
A Comprehensive Assessment of XGBoost Algorithm for Landslide Susceptibility Mapping in the Upper Basin of Ataturk Dam, Turkey


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Study Area Characteristics and the Datasets
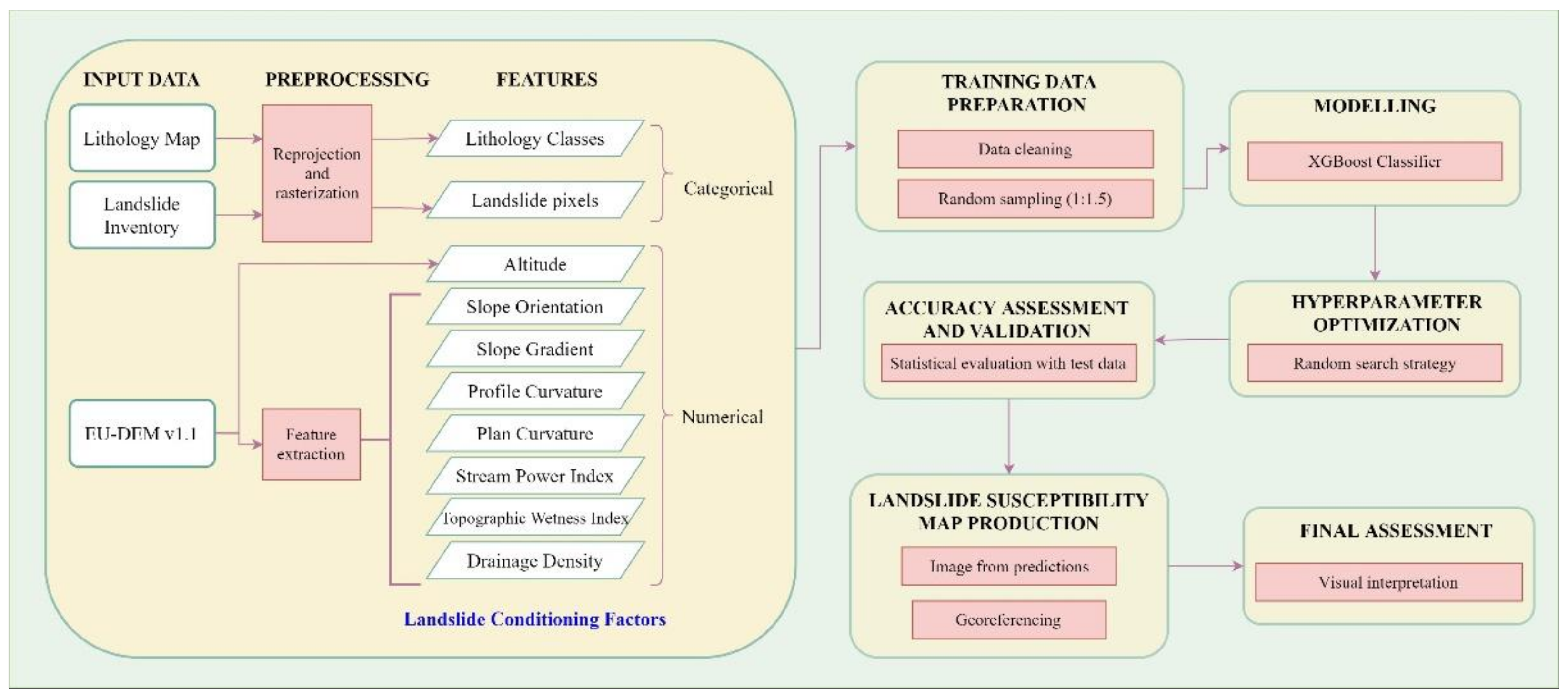
3.2. Methodology
3.2.1. Data Preprocessing
3.2.2. Modeling with XGBoost and Hyperparameter Optimization
- T: the number of leaves in the tree;
- w: the score of each leaf;
- the regularization degrees.
