
Estimating Rainfall from Surveillance Audio Based on Parallel Network with Multi-Scale Fusion and Attention Mechanism

 , ,
, ,
Abstract
:
1. Introduction
- A parallel dual-channel network model called PNNAMMS is proposed for extracting different features of surveillance audio.
- A multi-scale fusion block and attention mechanisms are used in the model to better select features. Further, the impact of different multi-scale fusion methods and attention mechanisms on the performance of the model is explored.
- The results obtained using PNNAMMS to estimate rainfall levels are presented and analyzed.
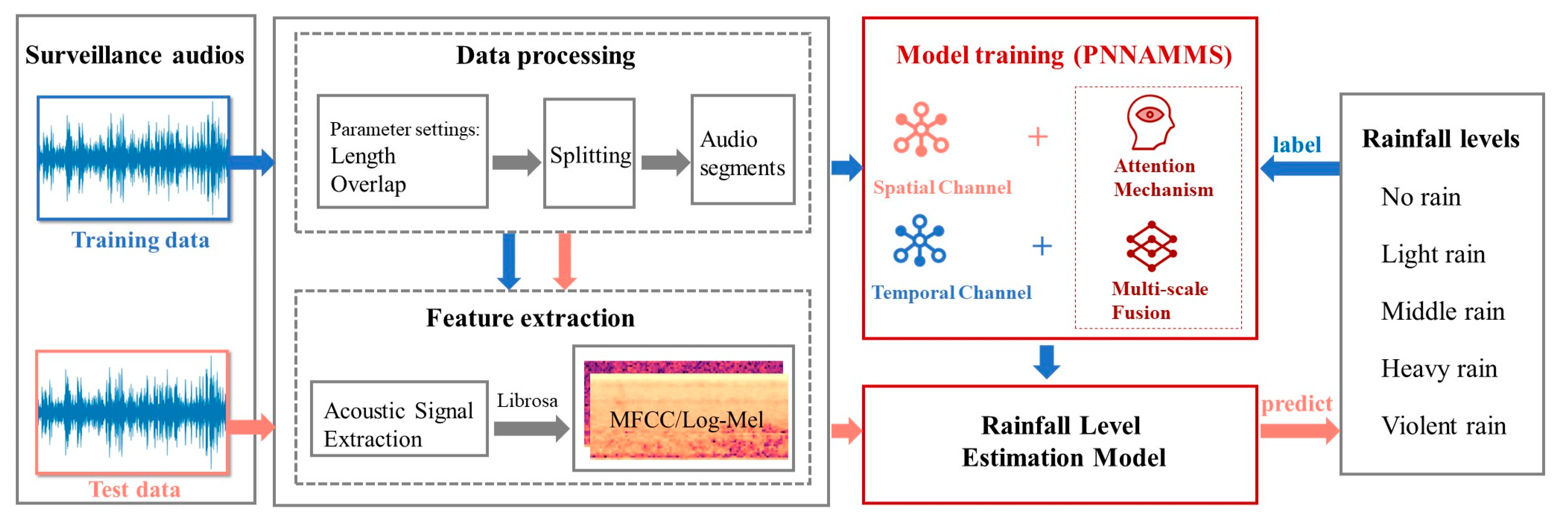
2. Methodology
2.1. Main Workflow
2.2. PNNAMMS
2.2.1. Parallel Spatiotemporal Network
- (a)
- L2 regularization: A regularization penalty term is added to the cost function, reducing the weights by an order of magnitude and mitigating overfitting.
- (b)
- Batch normalization: A normalization algorithm proposed by Ioffe and Szegedy [28] is used to speed up the convergence and stability of neural networks by normalizing every dimension of each batch of data.
- (c)
- Spatial dropout: A dropout method proposed by Tompson et al. [29] in the imaging field, which randomly sets some regions to zero, which is effective in image recognition.
