
Assessment of Quarterly, Semiannual and Annual Models to Forecast Monthly Rainfall Anomalies: The Case of a Tropical Andean Basin


Abstract
:1. Introduction
2. Materials and Methods
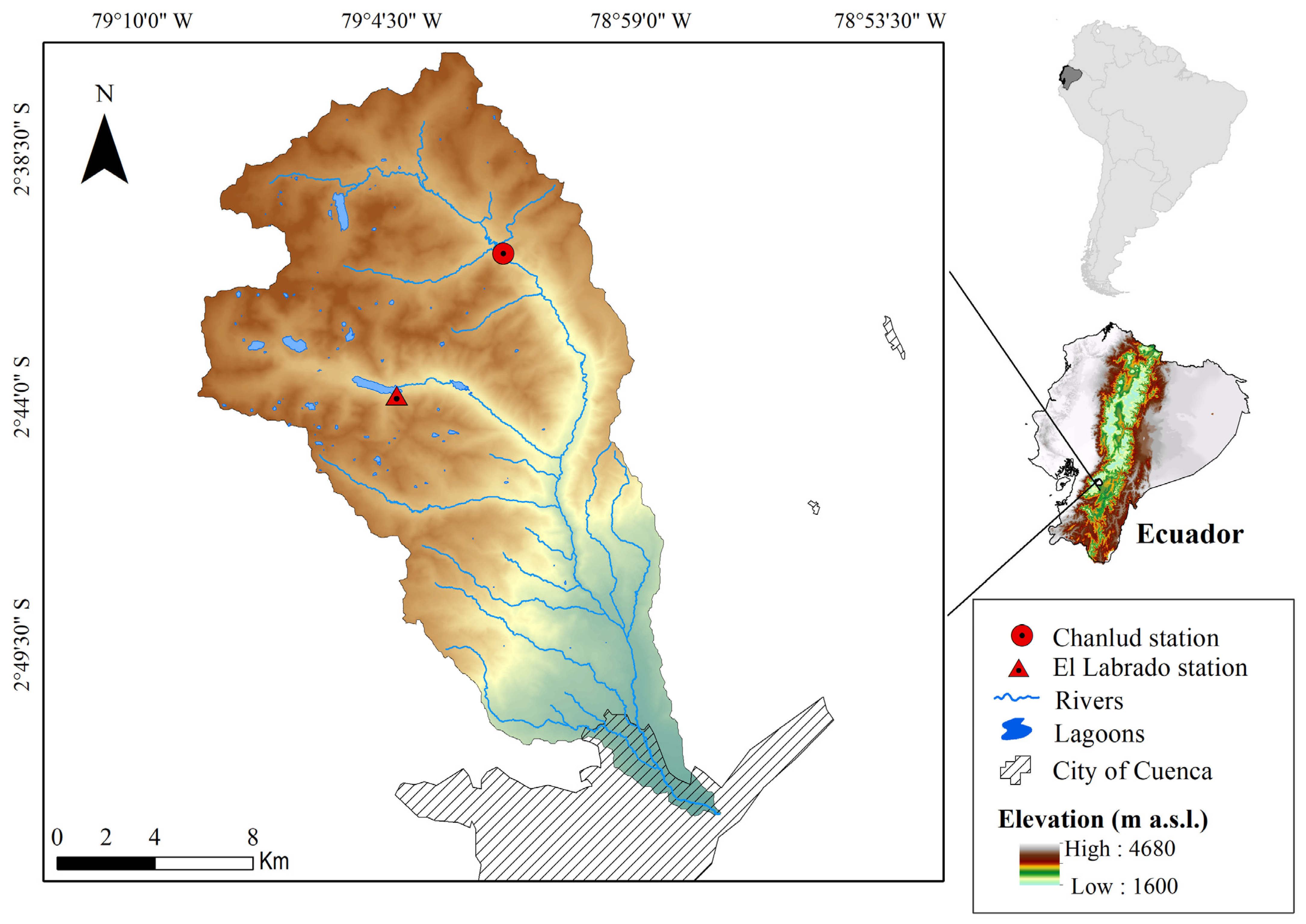
2.1. Study Zone
2.2. Data
2.3. Settings and Workflow
2.4. Maximum τ lag (τmax)
2.5. Generation of Candidate Predictor Sets
- DJF: 13 to τmax.
- MAM: 6 to τmax.
- JJA: 9 to τmax.
- SON: 12 to τmax.
- NDJFMA: 13 to τmax.
- MJJASO: 11 to τmax.
