
Improved Neural Network with Spatial Pyramid Pooling and Online Datasets Preprocessing for Underwater Target Detection Based on Side Scan Sonar Imagery
 , ,
, ,
Abstract
:1. Introduction
2. Methodology
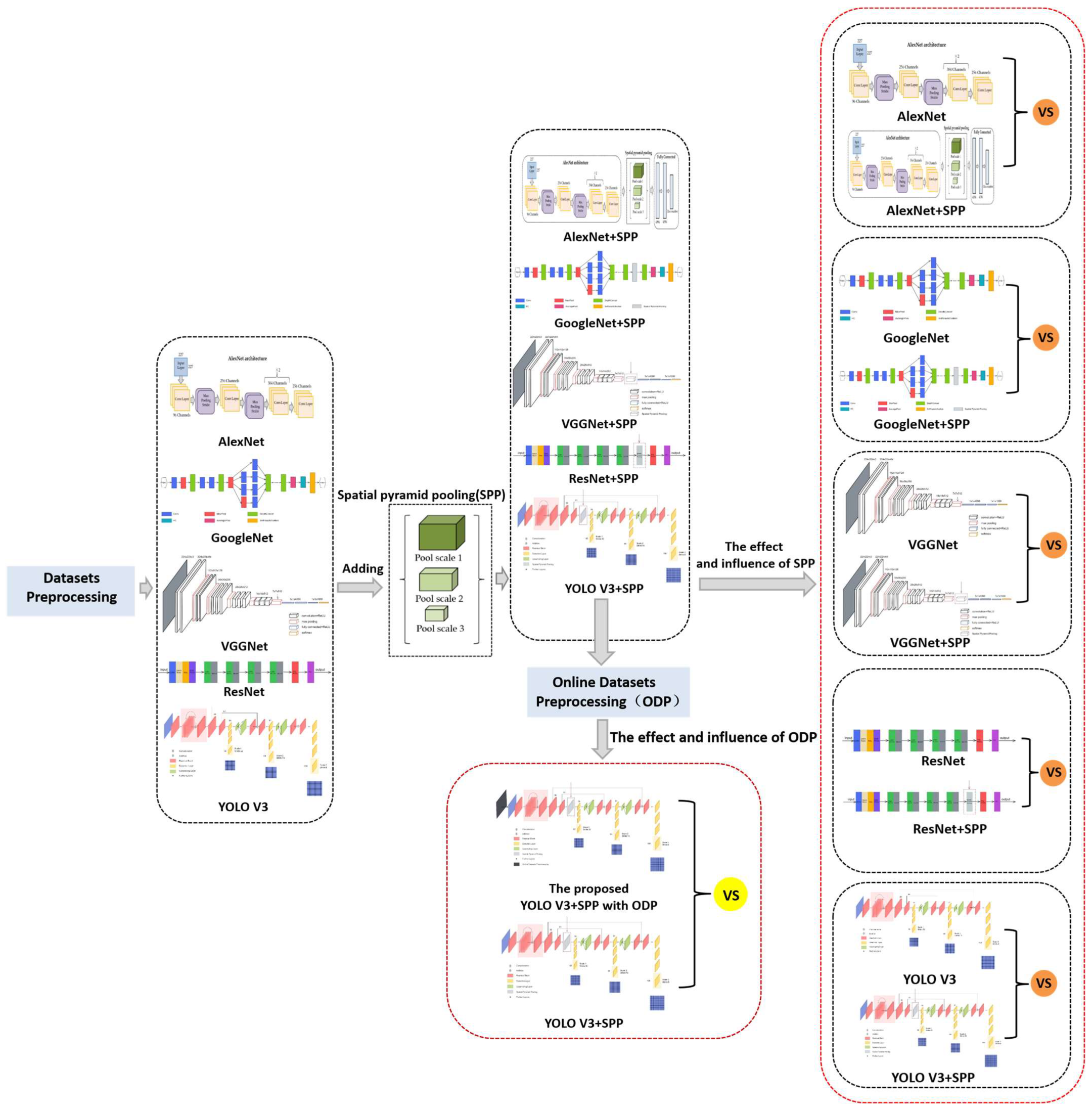
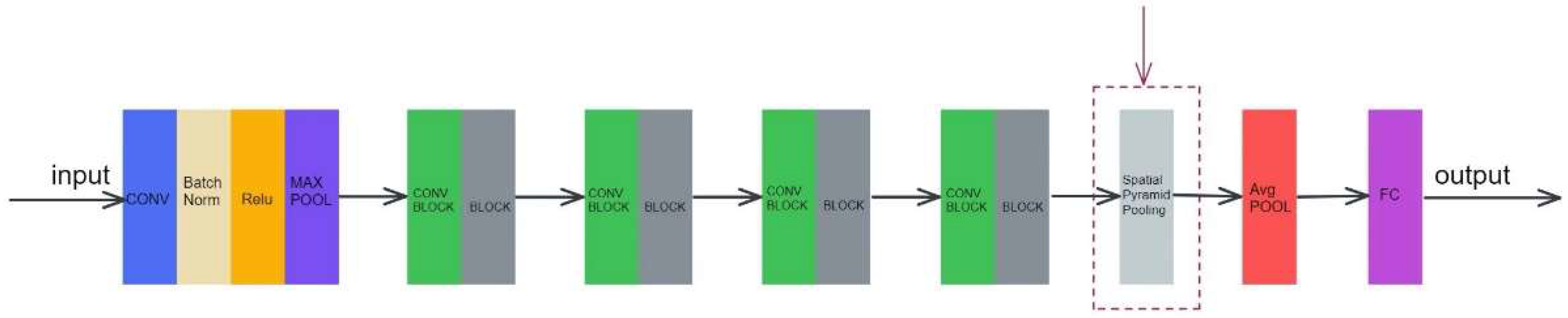
2.1. Improved Neural Networks with Spatial Pyramid Pooling and Online Datasets Preprocessing for Underwater Target Detection
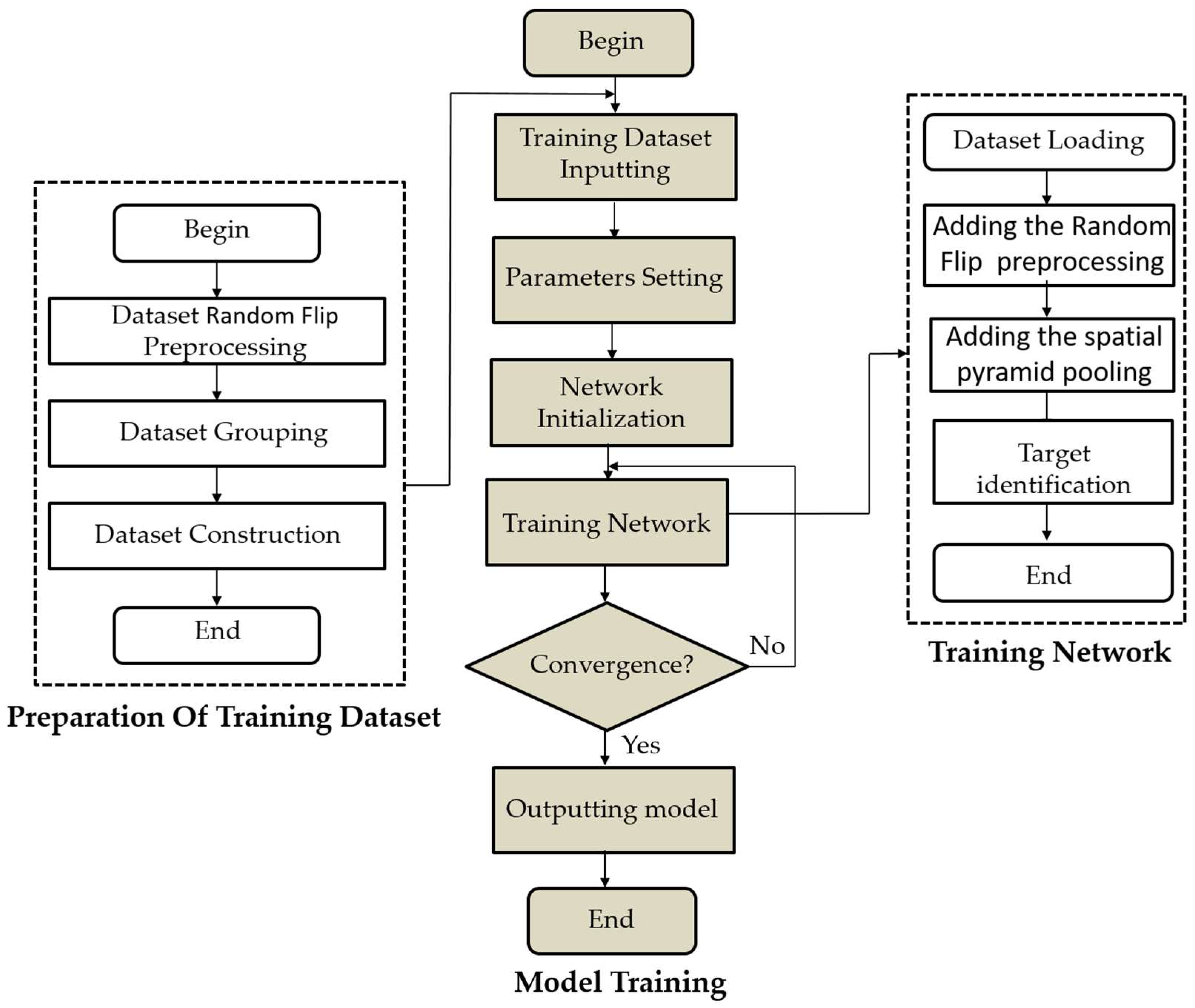
2.2. Datasets Preprocessing
- (1)
- The expanded datasets
- (2)
- Data Augmentation
- (3)
- Partition the datasets
- (4)
- YOLO dataset annotation
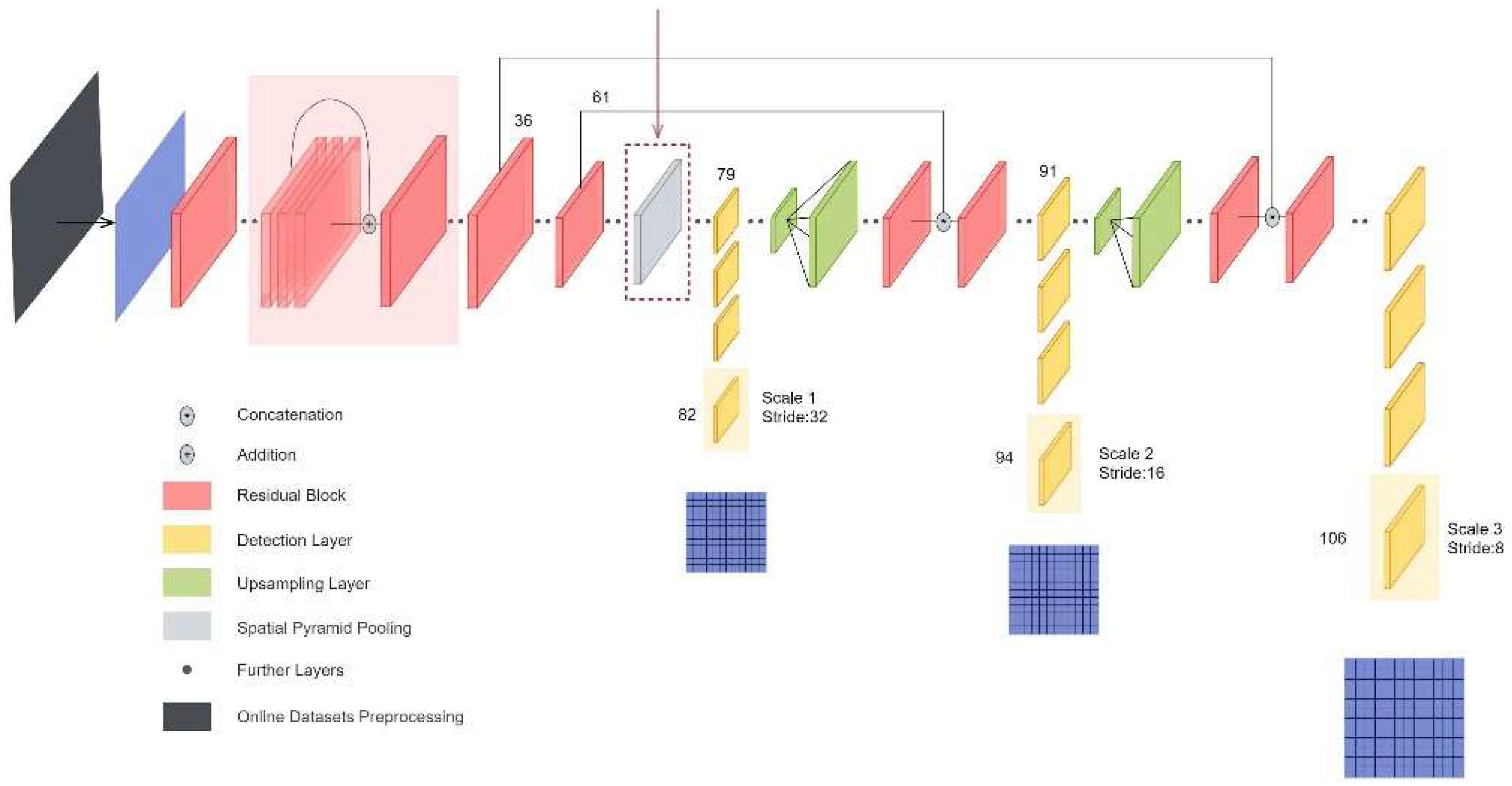
2.3. Using Online Dataset Preprocessing to Improve Target Detection Performance
2.3.1. DataLoader Platform
2.3.2. Random Flip
| Algorithm 1: Random Flip Algorithm |
| Input: All initialized Datasets |
| Based platform: Dataloader |
| Output: Updated Random Flip Datasets Listing 1: Random Flip Process |
| 1: → dataset = create_dataloader |
| 2: → mlc = int(np.concatenate (dataset.labels, 0)[:,0].max()) #max label class |
| 3: → nb = len (train_loader) #number of batches |
| 4: →→ assert mlc < nc Possible class labels are 0-{nc—1} |
| 5: →→ if Rank in [–1,0]: |
| 6: →→→val_loader =create_dataloader 7. →→ if not resume: 8. →→→labels = np.concatenate (datasets.labels, 0) 9. →→→→if plots: 10. →→→→→plot_labels (labels, names, save_dir) End procedure |
2.4. Networks Adopted in the Experiments
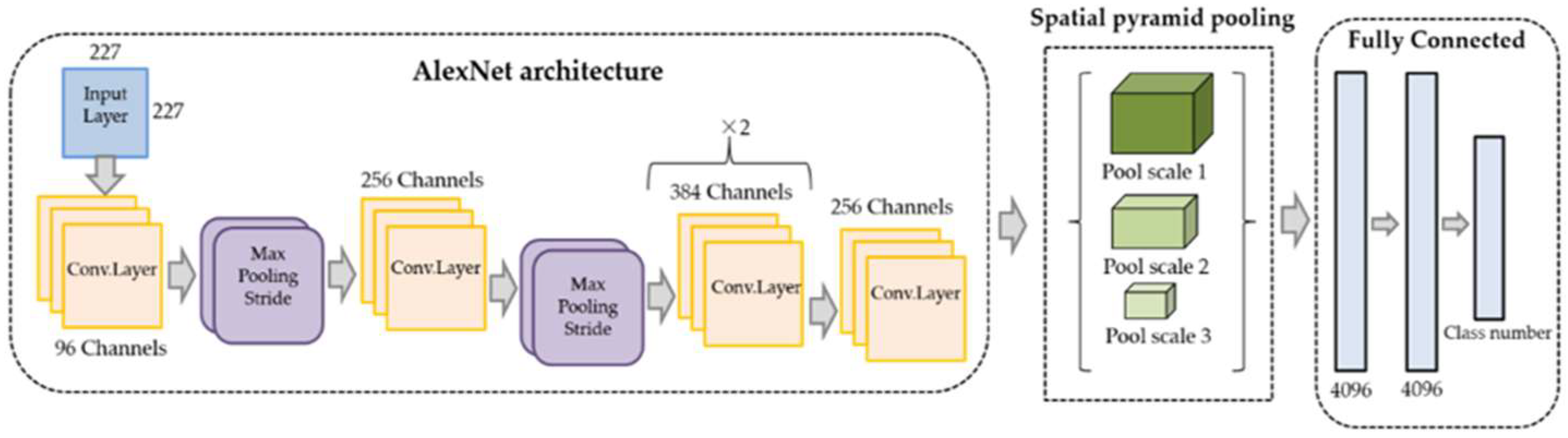
2.4.1. AlexNet
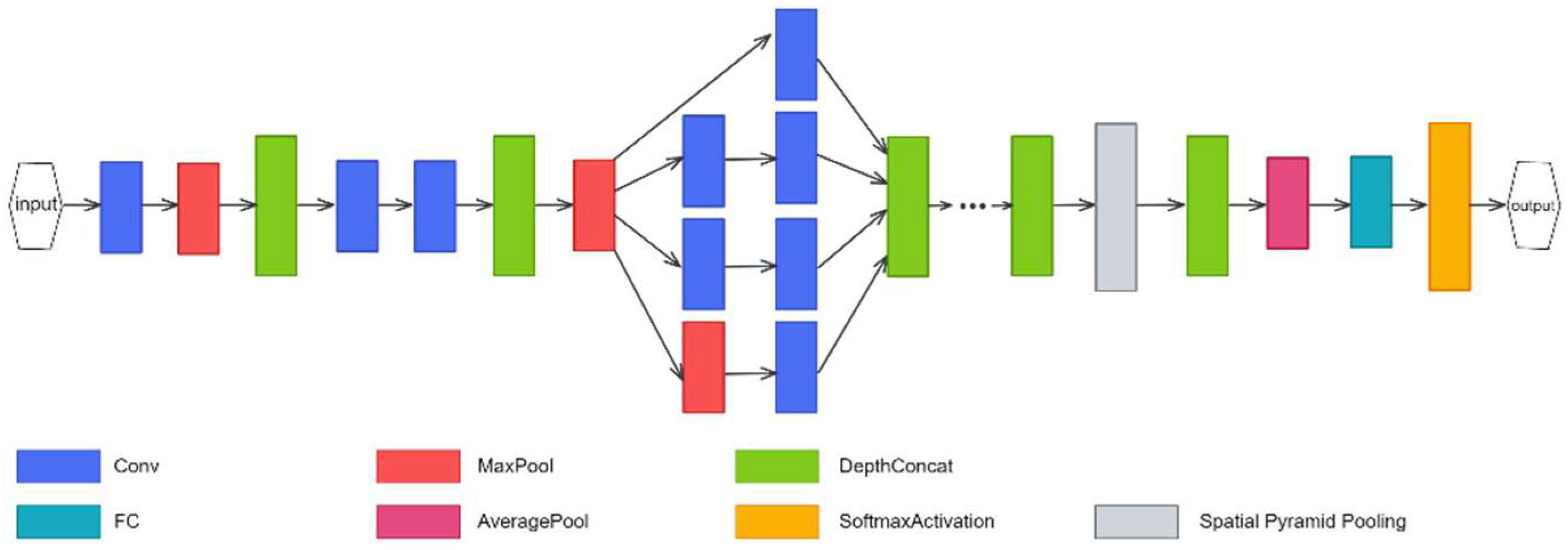
2.4.2. GoogleNet
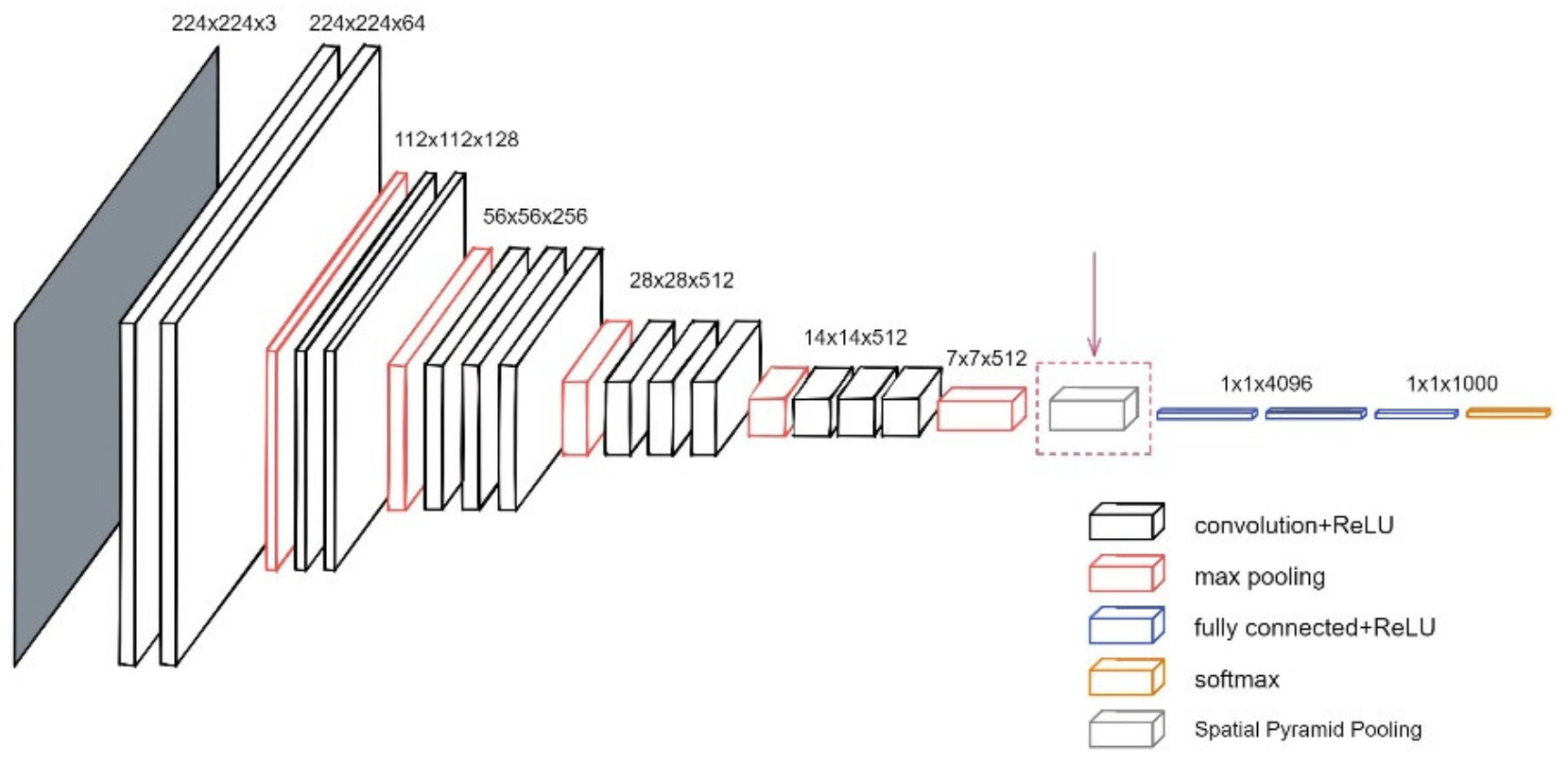
2.4.3. VGGNet
2.4.4. ResNet
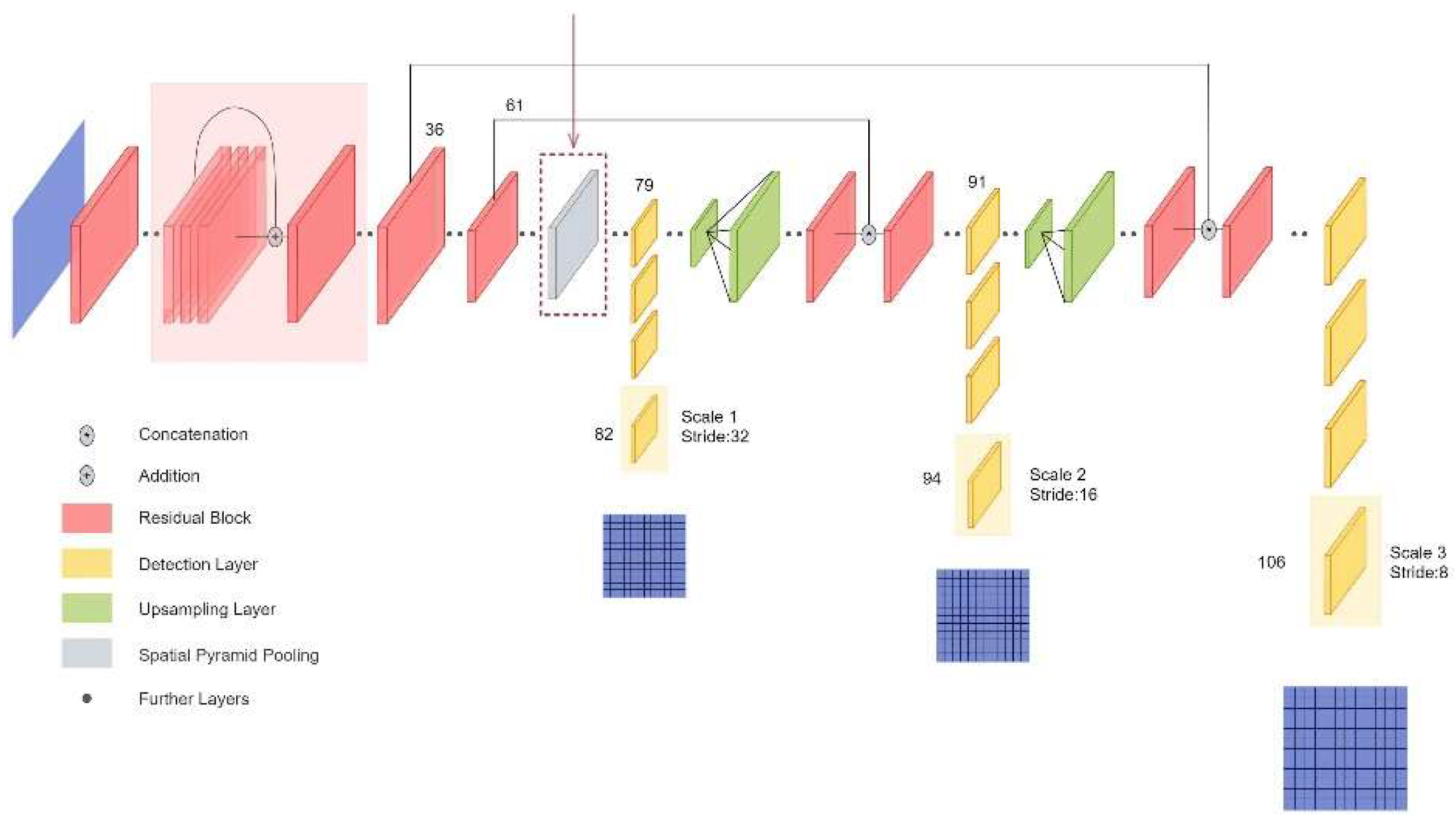
2.4.5. YOLO V3
2.5. Multi-Scale Inputting Based on the Spatial Pyramid Pooling
2.6. Networks with Spatial Pyramid Pooling Adopted Experiments in the Models
2.6.1. AlexNet + SPP
| Algorithm 2: AlexNet + SPP Algorithm |
| Input: SPP algorithm input |
| Based network: AlexNet algorithm |
| Output: AlexNet + SPP algorithm output Listing 2: SPP Process |
| 1: → class SPPLayer (nn.Module): |
| 2: → def __init__(self, num_levels, pool_type = ‘max_pool’): |
| 3: → → super (SPPLayer, self).__init__() |
| 4: → → self.num_levels = num_levels |
| 5: → → → self.pool_type = pool_type |
| End procedure |
2.6.2. GoogleNet + SPP
| Algorithm 3: GoogleNet + SPP Algorithm |
| Input: SPP algorithm input |
| Based network: GoogleNet algorithm |
| Output: GoogleNet + SPP algorithm output Listing 3: SPP Process |
| 1: → class SPPLayer (nn.Module): |
| 2: → def __init__(self, num_levels, pool_type = ‘max_pool’): |
| 3: → → super (SPPLayer, self).__init__() |
| 4: → → self.num_levels = num_levels |
| 5: → → → self.pool_type = pool_type |
| End procedure |
2.6.3. VGGNet + SPP
| Algorithm 4: VGGNet + SPP Algorithm |
| Input: SPP algorithm input |
| Based network: VGGNet algorithm |
| Output: VGGNet + SPP algorithm output Listing 4: SPP Process |
| 1: → class SPPLayer (nn.Module): |
| 2: → def __init__(self, num_levels, pool_type = ‘max_pool’): |
| 3: → → super (SPPLayer, self).__init__() |
| 4: → → self.num_levels = num_levels |
| 5: → → → self.pool_type = pool_type |
| End procedure |
2.6.4. ResNet + SPP
| Algorithm 5: ResNet + SPP Algorithm |
