3.1. Statistic Analysis
The
p-value given by the Kolmogorov–Smirnov Lilliefors test is less than 0.05 for both datasets (D = 0.24532 and D = 0.2397 for outdoor and indoor datasets, respectively), meaning that, indeed, the data is not normally distributed. The median PM
concentration registered is between 12
g/m
3 and 16
g/m
3, with an IQR between 10
g/m
3 and 22
g/m
3, in the different monitored areas of the city (see
Table 2). The maximum level for PM
was recorded at the AQIoT-4 station (621
g/m
3), and 636
g/m
3 for PM
, which occurred during the forest fire season at the beginning of August (summer season). At the AQIoT-3 station, a median PM
of 13
g/m
3 was registered, and a PM
of 18
g/m
3 at the AQIoT-4 station during the study period. In this period, the minimum temperature of 15.3 °C was recorded in the first week of October 2021 (autumn season) at the AQIoT-5 monitoring station, which is located near the mountain area (see
Table 2). Relative humidity was reported with minimums of 29% to 41% in late spring and summer, with a maximum of 99% recorded during the rainy season (September and October).
The reference value standard in Mexico is defined as 30
g/m
3 for PM
and 50
g/m
3 for PM
for a 24-h average, published by the Ministry of Health of the Government of Mexico in the environmental health norm [
52]. In this context, the AQIoT-2 station PM
daily mean exceeded the official norm on October 13 and 14 (33.9
g/m
3 and 37.75
g/m
3). At the AQIoT-3 station, the norm was exceeded on several days with a mean PM
concentration of 37.88
g/m
3 (July 18), 32.24
g/m
3 (1 September), and 34.68
g/m
3, 38.20
g/m
3, 41.18
g/m
3, and 32.84
g/m
3 from 12 October to 15 October, respectively. At the AQIoT-4 station, the greatest number of days with concentrations outside the permissible limits for PM
and PM
occurred. The following levels for PM
were recorded: 48.15
g/m
3 on 18 Jul, from 19 August to 31 August, levels between 43.77
g/m
3 and 258.72
g/m
3, on September 1, 32.56
g/m
3, and 36.97
g/m
3, 39.75
g/m
3, 44.64
g/m
3, and 35.37
g/m
3 from 12 October to 15 October, respectively. PM
concentrations exceeded the environmental health norm with 62.19
g/m
3 (18 July), 76.80
g/m
3 to 259.46
g/m
3 from 19 August to 31 August and on 14 October with a 56.12
g/m
3 level. Finally, at the AQIoT-5 station, the PM
limit was exceeded with levels of 33.37
g/m
3 (1 September) and between 31.48
g/m
3 to 42.73
g/m
3 from 12 October to 15 October and 51.74
g/m
3 for PM
on 14 October 2021.
On the other hand, in the descriptive analysis for particulate matter data inside the houses, the lowest median of 8(11)
g/m
3 was recorded in households located near the AQIoT-4 station (see
Table 3), and the highest median of 21(19)
g/m
3 at the AQIoT-2 station. PM
levels follow this pattern of these stations with 9(11)
g/m
3 and 23(21)
g/m
3, respectively. The maximum for PM
pollution was registered in 311
g/m
3 and for PM
in 365
g/m
3. The activities may influence these values carried out in the kitchen and the filtration of pollutants from the outside. In addition, most of the monitored houses do not have a cooker hood installed on the stove that allows the extraction of particles generated when cooking food and by the combustion of liquefied petroleum gas (butane/propane) used for cooking food. The maximum temperature recorded inside the houses was very high (from 37.9 °C to 39.6 °C), with an average temperature between 33.6 °C to 34.8 °C in the monitored areas (see
Table 3). These temperatures occurred between 3:00 p.m. and 9:00 p.m., from May to August 2021, coinciding with minimums of 33.9% to 38.7% relative humidity.
The accumulated confirmed cases during the study period were 5981 people with a positive test (53% are female patients), with a daily maximum of 104 confirmed cases of COVID-19.