- J-D: 13 to τmax.
2.6. Sequential Forward Selection (SFS) of Predictors
2.7. Support Vector Regression (SVR)
- ;
- ;
- .
2.8. Evaluation Metrics
3. Results
3.1. τmax for Generating the Candidate Predictors
3.2. Optimum Number of Predictors
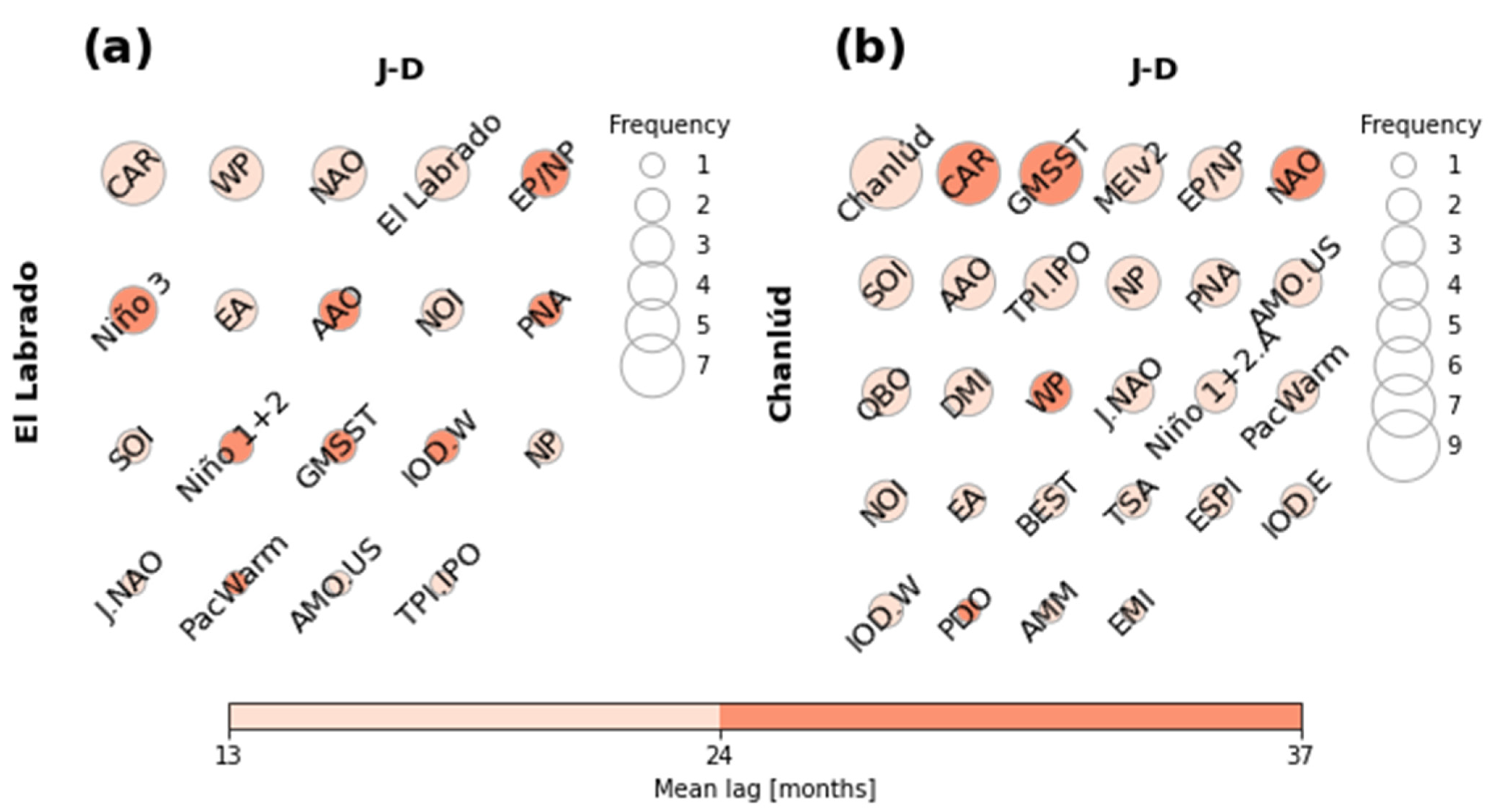
3.3. Relevant Predictors
3.4. Qualitative Evaluation
3.5. Quantitative Evaluation
4. Discussion
5. Conclusions and Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Esquivel, A.; Llanos-Herrera, L.; Agudelo, D.; Prager, S.D.; Fernandes, K.; Rojas, A.; Valencia, J.J.; Ramirez-Villegas, J. Predictability of Seasonal Precipitation across Major Crop Growing Areas in Colombia. Clim. Serv. 2018, 12, 36–47. [Google Scholar] [CrossRef]
- BBC News Megadrought in Southwest US Worst in a Millennium. Available online: https://www.bbc.com/news/world-us-canada-60396229 (accessed on 4 April 2022).
