
YOLOv7-GCA: A Lightweight and High-Performance Model for Pepper Disease Detection
 ,
,
Abstract
:1. Introduction
- (1)
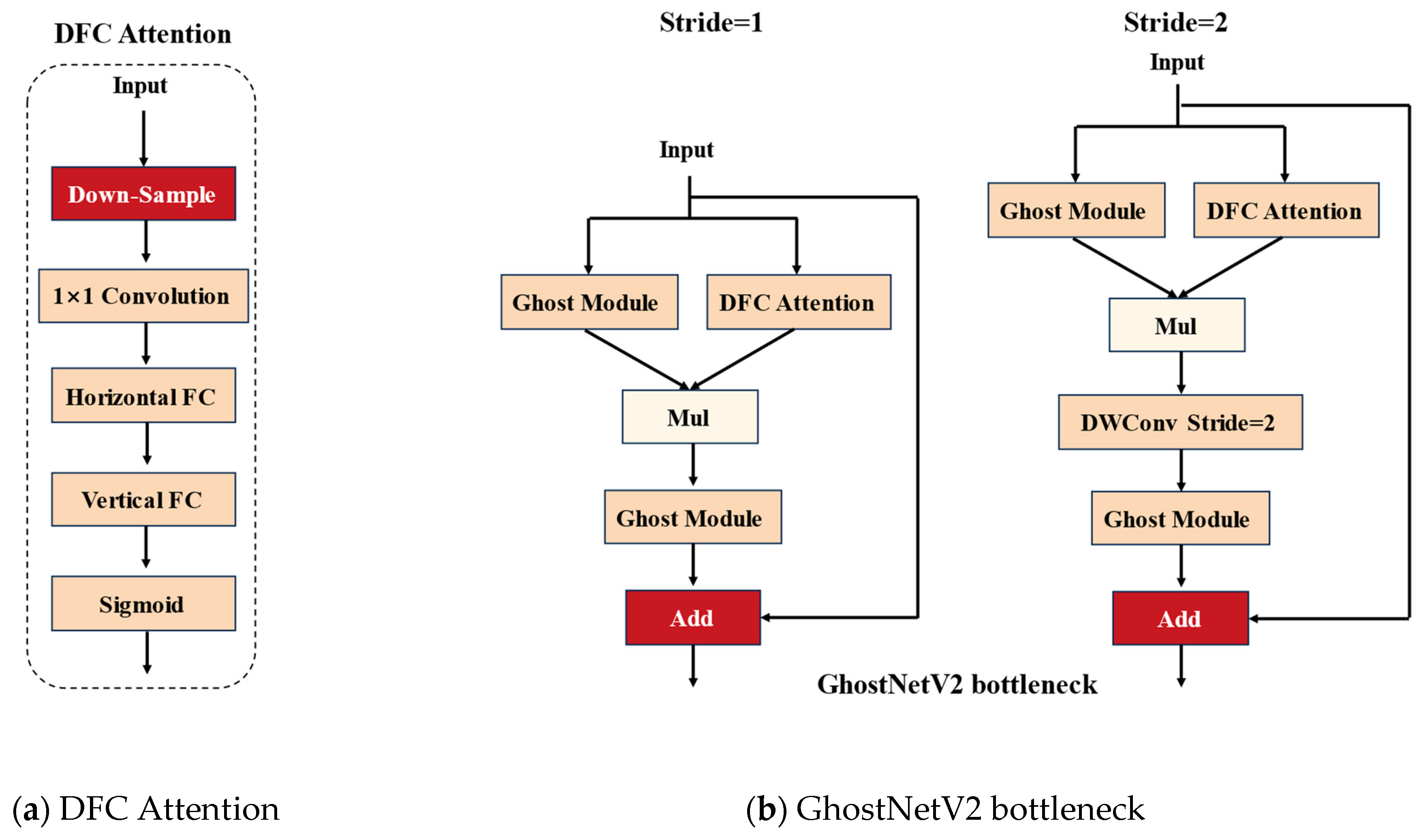
- Incorporating GhostNetV2 [29] as the backbone network, which can reduce the number of parameters caused by unnecessary feature computation, enhance the detection speed, and reduce the computing cost while ensuring high performance.