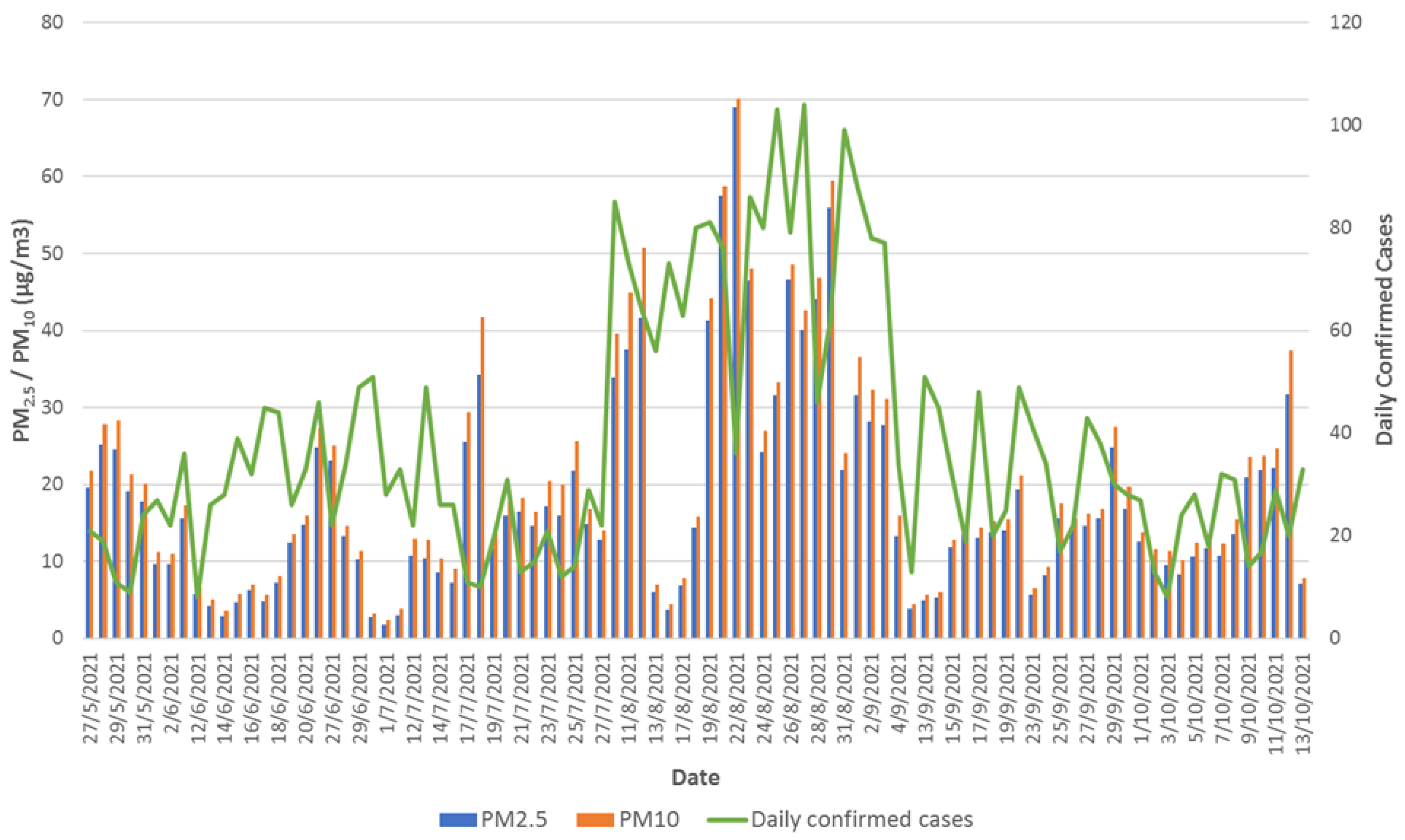
Figure 1 shows the daily increase in infected people reported by the Ministry of Public Health between 1 May and 31 October 2021. On the other hand, in the study period, 138 deaths caused by complications from COVID-19 were reported (63% correspond to male patients), with a cumulative of 571 deaths since initiating the process of confinement for the pandemic (17 March 2020).
