
A Statistical Model for Count Data Analysis and Population Size Estimation: Introducing a Mixed Poisson–Lindley Distribution and Its Zero Truncation

Abstract
:1. Introduction
2. Poisson-Improved Second-Degree Lindley Distribution
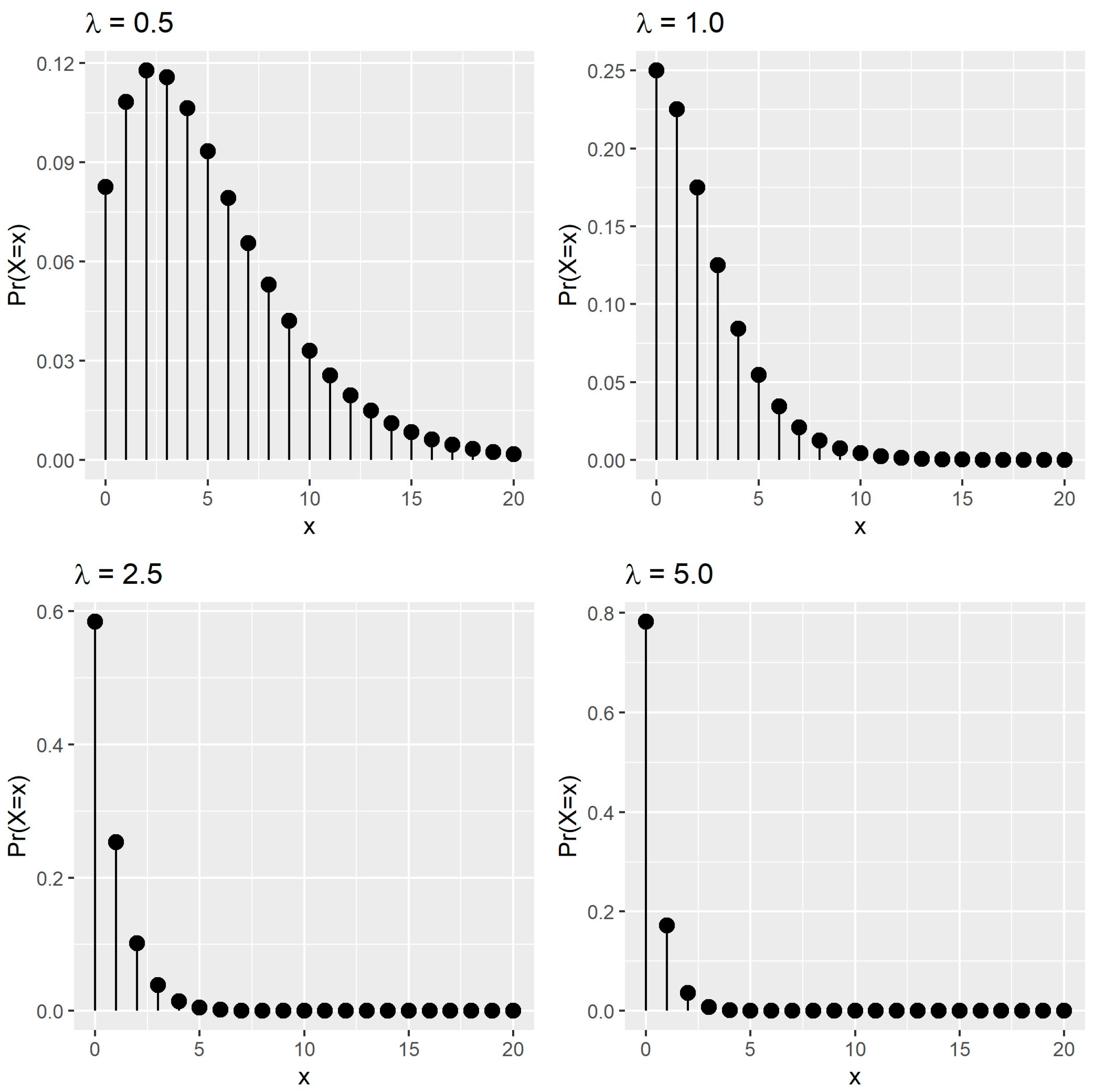
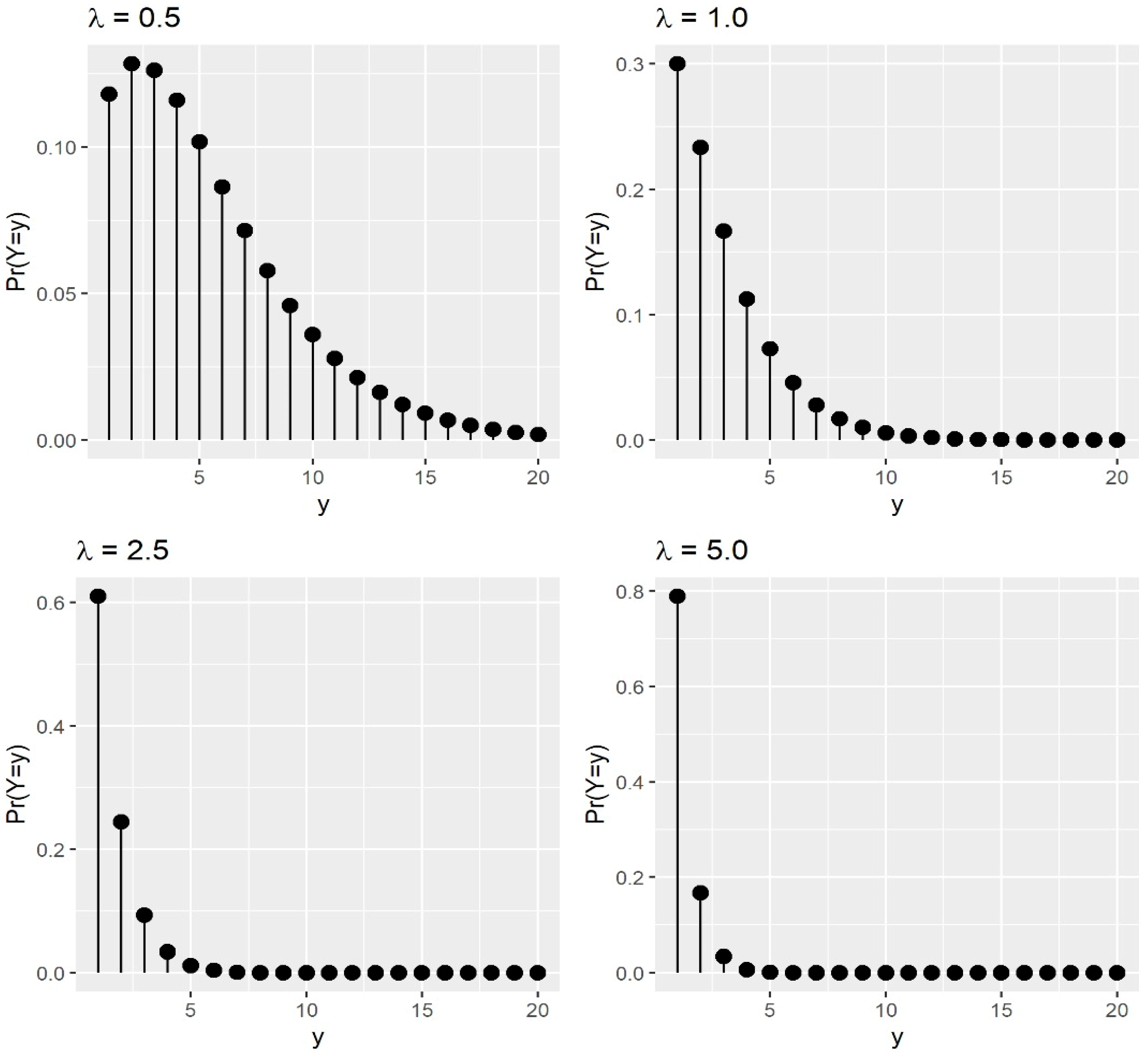
2.1. Probability Mass Function of the PISDL Distribution
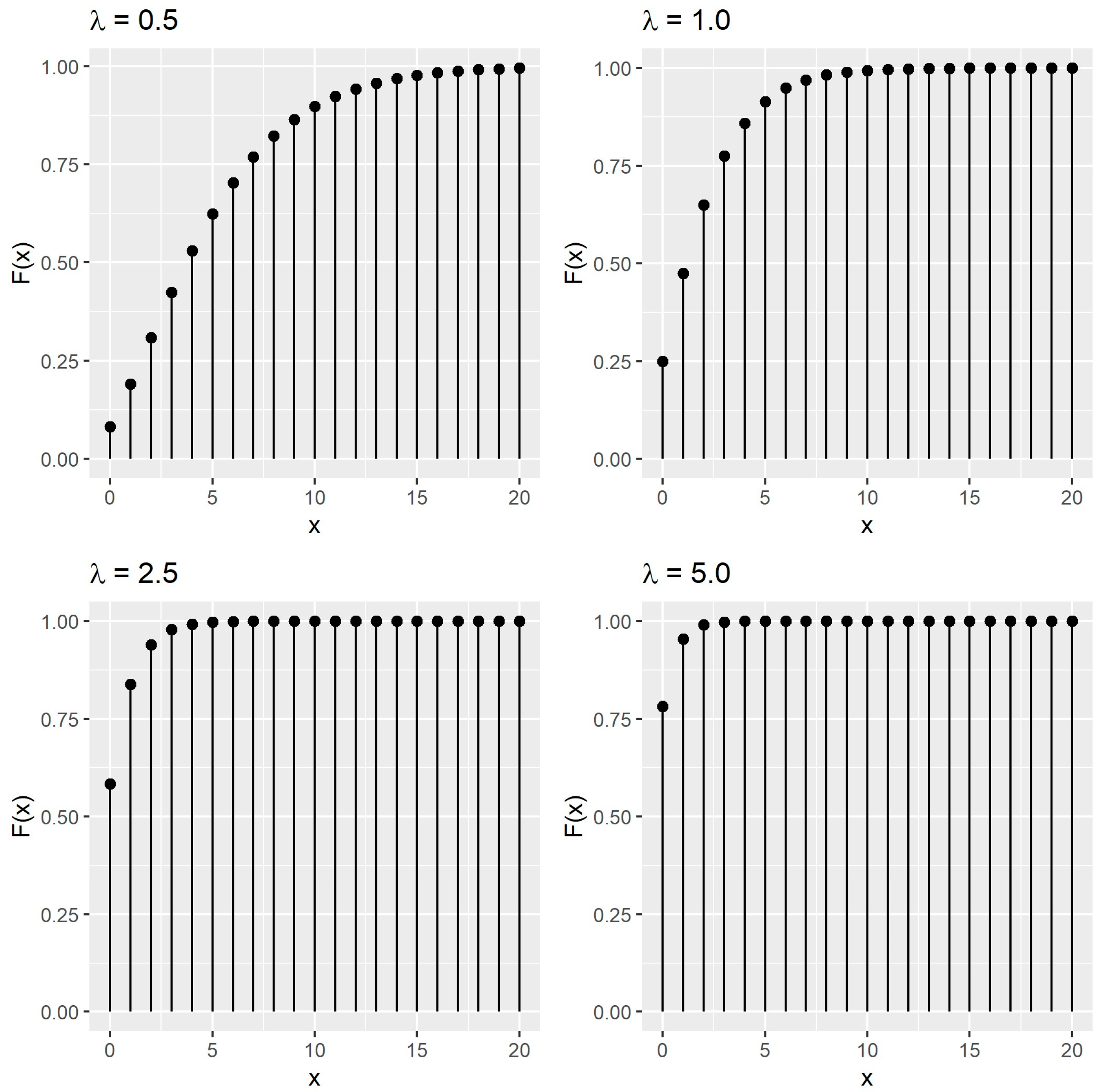
