1. Introduction
Cloud computing provides ubiquitous, convenient, and on-demand services and resources over the internet. A shared pool of configurable computing resources is used to provide these services. Services in cloud computing can be accessed and managed with less effort and fewer interactions [
1]. The world has become a global village with the use of the internet through remote access to services and hardware from distant locations. The services that are present over the internet are a revolution in the field of computing in this era. Complex jobs need more and more computational power to execute. Sophisticated and high-performance computing is needed to execute these jobs. Rather than purchasing new hardware, it is a better option to pay per use of services of high-performance computing hardware. Cloud service providers provide such facilities to users so they can access the resources and services by using a pay-per-use model [
2]. In the last few years, the number of cloud data centers has increased due to the suitability of storage and computation services for a large number of applications. The services of cloud computing are classified into three main categories, i.e., software as a service (SaaS), platform as a service (PaaS), and infrastructure as a service (IaaS) [
3]. Users have no geographical restrictions, i.e., they can access services from anywhere at any time [
4]. Cloud computing provides virtualized resources for handling various requests for different tasks [
5]. The infrastructure of a cloud data center usually consists of thousands of large computing hosts with high-speed computing resources.
A huge amount of data is generated every year; thus, a high processing power and storage capacity are required. Many scientific fields, such as astronomy, bioinformatics, meteorology, environmental science, and geological sciences, deal with large-scale data [
6]. The processing of the huge amounts of data generated by these scientific fields severely degrades the performance of clouds [
7]. It is a quite challenging task to ensure efficient task scheduling in cloud computing in order to improve the performance of the cloud. In a cloud computing environment, scheduling can be performed at different layers of service, i.e., IaaS, PaaS, and SaaS [
8]. Load balancing is used to distribute loads among available resources in a way that the overall load is balanced. The load balancing algorithm receives the requests and distributes user requests among available resources i.e., virtual machines (VMs). The task of the load balancer is to determine the load of available resources and distribute the load among resources. If resources are not utilized with a proper load balancing algorithm, the quality of service (QoS) will be degraded.
In this paper, we present an energy-efficient scheduling algorithm for workflow scheduling in cloud computing. The objective of the proposed algorithm is to reduce the energy consumption, makespan, with berrer load balancing. The proposed algorithm works in two phases, i.e., pre-processing and optimization with Particle Swarm Optimization (PSO). In the first phase, workflow tasks are placed in the respective queues according to the number of levels and length of the tasks. Thresholds are used to allocate resources to tasks to balance the load among resources. In the next phase, PSO is used to optimize scheduling and find better solutions. The paper is organized as follows.
Section 2 presents a literature review, followed by the presentation of the materials and methods in
Section 3.
Section 4 presents the results and a discussion. Finally,
Section 5 concludes the article.
2. Literature Review
Workflow scheduling and VM consolidation have been studied extensively in the literature. The scheduling of workflows in cloud environments has become popular due to the extensive applications in both scientific and business areas. Many task scheduling algorithms have been presented in various articles. The solutions consist of heuristic approaches, meta-heuristics, or a combination of both heuristics and meta-heuristics. In this section, we present a review of the different meta-heuristic methods for load balancing and workflow scheduling in cloud computing. There are also review articles with more details on resource allocation and scheduling.
The energy efficiency in cloud data centers has been widely studied. The authors of [
9] proposed an energy-efficient algorithm for reducing the energy consumption and improving the resource utilization in cloud data centers. The method is based on the classification of tasks and VMs in order to reduce scheduling time. The scheduling mechanism uses historical task scheduling data to classify user tasks and selects VM types accordingly. The algorithm targets resource utilization, energy consumption, and fault tolerance. The mechanism of merging the same task types minimizes the mean response time and reduces the overall energy consumption. Gill et al. [
10] proposed an algorithm called BULLET for scheduling workflows. The algorithm is based on PSO, and it schedules workloads in cloud computing by using QoS metrics according to the user’s requirements. QoS requirement metrics are established and the weight of each service is mentioned, such as the consumed energy, execution time, and execution cost. When the user asks for QoS, the services are checked in terms of their QoS metrics and a weight is calculated according to the demands. A workload analyzer analyzes the loads of different workloads and checks whether a workload is feasible for porting to the cloud. When a workload is feasible, it is submitted to the workload manager. The workload manager analyzes the workload characteristics described by the QoS metrics for clustering. The K-Means clustering algorithm is used for clustering. Resource information metrics include information on the available resources, such as the CPU, memory, resource cost, number of resources, and types of resources. The resource provisioner provides the available resources and, finally, the resource scheduler executes the workload on the provisioned resources. Workflow scheduling using hybrid GA-PSO in cloud computing was presented in [
11]. GA-PSO starts with random chromosomes to generate the initial population and defines the number of iterations for which to execute the workflow tasks in the cloud. The initial population is processed using the basic operators of the GA, i.e., selection, crossover, and mutation, in order to find the fittest chromosomes. The fittest chromosomes are passed to the PSO algorithm as the initial population. The number of iterations is equally divided between the GA and PSO, i.e., if the number of iterations in GA-PSO is n, then n/2 iterations are processed with GA, and the second half is processed by PSO. In the end, the fittest particles are selected as the solution to the workflow problem. Decreasing the number of initial populations decreases the complexity of the algorithm. Another technique for task scheduling based on a two-way strategy was proposed in [
12]. In the initial phase, the algorithm applies a Bayes classifier in order to classify tasks using historical scheduling data. Pre-created VMs are used to process the tasks. In case the classification does not match with the pre-created VMs, the method creates a specified number of VMs according to the classification of the tasks. Pre-created VMs are used to save time during the scheduling phase. In the second phase, task requirements are matched with VMs and scheduled dynamically. The proposed task scheduling method shows more accuracy and consumes less energy compared to the standard methods, i.e., Min-min and Max-min. The authors of [
13] proposed a hybrid technique to tackle the problem of workflow scheduling. The problem was considered as a multi-objective optimization considering the cost, makespan, and load balancing as measurement parameters. PSO was used for optimization. In the first phase, pre-processing was used, followed by optimization. The proposed algorithm was validated with comparative experimental results.
