1. Introduction
South Africa hosts the majority of the world’s platinum group metal (PGM)-reserves in the Bushveld Igneous Complex [
1]. These PGMs are extracted from nickel-copper ores contained in the Bushveld Complex through a series of process steps. Mined ore undergoes comminution, liberating sulphides to create a sulphide concentrate that is concentrated through flotation. Flotation concentrates are smelted and converted, yielding a copper-nickel matte rich in PGMs. Precious metals within the matte are separated from base metals through hydrometallurgical treatments before being refined into their pure forms [
2].
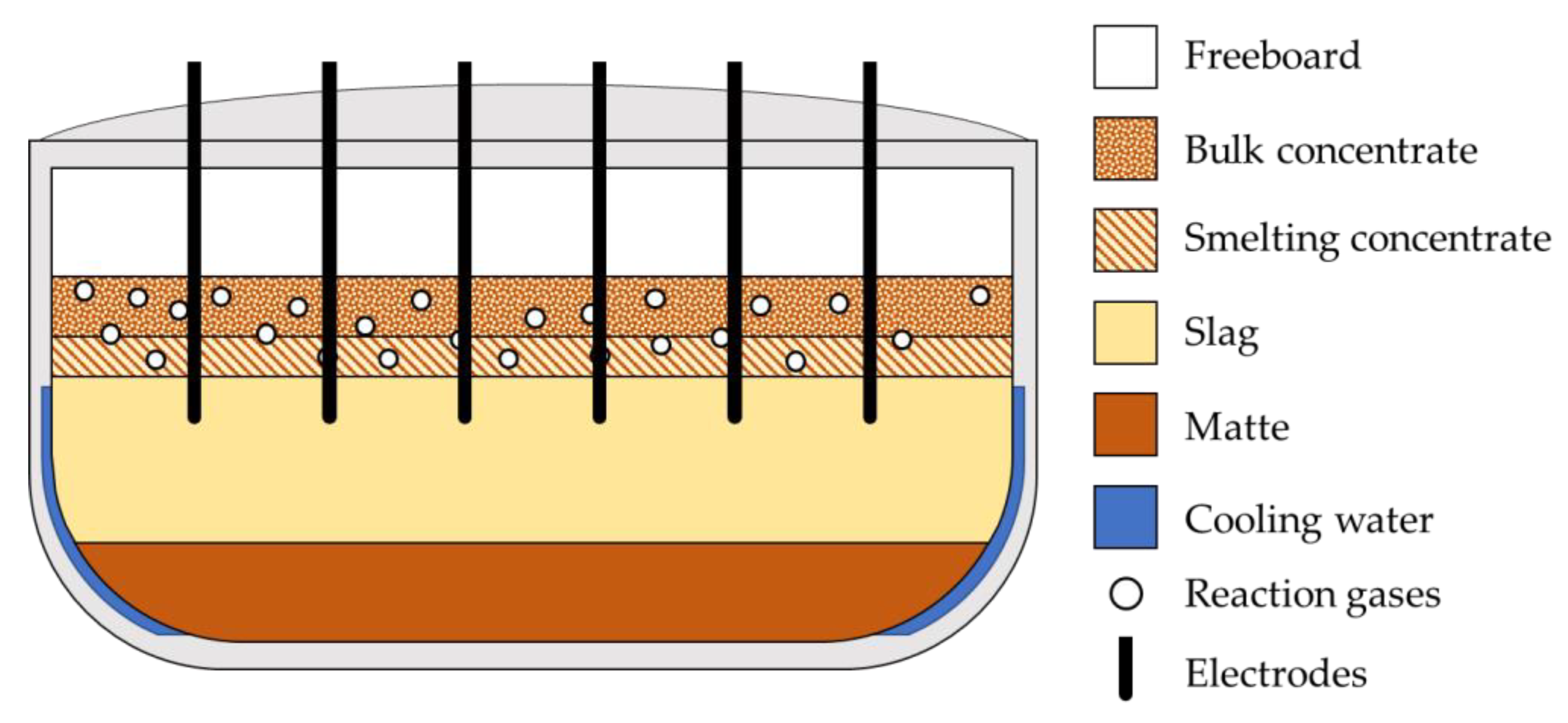
Each of the aforementioned processing steps reduces the bulk of the concentrate or separates gangue from precious metals, increasing the PGM concentration. The smelting step is crucial to the overall PGM extraction process; during smelting, submerged electrode arc furnaces melt dried concentrate into a sulphide matte that acts as a PGM collector, increasing the concentration of PGMs tenfold [
2]. The overall viability of the PGM extraction process is therefore reliant on the submerged arc furnaces being operated safely, effectively, and efficiently.
