
Automatic Hate Speech Detection in English-Odia Code Mixed Social Media Data Using Machine Learning Techniques

 ,
,  , , and
, , and
Abstract
:1. Introduction
- Propose the hate and offensive speech detection models for the English-Odia mixed code data by using a new dataset of posts and comments from public Facebook pages;
- The proposed model use multiple feature extraction methods and multiple machine learning classifier algorithms;
- The proposed system achieved good prediction accuracy on an imbalanced dataset and outperformed existing models.
2. Related Works
3. Datasets
3.1. Data Collection
- The number of followers and likes has to be greater than 50,000, because such criteria allows for more active public pages to be included in categories;
- Pages that post news or hot issues on political, ethnicity, religious, or gender issues at least once every two days;
- Pages that use the Odia language frequently for posts and comments;
- Pages that published more than 500 posts from April 2018 to April 2019.
3.2. Data Preparation
- Remove all non-Odia, non-English, and non-textual posts and comments;
- Remove all null, blank value, and whitespace;
- Filter data using keywords that are an indicator of hate and offensive language;
- Join data of each page into one dataset;
- Remove duplication to ensure the uniqueness of each text in the dataset.
3.3. Annotation
4. Proposed Hate Speech Detection Architecture
4.1. Proposed Odia-English Text Preprocessing
