Contribution of Known Genetic Risk Variants to Dyslipidemias and Type 2 Diabetes in Mexico: A Population-Based Nationwide Study

Abstract
:1. Introduction
2. Materials and Methods
2.1. 2000. National Health Survey
2.2. Genotyping and Quality Control Procedures
2.3. Polygenic Risk Score
2.4. Population Stratification Control
2.5. Statistical Analyses
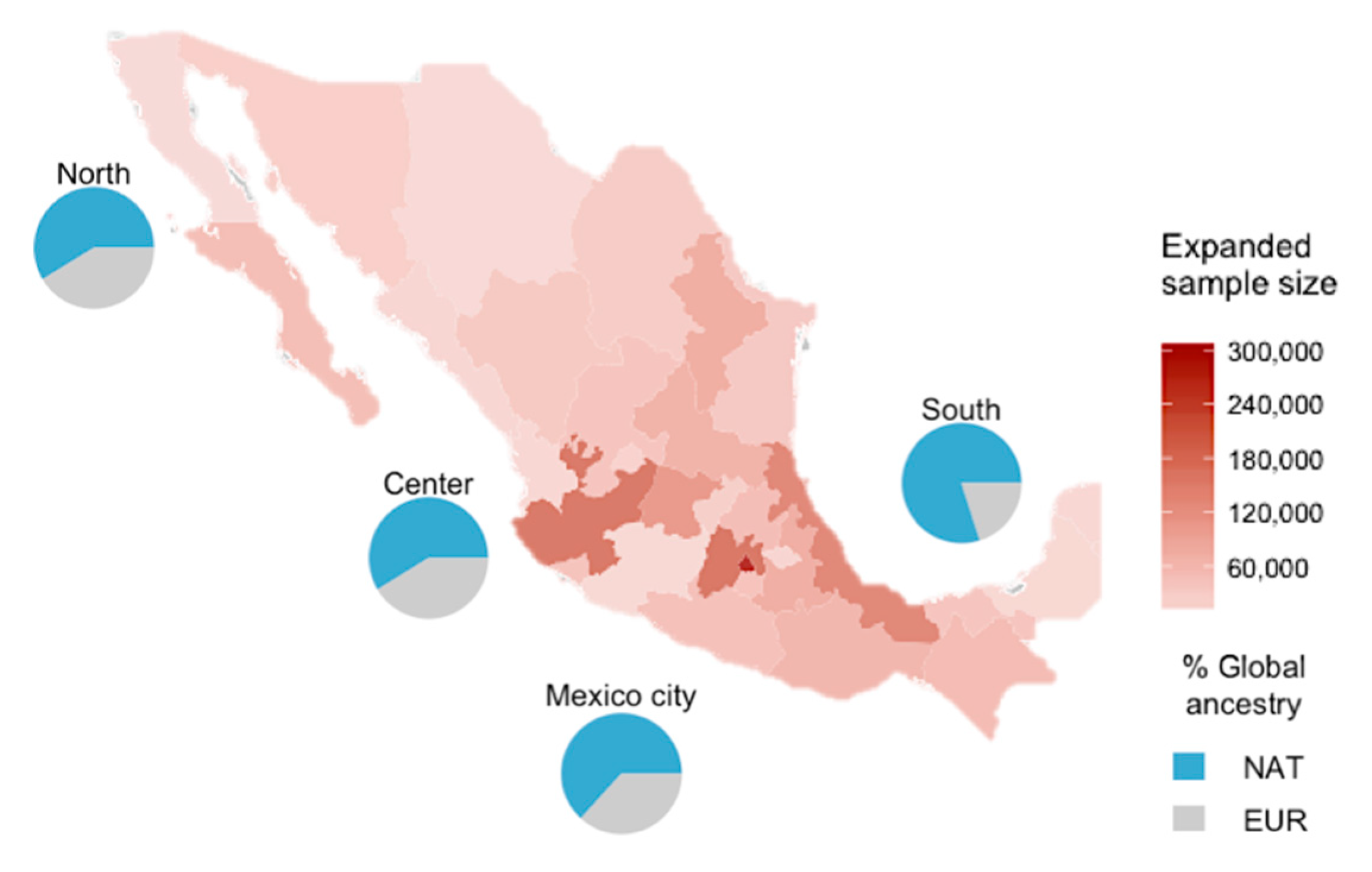
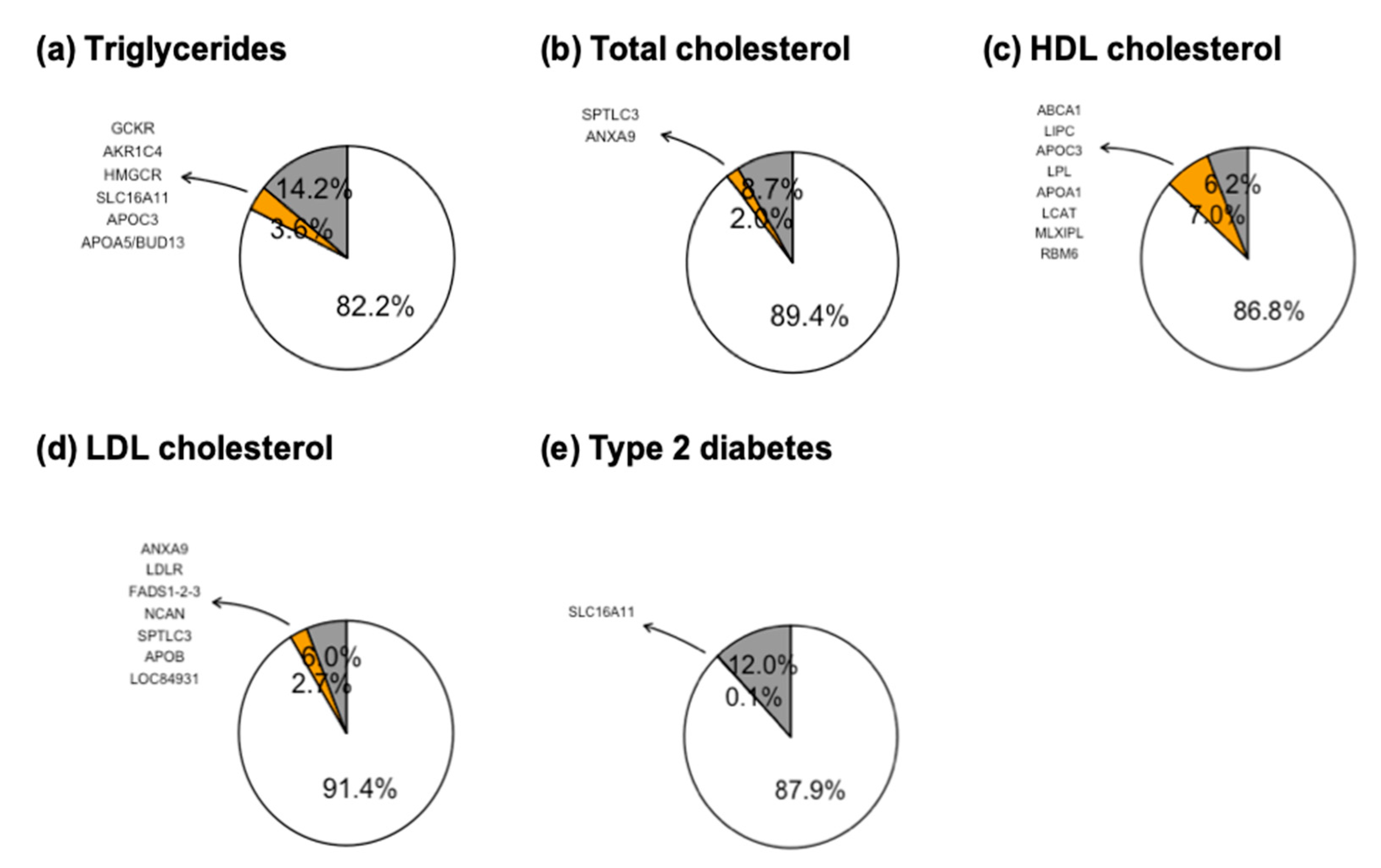
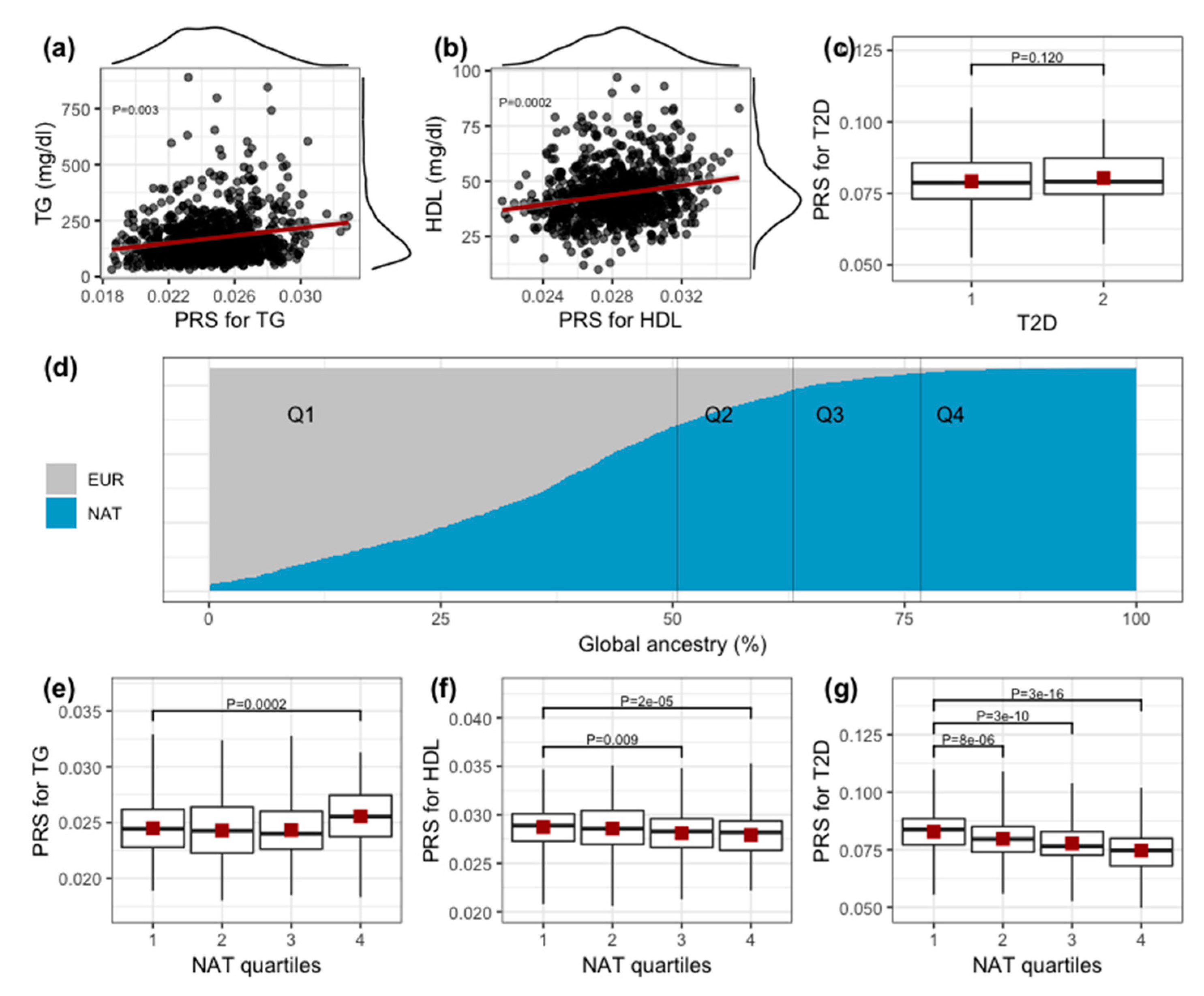
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rivera, J.A.; Barquera, S.; Campirano, F.; Campos, I.; Safdie, M.; Tovar, V. Epidemiological and nutritional transition in Mexico: Rapid increase of non-communicable chronic diseases and obesity. Public Health Nutr. 2002, 5, 113–122. [Google Scholar] [CrossRef] [PubMed]
- INEGI Mortalidad. Available online: http://www3.inegi.org.mx/rnm/index.php/catalog/246/related_materials?idPro= (accessed on 12 January 2020).
