
A Comparison of Seven Medium Resolution Impervious Surface Products on the Qinghai–Tibet Plateau, China from a User’s Perspective

Abstract
:1. Introduction
- Validation accuracy is closely related to the validation set being used: the accuracy assessment results may be different when they are calculated by a validation set with different magnitudes or different sampling strategies. Additionally, it is certainly the case that each product has an exclusive validation set. So, it is unreasonable to judge the data quality solely by comparing the absolute value of overall accuracy or category accuracy;
- Validation accuracy is highly correlated with the spatial scale: the accuracy will change with the spatial scale. Namely, the accuracy calculated based on a certain validation set can only measure the overall quality level of the sampling range to which the validation set belongs, rather than the quality of any local area. Common large-scale products often provide the accuracy calculated based on global, continental or national calculations, and for the above reason, this accuracy was unable to reflect the quality in a subset area or a highly heterogeneous region. The QTP is one such place that often has a lower regional accuracy than overall accuracy because of its complex topography, characteristic climatic conditions and lack of available images that are cloud-free or have minimal clouds;
- Discrepancy in choices of validation metrics or deficiency of accuracy assessment information [36,37]: Some existing products do not provide accurate information for specific years, used different validation metrics in the assessment process, or the choices of these metrics were not suitable or too few. For instance, GlobalLand30 only provided overall accuracy without precision and recall of category, and GAIA only assessed the data accuracy in seven representative years, but other years’ accuracies were unknown. This makes it difficult for the user to understand the product quality directly from the data publisher.
2. Materials and Methods
2.1. Study Area
2.2. Materials
2.2.1. Reported Accuracy Comparison
2.2.2. Mapping of Categories Related to Impervious Surfaces
2.3. Methodologies for Statistical Accuracy Assessment
2.3.1. Validation Sample Generation
2.3.2. Method of Accuracy Evaluation