4.1.1. Removing (Cleaning) Irrelevant Character, Punctuations Symbol, and Emoji’s
| Algorithm 1 Cleanup Odia-English Mixed Text. |
| Input: Text in a dataset Output: Clean text Begin: 1.Read the text in the dataset; 2.While (! end of the text in a dataset): If the text contains special_char [,’! @#$%^&*] then Remove special_char; If the text contains symbol [<>‹›«»=፦‘~_/] then Replace symbol and add space; If a text contains odia_Punc=[! . ?”] then Remove Odia_Punc; If text contain number = [0–9] then Remove number; If a text containsemoji = [    ……] then Remove emoji; ……] then Remove emoji;If a text contains extra white space then Trim the text; 3.Return clean_text; End: |
4.1.2. Tokenization
4.2. Proposed Feature Extractions
4.2.1. n-Gram Feature Extraction
4.2.2. TF-IDF Feature Extraction
4.2.3. Word2vec Feature Extraction
4.3. Machine Learning Model Building
4.4. Model Evaluation and Testing
5. Experiment and Results
5.1. Dataset Description
5.2. Preprocessing Implementation
5.3. Feature Extraction Result
5.4. Models Evaluation Results
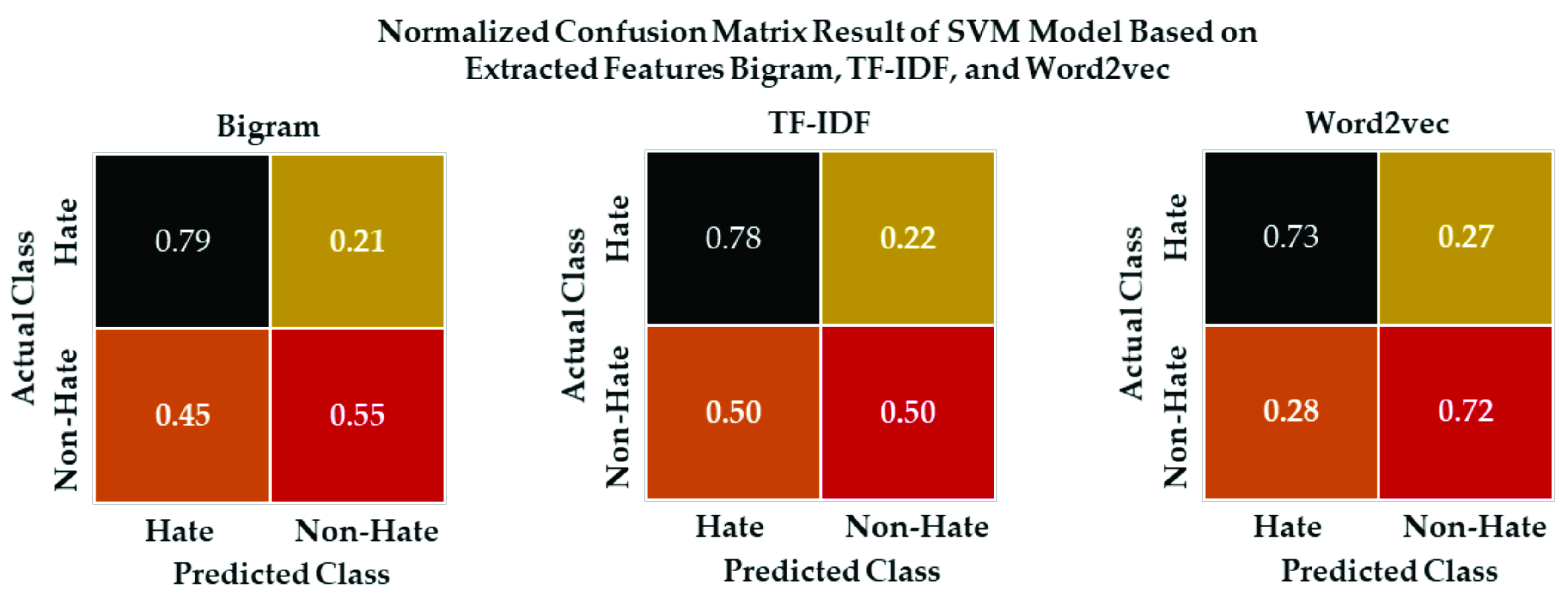
5.5. Binary Classification Models Evaluation Results
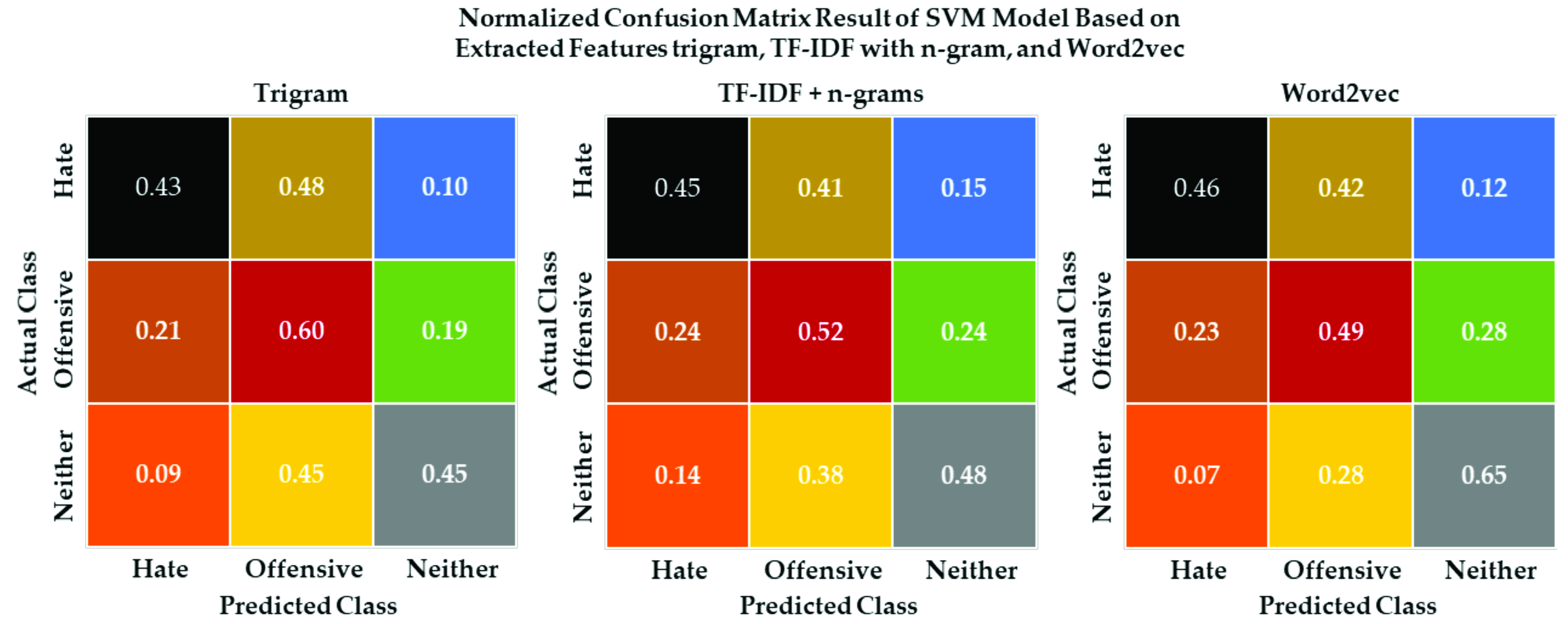
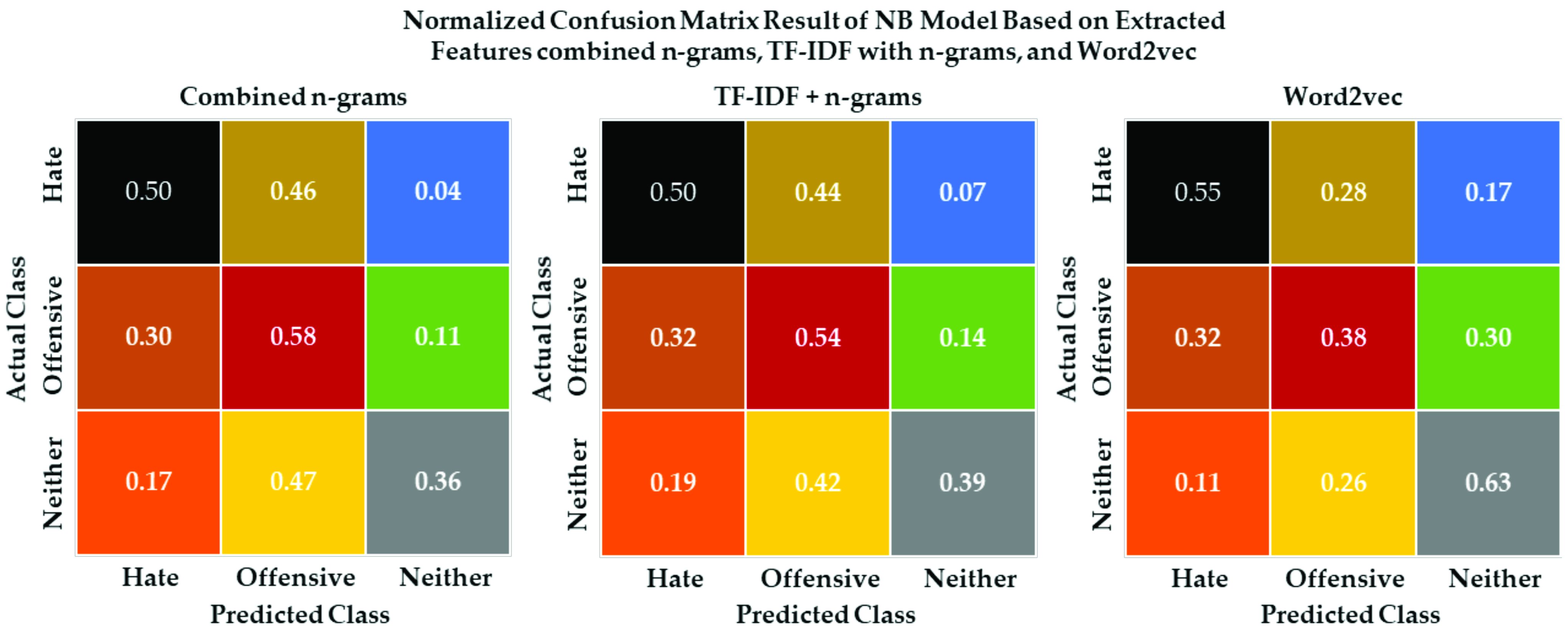
5.6. Ternary Classification Models Evaluation Results
5.7. Comparision with Results of Conventional ML Methods
5.8. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fiok, K.; Karwowski, W.; Gutierrez, E.; Liciaga, T.; Belmonte, A.; Capobianco, R. Automated Classification of Evidence of Respect in the Communication through Twitter. Appl. Sci. 2021, 11, 1294. [Google Scholar] [CrossRef]
