1. Introduction
In late December 2019, the COVID-19 disease was discovered in Wuhan, a city in eastern China, and began spreading worldwide. By March 2020, the World Health Organization (WHO) classified it as a pandemic. COVID-19 is a pathogen strain caused by SARS-CoV2 that causes severe acute respiratory discomfort and exhibits symptoms of pneumonia in humans. The infection usually starts in the mucous membrane in the throat and rapidly spreads to the lungs. Once in the lungs, it impairs function and mutates rapidly before a patient can be diagnosed correctly. It is transmitted efficiently from human-to-human via aerosol and is highly infectious. This makes COVID-19 a public health emergency. Early detection and diagnosis are significant for breaking the transmission chain and controlling its spread.
To help control the spread of the disease, healthcare professionals and researchers have adopted several modalities to detect the virus. Some of the modalities include reverse transcriptase–polymerase chain reaction (RT-PCR) test [
1], chest X-ray (CXR) image [
2,
3], and computed tomography (CT) scans [
4]. RT-PCR has been the go-to diagnostic modality for detecting COVID-19 pathogens. It requires acquiring a respiratory specimen from the subject’s body. Though efficient, it has some disadvantages, such as a longer detection time and a lower detection rate.
Chest radiography images in the last decade have been used as a primary diagnostic tool in clinical practice to examine the cardiothoracic region for abnormalities. Pulmonary fibrosis, pneumonia, emphysema, chronic bronchitis, and lung cancer are a few of the pulmonary diseases that have been detected using chest radiography images [
5,
6]. In using CXR images as a diagnostic tool, lung abnormalities, such as bilateral or interstitial lung consolidation and/or ground grass opacities [
7] can be identified, making CXR images a remarkable tool for detecting of COVID-19 disease at the early stage [
8]. Given the similarity between COVID-19 and other respiratory disorders, such as pneumonia, the experience of the specialist is essential to identify and characterize COVID-19 biomarkers from other related clinical findings. Manually characterizing and identifying these biomarkers is tedious and does not permit the procedure to be repeated since it is time-consuming. Therefore, an automatic system is required to identify normal or COVID-19 cases with high accuracy by analyzing CXR images. Not only will it speed up the detection process, but it will also help reduce the workloads of health professionals.
Detecting COVID-19 is a typical classification problem in machine learning (ML) and deep learning (DL). ML and DL have demonstrated their effectiveness in solving problems in several domains. One advantage that has placed ML and DL as benchmark techniques in medical imaging is their computational capabilities and the availability of large labeled datasets [
9]. They have been explored to detect pulmonary abnormalities in CXR imaging [
10]. A deep convolutional neural network (CNN) for classifying lung images was proposed by Anthimopoulos et al. [
11]. A CNN-based method to quantify the percentage of emphysema on simulated CXR images was presented by Campo et al. [
12]. A deep neural network that incorporates both global and local features to identify pneumonia was proposed by Jaiswal et al. [
13]. In the context of COVID-19, several works have been proposed to detect COVID-19 disease using CXR images [
14,
15,
16,
17].
DL models may suffer from overfitting, high variance, and/or generalization errors because of the limited size of the training data and the presence of noise in the training data. Ensemble learning is a technique used to combine multiple models and is a practical approach to handling these errors. Not only does it handle these errors, it also yields better results compared to single models [
18].