Figure 2 and
Figure 3 show the mean daily concentration of PM
and PM
in outdoor and indoor air, respectively, and the number of COVID-19 cases recorded per day.
Figure 2 shows that on several days in August 2021, the 24 h standard average (30
g/m
3) for PM
was exceeded, coinciding with the period in which the highest number of COVID-19 confirmed cases per day were recorded. In the case of the pollutant PM
, the short-term standard (50
g/m
3) for daily average was exceeded on four occasions during the same month.
Furthermore, Spearman correlation analysis was used to decipher the relationships between confirmed COVID-19 cases, particulate matter ambient air pollutants concentrations, and five meteorological variables.
Table 4 shows Spearman’s coefficient matrix calculated using the dataset of particulate matter and meteorological factors in outdoor air. This analysis aims to identify the behavior and association between the study variables, considering the growth in positive cases and deaths for COVID-19 in these 20 weeks. All particulate matter types showed perfect positive correlation with each other, r = 1 (
p-value < 0.01). Statistically moderate positive correlations between PM
and temperature (T) and PM
and T were found at a significant level of 5% (0.56 ≥ r ≤ 0.59). We found that PM
and PM
have a strong negative correlation for daily confirmed cases (DCC) of COVID-19, with a coefficient value of −0.74 (
p-value < 0.01) in both associations. Furthermore, results show a moderate correlation coefficient of atmospheric pressure and deaths for COVID-19 at 0.49, with a
p-value of less than 0.05. The correlation analysis reveals a negative coefficient between the relative humidity (RH) and T (r = −0.70,
p-value < 0.01). We observe that T exhibits a strong relationship (r = 0.64,
p-value < 0.01) with wind direction (WD) variable.
On the other hand,
Table 5 shows the Spearman correlation matrix computed for the indoor dataset. In this second correlation scenario, the concentration of pollutants and meteorological parameters for the 20 households and the confirmed cases and deaths from COVID-19 in the study’s period were considered. The correlation coefficient between PM
and PM
was highlighted as very high with r = 0.99 and the
p-value < 0.01, as well as a moderate association between PM
and PM
with the temperature (T) variable with r = 0.53 and r = 0.50, respectively. Furthermore, we found a moderate relationship between relative humidity (RH) and the two types of particulate matter, with a significance level of less than 0.05. The variables corresponding to the meteorological parameters present strong correlations. Temperature and relative humidity show a correlation coefficient of r = 0.60 (
p-value < 0.01). In addition, a strong positive correlation between wind direction (WD) and the variable wind speed (WS) with r = 0.69 (
p-value < 0.01), as well as a negative association between relative humidity and wind speed of r= −0.60,
p-value < 0.01. Finally, the correlation between PM
and PM
with the daily confirmed cases (DCC) of COVID-19 shows important changes with respect to the level of correlation found in the outdoor scenario: a moderate positive correlation of r = 0.50 between PM
and confirmed cases and a relationship between PM
and confirmed cases of r = 0.48 (
p-value < 0.05). Furthermore, in this scenario, we find a moderate positive correlation between the particulate matter variables and COVID-19 deaths, with r = 0.40 and
p-value < 0.05, in both cases.
3.2. Dataset Analysis
Before implementing the machine learning algorithm based on K-means clustering, the datasets were analyzed to identify if there is a structure in the behavior of the values of the multidimensional variables. Visualizing multidimensional data is a complex process compared to visualizing data in two or three dimensions. Then, implementing the Andrews curves method, one can identify the dataset structure since complex data is reduced to a two-dimensional graph, making it possible to specify the associated variables, the formation of groups, and outliers within the dataset. The curves are created using the features of instances of each dataset as coefficients of the Fourier series.