3.2.3. Accuracy Assessment and Validation
4. Results
4.1. Topographic Derivatives
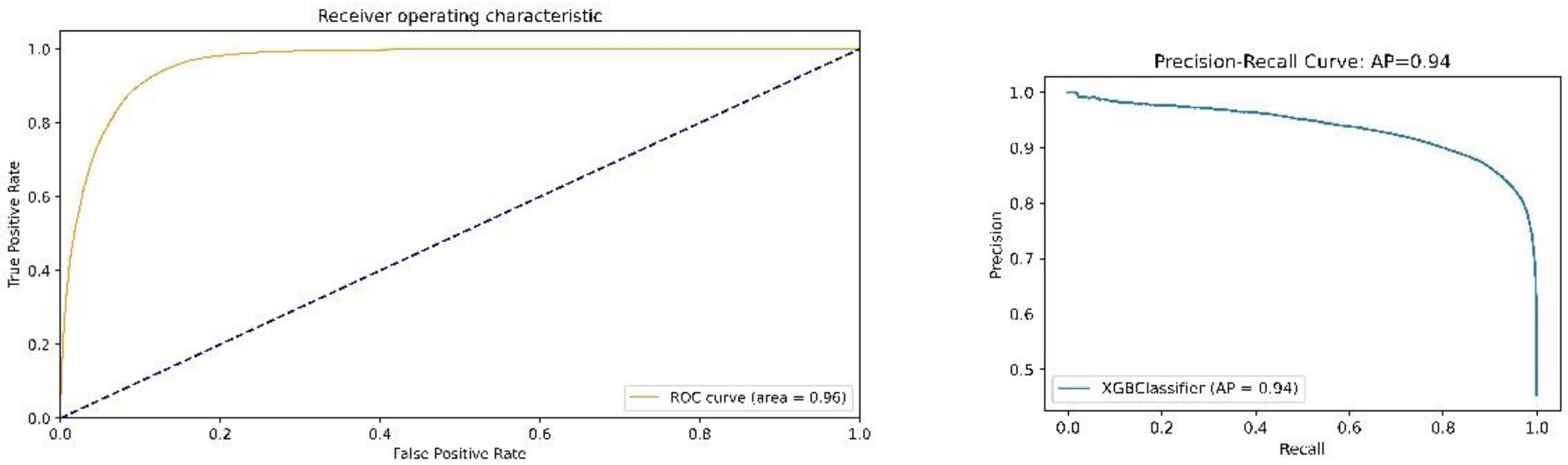
4.2. Prediction Performance Results
4.3. LS Map
5. Discussions
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- United Nations Sustainable Development Goals SDG Indicators. E/CN.3/2020/2. Available online: https://unstats.un.org/sdgs/indicators/indicators-list/ (accessed on 4 March 2021).
- AFAD. Afet ve Acil Durum Yönetimi Baskanligi Afet Yönetimi Kapsaminda 2019 Yilina Bakis ve Doga Kaynakli Olay Istatistikleri; Technical Report, AFAD, Ankara, Turkey: 7 July 2020. Available online: https://www.afad.gov.tr/kurumlar/afad.gov.tr/e_Kutuphane/Kurumsal-Raporlar/Afet_Istatistikleri_2020_web.pdf (accessed on 4 March 2021).
- Cetin, H.; Laman, M.; Ertunc, A. Settlement and slaking problems in the world’s fourth largest rock-fill dam, the Ataturk Dam in Turkey. Eng. Geol. 2000, 56, 225–242. [Google Scholar] [CrossRef]
- Akbaş, B.; Akdeniz, N.; Aksay, A.; Altun, İ.; Balcı, V.; Bilginer, E.; Bilgiç, T.; Duru, M.; Ercan, T.; Gedik, İ.; et al. Turkey Geological Map; Mineral Research & Exploration General Directorate: Ankara, Turkey, 2016. [Google Scholar]
- MTA Yerbilimleri Harita Goruntuleyici ve Cizim Editorü. Available online: http://yerbilimleri.mta.gov.tr/ (accessed on 4 March 2021).
