
Artificial Intelligence-Based Cervical Cancer Screening on Images Taken during Visual Inspection with Acetic Acid: A Systematic Review

 ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Protocol and Registration
2.2. Literature Searching Strategy
2.3. Studies Selection
- The studies should assess an automated artificial intelligence-based algorithm aimed at distinguishing CIN2+ (positive) from normal and benign conditions (negative), relying only on images taken during VIA. Were excluded: studies considering CIN1 as positive or not containing healthy cases.
- For precancerous and cancerous lesions, the gold standard used to study the accuracy of the algorithms should be histopathology results, while histopathology or normal cytology and normal colposcopy were considered sufficient for negative cases. This criterion is motivated by the fact that even though histopathology results remain the most reliable method for diagnosis, some screening procedures only conduct biopsies when there is a suspicion of precancerous lesion after cytology and colposcopy. Were excluded: studies not mentioning their gold standards or with unclear gold standards.
- The studies should be written in English and published between January 2015 and July 2022.
- The studies should be original research articles and peer-reviewed. Were excluded: review articles, conference abstracts articles and pre-prints.
2.4. Data Collection and Extraction
2.5. Quality Assessment
2.6. Data Analysis
3. Results
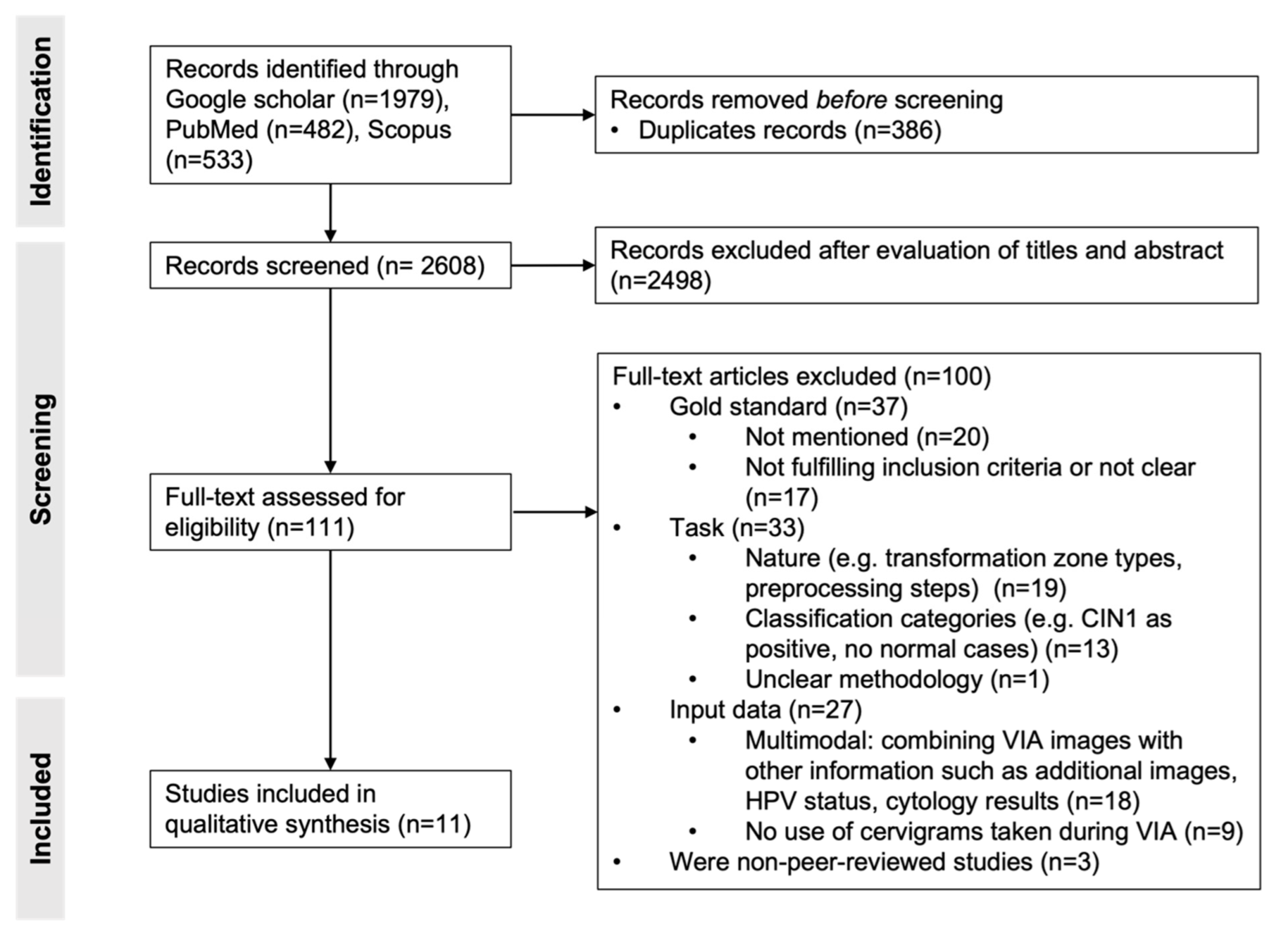
3.1. Study Selection
3.2. Study Characteristics
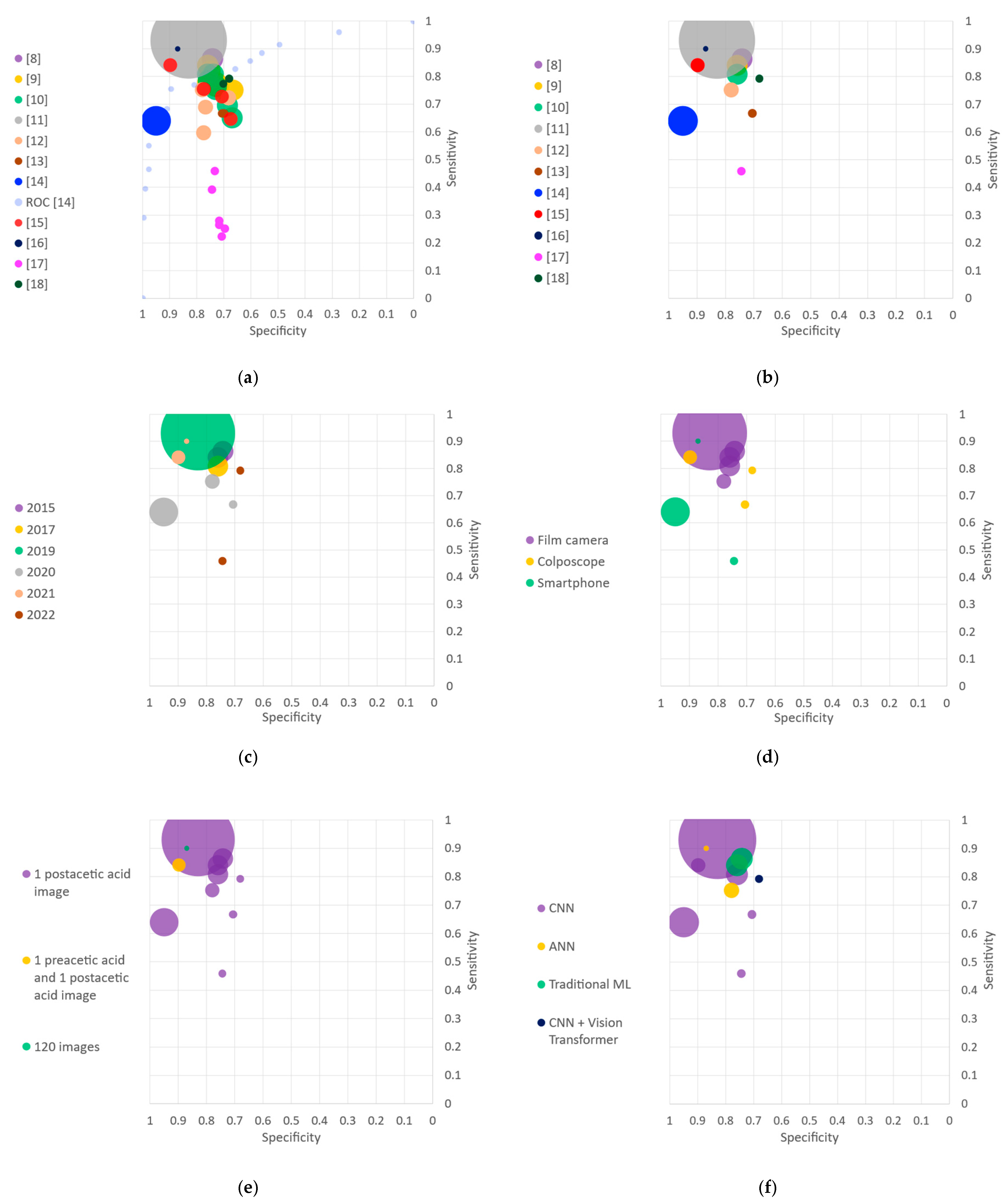
3.2.1. Data Acquisition Settings
3.2.2. Image Quality and Selection
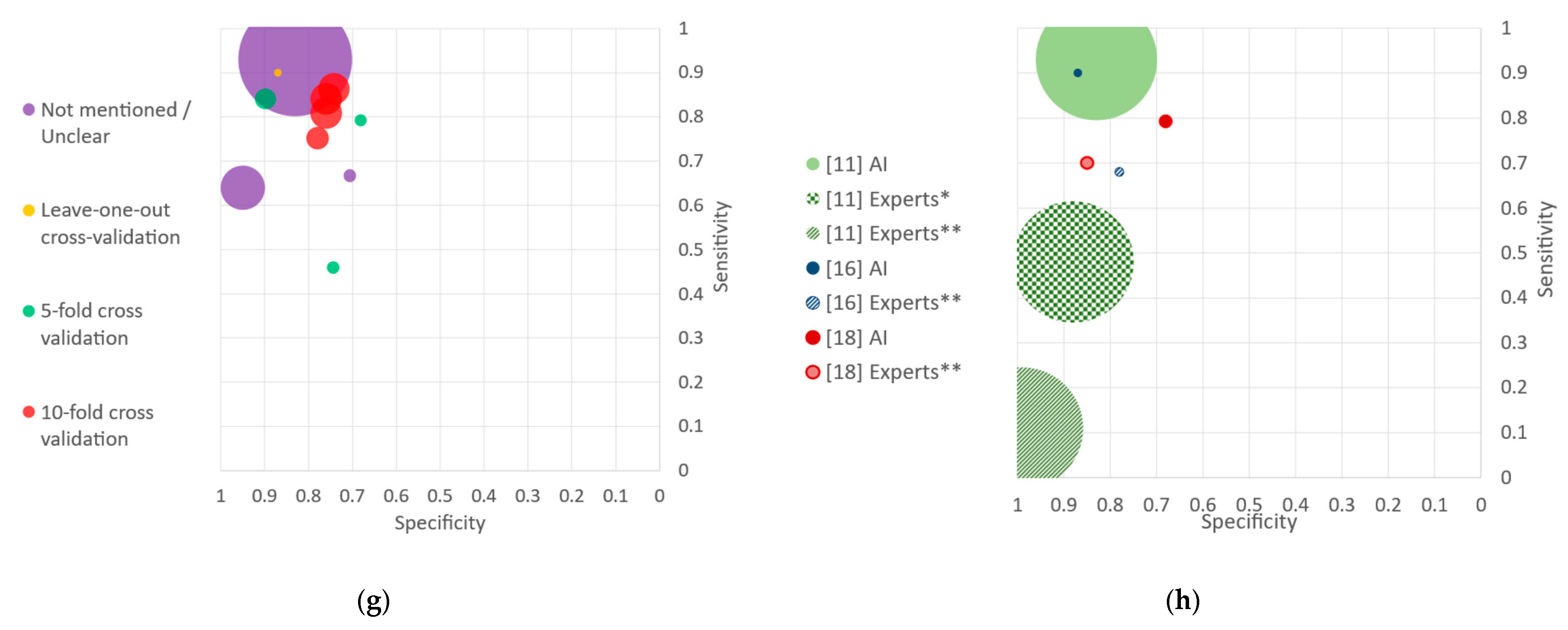
3.2.3. Gold Standard
3.2.4. Dataset Size and Partitioning
3.2.5. Preprocessing Steps
3.2.6. Classification Technique
3.2.7. Data Acquisition Settings
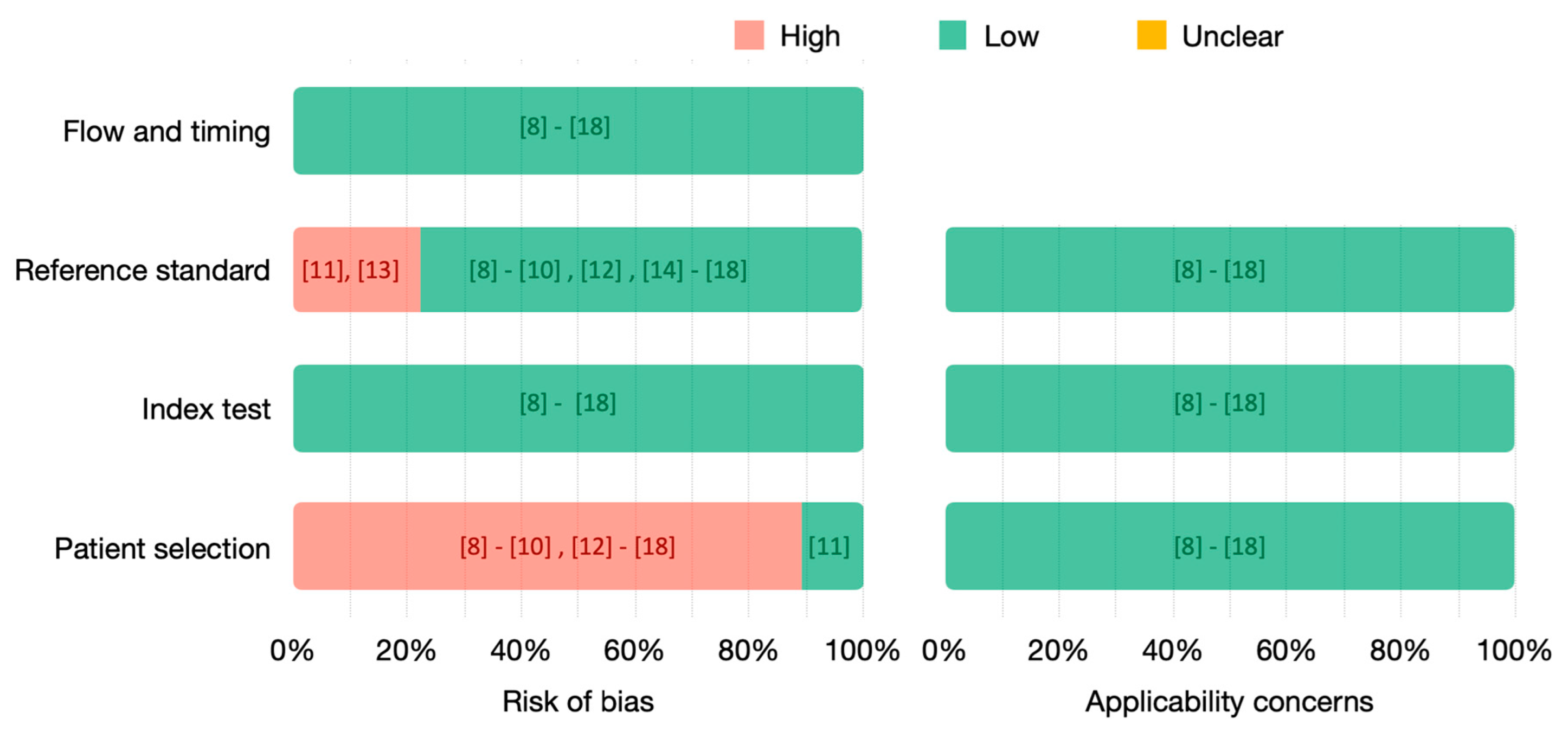
3.3. Quality Assessment
4. Discussion
4.1. Dataset Size and Diversity
4.2. Screening Approaches
4.3. Input to the Algorithm and Preprocessing Steps
4.4. Performance Reporting
4.5. Implementation for LMICs
4.6. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA. Cancer J. Clin. 2021, 71, caac.21660. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Global strategy to accelerate the elimination of cervical cancer as a public health problem and its associated goals and targets for the period 2020–2030. U. N. Gen. Assem. 2020, 2, 1–56. [Google Scholar]
- Gravitt, P.E.; Paul, P.; Katki, H.A.; Vendantham, H.; Ramakrishna, G.; Sudula, M.; Kalpana, B.; Ronnett, B.M.; Vijayaraghavan, K.; Shah, K.V.; et al. Effectiveness of VIA, pap, and HPV DNA testing in a cervical cancer screening program in a Peri-Urban community in Andhra Pradesh, India. PLoS ONE 2010, 5, e13711. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bigoni, J.; Gundar, M.; Tebeu, P.-M.; Bongoe, A.; Schäfer, S.; Domgue, J.B.F.; Catarino, R.; Tincho, E.F.; Bougel, S.; Vassilakos, P.; et al. Cervical cancer screening in sub-Saharan Africa: A randomized trial of VIA versus cytology for triage of HPV-positive women. Int. J. Cancer 2014, 137, 127–134. [Google Scholar] [CrossRef] [PubMed]
- De Vuyst, H.; Claeys, P.; Njiru, S.; Muchiri, L.; Steyaert, S.; De Sutter, P.; Van Marck, E.; Bwayo, J.; Temmerman, M. Comparison of pap smear, visual inspection with acetic acid, human papillomavirus DNA-PCR testing and cervicography. Int. J. Gynecol. Obstet. 2005, 89, 120–126. [Google Scholar] [CrossRef]
- Zuchna, C.; Hager, M.; Tringler, B.; Georgoulopoulos, A.; Ciresa-Koenig, A.; Volgger, B.; Widschwendter, A.; Staudach, A. Diagnostic accuracy of guided cervical biopsies: A prospective multicenter study comparing the histopathology of simultaneous biopsy and cone specimen. Am. J. Obstet. Gynecol. 2010, 203, 321.e1–321.e6. [Google Scholar] [CrossRef] [PubMed]
- Massad, L.S.; Jeronimo, J.; Katki, H.A.; Schiffman, M.; National Institutes of Health/American Society for Colposcopy and Cervical Pathology (The NIH/ASCCP) Research Group. The accuracy of colposcopic grading for detection of high-grade cervical intraepithelial neoplasia. J. Low. Genit. Tract Dis. 2009, 13, 137–144. [Google Scholar] [CrossRef]
