
Color Image Recovery Using Generalized Matrix Completion over Higher-Order Finite Dimensional Algebra
 ,
,  , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Background and Related Works
1.2. Contributions and Organization of This Paper
- This research presents a t-matrix model that can extend traditional matrix methods to a higher order. The higher-order algorithm, termed “Higher-Order TNN”, is designed to exploit intricate structures in high-dimensional data and refines classical lower-order algorithms for missing entry recovery of RGB images. Compared to its predecessors, Higher-Order TNN offers significantly improved recovery performance.
- Using the t-matrix model over a finite-dimensional algebra, several image analysis algorithms are extended to a higher order using a novel pixel neighborhood strategy.
- Many constructions in matrix and vector analysis are extended to the t-matrix model. Examples include rank, norm, and inner product. In addition, t-matrix versions of Lagrange multipliers are defined.
2. T-Matrices
2.1. T-Scalars
2.2. T-Scalars as Finite-Dimensional Linear Operators
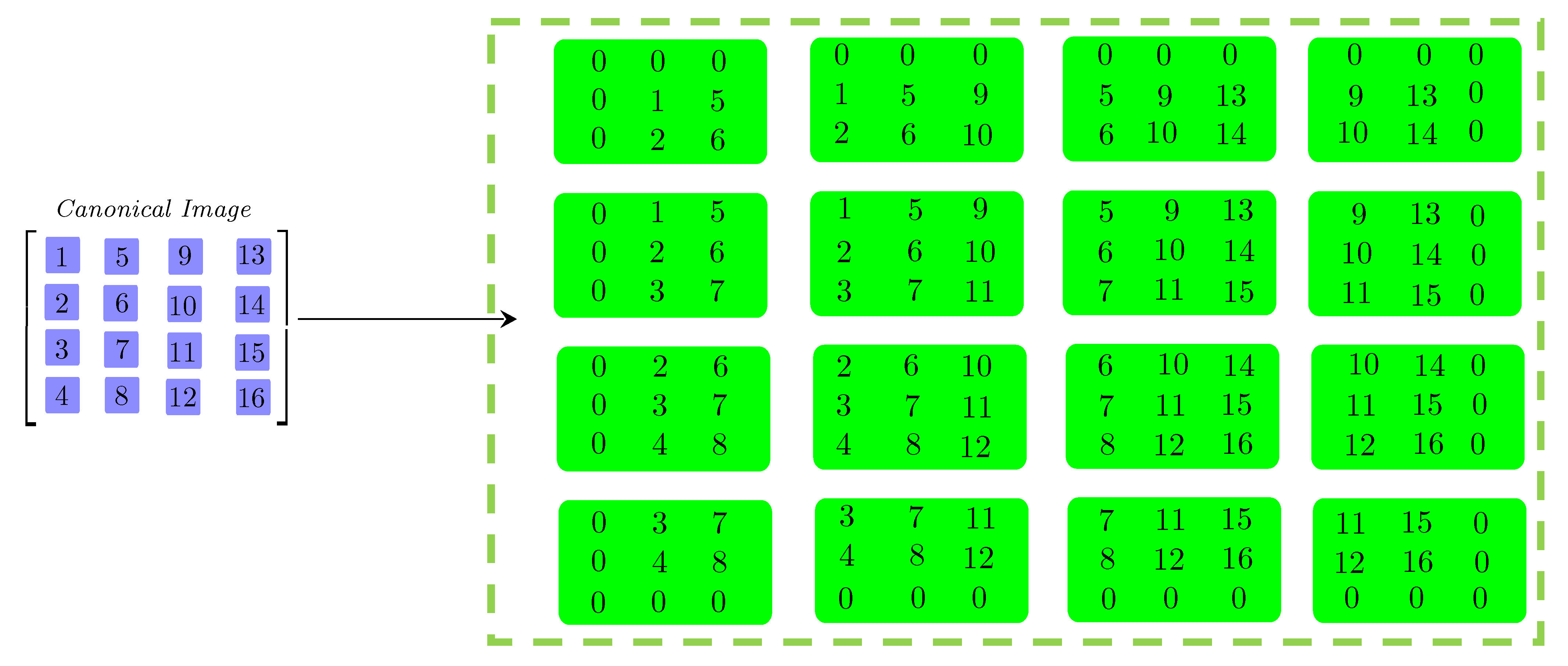
2.3. T-Matrices
2.4. Singular Value Decomposition of a T-Matrix
| Algorithm 1 Tensorial Singular Value Decomposition via Spectral Slices |
|
| Algorithm 2 Tensorial Singular Value Thresholding via Spectral Slices |