- (2)
- To tackle the problem of complex backgrounds, Cascade Fusion Network (CFNet) [30] is integrated as a feature fusion network, which enables more parameters to be used for feature fusion and improves the performance of the model.
- (3)
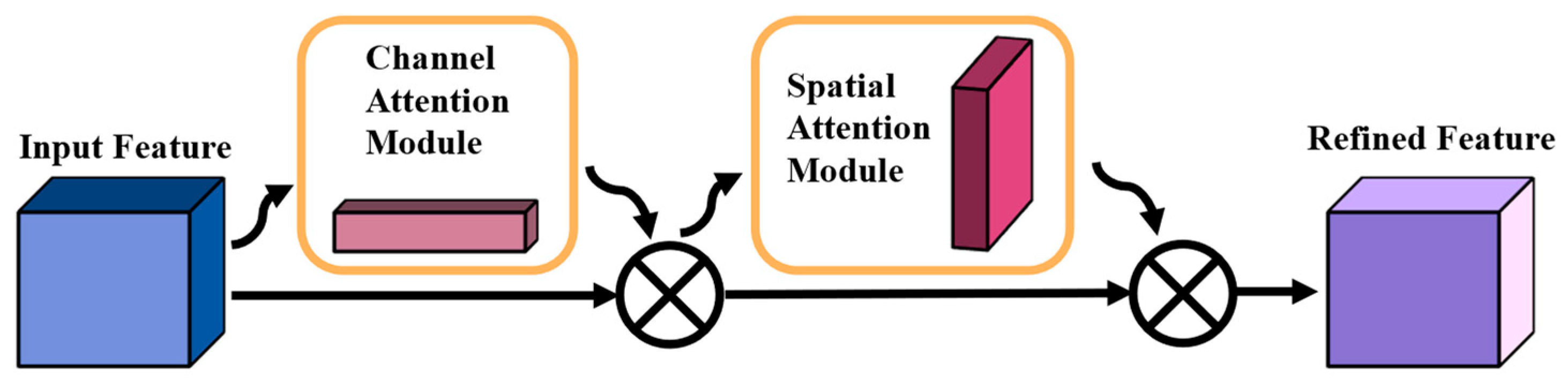
- The convolutional Block Attention Module (CBAM) [31] is introduced to improve the model by emphasizing only key features. In this way, the model can better distinguish the features of different channels and better capture key information in space, thus improving its feature extraction ability.
2. Materials and Methods
2.1. Materials
2.1.1. Data Acquisition
- (1)
- The image resolution is 3072 × 4093, and the shooting device is a Xiaomi13 smartphone (Xiaomi Corporation, Beijing, China). The maximum pixel value of the camera is 50 million;
- (2)
- The images contain pepper fruits and leaves with different diseases, but the umbilical rot has only the disease fruit image, and the bacterial disease only the disease has leaf image;
- (3)
- There are some complex background factors in the image, such as occlusion, overlap, blur, and small objects.