2.2.2. Multi-Scale Fusion Block
2.2.3. Attention Mechanism in PNNAMMS
3. Experiments
3.1. Dataset
3.1.1. Model Training
- (1)
- Intel(R) Xeon(R) Bronze 3104 CPU @ 1.70 GHz,
- (2)
- NVIDIA GeForce GTX 1080 Ti graphics cards,
- (3)
- 32 GB RAM,
- (4)
- Python 3.6.8, and
- (5)
- TensorFlow 1.8.0, Keras 2.1.6, and Librosa 0.8.0 libraries [26].
3.1.2. Evaluation Metrics
4. Results
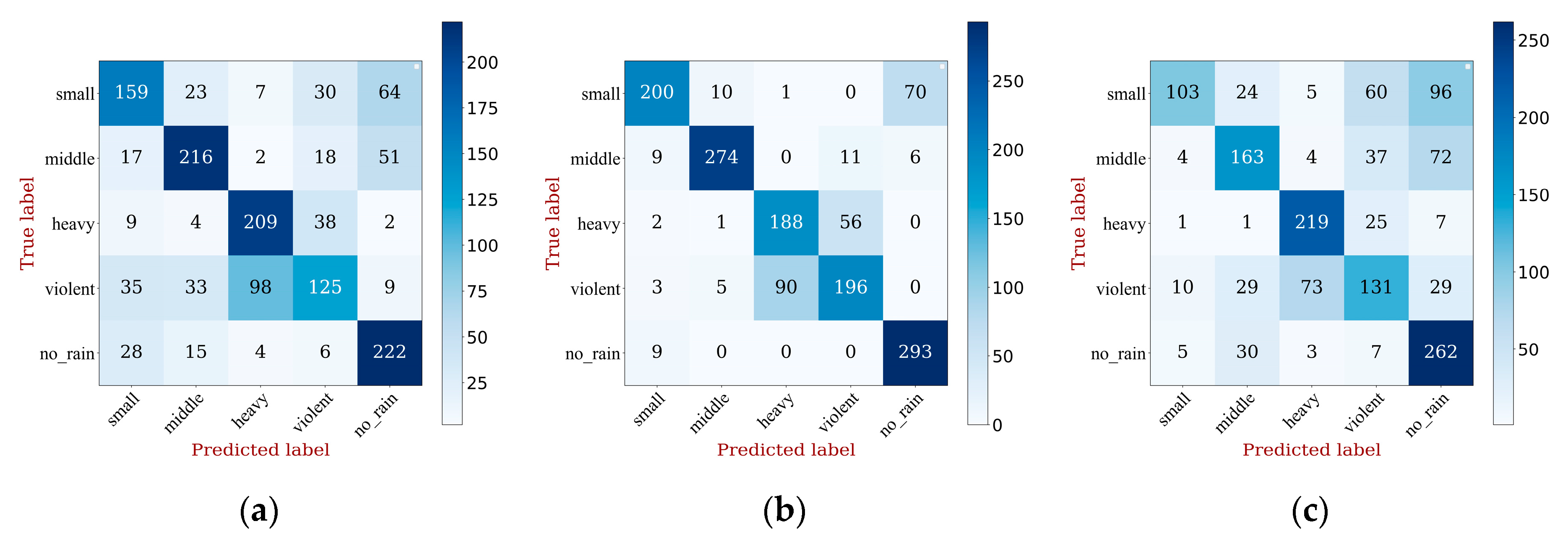
4.1. Classification Performance Comparison
4.2. Rainfall Inversion Validity
5. Discussion
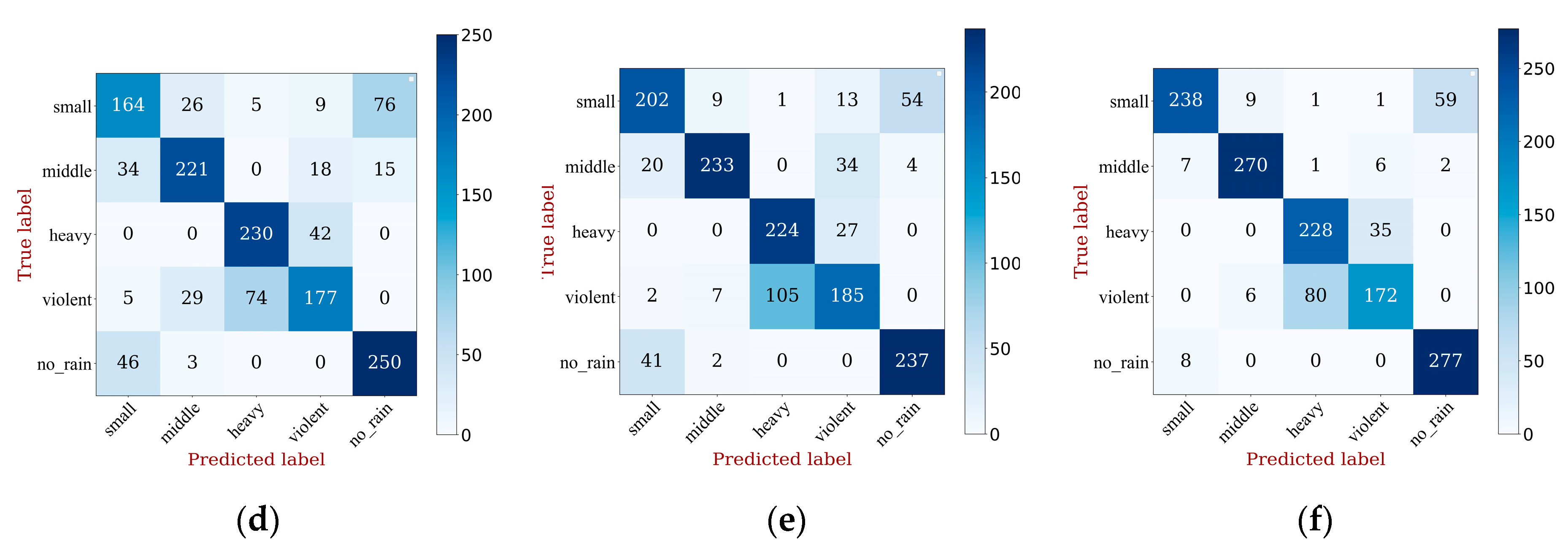
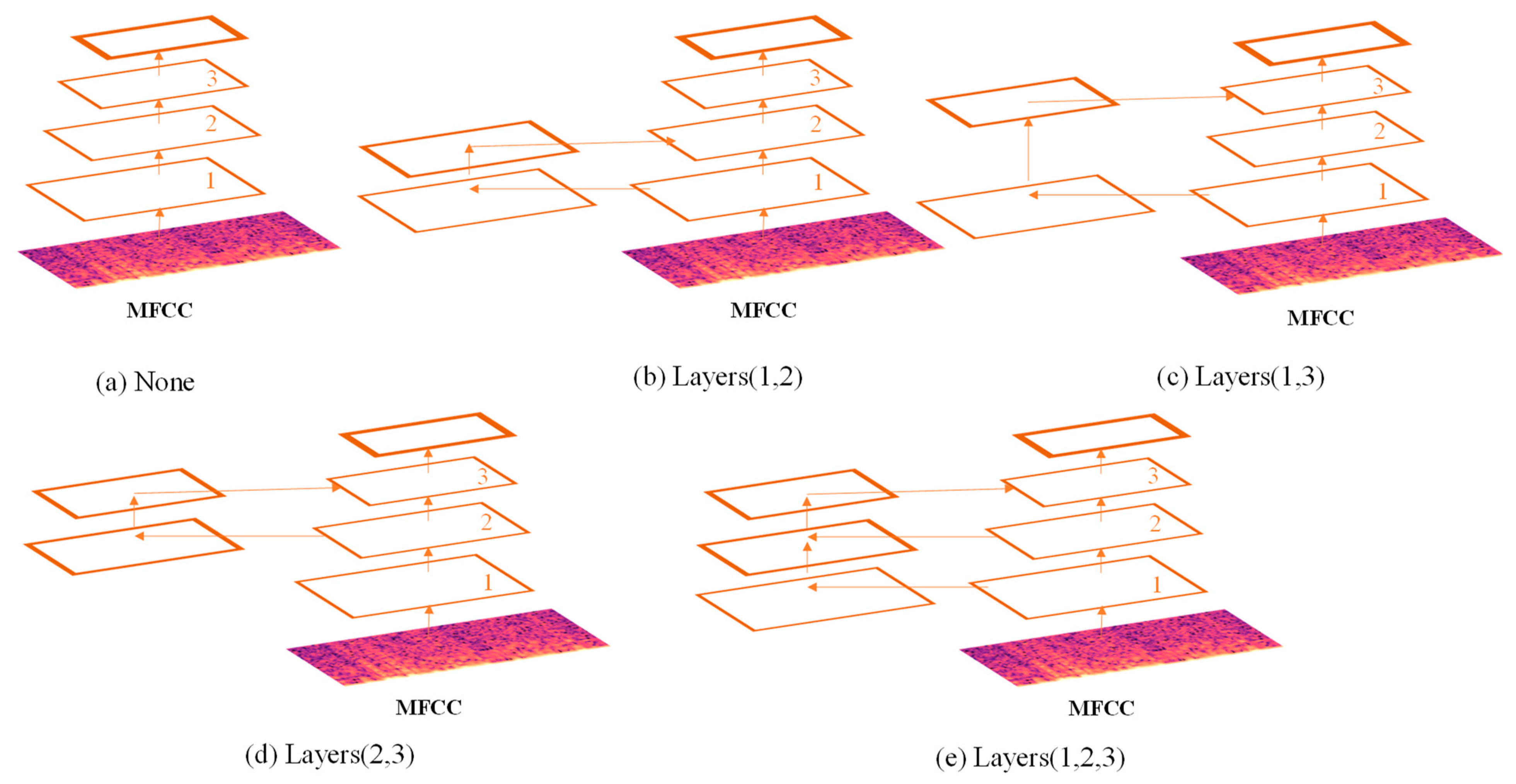
5.1. Multi-Scale Feature Fusion Performance Analysis
- (1)
- a single baseline network was used for training and evaluating on the RA_XZ dataset;
- (2)
- different combinations of fusion levels were used in the baseline network for training and evaluation (Figure 7).
5.2. Performance Analysis of Models with Different Attention Mechanisms
- (1)
- A single baseline network for training and evaluation of the RA_XZ dataset
- (2)
- Only a single attention mechanism in the baseline network for training and evaluation
- (3)
- Different combinations of attention mechanisms in the baseline network for training and evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Berne, A.; Delrieu, G.; Creutin, J.; Obled, C. Temporal and spatial resolution of rainfall measurements required for urban hydrology. J. Hydrol. 2004, 199, 166–179. [Google Scholar] [CrossRef]
- Li, L.; Zhang, K.; Wu, S.; Li, H.; Wang, X.; Hu, A.; Li, W.; Fu, E.; Zhang, M.; Shen, Z. An Improved Method for Rainfall Forecast Based on GNSS-PWV. Remote Sens. 2022, 14, 4280. [Google Scholar] [CrossRef]
- Rabiei, E.; Haberlandt, U.; Sester, M.; Fitzner, D.; Wallner, M. Areal rainfall estimation using moving cars—Computer experiments including hydrological modeling. Hydrol. Earth Syst. Sci. 2016, 20, 3907–3922. [Google Scholar] [CrossRef] [Green Version]
