
Identifying the Author Group of Malwares through Graph Embedding and Human-in-the-Loop Classification


Abstract
:1. Introduction
2. Related Work
3. Malware Graph Construction
3.1. Features
- Function: We define several operation codes from the gathered functions while statically analyzing binary files as static features. If the derivations reuse the exact code previously observed, the functions will be useful for classifying the malware as the same group [19]. Because using the whole plain text of the function is inefficient in terms of memory usage, we convert each function into a shortened fixed length value using a cryptographic hash function;
- Basic Block: We define the basic blocks of the operation codes from functions as static features. In the operation codes, each basic block is divided by a jump command. To prevent subdivision of the functions that occurred owing to such minor changes, we used the basic block as a feature, as well;
- Strings: We defined strings found in binary files as static features. Most strings are often meaningless for malware analysis. However, because of the possibility that the malware author’s habitual human behavior is reflected in the codes, strings can also be informative for the author group classification purpose [20];
- Imports and Exports: Some malware may also involve other files. During this process, the malware needs interfaces to call libraries and public methods. We define the processes as static features because they contain the names of the methods imported or exported. Because the names of the libraries are often consistent, this static feature is relatively effective against modification of the derivations [21].
- Mutexes: Mutexes are used as locking mechanisms for memory location. If the author groups or the original of the modified malware is the same, the names of the mutants are likely to be reused, as well [22]. Therefore, we defined mutexes as dynamic features.
- Networks: Each malware with a purpose will likely send some sort of report to the author or designated location. Locations, such as DNS, URLs, or IP addresses, are likely to be reused if the malware is in the same author group [23].
- Files: During the execution of the malware, certain patterns of read or write can be observed in the filesystem. Some patterns mimic benign programs patterns, and some may occur while processing the attack. Either case often occurs in the filesystem, and if the malware were developed by the same author group, the locations would likely be shared.
- Keys: There is a location called a registry where Microsoft Windows stores settings for the OS and other program files. As a means of malware attack, the authors often target the settings in this registry for certain purposes. Therefore, we defined the registry keys accessed or modified as a dynamic feature.