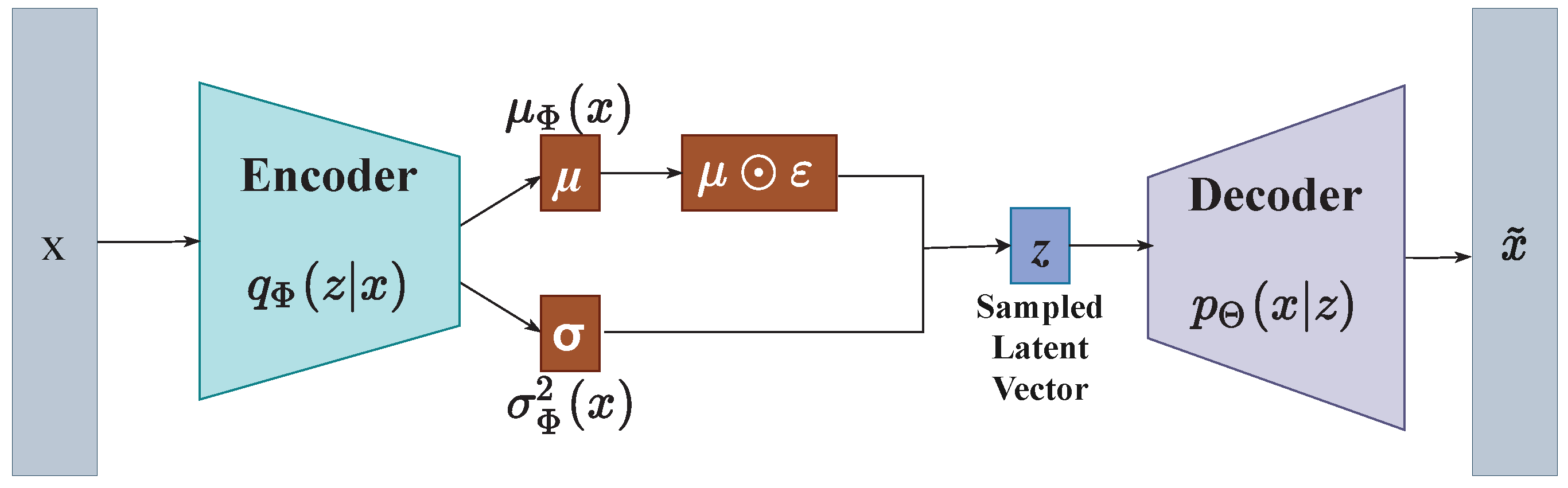
Researchers have recently found that unsupervised pre-training helps train supervised deep neural networks [
19]. One such fundamental unsupervised method employed to transform raw input data into a meaningful representation is autoencoders (AEs) [
20]. Unlike conventional AEs, which try to learn a distance function, VAEs, proposed by Kingma and Welling [
21], are powerful generative AEs that provide high-quality representations of the raw input data and generate desirable virtual instances in the controllable smooth latent space [
22].
Compared with conventional AEs, VAEs are highly capable of a more general approximation of the intractable posterior density and can efficiently carry out the inference [
21]. These advantages combined make VAEs extensively utilized and successful for a variety of machine learning tasks such as audio data recognition [
23], text captioning [
24], and natural image processing [
25]. Furthermore, the latent representations generated by VAEs can be controlled more accurately owing to the variational lower bound in the optimization of VAEs. This accurate modeling could provide superior representations compared to other AE variants and enhance the results of several downstream tasks, such as image classification [