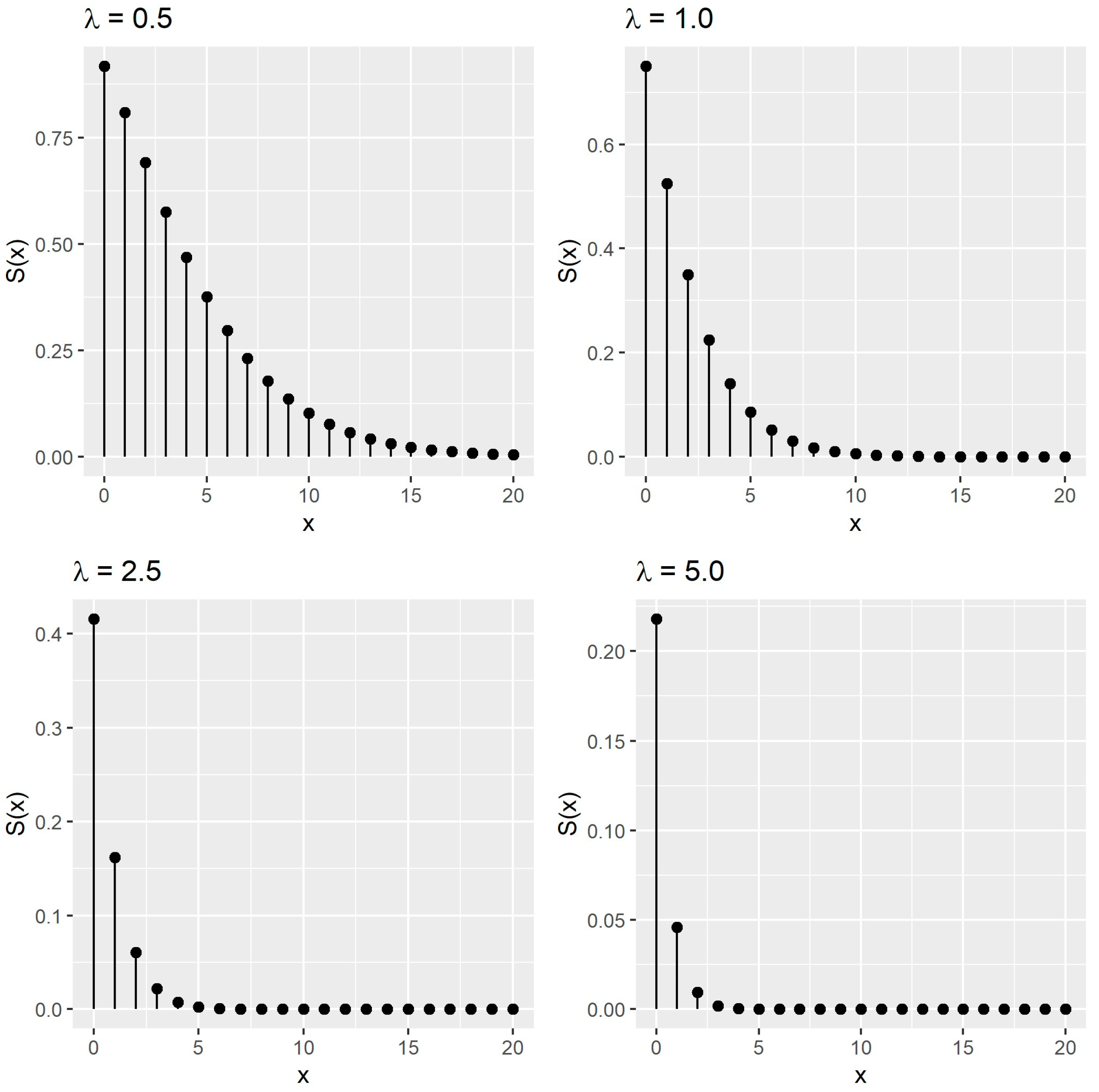
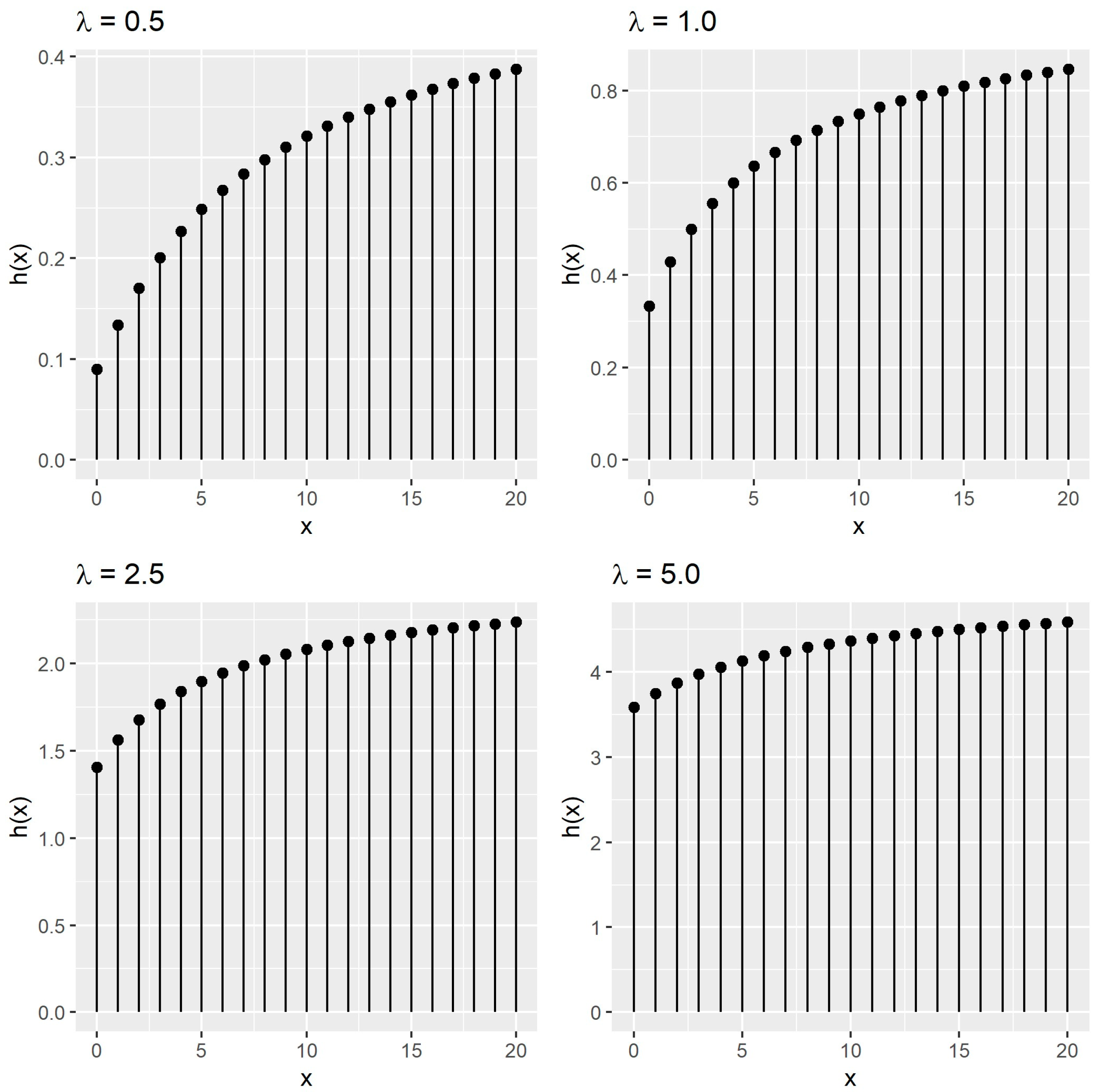
2.2. Some Statistical Properties of the PISDL Distribution
2.3. Parameter Estimation of the PISDL Distribution
2.3.1. Method of Moments Estimator
2.3.2. Maximum Likelihood Estimator
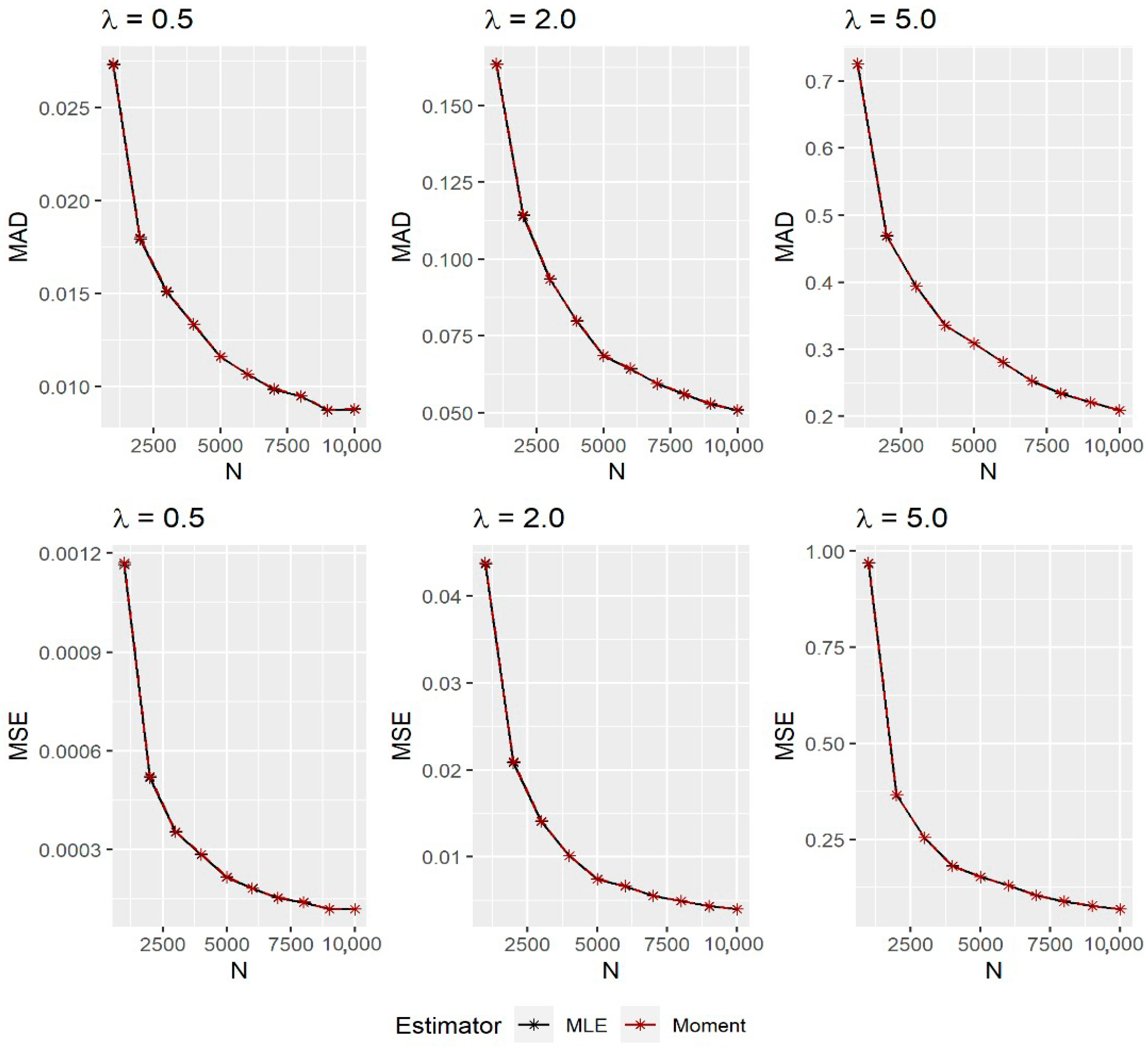
2.4. Simulation Study
- Step 1:
- Generate random data that follows the PISDL distribution with .
- Step 2:
- Obtain the estimated using MLE and moment estimator.
- Step 3:
- Repeat Steps 1–2 for a total of 2000 iterations and obtain the estimates.
- Step 4:
- Calculate the mean absolute deviation, MAD, and the mean squared error values, MSEs, given, respectively, as and , where can be the MLE or moment estimator for .
- Step 5:
- Repeat Steps 3–4 for .
3. Zero-Truncated Poisson-Improved Second-Degree Lindley Distribution
3.1. Probability Mass Function of the ZTPISDL Distribution
3.2. Some Statistical Properties of the ZTPISDL Distribution
3.3. Parameter Estimation of the ZTPISDL Distribution
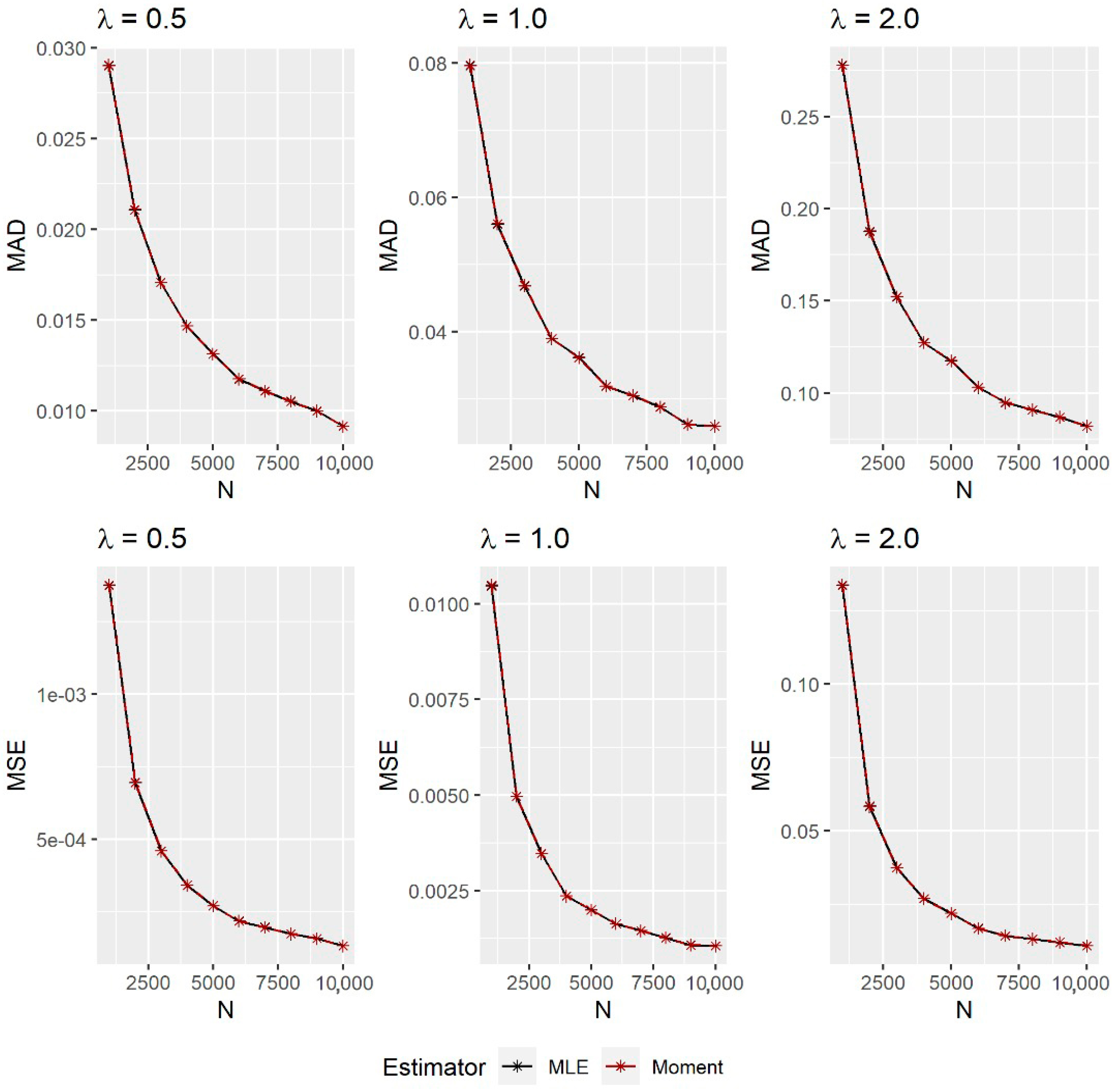
3.4. Simulation Study
4. Population Size Estimation
4.1. Horvitz–Thompson Estimator under ZTPISDL Distribution (HT-ZTPISDL)
4.2. Variance and Confidence Interval for HT-ZTPISDL
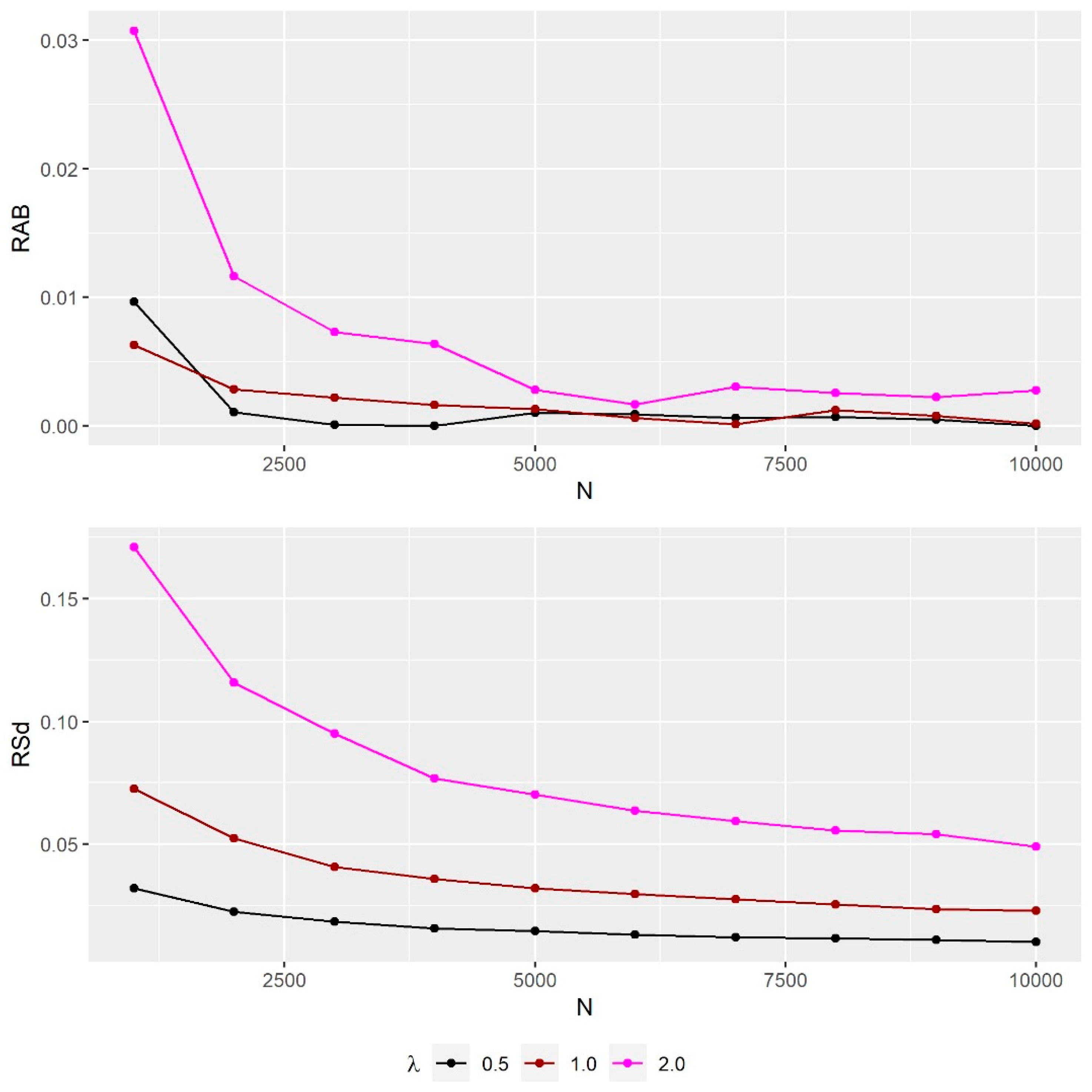
4.3. Simulation Study
- Step 1:
- Generate random data, which follow the ZTPISDL distribution with .
- Step 2:
- Obtain using the MLE and use to obtain .
- Step 3:
- Repeat Steps 1–2 for a total of 2000 iterations and obtain the estimates.
- Step 4:
- Calculate the relative absolute error, RAB values, and the relative standard deviation, RSd values, given, respectively, as and , where .
- Step 5:
- Repeat Steps 3–4 for .