2.1.2. Data Augmentation
2.2. YOLOv7-GCA Construction
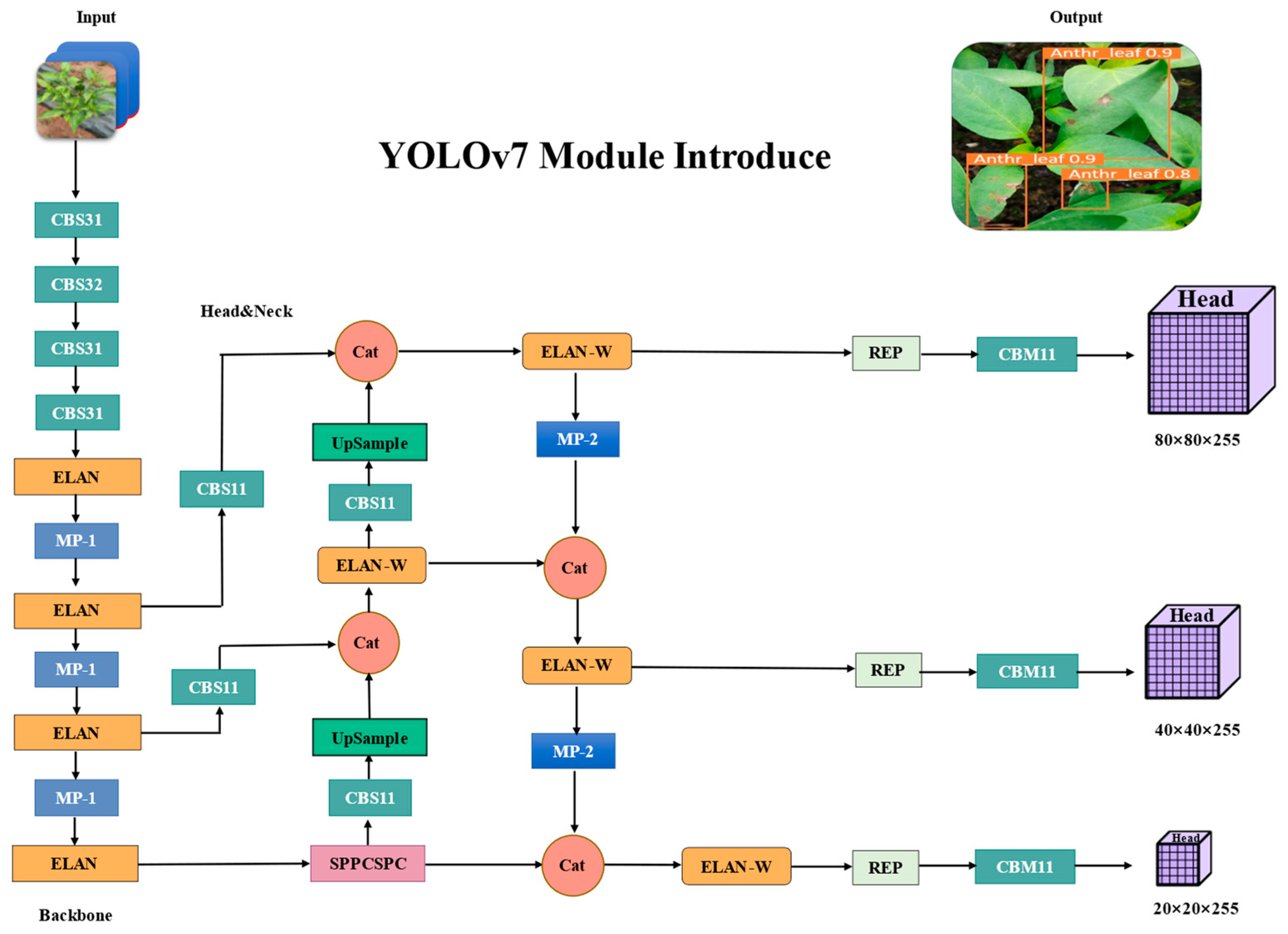
2.2.1. YOLOv7: Expand Efficient Layer Aggregation Networks
2.2.2. Lightweight Feature Extraction Module GhostNetV2
2.2.3. Attention Mechanism: Selectively Paying Attention to Information
2.2.4. Multi-Scale Fusion Method: CFNet
2.2.5. Improved Loss Function
2.2.6. YOLOv7-GCA Model
2.3. Training Environment and Evaluation Indicators
3. Results and Discussion
3.1. Model Training Results
3.2. Ablation Experiment
3.3. Comparison of Different Network Models
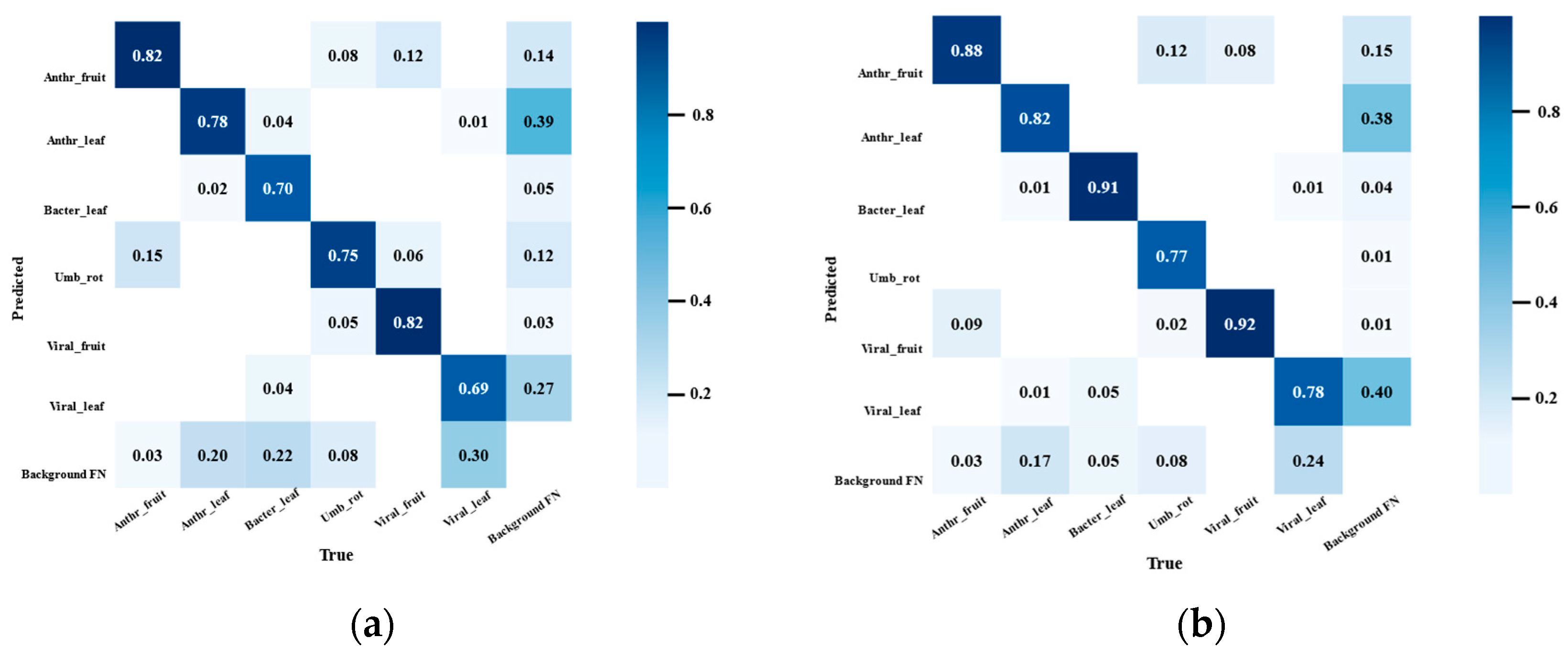
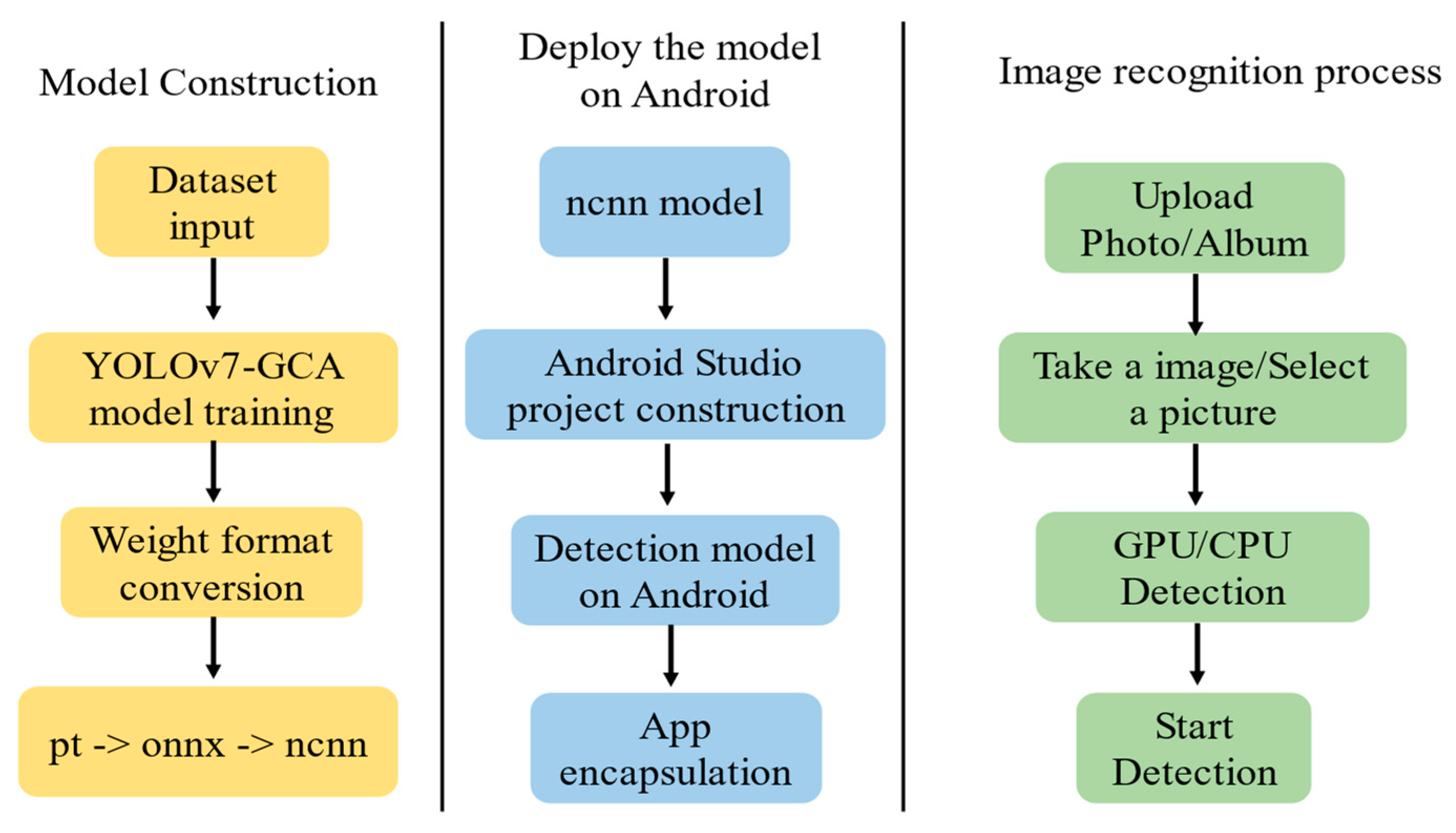
3.4. Android Deployment Testing
3.5. Sensitivity Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Karim, K.M.R.; Rafii, M.Y.; Misran, A.B.; Ismail, M.F.B.; Harun, A.R.; Khan, M.M.H.; Chowdhury, M.F.N. Current and Prospective Strategies in the Varietal Improvement of Chilli (Capsicum annuum L.) Specially Heterosis Breeding. Agronomy 2021, 11, 2217. [Google Scholar] [CrossRef]
- Olatunji, T.L.; Afolayan, A.J. The suitability of chili pepper (Capsicum annuum L.) for alleviating human micronutrient dietary deficiencies: A review. Food Sci. Nutr. 2018, 6, 2239–2251. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, H.F.A.; Seleiman, M.F.; Mohamed, I.A.A.; Taha, R.S.; Wasonga, D.O.; Battaglia, M.L. Activity of Essential Oils and Plant Extracts as Biofungicides for Suppression of Soil-Borne Fungi Associated with Root Rot and Wilt of Marigold (Calendula officinalis L.). Horticulturae 2023, 9, 222. [Google Scholar] [CrossRef]
- Ahmed, H.F.A.; Elnaggar, S.; Abdel-Wahed, G.A.; Taha, R.S.; Ahmad, A.; Al-Selwey, W.A.; Ahmed, H.M.H.; Khan, N.; Seleiman, M.F. Induction of Systemic Resistance in Hibiscus sabdariffa Linn. to Control Root Rot and Wilt Diseases Using Biotic and Abiotic Inducers. Biology 2023, 12, 789. [Google Scholar] [CrossRef] [PubMed]