2.4. Method for Spatial Consistency Analysis
2.5. Visual Comparison Method
3. Results
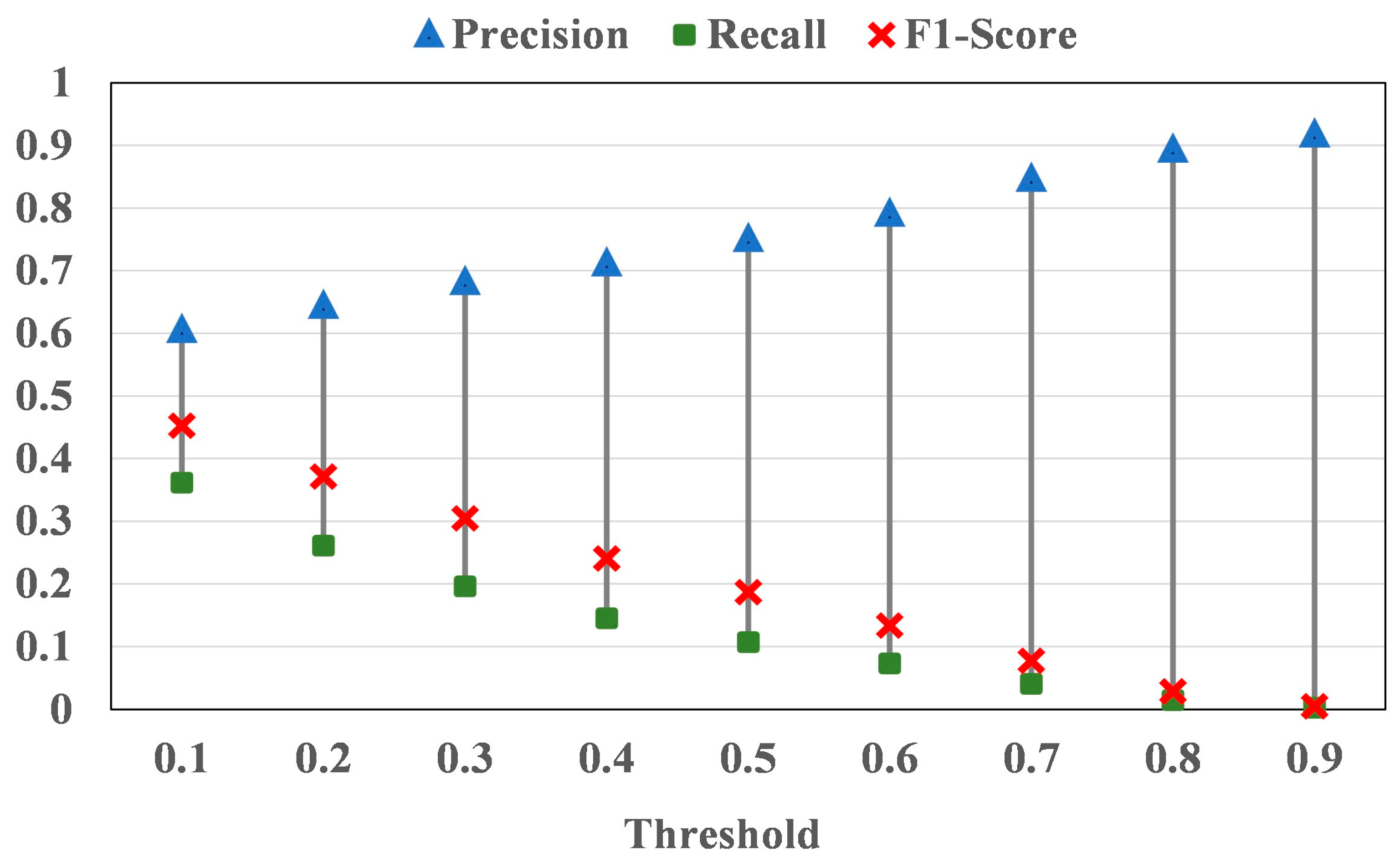
3.1. Statistical Accuracy Assessment
3.2. Spatial Consistency Analysis
3.3. Visual Comparison
4. Discussion
4.1. Reasons for Accuracy Underestimation Compared with the Published Accuracy of the Seven Products
- Accuracy underestimation due to discrepancies in category definitions: This paper directly adopted the definition of “impervious surface” to rigidly assess products, which was an assessment from the perspective of data users and was oriented towards applying impervious surface products rather than assessing their absolute quality. Thus, discrepancies in category definitions for the three products, GHSB, DW and GL30, whose original categories differed slightly from “impervious surface”, impacted the assessment results;
- Accuracy underestimation due to temporal difference in data sources: GAIA and GHSB were mapped in 2018, in which numerous omissions were found during visual comparison. Some of these omissions might be the new impervious surfaces built after 2018, but this led to an underestimation of recall in the results;
- Accuracy underestimation due to the scale of data being mapped: All products are global products except CISC, which is a product of the region encompassing China. The mapping difficulty of the global products is different from that of the Chinese products. One aspect of this is that it is easier to obtain higher data accuracy when mapping at a smaller spatial scale. Thus, the validation results of the other six products were lower than that of CISC, which only meant that their impervious surface layers’ accuracy in the QTP was lower than that of CISC but was not relevant to the overall quality of the total data or the performance of the data algorithms;
- Accuracy underestimation due to the high heterogeneity of the Qinghai–Tibet Plateau: The high altitude and complex meteorological conditions cause the Qinghai–Tibet Plateau to have fewer available data sources than other regions and make its ground object features much more unique, creating additional difficulties for classification. Thus, the QTP has a generally low local accuracy in all products, and it is reasonable for the local accuracy of the data in QTP to be less than the overall global accuracy.