- Yanar, T.; Kocaman, S.; Gokceoglu, C. Use of Mamdani Fuzzy Algorithm for Multi-Hazard Susceptibility Assessment in a Developing Urban Settlement (Mamak, Ankara, Turkey). ISPRS Int. J. Geo-Inf. 2020, 9, 114. [Google Scholar] [CrossRef] [Green Version]
- Kocaman, S.; Gokceoglu, C. Possible contributions of citizen science for landslide hazard assessment. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 295–300. [Google Scholar] [CrossRef] [Green Version]
- Kocaman, S.; Gokceoglu, C. A CitSci app for landslide data collection. Landslides 2019, 16, 611–615. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XG Boost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining-KDD, San Francisco, CA, USA, 13–17 August 2016; ACM Press: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- European Environment Agency. Copernicus Land Monitoring Service-Reference Data: EU-DEM, Factsheet, May. Available online: https://land.copernicus.eu/user-corner/publications/eu-dem-flyer/at_download/file (accessed on 23 February 2021).
- Copernicus Land Monitoring Service. 2021. Available online: https://land.copernicus.eu/ See also: https://land.copernicus.eu/imagery-in-situ/eu-dem/eu-dem-v1.1/view (accessed on 4 March 2021).
- Nefeslioglu, H.A.; Gokceoglu, C.; Sonmez, H. An assessment on the use of logistic regression and artificial neural networks with different sampling strategies for the preparation of landslide susceptibility maps. Eng. Geol. 2008, 97, 171–191. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C. Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat. Hazards 2012, 63, 965–996. [Google Scholar] [CrossRef]
- Regmi, N.R.; Giardino, J.R.; McDonald, E.V.; Vitek, J.D. A comparison of logistic regression-based models of susceptibility to landslides in western Colorado, USA. Landslides 2014, 11, 247–262. [Google Scholar] [CrossRef]
- Sevgen, E.; Kocaman, S.; Nefeslioglu, H.A.; Gokceoglu, C. A Novel Performance Assessment Approach Using Photogrammetric Techniques for Landslide Susceptibility Mapping with Logistic Regression, ANN and Random Forest. Sensors 2019, 19, 3940. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Zhang, S.; Li, R.; Shahabi, H. Performance evaluation of the GIS-based data mining techniques of best-first decision tree, random forest, and naïve Bayes tree for landslide susceptibility modeling. Sci. Total Environ. 2018, 644, 1006–1018. [Google Scholar] [CrossRef]
- Mutlu, B.; Nefeslioglu, H.A.; Sezer, E.A.; Akcayol, M.A.; Gokceoglu, C. An experimental research on the use of recurrent neural networks in landslide susceptibility mapping. ISPRS Int. J. Geo-inf. 2019, 8, 578. [Google Scholar] [CrossRef] [Green Version]
- Ozer, B.C.; Mutlu, B.; Nefeslioglu, H.A.; Sezer, E.A.; Rouai, M.; Dekayir, A.; Gokceoglu, C. On the use of hierarchical fuzzy inference systems (HFIS) in expert-based landslide susceptibility mapping: The central part of the Rif Mountains (Morocco). Bull. Eng. Geol. Environ. 2020, 79, 551–568. [Google Scholar] [CrossRef]
- Karakas, G.; Can, R.; Kocaman, S.; Nefeslioglu, H.A.; Gokceoglu, C. Landslide susceptibility mapping with random forest model for Ordu, Turkey. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1229–1236. [Google Scholar] [CrossRef]
- Karakas, G.; Kocaman, S.; Gokceoglu, C. Aerial photogrammetry and machine learning based regional landslide susceptibility assessment for an earthquake prone area in Turkey. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021. accepted. [Google Scholar]
- Kocaman, S.; Tavus, B.; Nefeslioglu, H.A.; Karakas, G.; Gokceoglu, C. Evaluation of Floods and Landslides Triggered by a Meteorological Catastrophe (Ordu, Turkey, August 2018) Using Optical and Radar Data. Geofluids 2020, 2020. [Google Scholar] [CrossRef]