- Barquera, S.; Flores, M.; Olaiz-Fernández, G.; Monterrubio, E.; Villalpando, S.; González, C.; Rivera, J.Á.; Sepúlveda, J. Dyslipidemias and obesity in Mexico. Salud Publica Mex. 2007, 49, 338–347. [Google Scholar] [CrossRef] [Green Version]
- Olaiz-Fernández, G.; Rojas, R.; Aguilar-Salinas, C.A.; Rauda, J.; Villalpando, S. Diabetes mellitus en adultos mexicanos. Resultados de la Encuesta Nacional de Salud 2000. Salud Publica Mex. 2007, 49, 331–337. [Google Scholar] [CrossRef] [Green Version]
- Mendis, S.; Armstrong, T.; Bettcher, D.; Branca, F.; Lauer, J.; Mace, C.; Poznyak, V.; Riley, L.; Da Costa, E.; Silva, V.; et al. Global Status Report on Noncommunicable Diseases 2014; World Health Organisation: Geneva, Switzerland, 2014. [Google Scholar]
- Lange, L.A.; Willer, C.J.; Rich, S.S. Recent developments in genome and exome-wide analyses of plasma lipids. Curr. Opin. Lipidol. 2015, 26, 96–102. [Google Scholar] [CrossRef] [PubMed]
- Teslovich, T.M.; Musunuru, K.; Smith, A.V.; Edmondson, A.C.; Stylianou, I.M.; Koseki, M.; Pirruccello, J.P.; Ripatti, S.; Chasman, D.I.; Willer, C.J.; et al. Biological, clinical and population relevance of 95 loci for blood lipids. Nature 2010, 466, 707–713. [Google Scholar] [CrossRef]
- Mahajan, A.; Taliun, D.; Thurner, M.; Robertson, N.R.; Torres, J.M.; Rayner, N.W.; Payne, A.J.; Steinthorsdottir, V.; Scott, R.A.; Grarup, N.; et al. Fine-mapping type 2 diabetes loci to single-variant resolution using high-density imputation and islet-specific epigenome maps. Nat. Genet. 2018, 50, 1505–1513. [Google Scholar] [CrossRef] [Green Version]
- Weissglas-Volkov, D.; Aguilar-Salinas, C.A.; Nikkola, E.; Deere, K.A.; Cruz-Bautista, I.; Arellano-Campos, O.; Muñoz-Hernandez, L.L.; Gomez-Munguia, L.; Ordoñez-Sánchez, M.L.; Linga Reddy, P.M.V.; et al. Genomic study in Mexicans identifies a new locus for triglycerides and refines European lipid loci. J. Med. Genet. 2013, 50, 298–308. [Google Scholar] [CrossRef]
- Williams Amy, A.L.; Jacobs Suzanne, S.B.R.; Moreno-Macías, H.; Huerta-Chagoya, A.; Churchhouse, C.; Márquez-Luna, C.; Gómez-Vázquez, M.J.; Burtt Noël, N.P.; Aguilar-Salinas, C.A.; González-Villalpando, C.; et al. Sequence variants in SLC16A11 are a common risk factor for type 2 diabetes in Mexico. Nature 2014, 506, 97–101. [Google Scholar]
- Estrada, K.; Aukrust, I.; Bjørkhaug, L.; Burtt, N.P.; Mercader, J.M.; García-Ortiz, H.; Huerta-Chagoya, A.; Moreno-Macías, H.; Walford, G.; Flannick, J.; et al. Association of a low-frequency variant in HNF1A with type 2 diabetes in a latino population the SIGMA Type 2 Diabetes Consortium. JAMA J. Am. Med. Assoc. 2014, 311, 2305–2314. [Google Scholar]