Figure 4 shows the graph of the Andrews curves generated by comparing the outdoor data of air pollution and meteorological factors with the indoor data of air pollution and meteorological parameters. In this Figure, each color represents a class (indoor/outdoor); it can be seen that the lines that represent the instances of the same class have similar curves. Furthermore, a similarity between the curves of the two classes is identified. In addition, it is observed that the vast majority of the data has a structure of sinusoidal curves with which a pattern is discovered in the data, which makes it possible to apply an automatic learning algorithm to discover this structure and understand the equation behind its data. The Andrews plot shows the areas where the classes are grouped and correlated (for example, on the
X-axis with a value of 1.1 and between −300 and −1200 on the
Y-axis. Similarly, a correlation between classes can be seen in the value 2 on the
X-axis and between the values 700 and 1500 on the
Y-axis). On the other hand, some atypical values are observed in the outdoor class (gray lines), for example; in the curve located at the value of 0.2 on the
X-axis with the value of 1750 on the
Y-axis. In values 2.2 and 1750 corresponding to the
X-axis and
Y-axis, other outliers occur in the same class. In addition, atypical values are observed in the indoor class (green lines), which are displayed correlated with atypical values of the outdoor class throughout the plot, for example, in the line located at the value −2 of the
X-axis with the value −250 of the
Y-axis.
In
Figure 5, four classes corresponding to outdoor air quality monitoring stations (AQIoT-2, AQIoT-3, AQIoT-4, and AQIoT-5) were defined to discover if the data from the four monitoring stations share a data structure and follow a pattern. This Figure shows the data structure using the Andrews curves method; it identified that it has a similar structure and is consistent with the data structure and patterns discovered in
Figure 4. In addition, the same types of outliers are identified, and most belong to the AQIoT-4 monitoring station (purple lines). It is observed that some of these outliers correlate with values from the AQIoT-2 monitoring station (gray lines). These two monitoring stations are located in the southeast and northeast areas of the city, with a linear distance of approximately 5 km, and share similar characteristics of altitude above sea level, topographical conditions, and wind currents. This correlation is visualized in the lines at the value −2 on the
X-axis and between −200 and −350 on the
Y-axis.
Figure 6 shows the indoor air pollution data structure for which 20 classes were defined and represent the data collected in the 20 monitored houses. At the level of detail displayed in
Figure 6, it is observed that in the data structure in the rise of the curve located at the value −2 of the
X-axis (between the values 700 and 1000 of the
Y-axis) until the descent before the curve located at the value −1 of the
X-axis (between the values −850 and −1300 of the
Y-axis) there is an almost perfect grouping of the lines, which continues at the end of this curve and until the beginning of the next curve. A group between fewer classes but with a correlation between all classes is visualized in the following curves. Regarding the outliers, it is identified that the house labeled with class 17 correlates with the outliers identified for outdoor class (see
Figure 4). This discovery is important because household 17 is close to the AQIoT-4 monitoring station (see outliers in
Figure 5).
3.3. Clustering Analysis
The K-means clustering algorithm was used to classify the instances of all variables in each dataset. The K-means algorithm is an unsupervised method of grouping by partitions; it does not require a class or prior knowledge to classify an instance within a group or cluster based on a measure of similarity between samples. In our approach, the algorithm was implemented using the Euclidean distance metric, selecting the instances with the minimum distance to the centroid (); that is, there is maximum homogeneity between the objects in the group and the greatest difference between the groups. The number of clusters (K) was defined by implementing the Elbow method, which allows for determining the optimal value for K. In the three datasets used in our experiment, this method determined an optimal value of , using all the variables and instances in each dataset. In addition, the value of the initial centroids was defined randomly, considering all the instances of the dataset.
The clustering analysis will allow identifying the groups that contain more instances and the origin of these instances (indoor or outdoor, monitoring station or homes), enabling us to find a representative group that allows training the LSTM neural network model with high performance and predict with the minimum error future cases of people infected by COVID-19.
