1. Introduction
In the field of remote sensing image analysis and processing, object detection is a very important research interest. The emergence of deep convolutional neural networks (CNNs) has given rise to lots of remarkable CNN-based methods for object detection. These approaches can be classified into two main categories: horizontal object detection [
1,
2,
3,
4] and oriented object detection [
5,
6,
7,
8], based on the difference in bounding box representation. But these methods usually depend on using a large-scale and diverse dataset, which entails a laborious and time-consuming process to accumulate huge amounts of data. Thus, the demand to develop robust detection capabilities for new categories when provided with only a few annotated samples is becoming increasingly urgent in object detection.
Over the last few years, few-shot learning (FSL) has gained prominence as a novel research focus, with the goal of training models using few annotated samples. FSL methods mainly focus on the classification problem, such as the Siamese neural network [
9], the matching network [
10], and the prototypical network [
11]. Based on these FSL methods, to require the model to not only recognize the object classes but also localize the objects in the image, few-shot object detection (FSD) has emerged as a prominent area of study in computer vision research. Usually, in the case of FSD, the dataset includes both base classes, which have numerous annotated samples, and novel classes, which have only a few annotated samples. Then, even with only a few annotated samples of novel classes and the aid of base classes, FSD models can more effectively detect novel classes than general detection methods. There are two approaches to categorizing the existing FSD methods: meta-learning based methods [
12,
13,
14] and transfer-learning based methods [
15,
16,
17]. Specifically, meta-learning aims to learn prior knowledge from a series of tasks for new tasks, while transfer-learning methods transfer the existing model learned from an original task to a new task through some measures. These FSD methods have shown significant progress on natural image datasets, such as PASCAL VOC and MS COCO.
However, these few-shot object detection methods all belong to horizontal object detection, and the orientation information of objects cannot be captured solely by using horizontal bounding boxes, which severely limits the use of these methods in practical applications, such as prow detection [
18] and object change detection [
19] in remote sensing images. And the multi-oriented and dense distribution characteristics of objects in remote sensing images often lead to situations where several objects are tightly grouped and encompassed by a single horizontal bounding box, typically resulting in misaligned bounding boxes and objects. Therefore, oriented object detection that can effectively solve the above problems has developed rapidly in recent years. But, it requires the detector to have higher classification and regression capabilities for multi-oriented and multi-scale objects. Specifically, multi-oriented refers to the situation where objects have different orientations in the images resulting from a single perspective with more consistent object features. And this is different from the situation known as multi-angular, where the images resulting from multiple perspectives contain information from different sides of the object, leading to significant differences in object features. Multi-scale refers to the significant difference in the size of objects of the same category in the images, which can be seen as the difference in the number of pixels contained in the object. In few-shot oriented object detection, because of the lack of annotated samples for model training, the challenge is more severe. To visualize this challenge, we take the ground track field class in the public oriented object detection remote sensing dataset DOTA [
20] as an example, and randomly select 30 samples as the few-shot case, while all labeled samples from the original dataset are used as original cases. As depicted in
Figure 1, the orientation and scale distribution of objects in the few-shot case (blue column) are considerably sparser than those in the original case (red column) of abundant training data. This challenge makes it more difficult for few-shot detectors to learn the ability to detect multi-oriented and multi-scale objects, and the issue of enriching the orientation and scale space using only a few annotated samples is still an open question in need of a solution.
Moreover, oriented object detection methods [
6,
21] often utilize rotate RoI alignment (RRoI align) to extract oriented proposals from the feature map for subsequent classification, which mainly contains the foreground information of the object, while there is little contextual information about the object and its surrounding environment. Researchers generally believe that the contextual information around the object is of little significance to oriented object detection [
6,
22] when an abundance of annotated samples are available. But, in few-shot oriented object detection, it is not enough to train the detector to effectively distinguish each object depending only on the foreground information. So, how to make use of other information in the few annotated samples is a very important problem. Most types of objects have specific backgrounds that contain different contextual information; as shown in
Figure 2a,b, the surrounding environment between ships and vehicles is different, and this clue can be used to help classification [
23]. However, as depicted in
Figure 2c,d, because surrounding environments are changeable and objects are often densely distributed in remote sensing images, it is not effective to simply expand the bounding box to add contextual information [
6]. Thus, effectively extracting and integrating the contextual information with the foreground information remains a significant challenge.
