

AL-MRIS: An Active Learning-Based Multipath Residual Involution Siamese Network for Few-Shot Hyperspectral Image Classification

Abstract
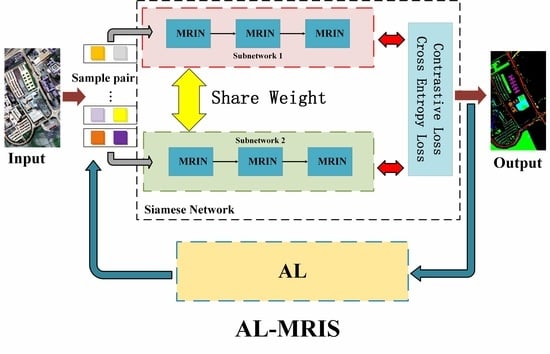
:
1. Introduction
- An active learning-based multipath residual involution Siamese network for few-shot HSI classification, AL-MRIS, is proposed. In the AL-MRIS method, the multipath residual involution (MRIN) module can comprehensively consider the local features, dynamic features and global features of HSIs. Moreover, to address the sample scarcity problem, the AL strategy is integrated into the Siamese network to make the training samples more representative to improve the classification performance.
- An AL-based Siamese network framework is constructed. The Siamese network can extract information beyond labels from the data itself, thereby achieving better classification performance, especially for few-shot training samples. Moreover, by integrating with AL, representative samples can be selected more effectively, thus improving the ability of the Siamese network to discriminate features while reducing the practical labeling cost.
- The multipath residual involution (MRIN) module is proposed. The MRIN module captures fine-grained features via an involution operation and effectively aggregates the contextual semantic information of the HSI through dynamic weights. Moreover, the MRIN module comprehensively considers local features, dynamic features and global features through multipath residual connections, which improves the representation ability of HSIs.
- A cosine distance-based contrastive loss (CD loss) for Siamese networks is proposed. The CD loss utilizes the directional similarity of high-dimensional HSI data and improves the discriminability of the Siamese classification network.
2. Related Works
2.1. Involution Network
2.2. Siamese Network
3. Our Proposed AL-MRIS Method
3.1. The Multipath Residual Involution (MRIN) Module
3.2. AL-Based Siamese Network
3.2.1. Construct Sample Pairs Based on the Training Sample Set
3.2.2. Siamese Network Learning Using the Training Set
3.2.3. AL Selecting Newly Labeled Training Samples
3.2.4. Updating the Training Set
4. Experiments and Results
4.1. Datasets
4.2. Evaluation Metrics
4.3. Comparison of Different Classification Methods
4.4. Parameter Discussions
4.4.1. Impacts of the MRIN Module Number
4.4.2. Comparison of Different Distance-Based Contrast Losses
4.4.3. Influences of Different Training Sample Numbers
4.4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Janne, M.; Sarita, K.-S.; Sonja, K.; Topi, T.; Pekka, H.; Peter, K.; Laura, P.; Arto, V.; Sakari, T.; Timo, K.; et al. Tree species classification from airborne hyperspectral and LiDAR data using 3D convolutional neural networks. Remote Sens. Environ. Interdiscip. J. 2021, 256, 112322. [Google Scholar]
