


Research on Self-Supervised Building Information Extraction with High-Resolution Remote Sensing Images for Photovoltaic Potential Evaluation


Abstract
:1. Introduction
- In this paper, a self-supervised learning framework for semantic segmentation is proposed considering the characteristics of remote sensing images, and it is demonstrated that a large number of unlabeled remote sensing images can be effectively used to train the network. For the self-supervised learning task, this paper designs a self-supervised structural method for multi-task learning called the PGSSL method. It improves the performance of the semantic segmentation task by guiding feature extraction with a pseudo-labeling task.
- The proposed method is validated on a public dataset (EA Dataset) and an independently constructed Beijing dataset (BJ Dataset), comparing the performance of algorithms under different sample conditions and verifying the good performance of the self-supervised learning method with a limited sample size. Finally, our method achieves better results than the ImageNet pre-training in the experiments.
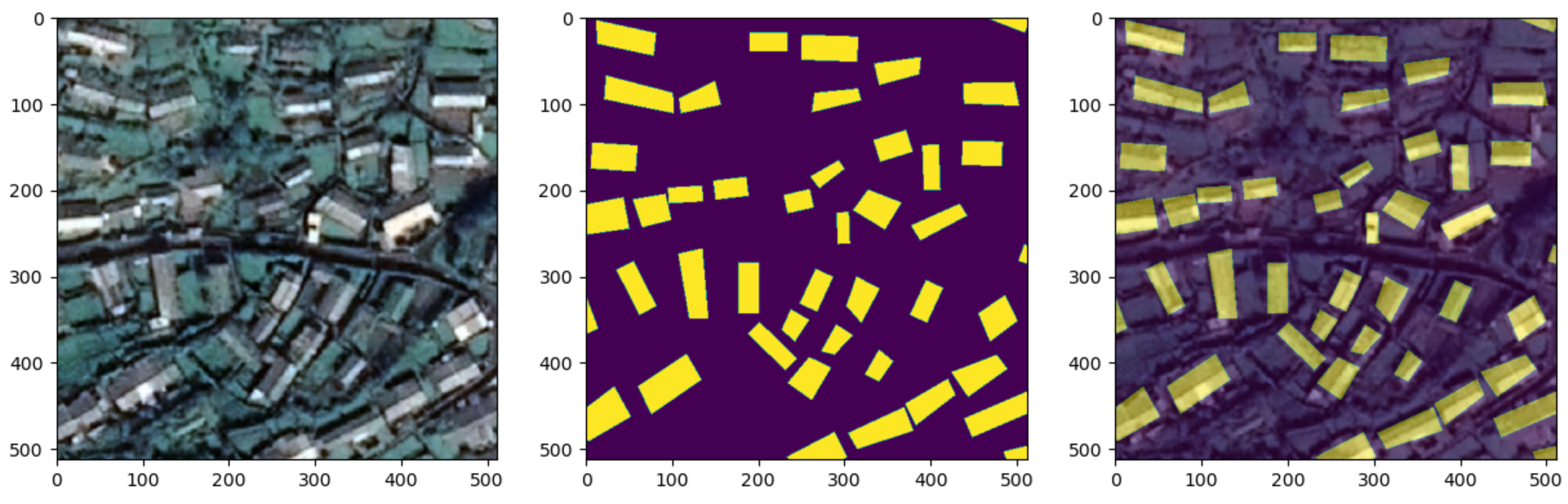
- In this paper, we further analyze the distribution of buildings based on the semantic segmentation of the buildings to obtain a more accurate picture of the suitability of building rooftops for the installation of PV equipment.