The authors of [
14] presented a novel solution for VM allocation in cloud data centers. The method was based on the Krill Herd algorithm. The algorithm uses VM aggregation and host shutdown for power management. During this process, QoS is maintained. Efficient integration and the selection of convenient VM migration strategies reduce energy consumption. The results showed that the proposed method reduced energy consumption compared to other algorithms. A scheduling solution based on a non-linear mixed-integer programming model was presented in [
15]. The proposed mechanism makes a tradeoff between execution time and energy consumption during the resource allocation phase. A backward technique is applied to adjust task scheduling and achieve the desired goals. The experimental results showed that the proposed approach significantly reduced the computation time for large sizes of parallel applications. Attiqa et al. [
16] proposed a Multi-Objective Genetic Algorithm (MOGA) that was used to schedule workflows in cloud environments. The MOGA gave a solution that reduced the makespan and provided an energy-efficient solution in a cloud environment. The results of the proposed algorithm showed a significant enhancement in terms of budget, deadline, and energy consumption. The technique also improved resource utilization. Verma et al. [
17] proposed a Hybrid PSO (HPSO) method for minimizing the execution time and execution cost in cloud computing. The algorithm is a hybridization of the Budget and Deadline Constraint Heterogeneous Earliest Finish Time (BDHEFT) and multi-objective PSO. The HPSO optimizes the two contradictory parameters—makespan and cost—under the budget and deadline constraint. In addition to these two parameters, energy consumption is also considered as a parameter. The proposed algorithm gives a set of the best solutions, from which the user can select the best solution. In another study [
18], a parallel Genetic Algorithm (GA) was used to solve the multi-objective optimization problem of workflow scheduling. The makespan, cost, and load balancing were the targeted parameters. The proposed algorithm first calculates the best solution for each parameter in parallel, and then the best solution is found for all parameters. The proposed method was evaluated with comparative experimental results. Another algorithm that minimizes energy consumption and Service-Level Agreement Violations (SLAVs) during VM consolidation was proposed in [
19]. The authors used an energy-aware VM consolidation algorithm that minimized SLAVs. The algorithm uses a fine-tuned prediction model for VM migration, CPU and memory utilization prediction, and target host selection. The proposed method was evaluated with the Planet Lab datasets. The comparative results showed that the proposed algorithm significantly reduced energy consumption and SLAVs. The authors of [
20] presented a technique for VM placement that was based on an improved permutation-based GA and a multidimensional resource-aware best-fit allocation strategy. The objective of the algorithm was to reduce energy consumption by reducing the active hosts. The comparative results showed that the proposed mechanism consumed less energy with fewer active hosts in comparison to other methods. Moreover, the proposed method also yielded better resource utilization and load balancing. Another technique based on prediction and dynamic resource-table-updating mechanisms was proposed in [
21]. The objective of the proposed method was energy efficiency in task scheduling. The algorithm considers the tasks’ arrival times and the sizes of the tasks for efficient scheduling. The results are computed in terms of the completion time and response time. The simulation results showed the efficiency of the proposed algorithm over the other techniques with which it was compared. The authors of [
22] proposed a task scheduling algorithm and workload classification architecture for VM placement in cloud data centers. The objectives of the technique were resource utilization and energy consumption. The proposed algorithm was validated with comparative experimental results. Cloud data centers demand a huge amount of energy, which changes at different hours of operation, together with the utilization of resources. A mechanism for handling the energy consumption in different operating hours was proposed in [
23]. The proposed technique uses frequency scaling and non-power-aware hosts to achieve the desired objectives. VM consolidation policies, i.e., the utilization of local regression minimization and static-threshold random selection, were used. The comparative results showed the improvements gained by the proposed method over the other methods with which it was compared. Ensuring the QoS in the presence of energy consumption is a challenge for cloud service providers. To address this issue, the authors of [
24] proposed an energy-efficient, QoS-aware algorithm for VM consolidation. The proposed algorithm was based on a Markov-chain-based prediction approach in order to measure the load of the hosts, i.e., to identify over-utilized and underutilized hosts. The linear weighted sum approach was used for VM selection and placement during migration. The algorithm targets QoS and energy consumption.