- Freitas, A.A.; Drumond, A.; Carvalho, V.S.B.; Reboita, M.S.; Silva, B.C.; Uvo, C.B. Drought Assessment in São Francisco River Basin, Brazil: Characterization through SPI and Associated Anomalous Climate Patterns. Atmosphere 2021, 13, 41. [Google Scholar] [CrossRef]
- da Rocha Júnior, R.L.; dos Santos Silva, F.D.; Costa, R.L.; Gomes, H.B.; Pinto, D.D.C.; Herdies, D.L. Bivariate Assessment of Drought Return Periods and Frequency in Brazilian Northeast Using Joint Distribution by Copula Method. Geosciences 2020, 10, 135. [Google Scholar] [CrossRef] [Green Version]
- Silva, E.H.D.L.; Silva, F.D.D.S.; Junior, R.S.D.S.; Pinto, D.D.C.; Costa, R.L.; Gomes, H.B.; Júnior, J.B.C.; de Freitas, I.G.F.; Herdies, D.L. Performance Assessment of Different Precipitation Databases (Gridded Analyses and Reanalyses) for the New Brazilian Agricultural Frontier: SEALBA. Water 2022, 14, 1473. [Google Scholar] [CrossRef]
- Cunha, A.P.M.A.; Zeri, M.; Deusdará Leal, K.; Costa, L.; Cuartas, L.A.; Marengo, J.A.; Tomasella, J.; Vieira, R.M.; Barbosa, A.A.; Cunningham, C.; et al. Extreme Drought Events over Brazil from 2011 to 2019. Atmosphere 2019, 10, 642. [Google Scholar] [CrossRef] [Green Version]
- Bojinski, S.; Verstraete, M.; Peterson, T.C.; Richter, C.; Simmons, A.; Zemp, M. The Concept of Essential Climate Variables in Support of Climate Research, Applications, and Policy. Bull. Am. Meteorol. Soc. 2014, 95, 1431–1443. [Google Scholar] [CrossRef]
- Ghil, M. Natural Climate Variability. Encycl. Glob. Environ. Chang. 2002, 1, 544–549. [Google Scholar]
- Maslin, M. What Is Climate Change? In Climate Change: A Very Short Introduction; Oxford University Press: Oxford, UK, 2021; pp. 1–9. ISBN 978-0-19-886786-9. [Google Scholar]
- Barnston, A.G.; Tippett, M.K. Do Statistical Pattern Corrections Improve Seasonal Climate Predictions in the North American Multimodel Ensemble Models? J. Clim. 2017, 30, 8335–8355. [Google Scholar] [CrossRef]
- Ashby, S.A.; Taylor, M.A.; Chen, A.A. Statistical Models for Predicting Rainfall in the Caribbean. Theor. Appl. Climatol. 2005, 82, 65–80. [Google Scholar] [CrossRef]
- Duan, Q.; Pappenberger, F.; Wood, A.; Cloke, H.L.; Schaake, J.C. (Eds.) Handbook of Hydrometeorological Ensemble Forecasting; Springer: Berlin/Heidelberg, Germany, 2019; ISBN 978-3-642-39924-4. [Google Scholar]
- Doblas-Reyes, F.J.; García-Serrano, J.; Lienert, F.; Biescas, A.P.; Rodrigues, L.R.L. Seasonal Climate Predictability and Forecasting: Status and Prospects. Wiley Interdiscip. Rev. Clim. Chang. 2013, 4, 245–268. [Google Scholar] [CrossRef]
- da Rocha Júnior, R.L.; Cavalcante Pinto, D.D.; dos Santos Silva, F.D.; Gomes, H.B.; Barros Gomes, H.; Costa, R.L.; Santos Pereira, M.P.; Peña, M.; dos Santos Coelho, C.A.; Herdies, D.L. An Empirical Seasonal Rainfall Forecasting Model for the Northeast Region of Brazil. Water 2021, 13, 1613. [Google Scholar] [CrossRef]
- Amelia, R.; Dalimunthe, D.Y.; Kustiawan, E.; Sulistiana, I. ARIMAX Model for Rainfall Forecasting in Pangkalpinang, Indonesia. IOP Conf. Ser. Earth Environ. Sci. 2021, 926, 012034. [Google Scholar] [CrossRef]
- Muñoz, P.; Orellana-Alvear, J.; Willems, P.; Célleri, R. Flash-Flood Forecasting in an Andean Mountain Catchment—Development of a Step-Wise Methodology Based on the Random Forest Algorithm. Water 2018, 10, 1519. [Google Scholar] [CrossRef] [Green Version]
- Peña, M.; Vázquez-Patiño, A.; Zhiña, D.; Montenegro, M.; Avilés, A. Improved Rainfall Prediction through Nonlinear Autoregressive Network with Exogenous Variables: A Case Study in Andes High Mountain Region. Adv. Meteorol. 2020, 2020, 1828319. [Google Scholar] [CrossRef]
