1. Introduction
Drones have attracted much attention recently due to their rapid and cost-effective deployment [
1]. Drone-view object detection (DroneDet) aims to locate and classify objects in images captured by drones, which is one of the most crucial algorithms deployed on drones for environmental perception. Recently, a few object detectors for DroneDet [
2,
3,
4] have been proposed to boost detection performance. Their detection accuracy decreases enormously in rainy weather, which is one of the most common weather conditions, although they have achieved impressive performance in favorable weather conditions.
Rain contains countless rain streaks, which have different density levels. These rain streaks block some of the light reflected by objects, thus decreasing the contrast between objects and the background in an image. A widely used rain model is the additive composite model [
5,
6], which is written as follows:
where
r is an image degraded by rain streaks,
c is the corresponding rain-free and clean image, and
s denotes rain streaks, which can be viewed as additive noise. The noise
s degrades features extracted for DroneDet in rainy weather conditions, resulting in poor detection performance.
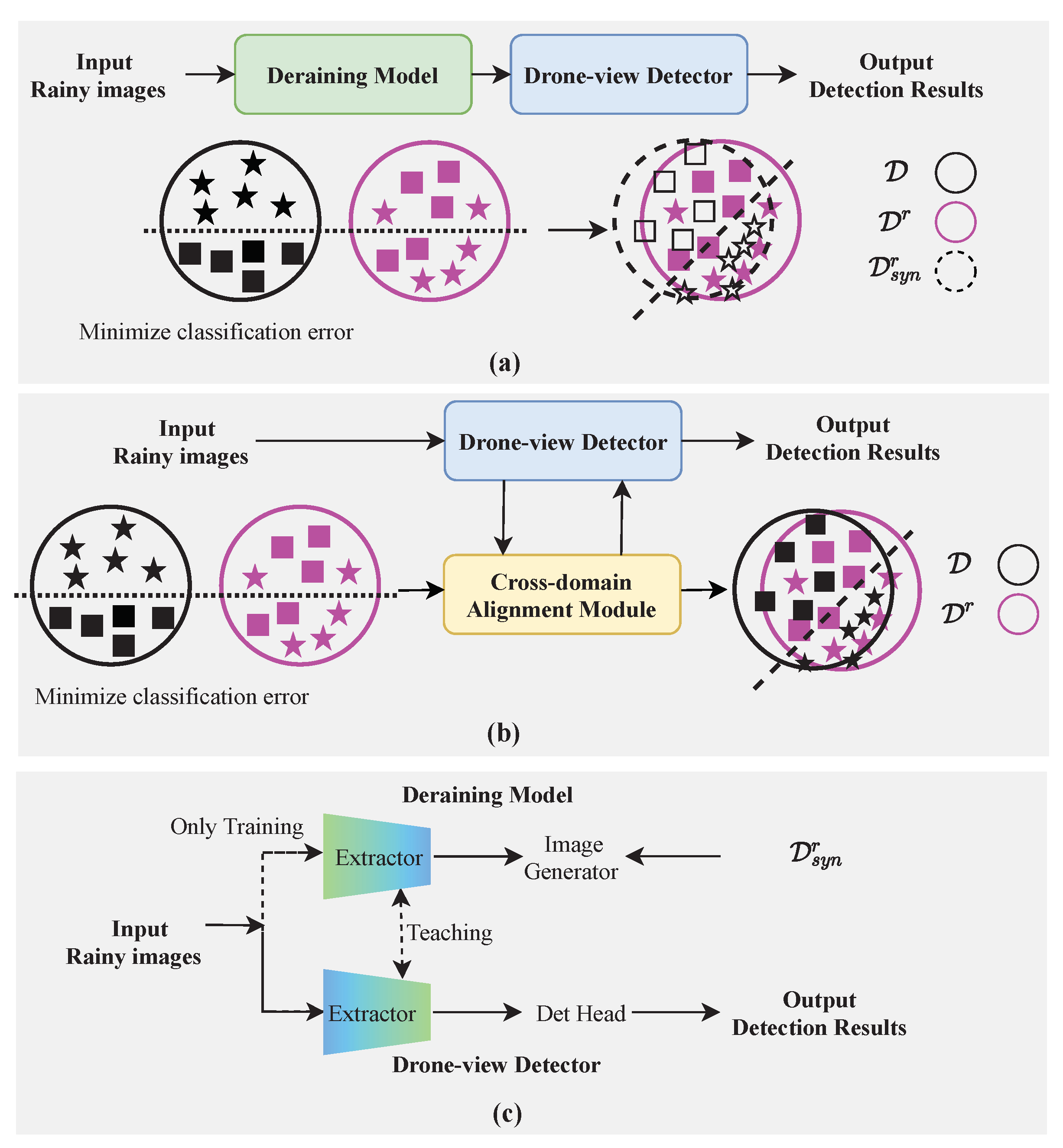
We explain the reasons for the poor detection performance from a probabilistic perspective. First, we define some notations for further analysis. Denote a rain-free (source) domain as
(indicated as the black circles in
Figure 1).
consists of clean images collected under favorable weather conditions, where
is a feature space,
is a marginal probability distribution, and
. Denote a rainy (target) domain as
(indicated as the pink circles in
Figure 1).
consists of degraded images collected under rainy weather conditions, where
is another feature space,
is a marginal probability distribution, and
. Let the task of drone-view object detection under rainy weather conditions (Rainy DroneDet) be
, where
is a feature space,
is a conditional probability distribution, and
. When a detector that is well trained in
is utilized to perform DroneDet in
, the detection performance will decrease significantly since
.