5. Medical Data Applications
5.1. Model Fittings Using the PISDL Distribution
5.2. Model Fittings Using ZTPISDL Distribution
5.3. Estimating Population Size
6. Conclusions, Limitations, and Future Research
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lindley, D.V. Fiducial distributions and Bayes’ theorem. J. R. Stat. Soc. Ser. B Methodol. 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Atieh, B.; Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Altun, E.; Cordeiro, G.M. The unit-improved second-degree Lindley distribution: Inference and regression modeling. Comput. Stat. 2020, 35, 259–279. [Google Scholar] [CrossRef]
- Asgharzadeh, A.; Bakouch, H.S.; Nadarajah, S.; Sharafi, F. A new weighted Lindley distribution with application. Braz. J. Probab. Stat. 2016, 30, 1–27. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Alqallaf, F.; Al-Mutairi, D.K.; Husain, H.A. A two-parameter weighted Lindley distribution and its applications to survival data. Math. Comput. Simul. 2011, 81, 1190–1201. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Mutairi, D.K.; Balakrishnan, N.; Al-Enezi, L.J. Power Lindley distribution and associated inference. Comput. Stat. Data Anal. 2013, 64, 20–33. [Google Scholar] [CrossRef]
- Karuppusamy, S.; Balakrishnan, V.; Sadasivan, K. Improved second-degree Lindley distribution and its applications. IOSR J. Math. 2018, 13, 50–56. [Google Scholar]
- Nadarajah, S.; Bakouch, H.S.; Tahmasbi, R. A generalized Lindley distribution. Sankhya B 2011, 73, 331–359. [Google Scholar] [CrossRef]
- Shanker, R.; Mishra, A. A quasi Lindley distribution. Afr. J. Math. Comput. Sci. Res. 2013, 6, 64–71. [Google Scholar]
- Shanker, R.; Mishra, A. A two-parameter Lindley distribution. Stat. Transit. New Ser. 2013, 14, 45–56. [Google Scholar] [CrossRef]
- Zakerzadeh, H.; Dolati, A. Generalized Lindley distribution. J. Math. Ext. 2009, 3, 1–7. [Google Scholar]
- Bakouch, H.S.; Al-Zahrani, B.M.; Al-Shomrani, A.A.; Marchi, V.A.; Louzada, F. An extended Lindley distribution. J. Korean Stat. Soc. 2012, 41, 75–85. [Google Scholar] [CrossRef]
- Shanker, R.; Shukla, K.K.; Shanker, R.; Tekie, A.L. A three-parameter Lindley distribution. Am. J. Math. Stat. 2017, 7, 15–26. [Google Scholar]
- Coşkun, K.U.Ş.; Korkmaz, M.Ç.; Kinaci, İ.; Karakaya, K.; Akdoğan, Y. Modified-Lindley distribution and its applications to the real data. Commun. Fac. Sci. Univ. Ank. Ser. A1 Math. Stat. 2022, 71, 252–272. [Google Scholar]
- Sankaran, M. Note: The discrete Poisson-Lindley distribution. Biometrics 1970, 145–149. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Mutairi, D.K. Estimation methods for the discrete Poisson–Lindley distribution. J. Stat. Comput. Simul. 2009, 79, 1–9. [Google Scholar] [CrossRef]
- Bhati, D.; Sastry, D.V.S.; Qadri, P.M. A new generalized Poisson-Lindley distribution: Applications and properties. Austrian J. Stat. 2015, 44, 35–51. [Google Scholar] [CrossRef]
- Das, K.K.; Ahmed, I.; Bhattacharjee, S. A new three-parameter Poisson-Lindley distribution for modeling over dispersed count data. Int. J. Appl. Eng. Res. 2018, 13, 16468–16477. [Google Scholar]
- Shanker, R.; Mishra, A. A two-parameter Poisson-Lindley distribution. Int. J. Stat. Syst. 2014, 9, 79–85. [Google Scholar]
- Karlis, D.; Xekalaki, E. Mixed Poisson distributions. Int. Stat. Rev. 2005, 35–58. [Google Scholar] [CrossRef]
- Wasinrat, S.; Choopradit, B. The Poisson inverse Pareto distribution and its applications. Thail. Stat. 2023, 21, 110–124. [Google Scholar]
- Erbayram, T.; Akdoğan, A. A new discrete model generated from mixed Poisson transmuted record type exponential distribution. Ric. Math. 2023, 1–23. [Google Scholar] [CrossRef]