- Saleem, M.H.; Potgieter, J.; Arif, K.M. Automation in Agriculture by Machine and Deep Learning Techniques: A Review of Recent Developments. Precis. Agric. 2021, 22, 2053–2091. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, X.; Au, W.; Kang, H.; Chen, C. Intelligent robots for fruit harvesting: Recent developments and future challenges. Precis. Agric. 2022, 23, 1856–1907. [Google Scholar] [CrossRef]
- Li, L.; Zhang, S.; Wang, B. Plant Disease Detection and Classification by Deep Learning—A Review. IEEE Access 2021, 9, 56683–56698. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, S.; Yang, J.; Shi, Y.; Chen, J. Apple leaf disease identification using genetic algorithm and correlation based feature selection method. Int. J. Agric. Biol. Eng. 2017, 10, 74–83. [Google Scholar]
- Chakraborty, S.; Paul, S.; Rahat-uz-Zaman, M. Prediction of Apple Leaf Diseases Using Multiclass Support Vector Machine. In Proceedings of the 2021 2nd International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST), Dhaka, Bangladesh, 5–7 January 2021. [Google Scholar]
- Zhang, S.; Wu, X.; You, Z.; Zhang, L. Leaf image based cucumber disease recognition using sparse representation classification. Comput. Electron. Agric. 2017, 134, 135–141. [Google Scholar] [CrossRef]
- Singh, A.K.; Sreenivasu, S.V.N.; Mahalaxmi, U.S.B.K.; Sharma, H.; Patil, D.D.; Asenso, E. Hybrid Feature-Based Disease Detection in Plant Leaf Using Convolutional Neural Network, Bayesian Optimized SVM, and Random Forest Classifier. J. Food Qual. 2022, 2022, 2845320. [Google Scholar] [CrossRef]
- Loti, N.N.A.; Noor, M.R.M.; Chang, S.-W. Integrated Analysis of Machine Learning and Deep Learning in Chili Pest and Disease Identification. J. Sci. Food Agric. 2020, 101, 3582–3594. [Google Scholar] [CrossRef]
- Neupane, K.; Baysal-Gurel, F. Automatic Identification and Monitoring of Plant Diseases Using Unmanned Aerial Vehicles: A Review. Remote Sens. 2021, 13, 3841. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Zhang, K.; Wu, Q.; Chen, Y. Detecting soybean leaf disease from synthetic image using multi-feature fusion faster R-CNN. Comput. Electron. Agric. 2021, 183, 106064. [Google Scholar] [CrossRef]
