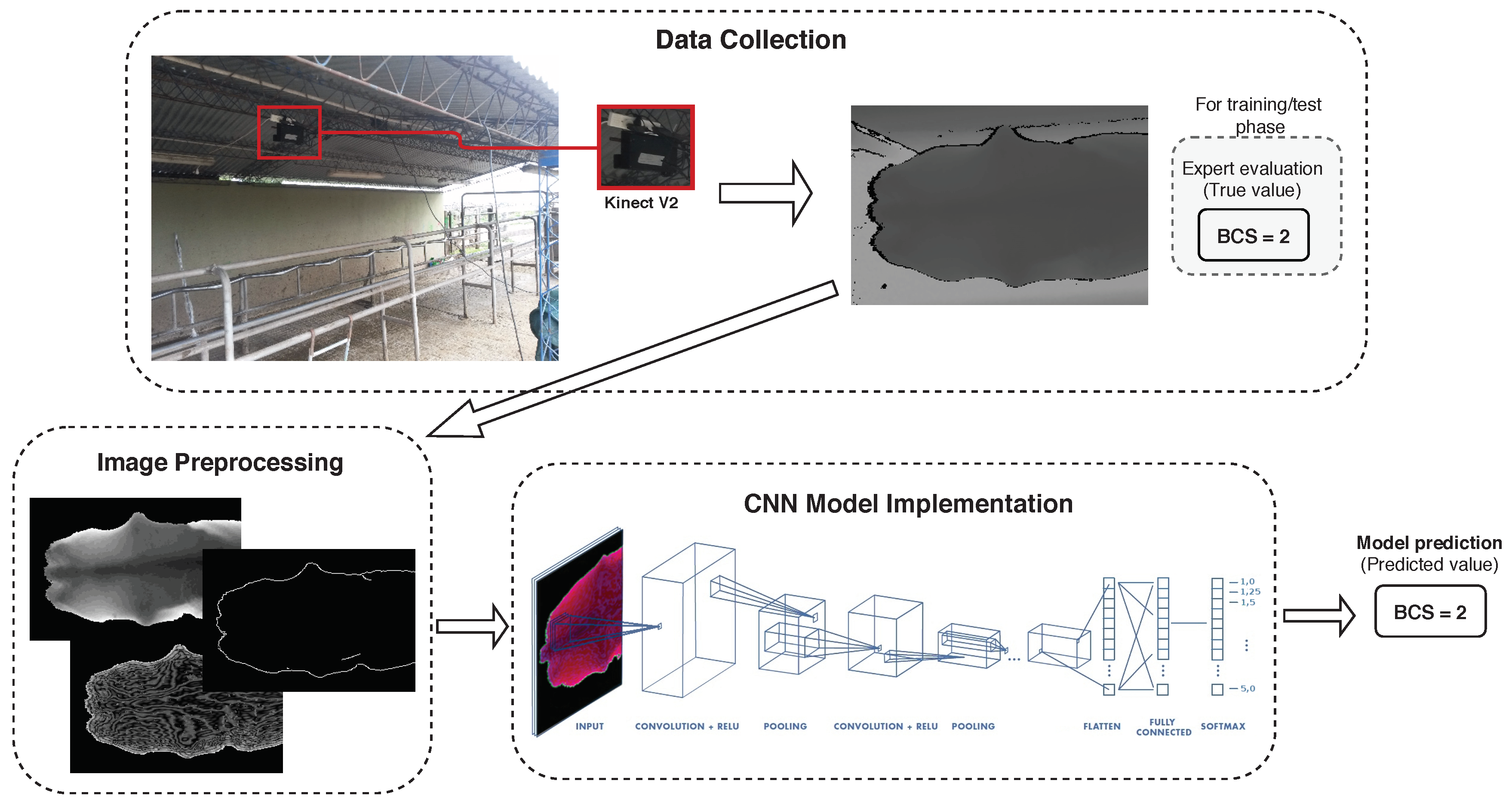
1. Introduction
BCS (“Body Condition Score”) is a technique for visually estimating body fat reserves which have no direct correlation with body weight and frame size [
1]. BCS is a 5-point scale system with 0.25-point intervals; in this system, cows with a score of 1 are emaciated, while cows with a score of 5 are obese [
2,
3]. BCS is especially important for dairy cows as it is not only a measurement of obesity degree, but also a suitable assessment of feeding management according to each stage of lactation, which heavily influences milk production, reproduction, and cow health. Despite its importance, BCS is currently a time-consuming manual task performed by expert. Furthermore, results are subjective as the experts estimate BCS scores relaying only in a naked-eye inspection and their experience.