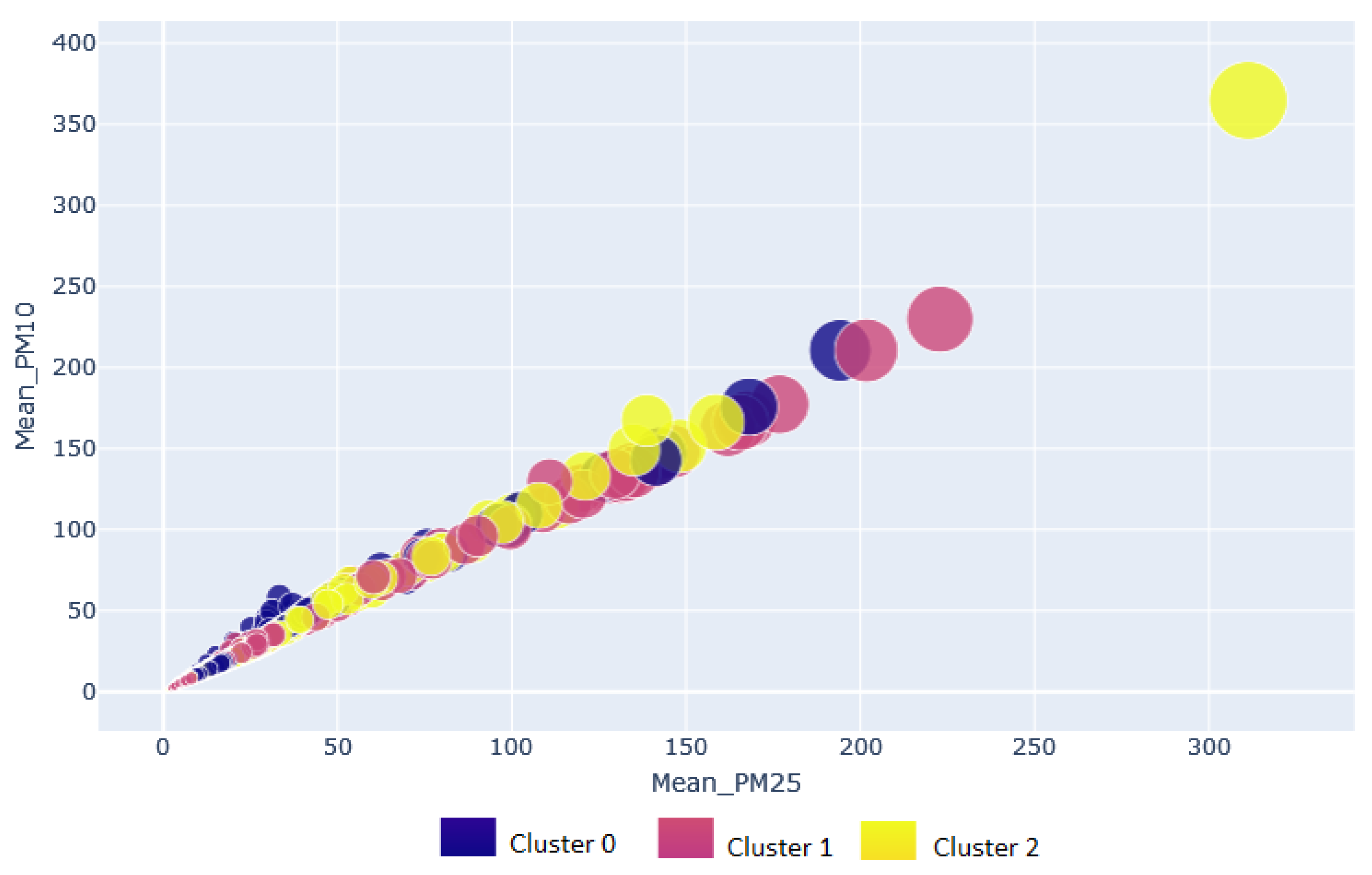
Figure 7 shows the result of the clustering analysis considering the dataset divided into indoor and outdoor environments. Cluster 0 is the most populated with 3643 instances, followed by clusters 2 and 1 with 3547 and 2789. Most cluster 0 instances belong to the AQIoT-4 monitoring station or the houses located near this station and are linked to the AQIoT-4 monitoring station; the same scenario is presented in cluster 2. The goodness of the clustering obtained was evaluated through the silhouette coefficient (also known as silhouette width), obtaining a value of Si = 0.61; a value in the Si > 0 means that the observation is well grouped; the closer it is to 1, the better the grouping. The silhouette coefficient allows interpreting and validating the coherence between the group elements; that is, it measures how similar an object is within its group (cohesion) compared to other groups (separation).