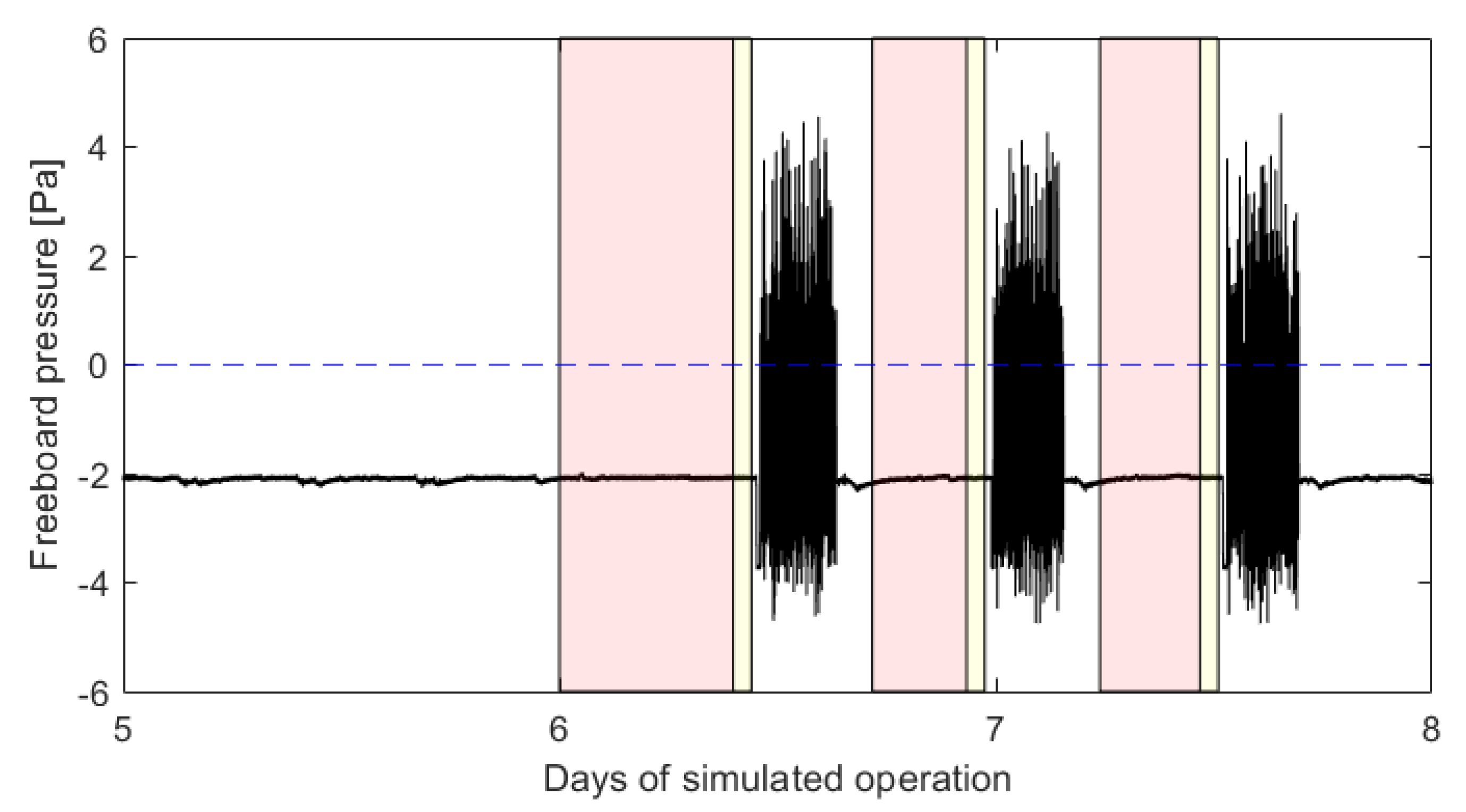
Desulphurization and electrode oxidation reactions within the furnace release sulphur dioxide and carbon monoxide into the furnace freeboard at high temperatures [
3], resulting in a freeboard filled with hot, hazardous gases. Freeboard gases are extracted continuously to maintain a negative gauge pressure, preventing these gases from escaping into the surrounding area and jeopardizing operator safety [
4]. Atmospheric air drawn in by the negative gauge pressure cools the furnace contents, consequently furnace efficiency is promoted by maintaining the pressure as close to zero as possible.
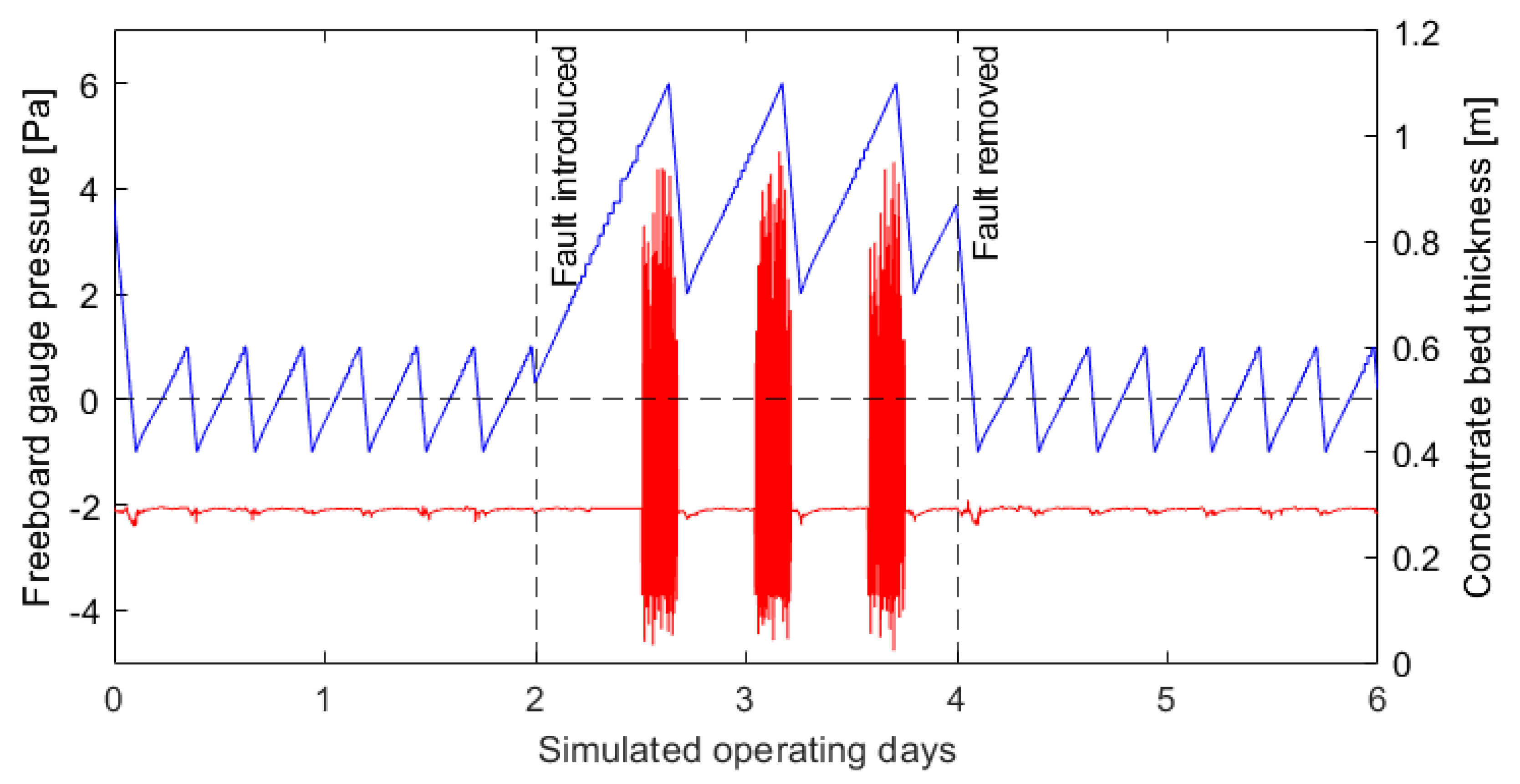
Freeboard pressures can routinely exceed atmospheric pressure despite gas extraction, causing blowbacks. Positive pressure events, also known as blowbacks, occur when hazardous gases escape from industrial furnaces and their causes are unknown. A monitoring model for predicting these events will therefore promote the safety of the smelting operation by providing a warning to operators of impending blowbacks and allow freeboard pressures to be raised when blowbacks are not imminent, promoting efficiency.