- Mercader, J.M.; Liao, R.G.; Bell, A.D.; Dymek, Z.; Estrada, K.; Tukiainen, T.; Huerta-Chagoya, A.; Moreno-Macías, H.; Jablonski, K.A.; Hanson, R.L.; et al. A Loss-of-Function Splice Acceptor Variant in IGF2 Is Protective for Type 2 Diabetes. Diabetes 2017, 66, 2903–2914. [Google Scholar] [CrossRef] [Green Version]
- Udler, M.S.; McCarthy, M.I.; Florez, J.C.; Mahajan, A. Genetic Risk Scores for Diabetes Diagnosis and Precision Medicine. Endocr. Rev. 2019, 40, 1500–1520. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sepúlveda, J.; Tapia-Conyer, R.; Velásquez, O.; Valdespino, J.L.; Olaiz-Fernández, G.; Kuri, P.; Sari, E.; Conde-González, C.J. Diseño y metodología de la Encuesta Nacional de Salud 2000. Salud Publica Mex. 2007, 49, 427–432. [Google Scholar] [CrossRef] [Green Version]
- Barquera, S.; Carrión, C.; Campos, I.; Espinosa, J.; Rivera, J.; Olaiz-Fernández, G. Methodology of the fasting sub-sample from the Mexican Health Survey, 2000. Salud Publica Mex. 2007, 49, 421–426. [Google Scholar] [CrossRef] [Green Version]
- Willer, C.J.; Schmidt, E.M.; Sengupta, S.; Peloso, G.M.; Gustafsson, S.; Kanoni, S.; Ganna, A.; Chen, J.; Buchkovich, M.L.; Mora, S.; et al. Discovery and refinement of loci associated with lipid levels. Nat. Genet. 2013, 45, 1274–1285. [Google Scholar] [PubMed] [Green Version]
- Villarreal-Molina, M.T.; Aguilar-Salinas, C.A.; Rodríguez-Cruz, M.; Riaño, D.; Villalobos-Comparan, M.; Coral-Vazquez, R.; Menjivar, M.; Yescas-Gomez, P.; Königsoerg-Fainstein, M.; Romero-Hidalgo, S.; et al. The ATP-binding cassette transporter A1 R230C variant affects HDL cholesterol levels and BMI in the Mexican population: Association with obesity and obesity-related comorbidities. Diabetes 2007, 56, 1881–1887. [Google Scholar] [CrossRef] [Green Version]
- Purcell, S.; Neale, B.; Todd-Brown, K.; Thomas, L.; Ferreira, M.A.R.; Bender, D.; Maller, J.; Sklar, P.; de Bakker, P.I.W.; Daly, M.J.; et al. PLINK: A Tool Set for Whole-Genome Association and Population-Based Linkage Analyses. Am. J. Hum. Genet. 2007, 81, 559–575. [Google Scholar] [CrossRef] [Green Version]
- Mahajan, A.; Go, M.J.; Zhang, W.; Below, J.E.; Gaulton, K.J.; Ferreira, T.; Horikoshi, M.; Johnson, A.D.; Ng, M.C.Y.; Prokopenko, I.; et al. Genome-wide trans-ancestry meta-analysis provides insight into the genetic architecture of type 2 diabetes susceptibility. Nat. Genet. 2014, 46, 234–244. [Google Scholar] [CrossRef]
- Price, A.L.; Patterson, N.J.; Plenge, R.M.; Weinblatt, M.E.; Shadick, N.A.; Reich, D. Principal components analysis corrects for stratification in genome-wide association studies. Nat. Genet. 2006, 38, 904–909. [Google Scholar] [CrossRef]