- Xu, T.; Kim, E.; Huang, X. Adjustable adaboost classifier and pyramid features for image-based cervical cancer diagnosis. Proc. Int. Symp. Biomed. Imaging 2015, 2015, 281–285. [Google Scholar] [CrossRef]
- Xu, T.; Xin, C.; Long, L.R.; Antani, S.; Xue, Z.; Kim, E.; Huang, X. A new image data set and benchmark for cervical dysplasia classification evaluation. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2015, 9352, 26–35. [Google Scholar] [CrossRef]
- Xu, T.; Zhang, H.; Xin, C.; Kim, E.; Long, L.R.; Xue, Z.; Antani, S.; Huang, X. Multi-feature based benchmark for cervical dysplasia classification evaluation. Pattern Recognit. 2017, 63, 468–475. [Google Scholar] [CrossRef] [Green Version]
- Hu, L.; Bell, D.; Antani, S.; Xue, Z.; Yu, K.; Horning, M.P.; Gachuhi, N.; Wilson, B.; Jaiswal, M.S.; Befano, B.; et al. An Observational Study of Deep Learning and Automated Evaluation of Cervical Images for Cancer Screening. JNCI J. Natl. Cancer Inst. 2019, 111, 923–932. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alyafeai, Z.; Ghouti, L. A fully-automated deep learning pipeline for cervical cancer classification. Expert Syst. Appl. 2019, 141, 112951. [Google Scholar] [CrossRef]
- Cho, B.-J.; Choi, Y.J.; Lee, M.-J.; Kim, J.H.; Son, G.-H.; Park, S.-H.; Kim, H.-B.; Joo, Y.-J.; Cho, H.-Y.; Kyung, M.S.; et al. Classification of cervical neoplasms on colposcopic photography using deep learning. Sci. Rep. 2020, 10, 13652. [Google Scholar] [CrossRef] [PubMed]