Similar to comminution and flotation processes, furnaces are subject to disturbances in the grade and supply of concentrate. These similarities extend to complex process interactions: furnaces are subject to interactions between various furnace zones just as particle interactions, recycle streams, and slurry-air interactions are present and challenging in comminution and flotation process units. Fault conditions in furnaces (i.e., blowbacks), comminution (e.g., mill trips from mill overloading), and flotation (e.g., sliming incidents) can cause sub-optimal operation with potentially rapid and extreme consequences.
Furnaces, as well as the physical mineral processing operations, generate large volumes of historical data. The large data volume recorded from these processes promotes the use of statistical process monitoring for predicting hazardous events such as blowbacks, mill trips, and sliming incidents [
5]. This paper evaluates one-dimensional convolutional neural networks as reconstruction-based process monitoring models for predicting blowbacks in industrial submerged arc furnaces. This evaluation will yield insights into the suitability of reconstruction-based monitoring models for predicting hazardous events across the mineral processing chain.
Ideally, historical data recorded from submerged arc furnaces used to develop blowback-prediction models would be completely characterized, i.e., all observations in the historical dataset would be labelled correctly. Models could be trained to predict all possible events from using such a dataset by separating all historical observations into distinct classes [
6]. Unfortunately furnace data, like most real-world datasets, are poorly characterized and event-prediction models must be trained using datasets where only a few observations are labelled properly. This constraint has spurred the development of reconstruction-based one-class classifiers as event prediction models [
7].
Reconstruction-based one-class classifiers are data-driven models trained to find effective, compressed representations of specific process patterns [
8]. If a model is trained to reconstruct the process patterns preceding specific events, then it will reconstruct the specific event-preceding patterns with minimal error. Process patterns that do not precede the target event will be reconstructed inaccurately. This facilitates event prediction based on reconstruction error [
9]; lower reconstruction errors suggest that the specific event is imminent, while large reconstruction errors suggest that the event is not imminent. Reconstruction-based event-prediction models are distinguished by how they find compressed representations of process faults.
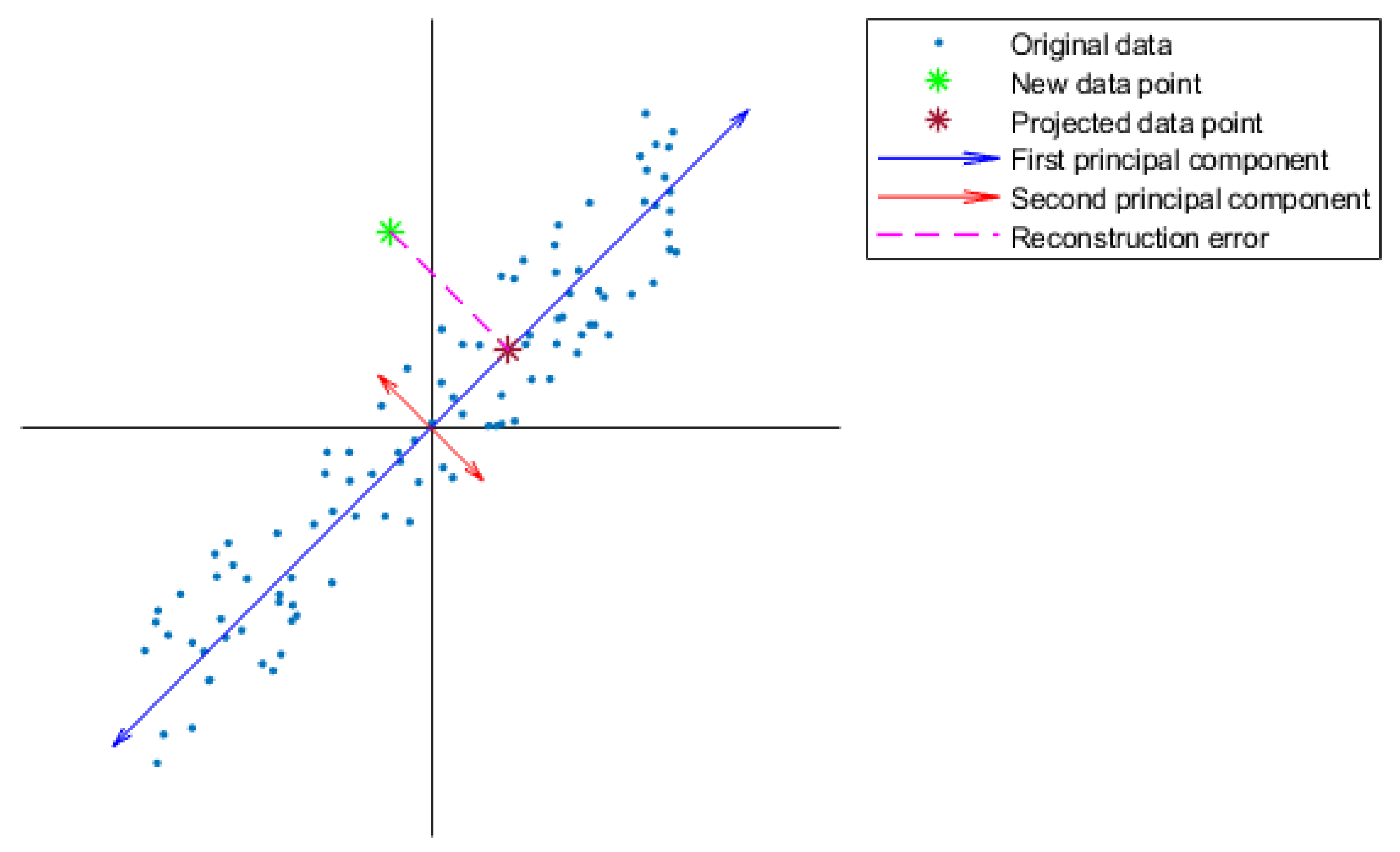
Principal component analysis (PCA) is the most common approach to feature learning [
5,
10], and recognizes linear correlations in event-preceding processes [
9]. The efficacy of PCA in recognizing specific process patterns has been demonstrated for detecting faults on the Tennessee Eastman simulated process [
11], for modelling the normal conditions of batch and continuous chemical processes [
12], and for detecting faults in industrial boiler data [
13]. Unfortunately, the performance of PCA deteriorates when applied to the nonlinear correlations typically found in industrial data [
8], leading to the increasing prominence of neural network-based one-class classifiers.