- Das, T.K.; Acharjya, D.P.; Patra, M.R. Opinion mining about a product by analyzing public tweets in Twitter. In Proceedings of the 2014 International Conference on Computer Communication and Informatics, Coimbatore, India, 3–5 January 2014; pp. 1–4. [Google Scholar]
- Bermingham, A.; Smeaton, A. On using Twitter to monitor political sentiment and predict election results. In Proceedings of the Workshop on Sentiment Analysis Where AI meets Psychology (SAAIP 2011), Chiang Mai, Thailand, 13 November 2011; pp. 2–10. [Google Scholar]
- Xu, X.; Mei, Y.; Sun, Y.; Zhu, X. Analysis of the Effectiveness of Promotion Strategies of Social Platforms for the Elderly with Different Levels of Digital Literacy. Appl. Sci. 2021, 11, 4312. [Google Scholar] [CrossRef]
- De Choudhury, M.; Sundaram, H.; John, A.; Seligmann, D.D. Analyzing the dynamics of communication in online social networks. In Handbook of Social Network Technologies and Applications; Springer: Boston, MA, USA, 2010; pp. 59–94. [Google Scholar]
- Florio, K.; Basile, V.; Polignano, M.; Basile, P.; Patti, V. Time of your hate: The challenge of time in hate speech detection on social media. Appl. Sci. 2020, 10, 4180. [Google Scholar] [CrossRef]
- Alshalan, R.; Al-Khalifa, H. A Deep Learning Approach for Automatic Hate Speech Detection in the Saudi Twittersphere. Appl. Sci. 2020, 10, 8614. [Google Scholar] [CrossRef]