- Dutta, R.; Maity, R. Time-Varying Network-Based Approach for Capturing Hydrological Extremes under Climate Change with Application on Drought. J. Hydrol. 2021, 603, 126958. [Google Scholar] [CrossRef]
- Avilés, A.; Célleri, R.; Solera, A.; Paredes, J. Probabilistic Forecasting of Drought Events Using Markov Chain- and Bayesian Network-Based Models: A Case Study of an Andean Regulated River Basin. Water 2016, 8, 37. [Google Scholar] [CrossRef]
- Recalde-Coronel, G.C.; Barnston, A.G.; Muñoz, Á.G. Predictability of December–April Rainfall in Coastal and Andean Ecuador. J. Appl. Meteorol. Climatol. 2014, 53, 1471–1493. [Google Scholar] [CrossRef] [Green Version]
- Ghamariadyan, M.; Imteaz, M.A. Monthly Rainfall Forecasting Using Temperature and Climate Indices through a Hybrid Method in Queensland, Australia. J. Hydrometeorol. 2021, 22, 1259–1273. [Google Scholar] [CrossRef]
- Mendoza, D.E.; Samaniego, E.P.; Mora, D.E.; Espinoza, M.J.; Campozano, L. Finding Teleconnections from Decomposed Rainfall Signals Using Dynamic Harmonic Regressions: A Tropical Andean Case Study. Clim. Dyn. 2019, 52, 4643–4670. [Google Scholar] [CrossRef]
- Córdova, M.; Orellana-Alvear, J.; Rollenbeck, R.; Célleri, R. Determination of Climatic Conditions Related to Precipitation Anomalies in the Tropical Andes by Means of the Random Forest Algorithm and Novel Climate Indices. Int. J. Climatol. 2022, joc.7519. [Google Scholar] [CrossRef]
- Dutta, R.; Maity, R. Temporal Networks-Based Approach for Nonstationary Hydroclimatic Modeling and Its Demonstration With Streamflow Prediction. Water Resour. Res. 2020, 56, e2020WR027086. [Google Scholar] [CrossRef]
- Pajankar, A.; Joshi, A. Preparing Data for Machine Learning. In Hands-on Machine Learning with Python; Apress: Berkeley, CA, USA, 2022; pp. 79–97. ISBN 978-1-4842-7920-5. [Google Scholar]
- Vázquez-Patiño, A.; Peña, M.; Avilés, A. The Assessment of Rainfall Prediction Using Climate Models Results and Projections under Future Scenarios: The Machángara Tropical Andean Basin Case. Int. J. Adv. Sci. Eng. Inf. Technol. 2021, 11, 1903–1911. [Google Scholar] [CrossRef]
- Campozano, L.; Trachte, K.; Célleri, R.; Samaniego, E.; Bendix, J.; Albuja, C.; Mejia, J.F. Climatology and Teleconnections of Mesoscale Convective Systems in an Andean Basin in Southern Ecuador: The Case of the Paute Basin. Adv. Meteorol. 2018, 2018, 4259191. [Google Scholar] [CrossRef]
- Ballari, D.; Giraldo, R.; Campozano, L.; Samaniego, E. Spatial Functional Data Analysis for Regionalizing Precipitation Seasonality and Intensity in a Sparsely Monitored Region: Unveiling the Spatio-Temporal Dependencies of Precipitation in Ecuador. Int. J. Climatol. 2018, 38, 3337–3354. [Google Scholar] [CrossRef]
- Vázquez-Patiño, A.; Campozano, L.; Ballari, D.; Córdova, M.; Samaniego, E. Virtual Control Volume Approach to the Study of Climate Causal Flows: Identification of Humidity and Wind Pathways of Influence on Rainfall in Ecuador. Atmosphere 2020, 11, 848. [Google Scholar] [CrossRef]
- Avilés, A.; Palacios, K.; Pacheco, J.; Jiménez, S.; Zhiña, D.; Delgado, O. Sensitivity Exploration of Water Balance in Scenarios of Future Changes: A Case Study in an Andean Regulated River Basin. Theor. Appl. Climatol. 2020, 141, 921–934. [Google Scholar] [CrossRef]