- Teng, M.Y.; Mehrubeoglu, R.; King, S.A.; Cammarata, K.; Simons, J. Investigation of epifauna coverage on seagrass blades using spatial and spectral analysis of hyperspectral images. In Proceedings of the 2013 5th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Gainesville, FL, USA, 26–28 June 2013. [Google Scholar] [CrossRef]
- Kirsch, M.; Lorenz, S.; Zimmermann, R.; Tusa, L.; Möckel, R.; Hödl, P.; Booysen, R.; Khodadadzadeh, M.; Gloaguen, R. Integration of Terrestrial and Drone-Borne Hyperspectral and Photogrammetric Sensing Methods for Exploration Mapping and Mining Monitoring. Remote Sens. 2018, 10, 1366. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef]
- Tao, H.; Duan, Q.; Lu, M.; Hu, Z. Learning discriminative feature representation with pixel-level supervision for forest smoke recognition. Pattern Recognit. J. Pattern Recognit. Soc. 2023, 143, 109761. [Google Scholar] [CrossRef]
- Deng, B.; Jia, S.; Shi, D. Deep Metric Learning-Based Feature Embedding for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1422–1435. [Google Scholar] [CrossRef]
- Guo, A.J.X.; Zhu, F. A CNN-Based Spatial Feature Fusion Algorithm for Hyperspectral Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7170–7181. [Google Scholar] [CrossRef]
- Gao, K.; Liu, B.; Yu, X.; Zhang, P.; Tan, X.; Sun, Y. Small sample classification of hyperspectral image using model-agnostic meta-learning algorithm and convolutional neural network. Int. J. Remote Sens. 2021, 42, 3090–3122. [Google Scholar] [CrossRef]
- Li, W.; Liu, Q.; Zhang, Y.; Wang, Y.; Yuan, Y.; Jia, Y.; He, Y. Few-Shot Hyperspectral Image Classification Using Meta Learning and Regularized Finetuning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, L.; Zhao, R.; Shi, Z. A Bayesian Meta-Learning-Based Method for Few-Shot Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5500613. [Google Scholar] [CrossRef]
- Cao, M.; Zhao, G.; Dong, A.; Lv, G.; Guo, Y.; Dong, X. Few-Shot Hyperspectral Image Classification Based on Cross-Domain Spectral Semantic Relation Transformer. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 9–12 October 2023; pp. 1375–1379. [Google Scholar]
- Li, Z.; Liu, M.; Chen, Y.; Xu, Y.; Li, W.; Du, Q. Deep Cross-Domain Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5501618. [Google Scholar] [CrossRef]
- Zhang, C.; Zhong, S.; Gong, C. Feature Integration-Based Training for Cross-Domain Hyperspectral Image Classification. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 3572–3575. [Google Scholar]
- Wang, B.; Xu, Y.; Wu, Z.; Zhan, T.; Wei, Z. Spatial–Spectral Local Domain Adaption for Cross Domain Few Shot Hyperspectral Images Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5539515. [Google Scholar] [CrossRef]
- Wang, W.; Liu, F.; Liu, J.; Xiao, L. Cross-Domain Few-Shot Hyperspectral Image Classification with Class-Wise Attention. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5502418. [Google Scholar] [CrossRef]