- Xue, Z.; Novetsky, A.P.; Einstein, M.H.; Marcus, J.Z.; Befano, B.; Guo, P.; Demarco, M.; Wentzensen, N.; Long, L.R.; Schiffman, M.; et al. A demonstration of automated visual evaluation of cervical images taken with a smartphone camera. Int. J. Cancer 2020, 147, 2416–2423. [Google Scholar] [CrossRef] [PubMed]
- Peng, G.; Dong, H.; Liang, T.; Li, L.; Liu, J. Diagnosis of cervical precancerous lesions based on multimodal feature changes. Comput. Biol. Med. 2021, 130, 104209. [Google Scholar] [CrossRef] [PubMed]
- Viñals, R.; Vassilakos, P.; Rad, M.S.; Undurraga, M.; Petignat, P.; Thiran, J.-P. Using dynamic features for automatic cervical precancer detection. Diagnostics 2021, 11, 716. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zall, Y.; Nissim, R.; Satyam; Zimmermann, R. Evaluation of a new dataset for visual detection of cervical precancerous lesions. Expert Syst. Appl. 2021, 190, 116048. [Google Scholar] [CrossRef]
- Li, P.; Wang, X.; Liu, P.; Xu, T.; Sun, P.; Dong, B.; Xue, H. Cervical Lesion Classification Method Based on Cross-Validation Decision Fusion Method of Vision Transformer and DenseNet. J. Healthc. Eng. 2022, 2022, 3241422. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Harzing, A.W. Publish or Perish. 2007. Available online: https://harzing.com/resources/publish-or-perish (accessed on 8 January 2023).