Techniques for energy efficiency suffer from the problem of performance degradation. To tackle this issue, thresholding is used to achieve a balance between the two parameters. The authors of [
25] proposed an energy-efficient algorithm for VM consolidation. The objectives of the method were energy efficiency and throughput. The workload of a host was considered in order to set thresholds for resource utilization and manage VM migrations. The proposed method performed well in terms of the desired parameters in comparison with other standard methods. In [
26], the authors proposed a scheduling algorithm based on the Deep Q-network (DQN) technique. The objectives of the method were the optimization of energy consumption and makespan. The tradeoff between the two parameters was used to optimize the problem and achieve the desired objectives. The dynamic behavior of the proposed algorithm according to different workload requirements was proved with experimental results. The results showed the effectiveness of the proposed algorithm in comparison to other methods. The authors of [
27] used bio-inspired heuristics for VM consolidation. A more desirable environment for cloud computing was considered on the basis of a larger capacity margin and a higher fitness value for the VMs and hosts, respectively. The comparative experimental results were shown to validate the performance of the proposed algorithm. The authors of [
28] proposed an algorithm that overcame the issues of load balancing and load scheduling. The algorithm worked with precision and privacy. The authors used a hybrid approach that could allocate tasks by using the Modified Canopy Fuzzy C-means Algorithm (MCFCMA). The algorithm allocates tasks to respective resources with the help of PSO. In the proposed technique, the load is based on the selected tasks, the cluster requests the tasks with the help of the MCFCMA, and it schedules these tasks for each VM. The feature value is calculated with the help of the PSO algorithm. The proposed technique minimizes the execution time, cost, and load. A scheduling algorithm that uses the Traveling Salesman Problem (TSP) solution strategy was proposed in [