- Nakazato, R.; Funakoshi, H.; Ishikawa, T.; Kameda, Y.; Matsuda, I.; Itoh, S. Rainfall intensity estimation from sound for generating CG of rainfall scenes. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–4. [Google Scholar]
- Barthès, L.; Mallet, C. Rainfall measurement from the opportunistic use of an Earth–space link in the Ku band. Atmos. Meas. Tech. 2013, 6, 2181–2193. [Google Scholar] [CrossRef] [Green Version]
- Fletcher, T.D.; Andrieu, H.; Hamel, P. Understanding, management and modelling of urban hydrology and its consequences for receiving waters: A state of the art. Adv. Water Resour. 2013, 51, 261–279. [Google Scholar] [CrossRef]
- Liu, D.; Zhang, Y.; Zhang, J.; Xiong, L.; Liu, P.; Chen, H.; Yin, J. Rainfall estimation using measurement report data from time-division long term evolution networks. J. Hydrol. 2021, 600, 126530. [Google Scholar] [CrossRef]
- Rafieeinasab, A.; Norouzi, A.; Seo, D.; Nelson, B. Improving high-resolution quantitative precipitation estimation via fusion of multiple radar-based precipitation products. J. Hydrol. 2015, 531, 320–336. [Google Scholar] [CrossRef]
- Kuang, Q.; Yang, X.; Zhang, W.; Zhang, G. Spatiotemporal Modeling and Implementation for Radar-Based Rainfall Estimation. IEEE Trans. Geosci. Remote Sens. 1990, 13, 1601–1605. [Google Scholar] [CrossRef]
- Bischoff, P. Surveillance Camera Statistics: Which City has the Most CCTV Cameras? 2022. Available online: https://www.comparitech.com/studies/surveillance-studies/the-worlds-most-surveilled-cities/ (accessed on 11 July 2022).
- Wang, X.; Wang, M.; Liu, X.; Glade, T.; Chen, M.; Xie, Y.; Yuan, H.; Chen, Y. Rainfall observation using surveillance audio. Appl. Acoust. 2022, 186, 108478. [Google Scholar] [CrossRef]
- Reynolds, D.A. Gaussian mixture models. Encycl. Biom. 2009, 196, 659–663. [Google Scholar]
- Rabiner, L.; Juang, B. An Introduction to Hidden Markov Models. IEEE ASSP Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Temko, A.; Malkin, R.; Zieger, C.; Macho, D.; Nadeu, C.; Omologo, M. CLEAR Evaluation of Acoustic Event Detection and Classification Systems; Springer: Berlin/Heidelberg, Germany, 2006; pp. 311–322. [Google Scholar]