The increasing advances in technology availability at an accessible cost, automation, and digitalization of livestock farming tasks offer multiple opportunities to aid BCS estimation. In this context, different studies have particularly focused on BCS automation using digital images [
4,
5,
6,
7,
8,
9,
10]. In these works the traditional model of pattern/image recognition was applied, in which a by hand-designed feature extractor gathers relevant information from the input image. Then, features are used to train a classifier (or a regression model), which outputs the class (or value) corresponding to an input image.
However, an alternative technique from the field of Deep Leaning, known as Convolutional Neural Network (CNN), has been found highly effective and been commonly used in computer vision and image classification [
11,
12,
13,
14,
15]. A CNN is a specialized kind of neural network with a particular architecture composed of a sequence three types of layers: convolutional, pooling (or subsampling) and fully-connected. In a CNN, convolution and pooling layers play the role of feature extractor, where the weights (model coefficients or parameters) of the convolutional layer being used for feature extraction as well as the fully connected layer being used for classification are automatically determined during the training process [
12]. Thus, CNNs have the advantage of locating the important features itself through training, reducing the need for by-hand feature engineering, which is a complex, time-consuming, and experts’ knowledge dependent process, whose performance could affect the overall results [
16].
Although CNNs, and more generally deep learning techniques, have been successfully applied in various domains, its adoption in agriculture tasks is relatively recent. Kamilaris et al. [
16] have performed a survey of 40 research works that employ deep learning techniques in the agriculture domain, among which only 3 works correspond to livestock activities. Within these, Demmers et al. [
17,
18] have developed first order DRNN (Differential Recurrent Neural Networks) models to control and predict growth of pigs and broiler chickens (by estimating their weight) using field sensory data and a combination of static and dynamic environmental variables. Santoni et al. [
19] have built a CNN model to classify cattles into 5 different races using grayscale images.
That is why, with the objective to exploit the benefits of deep learning in the cows’ BCS estimation problem, a novel CNN-based model was proposed in a recent published work [
15] to estimate BCS on cows from depth images. The development system has achieved very good results in comparison with related works, improving the classification accuracy within different error ranges (0.25, 0.50 BCS units) which are measures commonly used in literature to analyze model efficiency. However, obtaining close-to-ideal BCS estimations is still an open problem, so a detailed analysis of potential improvements could be carried out taking into account other model configurations and strategies. Particularly, two of the strategies considered in this work are transfer learning and model ensembling. Transfer learning aims to extract and transfer the knowledge from some source tasks to a target task when the latter has fewer high-quality training data [
20]. The main goal of this technique is to train the lower network layers, i.e., the ones which are closest to the input, which are likely to learn general features that can be fed to classifier, usually a shallow neural network, with less variance than a full deep neural network. On the other hand, model ensembling is a machine learning technique that combines the decisions from multiple models to improve the overall performance, based on the concept that a diverse set of model are likely to make better predictions in comparison to single models like [
15].
Therefore, the aim of this work is to develop alternative models employing different architecture configurations and commonly used techniques in deep learning area to study and analyze their impact and benefits when estimating BCS on cows. The next Section discusses the data used to train and test the system, explains the use of CNNs for the problem at hand, and presents our improvements to the approach first described in [
15].
Section 3 analyzes the obtained results. Finally,
Section 4 concludes the paper.
