1. Introduction
Hyperspectral images (HSIs) are three-dimensional (3D) volumetric data with a spectrum of continuous and narrow bands, which can reflect the characteristics of ground objects in detail [
1]. In recent years, many mini-sized and low-cost HSI sensors have appeared, which makes it easy to obtain HSI data with rich spatial–spectral information, such as AisaKESTREL10, AisaKESTREL16, and FireflEYE [
2,
3]. In this context, HSI is widely used in the fields of resource detection, environmental analysis, disaster monitoring, etc. [
4,
5,
6]. The classification of HSI is a basic analysis task that has become very popular [
7]. However, due to the influence of the small number of samples (small samples), the high-dimensional characteristics, the similarity between the spectra, and the mixed pixels, efficient and accurate classification of HSI data has been a challenging task for many years [
8,
9,
10]. To solve these problems, some deep learning network models have been applied in HSI processing [
11], especially the convolutional neural network (CNN).
Recently, CNN has attracted extensive attention due to its efficacy in many visual applications, for instance, classification, object detection, and semantic segmentation [
12,
13,
14]. Three types of CNNs—namely, one-dimensional (1D), two-dimensional (2D), and three-dimensional CNNs—are successfully applied in HSI classification tasks. The 1D and 2D CNNs can obtain more abstract level spectral or spatial features of HSI [
15]. The 3D CNN can learn the structural spatial–spectral feature representation using a 3D core, which can comprehensively characterize ground objects [
16]. Recently, 3D CNNs have attracted extensive attention in HSI classification. Li et al. presented a novel approach that uses a 3D CNN to view HSI cube data altogether [
17]. Mayra et al. used a 3D CNN to show the great potential of using HSI to map tree species [
18]. Although these two 3D CNN models offer a simple and effective method for HSI classification, their accuracy and efficiency can be still further improved.
As can be seen from the literature, the results of using a single CNN of the three CNNs have a few shortcomings in achieving high accuracy [
19]. The main reason is that HSI data are volumetric data and have information representation in both spatial and spectral dimensions. The 1D CNN and 2D CNN alone are not able to extract discriminating feature maps from both spatial and spectral dimensions. Similarly, a deep 3D CNN is more computationally complex, and it is difficult to classify a large volume of HSI data with its use. In addition, the performance of using a 3D CNN alone cannot satisfy the analysis of classes with similar textures over many spectral bands [
19]. To address these issues, hybrid CNNs for HSI classification are developed. Swalpa et al. proposed a hybrid spectral CNN model (HybridSN), which assembles the 3D and 2D convolutional layers for reducing the complexity of the 3D CNN model [
19]. Zhang et al. used a 3D–1D CNN model and showed improved accuracy in the classification of vegetation species [
16]. Since the performance of these two models is still limited for classification applications in the condition of ground scenes with many different land cover types, a hybrid 3D–2D–1D CNN has been proposed by Liu et al. [
20]. Notably, it does not perform well in terms of accuracy when the sample data are small. In this study, a new model that makes full use of multidimensional CNNs is proposed and uses some refinement mechanisms to overcome these shortcomings of the previous methods.
Moreover, for the problem of small samples, an attention mechanism was applied to an HSI analysis task [
21,
22]. The attention mechanism is a resource allocation scheme that can improve the performance of a model with a little computational complexity [
23], such as the squeeze-and-excitation networks (SENets) [
24], the selective kernel networks (SKNets) [
25], the convolutional block attention module (CBAM) [
26], and the bottleneck attention module (BAM) [
27]. Compared with SENet, SKNet, and BAM, CBAM is a lightweight model, and it can extract attention features in spatial–spectral dimensions for adaptive feature refinement. Considering HSI is a 3D feature map, CBAM is selected to enhance the expression ability of the HSI classification model. Additionally, to make it applicable to the characteristics of HSI and obtain a higher accuracy of the classification using HSI, a convolutional block self-attention module named CBSM is also proposed based on the CBAM.