2. Methods
2.1. Weighted Training on Pseudo-Labeled Data
2.2. Contrastive Learning Task
2.3. Inpainting Task
2.4. Analysis of Photovoltaic Potential Area Based on Building Semantic Segmentation
3. Dataset and Evaluation Metrics
3.1. Dataset
3.2. Evaluation
4. Results and Discussion
4.1. Experimental Setup
4.2. Comparison of Different Methods
4.3. Experiments with Different Sample Ratios
4.4. Ablation Experiment
4.5. Regional Photovoltaic Potential Assessment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Olejarnik, P. World Energy Outlook 2013; International Energy Agency: Paris, France, 2013; pp. 1–7. [Google Scholar]
- Ramachandra, T.; Shruthi, B. Spatial mapping of renewable energy potential. Renew. Sustain. Energy Rev. 2007, 11, 1460–1480. [Google Scholar] [CrossRef]
- IRENA. Renewable Capacity Statistics 2019; International Renewable Energy Agency (IRENA): Masdar, AbuDhabi, 2019; ISBN 978-92-9260-123-2. [Google Scholar]
- Chen, Y.; Peng, Y.; He, S.; Hou, Y.; Qin, H. A method for predicting the solar photovoltaic (PV) potential in China. IOP Conf. Ser. Earth Environ. Sci. 2020, 585, 012012. [Google Scholar] [CrossRef]
- Gassar, A.A.A.; Cha, S.H. Review of geographic information systems-based rooftop solar photovoltaic potential estimation approaches at urban scales. Appl. Energy 2021, 291, 116817. [Google Scholar] [CrossRef]
- Lukač, N.; Seme, S.; Žlaus, D.; Štumberger, G.; Žalik, B. Buildings roofs photovoltaic potential assessment based on LiDAR (Light Detection And Ranging) data. Energy 2014, 66, 598–609. [Google Scholar] [CrossRef]
- Borfecchia, F.; Caiaffa, E.; Pollino, M.; De Cecco, L.; Martini, S.; La Porta, L.; Marucci, A. Remote Sensing and GIS in planning photovoltaic potential of urban areas. Eur. J. Remote Sens. 2014, 47, 195–216. [Google Scholar] [CrossRef]
- Wong, M.S.; Zhu, R.; Liu, Z.; Lu, L.; Peng, J.; Tang, Z.; Lo, C.H.; Chan, W.K. Estimation of Hong Kong’s solar energy potential using GIS and remote sensing technologies. Renew. Energy 2016, 99, 325–335. [Google Scholar] [CrossRef]
- Song, X.; Huang, Y.; Zhao, C.; Liu, Y.; Lu, Y.; Chang, Y.; Yang, J. An approach for estimating solar photovoltaic potential based on rooftop retrieval from remote sensing images. Energies 2018, 11, 3172. [Google Scholar] [CrossRef] [Green Version]
- Tiwari, A.; Meir, I.A.; Karnieli, A. Object-based image procedures for assessing the solar energy photovoltaic potential of heterogeneous rooftops using airborne LiDAR and orthophoto. Remote Sens. 2020, 12, 223. [Google Scholar] [CrossRef] [Green Version]
- Lopez-Ruiz, H.G.; Blazquez, J.; Vittorio, M. Assessing residential solar rooftop potential in Saudi Arabia using nighttime satellite images: A study for the city of Riyadh. Energy Policy 2020, 140, 111399. [Google Scholar] [CrossRef]
- Huang, X.; Hayashi, K.; Matsumoto, T.; Tao, L.; Huang, Y.; Tomino, Y. Estimation of Rooftop Solar Power Potential by Comparing Solar Radiation Data and Remote Sensing Data—A Case Study in Aichi, Japan. Remote Sens. 2022, 14, 1742. [Google Scholar] [CrossRef]
- Li, X.; Yao, X.; Fang, Y. Building-a-nets: Robust building extraction from high-resolution remote sensing images with adversarial networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3680–3687. [Google Scholar] [CrossRef]
- Tian, T.; Li, C.; Xu, J.; Ma, J. Urban area detection in very high resolution remote sensing images using deep convolutional neural networks. Sensors 2018, 18, 904. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Y.; Guo, Y.; Li, J. Recognition and extraction of high-resolution satellite remote sensing image buildings based on deep learning. Neural Comput. Appl. 2022, 34, 2691–2706. [Google Scholar] [CrossRef]