|
3. Low-Rank Matrix Completion and Its Generalizations
3.1. Low-Rank Matrix Completion
3.2. Generalization of Matrix Completion over Higher-Order T-Scalars
| Algorithm 3 ADMM for solving Equation (7) |
|
| Algorithm 4 Higher-Order TNN: ADMM for recovering an image with missing values |
|
3.3. Computational Complexity
4. Rank Considerations
4.1. Tubal Rank and Average Rank
4.2. Higher-Order Rank and Its Trace Variant
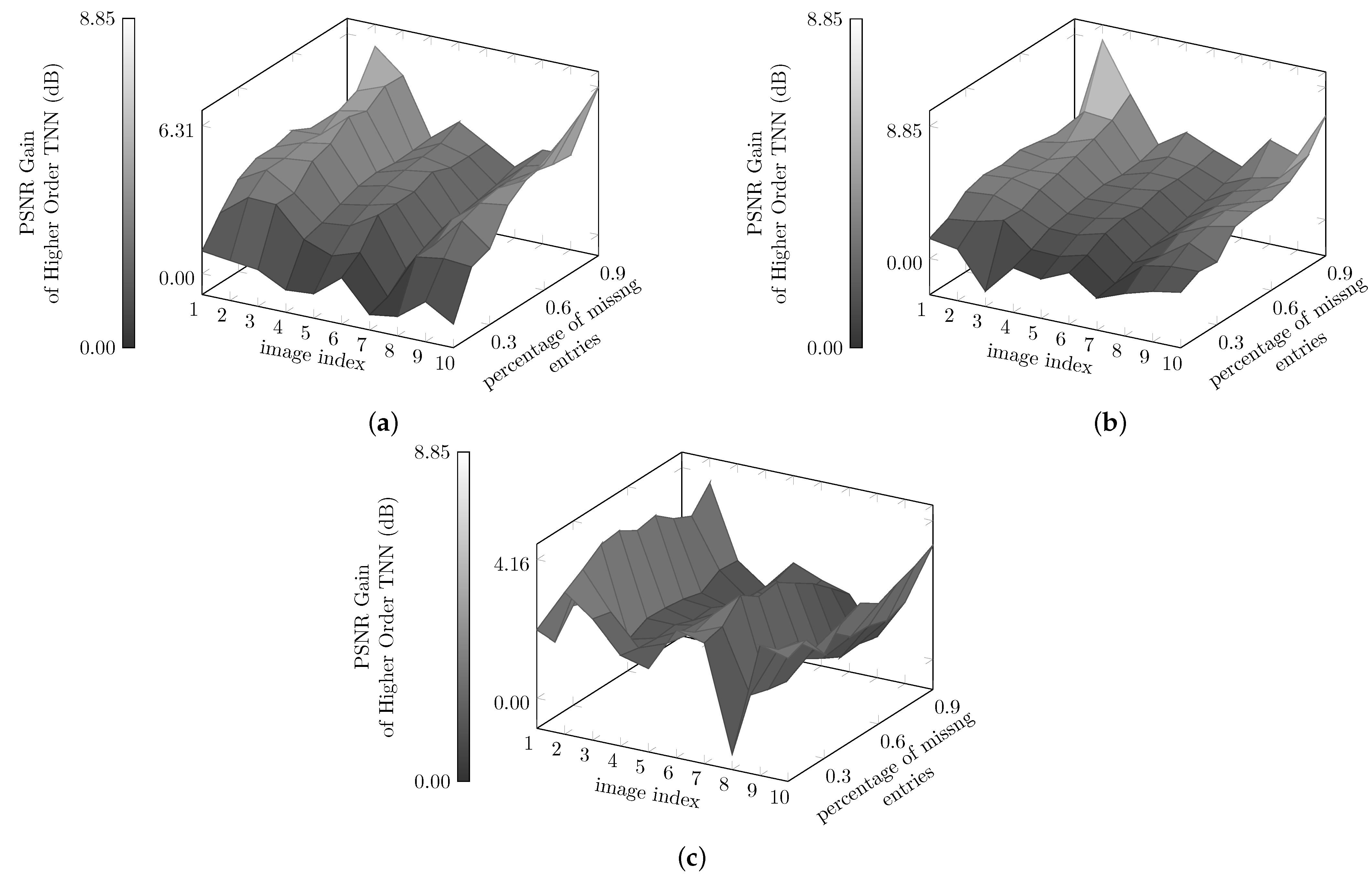
5. Experiments
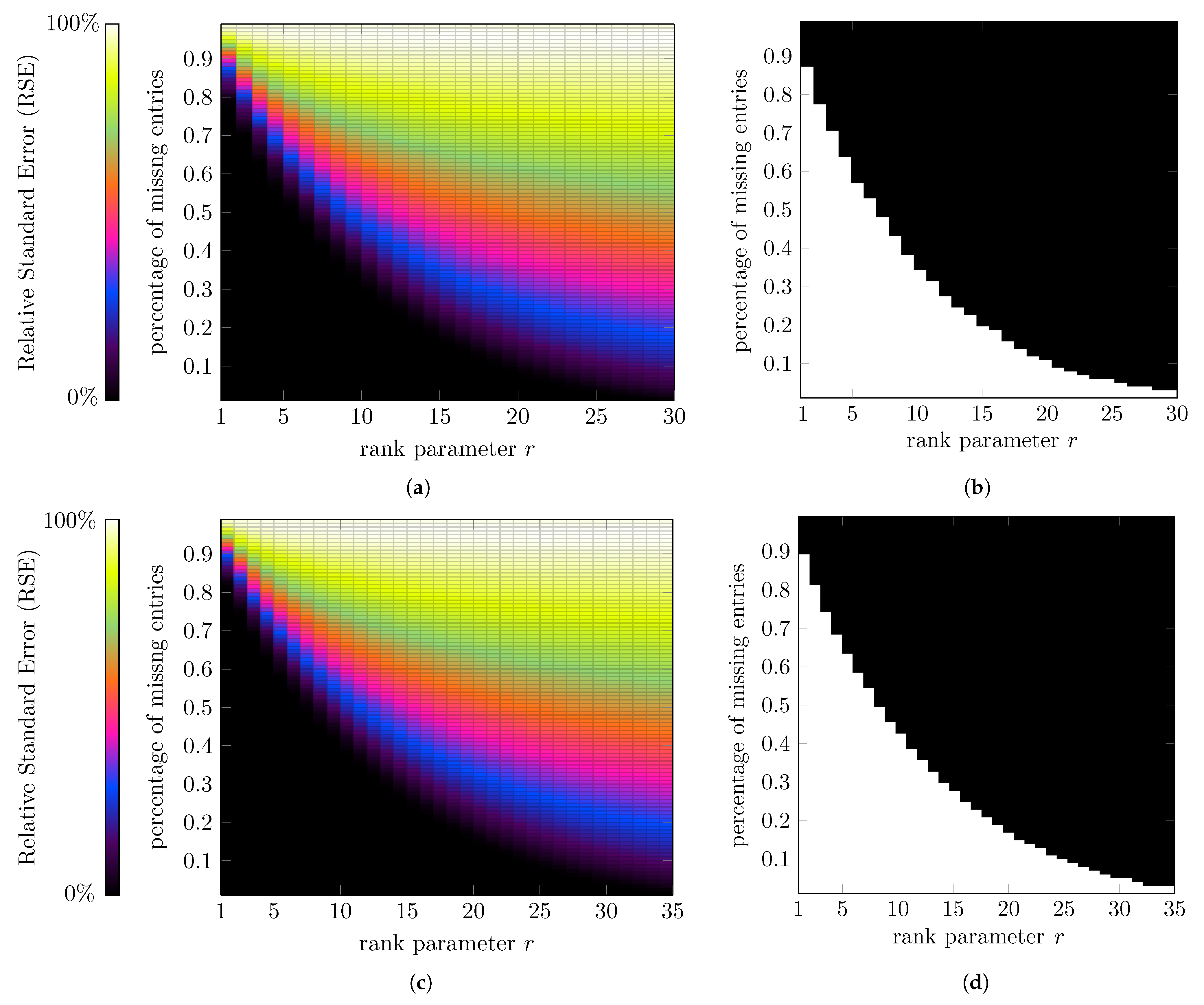
5.1. Experiments on Simulated Random Data
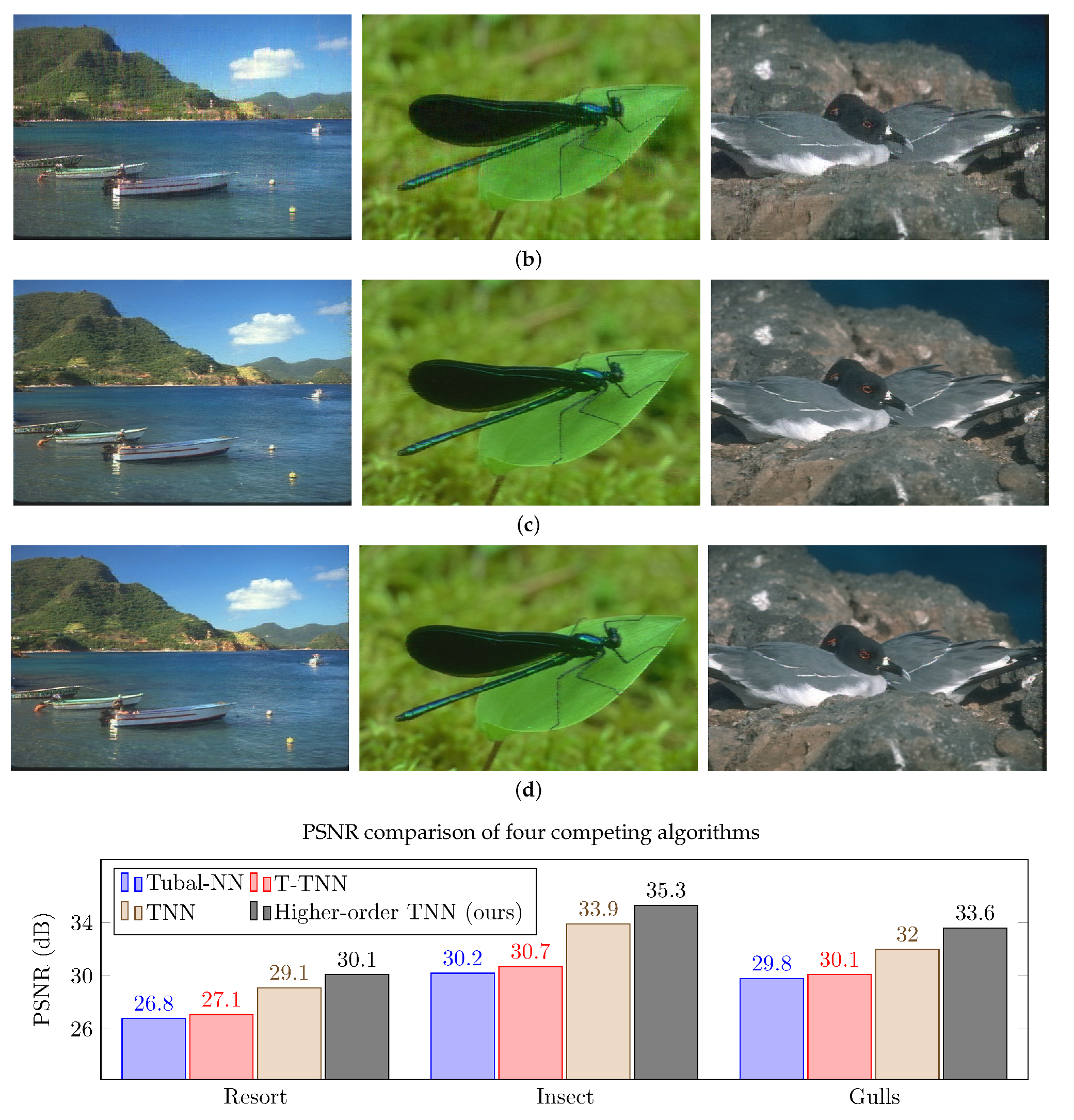
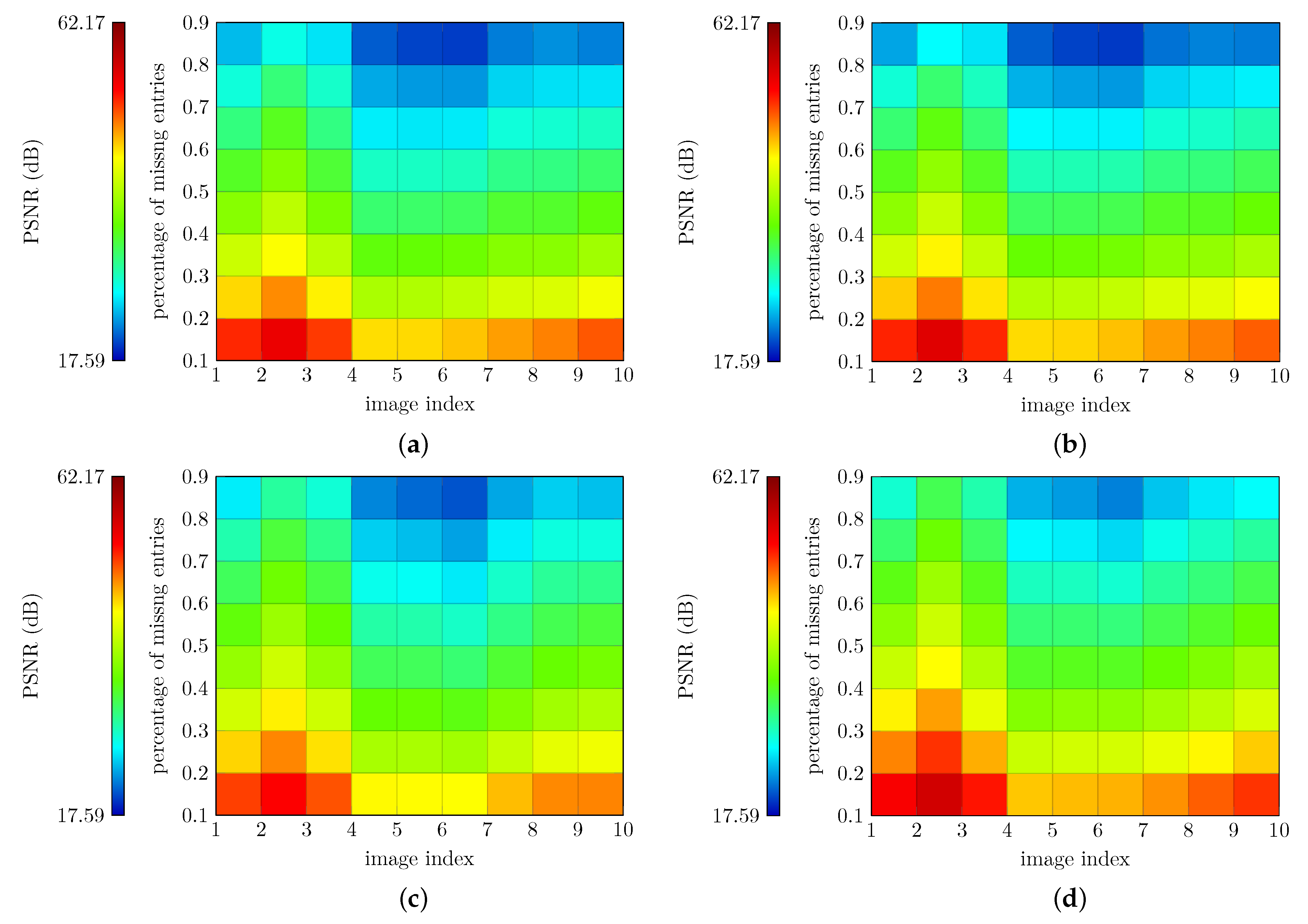
5.2. Experiments on BSD Color Images
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. A Mathematical Justification
Appendix A.1. Matrix Representation for T-Scalars and Higher-Order Measures
Appendix A.2. A Representation Model for T-Matrices and Higher-Order Measures
Appendix A.3. Lagrange Multiplier with T-Matrix Variables
References
- Floryan, D.; Graham, M.D. Data-driven discovery of intrinsic dynamics. Nat. Mach. Intell. 2022, 4, 1113–1120. [Google Scholar] [CrossRef]
- Li, T.; Tan, L.; Huang, Z.; Tao, Q.; Liu, Y.; Huang, X. Low dimensional trajectory hypothesis is true: DNNs can be trained in tiny subspaces. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3411–3420. [Google Scholar] [CrossRef]