- Sun, H.; Xu, H.; Liu, B.; He, D.; He, J.; Zhang, H.; Geng, N. MEAN-SSD: A novel real-time detector for apple leaf diseases using improved light-weight convolutional neural networks. Comput. Electron. Agric. 2021, 189, 106379. [Google Scholar] [CrossRef]
- Bao, W.; Fan, T.; Hu, G.; Liang, D.; Li, H. Detection and identification of tea leaf diseases based on AX-RetinaNet. Sci. Rep. 2022, 12, 2183. [Google Scholar] [CrossRef] [PubMed]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef]
- Lippi, M.; Bonucci, N.; Carpio, R.F.; Contarini, M.; Speranza, S.; Gasparri, A. A YOLO-Based Pest Detection System for Precision Agriculture. In Proceedings of the 2021 29th Mediterranean Conference on Control and Automation (MED), Puglia, Italy, 22–25 June 2021. [Google Scholar]
- Liu, J.; Wang, X. Plant diseases and pests detection based on deep learning: A review. Plant Methods 2021, 17, 22. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X. Tomato Diseases and Pests Detection Based on Improved Yolo V3 Convolutional Neural Network. Front. Plant Sci. 2020, 11, 521544. [Google Scholar] [CrossRef]
- Wang, X.; Liu, J. Tomato Anomalies Detection in Greenhouse Scenarios Based on YOLO-Dense. Front. Plant Sci. 2021, 12, 634103. [Google Scholar] [CrossRef]
- Li, D.; Ahmed, F.; Wu, N.; Sethi, A.I. YOLO-JD: A Deep Learning Network for Jute Diseases and Pests Detection from Images. Plants 2022, 11, 937. [Google Scholar] [CrossRef]
- Fang, W.; Guan, F.; Yu, H.; Bi, C.; Guo, Y.; Cui, Y.; Su, L.; Zhang, Z.; Xie, J. Identification of wormholes in soybean leaves based on multi-feature structure and attention mechanism. J. Plant Dis. Prot. 2022, 130, 401–412. [Google Scholar] [CrossRef]
- Xue, Z.; Xu, R.; Bai, D.; Lin, H. YOLO-Tea: A Tea Disease Detection Model Improved by YOLOv5. Forests 2023, 14, 415. [Google Scholar] [CrossRef]
- Xu, W.; Wang, R. ALAD-YOLO: An lightweight and accurate detector for apple leaf diseases. Front. Plant Sci. 2023, 14, 1204569. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Xing, Z.; Wang, H.; Dong, X.; Gao, X.; Liu, Z.; Zhang, X.; Li, S.; Zhao, Y. Maize-YOLO: A New High-Precision and Real-Time Method for Maize Pest Detection. Insects 2023, 14, 278. [Google Scholar] [CrossRef] [PubMed]