| Input: SPP algorithm input |
| Based network: ResNet algorithm |
| Output: ResNet + SPP algorithm output Listing 5: SPP Process |
| 1: → class SPPLayer (nn.Module): |
| 2: → def __init__(self, num_levels, pool_type = ‘max_pool’): |
| 3: → → super (SPPLayer, self).__init__() |
| 4: → → self.num_levels = num_levels |
| 5: → → → self.pool_type = pool_type |
| 6:return solution |
2.6.5. YOLO V3 + SPP
| Algorithm 6: YOLO V3 + SPP Algorithm |
| Input: SPP algorithm input |
| Based network: YOLO V3 algorithm |
| Output: YOLO V3 Net + SPP algorithm output Listing 6: SPP Process |
| 1: → class SPP (nn.Module): |
| 2: → def __init__(self, c1, c2, k = (5, 9, 13)): |
| 3: → → super ()._init_() |
| 4: → → self.cv1 = Conv (c1, c_, 1, 1) 5: → → self.cv2 = Conv (c_ *(len(k) + 1), c2, 1, 1) |
| 6: → → → self.m = nn.ModuleList ([nn.MaxPool]) |
| End procedure |
2.6.6. Online Dataset Preprocessing with YOLO V3 + SPP
| Algorithm 7: Online Datasets Preprocessing YOLO V3 + SPP Algorithm |
| Input: SPP algorithm input |
| Based network: YOLO V3 algorithm |
| Output: YOLO V3 Net + SPP algorithm output Listing 7: SPP Process |
| 1: → class SPP (nn.Module): |
| 2: → def __init__(self, c1, c2, k = (5, 9, 13)): |
| 3: → → super ()._init_() |
| 4: → → self.cv1 = Conv (c1, c_, 1, 1) 5: → → self.cv2 = Conv (c_ *(len(k) + 1), c2, 1, 1) |
| 6: → → → self.m = nn.ModuleList ([nn.MaxPool]) |
| End procedure |
2.6.7. Performance Comparisons
3. Experiments
3.1. Datasets
3.1.1. Datasets Description
3.1.2. Datasets Preprocessing
3.2. Experimental Preparation
3.2.1. Experimental Condition
3.2.2. Experiment Model Training
3.3. Evaluation Indicators
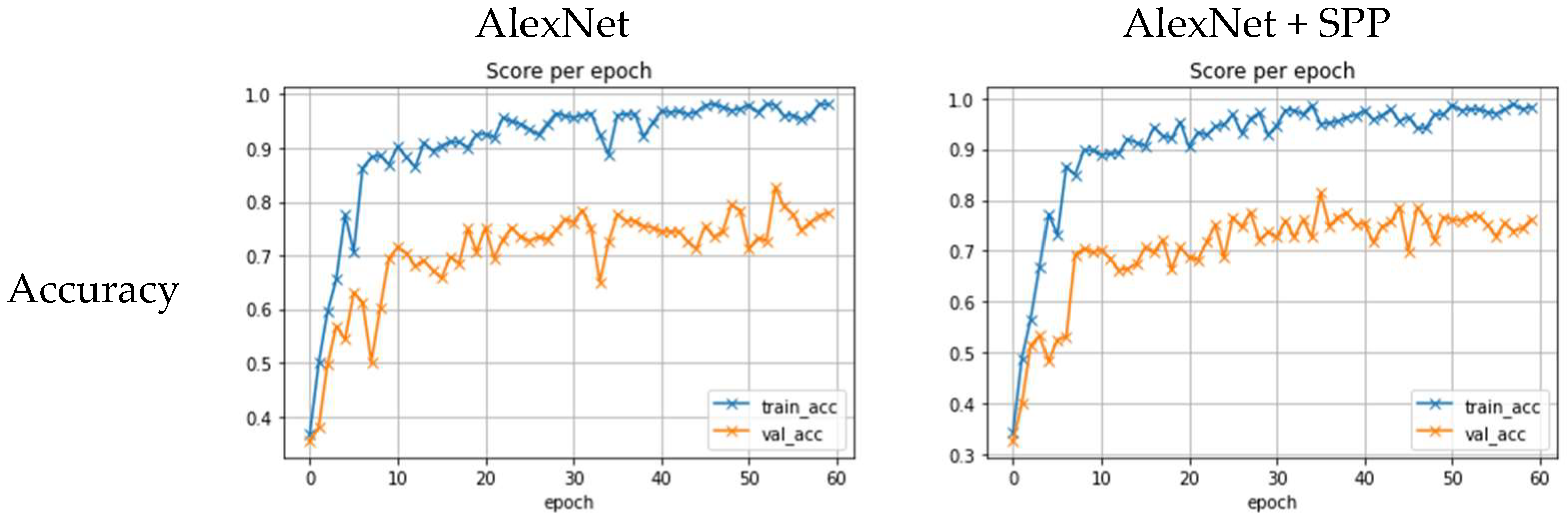
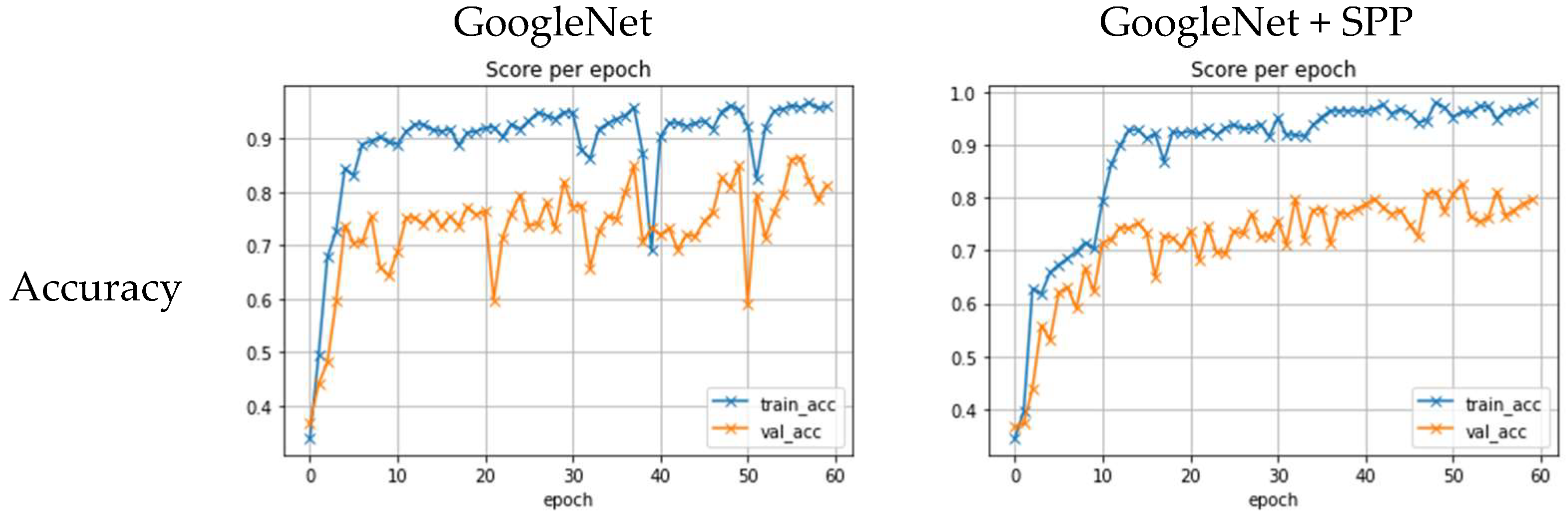
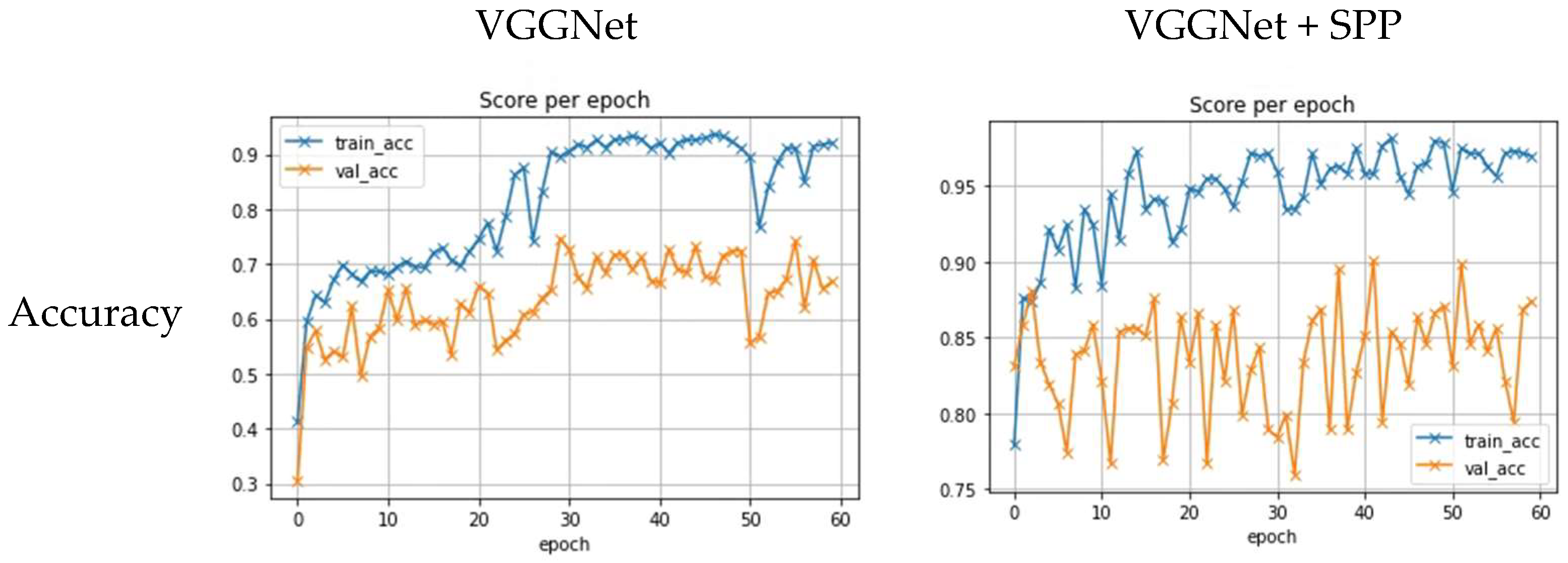
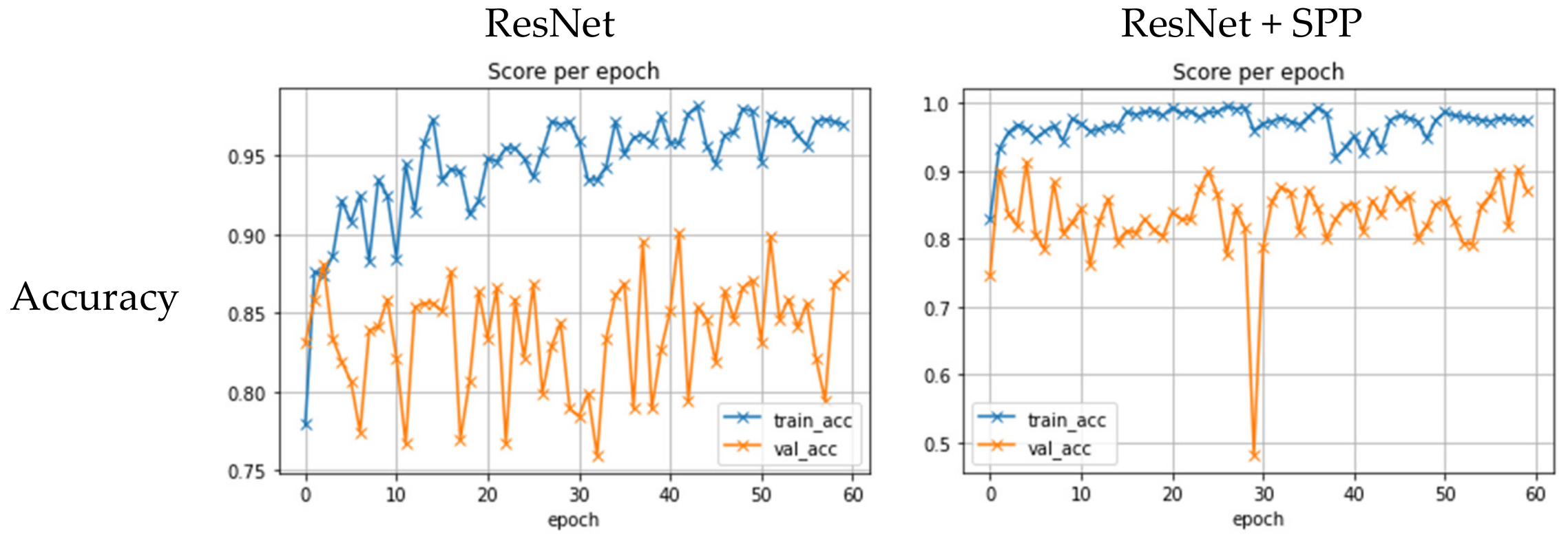
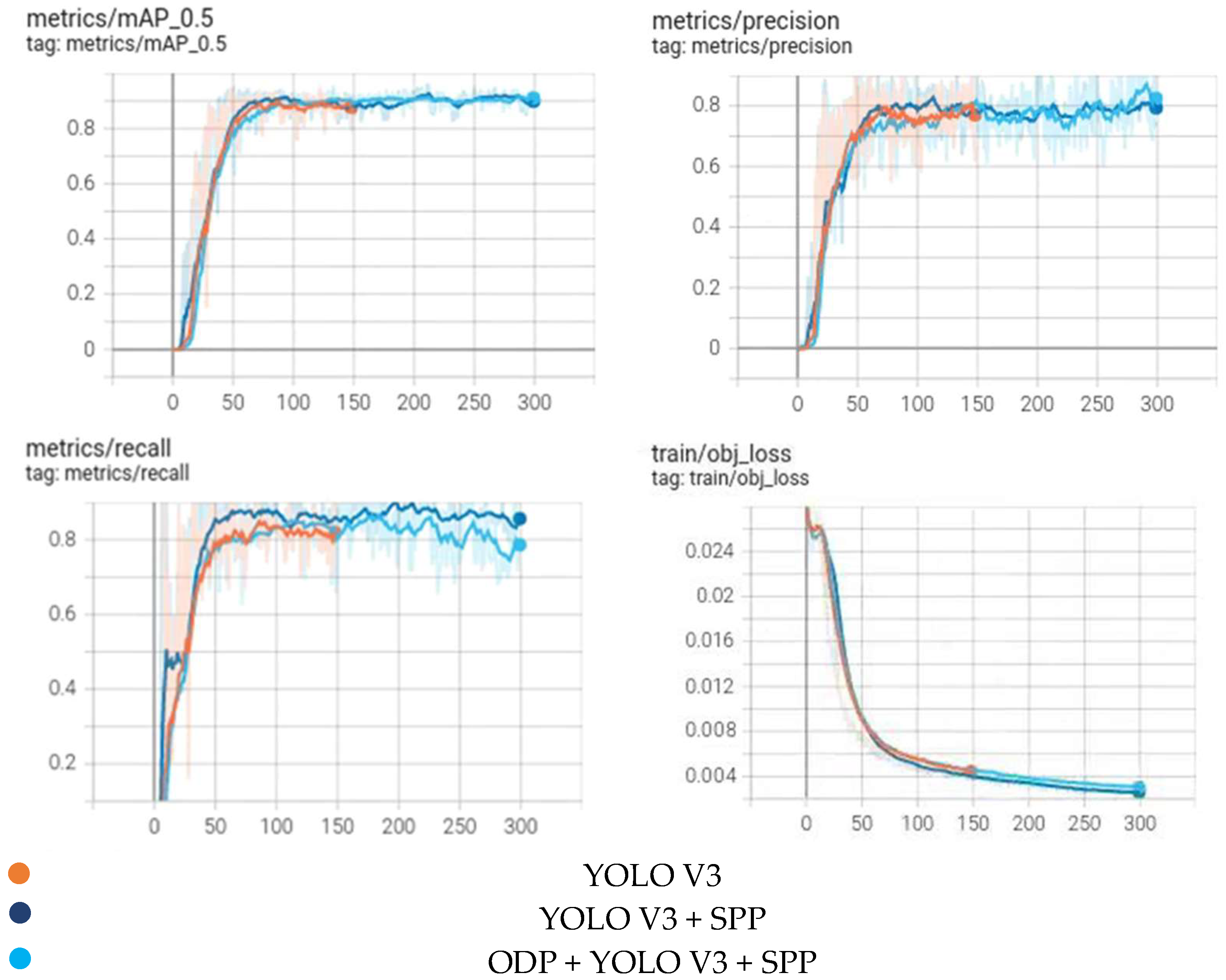
3.4. Experimental Results
3.5. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wei, S.; Ahmad, I.; Zhou, X.; Pan, D.; Li, J.; Su, H. Balance learning for ship detection from synthetic aperture radar remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 182, 190–207. [Google Scholar] [CrossRef]
- Siradjuddin, I.A.; Muntasa, A. Faster Region-based Convolutional Neural Network for Mask Face Detection. In Proceedings of the 2021 5th International Conference on Informatics and Computational Sciences (ICICoS), Semarang, Indonesia, 24–25 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 282–286. [Google Scholar]
- Zhang, T.; Zhang, X.; Ke, X. Quad-FPN: A novel quad feature pyramid network for SAR ship detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. HTC+ for SAR Ship Instance Segmentation. Remote Sens. 2022, 14, 2395. [Google Scholar] [CrossRef]
- Bara, M.; Sagues, L.; Paniagua, F.; Broquetas, A.; Fàbregas, X. High-speed focusing algorithm for circular synthetic aperture radar (C-SAR). Electron. Lett. 2000, 36, 1. [Google Scholar] [CrossRef]