29]. The algorithm first converts the problem into an instance of the TSP and then applies the solution to the problem. The method consists of three phases, i.e., clustering, conversion, and assignment. In the first phase, a large problem is divided into small-sized clusters. In the conversion phase, the problems are converted into an instance of the TSP. Finally, the clusters are scheduled to available resources in the assignment phase. The proposed technique was validated with comparative experimental results. Another algorithm for efficient resource utilization and energy consumption was proposed in [
30]. The proposed algorithm, i.e., ERES, dynamically allocates resources to workflow tasks according to the input tasks. The algorithm dynamically manages the server load, and live migration of the VMs is used to avoid overloaded and underloaded hosts. Simulation results were presented to validate the effectiveness of the proposed algorithm. FIMPSO is another algorithm for load balancing in a cloud computing environment [
31]. The hybridization of Firefly and PSO was used in the proposed algorithm. The Firefly algorithm is used to reduce the search space, whereas an improved, modified PSO is used to select the best responses during the resource allocation process. The resource utilization and response time are the targeted parameters of the proposed algorithm. Comparative experimental results were shown to validate the proposed algorithm.
Energy-efficient scheduling in the presence of other constraints, such as resource utilization and fault tolerance, is a challenging issue. There is a need to develop solutions that address the problem while considering these parameters. This paper presents a scheduling algorithm in order to address the above-mentioned problem. The proposed algorithm is based on task classification, queueing, and thresholds for allotting