- Drops: Malware, such as Trojan, is designed to download a drop from the web to disguise detection. As the dropper is undetected, it can keep downloading the drop and keep the malware attack. If the dropper is part of the malware built by the same author group, there is a high possibility of reuse of the drop file, which can be considered as a dynamic feature.
3.2. Graph Construction with Feature Refinement
4. Graph-Based Classification with Human Engagement
4.1. Graph Embedding
4.2. Human-in-the-Loop Classification
4.2.1. Inter-Class Closeness
4.2.2. Intra-Class Closeness
4.2.3. Intervention of Human Experts
4.2.4. Implementation Details
5. Evaluation
5.1. Experimental Setting
5.2. Experimental Results
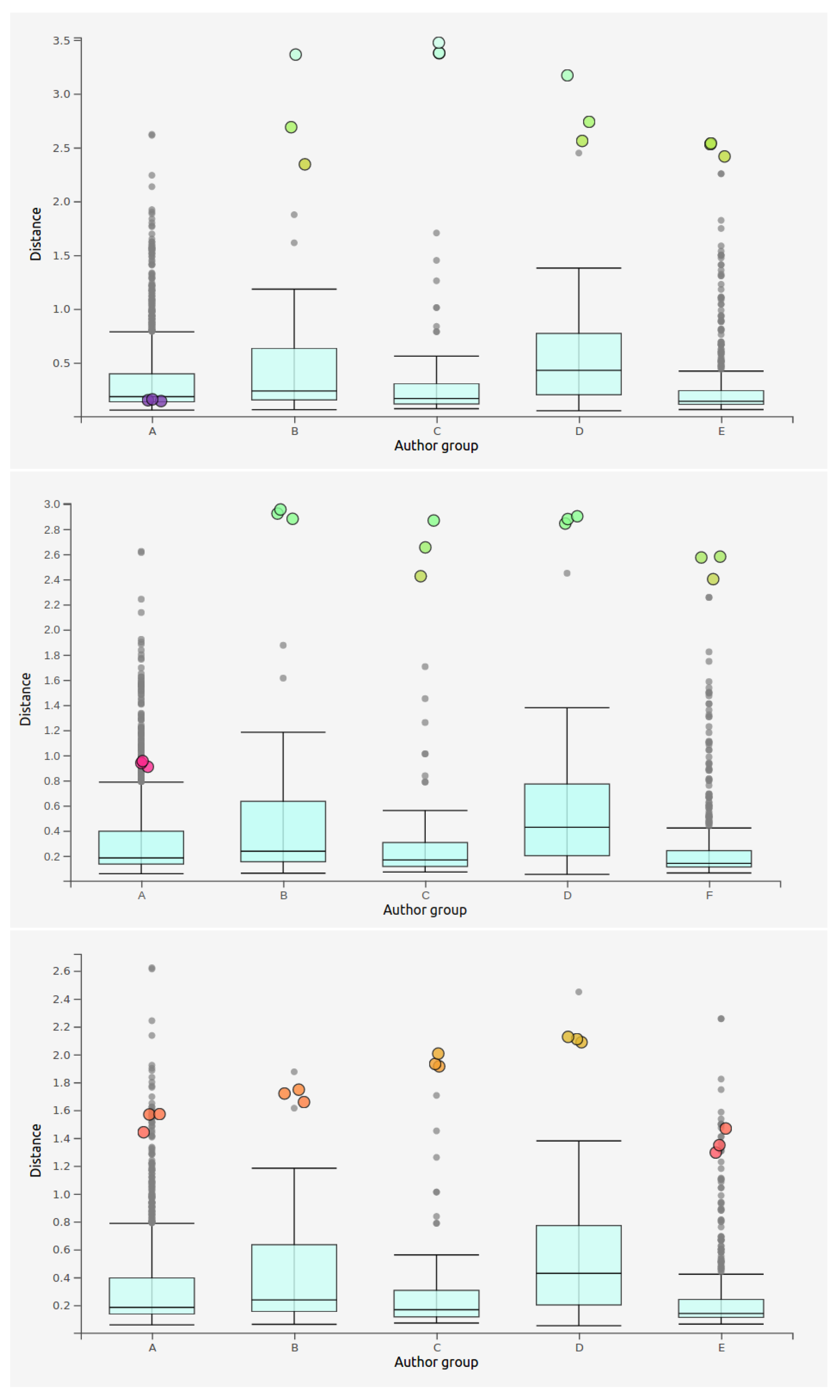
5.2.1. Effectiveness of Inter-Class Closeness
5.2.2. Effectiveness of Intra-Class Closeness
5.2.3. Effectiveness of Man-Machine Collaboration
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alabdulmohsin, I.; Han, Y.; Shen, Y.; Zhang, X. Content-agnostic malware detection in heterogeneous malicious distribution graph. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 2395–2400. [Google Scholar]
- Hong, J.; Park, S.; Kim, S.W.; Kim, D.; Kim, W. Classifying malwares for identification of author groups. Concurr. Comput. Pract. Exp. 2018, 30, e4197. [Google Scholar] [CrossRef]
- Souri, A.; Hosseini, R. A state-of-the-art survey of malware detection approaches using data mining techniques. Hum. Centric Comput. Inf. Sci. 2018, 8, 1–22. [Google Scholar] [CrossRef]
- Christodorescu, M.; Jha, S.; Seshia, S.A.; Song, D.; Bryant, R.E. Semantics-aware malware detection. In Proceedings of the 2005 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 8–11 May 2005; pp. 32–46. [Google Scholar]
- Cheng, S.M.; Ao, W.C.; Chen, P.Y.; Chen, K.C. On modeling malware propagation in generalized social networks. IEEE Commun. Lett. 2010, 15, 25–27. [Google Scholar] [CrossRef]
- Pitolli, G.; Aniello, L.; Laurenza, G.; Querzoni, L.; Baldoni, R. Malware family identification with birch clustering. In Proceedings of the 2017 International Carnahan Conference on Security Technology, Madrid, Spain, 23–26 October 2017; pp. 1–6. [Google Scholar]
- Rafique, M.Z.; Caballero, J. Firma: Malware clustering and network signature generation with mixed network behaviors. In International Workshop on Recent Advances in Intrusion Detection; Springer: Berlin/Heidelberg, Germany, 2013; pp. 144–163. [Google Scholar]
- Huang, W.; Stokes, J.W. MtNet: A multi-task neural network for dynamic malware classification. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, San Sebastián, Spain, 7–8 July 2016; pp. 399–418. [Google Scholar]
- Kong, D.; Yan, G. Discriminant malware distance learning on structural information for automated malware classification. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1357–1365. [Google Scholar]
- Plohmann, D.; Clauss, M.; Enders, S.; Padilla, E. Malpedia: A collaborative effort to inventorize the malware landscape. In Proceedings of the Botconf, Montpellier, France, 6–8 December 2017. [Google Scholar]
- Kreuk, F.; Barak, A.; Aviv-Reuven, S.; Baruch, M.; Pinkas, B.; Keshet, J. Deceiving end-to-end deep learning malware detectors using adversarial examples. arXiv 2018, arXiv:1802.04528. [Google Scholar]