- Jia, L.; Wang, T.; Chen, Y.; Zang, Y.; Li, X.; Shi, H.; Gao, L. MobileNet-CA-YOLO: An Improved YOLOv7 Based on the MobileNetV3 and Attention Mechanism for Rice Pests and Diseases Detection. Agriculture 2023, 13, 1285. [Google Scholar] [CrossRef]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance cheap operation with long-range attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- Zhang, G.; Li, Z.; Li, J.; Hu, X. Cfnet: Cascade fusion network for dense prediction. arXiv 2023, arXiv:2302.06052. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Germany, 2018. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Ying, Z.; Li, G.; Ren, Y.; Wang, R.; Wang, W. A New Image Contrast Enhancement Algorithm Using Exposure Fusion Framework. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Germany, 2017; pp. 36–46. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13001–13008. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Takahashi, R.; Matsubara, T.; Uehara, K. Data Augmentation Using Random Image Cropping and Patching for Deep CNNs. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2917–2931. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- WongKinYiu. YOLOv7.Git Code. 2022. Available online: https://github.com/WongKinYiu/yolov7 (accessed on 20 November 2022).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Lv, Y.; Ai, Z.; Chen, M.; Gong, X.; Wang, Y.; Lu, Z. High-Resolution Drone Detection Based on Background Difference and SAG-YOLOv5s. Sensors 2022, 22, 5825. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Number | Label | Characteristics | Picture |
|---|---|---|---|---|
| Anthracnose_leaf | 232 | Anthr_leaf | At the beginning of the disease, the leaves showed chlorotic water stain spots, brown round spots with the aggravation of the disease, and small black spots on the late spots. |  |
| Anthracnose_fruit | 216 | Anthr_fruit | At the beginning of the disease, the fruit has irregular or oblong brown spots, the surface of the fruit is sunken, with the aggravation of the disease, the disease spots are dry, and the spots are membranous and easy to rupture. |  |