- Chen, M.; Jiang, H.; Liao, W.; Zhao, T. Nonparametric regression on low-dimensional manifolds using deep ReLU networks: Function approximation and statistical recovery. Inf. Inference J. IMA 2022, 11, 1203–1253. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, Z.; Cao, W.; Chen, C.L.P. A novel classifier ensemble method based on subspace enhancement for high-dimensional data classification. IEEE Trans. Knowl. Data Eng. 2021, 35, 16–30. [Google Scholar] [CrossRef]
- Fu, L.; Yang, J.; Chen, C.; Zhang, C. Low-rank tensor approximation with local structure for multi-view intrinsic subspace clustering. Inf. Sci. 2022, 606, 877–891. [Google Scholar] [CrossRef]
- Wang, M.; Wang, Q.; Hong, D.; Roy, S.K.; Chanussot, J. Learning tensor low-rank representation for hyperspectral anomaly detection. IEEE Trans. Cybern. 2022, 53, 679–691. [Google Scholar] [CrossRef]
- Liu, N.; Li, W.; Wang, Y.; Tao, R.; Du, Q.; Chanussot, J. A survey on hyperspectral image restoration: From the view of low-rank tensor approximation. Sci. China Inf. Sci. 2023, 66, 140302. [Google Scholar] [CrossRef]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor Completion for Estimating Missing Values in Visual Data. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 208–220. [Google Scholar] [CrossRef]