- Huang, K.-K.; Yuan, H.T.; Ren, C.X.; Hou, Y.E.; Duan, J.L.; Yang, Z. Hyperspectral Image Classification via Cross-Domain Few-Shot Learning with Kernel Triplet Loss. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5530818. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Zhang, M.; Wang, S.; Tao, R.; Du, Q. Graph Information Aggregation Cross-Domain Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 1912–1925. [Google Scholar] [CrossRef]
- Li, Z.; Guo, H.; Chen, Y.; Liu, C.; Du, Q.; Fang, Z. Few-Shot Hyperspectral Image Classification with Self-Supervised Learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5517917. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, L.; Wei, W.; Zhang, Y. Deep Self-Supervised Learning for Few-Shot Hyperspectral Image Classification. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 501–504. [Google Scholar]
- Cao, Z.; Li, X.; Jiang, J.; Zhao, L. 3D convolutional Siamese network for few-shot hyperspectral classification. J. Appl. Remote Sens. 2020, 14, 048504. [Google Scholar] [CrossRef]
- Huang, L.; Chen, Y. Dual-Path Siamese CNN for Hyperspectral Image Classification with Limited Training Samples. IEEE Geosci. Remote Sens. Lett. 2024, 18, 518–522. [Google Scholar] [CrossRef]
- Wang, W.; Chen, Y.; He, X.; Li, Z. Soft Augmentation-Based Siamese CNN for Hyperspectral Image Classification with Limited Training Samples. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5508505. [Google Scholar] [CrossRef]
- Xue, Z.; Zhou, Y.; Du, P. S3Net: Spectral–Spatial Siamese Network for Few-Shot Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5531219. [Google Scholar] [CrossRef]
- Hou, W.; Chen, N.; Peng, J.; Sun, W. A Prototype and Active Learning Network for Small-Sample Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5510805. [Google Scholar] [CrossRef]
- Ma, K.Y.; Chang, C.-I. Iterative Training Sampling Coupled with Active Learning for Semi supervised Spectral–Spatial Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8672–8692. [Google Scholar] [CrossRef]
- Li, X.; Cao, Z.; Zhao, L.; Jiang, J. ALPN: Active-Learning-Based Prototypical Network for Few-Shot Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5508305. [Google Scholar] [CrossRef]
- Wang, G.; Ren, P. Hyperspectral Image Classification with Feature-Oriented Adversarial Active Learning. Remote Sens. 2020, 12, 3879. [Google Scholar] [CrossRef]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the Inherence of Convolution for Visual Recognition. arXiv 2021. [Google Scholar] [CrossRef]
- Meng, Z.; Zhao, F.; Liang, M.; Xie, W. Deep Residual Involution Network for Hyperspectral Image Classification. Remote Sens. 2021, 13, 3055. [Google Scholar] [CrossRef]