3. Results and Discussion
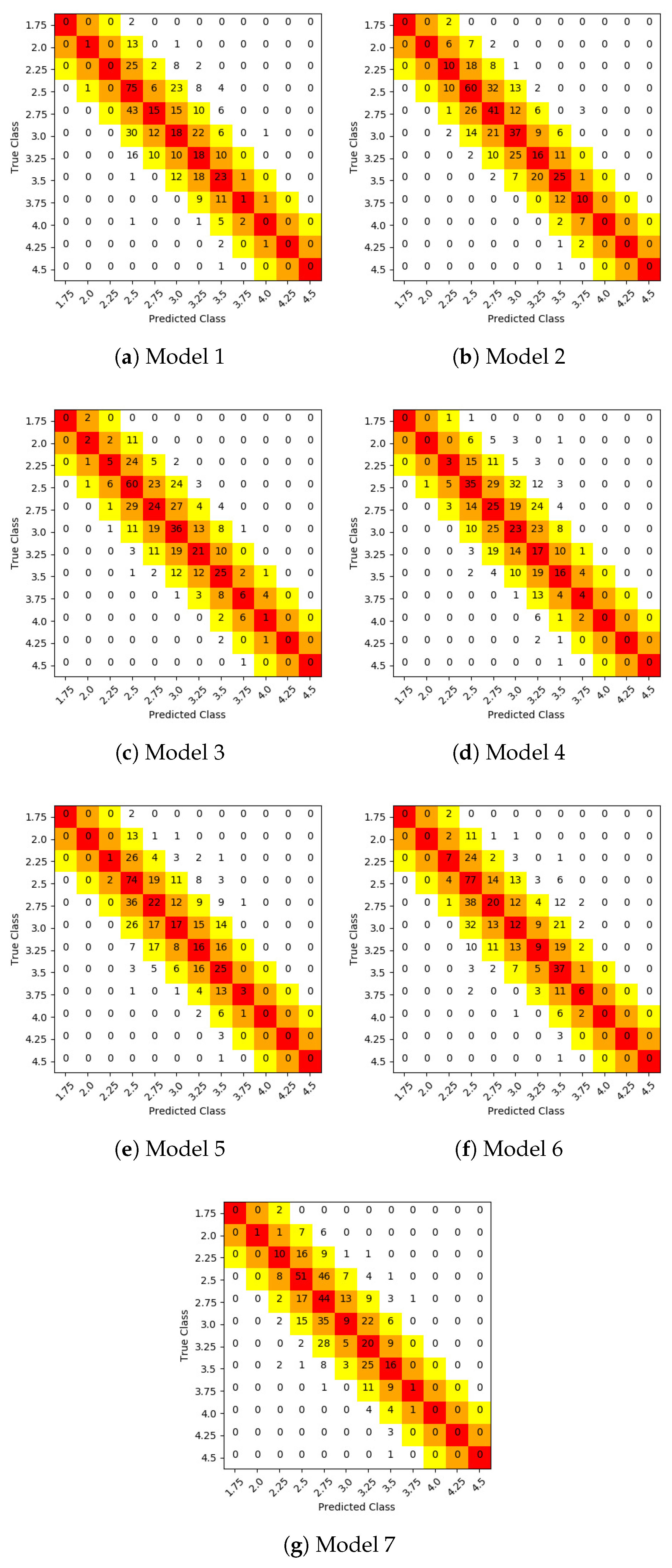
Figure 6 shows the confusion matrices of test samples classification of the individual models (first 7 models). The concept of predictions over the main diagonal of the confusion matrix was expanded and represented by a color scale (from red to yellow) in order to contemplate different human error ranges. Particularly, red cells represent exact predictions, orange cells represent predictions with 0.25 units of error, and yellow cells represent predictions with 0.50 units of error. This representation allows to simplify the calculation of the remaining metrics, which use confusion matrix values taking into account different error ranges.