- Atal, B.S. Automatic recognition of speakers from their voices. Proc. IEEE 1976, 64, 460–475. [Google Scholar] [CrossRef]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef] [Green Version]
- Sharan, R.V.; Moir, T.J. An overview of applications and advancements in automatic sound recognition. Neurocomputing 2016, 200, 22–34. [Google Scholar] [CrossRef] [Green Version]
- Das, J.K.; Ghosh, A.; Pal, A.K.; Dutta, S.; Chakrabarty, A. Urban Sound Classification Using Convolutional Neural Network and Long Short Term Memory Based on Multiple Features. In Proceedings of the 2020 Fourth International Conference On Intelligent Computing in Data Sciences (ICDS), Fez, Morocco, 21–23 October 2020; pp. 1–9. [Google Scholar]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Karthika, N.; Janet, B. Deep convolutional network for urbansound classification. Sādhanā 2020, 45, 1–8. [Google Scholar] [CrossRef]
- Sharma, J.; Granmo, O.; Goodwin, M. Environment Sound Classification Using Multiple Feature Channels and Attention Based Deep Convolutional Neural Network. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 1186–1190. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Ferroudj, M.; Truskinger, A.; Towsey, M.; Zhang, L.; Zhang, J.; Roe, P. Detection of Rain in Acoustic Recordings of the Environment; Springer International Publishing: Cham, Switzerland, 2014; pp. 104–116. [Google Scholar]
- Bedoya, C.; Isaza, C.; Daza, J.M.; López, J.D. Automatic identification of rainfall in acoustic recordings. Ecol. Indic. 2017, 75, 95–100. [Google Scholar] [CrossRef]
- Metcalf, C.; Lees, A.C.; Barlow, J.; Marsden, S.J.; Devenish, C. hardRain: An R package for quick, automated rainfall detection in ecoacoustic datasets using a threshold-based approach. Ecol. Indic. 2020, 109, 105793. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 June 2015; pp. 18–25. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6 July–11 July 2015; pp. 448–456. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using Convolutional Networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef] [Green Version]