- Wu, H.; Xu, Z.; Zhang, J.; Yan, W.; Ma, X. Face recognition based on convolution siamese networks. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Dey, S.; Dutta, A.; Toledo, J.I.; Ghosh, S.K.; Llados, J.; Pal, U. SigNet: Convolutional Siamese Network for Writer Independent Offline Signature Verification. arXiv 2017. [Google Scholar] [CrossRef]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese Box Adaptive Network for Visual Tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Richards, J.A. Classifier performance and map accuracy. Remote Sens. Environ. 1996, 57, 161–166. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Class | #Number |
|---|---|---|
| 1 | Asphalt | 6631 |
| 2 | Meadows | 18,649 |
| 3 | Gravel | 2099 |
| 4 | Trees | 3064 |
| 5 | Painted metal sheets | 1345 |
| 6 | Bare Soil | 5029 |
| 7 | Bitumen | 1330 |
| 8 | Self-Blocking Bricks | 3682 |
| 9 | Shadows | 947 |
| Total (9 classes) | 42,776 | |
| Label | Class | #Number |
|---|---|---|
| 1 | Alfalfa | 40 |
| 2 | Corn–notill | 1428 |
| 3 | Corn–mintill | 830 |
| 4 | Corn | 237 |
| 5 | Grass–pasture | 483 |
| 6 | Grass–trees | 730 |
| 7 | Grass–pasture–mowed | 28 |
| 8 | Hay–windrowed | 478 |
| 9 | Oats | 20 |
| 10 | Soybean–notill | 972 |
| 11 | Soybean–mintill | 2455 |
| 12 | Soybean–clean | 593 |
| 13 | Wheat | 205 |
| 14 | Woods | 1265 |
| 15 | Buildings–Grass–Trees–Drives | 386 |
| 16 | Stone–Steel–Towers | 93 |
| Total (16 classes) | 10,249 | |
| Label | Class | #Number |
|---|---|---|
| 1 | Brocoli_green_weeds_1 | 2006 |
| 2 | Brocoli_green_weeds_2 | 3723 |
| 3 | Fallow | 1973 |
| 4 | Fallow_rough_plow | 1391 |
| 5 | Fallow_smooth | 2675 |
| 6 | Stubble | 3956 |
| 7 | Celery | 3576 |
| 8 | Grapes_untrained | 11,268 |
| 9 | Soil_vinyard_develop | 6200 |
| 10 | Corn_senesced_green_weeds | 3275 |
| 11 | Lettuce_romaine_4wk | 1065 |
| 12 | Lettuce_romaine_5wk | 1924 |
| 13 | Lettuce_romaine_6wk | 913 |
| 14 | Lettuce_romaine_7wk | 1067 |
| 15 | Vinyard_untrained | 7265 |
| 16 | Vinyard_vertical_trellis | 1804 |
| Total (16 classes) | 54,081 | |
| DRIN | Sia-3DCNN | 3DCSN | S3Net | ALPN | FAAL | CFSL | Gia-CFSL | Proposed AL-MRIS | |
|---|---|---|---|---|---|---|---|---|---|
| OA (%) | 72.06 ± 4.59 | 63.73 ± 6.19 | 65.27 ± 5.01 | 75.24 ± 6.42 | 69.19 ± 8.29 | 37.18 ± 7.68 | 79.37 ± 1.05 | 73.58 ± 3.47 | 84.71 ± 3.58 |
| AA (%) | 80.42 ± 2.49 | 68.09 ± 4.47 | 71.99 ± 3.08 | 81.75 ± 3.67 | 71.54 ± 8.29 | 23.82 ± 7.86 | 81.07 ± 2.13 | 74.97 ± 1.20 | 82.27 ± 5.07 |
| Kappa × 100 | 65.70 ± 4.99 | 52.65 ± 7.96 | 57.78 ± 6.41 | 68.83 ± 7.18 | 61.29 ± 5.65 | 38.46 ± 5.01 | 74.29 ± 1.94 | 65.97 ± 3.79 | 79.81 ± 4.71 |
| Asphalt | 87.02 | 65.51 | 68.88 | 63.99 | 54.13 | 5.35 | 62.02 | 73.31 | 93.49 |
| Meadows | 41.75 | 25.53 | 66.12 | 74.20 | 74.27 | 23.51 | 82.64 | 68.35 | 82.01 |
| Gravel | 64.02 | 67.55 | 73.95 | 79.76 | 82.37 | 76.65 | 77.93 | 87.58 | 55.56 |
| Trees | 87.97 | 59.26 | 65.59 | 70.81 | 93.39 | 2.23 | 75.81 | 73.71 | 80.92 |