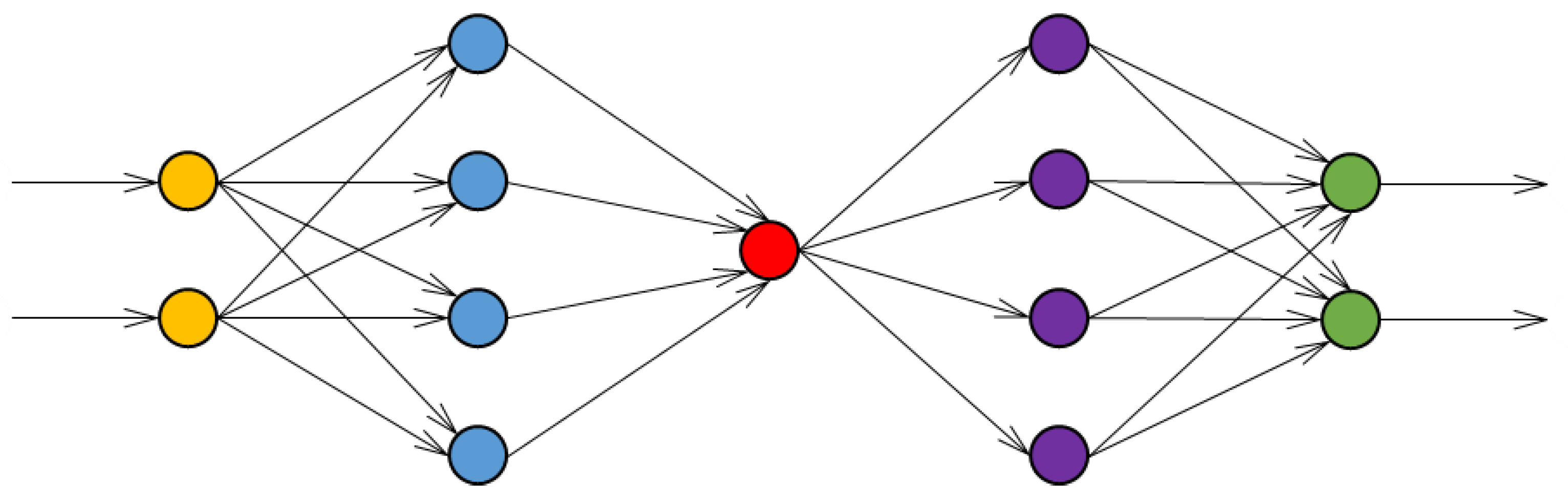
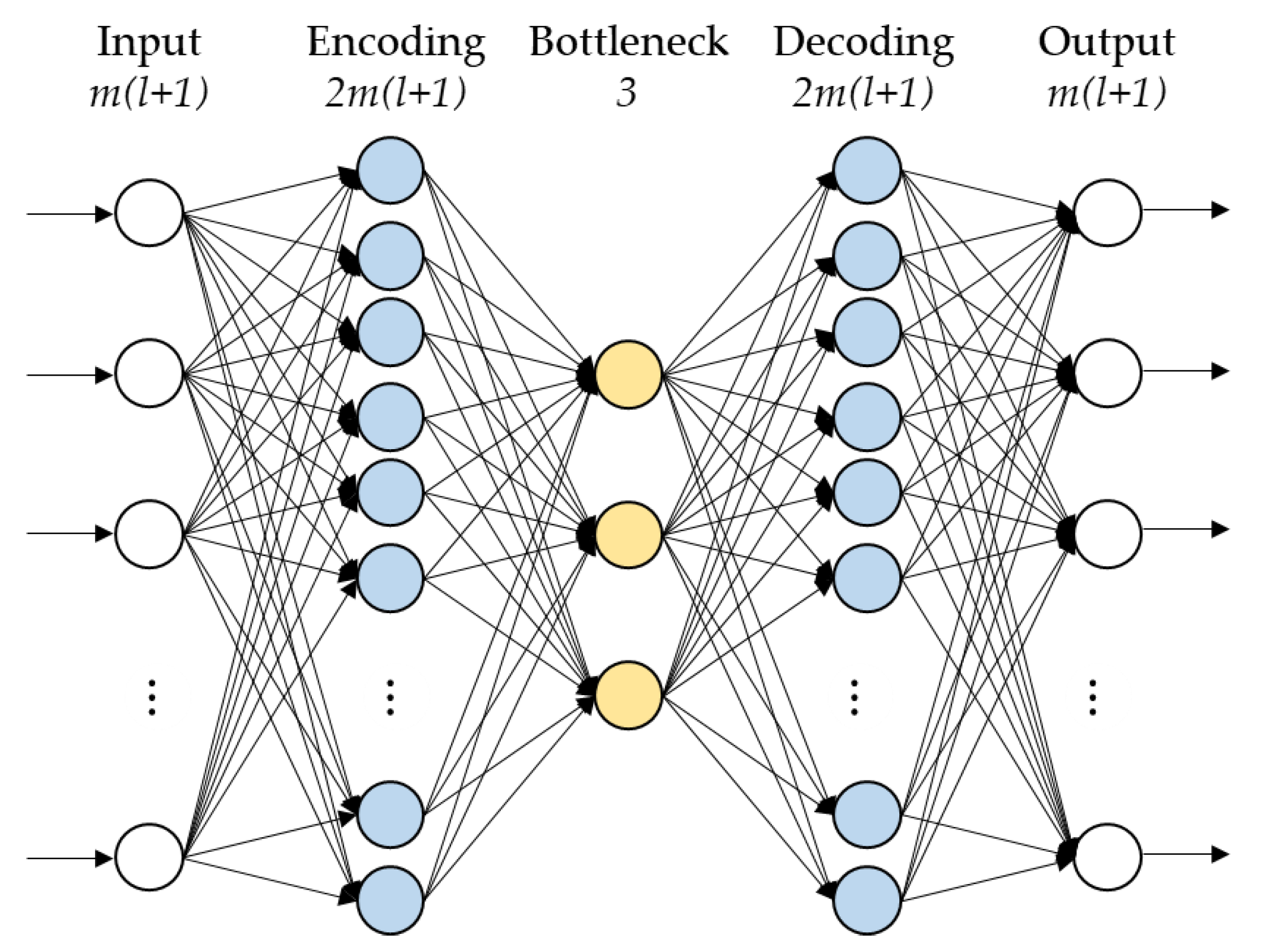
Auto-encoders (AEs) are neural networks that find the low-dimensional subspace that accurately represents network inputs, then reconstruct these inputs as the network outputs. When trained to reconstruct specific event-preceding process patterns they make ideal candidates for reconstruction-based one-class classifiers [
10]. Their ability to learn nonlinear representations of industrial process data was demonstrated on the Tennessee Eastman case study [
14], and their ability to recognize specific process patterns was demonstrated on a simulated coal mill system [
15].