26].
Additionally, by adjusting the distribution parameters, the generation of new instances can be easily controlled since VAEs learn the parameters of the specific probabilistic distributions. Again, due to their closed-form objective function, VAEs are more stable throughout training stages than other generative paradigms, such as generative adversarial networks (GANs) [
27], and have the potential to generate shaper samples that are comparable to GANs [
28]. Another major benefit of VAEs is their capability to handle larger datasets compared to variational inference. This is because VAEs can operate quickly using a single feedforward neural network to represent a stochastic function of the input variables. In contrast, variational inference typically becomes increasingly computationally complex as the number of samples increases.
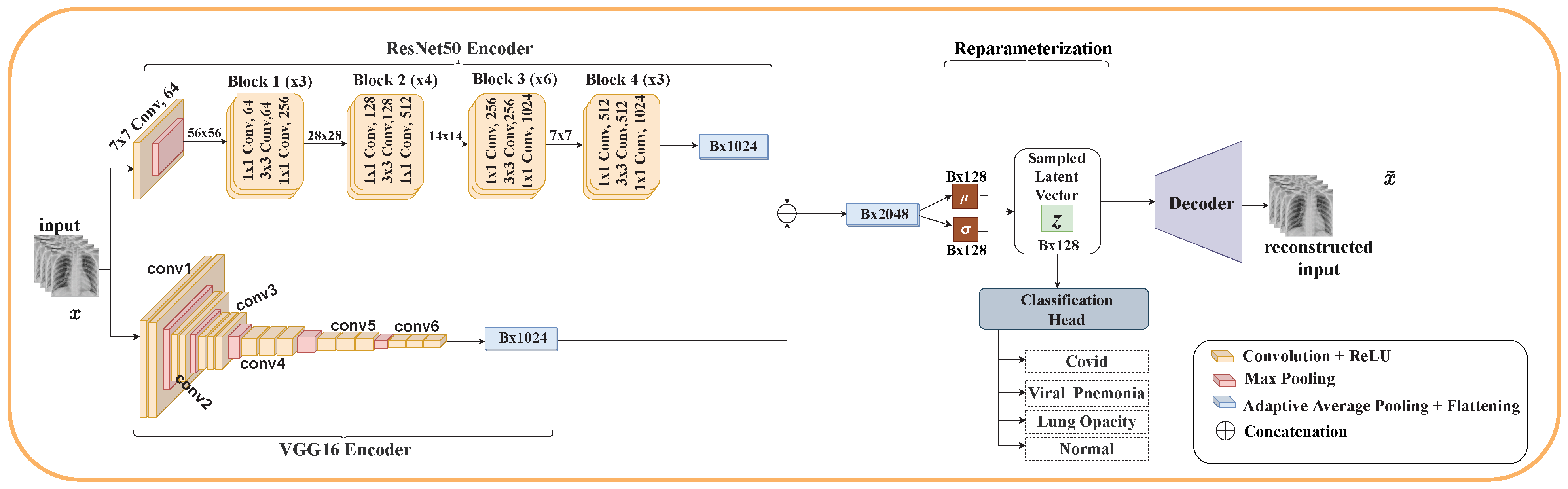
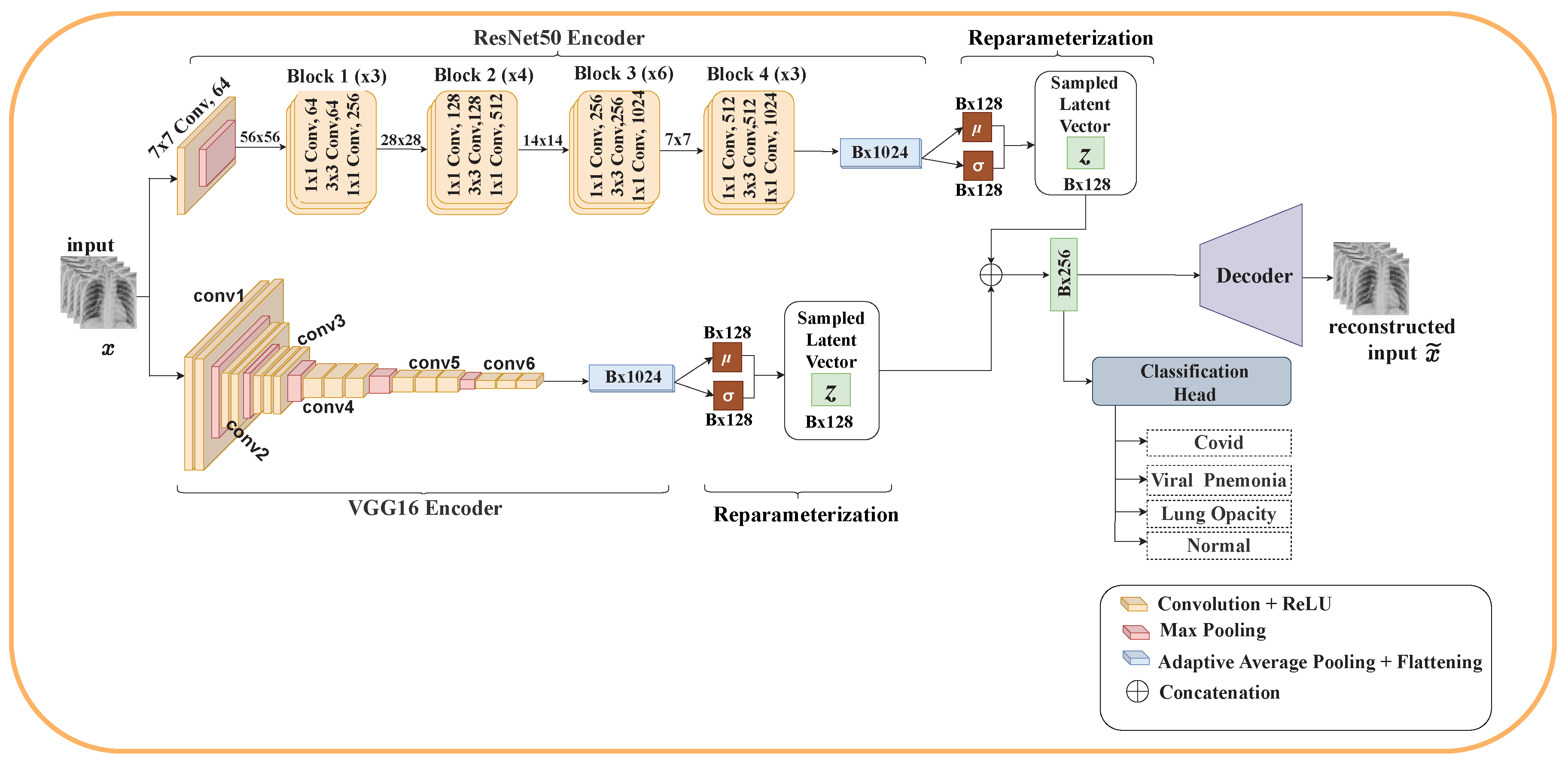
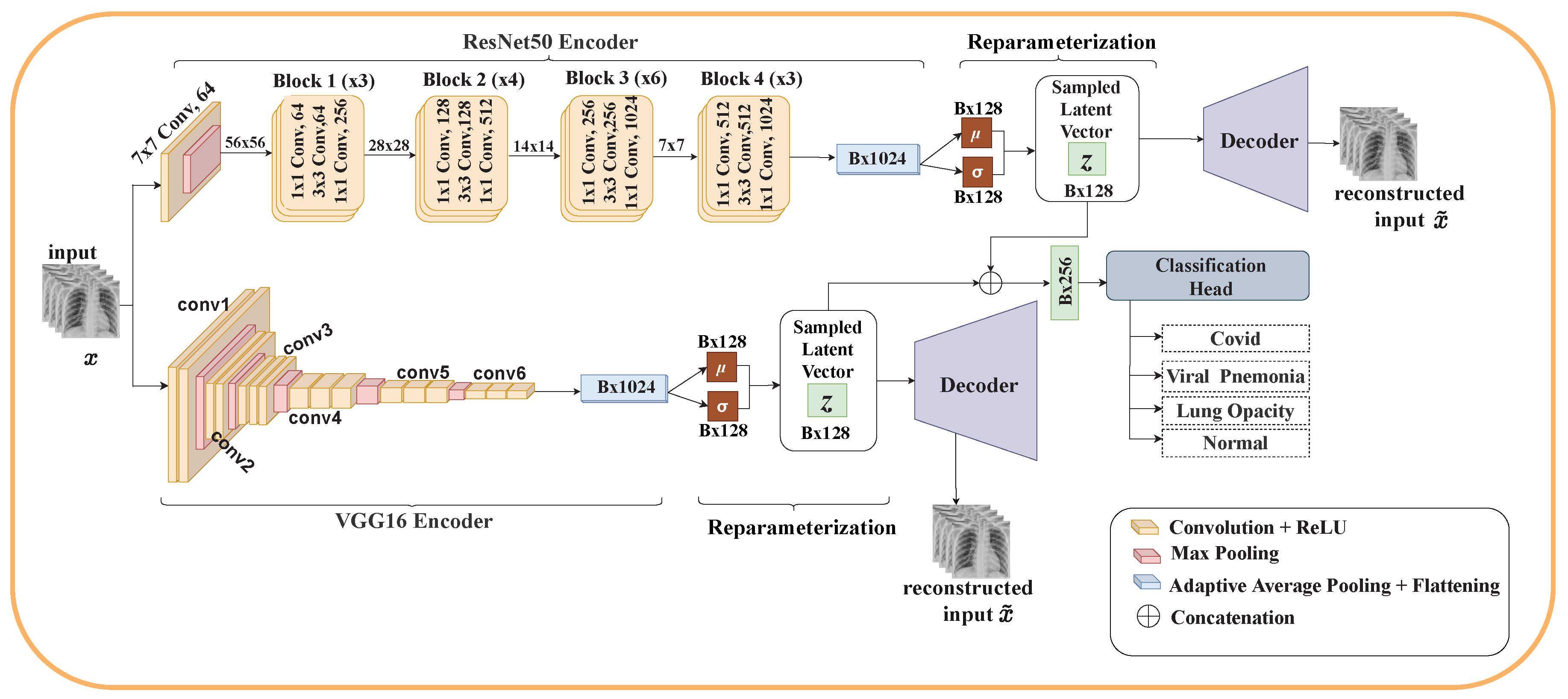
Motivated by this, we propose EVAE-Net, an ensemble variational autoencoder deep learning network that combines the high-quality latent representations generated by VAE and ensemble learning for COVID-19 classification based on chest X-ray images. Three variants of EVAE-Net are proposed, and their performances are compared. The proposed model consists of two encoders, one or two reparameterization phases, a classification head, and one or two decoders. In the case of the single reparameterization phase, the feature maps from the encoders are merged before sampling the latent embeddings. The latent embeddings are then passed to the classification head and the decoder for reconstruction. In the case where each encoder has its reparameterization phase, the feature maps from each encoder are passed to their respective reparameterization phase to generate the latent embeddings. The latent embeddings are merged to form a single latent embedding and passed to the classification head. The individual latent embeddings are passed to their respective decoders for reconstruction. Our proposed methodology achieves promising classification performance, with the best model achieving accuracy, recall, F1 score, and precision for three classes, and accuracy, recall and precision, and F1 score for four classes.