- Farfán, J.F.; Palacios, K.; Ulloa, J.; Avilés, A. A Hybrid Neural Network-Based Technique to Improve the Flow Forecasting of Physical and Data-Driven Models: Methodology and Case Studies in Andean Watersheds. J. Hydrol. Reg. Stud. 2020, 27, 100652. [Google Scholar] [CrossRef]
- Esquivel-Hernández, G.; Mosquera, G.M.; Sánchez-Murillo, R.; Quesada-Román, A.; Birkel, C.; Crespo, P.; Célleri, R.; Windhorst, D.; Breuer, L.; Boll, J. Moisture Transport and Seasonal Variations in the Stable Isotopic Composition of Rainfall in Central American and Andean Páramo during El Niño Conditions (2015–2016). Hydrol. Process. 2019, 33, 1802–1817. [Google Scholar] [CrossRef]
- Emck, P. A Climatology of South Ecuador—With Special Focus on the Major Andean Ridge as Atlantic-Pacific Climate Divide. Ph.D. Thesis, Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen, Germany, 2007. [Google Scholar]
- CENACE. Annual Report 2020; Management Reports; National Center for Energy Control: Quito, Ecuador, 2021; p. 209. (In Spanish) [Google Scholar]
- Alomía Herrera, I.; Carrera Burneo, P. Environmental Flow Assessment in Andean Rivers of Ecuador, Case Study: Chanlud and El Labrado Dams in the Machángara River. Ecohydrol. Hydrobiol. 2017, 17, 103–112. [Google Scholar] [CrossRef]
- Lenssen, N.J.L.; Schmidt, G.A.; Hansen, J.E.; Menne, M.J.; Persin, A.; Ruedy, R.; Zyss, D. Improvements in the GISTEMP Uncertainty Model. J. Geophys. Res. Atmos. 2019, 124, 6307–6326. [Google Scholar] [CrossRef]
- Bell, G.D.; Janowiak, J.E. Atmospheric Circulation Associated with the Midwest Floods of 1993. Bull. Am. Meteorol. Soc. 1995, 76, 681–695. [Google Scholar] [CrossRef] [Green Version]
- Barnston, A.G.; Livezey, R.E. Classification, Seasonality and Persistence of Low-Frequency Atmospheric Circulation Patterns. Mon. Weather Rev. 1987, 115, 1083–1126. [Google Scholar] [CrossRef]
- Jones, P.D.; Jonsson, T.; Wheeler, D. Extension to the North Atlantic Oscillation Using Early Instrumental Pressure Observations from Gibraltar and South-West Iceland. Int. J. Climatol. 1997, 17, 1433–1450. [Google Scholar] [CrossRef]
- Zhou, S.; Miller, A.J.; Wang, J.; Angell, J.K. Trends of NAO and AO and Their Associations with Stratospheric Processes. Geophys. Res. Lett. 2001, 28, 4107–4110. [Google Scholar] [CrossRef]
- Lee, D.Y.; Petersen, M.R.; Lin, W. The Southern Annular Mode and Southern Ocean Surface Westerly Winds in E3SM. Earth Space Sci. 2019, 6, 2624–2643. [Google Scholar] [CrossRef] [Green Version]
- Trenberth, K.E.; Hurrell, J.W. Decadal Atmosphere-Ocean Variations in the Pacific. Clim. Dyn. 1994, 9, 303–319. [Google Scholar] [CrossRef]
- Mantua, N.J.; Hare, S.R. The Pacific Decadal Oscillation. J. Oceanogr. 2002, 58, 35–44. [Google Scholar] [CrossRef]
- Ashok, K.; Behera, S.K.; Rao, S.A.; Weng, H.; Yamagata, T. El Niño Modoki and Its Possible Teleconnection. J. Geophys. Res. Oceans 2007, 112, C11007. [Google Scholar] [CrossRef]
- Schwing, F.B.; Murphree, T.; Green, P.M. The Northern Oscillation Index (NOI): A New Climate Index for the Northeast Pacific. Prog. Oceanogr. 2002, 53, 115–139. [Google Scholar] [CrossRef]
- Wang, C.; Enfield, D.B. The Tropical Western Hemisphere Warm Pool. Geophys. Res. Lett. 2001, 28, 1635–1638. [Google Scholar] [CrossRef]
- Enfield, D.B.; Mestas-Nuñez, A.M.; Trimble, P.J. The Atlantic Multidecadal Oscillation and Its Relation to Rainfall and River Flows in the Continental U.S. Geophys. Res. Lett. 2001, 28, 2077–2080. [Google Scholar] [CrossRef] [Green Version]