Figure 8 shows the clusters generated for the outdoor type dataset divided by a monitoring station. Cluster 1 has the largest number of instances (2910); in cluster 0, 2829 homogeneous instances are grouped. In cluster 1 and cluster 2, most samples correspond to the AQIoT-3 monitoring station, followed by AQIot-4 with a minimum difference of six instances. AQIoT-4 is the most representative in instances grouped in cluster 0. In the grouping validation, the model outdoor type dataset obtained an average silhouette width of Si = 0.62.
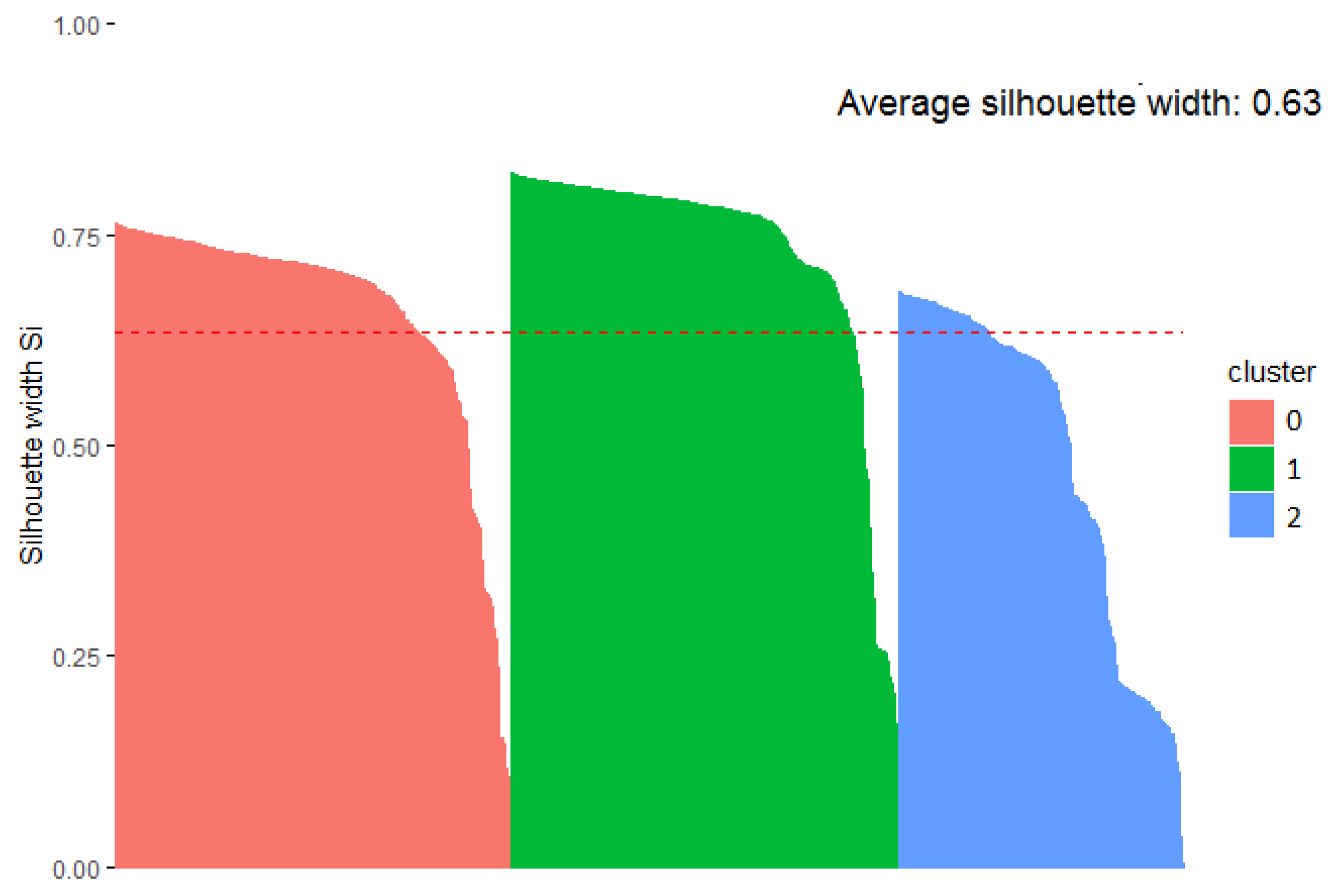
The cluster analysis, using the data collected inside houses presents a behavior similar to that displayed in the cluster analysis for indoor–outdoor and outdoor datasets. The similarity is observed in the formation of the clusters, the clusters with more instances, and the origin of the instances (linkage to a monitoring station).
Figure 9 shows the formation of the clusters using the indoor data; some instances with greater distance to the centroid of their cluster are observed for which they are shown separated from the group. The clusters generated from the indoor data obtained the best goodness evaluation compared to the previously presented clusters, with a Si = 0.63, as shown in
Figure 10.
3.4. Prediction Model
Instances labeled with the AQIoT-4 monitoring station identifier were extracted from the indoor and outdoor datasets, generating two new datasets. In each of these datasets, 80% of the instances were selected to build a sub-dataset (for each dataset) that will be used in the training of the LSTM neural network, which allows generating a prediction model based on LSTM for each dataset (indoor/outdoor). The remaining 20% of instances of the original dataset were built into the test sub-dataset and used to evaluate the prediction model’s performance. In the training stage, the LSTM model learns from the behavior (dependency between variables) identified from the regression analysis of each instance in the training dataset. The number of confirmed cases is the target or dependent variable (output) and is a function of independent