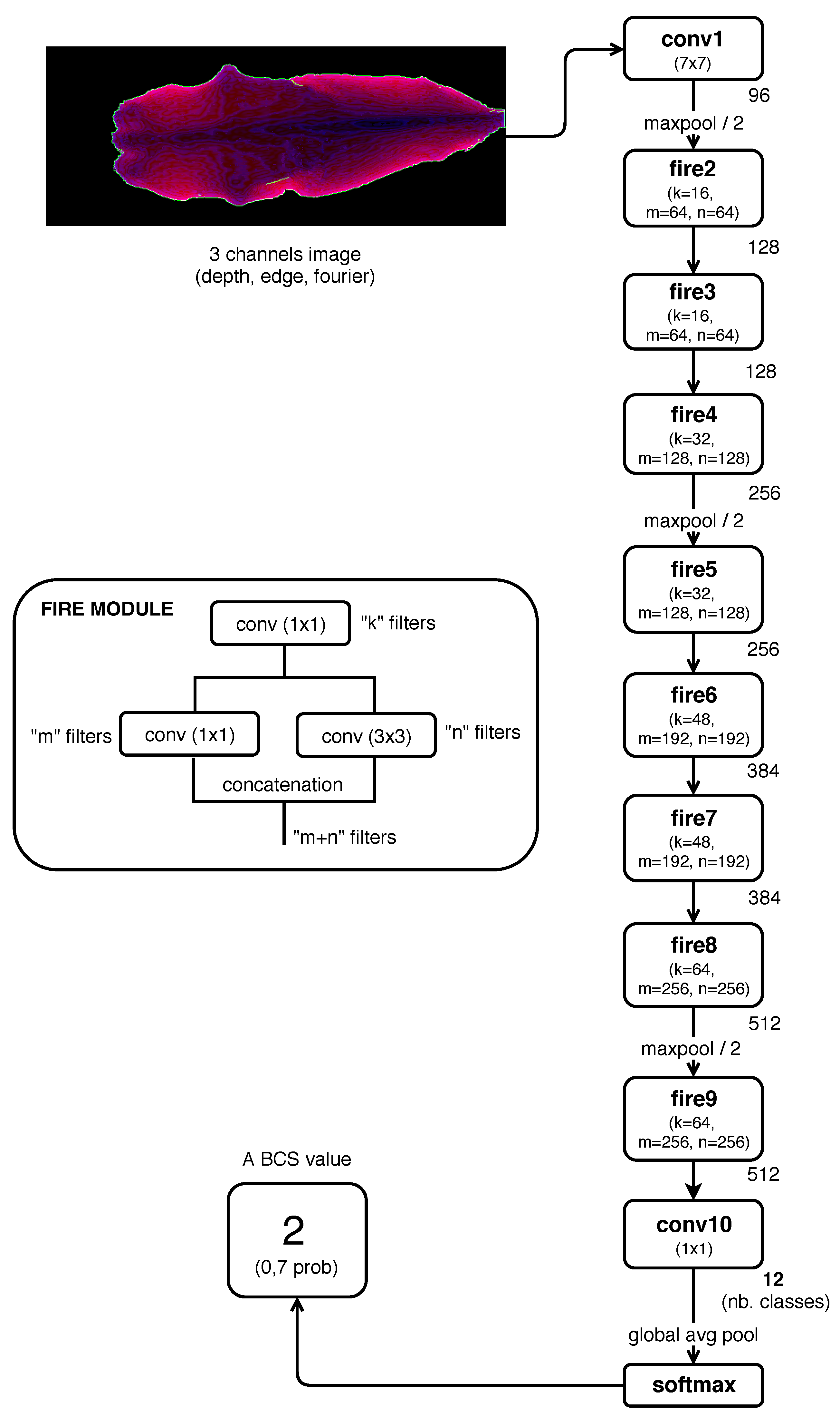
Table 2 shows micro-averaged accuracies of individual models. According to this comparison, Model 2 has achieved the best results regardless of human error range. This is one of the model trained from scratch, using input images composed by Depth and Edge channels.
A more detailed evaluation is shown in
Table 3,
Table 4 and
Table 5. These tables show precision, recall and F1-score evaluations per BCS values (class) in the test set, where particularly
Table 3 considers exact predictions,
Table 4 considers predictions within 0.25 units of error between true and predicted BCS values, and
Table 5 considers predictions within 0.50 units of differences.