VMs to tasks and creating the necessary resources. Queuing is used to hold tasks with different intensities in order to reduce resource allocation time. Task classification is used to find suitable VMs in order to reduce the scheduling time. Thresholds are used to efficiently utilize cloud resources and reduce the failure ratio.
4. Results and Discussion
This section presents the experimental evaluation of the proposed algorithm. Benchmark workflows were used to validate the proposed algorithm [
33]. The datasets consist of different workflows with varying numbers of tasks and varying dependency levels. The datasets have been used to validate many scheduling algorithms in cloud environments.
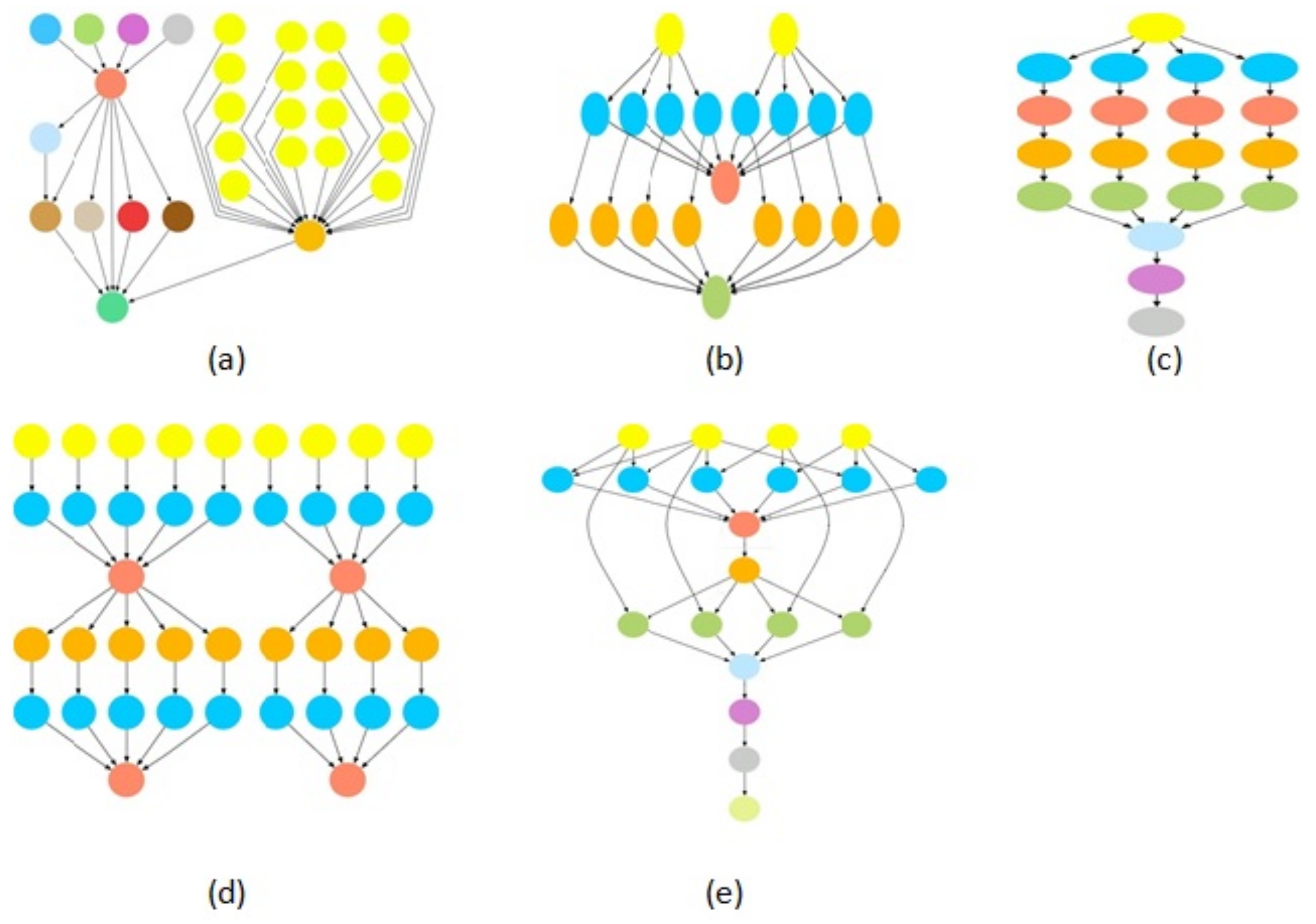
Table 1 and
Figure 1 show the details and structure of the workflows, respectively [
13].
Standard algorithms, i.e., GA and PSO, were used in the comparison as a baseline. Specialized schedulers [
30,
31] were also included in the comparison. The algorithms were selected based on their relevance to the problem. The experiments were carried out on an Intel Core i3 processor equipped with 8 GB of memory running on the Ubuntu 16.04 operating system. The algorithms were evaluated in terms of makespan, energy consumption, and balancing degree. CloudSim [
34] was used to simulate the algorithms. The simulation was performed with 10 VMs and three data centers. VMs with different specifications were selected for simulation. Each VM was allocated 1000 MBs of memory and MIPS from 1500 to 3000. Processing, memory, storage, and transfer costs were set to 0.017, 0.05, 0.01, and 0.01, respectively. The GA was evaluated with a crossover probability of 0.8 and a mutation probability of 0.2. PSO was executed with the value of inertia weight factor
of 1.2, and the learning factors were set to 2. The other algorithms were executed with the parameters specified in the respective articles. Each experiment was repeated 20 times, and the average values were selected for comparison.