- Zhang, Z.; Ely, G.; Aeron, S.; Hao, N.; Kilmer, M. Novel methods for multilinear data completion and de-noising based on tensor-SVD. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3842–3849. [Google Scholar]
- Kilmer, M.E.; Martin, C.D. Factorization strategies for third-order tensors. Linear Algebra Its Appl. 2011, 435, 641–658. [Google Scholar] [CrossRef]
- Lu, C.; Feng, J.; Lin, Z.; Yan, S. Exact low tubal rank tensor recovery from Gaussian measurements. arXiv 2018, arXiv:1806.02511. [Google Scholar]
- Xue, S.; Qiu, W.; Liu, F.; Jin, X. Low-rank tensor completion by truncated nuclear norm regularization. In Proceedings of the 2018 24th IEEE International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2600–2605. [Google Scholar]
- Zeng, H.; Xue, J.; Luong, H.Q.; Philips, W. Multimodal core tensor factorization and its applications to low-rank tensor completion. IEEE Trans. Multimed. 2022; early access. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, T.; Deng, L.; Dou, H.; Meng, D. Tensor wheel decomposition and its tensor completion application. Adv. Neural Inf. Process. Syst. 2022, 35, 27008–27020. [Google Scholar]
- Zhao, X.; Bai, M.; Sun, D.; Zheng, L. Robust tensor completion: Equivalent surrogates, error bounds, and algorithms. SIAM J. Imaging Sci. 2022, 15, 625–669. [Google Scholar] [CrossRef]