| Viral diseases_leaf | 251 | Viral_leaf | The diseased leaves are slightly chlorotic, and also show the diseased leaves and wrinkled deformity, and the leaf surface is uneven. When severe, the leaves become hard and thick, the leaf edge curls upward, and the young leaves show linear leaves. |  |
| Viral diseases_fruit | 187 | Viral_fruit | Fruit characteristics of virus disease: the fruit faded to yellow brown, with brown necrotic spots on the fruit. |  |
| Bacterial diseases_leaf | 163 | Bacter_leaf | After leaf disease, the initial symptoms are small green-yellow spots, water stains that gradually expand and deepen, and brown or rusty, membranous. The spots expand rapidly until most of the leaves of the pepper plants wither and fall. |  |
| Umbilical rot | 210 | Umb_rot | Pepper umbilical rot mainly occurs near the umbilicus of the fruit. At the early stage of the disease, water-stained green spots are formed in the umbilicus of the young fruit and green fruit. With the development of the fruit, the disease is grayish brown or white flat depression, and the disease can expand to half the fruit. |  |
| Name | Proportion | Number of Pictures | Number of Labels | |
|---|---|---|---|---|
| Dataset | Training Set | 80% | 1007 | 2066 |
| Validation Set | 10% | 126 | 267 | |
| Test Set | 10% | 126 | 255 | |
| Total | 100% | 1259 | 2588 |
| Model | [email protected] (%) | Model Size (MB) | FPS (Frames/s) | P (%) | R (%) | Params (M) |
|---|---|---|---|---|---|---|
| YOLOv7 | 83.4 | 71.3 | 178 | 85.6 | 77.9 | 35.49 |
| YOLOv7 + GN | 82.8 | 58.2 | 213 | 81.3 | 75.6 | 28.83 |
| YOLOv7 + CF | 83.53 | 60.3 | 200 | 87.3 | 71.1 | 29.98 |
| YOLOv7 + CBAM | 83.7 | 71.1 | 198 | 84.5 | 79.6 | 35.38 |
| YOLOv7 + GN + CBAM | 88.6 | 58.5 | 279 | 90.6 | 77.8 | 28.94 |
| YOLOv7 + GN + CF | 88.2 | 47.1 | 286 | 91.3 | 76.4 | 23.43 |
| YOLOv7 + CF + CBAM | 90.8 | 60.1 | 271 | 93.5 | 83.3 | 29.87 |
| YOLOv7-GCA | 96.8 | 46.9 | 303 | 95.7 | 93.8 | 23.32 |