- Fang, Z.; Wang, Y.; Peng, L.; Hong, H. Integration of convolutional neural network and conventional machine learning classifiers for landslide susceptibility mapping. Comput. Geosci. 2020, 139, 104470. [Google Scholar] [CrossRef]
- Achour, Y.; Pourghasemi, H.R. How do machine learning techniques help in increasing accuracy of landslide susceptibility maps? Geosci. Fron. 2020, 11, 871–883. [Google Scholar] [CrossRef]
- Chen, W.; Chen, X.; Peng, J.; Panahi, M.; Lee, S. Landslide susceptibility modeling based on ANFIS with teaching-learning-based optimization and Satin bowerbird optimizer. Geosci. Fron. 2021, 12, 93–107. [Google Scholar] [CrossRef]
- Chang, S.K.; Lee, D.H.; Wu, J.H.; Juang, C.H. Rainfall-based criteria for assessing slump rate of mountainous highway slopes: A case study of slopes along Highway 18 in Alishan, Taiwan. Eng. Geol. 2011, 118, 63–74. [Google Scholar] [CrossRef]
- Lin, H.M.; Chang, S.K.; Wu, J.H.; Juang, C.H. Neural network-based model for assessing failure potential of highway slopes in the Alishan, Taiwan Area: Pre-and post-earthquake investigation. Eng. Geol. 2009, 104, 280–289. [Google Scholar] [CrossRef]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.T.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth-Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Pradhan, A.M.S.; Kim, Y.-T. Rainfall-Induced Shallow Landslide Susceptibility Mapping at Two Adjacent Catchments Using Advanced Machine Learning Algorithms. ISPRS Int. J. Geo-Inf. 2020, 9, 569. [Google Scholar] [CrossRef]
- Sahin, E.K. Comparative analysis of gradient boosting algorithms for landslide susceptibility mapping. Geocarto Int. 2020, 1–25. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Du, J.; Zhang, L.; Song, Y.; Sun, G. Multi-geohazards susceptibility mapping based on machine learning—A case study in Jiuzhaigou, China. Nat. Hazards 2020, 102, 851–871. [Google Scholar] [CrossRef]
- Arabameri, A.; Chandra Pal, S.; Costache, R.; Saha, A.; Rezaie, F.; Seyed Danesh, A.; Hoang, N.D. Perdition of gully erosion susceptibility mapping using novel ensemble machine learning algorithms. Geomat. Nat. Haz. Risk 2021, 12, 469–498. [Google Scholar] [CrossRef]
- Zhang, Y.; Ge, T.; Tian, W.; Liou, Y.A. Debris flow susceptibility mapping using machine-learning techniques in Shigatse area, China. Remote Sens. 2019, 11, 2801. [Google Scholar] [CrossRef] [Green Version]
- Mukul, M.; Srivastava, V.; Jade, S.; Mukul, M. Uncertainties in the shuttle radar topography mission (SRTM) Heights: Insights from the indian Himalaya and Peninsula. Sci. Rep. 2017, 7, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Sengör, A.M.C.; Yilmaz, Y. Tethyan evolution of Turkey: A plate tectonic approach. Tectonophysics 1981, 75, 181–241. [Google Scholar] [CrossRef]
- Ural, M.; Arslan, M.; Göncüoğlu, M.C.; Tekin, U.K.; Kürüm, S. Late Cretaceous arc and back-arc formation within the southern neotethys: Whole-rock, trace element and Sr-Nd-Pb isotopic data from basaltic rocks of the Yüksekova complex (Malatya-Elazığ, SE Turkey). Ofioliti 2015, 40, 57–72. [Google Scholar] [CrossRef]
- Karakas, G.; Nefeslioglu, H.A.; Kocaman, S.; Buyukdemircioglu, M.; Yurur, T.; Gokceoglu, C. Derivation of earthquake-induced landslide distribution using aerial photogrammetry: The January 24, 2020, Elazig (Turkey) earthquake. Landslides 2021, 1–17. [Google Scholar] [CrossRef]
- GDAL/OGR Contributors. GDAL/OGR Geospatial Data Abstraction Software Library, Open Source Geospatial Foundation. Available online: https://gdal.org (accessed on 3 March 2021).