4.2. Influence of Geo-Registration Errors
5. Conclusions
- The statistical accuracy assessment results showed that CISC and DW had the highest overall quality among the 30 m and 10 m products, with F1-Scores of 0.5701 and 0.5670, respectively. CISC had the best precision at 87.18% and DW had the highest recall at 74.32% of the seven products. All seven products’ local quality in QTP was lower than their global quality, and most products had fewer misclassifications than omissions, which were more serious;
- For the two 2018 supplements, although GAIA had the lowest recall, which might be due to temporal differences, its impervious surface precision was 77.31%, which still had application potential. GHSB’s F1-Score was not the lowest of the 10 m products. Thus, it was feasible to apply the two 2018 products to 2020;
- A union of data combinations is able to improve precision, while an intersection can improve recall. Appropriate data combinations and operations must be chosen according to the study purpose. In addition, the validation results using the strict validation set showed that the impervious surface omissions were mostly mixed pixels with a smaller percentages of impervious surfaces;
- Spatial consistency analysis showed that the maximum impervious surface region on the QTP voted by seven products was only 0.82% of the total area, which was 2,786,800 km2, and the high-consistency area (more than four votes) was only 15.18% of this maximum extent;
- The VC accuracy of impervious surface layers with votes greater than three in the 10 m vote map and greater than six in the 30 m map was greater than 80%. In addition, the high-consistency areas were generally concentrated in large urban centers and within clustered buildings, and the low-consistency areas were in urban fringe areas, roads and sparse buildings;
- The visual comparison showed that the 10 m products generally contained more detail, and the extractions were more fragmented when they had more detail. The impervious surface layers with bare backgrounds were of lower quality than those with vegetated backgrounds.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Seto, K.C.; Güneralp, B.; Hutyra, L.R. Global Forecasts of Urban Expansion to 2030 and Direct Impacts on Biodiversity and Carbon Pools. Proc. Natl. Acad. Sci. USA 2012, 109, 16083–16088. [Google Scholar] [CrossRef] [PubMed]
- Arnold, C.L.; Gibbons, C.J. Impervious Surface Coverage: The Emergence of a Key Environmental Indicator. J. Am. Plan. Assoc. 1996, 62, 243–258. [Google Scholar] [CrossRef]
- Slonecker, E.T.; Jennings, D.B.; Garofalo, D. Remote Sensing of Impervious Surfaces: A Review. Remote Sens. Rev. 2001, 20, 227–255. [Google Scholar] [CrossRef]
- Bounoua, L.; Nigro, J.; Zhang, P.; Thome, K.; Lachir, A. Mapping Urbanization in the United States from 2001 to 2011. Appl. Geogr. 2018, 90, 123–133. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, X.; Tan, X.; Yuan, X. Extraction of Urban Built-up Area Based on Deep Learning and Multi-Sources Data Fusion—The Application of an Emerging Technology in Urban Planning. Land 2022, 11, 1212. [Google Scholar] [CrossRef]
- Angel, S.; Parent, J.; Civco, D.L.; Blei, A.; Potere, D. The Dimensions of Global Urban Expansion: Estimates and Projections for All Countries, 2000–2050. Prog. Plan. 2011, 75, 53–107. [Google Scholar] [CrossRef]
- Yuan, F.; Bauer, M.E. Comparison of Impervious Surface Area and Normalized Difference Vegetation Index as Indicators of Surface Urban Heat Island Effects in Landsat Imagery. Remote Sens. Environ. 2007, 106, 375–386. [Google Scholar] [CrossRef]
- Kafy, A.-A.; Al Rakib, A.; Fattah, M.A.; Rahaman, Z.A.; Sattar, G.S. Others Impact of Vegetation Cover Loss on Surface Temperature and Carbon Emission in a Fastest-Growing City, Cumilla, Bangladesh. Build. Environ. 2022, 208, 108573. [Google Scholar] [CrossRef]
- Boyko, C.T.; Cooper, R.; Davey, C.L.; Wootton, A.B. Informing an Urban Design Process by Way of a Practical Example. Proc. Inst. Civ. Eng.-Urban Des. Plan. 2010, 163, 17–30. [Google Scholar] [CrossRef]
- Yao, T.; Thompson, L.G.; Mosbrugger, V.; Zhang, F.; Ma, Y.; Luo, T.; Xu, B.; Yang, X.; Joswiak, D.R.; Wang, W.; et al. Third Pole Environment (TPE). Environ. Dev. 2012, 3, 52–64. [Google Scholar] [CrossRef]
- Qiu, J. China: The Third Pole. Nature 2008, 454, 393–397. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Liu, S.; Liu, Y.; Dong, Y.; Li, M.; An, Y.; Shi, F.; Beazley, R. Effects of the Interaction among Climate, Terrain and Human Activities on Biodiversity on the Qinghai-Tibet Plateau. Sci. Total Environ. 2021, 794, 148497. [Google Scholar] [CrossRef] [PubMed]