Contributions
The main contributions of our work are summarized as follows:
Propose a deep learning model based on VAE and ensemble learning for COVID-19 classification. Particularly, three models are proposed. Each model consists of an encoder for feature extraction, a reparameterization phase for sampling latent vectors from the extracted features, a decoder for reconstructing the input image from the latent vector, and a classification head for classifying COVID-19.
Demonstrate the superiority of the proposed model by performing essential experiments. The experiment was conducted on both three classes and four classes using the standard COVID-19 radiography database. Several classification metrics were used, including accuracy, recall, precision, F1 score, and ROC-AUC. The experimental results demonstrate that the proposed EVAE-Net can automatically classify COVID-19 infections from CXR images and achieve better performance.
Compare the performance of the proposed model to that of several state-of-the-art models, showing our proposed model outperforms these existing models.
The remaining work is structured as follows: In
Section 2, we present related studies and works.
Section 3 describes the research methodology. The datasets used in this work, evaluation metrics, and experimental setup are described in
Section 4, followed by results and analysis in
Section 5. Finally, we present discussion and conclusions of the study in
Section 6 and
Section 7, respectively.
5. Results and Analysis
This section reports the various experimental results of the proposed models using the COVID-19 Radiography dataset. For each of the models, we conducted several experiments by changing some of the hyperparameters. For the initial experiment, the Adam optimizer with a learning rate of was used and was trained for 20 epochs with a batch size of 4. This was done for both three and four classes. In the subsequent experiments, the optimizer was kept constant while we varied the learning rate.
5.1. Model Complexity
Table 5 shows the computational complexity of our proposed model in terms of the number of parameters and multiply-and-accumulate operations (MACs). From the table, Models One and Two have almost the same complexity since both models share a single decoder unit. The slight difference between their complexities is a result of Model Two performing a reparameterization operation for both encoders compared to a single reparameterization operation in Model One. For Model Three, each encoder has its own decoder, resulting in a higher number of parameters. Additionally, there are two reconstruction loss functions for the reconstruction of the input image, and one cross-entropy loss for the classification task, resulting in higher MACs.
5.2. Validation and Testing Performance Evaluation
Table 6 shows the best performance metrics for each model on the validation set. From the table, it can be observed that a learning rate of 0.00003 produced better results for the four classes, while for the three classes, different learning rates produced different results for every model.
For three classes, Model One achieves accuracy, recall, precision, and F1 score; Model Two achieves accuracy and recall, precision, and F1 score; Model Three achieves accuracy and recall, precision, and F1 score. For four classes, Model One achieves accuracy, recall, precision, and F1 score; Model Two achieves accuracy, recall, precision, and F1 score; Model Three achieves accuracy, recall, precision, and F1 score.
Table 7 shows the performance metrics of the best model (Model Three). For the three classes, it achieved
accuracy, recall, and F1 score, and
precision. For the four classes, an accuracy of
, recall of
, precision of
, and F1 score of
was achieved.