- Salamon, J.; Jacoby, C.; Bello, J.P. A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 1041–1044. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, H.; Chong, D.; Huang, D.; Zou, Y. What Affects the Performance of Convolutional Neural Networks for Audio Event Classification. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), Cambridge, UK, 3–6 September 2019; pp. 140–146. [Google Scholar]
- Zhang, Z.; Xu, S.; Cao, S.; Zhang, S. Deep convolutional neural network with mixup for environmental sound classification. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 23–26 November 2018; pp. 356–367. [Google Scholar]
- Xie, J.; Hu, K.; Zhu, M.; Yu, J.; Zhu, Q. Investigation of Different CNN-Based Models for Improved Bird Sound Classification. IEEE Access 2019, 7, 175353–175361. [Google Scholar] [CrossRef]
- Mesaros, A.; Heittola, T.; Virtanen, T. A multi-device dataset for urban acoustic scene classification. arXiv 2018, arXiv:1807.09840. [Google Scholar]
- Kwon, S. A CNN-Assisted Enhanced Audio Signal Processing for Speech Emotion Recognition. Sensors 2019, 20, 183. [Google Scholar]
- Li, S.; Yao, Y.; Hu, J.; Liu, G.; Yao, X.; Hu, J. An Ensemble Stacked Convolutional Neural Network Model for Environmental Event Sound Recognition. Appl. Sci. 2018, 8, 1152. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Yao, M.; Luo, L.; Liu, X.; Song, X.; Chu, W.; Guo, S.; Bai, L. Environmental Sound Recognition Based on Double-input Convolutional Neural Network Model. In Proceedings of the 2020 IEEE 2nd International Conference on Civil Aviation Safety and Information Technology (ICCASIT), Weihai, China, 14–16 October 2020; pp. 620–624. [Google Scholar]
- Dong, X.; Yin, B.; Cong, Y.; Du, Z.; Huang, X. Environment Sound Event Classification With a Two-Stream Convolutional Neural Network. IEEE Access 2020, 8, 125714–125721. [Google Scholar] [CrossRef]