- Yao, T.; Wu, F.; Ding, L.; Sun, J.; Zhu, L.; Piao, S.; Deng, T.; Ni, X.; Zheng, H.; Ouyang, H. Multispherical Interactions and Their Effects on the Tibetan Plateau’s Earth System: A Review of the Recent Researches. Natl. Sci. Rev. 2015, 2, 468–488. [Google Scholar] [CrossRef]
- Tan, K.; Ciais, P.; Piao, S.; Wu, X.; Tang, Y.; Vuichard, N.; Liang, S.; Fang, J. Application of the ORCHIDEE Global Vegetation Model to Evaluate Biomass and Soil Carbon Stocks of Qinghai-Tibetan Grasslands. Glob. Biogeochem. Cycles 2010, 24. [Google Scholar] [CrossRef]
- Kang, S.; Xu, Y.; You, Q.; Flügel, W.-A.; Pepin, N.; Yao, T. Review of Climate and Cryospheric Change in the Tibetan Plateau. Environ. Res. Lett. 2010, 5, 015101. [Google Scholar] [CrossRef]
- Hopping, K.A.; Knapp, A.K.; Dorji, T.; Klein, J.A. Warming and Land Use Change Concurrently Erode Ecosystem Services in Tibet. Glob. Chang. Biol. 2018, 24, 5534–5548. [Google Scholar] [CrossRef]
- Kennedy, C.M.; Oakleaf, J.R.; Theobald, D.M.; Baruch-Mordo, S.; Kiesecker, J. Managing the Middle: A Shift in Conservation Priorities Based on the Global Human Modification Gradient. Glob. Chang. Biol. 2019, 25, 811–826. [Google Scholar] [CrossRef]
- Mu, H.; Li, X.; Wen, Y.; Huang, J.; Du, P.; Su, W.; Miao, S.; Geng, M. A Global Record of Annual Terrestrial Human Footprint Dataset from 2000 to 2018. Sci. Data 2022, 9, 176. [Google Scholar] [CrossRef]
- Liu, T.; Liu, H.; Qi, Y. Construction Land Expansion and Cultivated Land Protection in Urbanizing China: Insights from National Land Surveys, 1996–2006. Habitat Int. 2015, 46, 13–22. [Google Scholar] [CrossRef]
- He, G.; Zhang, Z.; Jiao, W.; Long, T.; Peng, Y.; Wang, G.; Yin, R.; Wang, W.; Zhang, X.; Liu, H.; et al. Generation of Ready to Use (RTU) Products over China Based on Landsat Series Data. Big Earth Data 2018, 2, 56–64. [Google Scholar] [CrossRef]
- He, G.; Wang, L.; Ma, Y.; Zhang, Z.; Wang, G.; Peng, Y.; Long, T.; Zhang, X. Processing of Earth Observation Big Data: Challenges and Countermeasures. Chin. Sci. Bull. 2015, 60, 470–478. [Google Scholar]
- He, G.; Wang, G.; Long, T.; Peng, Y.; Jiang, W.; Yin, R.; Jiao, W.; Zhang, Z. Opening and Sharing of Big Earth Observation Data: Challenges and Countermeasures. Bull. Chin. Acad. Sci. Chin. Version 2018, 33, 783–790. [Google Scholar]
- He, G.; Jiao, W.; Zhang, Z.; Long, T.; Wang, G.; Peng, Y.; Yin, R. Remote Sensing Data Based Ready To Use (RTU) Products. China Sci. Data 2020, 5, 6–13. [Google Scholar]
- Weng, Q. Remote Sensing of Impervious Surfaces in the Urban Areas: Requirements, Methods, and Trends. Remote Sens. Environ. 2012, 117, 34–49. [Google Scholar] [CrossRef]
- Fu, S.; Zhang, X.; Kuang, W.; Guo, C. Characteristics of Changes in Urban Land Use and Efficiency Evaluation in the Qinghai–Tibet Plateau from 1990 to 2020. Land 2022, 11, 757. [Google Scholar] [CrossRef]
- Gong, P.; Li, X.; Wang, J.; Bai, Y.; Cheng, B.; Hu, T.; Liu, X.; Xu, B.; Yang, J.; Zhang, W.; et al. Annual Maps of Global Artificial Impervious Area (GAIA) between 1985 and 2018. Remote Sens. Environ. 2020, 236, 111510. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Zhao, T.; Gao, Y.; Chen, X.; Mi, J. GISD30: Global 30 m Impervious-Surface Dynamic Dataset from 1985 to 2020 Using Time-Series Landsat Imagery on the Google Earth Engine Platform. Earth Syst. Sci. Data 2022, 14, 1831–1856. [Google Scholar] [CrossRef]
- Wang, P.; Huang, C.; Tilton, J.C.; Tan, B.; de Colstoun, E.C.B. HOTEX: An Approach for Global Mapping of Human Built-up and Settlement Extent. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; 2017; pp. 1562–1565. [Google Scholar]
- Liu, X.; Hu, G.; Chen, Y.; Li, X.; Xu, X.; Li, S.; Pei, F.; Wang, S. High-Resolution Multi-Temporal Mapping of Global Urban Land Using Landsat Images Based on the Google Earth Engine Platform. Remote Sens. Environ. 2018, 209, 227–239. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer Resolution Observation and Monitoring of Global Land Cover: First Mapping Results with Landsat TM and ETM+ Data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global Land Cover Mapping at 30m Resolution: A POK-Based Operational Approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Corbane, C.; Syrris, V.; Sabo, F.; Politis, P.; Melchiorri, M.; Pesaresi, M.; Soille, P.; Kemper, T. Convolutional Neural Networks for Global Human Settlements Mapping from Sentinel-2 Satellite Imagery. Neural Comput. Appl. 2021, 33, 6697–6720. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; De Keersmaecker, W.; Souverijns, N.; Brockmann, C.; Quast, R.; Wevers, J.; Grosu, A.; Paccini, A.; Vergnaud, S.; et al. ESA WorldCover 10 m 2020 V100 2021. Available online: https://0-doi-org.brum.beds.ac.uk/10.5281/zenodo.5571936 (accessed on 7 March 2023).