- Penland, C.; Matrosova, L. Prediction of Tropical Atlantic Sea Surface Temperatures Using Linear Inverse Modeling. J. Clim. 1998, 11, 483–496. [Google Scholar] [CrossRef]
- Enfield, D.B.; Mestas-Nuñez, A.M.; Mayer, D.A.; Cid-Serrano, L. How Ubiquitous Is the Dipole Relationship in Tropical Atlantic Sea Surface Temperatures? J. Geophys. Res. Oceans 1999, 104, 7841–7848. [Google Scholar] [CrossRef]
- Chiang, J.C.H.; Vimont, D.J. Analogous Pacific and Atlantic Meridional Modes of Tropical Atmosphere–Ocean Variability. J. Clim. 2004, 17, 4143–4158. [Google Scholar] [CrossRef]
- Saji, N.H.; Yamagata, T. Possible Impacts of Indian Ocean Dipole Mode Events on Global Climate. Clim. Res. 2003, 25, 151–169. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Pajankar, A.; Joshi, A. Supervised Learning Methods: Part 2. In Hands-on Machine Learning with Python; Apress: Berkeley, CA, USA, 2022; pp. 149–165. ISBN 978-1-4842-7920-5. [Google Scholar]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and Statistical Modeling with Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 92–96. Available online: http://conference.scipy.org/proceedings/scipy2010/seabold.html (accessed on 25 April 2022).
- Brockwell, P.J.; Davis, R.A. Time Series: Theory and Methods; Springer Series in Statistics; Springer: New York, NY, USA, 1991; ISBN 978-1-4419-0319-8. [Google Scholar]
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting; Springer Texts in Statistics; Springer International Publishing: Cham, Switzerland, 2016; ISBN 978-3-319-29852-8. [Google Scholar]
- Contreras, P.; Orellana-Alvear, J.; Muñoz, P.; Bendix, J.; Célleri, R. Influence of Random Forest Hyperparameterization on Short-Term Runoff Forecasting in an Andean Mountain Catchment. Atmosphere 2021, 12, 238. [Google Scholar] [CrossRef]
- Ferri, F.J.; Pudil, P.; Hatef, M.; Kittler, J. Comparative Study of Techniques for Large-Scale Feature Selection. In Machine Intelligence and Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 1994; Volume 16, pp. 403–413. ISBN 978-0-444-81892-8. [Google Scholar]
- Raschka, S. MLxtend: Providing Machine Learning and Data Science Utilities and Extensions to Python’s Scientific Computing Stack. J. Open Source Softw. 2018, 3, 638. [Google Scholar] [CrossRef]
- Vapnik, V.N. Direct Methods in Statistical Learning Theory. In The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 2000; pp. 225–265. ISBN 978-1-4419-3160-3. [Google Scholar]
- Suykens, J.A.K.; Van Gestel, T.; De Brabanter, J.; De Moor, B.; Vandewalle, J. (Eds.) Least Squares Support Vector Machines; World Scientific: River Edge, NJ, USA, 2002; ISBN 981-238-151-1. [Google Scholar]
- Costa, R.L.; Barros Gomes, H.; Cavalcante Pinto, D.D.; da Rocha Júnior, R.L.; dos Santos Silva, F.D.; Barros Gomes, H.; Lemos da Silva, M.C.; Luís Herdies, D. Gap Filling and Quality Control Applied to Meteorological Variables Measured in the Northeast Region of Brazil. Atmosphere 2021, 12, 1278. [Google Scholar] [CrossRef]
- Fu, G.; Shen, Z.; Zhang, X.; Shi, P.; Zhang, Y.; Wu, J. Estimating Air Temperature of an Alpine Meadow on the Northern Tibetan Plateau Using MODIS Land Surface Temperature. Acta Ecol. Sin. 2011, 31, 8–13. [Google Scholar] [CrossRef]
- Gang, F.; Wei, S.; Shaowei, L.; Jing, Z.; Chengqun, Y.; Zhenxi, S. Modeling Aboveground Biomass Using MODIS Images and Climatic Data in Grasslands on the Tibetan Plateau. J. Resour. Ecol. 2017, 8, 42–49. [Google Scholar] [CrossRef]