- Zhu, M.; Hu, G.; Zhou, H.; Wang, S. H2Det: A high-speed and high-accurate ship detector in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12455–12466. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. HyperLi-Net: A hyper-light deep learning network for high-accurate and high-speed ship detection from synthetic aperture radar imagery. ISPRS J. Photogramm. Remote Sens. 2020, 167, 123–153. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S.; Wang, J.; Li, J.; Su, H.; Zhou, Y. Balance scene learning mechanism for offshore and inshore ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Shang, X.; Zhao, J.; Zhang, H. Automatic overlapping area determination and segmentation for multiple side scan sonar images mosaic. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2886–2900. [Google Scholar] [CrossRef]
- Qin, X.; Luo, X.; Wu, Z.; Shang, J. Optimizing the sediment classification of small side-scan sonar images based on deep learning. IEEE Access 2021, 9, 29416–29428. [Google Scholar] [CrossRef]
- Zhu, M.; Song, Y.; Guo, J.; Feng, C.; Li, G.; Yan, T.; He, B. PCA and kernel-based extreme learning machine for side-scan sonar image classification. In Proceedings of the 2017 IEEE Underwater Technology (UT), Busan, Republic of Korea, 21–24 February 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Fallon, M.F.; Kaess, M.; Johannsson, H.; Leonard, J.J. Efficient AUV navigation fusing acoustic ranging and side-scan sonar. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2398–2405. [Google Scholar]
- Wu, Z.; Yang, F.; Tang, Y. Side-scan sonar and sub-bottom profiler surveying. In High-Resolution Seafloor Survey and Applications; Springer: Singapore, 2021; pp. 95–122. [Google Scholar]
- Al-Qatf, M.; Lasheng, Y.; Al-Habib, M.; Yu, L. Deep Learning Approach Combining Sparse Autoencoder With SVM for Network Intrusion Detection. IEEE Access 2018, 6, 52843–52856. [Google Scholar] [CrossRef]
- Bertasius, G.; Shi, J.; Torresani, L. Deepedge: A multi-scale bifurcated deep network for top-down contour detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4380–4389. [Google Scholar]
- Wang, Y.; Sun, Y.; Lv, P.; Wang, H. Detection of line weld defects based on multiple thresholds and support vector machine. NDT E Int. 2008, 41, 517–524. [Google Scholar] [CrossRef]
- Gong, M.; Su, L.; Jia, M.; Chen, W. Fuzzy clustering with a modified MRF energy function for change detection in synthetic aperture radar images. IEEE Trans. Fuzzy Syst. 2013, 22, 98–109. [Google Scholar] [CrossRef]
- Dzieciuch, I.; Gebhardt, D.; Barngrover, C.; Parikh, K. Non-Linear Convolutional Neural Network for Automatic Detection of Mine-Like Objects in Sonar Imagery. In Proceedings of the International Conference on Applications in Nonlinear Dynamics, Rome, Italy, 21–25 May 2017; Springer: Cham, Switzerland, 2017; pp. 309–314. [Google Scholar]
- Rhinelander, J. Feature extraction and target classification of side-scan sonar images. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016. [Google Scholar]
- Song, Y.; Zhu, Y.; Li, G.; Feng, C.; He, B.; Yan, T. Side scan sonar segmentation using deep convolutional neural network. In Proceedings of the OCEANS 2017-Anchorage, Anchorage, AK, USA, 18–21 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Zhu, P.; Isaacs, J.; Fu, B.; Ferrari, S. Deep learning feature extraction for target recognition and classification in underwater sonar images. In Proceedings of the 2017 IEEE 56th Annual Conference on Decision and Control (CDC), Melbourne, Australia, 12–15 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2724–2731. [Google Scholar]