- David, F.N.; Johnson, N.L. The truncated Poisson. Biometrics 1952, 8, 275–285. [Google Scholar] [CrossRef]
- Sampford, M.R. The truncated negative binomial distribution. Biometrika 1955, 42, 58–69. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Mutairi, D.K.; Nadarajah, S. Zero-truncated Poisson–Lindley distribution and its application. Math. Comput. Simul. 2008, 79, 279–287. [Google Scholar] [CrossRef]
- Böhning, D.; Suppawattanabodee, B.; Kusolvisitkul, W.; Viwatwongkasem, C. Estimating the number of drug users in Bangkok 2001: A capture–recapture approach using repeated entries in one list. Eur. J. Epidemiol. 2004, 19, 1075–1083. [Google Scholar] [CrossRef] [PubMed]
- Bouchard, M. A capture–recapture model to estimate the size of criminal populations and the risks of detection in a marijuana cultivation industry. J. Quant. Criminol. 2007, 23, 221–241. [Google Scholar] [CrossRef]
- Bouchard, M.; Morselli, C.; Macdonald, M.; Gallupe, O.; Zhang, S.; Farabee, D. Estimating risks of arrest and criminal populations: Regression adjustments to capture–recapture models. Crime Delinq. 2019, 65, 1767–1797. [Google Scholar] [CrossRef]
- Cai, T.; Xia, Y. Estimating size of drug users in Macau: An open population capture-recapture model with data augmentation using public registration data. Asian J. Criminol. 2018, 13, 193–206. [Google Scholar] [CrossRef]
- Rossmo, D.K.; Routledge, R. Estimating the size of criminal populations. J. Quant. Criminol. 1990, 6, 293–314. [Google Scholar] [CrossRef]
- Tajuddin, R.R.M.; Ismail, N.; Ibrahim, K. Estimating population size of criminals: A new Horvitz–Thompson estimator under one-inflated positive Poisson–Lindley model. Crime Delinq. 2021, 68, 1004–1034. [Google Scholar] [CrossRef]
- Van Der Heijden, P.G.; Cruyff, M.; Van Houwelingen, H.C. Estimating the size of a criminal population from police records using the truncated Poisson regression model. Stat. Neerl. 2003, 57, 289–304. [Google Scholar] [CrossRef]
- Van der Heijden, P.G.; Cruyff, M.; Böhning, D. Capture recapture to estimate criminal populations. In Encyclopedia of Criminology and Criminal Justice; Springer: Berlin/Heidelberg, Germany, 2014; pp. 267–276. [Google Scholar]
- Tajuddin, R.R.M.; Ismail, N.; Ibrahim, K. Several two-component mixture distributions for count data. Commun. Stat. Simul. Comput. 2022, 51, 3760–3771. [Google Scholar] [CrossRef]
- Lerch, M. Note sur la function. Acta Math. 1887, 11, 19–24. [Google Scholar] [CrossRef]
- Horvitz, D.G.; Thompson, D.J. A generalization of sampling without replacement from a finite universe. J. Am. Stat. Assoc. 1952, 47, 663–685. [Google Scholar] [CrossRef]
- Böhning, D. A simple variance formula for population size estimators by conditioning. Stat. Methodol. 2008, 5, 410–423. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Puig, P.; Barquinero, J.F. An application of compound Poisson modelling to biological dosimetry, Proceedings of the Royal Society A: Mathematical. Phys. Eng. Sci. 2011, 467, 897–910. [Google Scholar]
- Snow, L.C.; Davies, R.H.; Christiansen, K.H.; Carrique-Mas, J.J.; Wales, A.D.; O’Connor, J.L.; Cook, A.J.; Evans, S.J. Survey of the prevalence of Salmonella species on commercial laying farms in the United Kingdom. Vet. Rec. 2007, 161, 471–476. [Google Scholar] [CrossRef]
- Arnold, M.E.; Papadopoulou, C.; Davies, R.H.; Carrique-Mas, J.J.; Evans, S.J.; Hoinville, L.J. Estimation of Salmonella prevalence in UK egg-laying holdings. Prev. Vet. Med. 2010, 94, 306–309. [Google Scholar] [CrossRef] [PubMed]
- Godwin, R.T.; Böhning, D. Estimation of the population size by using the one-inflated positive Poisson model. J. R. Stat. Soc. Ser. C Appl. Stat. 2017, 66, 425–448. [Google Scholar] [CrossRef]