- Wu, J.S.; Fu, G. Modelling Aboveground Biomass Using MODIS FPAR/LAI Data in Alpine Grasslands of the Northern Tibetan Plateau. Remote Sens. Lett. 2018, 9, 150–159. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River Flow Forecasting through Conceptual Models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the Mean Squared Error and NSE Performance Criteria: Implications for Improving Hydrological Modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef] [Green Version]
- Gubler, S.; Sedlmeier, K.; Bhend, J.; Avalos, G.; Coelho, C.A.S.; Escajadillo, Y.; Jacques-Coper, M.; Martinez, R.; Schwierz, C.; de Skansi, M.; et al. Assessment of ECMWF SEAS5 Seasonal Forecast Performance over South America. Weather Forecast. 2019, 35, 561–584. [Google Scholar] [CrossRef]
- Córdoba Machado, S.; Palomino Lemus, R.; Castro Díez, Y.; Gámiz-Fortis, S.; Esteban Parra, M.J. Mechanisms of precipitation variability at Colombia. In Proceedings of the VIII Congreso Internacional AEC: Cambio climático. Extremos e Impactos; Asociación Española de Climatología: Salamanca, Spain, 2012; pp. 301–310. (In Spanish) [Google Scholar]
- Mora, D.E.; Willems, P. Decadal Oscillations in Rainfall and Air Temperature in the Paute River Basin—Southern Andes of Ecuador. Theor. Appl. Climatol. 2012, 108, 267–282. [Google Scholar] [CrossRef] [Green Version]
- Vuille, M.; Bradley, R.S.; Keimig, F. Climate Variability in the Andes of Ecuador and Its Relation to Tropical Pacific and Atlantic Sea Surface Temperature Anomalies. J. Clim. 2000, 13, 2520–2535. [Google Scholar] [CrossRef]
- Vuille, M.; Bradley, R.S.; Keimig, F. Interannual Climate Variability in the Central Andes and Its Relation to Tropical Pacific and Atlantic Forcing. J. Geophys. Res. Atmos. 2000, 105, 12447–12460. [Google Scholar] [CrossRef] [Green Version]
- Raschka, S.; Mirjalili, V. Python Machine Learning: Machine Learning and Deep Learning with Python, Scikit-Learn, and TensorFlow 2, 2nd ed.; Packt Publishing Ltd.: Birmingham, UK, 2019; ISBN 978-1-78995-829-4. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Coelho, C.A.S.; Stephenson, D.B.; Balmaseda, M.; Doblas-Reyes, F.J.; van Oldenborgh, G.J. Toward an Integrated Seasonal Forecasting System for South America. J. Clim. 2006, 19, 3704–3721. [Google Scholar] [CrossRef] [Green Version]
- Kirtman, B.P.; Min, D.; Infanti, J.M.; Kinter, J.L.; Paolino, D.A.; Zhang, Q.; van den Dool, H.; Saha, S.; Mendez, M.P.; Becker, E.; et al. The North American Multimodel Ensemble: Phase-1 Seasonal-to-Interannual Prediction; Phase-2 toward Developing Intraseasonal Prediction. Bull. Am. Meteorol. Soc. 2014, 95, 585–601. [Google Scholar] [CrossRef]
- Becker, E.J.; Kirtman, B.P.; L’Heureux, M.; Muñoz, Á.G.; Pegion, K. A Decade of the North American Multimodel Ensemble (NMME): Research, Application, and Future Directions. Bull. Am. Meteorol. Soc. 2022, 103, E973–E995. [Google Scholar] [CrossRef]
- Liu, H.; Motoda, H. (Eds.) Computational Methods of Feature Selection, 1st ed.; Chapman and Hall/CRC Data Mining and Knowledge Discovery Series; Chapman and Hall: London, UK; CRC: Boca Raton, FL, USA, 2008; ISBN 978-1-58488-878-9. [Google Scholar]
- Zhang, X.; Hu, Y.; Xie, K.; Wang, S.; Ngai, E.W.T.; Liu, M. A Causal Feature Selection Algorithm for Stock Prediction Modeling. Neurocomputing 2014, 142, 48–59. [Google Scholar] [CrossRef]
- Sun, Y.; Li, J.; Liu, J.; Chow, C.; Sun, B.; Wang, R. Using Causal Discovery for Feature Selection in Multivariate Numerical Time Series. Mach. Learn. 2015, 101, 377–395. [Google Scholar] [CrossRef]