- Einsidler, D.; Dhanak, M.; Beaujean, P.P. A deep learning approach to target recognition in side scan sonar imagery. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Kim, J.; Choi, J.W.; Kwon, H.; Oh, R.; Son, S. The application of convolutional neural networks for automatic detection of underwater object in side scan sonar images. J. Acoust. Soc. Korea 2018, 37, 118–128. [Google Scholar]
- Wu, M.; Wang, Q.; Rigall, E.; Li, K.; Zhu, W.; He, B. ECNet: Efficient convolutional networks for side scan sonar image segmentation. Sensors 2019, 19, 2009. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.; Wu, M.; Yu, F.; Feng, C.; Li, K.; Zhu, Y.; Rigall, E.; He, B. Rt-seg: A real-time semantic segmentation network for side scan sonar images. Sensors 2019, 19, 1985. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, F.; He, B.; Li, K.; Yan, T.; Shen, Y.; Wang, Q.; Wu, M. Side scan sonar images segmentation for AUV with recurrent residual convolutional neural network module and self-guidance module. Appl. Ocean Res. 2021, 113, 102608. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, J.; Yu, S.; Wang, K.; Han, Z.; Tang, Y. Underwater Object Detection based on YOLO-v3 network. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 15–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 571–575. [Google Scholar]
- Li, J.W.; Cao, X. Target Recognition and Detection in Side scan Sonar Images based on YOLO v3 Model. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 7186–7190. [Google Scholar]
- Jin, S.; Zhang, N.; Bian, G.; Cui, Y. A seabed sediment classification model based on PSO-AlexNet. In Proceedings of the 2nd International Conference on Signal Image Processing and Communication (ICSIPC 2022), Qingdao, China, 20–22 May 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12246, pp. 349–361. [Google Scholar]
- Jia, X.; Wei, X.; Cao, X.; Foroosh, H. Comdefend: An efficient image compression model to defend adversarial examples. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6084–6092. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 677–694. [Google Scholar]
- Sahin, F.E.; Tanguay, A.R. Distortion optimization for wide-angle computational cameras. Optics Express 2018, 26, 5478–5487. [Google Scholar] [CrossRef]
- Zhang, X.; Karaman, S.; Chang, S.F. Detecting and simulating artifacts in gan fake images. In Proceedings of the 2019 IEEE International Workshop on Information Forensics and Security (WIFS), Delft, The Netherlands, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef]
- Zhang, W.; Ma, K.; Yan, J.; Deng, D.; Wang, Z. Blind image quality assessment using a deep bilinear convolutional neural network. IEEE Trans. Circuits Syst. Video Technol. 2018, 30, 36–47. [Google Scholar] [CrossRef] [Green Version]
- Canziani, A.; Paszke, A.; Culurciello, E. An analysis of deep neural network models for practical applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Zhou, Z.; Cui, Z.; Zang, Z.; Meng, X.; Cao, Z.; Yang, J. UltraHi-PrNet: An Ultra-High Precision Deep Learning Network for Dense Multi-Scale Target Detection in SAR Images. Remote Sens. 2022, 14, 5596. [Google Scholar] [CrossRef]