- Huerta-Chagoya, A.; Moreno-Macías, H.; Fernández-López, J.C.; Ordóñez-Sánchez, M.L.; Rodríguez-Guillén, R.; Contreras, A.; Hidalgo-Miranda, A.; Alfaro-Ruíz, L.A.; Salazar-Fernandez, E.P.; Moreno-Estrada, A.; et al. A panel of 32 AIMs suitable for population stratification correction and global ancestry estimation in Mexican mestizos. BMC Genet. 2019, 20, 1–5. [Google Scholar] [CrossRef]
- Auton, A.; Abecasis, G.R.; Altshuler, D.M.; Durbin, R.M.; Bentley, D.R.; Chakravarti, A.; Clark, A.G.; Donnelly, P.; Eichler, E.E.; Flicek, P.; et al. A global reference for human genetic variation. Nature 2015, 526, 68–74. [Google Scholar]
- Moreno-Estrada, A.; Gignoux, C.R.; Fernández-López, J.C.; Zakharia, F.; Sikora, M.; Contreras, A.V.; Acuña-Alonzo, V.; Sandoval, K.; Eng, C.; Romero-Hidalgo, S.; et al. The genetics of Mexico recapitulates Native American substructure and affects biomedical traits. Science 2014, 334, 1280–1285. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alexander, D.H.; Novembre, J.; Lange, K. Fast model-based estimation of ancestry in unrelated individuals. Genome Res. 2009, 19, 1655–1664. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lumley, T. Complex Surveys: A Guide to Analysis Using R; Wiley: Hoboken, NJ, USA, 2010; ISBN 111821093X. [Google Scholar]
- Szklarczyk, D.; Morris, J.H.; Cook, H.; Kuhn, M.; Wyder, S.; Simonovic, M.; Santos, A.; Doncheva, N.T.; Roth, A.; Bork, P.; et al. The STRING database in 2017: Quality-controlled protein-protein association networks, made broadly accessible. Nucleic Acids Res. 2017, 45, D362–D368. [Google Scholar] [CrossRef] [PubMed]
- Supek, F.; Bošnjak, M.; Škunca, N.; Šmuc, T. Revigo summarizes and visualizes long lists of gene ontology terms. PLoS ONE 2011, 6. [Google Scholar] [CrossRef] [Green Version]
- Coram, M.A.; Duan, Q.; Hoffmann, T.J.; Thornton, T.; Knowles, J.W.; Johnson, N.A.; Ochs-Balcom, H.M.; Donlon, T.A.; Martin, L.W.; Eaton, C.B.; et al. Genome-wide characterization of shared and distinct genetic components that influence blood lipid levels in ethnically diverse human populations. Am. J. Hum. Genet. 2013, 92, 904–916. [Google Scholar] [CrossRef] [Green Version]
- Rusu, V.; Rusu, V.; Hoch, E.; Mercader, J.M.; Gymrek, M.; von Grotthuss, M.; Fontanillas, P.; Spooner, A.; Altshuler, D.M.; Florez, J.C.; et al. Type 2 Diabetes Variants Disrupt Function of SLC16A11 through Two Distinct Mechanisms. Cell 2017, 170, 199–212.e20. [Google Scholar] [CrossRef]
- Talmud, P.J.; Drenos, F.; Shah, S.; Shah, T.; Palmen, J.; Verzilli, C.; Gaunt, T.R.; Pallas, J.; Lovering, R.; Li, K.; et al. Gene-centric Association Signals for Lipids and Apolipoproteins Identified via the HumanCVD BeadChip. Am. J. Hum. Genet. 2009, 85, 628–642. [Google Scholar] [CrossRef] [Green Version]