- Puth, M.; Neuhäuser, M.; Ruxton, G.D. Effective use of Pearson’s product–moment correlation coefficient. Anim. Behav. 2021, 93, 183–189. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SC Network | TC Network | ||||
|---|---|---|---|---|---|
| Layer | Output Shape | Setting | Layer | Output Shape | Setting |
| Conv Max pooling | (38 × 171 × 64) (19 × 86 × 64) | 3 × 3, 64 3 × 3, stride 2 | LSTM | (128 × 64) | 64, return sequences = True |
| Residual Block | (10 × 43 × 64) | × 2 | Channel attention | (128 × 64) | |
| Multiscale Block | (19 × 86 × 64) | Temporal attention | (128 × 64) | ||
| Residual Block | (10 × 43 × 128) | × 2 | LSTM | (128 × 128) | 128, return sequences = True |
| Multiscale Block | (10 × 43 × 128) | LSTM | (64) | 64, return sequences = False | |
| Residual Block | (10 × 43 × 128) | × 2 | FC | (64) | 64 |
| Spatial attention | (5 × 22 × 64) | FC | (128) | 128 | |
| Global Average pooling | (64) | FC | (64) | 64 | |
| Concatenate & Classify | Result | ||||
| Total params | 1,151,855 | ||||
| Trainable params | 1,147,631 | ||||
| Rainfall Level | Rainfall Intensity (r) |
|---|---|
| No rain | r = 0 mm/h |
| Light rain | r ≤ 2.5 mm/h |
| Middle rain | 2.5 mm/h ≤ r ≤10 mm/h |
| Heavy rain | 10 mm/h ≤ r ≤ 25 mm/h |
| Violent rain | r > 2.5 mm/h |
| Method | Feature | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| FPNet-2D | Mel | 0.6173 | 0.6141 | 0.6155 | 0.6056 |
| CNN | Mel | 0.6537 | 0.6511 | 0.6584 | 0.6538 |
| Mel-CNN | Mel | 06383 | 0.6415 | 0.6450 | 0.6385 |
| Baseline system | Mel | 0.6046 | 0.5979 | 0.6056 | 0.5983 |
| DSCNN | MFCC | 0.5520 | 0.5643 | 0.5585 | 0.5602 |
| DS-CNN | Mel&Raw | 0.6271 | 0.6650 | 0.6346 | 0.6105 |
| MRNet | Mel&Raw | 0.7317 | 0.7365 | 0.7342 | 0.7338 |
| 5-stacks CNN | MFCC-C-CH | 0.8082 | 0.8203 | 0.8165 | 0.8178 |
| RACNN | Log-mel&Raw | 0.7721 | 0.7839 | 0.7794 | 0.7765 |
| PNNAMMS | MFCC&Log-mel | 0.8464 | 0.8543 | 0.8569 | 0.8468 |
| Index | PPMCC_MFCC | PPMCC_Log-mel |
|---|---|---|