variables or predictors (input). In our experiment, the predictors are PM, PM, temperature, relative humidity, atmospheric pressure, wind speed, and wind direction. Then, with the predictive model generated in the training stage, each instance of the test dataset is used to predict the value per day of the confirmed cases variable. In each prediction, the LSTM model receives the value of the eight predictor variables as input.
Table 6 shows the performance obtained by the LSTM prediction model using the outdoor dataset. First, the prediction model is evaluated with the remaining 20% of the AQIoT-4 monitoring station dataset instances. The prediction model obtains error metrics very close to 0. The RMSE metric reaches a value of 0.0897, indicating the concentration level of the data in the regression line has an excellent fit, with a minimum distance from the data points of the regression line. Furthermore, the difference between the predicted and actual values is low, with an MAE of 0.0837, indicating that the average forecast is very acceptable. Regarding the MAPE metric, a value reached 0.4229 suggests that the average difference between the predicted and current values is less than 1%.
The LSTM prediction model was validated with 100% of the dataset instances from the AQIoT-2, AQIoT-3, and AQIoT-5 monitoring stations. An RMSE metric of 0.2560 was obtained with the first dataset (see
Table 6), indicating an average distance between the predicted values of confirmed cases of COVID-19 by the model and the real values in the validation dataset. Moreover, the prediction model obtained an MAE = 0.2560, an MSE = 0.0655, and a MAPE = 0.4196, reporting a high accuracy of the regression model in the prediction. Similarly, in the validation of the prediction model with the datasets of the monitoring stations AQIoT-3 and AQIoT-5, very acceptable error metrics were achieved, 0.2523 and 0.2386 in the RMSE and MAE of 0.1483 and 0.1508, respectively. In the validation stage with the outdoor data collected at the AQIoT-5 station, the model obtained the highest MAPE error metric for the prediction task (0.5070).