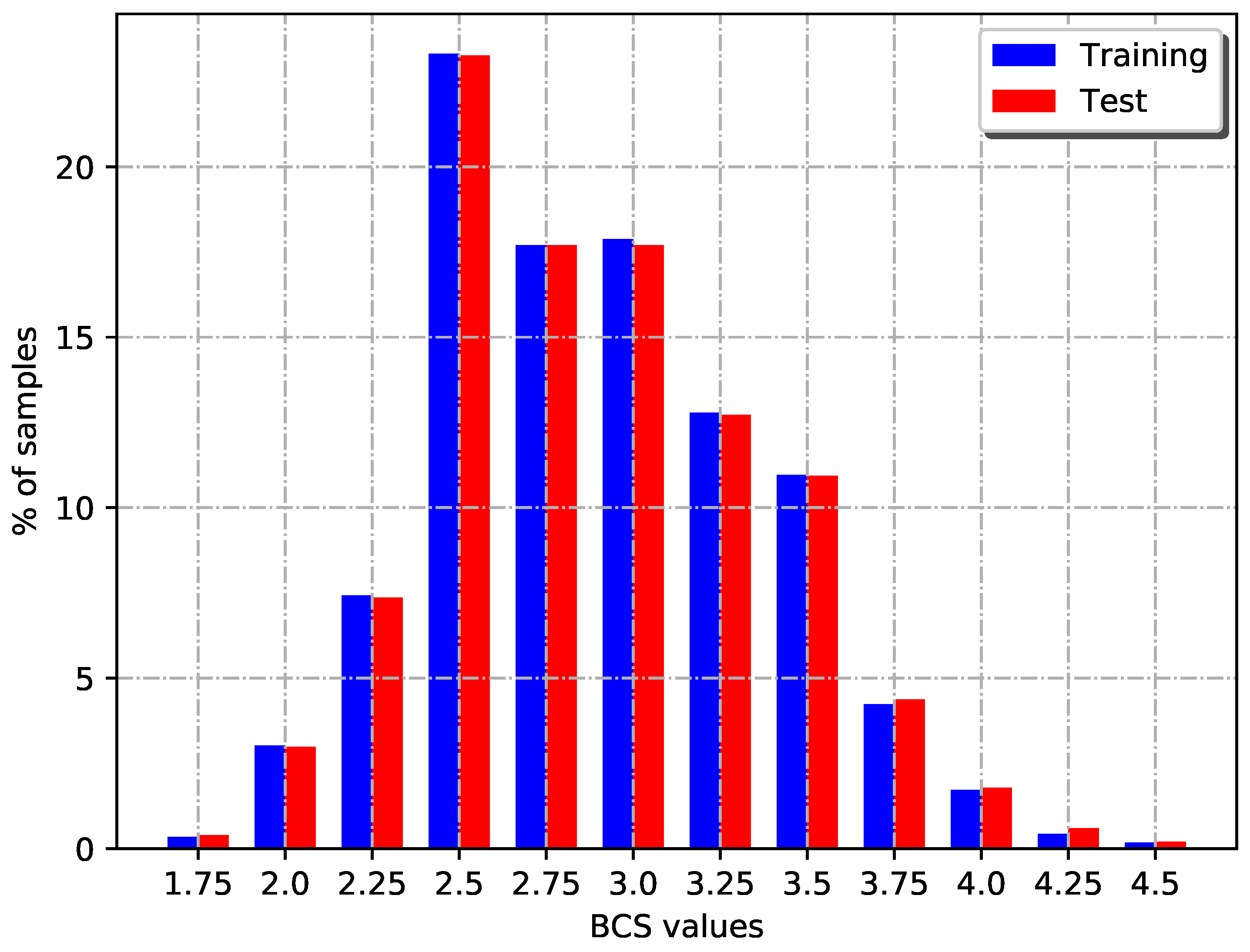
In each table, the last two rows combine per-class results to respectively calculate weighted and unweighted average metrics, i.e., these two rows present the macro-averaged classification measures of the model, considering (or not) the distribution of BCS values in the test set. Weighted metrics were added because, as it was shown before, the image dataset is imbalanced in terms of class instances.
The tables show zero values for a metric when there are not true positive values for a class. Particularly, it is possible to see that BCS = 4.5 class could not be predicted by any model irrespectively of error range. This happened because the whole dataset of images had very few samples of this class (3 in total), because of which only two samples were used to train the model to identify particular patterns, and only one sample to test them.
In general, considering confusion matrices and classification measures results, models have shown problems or difficulties to classify images on extreme BCS values, mainly in higher classes. These problems were related to low data distribution of low (emaciated) and high (fat) BCS values, because in an average livestock establishment is rare to find cows with poor body condition. This hinders the ability of models to learn features associated with extreme values, considering only a few training examples. In this sense, classes with more images to train, in the middle of the scale, present better results.
From the tables, it is possible to appreciate that two of the individual models have obtained the best results. Those were the models that transformed the depth images to generate additional channels which added extra information to assist network training. Particularly, it is important to note the incidence of the channel that highlight cow body contour, whose impact or influence on the value of the BCS has been assumed and demonstrated in different related works.