- Chen, B.; Xu, B.; Zhu, Z.; Yuan, C.; Suen, H.P.; Guo, J.; Xu, N.; Li, W.; Zhao, Y.; Yang, J.; et al. Stable Classification with Limited Sample: Transferring a 30-m Resolution Sample Set Collected in 2015 to Mapping 10-m Resolution Global Land Cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar]
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near Real-Time Global 10 m Land Use Land Cover Mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Foody, G.M. Status of Land Cover Classification Accuracy Assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key Issues in Rigorous Accuracy Assessment of Land Cover Products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Xing, H.; Meng, Y.; Hou, D.; Cao, F.; Xu, H. Exploring Point-of-Interest Data from Social Media for Artificial Surface Validation with Decision Trees. Int. J. Remote Sens. 2017, 38, 6945–6969. [Google Scholar] [CrossRef]
- Wickham, J.; Stehman, S.V.; Sorenson, D.G.; Gass, L.; Dewitz, J.A. Thematic Accuracy Assessment of the NLCD 2016 Land Cover for the Conterminous United States. Remote Sens. Environ. 2021, 257, 112357. [Google Scholar] [CrossRef]
- Wang, J.; Yang, X.; Wang, Z.; Cheng, H.; Kang, J.; Tang, H.; Li, Y.; Bian, Z.; Bai, Z. Consistency Analysis and Accuracy Assessment of Three Global Ten-Meter Land Cover Products in Rocky Desertification Region—A Case Study of Southwest China. ISPRS Int. J. Geo-Inf. 2022, 11, 202. [Google Scholar] [CrossRef]
- Gao, Y.; Liu, L.; Zhang, X.; Chen, X.; Mi, J.; Xie, S. Consistency Analysis and Accuracy Assessment of Three Global 30-m Land-Cover Products over the European Union Using the LUCAS Dataset. Remote Sens. 2020, 12, 3479. [Google Scholar] [CrossRef]
- Chen, J.; Yan, F.; Lu, Q. Spatiotemporal Variation of Vegetation on the Qinghai–Tibet Plateau and the Influence of Climatic Factors and Human Activities on Vegetation Trend (2000–2019). Remote Sens. 2020, 12, 3150. [Google Scholar] [CrossRef]
- Yin, R. Research on Impervious Surface Coverage and Change Information Mining Methods in Large-Scale and Long Time Series. Ph.D. Thesis, Aerospace Information Research Institute, Chinese Academy of Sciences, Beijing, China, 2022. [Google Scholar]
- Zhang, X.; Liu, L.; Wu, C.; Chen, X.; Gao, Y.; Xie, S.; Zhang, B. Development of a Global 30 m Impervious Surface Map Using Multisource and Multitemporal Remote Sensing Datasets with the Google Earth Engine Platform. Earth Syst. Sci. Data 2020, 12, 1625–1648. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Chen, X.; Gao, Y.; Xie, S.; Mi, J. GLC_FCS30: Global Land-Cover Product with Fine Classification System at 30 m Using Time-Series Landsat Imagery. Earth Syst. Sci. Data 2021, 13, 2753–2776. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhu, Z. ASI: An Artificial Surface Index for Landsat 8 Imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102703. [Google Scholar] [CrossRef]
- Yang, F.; Wang, Z.; Yang, X.; Liu, Y.; Liu, B.; Wang, J.; Kang, J. Using Multi-Sensor Satellite Images and Auxiliary Data in Updating and Assessing the Accuracies of Urban Land Products in Different Landscape Patterns. Remote Sens. 2019, 11, 2664. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, J.; Lin, H.; Cong, M.; Wan, Y.; Zhang, J. Fusing Multiple Land Cover Products Based on Locally Estimated Map-Reference Cover Type Transition Probabilities. Remote Sens. 2023, 15, 481. [Google Scholar] [CrossRef]
- Huang, X.; Song, Y.; Yang, J.; Wang, W.; Ren, H.; Dong, M.; Feng, Y.; Yin, H.; Li, J. Toward Accurate Mapping of 30-m Time-Series Global Impervious Surface Area (GISA). Int. J. Appl. Earth Obs. Geoinf. 2022, 109, 102787. [Google Scholar] [CrossRef]