- Han, B.; Hu, Z.; Su, Z.; Bai, X.; Yin, S.; Luo, J.; Zhao, Y. Mask_LaC R-CNN for measuring morphological features of fish. Measurement 2022, 203, 111859. [Google Scholar] [CrossRef]
- Wang, H.; Shi, Y.; Yue, Y.; Zhao, H. Study on freshwater fish image recognition integrating SPP and DenseNet network. In Proceedings of the 2020 IEEE International Conference on Mechatronics and Automation (ICMA), Osaka, Japan, 24–26 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 564–569. [Google Scholar]
- Guo, H.; Gao, H.; Guo, C.; Lu, J.; Lin, Y. Dock detection method in remote sensing images based on improved YOLOv4. In Proceedings of the Fourteenth International Conference on Digital Image Processing (ICDIP 2022), Wuhan, China, 20–23 May 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12342, pp. 105–112. [Google Scholar]
- Han, Q.; Yin, Q.; Zheng, X.; Chen, Z. Remote sensing image building detection method based on Mask R-CNN. Complex Intell. Syst. 2022, 8, 1847–1855. [Google Scholar] [CrossRef]
- Le, Y.; Yang, X. Tiny imagenet visual recognition challenge. CS 231n 2015, 7, 3. [Google Scholar]
- Li, Y.; Zhang, X.; Shen, Z. YOLO-Submarine Cable: An Improved YOLO-V3 Network for Object Detection on Submarine Cable Images. J. Mar. Sci. Eng. 2022, 10, 1143. [Google Scholar] [CrossRef]
- Ju, M.; Luo, H.; Wang, Z.; Hui, B.; Chang, Z. The application of improved YOLO V3 in multi-scale target detection. Appl. Sci. 2019, 9, 3775. [Google Scholar] [CrossRef] [Green Version]
- Xu, D.; Wu, Y. Improved YOLO-V3 with DenseNet for multi-scale remote sensing target detection. Sensors 2020, 20, 4276. [Google Scholar] [CrossRef] [PubMed]
- Karathanassi, V.; Kolokousis, P.; Ioannidou, S. A comparison study on fusion methods using evaluation indicators. Int. J. Remote Sens. 2007, 28, 2309–2341. [Google Scholar] [CrossRef]
- Shang, R.; Wang, J.; Jiao, L.; Rustam, S.; Hou, B.; Li, Y. SAR targets classification based on deep memory convolution neural networks and transfer parameters. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2834–2846. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-scale interactive network for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9413–9422. [Google Scholar]
- Sriram, S.; Vinayakumar, R.; Sowmya, V.; Aamoun, A.; Soman, K. Multi-scale learning based malware variant detection using spatial pyramid pooling network. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 740–745. [Google Scholar]
- Li, S.; Yuan, S.; Liu, S.; Wen, J.; Huang, Q.; Zhang, Z. Characteristics of Low-Frequency Acoustic Wave Propagation in Ice-Covered Shallow Water Environment. Appl. Sci. 2021, 11, 7815. [Google Scholar] [CrossRef]
- Sebens, K.P.; Witting, J.; Helmuth, B. Effects of water flow and branch spacing on particle capture by the reef coral Madracis mirabilis (Duchassaing and Michelotti). J. Exp. Mar. Biol. Ecol. 1997, 211, 1–28. [Google Scholar] [CrossRef]
- Wang, X.; Wang, L.; Li, G.; Xie, X. A Robust and Fast Method for Sidescan Sonar Image Segmentation Based on Region Growing. Sensors 2021, 21, 6960. [Google Scholar] [CrossRef] [PubMed]