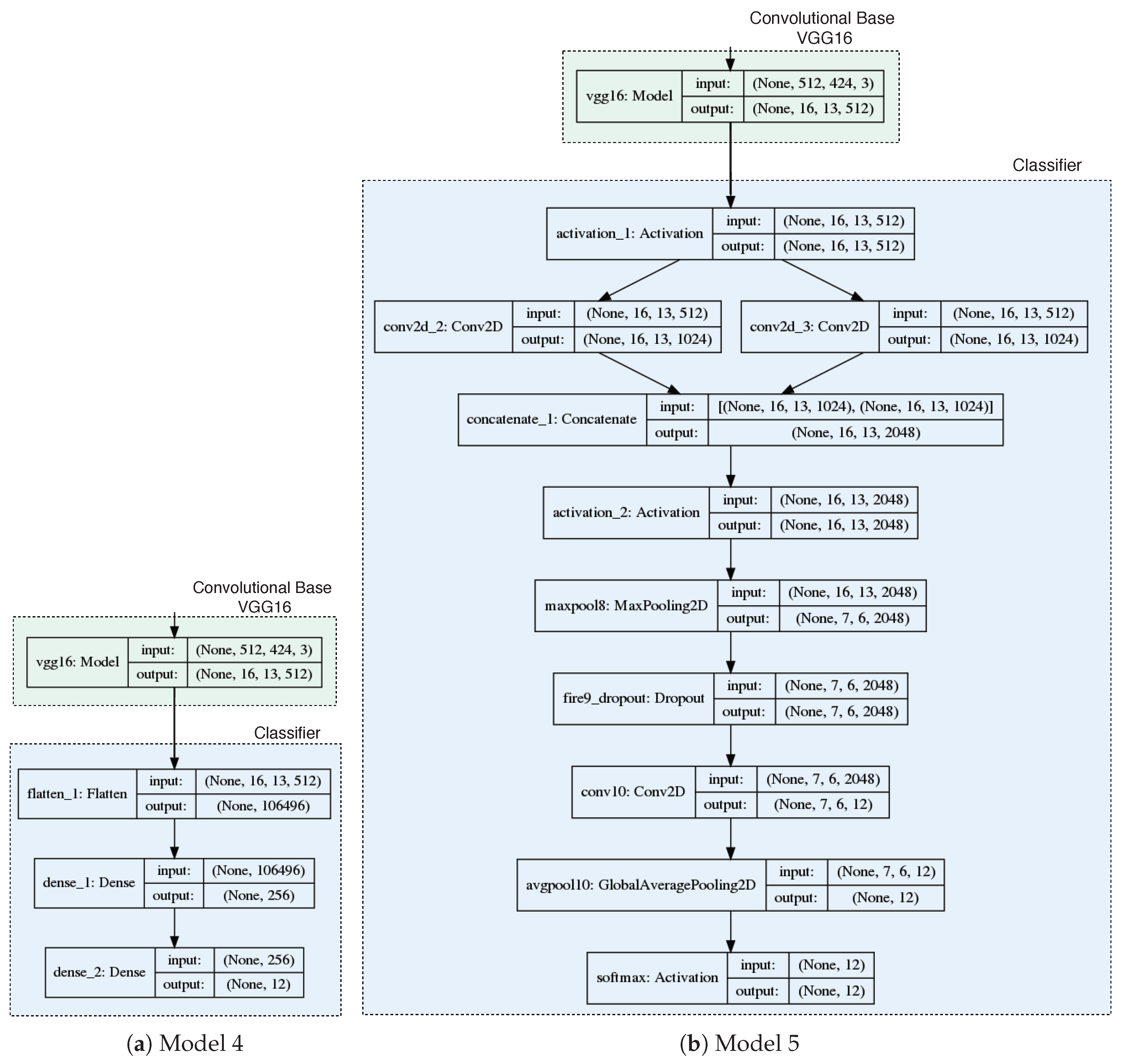
With respect to models which applied transfer learning, it was not possible to obtain the desired results and take advantage of the use of pre-trained networks over large volumes of data. At this point, the negative effect of diverse data sources was observed, corresponding to the differences between the characteristics of the images on which the weights of the VGG16 network (base) were trained and the images used in this work. The VGG16 network adjusts its weights using RGB images (with the well-known red, green and blue channels), while the cow images used in this work were composed of 3 completely different channels (Depth, Edges and Fourier). It is important to remember that we used these type of channels (i.e., channels built from depth values) instead of RGB channels because they have proven to be more suitable to depict cow body variability associated with changes in BCS [
5,
15]. Therefore, it was this disparity in the data sources that generates a negative impact on the final predictions.