- Venter, Z.S.; Barton, D.N.; Chakraborty, T.; Simensen, T.; Singh, G. Global 10 m Land Use Land Cover Datasets: A Comparison of Dynamic World, World Cover and Esri Land Cover. Remote Sens. 2022, 14, 4101. [Google Scholar] [CrossRef]
- Global Land Cover—Product Introduction. Available online: http://www.globeland30.org/Page/EN_sysFrame/dataIntroduce.html?columnID=81&head=product¶=product&type=data (accessed on 25 February 2023).
- Yin, R.; He, G.; Wang, G.; Long, T.; Li, H.; Zhou, D.; Gong, C. Automatic Framework of Mapping Impervious Surface Growth With Long-Term Landsat Imagery Based on Temporal Deep Learning Model. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good Practices for Estimating Area and Assessing Accuracy of Land Change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- See, L.; Georgieva, I.; Duerauer, M.; Kemper, T.; Corbane, C.; Maffenini, L.; Gallego, J.; Pesaresi, M.; Sirbu, F.; Ahmed, R.; et al. A Crowdsourced Global Data Set for Validating Built-up Surface Layers. Sci. Data 2022, 9, 13. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Region | Validation Samples Description | Accuracy Description |
|---|---|---|---|
| Xing et al. [38] | Beijing, China | The validation set was generated from social media point of interest (POI) data via modified decision trees. | The validation accuracy of artificial surfaces in GL30 in 2010 in Beijing is 92.82%. |
| Yang et al. [47] | Kuala Lumpur, Malaysia, and its surrounding areas | 15 land investigation points and 1635 validation points were obtained via stratified random sampling with the strata of non-urban/urban land and was interpreted based on HR image. | The overall accuracy (OA) of GL30 2010 is 80.54%. |
| Zhang et al. [48] | Shaanxi, China | The validation set was generated using an augmented sampling method without violating the principles of stratified sampling, containing a shared subset for all products and a separate one for individual products. Concretely, there were 712 and 703 samples for GL30 in 2010 and 2020 and 705 and 699 samples for FCS30 in 2010 and 2020. | The OA of GL30, FCS30 is 80.80%, 75.33% in 2010 and 78.41%, 79.41% in 2020; the user accuracy (UA) of artificial surfaces in GL30, FCS30 is 61.54%, 86.27% in 2010 and 66.04%, 86.79 in 2020. |
| J. Wang et al. [40] | The southwest of China | 3113 samples from the Geo-Wiki Global Validation Sample Set (Geo-Wiki); 488 samples from the Global Land Cover Validation Sample Set (GLCVSS) and 4606 samples from visual interpretation (VI). | The overall accuracy of WC10 2020 is 45.13%, 54.92%, and 64.50%, respectively, calculated by Geo-Wiki, GLCVSS, and VI, with the kappa is 0.314, 0.42 and 0.58; The UA of “built up” is 73.17%, 50% and 94.57% and the producer accuracy (PA) of “built up” is 65.22%, 50% and 74.49, correspondingly. |
| Huang et al. [49] | Global | 39,477 impervious surface area samples and 79,345 non-impervious surface samples were extracted from the ZiYuan-3 global built-up dataset and visually inspected. | The OA of GAIA is 87.91%; the UA and PA of impervious surfaces are 80.98% and 83.13%, respectively, with an F1-score of 0.821. |
| Venter et al. [50] | Global | Two validation sets were obtained from open-access data; one contains 72 million distinct 10 × 10 m pixels from the ground truth validation dataset, and the other has 337,845 points from the Land Use/Cover Area Frame Survey (LUCAS) over the European Union. | The OA is 72% of DW and 65% of WC10 in 2020. |