Table 2 shows the results of the proposed algorithm compared to those of the other algorithms. The proposed algorithm yielded better results for all parameters on all datasets. In comparison to the standard algorithms, i.e., PSO and GA, the proposed algorithm performed better and at higher rates than the specialized algorithms. In the specialized schedulers, ERES remained closest to the proposed algorithm in terms of energy consumption. In terms of makespan and load balance, FIMPSO remained close to the proposed algorithm on the majority of the datasets. For some datasets, the energy consumption of FIMPSO was better than that of ERES and was close to that of the proposed algorithm.
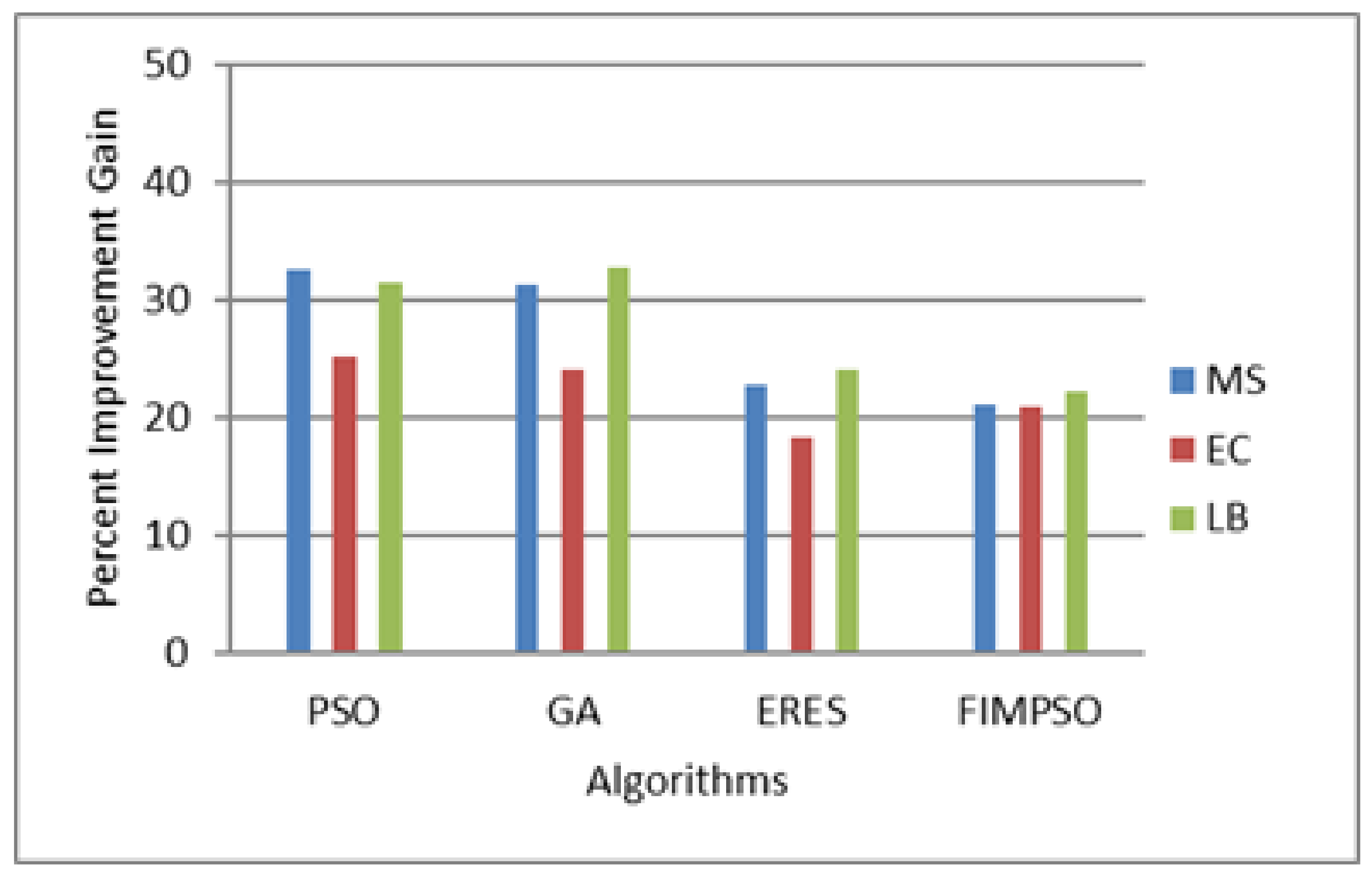
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 show the percent improvement gain of the proposed algorithm over the other algorithms. For the Montage dataset, in terms of makespan, the proposed algorithm achieved percent improvement gain of 32.60, 31.36, 22.8, and 21.18 over PSO, GA, ERES, and FIMPSO, respectively. For the same dataset, the improvement gains in terms of energy consumption over the compared methods were 25.1, 24.01, 18.35, and 20.99. In terms of load balance, the percent improvement gains of the proposed algorithm over PSO, GA, ERES, and FIMPSO were 31.55, 32.75, 24.13, and 22.22, respectively. The results are shown in
Figure 2.
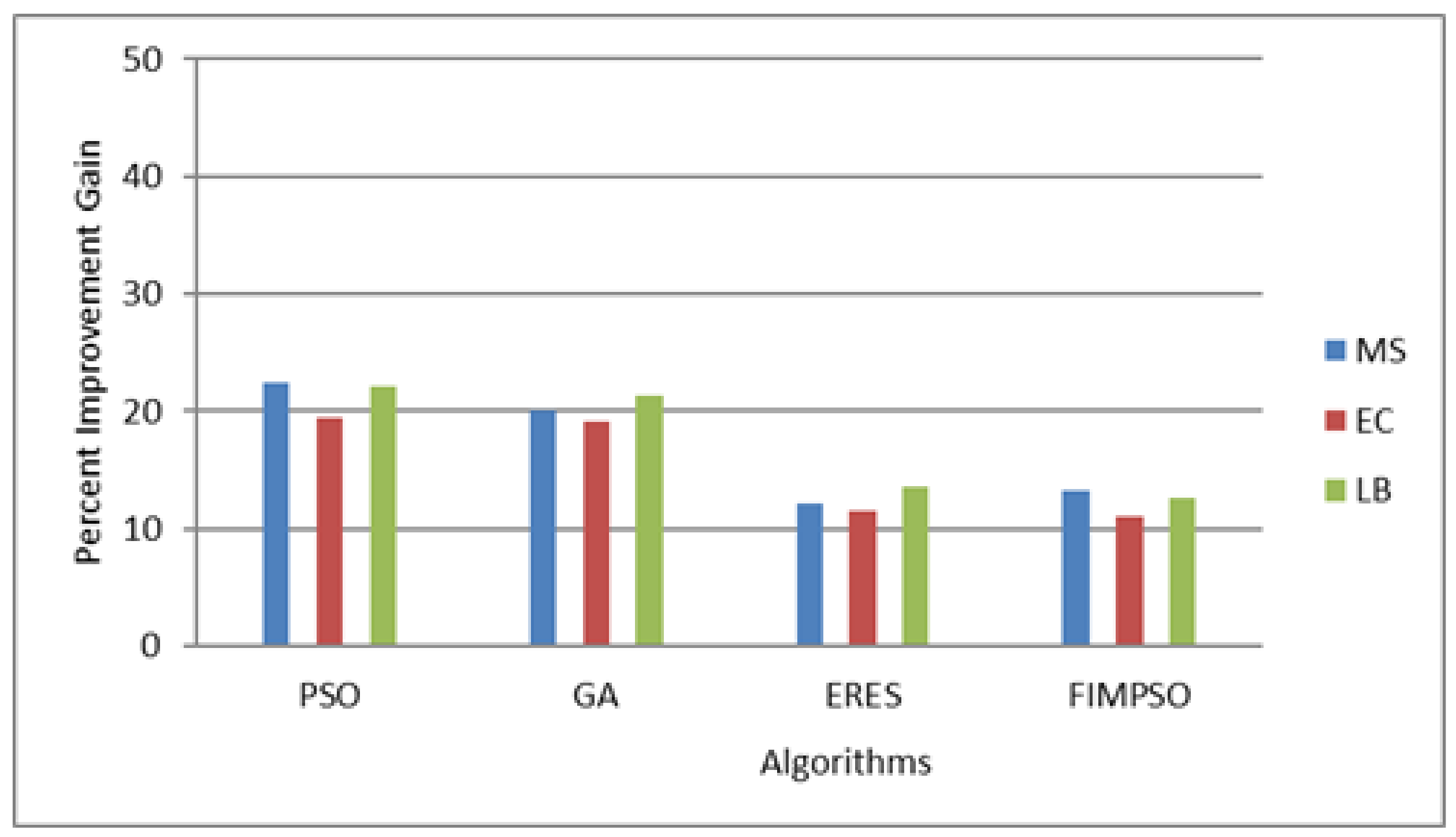
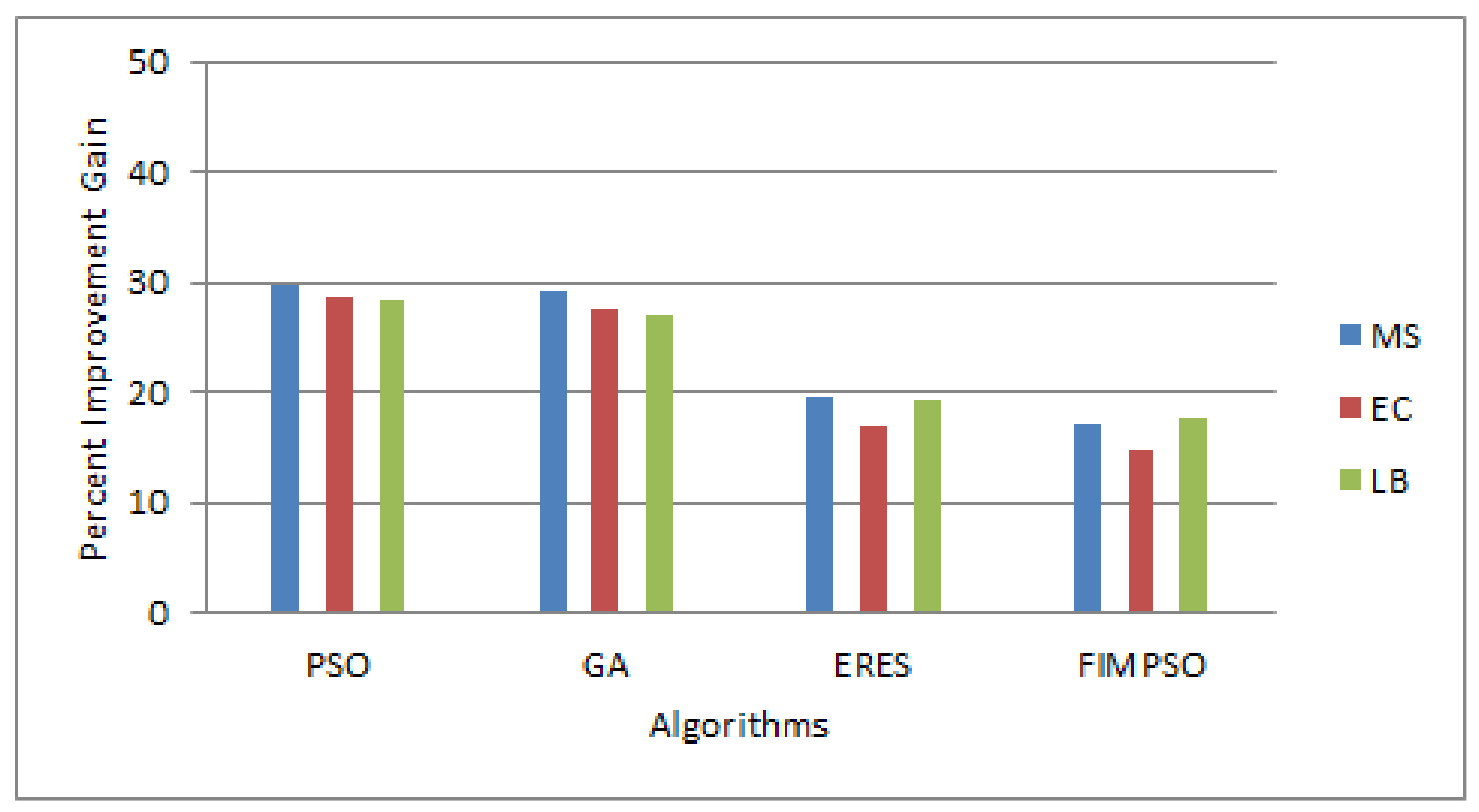
In the case of the Sipht dataset, the percent improvement gains in terms of makespan over PSO, GA, ERES, and FIMPSO were 22.41, 20.09, 12.15, and 13.21, respectively. In terms of energy consumption, the improvement gains of the proposed algorithm were 19.51, 19.14, 11.55, and 11.10 over PSO, GA, ERES, and FIMPSO. In terms of load balance, the proposed algorithm achieved percent improvement gains of 22.05, 21.28, 13.58, and 12.63 over the other algorithms.
Figure 3 shows the results of the percent improvement gains of the proposed algorithm over the other algorithms.