- Hmamouche, Y.; Casali, A.; Lakhal, L. A Causality Based Feature Selection Approach for Multivariate Time Series Forecasting. In Proceedings of the The Ninth International Conference on Advances in Databases, Knowledge, and Data Applications, IARIA, Barcelona, Spain, 21 May 2017; pp. 97–102. [Google Scholar]
- Yu, K.; Guo, X.; Liu, L.; Li, J.; Wang, H.; Ling, Z.; Wu, X. Causality-Based Feature Selection: Methods and Evaluations. ACM Comput. Surv. 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Yu, K.; Liu, L.; Li, J. A Unified View of Causal and Non-Causal Feature Selection. ACM Trans. Knowl. Discov. Data 2021, 15, 1–46. [Google Scholar] [CrossRef]
- Huang, J.-C.; Ko, K.-M.; Shu, M.-H.; Hsu, B.-M. Application and Comparison of Several Machine Learning Algorithms and Their Integration Models in Regression Problems. Neural Comput. Appl. 2020, 32, 5461–5469. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Zone | Indices |
|---|---|
| Global | Global Mean Land-Ocean Temperature (GMSST) [36]. |
| North Hemisphere | Pacific/North American Index (PNA), East Pacific/North Pacific Oscillation (EP/NP) [37], West Pacific Index (WP), North Atlantic Oscillation (NAO) [38], Jones NAO (J.NAO *) [39], East Atlantic (EA) and Arctic Oscillation (AO) [40]. |
| South Hemisphere | Antarctic Oscillation (AAO) [41]. |
| Northern Pacific | North Pacific pattern (NP) [42] and Pacific Decadal Oscillation (PDO) [43]. |
| Tropical Pacific | Pacific Warmpool Area Average (PacWarm), Extreme Eastern Tropical Pacific sea surface temperature (SST) (Niño 1+2) and its anomaly values (Niño 1+2.A), Eastern Tropical Pacific SST (Niño 3) and its anomaly values (Niño 3.A), East Central Tropical Pacific SST (Niño 3.4) and its anomaly values (Niño 3.4.A), Central Tropical Pacific SST (Niño 4) and its anomaly values (Niño 4.A), Trans-Niño Index (TNI), Southern Oscillation Index (SOI), Bivariate ENSO Timeseries (BEST), Bi-monthly Multivariate El Niño/Southern Oscillation (ENSO) index version 2 (MEIv2) and El Niño Modoki Index (EMI) [44]. |
| Pacific | Tripole Index for the Interdecadal Pacific Oscillation (TPI.IPO) and Northern Oscillation Index (NOI) [45]. |
| Atlantic and Eastern North Pacific | Western Hemisphere Warm Pool (WHWP) [46]. |
| North Atlantic | Atlantic Multidecadal Oscillation UnSmoothed (AMO.US †) [47]. |
| Tropical Atlantic | Caribbean SST Index (CAR) [48], Tropical Northern Atlantic Index (TNA) [49], Tropical Southern Atlantic Index (TSA) [49] and Atlantic Meridional Mode SST index (AMM) [50]. |
| Tropic | Quasi-Biennial Oscillation (QBO), ENSO precipitation index (ESPI), Western Indian Ocean Dipole (IOD.W ‡), Eastern Indian Ocean Dipole (IOD.E ‡) and Dipole Mode Index (DMI ‡) [51]. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vázquez-Patiño, A.; Peña, M.; Avilés, A. Assessment of Quarterly, Semiannual and Annual Models to Forecast Monthly Rainfall Anomalies: The Case of a Tropical Andean Basin. Atmosphere 2022, 13, 895. https://0-doi-org.brum.beds.ac.uk/10.3390/atmos13060895
Vázquez-Patiño A, Peña M, Avilés A. Assessment of Quarterly, Semiannual and Annual Models to Forecast Monthly Rainfall Anomalies: The Case of a Tropical Andean Basin. Atmosphere. 2022; 13(6):895. https://0-doi-org.brum.beds.ac.uk/10.3390/atmos13060895
Chicago/Turabian StyleVázquez-Patiño, Angel, Mario Peña, and Alex Avilés. 2022. "Assessment of Quarterly, Semiannual and Annual Models to Forecast Monthly Rainfall Anomalies: The Case of a Tropical Andean Basin" Atmosphere 13, no. 6: 895. https://0-doi-org.brum.beds.ac.uk/10.3390/atmos13060895