- Yan, J.; Qi, Y.; Rao, Q. Detecting Malware with an Ensemble Method Based on Deep Neural Network; Security and Communication Networks: London, UK, 2018. [Google Scholar]
- Bhandai, S.; Panihar, R.; Naval, S.; Laxmi, V.; Zemmari, A.; Gaur, M.S. Sword: Semantic aware android malware detector. J. Inf. Secur. Appl. 2018, 42, 46–56. [Google Scholar]
- Bayer, U.; Comparetti, P.M.; Hlauschek, C.; Kruegel, C.; Kirda, E. Scalable, behavior-based malware clustering. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 8–11 February 2009; Volume 9, pp. 8–11. [Google Scholar]
- Islam, R.; Tian, R.; Batten, L.M.; Versteeg, S. Classification of malware based on integrated static and dynamic features. J. Netw. Comput. Appl. 2013, 36, 646–656. [Google Scholar] [CrossRef]
- Sneha, S.; Malathi, L.; Saranya, R. A survey on malware propagation analysis and prevention model. Int. J. Adv. Technol. 2015, 6, 1–4. [Google Scholar]
- Ronen, R.; Radu, M.; Feuerstein, C.; Yom-Tov, E.; Ahmadi, M. Microsoft malware classification challenge. arXiv 2018, arXiv:1802.10135. [Google Scholar]
- Ahmadi, M.; Ulyanov, D.; Semenov, S.; Trofimov, M.; Giacinto, G. Novel feature extraction, selection and fusion for effective malware family classification. In Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 9–11 March 2016; pp. 183–194. [Google Scholar]
- Bilar, D. Opcodes as predictor for malware. Int. J. Electron. Secur. Digit. Forensics 2007, 1, 156–168. [Google Scholar] [CrossRef]
- Costantini, G.; Ferrara, P.; Cortesi, A. Static analysis of string values. In Proceedings of the International Conference on Formal Engineering Methods, Durham, UK, 26–28 October 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 505–521. [Google Scholar]
- Sikorski, M.; Honig, A. Practical Malware Analysis: The Hands-on Guide to Dissecting Malicious Software. No Starch Press. Available online: https://nostarch.com/malware (accessed on 1 February 2012).
- Egele, M.; Scholte, T.; Kirda, E.; Kruegel, C. A survey on automated dynamic malware-analysis techniques and tools. ACM Comput. Surv. CSUR 2008, 44, 1–42. [Google Scholar] [CrossRef]
- Grégio, A.R.; Fernandes Filho, D.S.; Afonso, V.M.; Santos, R.D.; Jino, M.; de Geus, P.L. Behavioral analysis of malicious code through network traffic and system call monitoring. In Evolutionary and Bio-Inspired Computation: Theory and Applications V; International Society for Optics and Photonics: Bellingham, WA, USA, 2011; Volume 8059, p. 80590O. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Dekking, F.M.; Kraaikamp, C.; Lopuhaä, H.P.; Meester, L.E. A Modern Introduction to Probability and Statistics: Understanding Why and How; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; Volume 14, pp. 1137–1145. [Google Scholar]
- Berrar, D. Cross-Validation. 2019. Available online: https://0-www-sciencedirect-com.brum.beds.ac.uk/science/article/pii/B978012809633820349X?via%3Dihub (accessed on 20 May 2021).