Figure 11 shows the comparison of the time series between the actual data (blue line) and the predicted data (red line), with a prediction of 85 days of confirmed cases of COVID-19, using 100% of the dataset on particulate matter and meteorological factors collected at the AQIoT-2 monitoring station (outdoor).
Figure 11 shows a similar prediction between the real (original) value and the predicted value; only in the forecast between days 40 and 42 (
X-axis) is there a slight separation between predicted and real data. On days 46, 48, 51, and 83, a prediction slightly lower than the real value is observed.
Figure 12 shows the prediction of confirmed cases of COVID-19 generated from the AQIoT-4 station test dataset. The predicted data is for 16 days, without observing a difference between the predicted data line and the real data. This is because the difference between the number of confirmed cases predicted and the number of confirmed cases contained in the test dataset is at the decimal level (for example, 6.148918 vs. 6), which is confirmed by the metrics of very low errors achieved by the deep learning LSTM network model.
Table 7 presents the performance of the LSTM prediction model for confirmed cases of COVID-19, using PM
, PM
concentration data and meteorological parameters collected inside houses as input data to the model. The neural network LSTM was trained with 80% of the instances of the indoor dataset linked (located near) to the AQIoT-4 monitoring station. The remaining 20% of the dataset was used to test the prediction model. Moreover, the predictive model was validated with 100% of the three datasets containing particulate matter concentration and meteorological factor values in five households (indoor) each. These houses are located near the AQIoT-2, AQIoT-3, and AQIoT-5 monitoring stations, respectively. The validation of the prediction model using the dataset of houses near the AQIoT-2 monitoring station obtained a very acceptable performance with very low error metrics, with values of 0.4152, 0.3243, and 0.1724, in RMSE, MAE, and MSE, and with a value in the MAPE metric less than 2%. In the validation with data from houses near the AQIoT-3 station, the highest error metrics of the model were reached, with an RMSE = 3.9084, an MAE = 1.1627, and a MAPE of 4.0744 (see
Table 7). These metrics are acceptable since the prediction model adjusts to unknown values and complex behaviors in the input data and manages to predict confirmed cases of COVID-19 with error metrics of less than 5%. The minor error metrics in the testing and validation stages of the predictive model were obtained with the dataset of houses near the AQIoT-4 monitoring station, with values of 0.0892, 0.0592, and 0.2061 for RMSE, MAE, and MAPE, respectively, confirming the high performance and accuracy of the predictive model (see
Table 7). When the model was validated with the dataset of houses near the AQIoT-5 monitoring station, an RMSE = 1.5046, a MAPE of less than 2%, and an MAE value of 1.0603 were obtained, demonstrating that the predicted data are very close to actual data.
Figure 13 and
Figure 14 show the predictions of confirmed cases of COVID-19 using the pollution values by particulate matter (PM
and PM
) and meteorological parameters inside houses located around the monitoring stations AQIoT-3 and AQIoT-5. With these datasets, the prediction model reached the highest values in the error metrics in its validation stage (see
Table 7). In the predicted data shown in the time series of
Figure 13, a different behavior than expected is identified on day 4, with a predicted value lower than the actual value (8.12 versus 26). Subsequently, the behavior is similar between the real and the predicted data, with a slightly smaller difference between the predicted data and the original data on days 12, 16, 18, and 20. In the time series shown in
Figure 14, the predicted data line follows the behavior discovered in the real data. However, in the prediction of the second day, it has a value slightly higher than expected. In contrast, from day 13 to day 22, it predicts slightly lower than expected values in the number of confirmed cases.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}