- Hui, J.; Du, M.; Ye, X.; Qin, Q.; Sui, J. Effective building extraction from high-resolution remote sensing images with multitask driven deep neural network. IEEE Geosci. Remote Sens. Lett. 2018, 16, 786–790. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 16 June–1 July 2016; pp. 2536–2544. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chaitanya, K.; Erdil, E.; Karani, N.; Konukoglu, E. Contrastive learning of global and local features for medical image segmentation with limited annotations. Adv. Neural Inf. Process. Syst. 2020, 33, 12546–12558. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 649–666. [Google Scholar]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1422–1430. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. arXiv 2016, arXiv:1603.09246. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- Guo, Q.; Wang, Z. A self-supervised learning framework for road centerline extraction from high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4451–4461. [Google Scholar] [CrossRef]
- Dong, H.; Ma, W.; Wu, Y.; Zhang, J.; Jiao, L. Self-supervised representation learning for remote sensing image change detection based on temporal prediction. Remote Sens. 2020, 12, 1868. [Google Scholar] [CrossRef]
- Li, W.; Chen, H.; Shi, Z. Semantic segmentation of remote sensing images with self-supervised multitask representation learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6438–6450. [Google Scholar] [CrossRef]
- Kalibhat, N.M.; Narang, K.; Tan, L.; Firooz, H.; Sanjabi, M.; Feizi, S. Understanding Failure Modes of Self-Supervised Learning. arXiv 2022, arXiv:2203.01881. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.B.; He, K. Improved Baselines with Momentum Contrastive Learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Jia, L. The Remote Sensing Analysis of Urban Sprawl and Environment Change in Beijing City. Master’s Thesis, Northeast Normal University, Changchun, China, 2006. [Google Scholar]
- Comprehensive Finance Department of the Ministry of Construction, C.F.D. China Urban-Rural Construction Statistical Yearbook; China Statistics Press: Beijing, China, 2006.
- Hu, Z. China Urban-Rural Construction Statistical Yearbook; China Statistics Press: Beijing, China, 2019. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DataSet | Unlabeled | Split: Train/Val/Test | Location | Resolution |
|---|---|---|---|---|
| BJ Dataset | 21,417 | 797/202/34(16) | Beijing, China | 1 m |
| EA DataSet | 4038 | 2508/903/627 | East Asia | 0.45 m |
| Hyperparameters | Setting Details |
|---|---|
| Basic Backbone Encoder (ResNet34[Default]) | 7 × 7, conv, stride = (2, 2), padding = (3, 3), 64, 3 × 3, maxpool |
| [[3 × 3conv, 64] × 2], concat, 1 × 1 conv, 64] × 3, | |
| 3 × 3conv, stride = (2, 2), 128, 3 × 3 conv, 128 | |
| [[3 × 3 conv, 128] × 2], concat, 1 × 1 conv, 128] × 3 | |
| 3 × 3 conv, stride = (2, 2), 256, 3 × 3 conv, 256 | |
| [[3 × 3 conv, 256] × 2], concat, 1 × 1 conv, 256] × 5 | |
| 3 × 3 conv, stride = (2, 2), 512, 3 × 3 conv, 512 | |
| [[3 × 3 conv, 512] × 2], concat, 1 × 1 conv, 512] × 3 | |
| contrastive Learning | Q-encoder, Basic Backbone |
| K-encoder, Basic Backbone | |
| Q-mlp, [1 × 1, avgpool, flatten, Liner(512, 128)] | |
| K-mlp, [1 × 1, avgpool, flatten, Liner(512, 128)] | |
| projector, [Liner(128, 512), BatchNorm(512), Liner(512, 128)] | |