- Whiting, P.F.; Rutjes, A.W.S.; Westwood, M.E.; Mallett, S.; Deeks, J.J.; Reitsma, J.B.; Leeflang, M.M.G.; Sterne, J.A.C.; Bossuyt, P.M.M.; QUADAS-2 Group. Quadas-2: A revised tool for the quality assessment of diagnostic accuracy studies. Ann. Intern. Med. 2011, 155, 529–536. [Google Scholar] [CrossRef]
- Herrero, R.; Hildesheim, A.; Bratti, C.; Sherman, M.E.; Hutchinson, M.; Morales, J.; Balmaceda, I.; Greenberg, M.D.; Alfaro, M.; Burk, R.D.; et al. Population-based study of human papillomavirus infection and cervical neoplasia in rural Costa Rica. J. Natl. Cancer Inst. 2000, 92, 464–474. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Li, P.; Lv, Y.; Xue, H.; Xu, T.; Du, Y.; Liu, P. Integration of Global and Local Features for Specular Reflection Inpainting in Colposcopic Images. J. Healthc. Eng. 2021, 2021, 5401308. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31, pp. 4278–4284. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. Comput. Vis. ECCV 2016, 2016, 630–645. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Tan, M.; Le, Q. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; Volume 139, pp. 10096–10106. [Google Scholar]
- Hilal, Z.; Tempfer, C.B.; Burgard, L.; Rehman, S.; Rezniczek, G.A. How long is too long? Application of acetic acid during colposcopy: A prospective study. Am. J. Obstet. Gynecol. 2020, 223, 101.e1–101.e8. [Google Scholar] [CrossRef]
- Darragh, T. The lower anogenital squamous terminology standardization project for HPV-associated lesions: Background and consensus recommendations from the College of American Pathologists and the American Society for colposcopy and cervical pathology. Arch. Pathol. Lab. Med. 2012, 136, 1266–1297. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Title | First Author | Year | Acquisition Device | Cross Validation | Acquisition Country | Gold Standard | Number of Patients and Images | Number of Positive and Negative Patients | |
|---|---|---|---|---|---|---|---|---|---|
| [8] | Adjustable adaboost classifier and pyramid features for image-based cervical cancer diagnosis | T Xu | 2015 | Film camera (Cerviscope) | 10-fold cross validation | Costa Rica | Negative: Histopathology Positive: Histopathology | Selection of balanced dataset only | |
| Number of patients: 690 patients Number of images per patient: 2 sequential images Number of images used for classifying one patient: 1 Training and test sets (sample size): 690 patients Each fold: 621 patients used for training and 69 for testing | 345 negative (normal or CIN1) and 345 positive (CIN2+) Prevalence: 0.5 | ||||||||
| [9] | A new image data set and benchmark for cervical dysplasia classification evaluation | T Xu | 2015 | Film camera (Cerviscope) | 10-fold cross validation | Costa Rica | Negative: Histopathology Positive: Histopathology | Similar to [8] | Similar to [8] |
| [10] | Multi-feature based benchmark for cervical dysplasia classification evaluation | T Xu | 2017 | Film camera (Cerviscope) | 10-fold cross validation | Costa Rica | Negative: Histopathology Positive: Histopathology | Similar to [8] | Similar to [8] |
| [11] | An observational study of deep learning and automated evaluation of cervical images for cancer screening | L Hu | 2019 | Film camera (Cerviscope) | Not mentioned | Costa Rica | Negative: Normal cytology and normal cervicography Positive: Histopathology | Number of patients: 9406 patients Number of images per patient: Multiple images per patient Number of images used for classifying one patient: 1 Test set (sample size): 8917 patients Each fold: not applicable | Results reported on 8917 patients: 8689 negative (normal or CIN1) and 228 positive (CIN2+) Prevalence: 0.03 |
| [12] | A fully-automated deep learning pipeline for cervical cancer classification | Z Alyafeai | 2020 | Film camera (Cerviscope) | Stratified 10-fold cross validation | Costa Rica | Negative: Histopathology Positive: Histopathology | Number of patients: 348 patients Number of images per patient: 1 image per patient Number of images used for classifying one patient: 1 Training and test sets (sample size): 348 images Each fold: 314 images used for training and 34 for testing | 174 negative (normal or CIN1) and 174 positive (CIN2+) Prevalence: 0.5 |
| [13] | Classification of cervical neoplasms on colposcopic photography using deep learning | BJ Cho | 2020 | Colposcope | Unclear a | South Korea | Negative: Normal cytology and normal cervicography Positive: Histopathology | Number of patients: 791 patients Number of images per patient: 1.8 image per patient on average (1426 in total) Number of images used for classifying one patient: 1 (highest quality) Train set: 675 images Test set (sample size): 116 images Each fold: not applicable | Training dataset: 193 negative (normal or CIN1) and 482 positive (CIN2+). Prevalence: 0.72 Test dataset: 33 negative (normal or CIN1) and 83 positive (CIN2+). Prevalence: 0.72 |