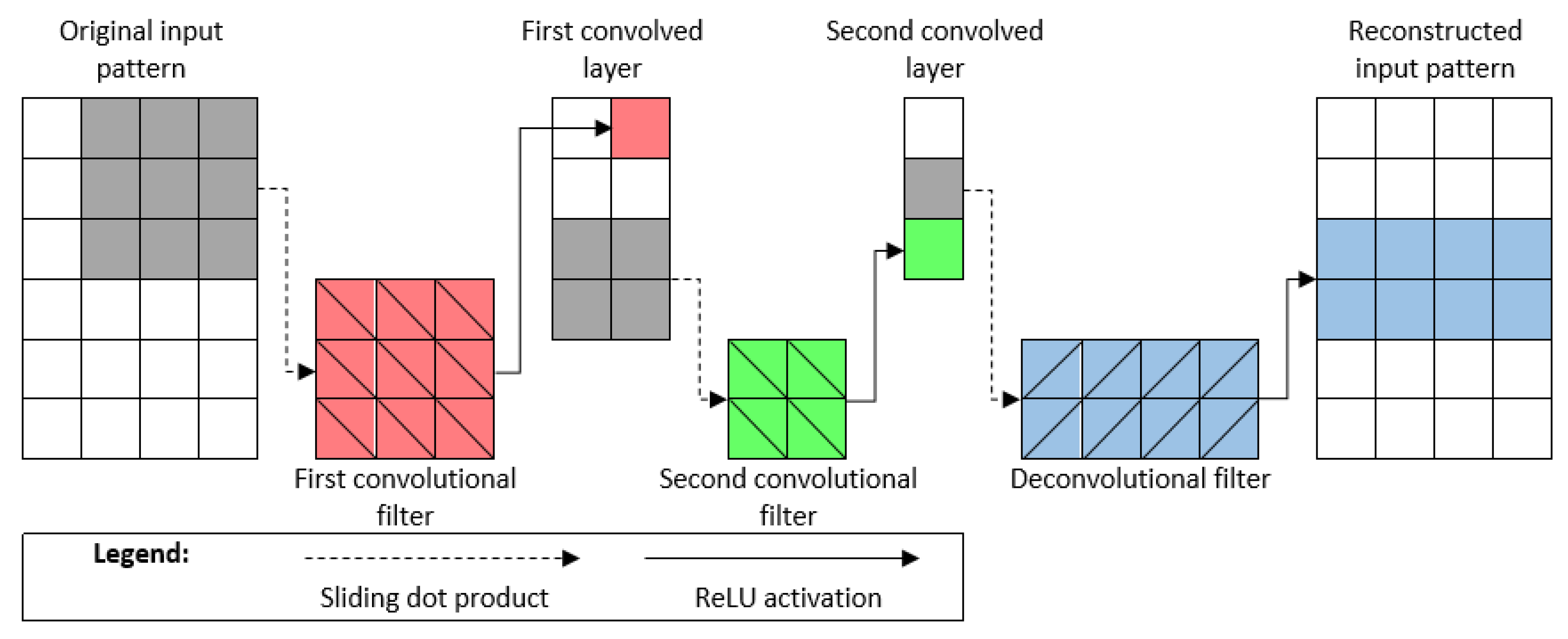
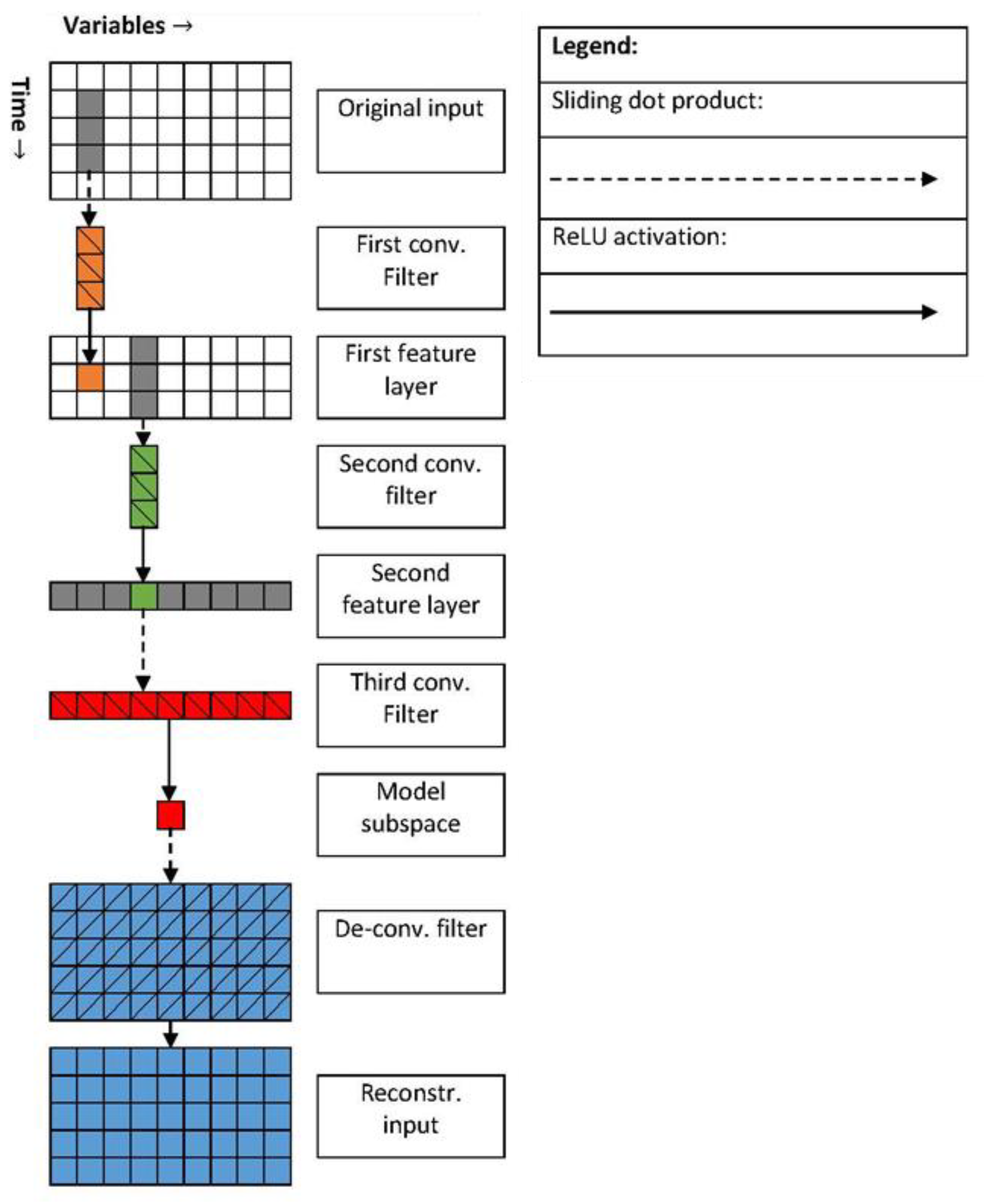
Convolutional neural networks (CNNs) were developed for and completely outclass traditional neural networks in image processing [
16]. CNNs extract simple, localized features from network inputs before moving on to more complicated features. This allows for more effective representations of network inputs across convolutional layers [
17]. Their adoption for monitoring industrial processes has been slow due to the intrinsic differences between images and multivariate time series, but the localized feature extraction of CNNs can lead to better representations of multivariate time series. Recently, convolutional auto-encoders (CAEs) have been developed for compressing univariate electrocardiogram signals [
18] and for fault detection using multivariate time series in the context of process monitoring [
19].