- Link, J.C.; Reue, K. Genetic Basis for Sex Differences in Obesity and Lipid Metabolism. Annu. Rev. Nutr. 2017, 37, 225–245. [Google Scholar] [CrossRef]
- Heid, I.M.; Jackson, A.U.; Randall, J.C.; Winkler, T.W.; Qi, L.; Ssteinthorsdottir, V.; Tthorleifsson, G.; Zillikens, C.; Sspeliotes, E.K.; Mägi, R.; et al. Meta-analysis identifies 13 new loci associated with waist-hip ratio and reveals sexual dimorphism in the genetic basis of fat distribution. Nat. Genet. 2010, 42, 949–960. [Google Scholar] [CrossRef] [Green Version]
- Sung, Y.J.; Pérusse, L.; Sarzynski, M.A.; Fornage, M.; Sidney, S.; Sternfeld, B.; Rice, T.; Terry, J.G.; Jacobs, D.R.; Katzmarzyk, P.; et al. Genome-wide association studies suggest sex-specific loci associated with abdominal and visceral fat. Int. J. Obes. 2016, 40, 662–674. [Google Scholar] [CrossRef] [Green Version]
- Wheeler, E.; Leong, A.; Liu, C.T.; Hivert, M.F.; Strawbridge, R.J.; Podmore, C.; Li, M.; Yao, J.; Sim, X.; Hong, J.; et al. Impact of common genetic determinants of Hemoglobin A1c on type 2 diabetes risk and diagnosis in ancestrally diverse populations: A transethnic genome-wide meta-analysis. PLoS Med. 2017, 14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sarnowski, C.; Leong, A.; Raffield, L.M.; Wu, P.; de Vries, P.S.; DiCorpo, D.; Guo, X.; Xu, H.; Liu, Y.; Zheng, X.; et al. Impact of Rare and Common Genetic Variants on Diabetes Diagnosis by Hemoglobin A1c in Multi-Ancestry Cohorts: The Trans-Omics for Precision Medicine Program. Am. J. Hum. Genet. 2019, 105, 706–718. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Variable | Raw | Expansion |
|---|---|---|
| N | 1627 | 1,920,663 |
| Age (years) | 38.21 ± 14.84 | 35.21 ± 13.97 |
| Sex (% females) | 32.49 | 50.0 |
| Diabetic status (%) | 13 | 8.0 |
| Systolic blood pressure (mmHg) | 120.81 ± 15.71 | 120.8 ± 14.99 |
| Diastolic blood pressure (mmHg) | 79.51 ± 11.4 | 79.10 ± 11.36 |
| BMI (kg/m2) | 27.18 ± 5.38 | 26.76 ± 5.20 |
| Waist circumference (cm) | 93.26 ± 15.7 | 92.16 ± 15.85 |
| Glucose (mg/dL) | 74 [65–86] | 74 [65–85] |
| Creatinine (mg/dL) | 0.9 [0.8–1] | 0.9 [0.8–1.1] |
| Total cholesterol (mg/dL) | 190 [164–223] | 183 [159–219] |
| Triglycerides (mg/dL) | 146 [98–212] | 131 [87–192] |
| HDL cholesterol (mg/dL) | 43 [37–52] | 41 [34–48] |
| LDL cholesterol (mg/dL) | 114 [94–139] | 111 [94–136] |
| Native American ancestry (%) | 61.9 [49.1–77.3] | 62.9 [50.4–76.8] |
| Variable | Euglycemia | Diabetes | Normolipidemia | Dyslipidemia |
|---|---|---|---|---|