- Tajuddin, R.R.M.; Ismail, N.; Ibrahim, K. On variance estimation for the population size estimator under one-inflated positive Poisson distribution. Malays. J. Fundam. Appl. Sci. 2022, 18, 237–244. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distributions | |||||
|---|---|---|---|---|---|
| Poisson | (MLE) | (Moment) | |||
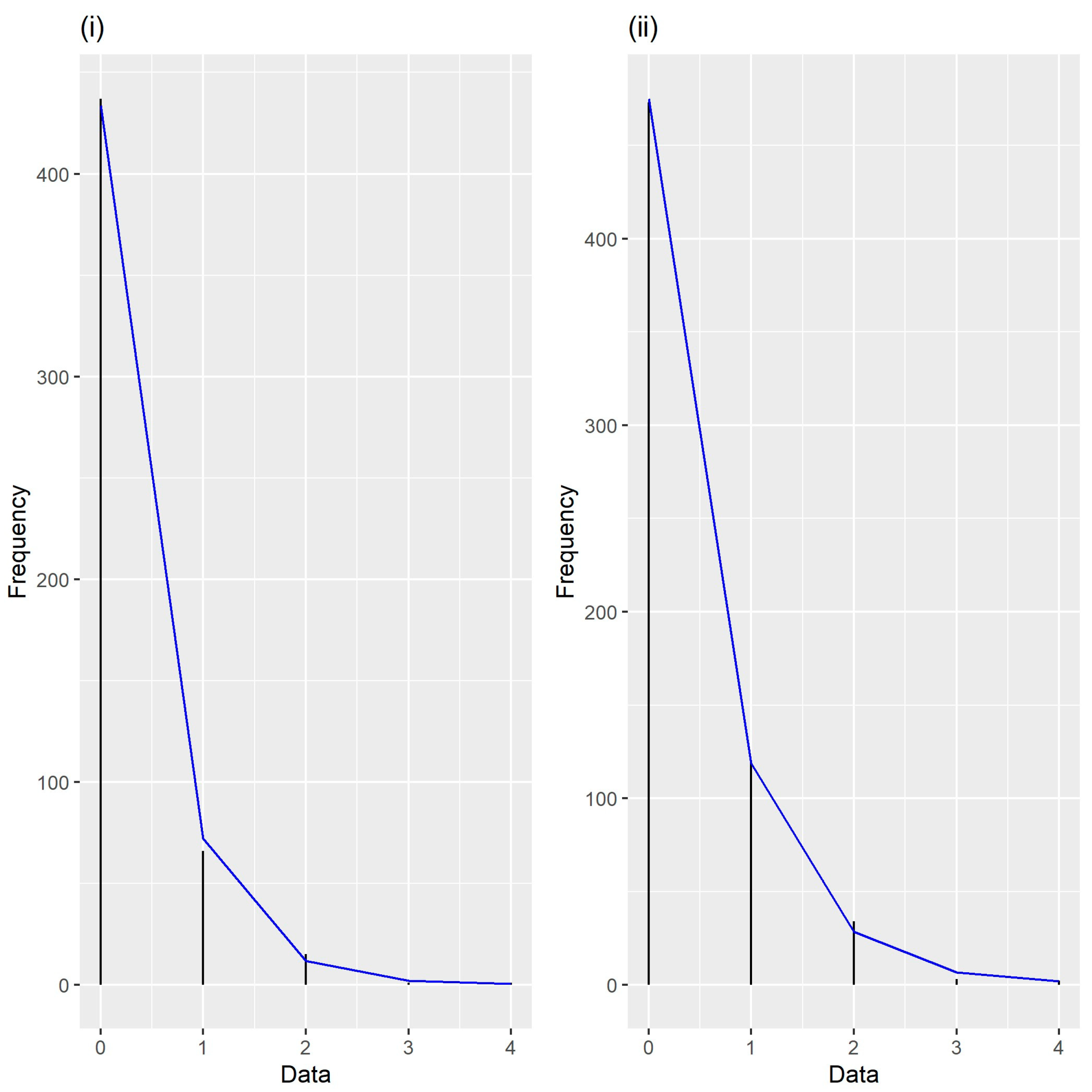
| 0 | 437 | 426.55 | 433.87 | 433.73 | 433.64 |
| 1 | 66 | 84.50 | 72.04 | 72.30 | 72.36 |
| 2 | 15 | 8.37 | 11.81 | 11.75 | 11.77 |
| 3 | 1 | 0.55 | 1.91 | 1.87 | 1.88 |
| 4 | 1 | 0.03 | 0.37 | 0.35 | 0.37 |
| Total | 520 | 520.00 | 520.00 | 520.00 | 520.00 |
| Parameter | |||||
| 0.1981 | - | 6.5464 | 6.5392 | ||
| - | 5.7953 | - | - | ||
| Max log-likelihood | −285.14 | −279.40 | −279.45 | ||
| 572.27 | 560.80 | 560.90 | - | ||
| 576.52 | 565.05 | 565.15 | - | ||
| 11.55 | 1.13 | 1.23 | 1.22 | ||
| df | 1 | 1 | 1 | 1 | |
| p-value | 0.0007 | 0.2878 | 0.2674 | 0.2694 | |
| Distributions | |||||
|---|---|---|---|---|---|
| Poisson | (MLE) | (Moment) | |||
| 0 | 473 | 456.69 | 475.79 | 474.91 | 475.07 |
| 1 | 119 | 147.65 | 117.81 | 118.96 | 118.88 |
| 2 | 34 | 23.87 | 28.53 | 28.55 | 28.50 |
| 3 | 3 | 2.57 | 6.79 | 6.64 | 6.62 |
| 4 | 2 | 0.22 | 2.08 | 1.94 | 1.93 |
| Total | 631 | 631.00 | 631.00 | 631.00 | 631.00 |
| Parameter | |||||
| 0.3233 | - | 4.4001 | 4.4046 | ||
| - | 3.7420 | - | - | ||
| Max log-likelihood | −469.65 | −464.09 | −463.96 | ||
| 941.30 | 930.17 | 929.91 | - | ||
| 945.75 | 934.61 | 934.36 | - | ||
| 11.85 | 2.77 | 2.54 | 2.54 | ||
| df | 1 | 2 | 2 | 2 | |
| p-value | 0.0006 | 0.2503 | 0.2808 | 0.2808 | |
| Distributions | |||||
|---|---|---|---|---|---|
(MLE) | (Moment) | ||||
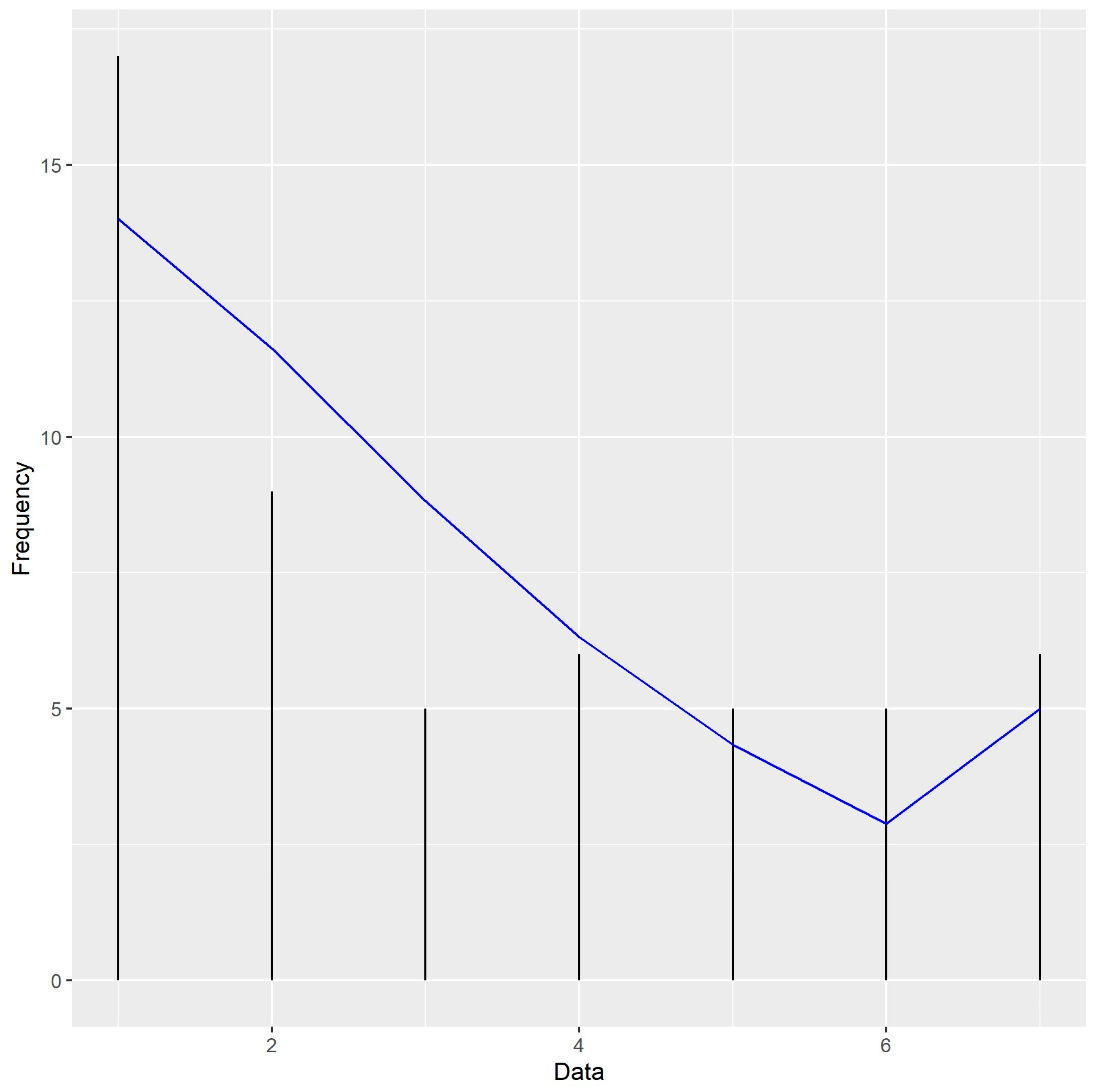
| 1 | 17 | 7.88 | 15.06 | 14.01 | 14.00 |
| 2 | 9 | 12.12 | 11.55 | 11.62 | 11.62 |
| 3 | 5 | 12.44 | 8.45 | 8.82 | 8.82 |
| 4 | 6 | 9.57 | 5.99 | 6.32 | 6.32 |
| 5 | 5 | 5.89 | 4.15 | 4.34 | 4.34 |
| 6 | 5 | 3.02 | 2.83 | 2.89 | 2.89 |
| 7 | 6 | 2.08 | 4.97 | 5.00 | 5.01 |
| Total | 53 | 53.00 | 53.00 | 53.00 | 53.00 |
| Parameter | |||||
| 3.0778 | - | 0.8932 | 0.8928 | ||
| - | 0.6660 | - | - | ||
| Max log-likelihood | −110.64 | −105.28 | −105.10 | ||
| 223.27 | 212.55 | 212.19 | - | ||
| 225.24 | 214.53 | 214.16 | - | ||
| 24.10 | 3.61 | 4.16 | 4.16 | ||
| df | 4 | 3 | 4 | 4 | |
| p-value | <0.0001 | 0.3068 | 0.3848 | 0.3848 | |
| Distributions | 95% Lower Limit | 95% Upper Limit | ||
|---|---|---|---|---|
| 55.56 | 1.761 | 52.11 | 59.01 | |
| 71.21 | 4.045 | 63.28 | 79.14 | |
| (MLE) | 66.64 | 4.896 | 57.04 | 76.24 |
| (Moment) | 63.10 | 4.961 | 53.38 | 72.82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alomair, G.; Tajuddin, R.R.M.; Bakouch, H.S.; Almohisen, A. A Statistical Model for Count Data Analysis and Population Size Estimation: Introducing a Mixed Poisson–Lindley Distribution and Its Zero Truncation. Axioms 2024, 13, 125. https://0-doi-org.brum.beds.ac.uk/10.3390/axioms13020125
Alomair G, Tajuddin RRM, Bakouch HS, Almohisen A. A Statistical Model for Count Data Analysis and Population Size Estimation: Introducing a Mixed Poisson–Lindley Distribution and Its Zero Truncation. Axioms. 2024; 13(2):125. https://0-doi-org.brum.beds.ac.uk/10.3390/axioms13020125
Chicago/Turabian StyleAlomair, Gadir, Razik Ridzuan Mohd Tajuddin, Hassan S. Bakouch, and Amal Almohisen. 2024. "A Statistical Model for Count Data Analysis and Population Size Estimation: Introducing a Mixed Poisson–Lindley Distribution and Its Zero Truncation" Axioms 13, no. 2: 125. https://0-doi-org.brum.beds.ac.uk/10.3390/axioms13020125