This study compares the performance of different reconstruction-based event prediction models using a simulated furnace as case study. The furnace model was developed to specifically account for the complex dynamic interactions in a submerged arc furnace while maintaining a lumped parameter approach to ensure feasible computational costs. Further details on the current study are provided in [
20].
3. Results and Discussions
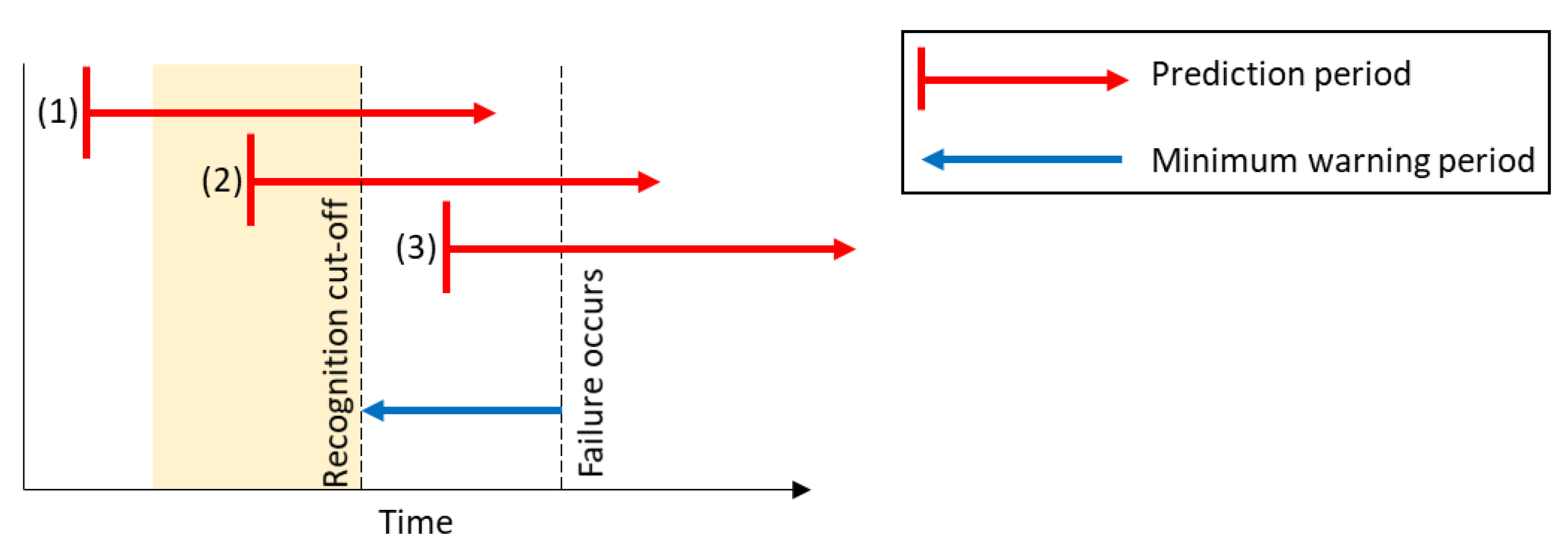
The performances of the evaluated reconstruction-based models are closely linked to the recognition thresholds at which they are evaluated. However, these thresholds can be selected arbitrarily. Therefore, each model will be evaluated at three different thresholds shown in
Table 8, as well as the motivation for using these thresholds for evaluation.
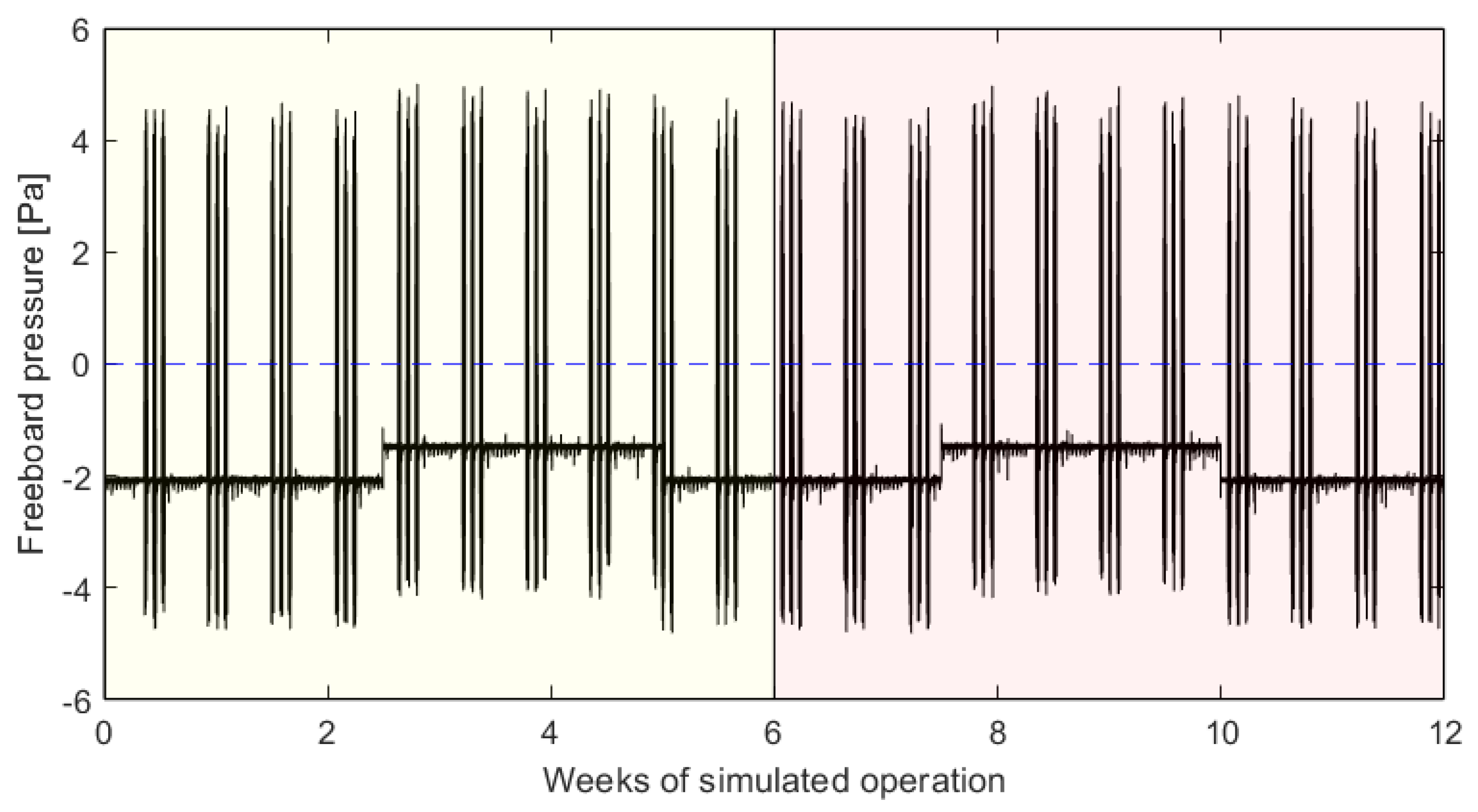
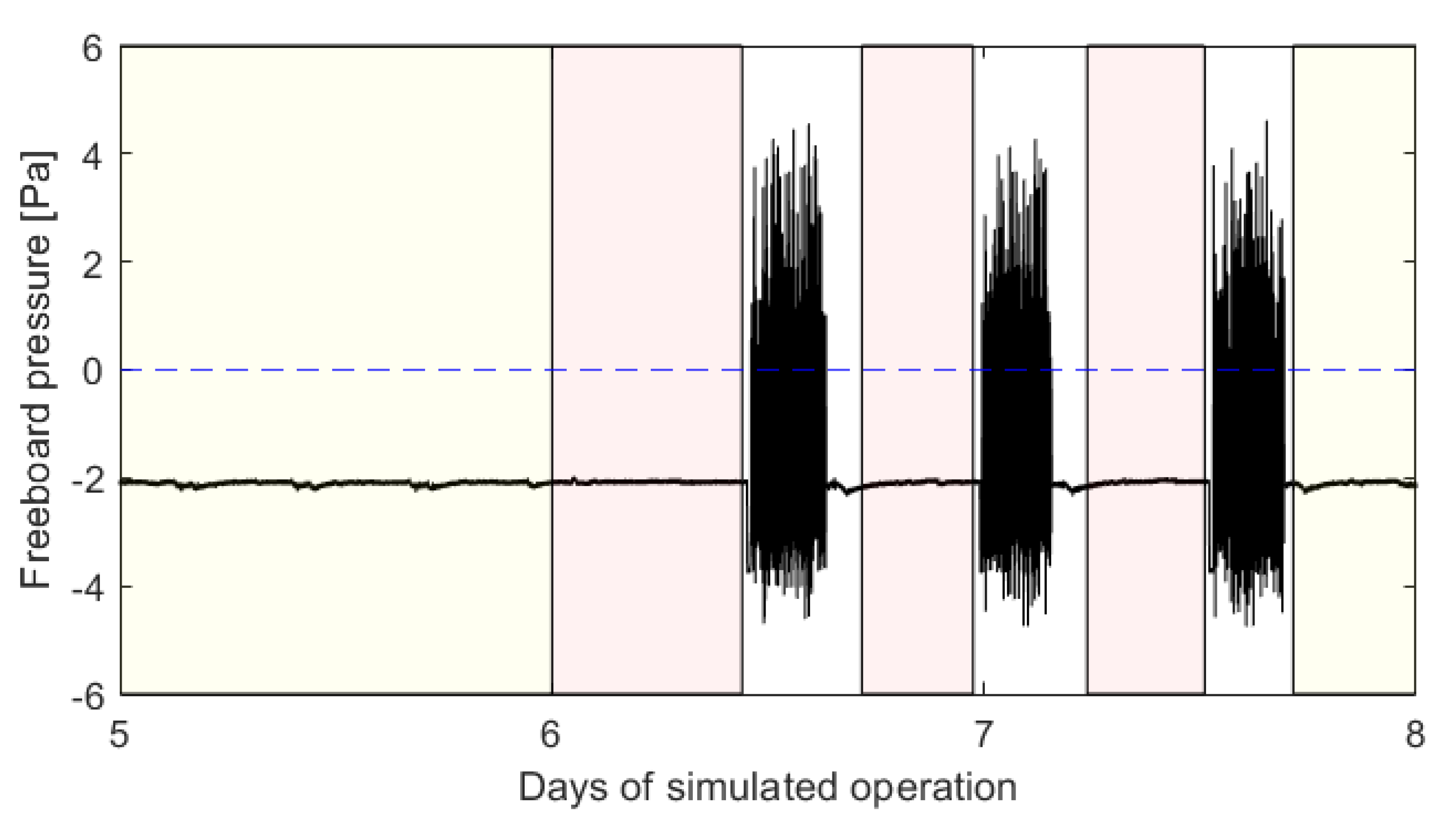
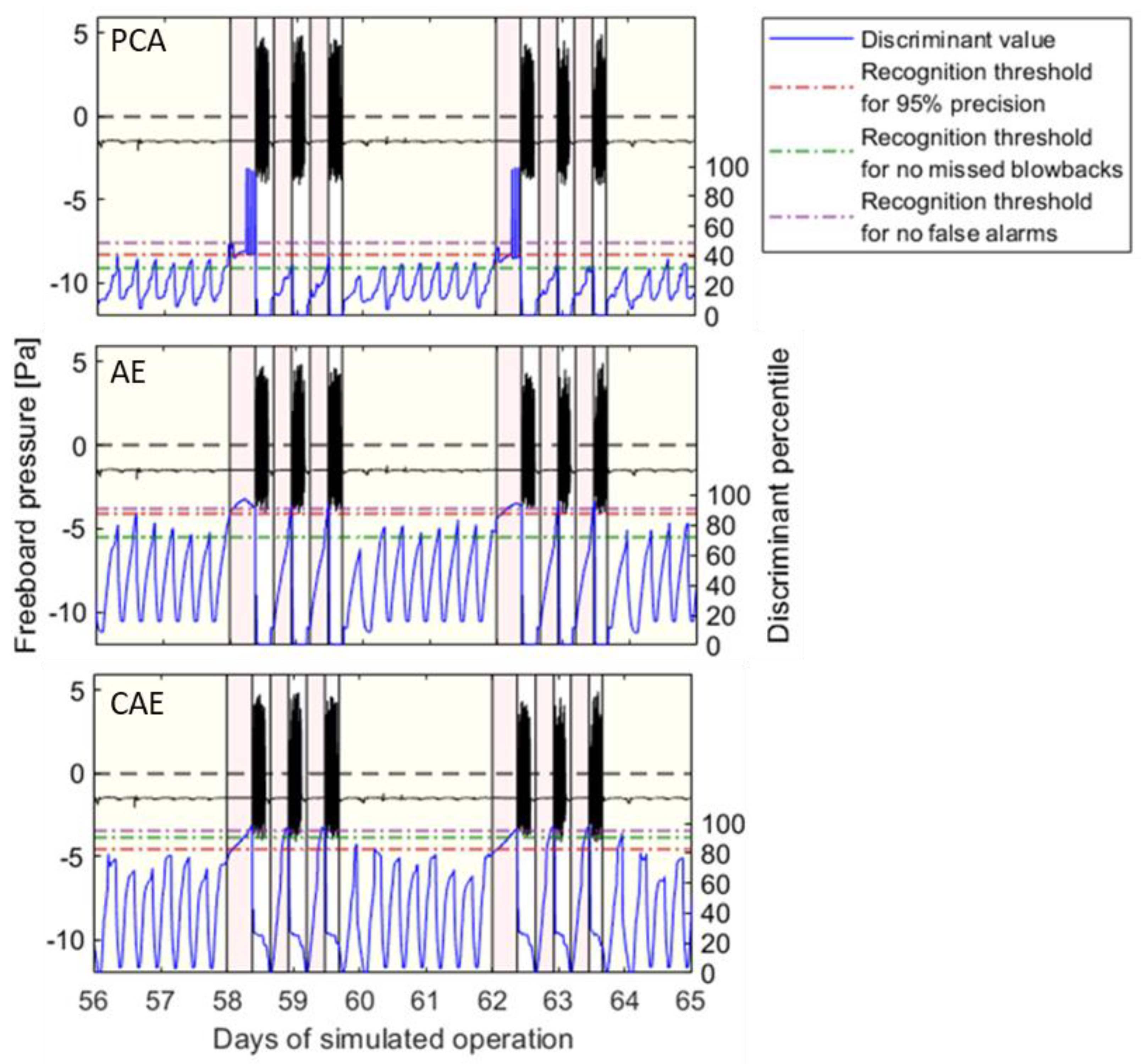
Figure 12 shows the discriminant values generated by each of the investigated models over 9 days of simulated operation. Note that this evaluation is performed over 42 days of simulated operation; these figures are only for illustrative purposes. These figures also show the recognition thresholds given in
Table 8.
Figure 12 shows that the dPCA, AE, and CAE models are all unable to achieve both zero missed predictions and perfect specificity: the recognition threshold for no false alarms is greater than that for no missed blowbacks for each model.
Table 9 shows the event prediction performance metrics at 95% precision, no missed alarms, and perfect specificity for each investigated model, respectively.
Note that sensitivity refers to the fraction of all observations that precede events that is recognized by the predictive models. The number of failed predictions is the number of the predictive models failed to recognize a single observation in the windows preceding the target events. Therefore, a model can have a sensitivity lower than 100% while still succeeding in predicting each event.
The results presented in