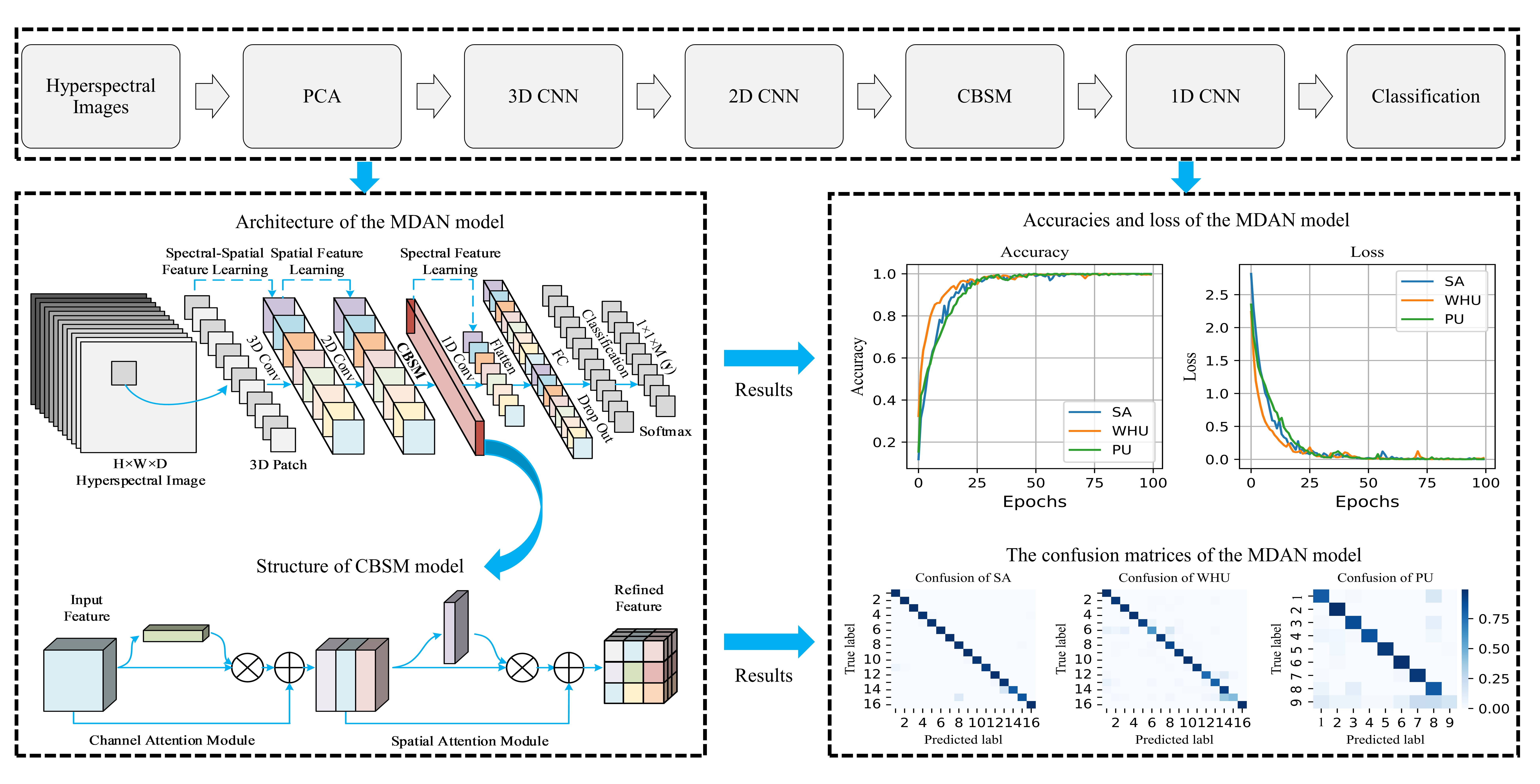
For the application of the CBSM model, this study proposes a multidimensional CNN with an attention mechanism model named MDAN. The MDAN model contains three types of CNNs components and the CBSM model for higher efficiency and accuracy of classification purposes.
The main contributions of this study are as follows:
An improved graph convolutional network MDAN is proposed for HSI classification with small samples;
A multidimensional CNN and a classical attention mechanism CBAM are used to create deeper feature maps from small samples;
Based on CBAM, an attention module CBSM is designed to improve HSI classification accuracy. The CBSM has increased connections, which is more suitable for the classification of HSI data. Comparative experiments are carried out on three open datasets, and the experimental results indicate that the MDAN model and the CBSM model are superior to other state-of-the-art HSI classification models.
The rest of the paper is organized as follows:
Section 2 introduces the proposed MDAN and CBSM.
Section 3 presents the parameter settings and the results of the proposed approaches on the three different HSI datasets. The discussion of the results is described in
Section 4. Finally, the conclusions are shown in
Section 5.