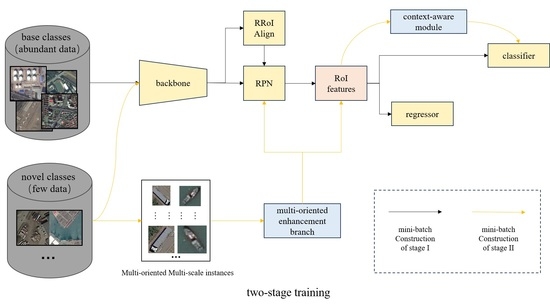
To tackle these challenges, we introduce a few-shot oriented object detection method: MOCA-Net. Specifically, based on the latest oriented object detection method, Oriented R-CNN [
22], our method introduces multi-oriented enhancement branch and context-aware modules. To solve the problem of orientation and scale distribution sparsity, inspired by MPSR [
24], we propose a multi-oriented enhancement branch, adding a new branch to generate multi-oriented and multi-scale positive samples to assist training. During model training, this enhancement branch not only classifies the generated multi-oriented and multi-scale objects but also performs oriented bounding box regression in a region proposal network (RPN) and the detector head, which can enhance both the classification and the regression capabilities of the detector for objects with different orientations and scales. This branch shares parameters with the basic detector, and we actively select feature pyramid network (FPN) [
25] stages and proposals to avoid introducing a large number of improper negative samples. Meanwhile, we also propose a context-aware module for object classification that introduces contextual information between the object and the surrounding environment. The module expands the areas of proposals to include the background as context-aware areas, obtains their features through RRoI align, and then determines the relevance between each context-aware feature and its corresponding RoI features. Then, the contextual information is adaptively integrated into the RoI features based on their relevance. And the module makes full use of the contextual information in the external horizontal bounding box, selects the top/bottom/left/right half part as the contextual subregions, which contain different contextual information about different parts of the object and the background, then concatenates and fuses these corresponding features after RRoI align, and finally integrates them into RoI features. We tested our method on the public oriented object detection dataset DOTA [
20], and general oriented object detection methods, such as RoI transformer [
6] and ReDet [
8], and existing FSD methods, such as Meta R-CNN [
13] and TFA [
16], were adopted to compare with our method and proved its effectiveness. Our key contributions, summarized as four main points, can be outlined as follows:
We introduce a few-shot oriented object detection method with a multi-oriented enhancement branch and context-aware module. As far as we know, we are the first to introduce few-shot object detection research into the field of oriented object detection.
To deal with this problem of oriented and scale distribution sparsity, we propose a multi-oriented enhancement branch to enrich the orientation and scale space of the object.
We propose a context-aware module that introduces the context mechanism into few-shot oriented object detection.
This is the first time that we have built three different base/novel settings specifically for few-shot oriented object detection on the large-scale remote sensing dataset DOTA. Furthermore, we present baseline results that can serve as a benchmark for future studies.
The subsequent portions of this article are organized in the manner described below.
Section 2 offers a brief overview of the relevant literature regarding our method.
Section 3 provides a comprehensive description of our proposed approach, MOCA-Net. In
Section 4, we present the experimental setup and comprehensive results. We further discuss our method in
Section 5. In the end, we summarize the article in
Section 6.
5. Discussion
Our proposed method, MOCA-Net, was evaluated in numerous experiments on the DOTA datasets and compared with various general oriented object detection methods and FSD methods. The results obtained from the comparative experiments serve as evidence for the strengths of our proposed method, which will be individually analyzed and discussed in this section.
Firstly, the observation can be made from
Table 2 that the performance of general oriented detection methods drops sharply when there are only few data of novel classes. For the DOTA dataset, these methods can only achieve an mAP of 20% to 40% in the 30-shot case, and the performance is significantly worse than when there are huge amounts of data. In addition, the results in
Table 2 also reveal that FR-O, only adding angle
to the last output of Faster R-CNN, performs better than Gliding Vertex, R3Det, and Sa2Net, which are well-designed for oriented object detection with large amounts of data. This situation reveals the weakness of the existing oriented object detection methods: the existing improvements proposed are mainly aimed at situations where there are plenty of annotated samples for model training, and these improvements will not significantly improve the detection accuracy when there is a lack of annotated samples. And the performance of our method surpasses all others in every case, with an mAP that was generally higher than other methods by at least 5% and even up to 10%, which demonstrates the significant advantages of introducing a multi-oriented enhancement branch and context-aware module in few-shot oriented object detection.
Secondly, from the data results presented in
Table 4, the FSD method, which has excellent performance in natural images, is not significantly effective in remote sensing images. The detection accuracy of FSD methods is not significantly higher than that of the latest general oriented object detection methods such as Oriented R-CNN, while our method, MOCA-Net, performs the best in all cases, reflecting that the FSD methods for the horizontal bounding box are not completely applicable to object detection in remote sensing images, and our method is specifically designed on an oriented bounding box, making it more suitable than FSD methods. Furthermore, compared with MPSR, which only focuses on the problem of object scale, our approach increased mAP by averages of 4.7%, 11.2%, and 5.4% in split1, split2, and split3 settings, respectively. And compared with FSCE, which only focuses on the classification part, our approach increased mAP by averages of 4.9%, 9.6%, and 3.5% in split1, split2, and split3 settings, respectively. These results further demonstrate the advantages of our approach in addressing the issues of both object orientation and object scale while not only enhancing the model’s regression capability but also the model’s classification capability.