- Pereira-Kohatsu, J.C.; Quijano-Sánchez, L.; Liberatore, F.; Camacho-Collados, M. Detecting and monitoring hate speech in Twitter. Sensors 2019, 19, 4654. [Google Scholar] [CrossRef] [Green Version]
- Gagliardone, I.; Pohjonen, M.; Beyene, Z.; Zerai, A.; Aynekulu, G.; Bekalu, M.; Teferra, Z. Mechachal: Online Debates and Elections in Ethiopia-from Hate Speech to Engagement in Social Media. Available online: https://ssrn.com/abstract=2831369 (accessed on 5 September 2021).
- Gagliardone, I. Mapping and Analysing Hate Speech Online. Available online: https://ssrn.com/abstract=2601792 (accessed on 5 September 2021).
- Stokel-Walker, C. Alt-right’s’ Twitter’is hate-speech hub. New Sci. 2018, 3167, 15. [Google Scholar] [CrossRef]
- Mathew, B.; Dutt, R.; Goyal, P.; Mukherjee, A. Spread of hate speech in online social media. In Proceedings of the 10th ACM Conference on Web Science, Boston, MA, USA, 30 June 2019; pp. 173–182. [Google Scholar]
- Malmasi, S.; Zampieri, M. Detecting hate speech in social media. arXiv 2017, arXiv:1712.06427. [Google Scholar]
- Zhang, Z.; Luo, L. Hate speech detection: A solved problem? the challenging case of long tail on twitter. Semant. Web 2019, 10, 925–945. [Google Scholar] [CrossRef] [Green Version]
- Jaki, S.; De Smedt, T. Right-Wing German Hate Speech on Twitter: Analysis and Automatic Detection. arXiv 2019, arXiv:1910.07518. [Google Scholar]
- Saleem, H.M. A Web of Hate Tackling Hateful Speech in Online Social Spaces. arXiv 2017, arXiv:1709.10159. Available online: http://arxiv.org/abs/1709.10159 (accessed on 5 September 2021).