| Painted metal sheets | 96.34 | 100 | 98.95 | 95.97 | 99.70 | 99.08 | 99.32 | 99.92 | 100 |
| Bare Soil | 80.00 | 69.11 | 86.64 | 77.79 | 82.12 | 81.32 | 82.40 | 85.35 | 100 |
| Bitumen | 60.28 | 88.62 | 97.89 | 89.74 | 93.28 | 100 | 93.51 | 96.75 | 96.83 |
| Self-Blocking Bricks | 99.13 | 36.62 | 56.71 | 35.23 | 69.40 | 8.56 | 42.42 | 54.96 | 94.45 |
| Shadows | 98.83 | 64.08 | 54.23 | 79.74 | 58.81 | 1.61 | 56.68 | 60.51 | 74.89 |
| DRIN | Sia-3DCNN | 3DCSN | S3Net | ALPN | FAAL | CFSL | Gia-CFSL | Proposed AL-MRIS | |
|---|---|---|---|---|---|---|---|---|---|
| OA (%) | 63.91 ± 3.28 | 50.34 ± 2.81 | 59.62 ± 3.20 | 66.66 ± 1.88 | 60.98 ± 1.09 | 32.42 ± 4.26 | 68.47 ± 2.79 | 56.00 ± 5.62 | 75.31 ± 2.09 |
| AA (%) | 78.16 ± 1.67 | 64.84 ± 3.49 | 74.33 ± 2.47 | 79.66 ± 2.35 | 69.49 ± 1.38 | 45.28 ± 3.21 | 77.13 ± 2.43 | 68.62 ± 3.48 | 78.69 ± 2.09 |
| Kappa × 100 | 56.87 ± 3.42 | 44.68 ± 2.94 | 54.83 ± 3.49 | 62.85 ± 2.05 | 55.71 ± 1.29 | 52.92 ± 3.65 | 64.84 ± 2.56 | 50.60 ± 5.97 | 71.86 ± 2.26 |
| Alfalfa | 100 | 90.69 | 97.67 | 100 | 100 | 72.09 | 83.72 | 95.34 | 100 |
| Corn-notill | 30.31 | 39.92 | 31.01 | 55.12 | 39.18 | 29.37 | 53.89 | 59.37 | 72.75 |
| Corn-mintill | 57.67 | 21.88 | 61.54 | 54.17 | 22.88 | 2.52 | 81.98 | 77.53 | 69.93 |
| Corn | 100 | 54.27 | 90.17 | 82.48 | 75.53 | 20.08 | 38.88 | 94.44 | 97.31 |
| Grass-pasture | 63.12 | 60.41 | 64.58 | 84.61 | 69.10 | 10.98 | 71.45 | 65.62 | 91.68 |
| Grass-trees | 95.59 | 93.94 | 91.61 | 91.75 | 95.59 | 64.99 | 81.15 | 76.25 | 96.50 |
| Grass-pasture-mowed | 100 | 100 | 100 | 100 | 100 | 50.00 | 100 | 100 | 100 |
| Hay-windrowed | 95.36 | 79.36 | 88.21 | 99.21 | 74.05 | 62.76 | 99.36 | 95.57 | 99.13 |
| Oats | 100 | 88.23 | 100 | 100 | 100 | 73.68 | 100 | 100 | 100 |
| Soybean-notill | 70.89 | 65.12 | 53.56 | 98.71 | 40.80 | 28.08 | 75.23 | 46.59 | 72.51 |
| Soybean-mintill | 57.25 | 27.36 | 47.96 | 46.31 | 41.91 | 58.34 | 63.25 | 35.91 | 69.05 |
| Soybean-clean | 56.61 | 38.13 | 20.11 | 56.21 | 25.97 | 11.48 | 68.64 | 75.59 | 63.03 |
| Wheat | 100 | 74.25 | 76.73 | 99.62 | 82.58 | 36.66 | 100 | 92.43 | 99.47 |
| Woods | 99.68 | 69.17 | 34.07 | 89.31 | 87.71 | 81.79 | 31.69 | 81.11 | 94.16 |
| Buildings-Grass-Trees-Drives | 63.44 | 66.57 | 64.75 | 72.45 | 47.64 | 16.95 | 77.75 | 75.14 | 94.07 |
| Stone-Steel-Towers | 99.67 | 97.77 | 95.55 | 98.89 | 98.87 | 70.73 | 100 | 100 | 100 |
| DRIN | Sia-3DCNN | 3DCSN | S3Net | ALPN | FAAL | CFSL | Gia-CFSL | Proposed AL-MRIS | |
|---|---|---|---|---|---|---|---|---|---|
| OA (%) | 87.42 ± 5.07 | 85.62 ± 2.07 | 88.20 ± 1.97 | 88.84 ± 3.21 | 79.84 ± 0.61 | 62.57 ± 4.28 | 79.57 ± 2.45 | 87.44 ± 1.91 | 90.18 ± 1.79 |
| AA (%) | 90.13 ± 2.49 | 88.55 ± 2.05 | 91.44 ± 1.48 | 92.39 ± 1.24 | 91.83 ± 0.39 | 62.47 ± 3.65 | 92.19 ± 2.18 | 91.13 ± 2.22 | 92.79 ± 2.25 |