| Average | 0.9496 | 0.8938 |
| Variance | 0.0007 | 0.0016 |
| Standard Deviation | 0.0264 | 0.0400 |
| Levels | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| None | 0.7907 | 0.7951 | 0.7945 | 0.7849 |
| Layers(1,2) | 0.7328 | 0.7381 | 0.7335 | 0.73647 |
| Layers(1,3) | 0.8200 | 0.8345 | 0.8279 | 0.8298 |
| Layers(2,3) | 0.7828 | 0.7934 | 0.7856 | 0.7875 |
| Layers(1,2,3) | 0.8464 | 0.8543 | 0.8569 | 0.8468 |
| Attention | Description | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| None | None | 0.8114 | 0.8109 | 0.8155 | 0.8148 |
| S | Spatial | 0.8092 | 0.8238 | 0.8125 | 0.8057 |
| T | Temporal | 0.8050 | 0.8146 | 0.8168 | 0.8034 |
| C | Channel | 0.8164 | 0.8345 | 0.8239 | 0.8198 |
| C-S | Channel_Spatial | 0.8071 | 0.8113 | 0.8165 | 0.8143 |
| C-T | Channel_Temporal | 0.8235 | 0.8468 | 0.8265 | 0.8250 |
| S_T | Spatial + Temporal | 0.8242 | 0.9135 | 0.9142 | 0.9130 |
| C-S_T | Channel_Spatial + Temporal | 0.8007 | 0.8188 | 0.8059 | 0.8086 |
| S-C_T | Spatial + Channel_Temporal | 0.8464 | 0.8543 | 0.8569 | 0.8468 |
| C-S_C-T | Channel_Spatial + Channel_Temporal | 0.8200 | 0.8313 | 0.8243 | 0.8240 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Wang, X.; Wang, M.; Liu, X.; Wu, Y.; Wang, X. Estimating Rainfall from Surveillance Audio Based on Parallel Network with Multi-Scale Fusion and Attention Mechanism. Remote Sens. 2022, 14, 5750. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14225750
Chen M, Wang X, Wang M, Liu X, Wu Y, Wang X. Estimating Rainfall from Surveillance Audio Based on Parallel Network with Multi-Scale Fusion and Attention Mechanism. Remote Sensing. 2022; 14(22):5750. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14225750
Chicago/Turabian StyleChen, Mingzheng, Xing Wang, Meizhen Wang, Xuejun Liu, Yong Wu, and Xiaochu Wang. 2022. "Estimating Rainfall from Surveillance Audio Based on Parallel Network with Multi-Scale Fusion and Attention Mechanism" Remote Sensing 14, no. 22: 5750. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14225750