- Ying, X. An overview of overfitting and its solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Pecorelli, F.; Di Nucci, D.; De Roover, C.; De Lucia, A. A large empirical assessment of the role of data balancing in machine-learning-based code smell detection. J. Syst. Softw. 2020, 169, 110693. [Google Scholar] [CrossRef]
- Osetsky, Y.; Barashev, A.V.; Zhang, Y. Sluggish, chemical bias and percolation phenomena in atomic transport by vacancy and interstitial diffusion in NiFe alloys. Curr. Opin. Solid State Mater. Sci. 2021, 25, 100961. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Chintala, S. Pytorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2019; Volume 32. [Google Scholar]
- Moura, P.; Crocker, P.; Nunes, P. High-level multi-threading programming in logtalk. In Proceedings of the International Symposium on Practical Aspects of Declarative Languages, San Francisco, CA, USA, 7–8 January 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 265–281. [Google Scholar]
- He, K.; Girshick, R.; Dollár, P. Rethinking imagenet pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4918–4927. [Google Scholar]
- Jaikrishnan, S.V.J.; Chantarakasemchit, O.; Meesad, P. A breakup machine learning approach for breast cancer prediction. In Proceedings of the 2019 11th International Conference on Information Technology and Electrical Engineering (ICITEE), Pattaya, Thailand, 10–11 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Chu, H.; Xiong, X.; Gao, Y.J.; Luo, J.; Jing, H. Diffuse reflection and reciprocity-protected transmission via a random-flip metasurface. Sci. Adv. 2021, 7, eabj0935. [Google Scholar] [CrossRef]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: A backbone network for object detection. arXiv 2018, arXiv:1804.06215. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Wang, Z.J.; Turko, R.; Shaikh, O.; Park, H.; Das, N. CNN explainer: Learning convolutional neural networks with interactive visualization. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1396–1406. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Zhang, T.; Zhang, X.; Ke, X.; Liu, C.; Xu, X. HOG-ShipCLSNet: A novel deep learning network with hog feature fusion for SAR ship classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–22. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H. Ship classification in high-resolution SAR images using deep learning of small datasets. Sensors 2018, 18, 2929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nguyen, D.P.T.; Matsuo, Y.; Ishizuka, M. Exploiting syntactic and semantic information for relation extraction from wikipedia. In Proceedings of the IJCAI Workshop on Text-Mining & Link-Analysis (TextLink 2007), Hyderabad, India, 6–12 January 2007. [Google Scholar]
- Sacramento, J.; Ponte Costa, R.; Bengio, Y.; Senn, W. Dendritic cortical microcircuits approximate the backpropagation algorithm. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2018; Volume 31. [Google Scholar]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Asari, V.K. The history began from alexnet: A comprehensive survey on deep learning approaches. arXiv 2018, arXiv:1803.01164. [Google Scholar]