| Kappa × 100 | 86.08 ± 5.54 | 84.02 ± 2.27 | 86.90 ± 2.16 | 87.62 ± 3.53 | 77.83 ± 0.64 | 58.06 ± 4.89 | 77.63 ± 2.61 | 86.03 ± 2.13 | 89.05 ± 1.99 |
| Brocoli_green_weeds_1 | 98.05 | 90.01 | 93.07 | 100 | 97.95 | 99.28 | 93.96 | 92.82 | 99.70 |
| Brocoli_green_weeds_2 | 100 | 98.92 | 98.41 | 83.81 | 95.13 | 95.07 | 100 | 100 | 99.11 |
| Fallow | 99.89 | 99.13 | 99.34 | 93.76 | 97.87 | 65.84 | 89.05 | 92.56 | 100 |
| Fallow_rough_plow | 98.56 | 98.71 | 71.02 | 99.07 | 97.91 | 69.58 | 100 | 100 | 98.41 |
| Fallow_smooth | 94.65 | 89.98 | 83.73 | 99.96 | 82.91 | 54.41 | 93.75 | 90.15 | 95.72 |
| Stubble | 97.69 | 87.63 | 94.38 | 95.73 | 83.74 | 91.26 | 100 | 87.26 | 90.40 |
| Celery | 98.82 | 92.95 | 98.99 | 100 | 88.17 | 98.65 | 100 | 48.16 | 99.32 |
| Grapes_untrained | 18.19 | 88.55 | 85.51 | 61.43 | 54.81 | 85.83 | 7.81 | 87.84 | 91.49 |
| Soil_vinyard_develop | 99.90 | 98.45 | 99.22 | 100 | 96.98 | 13.31 | 99.88 | 98.72 | 96.09 |
| Corn_senesced_green_weeds | 89.19 | 32.51 | 90.04 | 94.05 | 57.25 | 81.58 | 97.92 | 94.16 | 95.56 |
| Lettuce_romaine_4wk | 98.87 | 92.11 | 96.61 | 100 | 91.92 | 73.32 | 99.43 | 100 | 97.54 |
| Lettuce_romaine_5wk | 96.04 | 89.71 | 92.09 | 94.29 | 95.47 | 55.21 | 99.74 | 89.48 | 94.41 |
| Lettuce_romaine_6wk | 98.13 | 99.56 | 98.91 | 82.09 | 98.02 | 97.77 | 100 | 100 | 100 |
| Lettuce_romaine_7wk | 98.21 | 98.21 | 92.41 | 98.03 | 95.12 | 39.96 | 99.71 | 97.78 | 97.35 |
| Vinyard_untrained | 98.03 | 70.43 | 60.51 | 80.99 | 91.85 | 42.18 | 99.46 | 65.88 | 84.23 |
| Vinyard_vertical_trellis | 96.51 | 78.54 | 82.15 | 98.45 | 84.58 | 13.44 | 100 | 90.28 | 99.67 |
| Euclidean Distance | Manhattan Distance | Jensen–Shannon Distance | Cosine Distance | |
|---|---|---|---|---|
| OA (%) | 82.77 | 80.07 | 79.31 | 84.71 |
| AA (%) | 79.96 | 75.29 | 76.18 | 82.27 |
| Kappa × 100 | 77.32 | 74.01 | 72.34 | 79.81 |
| No Siamese | No AL | No MIRN | Proposed AL-MRIS | |
|---|---|---|---|---|
| OA (%) | 66.72 | 74.51 | 64.42 | 84.71 |
| AA (%) | 62.15 | 73.01 | 50.86 | 82.27 |
| Kappa × 100 | 57.41 | 68.82 | 52.51 | 79.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Qin, J.; Qian, J.; Li, A.; Wang, L. AL-MRIS: An Active Learning-Based Multipath Residual Involution Siamese Network for Few-Shot Hyperspectral Image Classification. Remote Sens. 2024, 16, 990. https://0-doi-org.brum.beds.ac.uk/10.3390/rs16060990
Yang J, Qin J, Qian J, Li A, Wang L. AL-MRIS: An Active Learning-Based Multipath Residual Involution Siamese Network for Few-Shot Hyperspectral Image Classification. Remote Sensing. 2024; 16(6):990. https://0-doi-org.brum.beds.ac.uk/10.3390/rs16060990
Chicago/Turabian StyleYang, Jinghui, Jia Qin, Jinxi Qian, Anqi Li, and Liguo Wang. 2024. "AL-MRIS: An Active Learning-Based Multipath Residual Involution Siamese Network for Few-Shot Hyperspectral Image Classification" Remote Sensing 16, no. 6: 990. https://0-doi-org.brum.beds.ac.uk/10.3390/rs16060990