- Deng, L.; Xiao, M. A New Automatic Hyperparameter Recommendation Approach Under Low-Rank Tensor Completion e Framework. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4038–4050. [Google Scholar] [CrossRef]
- Nguyen, T.; Uhlmann, J. Tensor completion with provable consistency and fairness guarantees for recommender systems. ACM Trans. Recomm. Syst. 2023, 1, 1–26. [Google Scholar] [CrossRef]
- Hui, B.; Yan, D.; Chen, H.; Ku, W.-S. Time-sensitive POI Recommendation by Tensor Completion with Side Information. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 205–217. [Google Scholar]
- Song, Q.; Ge, H.; Caverlee, J.; Hu, X. Tensor completion algorithms in big data analytics. ACM Trans. Knowl. Discov. Data 2019, 13, 1–48. [Google Scholar] [CrossRef]
- Wu, X.; Xu, M.; Fang, J.; Wu, X. A multi-attention tensor completion network for spatiotemporal traffic data imputation. IEEE Internet Things J. 2022, 9, 20203–20213. [Google Scholar] [CrossRef]
- Lee, C.; Wang, M. Beyond the signs: Nonparametric tensor completion via sign series. Adv. Neural Inf. Process. Syst. 2021, 34, 21782–21794. [Google Scholar]
- Liao, L.; Maybank, S.J. Generalized visual information analysis via tensorial algebra. J. Math. Imaging Vis. 2020, 62, 560–584. [Google Scholar] [CrossRef]
- Chang, S.Y.; Wei, Y. T-product tensors—Part II: Tail bounds for sums of random T-product tensors. Comput. Appl. Math. 2022, 41, 99. [Google Scholar] [CrossRef]