Two types of solutions for the Rainy DroneDet are Image Deraining-based methods (“ImDerain-based”, as illustrated in
Figure 1a) and Domain Adaptation-based methods (“DA-based”, as illustrated in
Figure 1b). The ImDerain-based methods [
7,
8,
9] generally consist of two stages: image deraining and object detection. However, they adopt a multi-stage and progressively deraining model [
10] to obtain rain-free images, resulting in huge computation costs. Deploying these ImDerain-based methods on drones is infeasible due to the very limited onboard computing resources.
Essentially, these ImDerain-based methods attempt to build a synthetic rainy domain to mitigate the domain gap between
, as shown in
Figure 1a. Let the synthetic rainy domain be
, where
is another feature space, and
is a marginal probability distribution,
, and
is synthesized by the combination of
c and synthetic rain streaks
. However, Wei et al. [
11] reported that there was a large difference between
, such as the direction and density of rain streaks. Instead of building
, DA-based methods, [
12,
13,
14] design a cross-domain alignment module to directly align the two feature spaces,
, as shown in
Figure 1b. The DA-based methods investigate cross-domain knowledge from a probabilistic perspective, but neglect intrinsic knowledge in the image degradation from
.
In this paper, we mitigate the two issues and propose a light image degradation knowledge-transferring network for Rainy DroneDet, called “CoDerainNet”, which is a
Collaborative
Deraining
Network. As shown in
Figure 1c, our CoDerainNet includes the Deraining Subnetwork, DroneDet Subnetwork, and a Collaborative Teaching paradigm. CoDerainNet can interactively train the Deraining Subnetwork and DroneDet Subnetwork to improve the Rainy DroneDet performance with limited additional computational cost during inference. Furthermore, we propose a Collaborative Teaching paradigm called “ColTeaching”, which transfers intrinsic degradation knowledge from the Deraining Subnetwork to DroneDet Subnetwork and teaches the DroneDet Subnetwork such knowledge to prevent rain-specific interference in features for DroneDet.
We build three drone-captured datasets due to the scarcity of datasets for Rainy DroneDet. They include two synthetic drone-captured datasets, namely RainVisDrone and RainUAVDT, based on the VisDrone [
15] and UAVDT [
16] benchmark datasets. Moreover, we create a real drone-captured dataset, “RainDrone”, to verify CoDerainNet’s effectiveness in real rainy scenarios. More details of our RainDrone will be introduced in
Section 5.1.
Our main contributions can be summarized as follows.
- (1)
We propose CoDerainNet, a light object detector for Rainy DroneDet that can interactively train the Deraining Subnetwork and DroneDet Subnetwork to improve Rainy DroneDet performance with limited additional computational cost during inference;
- (2)
We propose ColTeaching, which transfers intrinsic degradation knowledge from the Deraining Subnetwork to DroneDet Subnetwork to block rain-specific interference in features for Rainy DroneDet. This offers a new solution to the problem of how image restoration techniques can help improve tasks of low-quality image understanding;
- (3)
To advance the research on DroneDet under inclement weather, we build three drone-captured datasets, including two synthetic datasets and one real dataset.
We compare CoDerainNet with seven state-of-the-art (SOTA) models to verify its effectiveness and conduct extensive experiments on the three drone-captured datasets. The experiment results show that CoDerainNet can significantly reduce the computational costs of these SOTA object detectors while maintaining detection performance comparable to these SOTA models.
The rest of the paper is organized as follows: Firstly, in
Section 2, we review the current development of Rainy DroneDet and provide a summary of related works.
Section 3 describes the problem in collaborative deraining learning for Rainy DroneDet. In
Section 4, we provide details of CoDerainNet.
Section 5 presents the experimental results on CoDerainNet.
Section 6 discusses the limitations and presents a discussion of CoDerainNet. Finally, in
Section 7, we conclude the paper.
3. Problem Definition
We follow Multi-Task Learning (MTL) [
30] to define the problem in collaborative deraining learning for Rainy DroneDet.
Definition (MTL). Given n related tasks , the goal of MTL is to improve the performance of all or some of the tasks by simultaneously learning the n tasks.
Based on this definition, we can formulate the task of Rainy DroneDet. Recall that is the task of Rainy DroneDet. Let be the task of image deraining. is trained on the dataset , which consists of N training samples , where is the ith rainy image and is the image’s label for DroneDet. is trained on the dataset , which consists of M training samples , where is the corresponding rain-free image of for image deraining. Therefore, the problem of the collaborative deraining learning for Rainy DroneDet can be formulated as follows.
Definition (collaborative deraining learning for Rainy DroneDet). Given two tasks, Rainy DroneDet and image deraining , the goal of the collaborative deraining learning for Rainy DroneDet is to improve the performance with limited computational costs during inference by simultaneously optimizing these two tasks.
7. Conclusions
We proposed CoDerainNet to improve Rainy DroneDet with slightly increased computational costs. CoDerainNet is an interactively trained Deraining Subnetwork and DroneDet Subnetwork through our ColTeaching paradigm. Our key idea was to transfer the intrinsic degradation knowledge from the Deraining Subnetwork to the DroneDet Subnetwork and teaches the DroneDet Subnetwork such knowledge to suppress the impact of rain-specific interference on features extracted for DroneDet. Three new drone-captured datasets, i.e., RainVisDrone, RainUVADT, and RainDrone, were also built for interactive detection and deraining. Extensive experiments demonstrated that CoDerainNet can obtain better detection results. The results also demonstrated its effectiveness in a real rainy scenario.
In the near future, we can extend our CoDerainNet in the following directions. Firstly, we can adapt it to other kinds of challenging weather conditions, including foggy weather, snowy weather, and nighttime conditions. Secondly, we can investigate a simple semi-supervised learning framework for deraining images collected in real rainy scenarios.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}