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Wagner, M.; Fischer, F.; Luh, R.; Haberson, A.; Rind, A.; Keim, D.A.; Aigner, W. A survey of visualization systems for malware analysis. In Proceedings of the Eurographics Conference on Visualization, Cagliari, Italy, 25–29 May 2015; pp. 105–125. [Google Scholar]


{kind=link}
| Total | # Inliers | # Outliers | ||
|---|---|---|---|---|
| Total | # malwares | 1941 | 1670 | 271 |
| # correct/incorrect | 1819(93.7%)/122 | 1613(96.6%)/57 | 206(76.0%)/70 | |
| Group A | # malwares | 1220 | 1074 | 146 |
| # correct/incorrect | 1176(96.4%)/44 | 1074(98.2%)/19 | 121(82.9%)/25 | |
| Group B | # malwares | 85 | 71 | 14 |
| # correct/incorrect | 63(74.1%)/22 | 61(85.9%)/10 | 2(14.3%)/12 | |
| Group C | # malwares | 85 | 69 | 16 |
| # correct/incorrect | 70(82.4%)/15 | 61(88.4%)/8 | 9(56.3%)/7 | |
| Group D | # malwares | 72 | 65 | 7 |
| # correct/incorrect | 58(80.6%)/14 | 57(87.7%)/8 | 1(14.3%)/6 | |
| Group E | # malwares | 479 | 391 | 88 |
| # correct/incorrect | 452(94.4%)/27 | 379(96.9%)/12 | 73(14.3%)/21 | |
| (total) | 85.1% | 90.0% | 51.1% | |
| (total) | 85.1% | 96.6% | 76.0% | |
| (total) | 85.1% | 96.7% | 74.8% | |
| # of Outliers | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Y/Correct | N | Y/Correct | N | Y/Correct | N | Y/Correct | N | ||
| Total | 271 | 45/44 | 226 | 93/88 | 178 | 141/129 | 130 | 186/161 | 85 |
| Group A | 146 | 11/11 | 135 | 49/48 | 97 | 84/81 | 62 | 105/98 | 41 |
| Group B | 14 | 1/0 | 13 | 3/0 | 11 | 5/0 | 9 | 6/0 | 8 |
| Group C | 16 | 2/2 | 14 | 2/2 | 14 | 4/3 | 12 | 8/5 | 8 |
| Group D | 7 | 0/0 | 7 | 0/0 | 7 | 0/0 | 7 | 3/0 | 4 |
| Group E | 88 | 31/31 | 57 | 39/38 | 49 | 48/45 | 40 | 64/58 | 24 |
| - | 70.0% | - | 68.3% | - | 62.1% | - | 47.2% | - | |
| - | 97.% | - | 94.6% | - | 91.5% | - | 86.6% | - | |
| - | 96.9% | - | 93.2% | - | 90.1% | - | 84.6% | - | |
| k-NN (w/o Give Up) | Inter-Class | Intra-Class () | Intra-Class () | Intra-Class () | Intra-Class () | |
|---|---|---|---|---|---|---|
| # classified | 1941 | 1670 | 1715 | 1763 | 1811 | 1856 |
| # correct | 1819 | 1613 | 1657 (1613 + 44) | 1701 (1613 + 88) | 1742 (1613 + 129) | 1774 (1613 + 161) |
| 85.1 % | 90.0 % | 89.8 % | 89.5 % | 88.9% | 87.8 % | |
| 93.7 % | 96.6 % | 96.6 % | 96.5 % | 96.2 % | 95.6 % | |
| 93.7 % | 96.7 % | 96.7 % | 96.5 % | 96.2% | 95.6 % | |
| # give up | 0 | 271 | 226 | 178 | 130 | 85 |
| % of classified | 100 % | 86.0 % | 88.4 % | 90.8 % | 93.3 % | 95.6 % |
| k-NN (w/o Give Up) | Intra-Class () | Expert 1 | Expert 2 | Average | |
|---|---|---|---|---|---|
| # classified | 1941 | 1811 | 1860 | 1884 | 1872 |
| # correct | 1819 | 1742 | 1777 | 1789 | 1783 |
| 93.7% | 96.2% | 95.5% | 95.0% | 95.25% | |
| # give up | 0 | 130 | 81 | 57 | 69 |
| # correct after manual inspection | - | - | 1858 (1777 + 81) | 1846 (1789 + 57) | 1852 (1783 + 69) |
| after manual inspection | - | - | 95.7% | 95.1% | 95.4% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chae, D.-K.; Park, S.-J.; Kim, E.; Hong, J.; Kim, S.-W. Identifying the Author Group of Malwares through Graph Embedding and Human-in-the-Loop Classification. Appl. Sci. 2021, 11, 6640. https://0-doi-org.brum.beds.ac.uk/10.3390/app11146640
Chae D-K, Park S-J, Kim E, Hong J, Kim S-W. Identifying the Author Group of Malwares through Graph Embedding and Human-in-the-Loop Classification. Applied Sciences. 2021; 11(14):6640. https://0-doi-org.brum.beds.ac.uk/10.3390/app11146640
Chicago/Turabian StyleChae, Dong-Kyu, Sung-Jun Park, Eujeanne Kim, Jiwon Hong, and Sang-Wook Kim. 2021. "Identifying the Author Group of Malwares through Graph Embedding and Human-in-the-Loop Classification" Applied Sciences 11, no. 14: 6640. https://0-doi-org.brum.beds.ac.uk/10.3390/app11146640