| [14] | A demonstration of automated visual evaluation of cervical images taken with a smartphone camera | Z Xue | 2020 | Smartphone | Not mentioned | Various countries in Asia, Africa, North America and South America | Negative: Histopathology Positive: Histopathology | Subdataset of only data with histopathologic results | |
| Number of patients: 537 patients Number of images per patient: 2.2 images per patient on average (1159 in total) Number of images used for classifying one patient: All images are independently used Test set (sample size): approximately 107 cases (20% of the data are biopsy validated). Each fold: not applicable | Test dataset (biopsy validated): 405 negative cases (1027 images) (normal or CIN1) and 132 positive cases (315 images)(CIN2+). Prevalence (at image level): 0.23 Prevalence (at patient level): 0.25 | ||||||||
| [15] | Diagnosis of cervical precancerous lesions based on multimodal feature changes | G Peng | 2021 | Colposcope | 5-fold cross validation | China | Negative: Histopathology Positive: Histopathology | Number of patients: 300 patients Number of images per patient: 2 images (preacetic and postacetic acid) Number of images used for classifying one patient: 1 or 2, depending on the algorithm Training and test sets (sample size): 300 patients Each fold: 240 patients used for training and 60 for testing | 75 normal, 75 CIN1, 75 CIN2, and 75 CIN3 patients Prevalence: 0.5 |
| [16] | Using dynamic features for automatic cervical precancer detection | R Viñals | 2021 | Smartphone | Leave-one-out cross validation | Cameroon and Switzerland | Negative: Histopathology Positive: Histopathology | Number of patients: 44 patients Number of images per patient: 120 sequential images Number of images used for classifying one patient: 120 Training and test sets (sample size): 44 patients Each fold: 43 patients used for training and 1 for testing | 15 negative (12 normal and 3 CIN1) and 29 positive (11 CIN2 and 18 CIN3) Prevalence: 0.66 |
| [17] | Evaluation of a new dataset for visual detection of cervical precancerous lesions | Y Zhang | 2022 | Eva system (smartphone with auxiliary lens) | 5-fold cross validation | 42 countries in North America, Africa, Asia, and Latin America | EVA dataset b | ||
| Negative: Histopathology Positive: Histopathology | Number of patients: 544 patients Number of images per patient: 2.46 images per patient on average (1342 images in total) Number of images used for classifying one patient: 1 Training and validation sets: 435 patients Each fold: 348 for training and 87 for validation Test set (sample size): 109 patients | 132 positive (315 images): 95 CIN2 (242 images), 32 CIN3 (67 images) and 5 cancer (6 images) 412 negative (1027 images): 206 normal (520 images) and 199 CIN1 (507 images) Prevalence (at image level): 0.23 Prevalence (at patient level): 0.24 | |||||||
| [18] | Cervical lesion classification method based on cross-validation decision fusion method of vision transformer and DenseNet | P Li | 2022 | Colposcope | 5-fold cross validation | China | Negative: Histopathology Positive: Histopathology | Number of patients: 732 patients Number of images per patient: 3.43 images per patient on average (2512 images in total) Number of images used for classifying one patient: 1 Training and validation set: 632 patients (2412 images) Each fold: 1930 images for training and 482 for validation Test set (sample size): 100 patients (100 images) | 375 positive (1403 images): 324 CIN2+ (1223 images) and 51 cancer (180 images) 357 negative (1109 images): 175 normal (534 images) and 182 CIN1 (575 images) Prevalence (at image level): 0.56 Prevalence (at patient level): 0.49 |
| Classifiers | Images Used for Classification | Mean Accuracy | Mean Sensitivity | Mean Specificity | |
|---|---|---|---|---|---|
| [8] | AdaBoost classifier. Multi-feature descriptors are used combining a pyramid histogram of oriented gradients (PHOG), the pyramid color histogram in L∗A∗ B space (PLAB) and the pyramid histogram of local binary pattern (PLBP) a | 1 postacetic acid image | 0.803 | 0.864 | 0.742 |
| [9] | 7 models are proposed a | ||||
| ✔ | (i) Random forest (RF) | 1 postacetic acid image | 0.800 | 0.841 | 0.759 |
| (ii) Gradient boosting decision tree (GBDT) | 1 postacetic acid image | 0.786 | 0.820 | 0.751 | |
| (iii) AdaBoost | 1 postacetic acid image | 0.768 | 0.777 | 0.759 | |
| (iv) Support vector machines (SVM) | 1 postacetic acid image | 0.748 | 0.765 | 0.730 | |
| (v) Logistic regression (LR) | 1 postacetic acid image | 0.742 | 0.762 | 0.722 | |
| (vi) Multilayer perceptron (MLP) | 1 postacetic acid image | 0.753 | 0.778 | 0.728 | |
| (vii) k-Nearest Neighbors (kNN) | 1 postacetic acid image | 0.709 | 0.751 | 0.667 | |
| [10] | Several classifiers are analyzed. The sensitivity, specificity and accuracy are only specified for few of them a | ||||
| ✔ | (i) Fine-tuned CaffeNet-based CNN (network adapted from Alexnet [24] with softmax classifier pretrained with ImageNet | 1 postacetic acid image | 0.784 | 0.809 | 0.759 |