| Data Augmentation | RandomHSV(20, 20, 20), Flip(0.5), Rotate(20), Scale(1), Clip(350, Rescale(384)[BJ Dataset] |
| RandomHSV(20, 20, 20), Flip(0.5), Rotate(20), Scale(1), Clip(500), Rescale(512)[EA Dataset] | |
| ColorJitter(0.4, 0.4, 0.4, 0.1), Flip(0.5), Rotate(20), Scale(1), RandomClip(256), Rescale(224)[Contrastive learning] | |
| Loss Function Adjustment | CrossEntropLoss[Default] |
| CosineSimilarity[Contrastive] | |
| Other Hyperparameters | Batchsize, 4 |
| iter, 80,000 | |
| Base Learning Rate, |
| Dataset | BJ Dataset | EA Dataset | |||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | IOU | |
| PSPNet | 0.811 | 0.598 | 0.688 | 0.708 | 0.854 | 0.774 | 0.642 |
| DeepLabv3+ | 0.842 | 0.550 | 0.665 | 0.798 | 0.839 | 0.818 | 0.692 |
| UNet(Random) | 0.578 | 0.836 | 0.684 | 0.682 | 0.850 | 0.757 | 0.610 |
| UNet(ImageNet) | 0.632 | 0.839 | 0.720 | 0.794 | 0.852 | 0.822 | 0.698 |
| SimCLR | 0.706 | 0.798 | 0.749 | 0.805 | 0.846 | 0.825 | 0.702 |
| BYOL | 0.823 | 0.682 | 0.746 | 0.790 | 0.858 | 0.822 | 0.704 |
| PGSSL | 0.871 | 0.666 | 0.755 | 0.818 | 0.816 | 0.817 | 0.690 |
| PGSSL* | 0.853 | 0.702 | 0.770 | 0.796 | 0.856 | 0.825 | 0.706 |
| 1% | 5% | 10% | 20% | 50% | 80% | 100% | |
|---|---|---|---|---|---|---|---|
| PSPNet | 0.221 | 0.570 | 0.588 | 0.611 | 0.650 | 0.702 | 0.688 |
| Deeplabv3+ | 0.509 | 0.548 | 0.573 | 0.620 | 0.723 | 0.704 | 0.665 |
| UNet | 0.636 | 0.621 | 0.598 | 0.656 | 0.700 | 0.703 | 0.720 |
| SimCLR | 0.649 | 0.624 | 0.490 | 0.610 | 0.754 | 0.723 | 0.749 |
| BYOL | 0.530 | 0.572 | 0.622 | 0.554 | 0.714 | 0.700 | 0.746 |
| PGSSL | 0.050 | 0.616 | 0.602 | 0.575 | 0.658 | 0.746 | 0.755 |
| PGSSL | 0.498 | 0.500 | 0.634 | 0.671 | 0.719 | 0.744 | 0.770 |
| 1% | 5% | 10% | 20% | 50% | 80% | 100% | |
|---|---|---|---|---|---|---|---|
| PSPNet | 0.640 | 0.729 | 0.737 | 0.726 | 0.780 | 0.777 | 0.774 |
| Deeplabv3+ | 0.712 | 0.776 | 0.796 | 0.803 | 0.811 | 0.815 | 0.818 |
| Unet | 0.719 | 0.782 | 0.800 | 0.811 | 0.813 | 0.822 | 0.823 |
| SimCLR | 0.728 | 0.776 | 0.800 | 0.809 | 0.822 | 0.822 | 0.825 |
| BYOL | 0.725 | 0.780 | 0.800 | 0.812 | 0.818 | 0.824 | 0.822 |
| PGSSL | 0.736 | 0.792 | 0.808 | 0.812 | 0.818 | 0.821 | 0.817 |
| PGSSL | 0.751 | 0.787 | 0.806 | 0.817 | 0.822 | 0.826 | 0.825 |
| Pseudo-Sample Learning | Contrastive Learning | Image Inpainting | EA DataSet [1%] | BJ DataSet [100%] |
|---|---|---|---|---|
| ✘ | ✘ | ✘ | 0.720 | 0.720 |
| ✔ | ✘ | ✘ | 0.740 | 0.732 |
| ✘ | ✔ | ✘ | 0.725 | 0.746 |
| ✘ | ✘ | ✔ | 0.731 | 0.730 |
| ✔ | ✔ | ✘ | 0.748 | 0.746 |
| ✔ | ✔ | ✔ | 0.751 | 0.770 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.-Y.; Peng, L.; Zhang, W.-Y.; Wang, Y.-D.; Yang, L.-N. Research on Self-Supervised Building Information Extraction with High-Resolution Remote Sensing Images for Photovoltaic Potential Evaluation. Remote Sens. 2022, 14, 5350. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14215350
Chen D-Y, Peng L, Zhang W-Y, Wang Y-D, Yang L-N. Research on Self-Supervised Building Information Extraction with High-Resolution Remote Sensing Images for Photovoltaic Potential Evaluation. Remote Sensing. 2022; 14(21):5350. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14215350
Chicago/Turabian StyleChen, De-Yue, Ling Peng, Wen-Yue Zhang, Yin-Da Wang, and Li-Na Yang. 2022. "Research on Self-Supervised Building Information Extraction with High-Resolution Remote Sensing Images for Photovoltaic Potential Evaluation" Remote Sensing 14, no. 21: 5350. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14215350