- Jordahl, K.; Van den Bossche, J.; Fleischmann, M.; Wasserman, J.; McBride, J.; Gerard, J.; Tratner, J.; Perry, M.; Badaracco, A.G.; Farmer, C.; et al. Geopandas/Geopandas: V0.8.1 (Version V0.8.1). Zenodo 2020. Available online: http://0-doi-org.brum.beds.ac.uk/10.5281/zenodo.3946761 (accessed on 3 March 2021).
- Conrad, O.; Bechtel, B.; Bock, M.; Dietrich, H.; Fischer, E.; Gerlitz, L.; Wehberg, J.; Wichmann, V.; Böhner, J. System for Automated Geoscientific Analyses (SAGA) v. 2.1.4. Geosci. Model. Dev. 2015, 8, 1991–2007. [Google Scholar] [CrossRef] [Green Version]
- Gokceoglu, C.; Sonmez, H.; Nefeslioglu, H.A.; Duman, T.Y.; Can, T. The 17 March 2005 Kuzulu landslide (Sivas, Turkey) and landslide-susceptibility map of its near vicinity. Eng. Geol. 2005, 81, 65–83. [Google Scholar] [CrossRef]
- ESRI ArcGIS Software. Available online: https://www.esri.com/en-us/arcgis/about-arcgis/overview (accessed on 6 March 2021).
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modeling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Wilson, J.P.; Gallant, J.C. Terrain Analysis Principles and Applications; John Wiley and Sons Inc.: Hoboken, NJ, USA, 2000; ISBN 978-0-471-32188-0. [Google Scholar]
- Friedman, J. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Nielsen, D. Tree Boosting with XGBoost-Why Does XGBoost Win “Every” Machine Learning Competition? Master’s Thesis, Department of Mathematical Sciences, Norwegian University of Science and Technology, Trondheim, Norway, 2016. Available online: https://ntnuopen.ntnu.no/ntnu-xmlui/bitstream/handle/11250/2433761/16128_FULLTEXT.pdf (accessed on 3 March 2021).
- Wang, C.; Deng, C.; Wang, S. Imbalance-XGBoost: Leveraging weighted and focal losses for binary label-imbalanced classification with XGBoost. Pattern Recogn. Let 2020, 136, 190–197. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. 10. Boosting and Additive Trees. In The Elements of Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 2009; pp. 337–384. ISBN 978-0-387-84858-7. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lundberg, S.; Lee, S. A Unified Approach to Interpreting Model Predictions. In NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems; ACM Press: New York, NY, USA, 2017; Volume 1705, pp. 4765–4774. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recogn. Let. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The Relationship between Precision-Recall and ROC Curves. In Proceedings of the 23rd international conference on Machine learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Piramuthu, S. Input data for decision trees. Expert Syst. Appl. 2008, 34, 1220–1226. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Mean | Std. Dev | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|
| DEM (m) | 1262.1 | 391.4 | 524.3 | 955.1 | 1255.8 | 1561.3 | 2431.6 |
| Landslide inventory (km2) | 0.51468 | 0.60711 | 0.01767 | 0.11635 | 0.23652 | 0.73473 | 3.43389 |
| ID | Lithological Units | Fi (%) | FLi (%) |
|---|---|---|---|
| 1 | Diorite | 0.231 | 0 |
| 2 | Undifferentiated | 1.214 | 0 |
| 3 | Non graded terrigenous clastics | 0.007 | 0 |
| 4 | Sheeted dyke complex | 1.520 | 0 |
| 5 | Neritic limestone | 12.547 | 34.146 |
| 6 | Terrigenous clastics | 1.403 | 9.949 |
| 7 | Volcanites and sedimentary rocks | 6.803 | 0.237 |
| 8 | Neritic limestone | 0.888 | 0 |