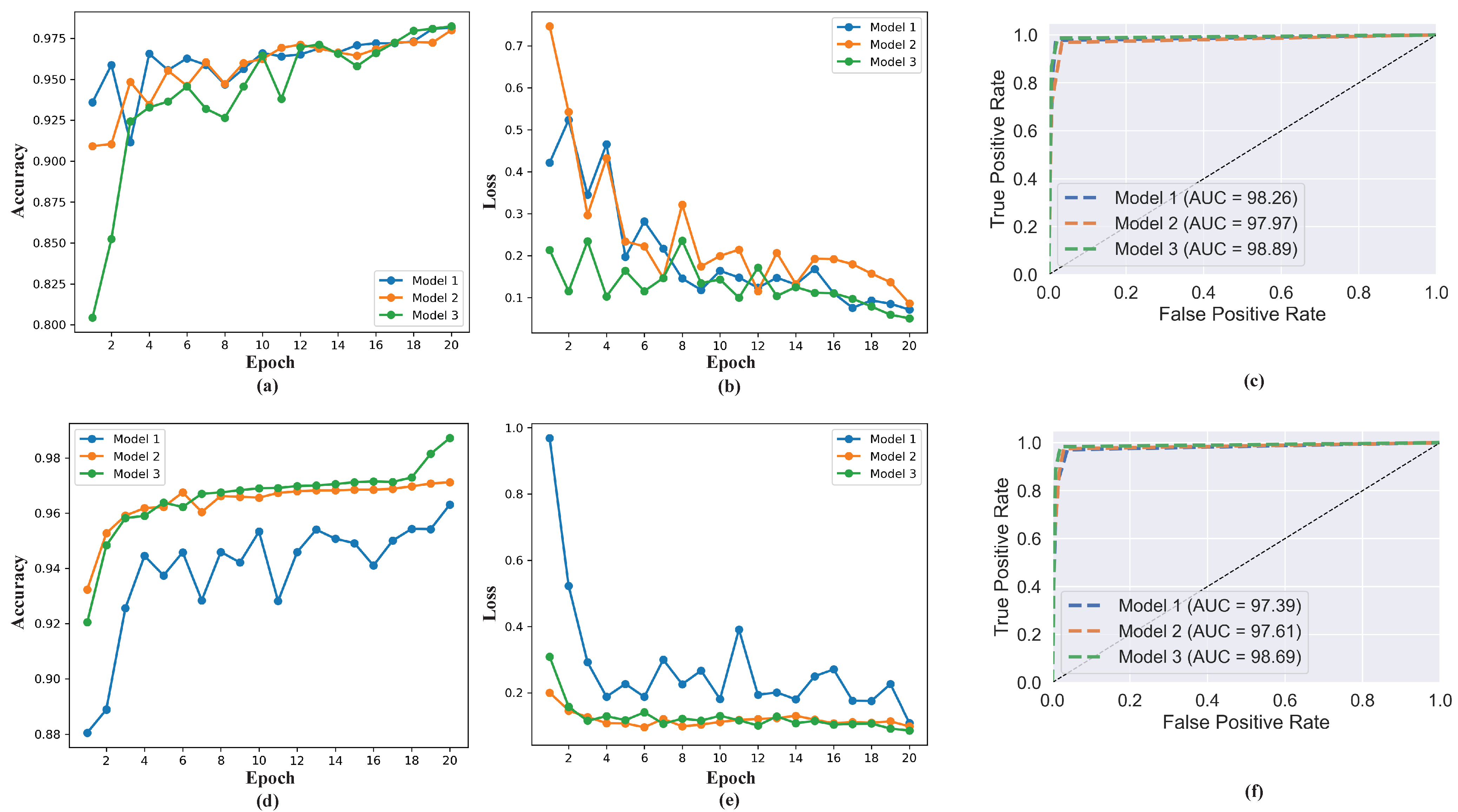
Figure 6 shows the accuracy, loss, and ROC AUC graph comparing the performance of the three models for both three classes and four classes. These results indicates the proposed model’s capability in classifying COVID-19. For all the performances measured, the best results are obtained with 20 training epochs, which is an indication that the performance of the model increases gradually as the number of epochs increases.
We performed cross-validation using the testing set, as depicted in
Table 8, which the model was not exposed to during training and validation. Cross-validations was performed to verify that our model does not suffer from overfitting and to test the model’s robustness. For three classes, Model One achieves
accuracy,
recall, and
precision and F1 score; Model Two achieves
accuracy,
recall, and
precision and F1 score; Model Three achieves
accuracy,
recall,
precision, and
F1 score. For four classes, Model One achieves
accuracy,
recall and F1 score, and
precision; Model Two achieves
accuracy,
recall,
precision, and
F1 score; Model Three achieves
accuracy,
recall and precision, and
F1 score.
Table 9 and
Table 10 show the confusion matrix for the cross-validation on the testing dataset. For three classes, out of a total of 487 radiographs, the model misclassified 130 radiographs; of those, 47 were COVID-19 images, 43 were normal images, and 40 were viral pneumonia images. For four classes, out of 2118 radiographs, the proposed model misclassified 17; of those, 4 were COVID-19 images, 3 were normal images, 6 were lung opacity images, and 4 were viral pneumonia images. This indicates the proposed model has higher true negative and true positive values and lower false negative and false positive values, suggesting the proposed model can accurately classify COVID-19 infections.