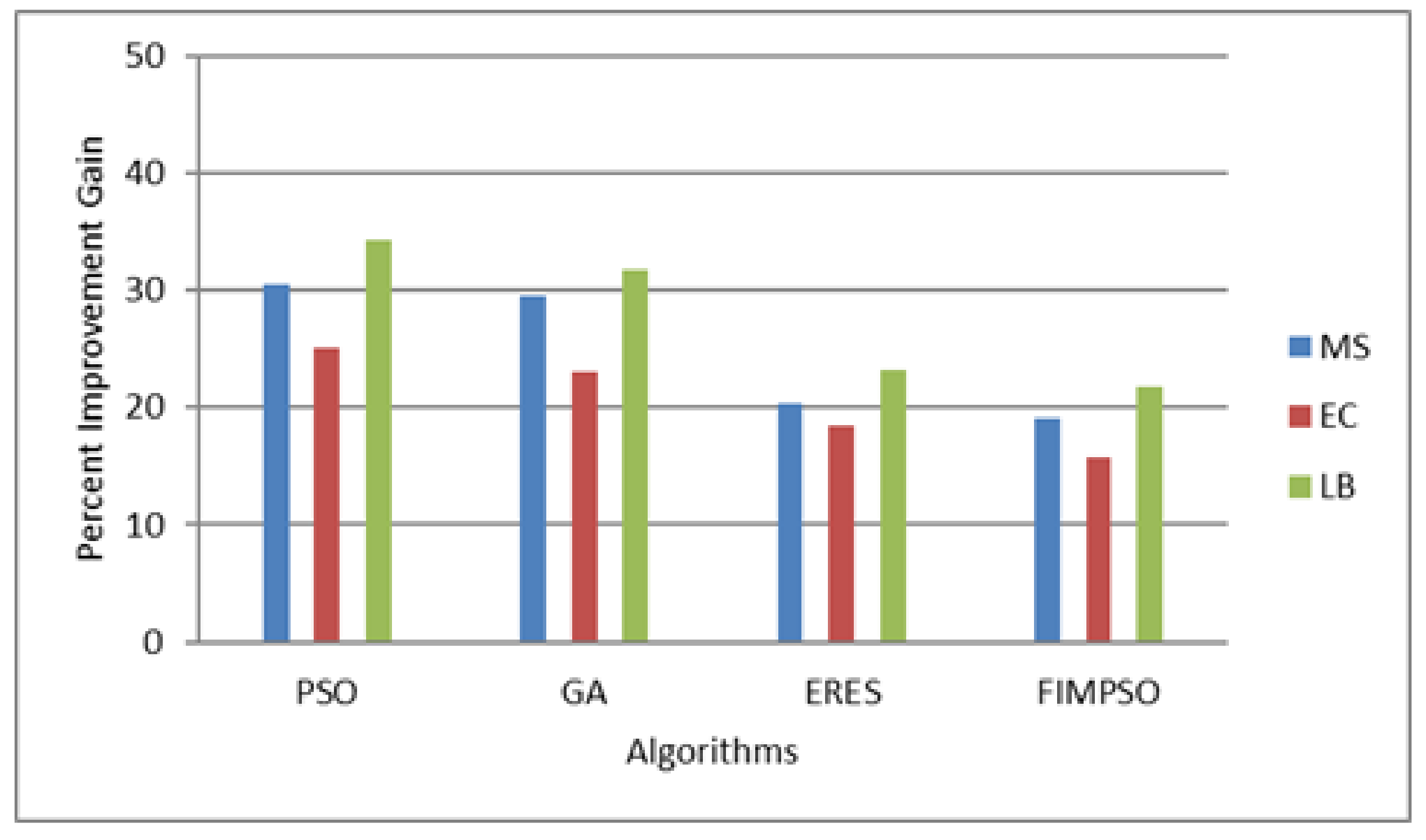
The proposed algorithm also achieved similar improvements compared to the other methods on the LIGO dataset.
Figure 4 shows the results for the LIGO dataset. The results show that the proposed algorithm achieved percent improvement gains of 30.46, 29.44, 20.28, and 19.14 in terms of makespan over the other methods. For the same dataset, the improvement gains in terms of energy consumption over the compared methods were 25.09, 22.97, 18.45, and 15.81. In terms of load balance, the improvement gains of the proposed algorithm over PSO, GA, ERES, and FIMPO were 34.32, 31.71, 32.26, and 21.71, respectively.
Figure 5 shows the results of the percent improvement gain of the proposed algorithm over the other algorithms for the CyberShake dataset. The improvement gains in terms of the makespan over the other methods for this dataset were 29.66, 29.17, 19.68, and 17.02. The improvement gains over PSO, GA, ERES, and FIMPSO in terms of energy consumption were 28.72, 27.56, 16.77, and 14.64, respectively. For the same dataset, the improvement gains in terms of load balance were 28.45, 26.97, 19.26, and 17.75 over PSO, GA, ERES, and FIMPSO, respectively.