| 9 | Clastics and carbonates | 0.461 | 0.510 |
| 10 | Diorite, tonalite, monzonite, gabbro, etc. | 4.263 | 0.166 |
| 11 | Gneiss, schist | 32.699 | 2.352 |
| 12 | Pelagic limestone, clastics, radiolarite, chert, etc. | 5.491 | 23.573 |
| 13 | Basalt, spilite etc. | 1.545 | 0 |
| 14 | Carbonates and clastics (Upper Cretaceous—Eocene) | 0.156 | 0.985 |
| 15 | Clastics and carbonates (flysch) | 1.075 | 0.068 |
| 16 | Clastics and carbonates (Miocene) | 3.691 | 0.088 |
| 17 | Terrigenous clastics (Miocene) | 1.789 | 7.197 |
| 18 | Basalt (Upper Miocene) | 1.687 | 4.321 |
| 19 | Terrigenous clastics (Upper Miocene) | 0.328 | 0 |
| 20 | Marble | 3.008 | 0.131 |
| 21 | Undifferentiated basic and ultrabasic rocks | 6.485 | 1.720 |
| 22 | Terrigenous clastics (Pliocene) | 2.160 | 0.248 |
| 23 | Non graded terrigenous clastics (Pliocene-Quaternary) | 1.294 | 0 |
| 24 | Quartzite, quartz schist | 0.072 | 0 |
| 25 | Carbonates and clastics (Silurian Lower Devonian) | 0.296 | 0.329 |
| 26 | Pelagic limestone, radiolarite, chert clastics, etc. | 5.317 | 13.980 |
| 27 | Gabbro | 3.571 | 0 |
| Hyperparameter | Description | Value |
|---|---|---|
| subsample | Subsample ratio of the observations for each tree | 0.3 |
| reg_lambda | L2 regularization term | 3.0 |
| reg_alpha | L1 regularization term | 0.01 |
| n_estimators | Number of gradient boosted trees | 100 |
| min_child_weight | Minimum weight to create a new node | 5 |
| max_depth | Maximum depth of a tree | 10 |
| learning_rate | Shrinkage factor | 0.3 |
| gamma | Regularization term | 3 |
| colsample_bytree | Subsample ratio of features for each tree | 0.5 |
| Performance Metric | Equation | Equation Number |
|---|---|---|
| Precision | (7) | |
| Recall | (8) | |
| F1-Score | (9) | |
| Accuracy | (10) |
| Feature | Mean | Std.Dev | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|
| Slope Orientation (radian) | 3.292 | 1.791 | 0.000 | 1.898 | 3.156 | 4.951 | 6.283 |
| Drainage Density | 5.086 | 6.726 | 0.000 | 0.000 | 2.596 | 7.694 | 76.997 |
| Plan Curvature | 0.0001 | 0.0440 | −29.6834 | −0.0036 | 0.0001 | 0.0042 | 24.9625 |
| Profile Curvature | −0.0001 | 0.0023 | −0.1168 | −0.0009 | 0.0000 | 0.0009 | 0.0399 |
| Slope Gradient | 0.284 | 0.164 | 0.000 | 0.161 | 0.270 | 0.390 | 1.252 |
| SPI | 6593.0 | 45,812.1 | 0 | 394.6 | 1164.2 | 2894.0 | 5,984,523.5 |
| TWI | 7.166 | 2.583 | 2.445 | 5.670 | 6.466 | 7.707 | 26.575 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Non-Landslide | 0.93 | 0.90 | 0.92 | 31,070 |
| Landslide | 0.86 | 0.91 | 0.88 | 21,410 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Can, R.; Kocaman, S.; Gokceoglu, C. A Comprehensive Assessment of XGBoost Algorithm for Landslide Susceptibility Mapping in the Upper Basin of Ataturk Dam, Turkey. Appl. Sci. 2021, 11, 4993. https://0-doi-org.brum.beds.ac.uk/10.3390/app11114993
Can R, Kocaman S, Gokceoglu C. A Comprehensive Assessment of XGBoost Algorithm for Landslide Susceptibility Mapping in the Upper Basin of Ataturk Dam, Turkey. Applied Sciences. 2021; 11(11):4993. https://0-doi-org.brum.beds.ac.uk/10.3390/app11114993
Chicago/Turabian StyleCan, Recep, Sultan Kocaman, and Candan Gokceoglu. 2021. "A Comprehensive Assessment of XGBoost Algorithm for Landslide Susceptibility Mapping in the Upper Basin of Ataturk Dam, Turkey" Applied Sciences 11, no. 11: 4993. https://0-doi-org.brum.beds.ac.uk/10.3390/app11114993