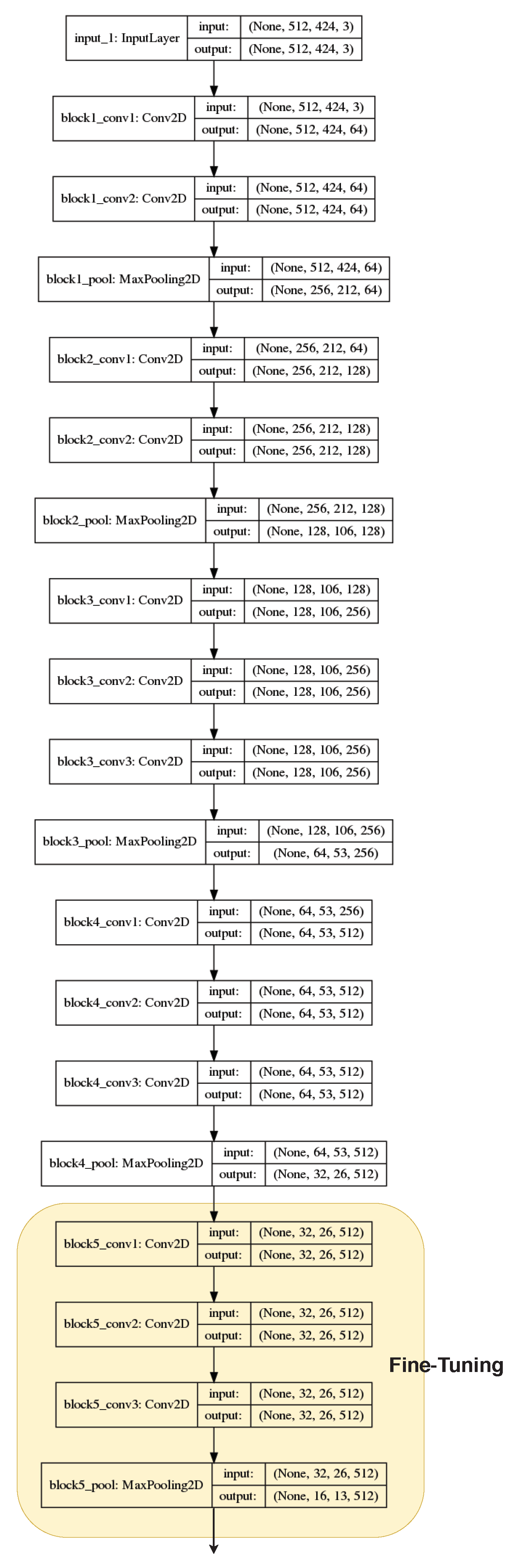
Despite this, it was decided to test the generality and reusability of the first layers of a pre-trained deep network, fine-tuning the weights of the final layers of the VGG16 network convolutional base. Although the results improved marginally, these values did not reach those achieved by two of the models trained from scratch (Model 2 and Model 3), since the growth in the number of parameters to train produced overfitting over training set images, without contributing significantly to the generality of the model.
Although the accuracy obtained by models which applied transfer learning techniques was not as good as expected, it was decided to exploit the diversity generated and analyze if these models could contribute to give diversity to a set of predictions or model ensemble, which could allow improving the overall results of the system obtained by the best of the individual models. Thus, according to previous results and the considerations in
Section 2.3.3, we define the models which compose the model ensemble as:
Model 2 (SqueezeNet 2 channels),
Model 3 (SqueezeNet 3 channels),
Model 6 (Fine tuning over VGG16 with a fully connected classifier),
Model 7 (Fine tuning over VGG16 with a classifier based on Fire modules).
Additionally, it was necessary to determine how the predictions of the models are combined to generate a new one associated with the model ensemble. The weighted average of the predictions of the individual models was chosen to calculate this value, taking into account the efficiency of each one.
Table 6 shows the accuracy of each model of the ensemble and the weights assigned to each one, highlighting the importance that the best models have greater weight in the final prediction. Also, model ensemble accuracy value is shown and compared to the values achieved by its individual models. Although the improvement was small (in comparison with Model 2), these results demonstrated the importance of having an architecturally heterogeneous set of models in the model ensemble. That is, obtained results were improved even though individual models that were not as good enough as others were taken into account (particularly Model 6 and Model 7), but that allowed to add diversity to the model ensemble and counteract prediction biases. It remains to be analyzed as part of future works if these results could be even improved if models of comparable accuracy (i.e., accuracy values close to Model 2) were taken into account in the ensemble.