4. Discussion
The results of the proposed models and the selected models are shown in
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9. It can be seen that the MDAN model achieves the best performance among all of the selected models in terms of both accuracy and efficiency and achieves the overall accuracies of 97.34%, 92.23%, and 96.42%, respectively, in the test results of the SA, PU, and WHU datasets. In addition, compared with the two basic algorithms of 2D CNN and 3D CNN, the efficiency of MDAN is significantly improved. Additionally, compared with the 3D–2D–1D CNN, which is the most efficient model among all of the selected CNN models, MDAN takes slightly longer in terms of training and testing times. Different from the selected CNN models, the SVM model achieves the lowest accuracy but the highest efficiency among all of the selected models; thus, it is suitable for the situation of HSI classification that does not require high accuracy but needs high efficiency.
The classification results of the 2D CNN indicate lower efficiency but higher accuracy than those of the 3D CNN in the case of small samples. However, if the samples are sufficiently large, the 3D CNN is better capable of extracting discriminating features than the 2D CNN; then, the accuracy of the 3D CNN can meet the most requirements [
37]. This is because the 3D CNN can obtain higher-level features than the 2D CNN and can further reduce the number of training samples. In general, a CNN model needs massive volumes of data for a good performance; thus, the classification accuracy of the 3D CNN is lower than that of the 2D CNN with small samples when the valid information of the HSI features is removed. Moreover, the 2D CNN retains more parameters, which tend to consume a large amount of time in the stage of using a classifier. As a result, the efficiency of the 2D CNN is the lowest efficiency among all selected models.
In the case of small samples, the hybrid 3D–2D–1D CNN is more efficient and accurate than the 3D CNN. However, the accuracy of this hybrid model is not as good as that of the 2D CNN, and it is reduced in the results of the SA and PU datasets, while it remains the same in the results of the WHU dataset. Therefore, this method still can be improved regarding the accuracy of the classification using HSI.
The accuracy of the 3D–2D–CBAM–1D CNN is higher than that of the hybrid 3D–2D–1D CNN model. In addition, the 2D and the 1D convolutional layers are incorporated in the hybrid model for high efficiency; thus, the CBAM model is also used between the 2D and 1D convolutional layers to form the 3D–2D–CBAM–1D CNN for high accuracy. CBAM is a spatial-spectrum attention module, which significantly improves the performance of a vision task based on its rich representation power [
26]. As shown in
Table 3, this model achieves an accuracy improvement, as expected by using CBAM. However, due to the unique high-dimensional spectral characteristics of HSI, the best performance cannot be achieved by CBAM only, and the accuracy of the 3D–2D–CBAM–1D CNN is close to that of the 2D CNN.
According to the literature on attention models, different attention connections lead to different classification results [
39,
40,
41]. Thus, the CBSM attention module with different attention structural connections from CBAM is proposed to suit the 3D characteristics of HSI data. CBSM can significantly improve CNN’s ability to classify HSI data, and the application of CBSM in MDAN, i.e., 3D–2D–CBSM–1D CNN further improves the accuracy from the CBAM used in 3D–2D–CBAM–1D CNN by 1%. Compared with the selected models of the SVM, 2D CNN,3D CNN, 3D–2D–1D CNN, and 3D–2D–CBAM–1D CNN, the MDAN model is the best performer on all three datasets. In addition, the MDAN model also performs well in balanced training samples and correctly classifies all classes, as shown in
Table 4.
In summary, since the application of the attention mechanism, the MDAN model can make CNN more efficient and more accurate in HSI classification than other selected CNN models for small-sample problems. The attention module CBSM can further improve the accuracy of the HSI classification model and can be easily integrated into other CNN models to improve model performance.
5. Conclusions
In this study, to address the poor accuracy of HSI classification models on the small samples in the training data, an improved graph model MDAN was proposed from the perspective of multidimensional CNNs and attention mechanisms. The MDAN model can efficiently extract and refine features to obtain better performance in terms of both accuracy and efficiency. To make the model more suitable for HSI data structure, an attention module CBSM was also proposed in this study, which provided a better connection method than the most widely used CBAM model. The CBSM module was used in the MDAN model; thus, the spatial–spectral features were further refined, resulting in a model that significantly helps to improve the accuracy of the HSI classification under the condition of small samples. A series of comparative experiments were carried out using three open HSI datasets. The experiment results indicated that the combination of multidimensional CNN and attention mechanisms has a better performance on HSI data among all of the selected models using both balanced and unbalanced small samples. The connection method used in the CBSM model is more suitable for the extraction and classification of HSI data and further improved the accuracy.
However, the performance of CBSM is better than CBAM only in the connection method. Hence, future studies will be focused on finding a more targeted attention module for HSI data. Moreover, the accuracy improvement made by new models is still limited; thus, other strategies, such as supplementing the small samples using open high-dimensional spectral data, may be used in the future. In addition, future research will also focus on transfer learning and the samples randomly selected from anywhere when a large number of rich HSI data appear.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}