- Alippi, C.; Disabato, S.; Roveri, M. Moving convolutional neural networks to embedded systems: The alexnet and VGG-16 case. In Proceedings of the 2018 17th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Porto, Portugal, 11–13 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 212–223. [Google Scholar]
- Yuan, Z.W.; Zhang, J. Feature extraction and image retrieval based on AlexNet. In Proceedings of the Eighth International Conference on Digital Image Processing (ICDIP 2016), Chengu, China, 20–22 May 2016; SPIE: Bellingham, WA, USA, 2016; Volume 10033, pp. 65–69. [Google Scholar]
- Ballester, P.; Araujo, R.M. On the performance of GoogLeNet and AlexNet applied to sketches. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Anand, R.; Shanthi, T.; Nithish, M.S.; Lakshman, S. Face recognition and classification using GoogleNET architecture. In Soft Computing for Problem Solving; Springer: Singapore, 2020; pp. 261–269. [Google Scholar]
- Salavati, P.; Mohammadi, H.M. Obstacle detection using GoogleNet. In Proceedings of the 2018 8th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 25–26 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 326–332. [Google Scholar]
- Muhammad, U.; Wang, W.; Chattha, S.P.; Ali, S. Pre-trained VGGNet architecture for remote-sensing image scene classification. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1622–1627. [Google Scholar]
- Sathish, K.; Ramasubbareddy, S.; Govinda, K. Detection and localization of multiple objects using VGGNet and single shot detection. In Emerging Research in Data Engineering Systems and Computer Communications; Springer: Singapore, 2020; pp. 427–439. [Google Scholar]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the ResNet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Jiao, J.; Han, Y.; Weissman, T. Demystifying ResNet. arXiv 2016, arXiv:1611.01186. [Google Scholar]
- Chen, Z.; Xie, Z.; Zhang, W.; Xu, X. ResNet and Model Fusion for Automatic Spoofing Detection. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 102–106. [Google Scholar]
- Khan, R.U.; Zhang, X.; Kumar, R.; Aboagye, E.O.; Kumar, R. Evaluating the performance of ResNet model based on image recognition. In Proceedings of the 2018 International Conference on Computing and Artificial Intelligence, Chengdu, China, 12–14 March 2018; pp. 86–90. [Google Scholar]
- He, F.; Liu, T.; Tao, D. Why ResNet works? Residuals generalize. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5349–5362. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhao, L.; Li, S. Object detection algorithm based on improved YOLOV3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef] [Green Version]
- Won, J.H.; Lee, D.H.; Lee, K.M.; Lin, C.H. An improved YOLOv3-based neural network for de-identification technology. In Proceedings of the 2019 34th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Jeju, Republic of Korea, 23–26 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–2. [Google Scholar]
- Lang, P.; Fu, X.; Martorella, M.; Dong, J.; Xie, M. A comprehensive survey of machine learning applied to radar signal processing. arXiv 2020, arXiv:2009.13702. [Google Scholar]