- Al-Hassan, A.; Al-Dossari, H. Detection of hate speech in social networks: A survey on multilingual corpus. In Proceedings of the 6th International Conference on Computer Science and Information Technology, Dubai, United Arab Emirates, 4–5 May 2019; Volume 10. [Google Scholar]
- Bohra, A.; Vijay, D.; Singh, V.; Akhtar, S.S.; Shrivastava, M. A dataset of Hindi-English code-mixed social media text for hate speech detection. In Proceedings of the Second Workshop on Computational Modeling of People’s Opinions, Personality, and Emotions in Social Media, New Orleans, LA, USA, 6 June 2018; pp. 36–41. [Google Scholar]
- Kamble, S.; Joshi, A. Hate speech detection from code-mixed hindi-english tweets using deep learning models. arXiv 2018, arXiv:1811.05145. [Google Scholar]
- Sreelakshmi, K.; Premjith, B.; Soman, K.P. Detection of Hate Speech Text in Hindi-English Code-mixed Data. Procedia Comput. Sci. 2020, 171, 737–744. [Google Scholar] [CrossRef]
- Saroj, A.; Pal, S. An Indian language social media collection for hate and offensive speech. In Proceedings of the Workshop on Resources and Techniques for User and Author Profiling in Abusive Language, Marseille, France, 11–16 May 2020; pp. 2–8. [Google Scholar]
- Mossie, Z.; Wang, J.H. Social network hate speech detection for Amharic language. In Proceedings of the 6th International Conference on Computer Science and Information Technology, Copenhagen, Denmark, 28–29 April 2018; pp. 41–55. [Google Scholar]
- Ibrohim, M.O.; Budi, I. A dataset and preliminaries study for abusive language detection in Indonesian social media. Procedia Comput. Sci. 2018, 135, 222–229. [Google Scholar] [CrossRef]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017. [Google Scholar]
- Gambäck, B.; Sikdar, U.K. Using convolutional neural networks to classify hate-speech. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 85–90. [Google Scholar]
- Benikova, D.; Wojatzki, M.; Zesch, T. What does this imply? Examining the Impact of Implicitness on the Perception of Hate Speech. In International Conference of the German Society for Computational Linguistics and Language Technology; Springer: Cham, Switzerland, 2017; pp. 171–179. [Google Scholar]
- Del Vigna, F.; Cimino, A.; Dell’Orletta, F.; Petrocchi, M.; Tesconi, M. Hate me, hate me not: Hate speech detection on facebook. In Proceedings of the First Italian Conference on Cybersecurity (ITASEC17), Venice, Italy, 17–20 January 2017; pp. 86–95. [Google Scholar]
- Bassignana, E.; Basile, V.; Patti, V. Hurtlex: A multilingual lexicon of words to hurt. In Proceedings of the 5th Italian Conference on Computational Linguistics, CLiC-it 2018, Torino, Italy, 10–12 December 2018; Volume 2253, pp. 1–6. [Google Scholar]
- Alfina, I.; Mulia, R.; Fanany, M.I.; Ekanata, Y. Hate speech detection in the Indonesian language: A dataset and preliminary study. In Proceedings of the 2017 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Bali, Indonesia, 28–29 October 2017; pp. 233–238. [Google Scholar]
- Djuric, N.; Zhou, J.; Morris, R.; Grbovic, M.; Radosavljevic, V.; Bhamidipati, N. Hate speech detection with comment embeddings. In Proceedings of the 24th International Conference On World Wide Web, Florence, Italy, 18–22 May 2015; pp. 29–30. [Google Scholar]
- Watanabe, H.; Bouazizi, M.; Ohtsuki, T. Hate speech on twitter: A pragmatic approach to collect hateful and offensive expressions and perform hate speech detection. IEEE Access 2018, 6, 13825–13835. [Google Scholar] [CrossRef]
- Fauzi, M.A.; Yuniarti, A. Ensemble method for indonesian twitter hate speech detection. Indones. J. Electr. Eng. Comput. Sci. 2018, 11, 294–299. [Google Scholar] [CrossRef]
- Kiilu, K.K.; Okeyo, G.; Rimiru, R.; Ogada, K. Using Naïve Bayes algorithm in detection of hate tweets. Int. J. Sci. Res. Publ. 2018, 8, 99–107. [Google Scholar] [CrossRef] [Green Version]
- Tulkens, S.; Hilte, L.; Lodewyckx, E.; Verhoeven, B.; Daelemans, W. A dictionary-based approach to racism detection in dutch social media. arXiv 2016, arXiv:1608.08738. [Google Scholar]
- Gaydhani, A.; Doma, V.; Kendre, S.; Bhagwat, L. Detecting hate speech and offensive language on twitter using machine learning: An n-gram and tfidf based approach. arXiv 2018, arXiv:1809.08651. [Google Scholar]