Thirdly, it is apparent from
Table 5 that our method has exhibited outstanding performance in most categories, and for some categories, such as plane (PL) and large vehicle (LV), which have various scales and arbitrary orientations, our method has resulted in significant increases in the detection accuracy of 7.5% and 9.1%, respectively, compared to Oriented R-CNN. And it is also apparent that the detection difficulty varies across different categories in few-shot oriented object detection and that there is a significant difference in detection accuracy between different categories. For the categories with large aspect ratios, such as harbor (HA) and bridge (BR), it is still challenging for our approach to detect them. In addition, some methods have shown excellent detection performance for specific categories. For example, Sa2net, which introduces a feature alignment module, performs well on small vehicles (SV), and ReDet, which incorporates a rotation-invariant backbone and rotation-invariant ROI align, achieves outstanding results on tennis courts (TC), which is worthy of further research.
But, in few-shot oriented object detection, due to the large number of parameters and strong representation ability of CNN-based models, if the annotated samples are few, the model is easily able to remember non-universal features of the object, resulting in overfitting and reducing the model’s generalization ability [
12]. The results in
Table 2 show that the mAPs of all methods, including our proposed method, are still less than 50% and that there is still a huge improvement range. And because of the variable scale and orientation of objects as well as the complex background in remote sensing images, few-shot object detection is more difficult in remote sensing images. It can been seen from
Table 3, that the performance of FSD methods such as TFA and Meta R-CNN in remote sensing images is far inferior to their performance in natural images. In addition, for the categories with large aspect ratios, such as harbor (HA) and bridge (BR), with difficulty in bounding box regression, it is still hard for the existing methods to detect them. And the large-scale dataset DOTA, containing 15 classes and 188,282 objects, which covers most cases in oriented object detection, makes the detection more difficult. Therefore, few-shot oriented object detection still remains a huge challenge and has great research space in the future.
Meanwhile, we conducted a comprehensive ablation study to further explore our methods. These experiments in the ablation study provide a detailed demonstration of the effects and performance of each component in the multi-oriented enhancement branch and the context-aware module.
According to the ablation experiments of the multi-oriented enhancement branch, as shown in
Table 6, the models with only RPN and RoI partially enhanced all exceeded the baseline in all shots, which proved their effectiveness. When they are combined, the detection accuracy of the model is further improved, which shows that the two parts play a complementary role. And, although most FSD methods assume that the box regression capability of the model is class-agnostic and does not need to be enhanced during model transfer, it can be seen from the comparison between line 2 and line 5 of
Table 6 that further improvements can be made to enhance the detection performance by incorporating regression enhancement when classification enhancement is carried out, indicating that the enhancement of the regression task is also important in few-shot oriented object detection. In addition, after adding random crop to the multi-oriented enhancement branch, the model achieved the best performance, proving that random clipping can increase the generalization of the detector and improve its detection effect.
According to the ablation experiments of the context-aware module, as shown in
Table 7, we can see that adding background context information or horizontal box context information to assist the object classification can bring about a significant improvement in the detection accuracy of the detector, and that the combination of both components results in the best performance, indicating their complementary roles. And, as shown in
Table 8, it can be seen that increasing the expansion coefficient does not necessarily lead to better results. When the expansion coefficient is 1.5, the module achieves the best performance. When the expansion coefficient is too small to be 1.2, the added contextual information is small, resulting in only a small increase in detection precision. When the expansion coefficient is too large to be 2.0, it will add too much contextual information, reducing the proportion of object features, and the detection precision is lower than when the coefficient is 1.5. In addition, as evidenced by the results presented in
Table 9, the introduction of our context-aware module into different oriented object detection methods has led to a significant improvement in the detection accuracy after introducing our context-aware module into different oriented object detection methods, which demonstrates the importance of contextual information in few-shot oriented object detection.
For the applicability of our proposed method on real measured RS data, we tested the effectiveness of our proposed method on the public large-scale dataset DOTA (Dataset for Object Detection in Aerial Images) [
20]. This dataset is the most representative public remote sensing image dataset for oriented object detection and consists of 2806 optical aerial images and contains 188,282 objects and 15 object classes, with data from various sensors and platforms such as Google Earth. Because the dataset DOTA covers most cases of oriented object detection in optical aerial images, many famous object detection algorithms in the field of remote sensing are based on this dataset, such as RoI transformer [
6] and ReDet [
8], and based on these methods, excellent methods have been developed for specific applications such as ship detection [
18,
37]. Due to this, we believe that our proposed method can be applied to scenes and inspire future research for few-shot oriented object detection in optical aerial images.
To summarize, we designed a few-shot oriented object detection method, MOCA-Net, based on a multi-oriented enhancement branch and a context-aware module in this study, and our method has been proven effective through numerous experiments and an ablation study. Although a remarkable level of improvement is brought about through our method, as shown in the experiment results, the detection accuracy of our method is still relatively low, with an mAP of less than 40% in most cases. And the multi-oriented enhancement branch cannot be fully plug-and-play like the context-aware module, which makes it unable to be directly added to other methods such as RoI transformer and ReDet. In the future, we will make the multi-oriented enhancement branch easier to add to other methods and improve our approach by studying the principles of other methods, such as Sa2net and ReDet, refining the network architecture, and optimizing the training strategy to further enhance the detection performance on various categories, with a specific focus on categories characterized by a large aspect ratio.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}