- Lee, Y.H.; Kim, Y. Comparison of CNN and YOLO for Object Detection. J. Semicond. Disp. Technol. 2020, 19, 85–92. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Yue, J.; Mao, S.; Li, M. A deep learning framework for hyperspectral image classification using spatial pyramid pooling. Remote Sens. Lett. 2016, 7, 875–884. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Wang, R. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gross, L.; Li, Z.; Li, X.; Qi, W. Automatic building extraction on high-resolution remote sensing imagery using deep convolutional encoder-decoder with spatial pyramid pooling. IEEE Access 2019, 7, 128774–128786. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, W.; Zhao, Y.; Xie, H. An improved YOLOv3 model based on skipping connections and spatial pyramid pooling. Syst. Sci. Control Eng. 2021, 9 (Suppl. 1), 142–149. [Google Scholar] [CrossRef]
- Xu, F.; Wang, H.; Sun, X.; Fu, X. Refined marine object detector with attention-based spatial pyramid pooling networks and bidirectional feature fusion strategy. Neural Comput. Appl. 2022, 34, 14881–14894. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Class | Sunken Ship | Fish Flock | Seafloor Topography |
|---|---|---|---|
| Image Quantity | 250 | 250 | 250 |
| Networks | Testing Time Used (Mins) | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| AlexNet | 5.10 | 0.76 | 0.79 | 0.74 | 0.71 |
| AlexNet + SPP | 4.27 | 0.78 | 0.80 | 0.73 | 0.74 |
| GoogleNet | 5.81 | 0.71 | 0.71 | 0.82 | 0.76 |
| GoogleNet + SPP | 3.64 | 0.75 | 0.75 | 0.73 | 0.78 |
| VGGNet | 14.34 | 0.84 | 0.81 | 0.97 | 0.88 |
| VGGNet + SPP | 8.25 | 0.86 | 0.89 | 0.86 | 0.89 |
| ResNet | 4.39 | 0.87 | 0.89 | 0.87 | 0.87 |
| ResNet + SPP | 4.18 | 0.89 | 0.91 | 0.86 | 0.88 |
| Networks | Testing Time Used (Hours) | mAP | Precision | Recall |
|---|---|---|---|---|
| YOLO V3 | 1.17 | 0.89 | 0.78 | 0.8 |
| YOLO V3 + SPP | 1.09 | 0.91 | 0.89 | 0.88 |
| The proposed ODP + YOLO V3 + SPP | 1.07 | 0.95 | 0.91 | 0.83 |
| Target Classes | mAP | Precision | Recall |
|---|---|---|---|
| All | 0.95 | 0.9 | 0.83 |
| Sunken ship | 0.98 | 0.89 | 0.88 |
| Fish flock | 0.91 | 0.98 | 0.77 |
| Seafloor topography | 0.96 | 0.82 | 0.84 |
| Methods | The Overall Detection Time for All Images | The Average Detection Time for Each Image |
|---|---|---|
| Google + SPP | 218.25 | 0.97 |
| The Proposed ODP + YOLO V3 + SPP | 128.25 | 0.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Chen, L.; Shen, J.; Xiao, X.; Liu, X.; Sun, X.; Wang, X.; Li, D. Improved Neural Network with Spatial Pyramid Pooling and Online Datasets Preprocessing for Underwater Target Detection Based on Side Scan Sonar Imagery. Remote Sens. 2023, 15, 440. https://0-doi-org.brum.beds.ac.uk/10.3390/rs15020440
Li J, Chen L, Shen J, Xiao X, Liu X, Sun X, Wang X, Li D. Improved Neural Network with Spatial Pyramid Pooling and Online Datasets Preprocessing for Underwater Target Detection Based on Side Scan Sonar Imagery. Remote Sensing. 2023; 15(2):440. https://0-doi-org.brum.beds.ac.uk/10.3390/rs15020440
Chicago/Turabian StyleLi, Jinrui, Libin Chen, Jian Shen, Xiongwu Xiao, Xiaosong Liu, Xin Sun, Xiao Wang, and Deren Li. 2023. "Improved Neural Network with Spatial Pyramid Pooling and Online Datasets Preprocessing for Underwater Target Detection Based on Side Scan Sonar Imagery" Remote Sensing 15, no. 2: 440. https://0-doi-org.brum.beds.ac.uk/10.3390/rs15020440