| Model | Backbone Network | [email protected] (%) | FPS (Frames/s) | P (%) | R (%) | Params (MB) | FLOPs (G) |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | ResNet-50 | 80.5 | 20 | 76.4 | 87.1 | 157.22 | 366.72 |
| SSD | VGG16 | 71.2 | 36 | 72.3 | 65.5 | 24.55 | 270.15 |
| YOLOv3 | CSPDarknet53 | 77.8 | 53 | 78.3 | 73.5 | 58.64 | 155.15 |
| YOLOv5s | CSPDarknet53 | 82.8 | 156 | 81.6 | 79.8 | 9.23 | 18.13 |
| YOLOv8n | SPPCSPResNet52 | 84.1 | 183 | 84.7 | 78.1 | 6.31 | 9.55 |
| YOLOv7 | SPPCSPCDarkNet50 | 83.4 | 178 | 85.6 | 77.9 | 35.49 | 103.12 |
| YOLOv7-GCA | SPPCSPCDarkNet58 | 96.8 | 303 | 95.7 | 93.8 | 23.32 | 65.63 |
| Index | Number | Loss Function | [email protected] (%) | FPS (Frames/s) |
|---|---|---|---|---|
| Learning Rate | 0.001 | 0.03705 | 95.5 | 301 |
| Learning Rate | 0.01 | 0.03635 | 96.8 | 303 |
| Learning Rate | 0.1 | 0.04175 | 93.4 | 305 |
| Batch Size | 16 | 0.03635 | 96.8 | 303 |
| Batch Size | 32 | 0.03685 | 96.4 | 313 |
| Batch Size | 64 | 0.03715 | 96.1 | 323 |
| Optimization Function | Adam | 0.03675 | 96.2 | 303 |
| Optimization Function | SGD | 0.03635 | 96.8 | 303 |
| Optimization Function | RMSprop | 0.03655 | 96.3 | 303 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, X.; Li, H.; Song, Q.; Zeng, F.; Zheng, J.; Ding, Z.; Kang, G.; Cai, Y.; Lin, Y.; Xu, X.; et al. YOLOv7-GCA: A Lightweight and High-Performance Model for Pepper Disease Detection. Agronomy 2024, 14, 618. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy14030618
Yue X, Li H, Song Q, Zeng F, Zheng J, Ding Z, Kang G, Cai Y, Lin Y, Xu X, et al. YOLOv7-GCA: A Lightweight and High-Performance Model for Pepper Disease Detection. Agronomy. 2024; 14(3):618. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy14030618
Chicago/Turabian StyleYue, Xuejun, Haifeng Li, Qingkui Song, Fanguo Zeng, Jianyu Zheng, Ziyu Ding, Gaobi Kang, Yulin Cai, Yongda Lin, Xiaowan Xu, and et al. 2024. "YOLOv7-GCA: A Lightweight and High-Performance Model for Pepper Disease Detection" Agronomy 14, no. 3: 618. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy14030618