| (ii) Support vector machines (SVM) using hand-crafter pyramidal features (PLBP, PLAB and PHOG). | 1 postacetic acid image | 0.772 | 0.786 | 0.758 | |
| (iii) Support vector machines (SVM) using features extracted with a CaffeNet (network adapted from Alexnet [24]) and one fully-connected layer | 1 postacetic acid image | 0.660 | 0.651 | 0.670 | |
| (iv) Support vector machines (SVM) using features extracted with a CaffeNet (network adapted from Alexnet [24]) and two fully-connected layers | 1 postacetic acid image | 0.691 | 0.696 | 0.687 | |
| (v) Fined-tuned support vector machines (SVM) using features extracted with a CaffeNet and one fully-connected layer | 1 postacetic acid image | 0.742 | 0.754 | 0.730 | |
| (vi) Fined-tuned support vector machines (SVM) using features extracted with a CaffeNet and two fully-connected layers | 1 postacetic acid image | 0.746 | 0.765 | 0.728 | |
| (vii) Fined-tuned AdaBoost classifier using features extracted with a CaffeNet and two fully-connected layers | 1 postacetic acid image | 0.774 | 0.809 | 0.739 | |
| [11] | Faster R-CNN architecture [25]. | 1 postacetic acid image | 0.832 | 0.930 | 0.830 |
| [12] | 4 different models. | ||||
| (i) CNN with two convolutional layers. Automatic feature extraction. | 1 postacetic acid image | 0.682 | 0.597 | 0.774 | |
| (ii) CNN with three convolutional layers. Automatic feature extraction. | 1 postacetic acid image | 0.703 | 0.723 | 0.683 | |
| (iii) ANN with one hidden layer. Hand-crafted features. | 1 postacetic acid image | 0.729 | 0.690 | 0.768 | |
| ✔ | (iv) ANN with two hidden layers. Hand-crafted features. | 1 postacetic acid image | 0.771 | 0.752 | 0.780 |
| [13] | 2 networks used. | ||||
| ✔ | (i) Inception-Resnet-v2 (modified version of the Inception-v3 model) [26] | 1 postacetic acid image | 0.693 | 0.667 | 0.706 |
| (ii) Resnet-152 (updated version of the Resnet model) [27] | 1 postacetic acid image | 0.689 | 0.667 | 0.699 | |
| [14] | Faster R-CNN architecture [25] b. | 1 postacetic acid image | AUC = 0.87 (95% CI 0.81–0.92) | ||
| [15] | Algorithms based on VGG16 [28] | ||||
| (i) Network model that uses VGG16 to extract the features of postacetic acid test colposcopy images | 1 postacetic acid image | 0.660 | 0.647 | 0.675 | |
| (ii) Network model that uses VGG16 to extract the features of preacetic acid test and postacetic acid test colposcopy images | 1 preacetic acid and 1 postacetic acid image | 0.717 | 0.728 | 0.707 | |
| (iii) Network model that uses VGG16 to extract the features of registered preacetic acid test and postacetic acid test colposcopy images | 1 preacetic acid and 1 postacetic acid image | 0.767 | 0.755 | 0.774 | |
| ✔ | (iv) Network model that uses VGG16 to extract the features of registered preacetic acid test and postacetic acid test cervical images (after cervical region extraction). | 1 preacetic acid and 1 postacetic acid image | 0.863 | 0.841 | 0.898 |
| [16] | Pixel-wise classification using an ANN with one hidden layer and combined with region growing segmentation. | 120 images during VIA | 0.886 | 0.897 | 0.867 |
| [17] | 3 models are proposed. | ||||
| (i) LeNet [29] | 1 postacetic acid image | 0.609 | 0.265 | 0.717 | |
| (ii) CaffeNet (network adapted from Alexnet [24]) | 1 postacetic acid image | 0.624 | 0.280 | 0.733 | |
| (iii) Pretrained VGG16 [28] trained on | |||||
| ✔ | (a) 16 top layers | 1 postacetic acid image | 0.676 | 0.459 | 0.744 |
| (b) 12 top layers | 1 postacetic acid image | 0.632 | 0.392 | 0.708 | |
| (c) 8 top layers | 1 postacetic acid image | 0.582 | 0.223 | 0.696 | |
| (d) 4 top layers | 1 postacetic acid image | 0.585 | 0.251 | 0.691 | |
| [18] | 2 models are proposed. | ||||
| (i) DenseNet161 [30] with EfficientNetV2 [31] | 1 postacetic acid image | 0.740 | 0.774 | 0.702 | |
| ✔ | (ii) DenseNet161 [30] with ViT | 1 postacetic acid image | 0.740 | 0.792 | 0.681 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Viñals, R.; Jonnalagedda, M.; Petignat, P.; Thiran, J.-P.; Vassilakos, P. Artificial Intelligence-Based Cervical Cancer Screening on Images Taken during Visual Inspection with Acetic Acid: A Systematic Review. Diagnostics 2023, 13, 836. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics13050836
Viñals R, Jonnalagedda M, Petignat P, Thiran J-P, Vassilakos P. Artificial Intelligence-Based Cervical Cancer Screening on Images Taken during Visual Inspection with Acetic Acid: A Systematic Review. Diagnostics. 2023; 13(5):836. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics13050836
Chicago/Turabian StyleViñals, Roser, Magali Jonnalagedda, Patrick Petignat, Jean-Philippe Thiran, and Pierre Vassilakos. 2023. "Artificial Intelligence-Based Cervical Cancer Screening on Images Taken during Visual Inspection with Acetic Acid: A Systematic Review" Diagnostics 13, no. 5: 836. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics13050836