- Yu, Q.; Zhang, X. T-product factorization based method for matrix and tensor completion problems. Comput. Optim. Appl. 2022, 84, 761–788. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Braman, K.; Hao, N.; Hoover, R.C. Third-order tensors as operators on matrices: A theoretical and computational framework with applications in imaging. SIAM J. Matrix Anal. Appl. 2021, 34, 148–172. [Google Scholar] [CrossRef]
- Lim, L.-H. Tensors and Hypermatrices, Handbook of Linear Algebra (Leslie Hogben, Ed.); CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM (JACM) 2021, 58, 1–37. [Google Scholar] [CrossRef]
- Candès, E.; Recht, B. Exact matrix completion via convex optimization. Commun. ACM 2012, 55, 111–119. [Google Scholar] [CrossRef]
- Lin, Z.; Li, H.; Fang, C. Alternating Direction Method of Multipliers for Machine Learning; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Han, D.-R. A survey on some recent developments of alternating direction method of multipliers. J. Oper. Res. Soc. China 2022, 10, 1–52. [Google Scholar] [CrossRef]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor robust principal component analysis with a new tensor nuclear norm. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 925–938. [Google Scholar] [CrossRef]
- Liao, L.; Maybank, S.J. General data analytics with applications to visual information analysis: A provable backward-compatible semisimple paradigm over t-algebra. arXiv 2020, arXiv:2011.00307. [Google Scholar]
- Liao, L.; Lin, S.; Li, L.; Zhang, X.; Zhao, S.; Wang, Y.; Wang, X.; Gao, Q.; Wang, J. Approximation of Images via Generalized Higher Order Singular Value Decomposition over Finite-Dimensional Commutative Semisimple Algebra. arXiv 2022, arXiv:2202.00450. [Google Scholar]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, L.; Guo, Z.; Gao, Q.; Wang, Y.; Yu, F.; Zhao, Q.; Maybank, S.J.; Liu, Z.; Li, C.; Li, L. Color Image Recovery Using Generalized Matrix Completion over Higher-Order Finite Dimensional Algebra. Axioms 2023, 12, 954. https://0-doi-org.brum.beds.ac.uk/10.3390/axioms12100954
Liao L, Guo Z, Gao Q, Wang Y, Yu F, Zhao Q, Maybank SJ, Liu Z, Li C, Li L. Color Image Recovery Using Generalized Matrix Completion over Higher-Order Finite Dimensional Algebra. Axioms. 2023; 12(10):954. https://0-doi-org.brum.beds.ac.uk/10.3390/axioms12100954
Chicago/Turabian StyleLiao, Liang, Zhuang Guo, Qi Gao, Yan Wang, Fajun Yu, Qifeng Zhao, Stephen John Maybank, Zhoufeng Liu, Chunlei Li, and Lun Li. 2023. "Color Image Recovery Using Generalized Matrix Completion over Higher-Order Finite Dimensional Algebra" Axioms 12, no. 10: 954. https://0-doi-org.brum.beds.ac.uk/10.3390/axioms12100954