---|---|---|---|---|
| baseline | naïve Bayes | 0.87 (0.11) | 0.81 (0.10) | 0.50 (0.08) | 0.71 (0.20) | 0.41 (0.10) |
| log reg | 0.95 (0.03) | 0.77 (0.03) | 0.63 (0.06) | 0.56 (0.06) | 0.73 (0.09) | |
| tree | 0.94 (0.04) | 0.80 (0.08) | 0.66 (0.08) | 0.63 (0.18) | 0.76 (0.14) | |
| tuned | knn | 0.93 (0.02) | 0.73 (0.05) | 0.57 (0.07) | 0.49 (0.10) | 0.73 (0.10) |
| svm | 0.96 (0.02) | 0.80 (0.07) | 0.65 (0.09) | 0.61 (0.14) | 0.72 (0.06) | |
| rf | 0.96 (0.02) | 0.81 (0.06) | 0.70 (0.08) | 0.65 (0.12) | 0.77 (0.09) | |
| xgboost | 0.97 (0.01) | 0.82 (0.04) | 0.71 (0.05) | 0.66 (0.09) | 0.78 (0.07) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghada, W.; Casellas, E.; Herbinger, J.; Garcia-Benadí, A.; Bothmann, L.; Estrella, N.; Bech, J.; Menzel, A. Stratiform and Convective Rain Classification Using Machine Learning Models and Micro Rain Radar. Remote Sens. 2022, 14, 4563. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14184563
Ghada W, Casellas E, Herbinger J, Garcia-Benadí A, Bothmann L, Estrella N, Bech J, Menzel A. Stratiform and Convective Rain Classification Using Machine Learning Models and Micro Rain Radar. Remote Sensing. 2022; 14(18):4563. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14184563
Chicago/Turabian StyleGhada, Wael, Enric Casellas, Julia Herbinger, Albert Garcia-Benadí, Ludwig Bothmann, Nicole Estrella, Joan Bech, and Annette Menzel. 2022. "Stratiform and Convective Rain Classification Using Machine Learning Models and Micro Rain Radar" Remote Sensing 14, no. 18: 4563. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14184563