| N | 1,095,837 | 95,177 | 643,776 | 1,271,329 |
| Age (years) | 34.17 ± 13.45 | 50.30 ± 14.85 a | 31.48 ± 13.06 | 37.06 ± 14.01 b |
| Sex (% females) | 48.3 | 68.5 a | 59.85 | 45.03 b |
| Diabetic status (%) | 0 | 100 | 6.0 | 8.9 |
| Dyslipidemia status (%) | 70.6 | 78.7 | 0 | 100 |
| Systolic blood pressure (mmHg) | 120.9 ± 14.99 | 129.4 ± 17.67 a | 116.22 ± 12.25 | 123.14 ± 15.73 b |
| Diastolic blood pressure (mmHg) | 79.10 ± 14.96 | 81.87 ± 11.97 | 76.17 ± 9.32 | 80.62 ± 12 b |
| BMI (kg/m2) | 26.79 ± 5.36 | 29.43 ± 4.98 a | 25.26 ± 4.99 | 27.53 ± 5.1 b |
| Waist circumference (cm) | 92.75 ± 16.33 | 101.19 ± 14 a | 87.08 ± 14.50 | 94.71 ± 15.9 b |
| Glucose (mg/dL) | 75 [66–85] | 190 [136–255] a | 72 [63–82] | 75 [67–87] b |
| Creatinine (mg/dL) | 0.9 [0.8–1.1] | 0.9 [0.8–1.0] | 0.9 [0.8–1.0] | 0.95 [0.8–1.1] b |
| Total cholesterol (mg/dL) | 187 [161–222] | 200 [176–242.3] a | 170 [154.6–182] | 207 [166–232.1] b |
| Triglycerides (mg/dL) | 144 [97–207] | 188.2 [139.1–243.5] a | 94 [72–116.9] | 175 [125–238] b |
| HDL cholesterol (mg/dL) | 41 [34–48] | 40 [33–45] | 46 [40–53] | 40 [32–48] b |
| LDL cholesterol (mg/dL) | 112.3 [96–140] | 124.5 [107–152.7] | 102 [89–114] | 127 [101–150] b |
| Native American ancestry (%) | 58.2 [47–72.8] | 64.8 [53.9–80.4] a | 64.5 [53.2–81.4] | 61.5 [49.5–76] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huerta-Chagoya, A.; Moreno-Macías, H.; Sevilla-González, M.; Rodríguez-Guillén, R.; Ordóñez-Sánchez, M.L.; Gómez-Velasco, D.; Muñóz-Hernández, L.; Segura-Kato, Y.; Arellano-Campos, O.; Cruz-Bautista, I.; et al. Contribution of Known Genetic Risk Variants to Dyslipidemias and Type 2 Diabetes in Mexico: A Population-Based Nationwide Study. Genes 2020, 11, 114. https://0-doi-org.brum.beds.ac.uk/10.3390/genes11010114
Huerta-Chagoya A, Moreno-Macías H, Sevilla-González M, Rodríguez-Guillén R, Ordóñez-Sánchez ML, Gómez-Velasco D, Muñóz-Hernández L, Segura-Kato Y, Arellano-Campos O, Cruz-Bautista I, et al. Contribution of Known Genetic Risk Variants to Dyslipidemias and Type 2 Diabetes in Mexico: A Population-Based Nationwide Study. Genes. 2020; 11(1):114. https://0-doi-org.brum.beds.ac.uk/10.3390/genes11010114
Chicago/Turabian StyleHuerta-Chagoya, Alicia, Hortensia Moreno-Macías, Magdalena Sevilla-González, Rosario Rodríguez-Guillén, María L. Ordóñez-Sánchez, Donají Gómez-Velasco, Liliana Muñóz-Hernández, Yayoi Segura-Kato, Olimpia Arellano-Campos, Ivette Cruz-Bautista, and et al. 2020. "Contribution of Known Genetic Risk Variants to Dyslipidemias and Type 2 Diabetes in Mexico: A Population-Based Nationwide Study" Genes 11, no. 1: 114. https://0-doi-org.brum.beds.ac.uk/10.3390/genes11010114