5.3. Ablation Studies
An ablation study was conducted to observe the contribution of the latent vector’s dimension to the model’s performance. The default dimension of the latent vector throughout the experiment was 128. Using a learning rate of 0.00003 and the Adam optimizer, we experimented with two lower dimensions for the ablation study: 32 and 64. The ablation study was conducted for both three classes and four classes on the validation dataset.
Table 11 shows the ablation study for various latent sizes. The table shows that the model’s performance increases with an increase in the latent vector’s dimension. A latent dimension of 128 achieves higher performance in all the models.
5.4. Comparison with State-of-the-Art Methods
We compared our proposed model to various methods, as shown in
Table 12. The comparison shows the proposed model, EVAE-Net, outperformed the methods in [
37,
40,
41,
95,
96] using the same dataset (COVID-19 Radiography Database) for COVID-19 classification and methods that used other modalities [
17,
38,
49,
97]. It was worth noting that most of these methods only focused on either three classes or four classes. In our proposed model, we tested both three classes and four classes, making our model generalize better for COVID-19 classification.
6. Discussion and Future Work
In this study, we adopted VAE combined with an ensemble technique for the classification of COVID-19 with high accuracy.
Table 4 and
Table 7 show the best model’s validation and testing performance metrics. Of the three models, Model Three achieved the best performance. This reveals that the best result is obtained when each encoder implements its own decoder. With a single decoder, as with Model One and Model Two, the model’s performance highly depends on how each encoder can extract relevant features from the input, since they share a single
. With a decoder for each encoder, each encoder implements its
with the advantage of learning to improve its performance from the loss by extracting more relevant features from the input. This further improves the latent embeddings sampled during the reparameterization stage since they are sampled from feature maps with more relevant features. A merger of the two latent vectors produces a richer latent vector, producing a higher classification result. The proposed EVAE-Net is more accurate than PCR since PCR results rely on the sample collection time and how they are stored and processed. Again, PCR results have high false negative rates when the patient is tested too early or too late after exposure to the virus. Further, the proposed model has higher true negative and true positive values and lower false negative and false positive values, suggesting the proposed model can accurately classify COVID-19 infections.
Although the proposed EVAE-Net produced interesting results, it still has some limitations, which we will address in future work. The proposed model cannot indicate the exact region of pneumonia in the chest X-ray image, which is vital for a radiologist. Future work will consider an attention mechanism focusing on the precise pneumonia region in the chest X-ray image. Since we only concentrated on using chest X-ray images for this study, the proposed model is biased toward chest X-ray images. This study did not consider other data modalities, such as CT scans. In future research, we will extensively examine other imaging modalities, which will help the model to generalize better.
Furthermore, we will combine several imaging modalities into a single dataset to investigate the robustness of the proposed model in future studies. We will also examine how image enhancement techniques such as discrete wavelet transform (DWT), CLAHE, etc., will enhance the feature maps from the encoders to improve the model’s performance. We believe images that the model incorrectly classified can be improved when enhanced.
Other limitations are associated with the nature of VAE architecture. VAE architecture requires rich domain-specific knowledge, and this barrier prevents end users without design expertise from utilizing VAEs. Even researchers with expert knowledge must go through an arduous trial-and-error process to tune the architecture manually. For example, finding the optimal depth of the VAE is unknown from the beginning. Thus, it is unknown how to choose the appropriate number of convolutional, pooling, and dense layers for the VAE architecture and what the optimal hyperparameters for each convolutional and deconvolutional layer are. In future studies, we will explore neural architecture search (NAS) to find solutions to this limitation.
In recent years, many Internet of Things (IoT) devices, particularly Medical Internet of Things (MIoT), have been adopted in the health sector to combat various medical issues. Several applications have been deployed in these smart devices for remote patient monitoring (RPM) and other related medical tasks. In fighting against COVID-19, one important aspect of containing the virus is an effective and fast diagnosis method. With the rate at which the virus spreads, diagnosing and screening it quickly is key to containing it. Therefore, there is a need to develop effective and efficient deep learning models leveraging the advantages of IoT and MIoT to diagnose and screen COVID-19 with speed.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}