Similar to the analysis made in the previous work [
15], overall accuracy of the best single model and the model ensemble were contrasted against works presenting medium to high BCS automatization level in the bibliography. Each related work builds and uses its own dataset to calculate this metric, i.e., there is no universal dataset of cow images that allows for a standardization of experimental factors. That is why just a high-level accuracy comparison could be made (such as those found in previous works [
7,
8,
9,
10,
15].
Table 7 shows the accuracy comparison within different human error ranges, which is one of the most frequently used measure in the literature to evaluate the precision of models [
3,
4,
7,
10,
24,
35,
36]. It is possible to appreciate how Model 2 has achieved very good results, outperforming in all cases accuracy estimations within 0.25 and 0.50 units of difference between true and predicted BCS value. However, it is important to highlight how the model ensemble has improved these results by combining different models, demonstrating a higher prediction capacity than the individual models.
An automatic estimation of BCS, as we mentioned before, already means a qualitative improvement of great impact in terms of effort, time, money and objectivity in capturing this productive variable. However, in addition, improvements in the accuracy of any of these automatic processes (such as the 3–4% achieved by this work in comparison with the previous one), which a priori seem scarce numerically, represent a great advance (especially if we take into account that quality jumps in accuracy values are reduced as they approach 100% accuracy) that allow a more precise monitoring of this indicator, which could directly impact and achieve a greater nutritional efficiency, and at the same time would lead to improve the profitability of the livestock business.
Regarding Model 8, it is true that implementing an ensemble could increase the computational cost of the solution, but as we mentioned before at this scale of accuracy each improvement represents a challenge and it is justified if the cost is not too high. In this sense, on one hand each model used by the ensemble was trained offline, and each one represented a potential solution during the learning cycle (Idea-Code new model-Training-Testing/Evaluation). Thus, at this point, the extra computational cost was just associated in order to decide how the results of the individual models should be combined to generate a more accurate final prediction. On the other hand, in practice the estimation produced by each trained model could be done in parallel, and then simply combine the values in the previously defined way.
4. Conclusions
This work has analyzed how different model configuration and machine learning techniques could be used in order to estimate BCS on cows from depth images. As base system, we employed a single-model BCS estimator that uses CNNs already proposed in [
15].
Particularly, a variation on the number of input channel model has proven to get better results than the legacy model. It was possible to appreciate that the information added by Fourier channel was not relevant to this problem, since it was not reflected in an increase in model performance and could even generate an increase in preprocessing times.
The models that used the different transfer learning alternatives were not able to improve classification measures. This is due to the disparate nature of the data used to pre-train models (used to transfer knowledge) and data used to solve the current problem. At this point it may be convenient to use only part of the convolutional base of the pre-trained network, in particular some of the first layers, since they extract more generic features and they are less linked to the source problem. This would reduce the bias of the layers near the output of the convolutional base towards classes of the source task. Nevertheless, these models were useful to give diversity to an ensemble of models, improving the obtained results by any of the individual models, and validating the application of this technique. However, in future works it will be necessary to analyze if it is possible to improve the ensemble accuracy considering new models that are better than those obtained through transfer learning techniques, and achieve accuracy values comparable to Model 2. According to the shown results, these new models should be trained from scratch (as far as we know there are not CNN models trained over similar problem which could be used to transfer learning) and they should developed using different architectures or configurations (with respect to Model 2), in order to preserve models diversity in the ensemble, which has demostrated to be useful.
Summarizing, two of the model analyzed in this work have improved the results achieved by the previous work. These two models were:
Model 2: a model based on SqueezeNet with two input channels (Depth and Edge) trained from scratch;
Model 8: an ensemble which combined the two best models (Model 2 and Model 3) with two other architecturally different models (Model 6, Model 7).
However, although the results of Rodríguez Alvarez et al. [
15] have been improved, at this point the need to increase the dataset is stressed, especially extreme BCS values. That is, it is necessary to have an extended data set with an equitable data distribution in order to achieve a quality jump in the system accuracy.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}