| Gao et al. [41] | European Union and the United Kingdom | The validation set has 691,521 sample points in 2010 and 632,315 ones in 2015, which were obtained from LUCAS and were visually interpreted and temporal filtered. | The OA of GL30-2010 is 88.90 ± 0.68%, and 84.33 ± 0.80% of FCS30-2015. |
| Product Name | Year | Resolution | Source of Images | Spatial Scale of Validation | Accuracy Information | Object |
|---|---|---|---|---|---|---|
| GAIA | 2018 | 30 m | Landsat | Global | (report of data in 2015) The overall accuracy is 89%; precision of artificial impervious area is 99% and its recall is 78%. | Changes in impervious surface |
| GHSB | 2018 | 10 m | Sentinel | Continent | (Binarized with a threshold of 0.2) the average balanced accuracy of the seven continents is greater than 0.7, and that of Asia is more than 0.875. | Built-up area |
| CISC | 2020 | 30 m | Landsat | China | No overall accuracy was reported; precision of impervious surface is 94.9% and its recall is 93.7%. | Impervious surface |
| GL30 | 2020 | 30 m | Landsat | Global | The overall accuracy of data in 2020 is 85.72%; no details for specific type. | Land cover |
| FCS30 | 2020 | 30 m | Landsat | Global | The overall accuracy of data in 2020 is 82.5%, and the kappa score is 0.784; the impervious surface in FCS30 was mapped separately, whose overall accuracy is 95.1% and the kappa score is 0.898 [27]. | Land cover |
| WC10 | 2020 | 10 m | Sentinel | Global, Continent | The overall accuracy is 74.4 ± 0.1% for global and 80.7 ± 0.1% for Asia; precision for built-up is 67.7 ± 0.9% for global and 69.6 ± 1.4% for Asia; its recall is 67.9 ± 0.8% for global and 69.1 ± 1.4% for Asia. | Land cover |
| DW | 2020 | 10 m | Sentinel | None | DW was generated by a near real-time land-cover mapping model, which output customized results according to the user-defined temporal and spatial range, so the specific map has no accuracy reported. | Land cover |
| Product Name | Class Name | Definition | Literature |
|---|---|---|---|
| GAIA | Artificial impervious areas | “Artificial impervious areas are mainly man-made structures that are composed of any material that impedes or prevents natural infiltration of water into the soil. They include roofs, paved surfaces, hardened grounds, and major road surfaces mainly found in human settlements.” | Gong et al. [26] |
| GL30 | Artificial Surfaces | “It refers to the surfaces formed by man-built activities. All kinds of habitation in urban and rural areas, industrial and mining area, transportation facilities etc. are included in this category, while interior contiguous green land and water bodies in the construction land use.” | Quote from GL30 official website [51]: http://www.globeland30.org/, accessed on 4 November 2022. |
| FCS30 | Impervious surfaces | “Impervious surfaces are usually covered by anthropogenic materials which prevent water penetrating into the soil and are primarily composed of asphalt, sand and stone, concrete, bricks, glass, etc.” | Zhang et al. [44,45] |
| CISC | Impervious surfaces | “Impervious surfaces are surfaces covered by various impervious construction materials, such as roofs, roads and squares made of tiles, asphalt, cement concrete, etc.” | Yin [43] Yin et al. [52] |
| GHSB | Human settlements | “The union of all the satellite data samples that corresponds to a roofed construction above ground which is intended or used for the shelter of humans, animals, things, the production of economic goods or the delivery of services.” | Corbane et al. [32] |
| WC10 | Built-up | “Human made structures; major road and rail networks; large homogenous impervious surfaces including parking structures, office buildings and residential housing; examples: houses, dense villages/towns/cities, paved roads, asphalt.” | Zanaga et al. [33] |