Table 9 suggests that the performance of the CAE model, relative to the AE- and dPCA models, is superior in the case study evaluated in this work.
Entry 1 in
Table 9 show that the CAE model correctly recognized event-preceding conditions more quickly than the dPCA and AE models when the recognition threshold is set so that the precision of each model in recognizing event-preceding conditions is 95%. Furthermore, entry 4 shows that the CAE model managed to predict each event, while the AE- and dPCA models failed to predict 20 and 40 blowbacks out of 63, respectively.
While inferior to the CAE model at the 95% precision threshold, the nonlinear AE model did manage to outperform the linear dPCA model. The dPCA model did show lower average detection delays than the AE model (as seen in entry 1 in
Table 9) but failed in predicting events twice as often. This suggests that predictions based solely on a process’ linear characteristics will struggle to compete with predictions that utilize nonlinear characteristics.
The CAE model’s superior performance was maintained when the recognition threshold was set so that no prediction fails. While the AE- and dPCA models did achieve significantly lower detection delays at this recognition threshold, they did so at far lower specificities (86.70% for the dPCA model and 90.14% for AE model). The CAE model successfully predicted all events at the highest specificity (99.86%) over all investigated recognition thresholds.
Finally, when the recognition threshold was set so that a perfect specificity was achieved, none of the evaluated models managed to predict each event. However, both the AE and CAE models failed to predict less than half of the events (24 and 16 out of 63, respectively). The dPCA model trailed significantly by failing to predict more than two thirds of the events (42 out of 63). This further suggests that modelling nonlinear characteristics is a crucial part of an event prediction model.
4. Conclusions