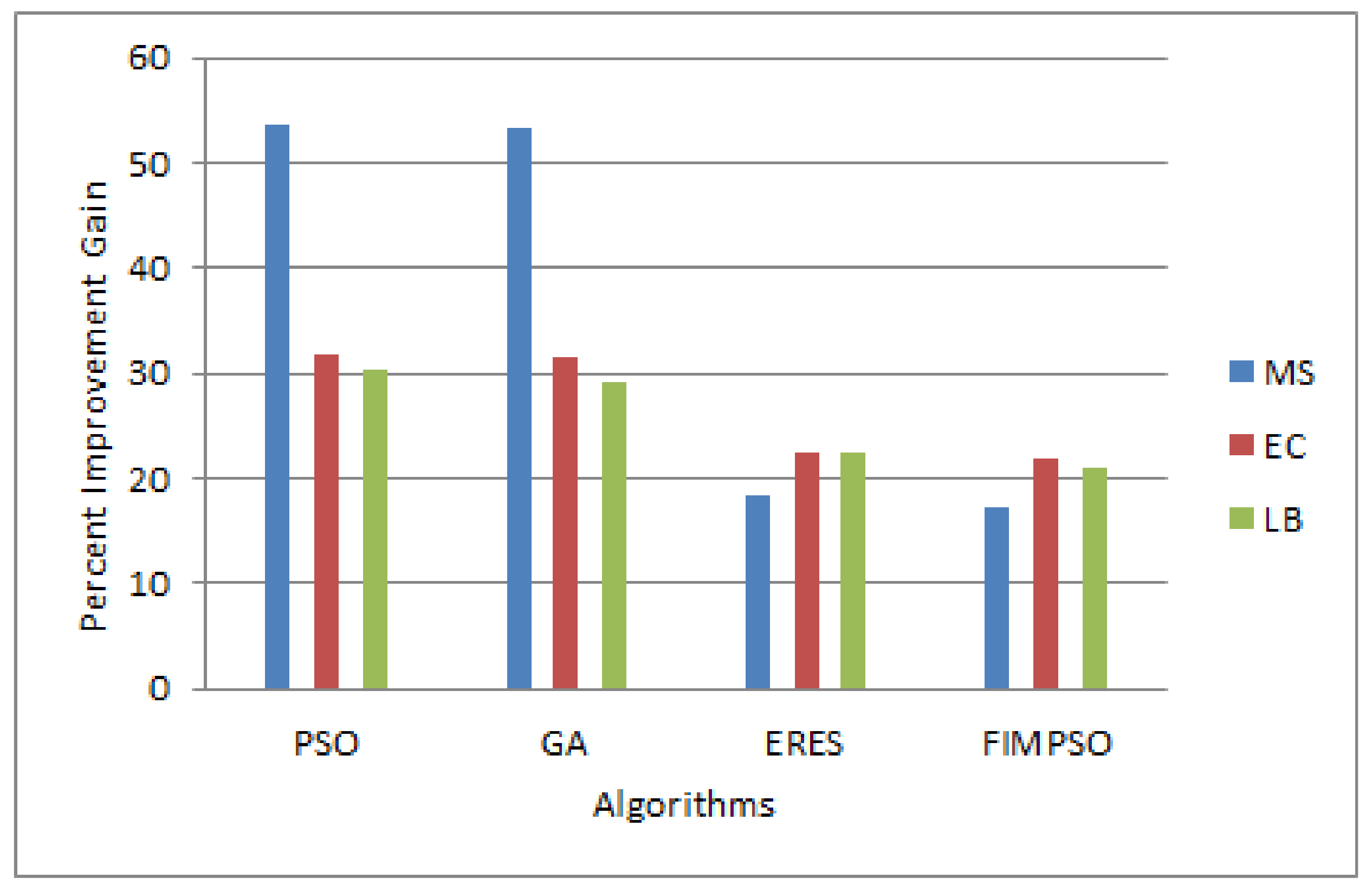
In the case of the Epigenomics datasets, the proposed algorithm achieved percent improvement gains of 53.55, 53.21, 18.27, and 17.30 over the other algorithms. In terms of the energy consumption, the proposed algorithm achieved percent improvement gains of 28.72, 27.56, 16.77, and 14.64 over PSO, GA, ERES, and FIMPSO, respectively. For the same dataset, the improvement gains of the proposed algorithm over the other methods in terms of load balance were 28.45, 26.97, 19.26, and 17.75.
Figure 6 shows the detailed results.
5. Conclusions
Cloud computing is a technology that is widely used in many domains, including scientific applications. Due to the large numbers of users and applications, cloud computing environments suffer from some issues. These issues include energy consumption, fault tolerance, user deadlines, etc. Scheduling and VM placement are techniques that are used to handle these issues. There are many solutions for scheduling cloud resources. This article addresses the problem of energy efficiency and resource utilization in cloud data centers. The proposed work is based on task classification, thresholds, and queueing. In the first phase, workflow tasks are placed in queues according to the number of levels and the execution times of the tasks. The tasks are classified accordingly, and resources are created. The proposed algorithm was validated on benchmark datasets, and comparative experimental results were presented in terms of the makespan, energy efficiency, and load balancing. The results were compared with those of standard algorithms and specialized schedulers. The results showed that the proposed algorithm achieved better results than those of the other methods in terms of all parameters. A percent improvement gain from 13 to 53 percent was achieved.
The issues of VM migration and adaptive thresholds require further investigation in order to further improve the solution and achieve better results. The scheduling problem consists of many parameters, but some parameters are contradictory. The designed solutions must consider effects on other parameters while improving the desired parameters. Security and privacy are examples of such parameters that need to be addressed, in addition to other parameters. The implementation of the simulated algorithm in actual environments will also bring challenges, such as the administration cost, energy consumed by factors other than computing, failures in hardware, and data backups.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}