| DW | Built area | “1. Clusters of human-made structures or individual very large human-made structures; 2. Contained industrial, commercial, and private building, and the associated parking lots; 3. A mixture of residential buildings, streets, lawns, trees, isolated residential structures or buildings surrounded by vegetative land covers; 4. Major road and rail networks outside of the predominant residential areas; 5. Large homogeneous impervious surfaces, including parking structures, large office buildings, and residential housing developments containing clusters of cul-de-sacs.” | Brown et al. [35] |
| Products | Intersection Set | Union Set | IoU | Number of Intersections | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |||
| GAIA | 77.31% | 9.06% | 0.1622 | 77.31% | 9.06% | 0.1622 | 1 | 401 |
| CISC | 87.18% | 42.36% | 0.5701 | 87.18% | 42.36% | 0.5701 | 1 | 1662 |
| GL30 | 66.76% | 26.95% | 0.3840 | 66.76% | 26.95% | 0.3840 | 1 | 1381 |
| FCS30 | 79.55% | 19.67% | 0.3154 | 79.55% | 19.67% | 0.3154 | 1 | 846 |
| GAIA + CISC | 94.60% | 7.69% | 0.1422 | 83.81% | 43.73% | 0.5747 | 0.1557 | 278 |
| GAIA + GL30 | 86.57% | 7.16% | 0.1323 | 65.84% | 28.85% | 0.4012 | 0.1888 | 283 |
| GAIA + FCS30 | 89.27% | 6.81% | 0.1266 | 76.06% | 21.92% | 0.3404 | 0.2647 | 261 |
| CISC + GL30 | 93.76% | 19.76% | 0.3264 | 73.00% | 49.55% | 0.5903 | 0.3105 | 721 |
| CISC + FCS30 | 95.42% | 15.84% | 0.2717 | 81.44% | 46.19% | 0.5894 | 0.2928 | 568 |
| GL30 + FCS30 | 92.34% | 11.98% | 0.2122 | 66.46% | 34.64% | 0.4554 | 0.2490 | 444 |
| GAIA + CISC + GL30 | 95.59% | 6.34% | 0.1190 | 71.75% | 50.10% | 0.5900 | 0.0950 | 227 |
| GAIA+ CISC + FCS30 | 95.09% | 6.23% | 0.1169 | 79.32% | 46.97% | 0.5900 | 0.1106 | 224 |
| GAIA + GL30 + FCS30 | 92.89% | 5.73% | 0.1079 | 65.53% | 35.46% | 0.4602 | 0.1140 | 211 |
| CISC + GL30 + FCS30 | 96.08% | 10.76% | 0.1935 | 70.26% | 52.15% | 0.5987 | 0.1508 | 383 |
| GAIA + CISC + GL30 + FCS30 | 96.28% | 5.29% | 0.1003 | 69.37% | 52.56% | 0.5980 | 0.0725 | 188 |
| Products | Intersection Set | Union Set | IoU | Number of Intersections | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |||
| GHSB | 60.43% | 36.15% | 0.4524 | 60.43% | 36.15% | 0.4524 | 1 | 11345 |
| WC10 | 73.76% | 28.60% | 0.4121 | 73.76% | 28.60% | 0.4121 | 1 | 7354 |
| DW | 45.83% | 74.32% | 0.5670 | 45.83% | 74.32% | 0.567 | 1 | 30755 |
| GHSB + WC10 | 84.28% | 19.33% | 0.3145 | 60.03% | 45.41% | 0.5171 | 0.3032 | 4351 |
| GHSB + DW | 67.66% | 34.36% | 0.4558 | 44.46% | 76.10% | 0.5613 | 0.2967 | 9634 |
| WC10 + DW | 84.01% | 22.35% | 0.3531 | 46.22% | 80.56% | 0.5874 | 0.1527 | 5047 |
| GHSB + WC10 + DW | 85.94% | 18.65% | 0.3065 | 44.84% | 81.66% | 0.5790 | 0.1192 | 4117 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, K.; He, G.; Yin, R.; Wang, G.; Long, T. A Comparison of Seven Medium Resolution Impervious Surface Products on the Qinghai–Tibet Plateau, China from a User’s Perspective. Remote Sens. 2023, 15, 2366. https://0-doi-org.brum.beds.ac.uk/10.3390/rs15092366
Zheng K, He G, Yin R, Wang G, Long T. A Comparison of Seven Medium Resolution Impervious Surface Products on the Qinghai–Tibet Plateau, China from a User’s Perspective. Remote Sensing. 2023; 15(9):2366. https://0-doi-org.brum.beds.ac.uk/10.3390/rs15092366
Chicago/Turabian StyleZheng, Kaiyuan, Guojin He, Ranyu Yin, Guizhou Wang, and Tengfei Long. 2023. "A Comparison of Seven Medium Resolution Impervious Surface Products on the Qinghai–Tibet Plateau, China from a User’s Perspective" Remote Sensing 15, no. 9: 2366. https://0-doi-org.brum.beds.ac.uk/10.3390/rs15092366