While the dPCA model showed inferior performance at each evaluated recognition threshold due to its limitations as a linear model, it should be noted that the computational requirements for developing and applying dPCA models are far lower than for AEs and CAEs. Kernel PCA is a non-linear alternative to PCA that performs eigenvalue decomposition of the outer product of modelled data, but this is computationally infeasible on the larger datasets typically recorded on industrial furnaces. The AE- and CAE models evaluated in this project were not limited by computing requirements but scaling them in complexity may not always be feasible. dPCA may be more suitable for applications where time-consuming optimization algorithms are undesired.
The superior performance observed for the CAE model compared to the AE model suggests that using one dimensional convolutional neural networks allows for more effective representations of the simulated furnace’s multivariate time series data. As a reconstruction-based classifier, CAEs extract features using fewer parameters than AEs, representing inputs in fewer, more informative features. This suggests that the superior performance of convolutional networks is not limited to image data.
Overall, the results obtained in this investigation suggest that one-dimensional CAEs are promising models for extracting features from multivariate time series data recorded from submerged arc furnaces, and that they can be applied as reconstruction-based event prediction models for online process monitoring to improve the safety and therefore viability of mineral processing applications. However, this investigation only provided a comparative evaluation of PCA models, auto-encoders, and convolutional auto-encoders on a single dataset obtained from a furnace model as a case study. Further evaluations of datasets obtained from industrial furnaces and other mineral processing applications will provide crucial insights that cannot be obtained from a modelled system such as the one used in this study on the performance of convolutional auto-encoders as event prediction models for promoting safe operation of various mineral processing applications.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}