- Biere, S.; Bhulai, S.; Analytics, M.B. Hate Speech Detection Using Natural Language Processing Techniques; Master Business Analytics, Department of Mathematics, Faculty of Science, Vrije Universiteit Amsterdam: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Badjatiya, P.; Gupta, S.; Gupta, M.; Varma, V. Deep learning for hate speech detection in tweets. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 759–760. [Google Scholar]
- Gitari, N.D.; Zuping, Z.; Damien, H.; Long, J. A lexicon-based approach for hate speech detection. Int. J. Multimed. Ubiquitous Eng. 2015, 10, 215–230. [Google Scholar] [CrossRef]
- Zimmerman, S.; Kruschwitz, U.; Fox, C. Improving hate speech detection with deep learning ensembles. In Proceedings of the 11th Edition of the Language Resources and Evaluation Conference, Miyazaki, Japan, 7–12 May 2018; pp. 2546–2553. [Google Scholar]
- MacAvaney, S.; Yao, H.R.; Yang, E.; Russell, K.; Goharian, N.; Frieder, O. Hate speech detection: Challenges and solutions. PLoS ONE 2019, 14, e0221152. [Google Scholar] [CrossRef]
- Miron’czuk, M.M.; Protasiewicz, J. A recent overview of the state-of-the-art elements of text classification. Expert Syst. Appl. 2018, 106, 36–54. [Google Scholar] [CrossRef]
- Roy, P.K.; Tripathy, A.K.; Das, T.K.; Gao, X.Z. A Framework for Hate Speech Detection Using Deep Convolutional Neural Network. IEEE Access 2020, 8, 204951–204962. [Google Scholar] [CrossRef]
- Das, T.K. A customer classification prediction model based on machine learning techniques. In Proceedings of the 2015 International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Davangere, India, 29–31 October 2015; pp. 321–326. [Google Scholar]
- Salminen, J.; Almerekhi, H.; Milenkovic’, M.; Jung, S.G.; An, J.; Kwak, H.; Jansen, B.J. Anatomy of online hate: Developing a taxonomy and machine learning models for identifying and classifying hate in online news media. In Proceedings of the Twelfth International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Objective | Feature Extraction | ML Method & Accuracy |
|---|---|---|---|
| Binary Class Hate speech | |||
| Mossie and Wang [22] | Detection of HS in the Amharic language | Word2Vec and TF-IDF | NB and RF: 79.83% & 65.34% respectively |
| Alfina et al. [29] | Detection of HS in the Indonesian Language | Bag-of-word (BOW), word n-gram and character n-gram | NB, SVM, Bayesian LR (BLR) & (RFDT): 93.5% RFDT |
| Djuric et al. [30] | Detection of HS with comment embeddings | Paragraph2vec & BOW with TF & TF-IDF | Logistic regression obtains 0.80 AUC |
| Watanabe et al. [31] | Detection of HS on Twitter | Unigrams with sentimental, semantic features and pattern features | J48graft, SVM and RF: accuracy 87.4% for binary and 78.4% for ternary |
| Fauzi et al. [32] | Ensemble method for HS detection in Indonesian Twitter | BOW with TF.IDF weighting | NB, KNN, Maximum Entropy, RF, and SVM, and two ensemble methods: hard and soft vote, F1 measure 79.8%. (SVM, NB, and RF) |
| Kiilu et al. [33] | Detection of HS in Kenyan tweets | Sentiment analysis & N-Gram feature | NB: P-0.58, R-0.62, A-0.67 |
| Multi-class hate speech | |||
| Davidson et al. [24] | Automated HS and offensive language detection | Bigram, unigram, and trigram features with TF-IDF | Logistic regression with L1 regularization: 90% |
| Tulkens et al. [34] | Racism detection in Dutch social media | Word2vec, Dictionary-based | SVM; F1: 0.46 |
| Gaydhani et al. [35] | Detecting HS and offensive language on Twitter | N-gram and TF-IDF | LR, NB and SVM 95.6% |
| Shervin and Marcos [13] | Detecting HS in social media | Word skip-gram, and surface n-gram | SVM: 0.78 |
| Binary and multi-classification with deep learning | |||
| Gambäck and Kumar [25] | Convolutional neural network (CNN) to classify HS | Word2vec, Random vector, character n-grams, and word2vec+character n-grams | CNN with word2vec: 0.78 F-score multi-classification |
| Biere and Bhulai (2018) [36] | HS detection using NLP | Word2vec with 300 dimensions | CNN accuracy of 91%, and a loss of 36%. |
| Badjatiya et al. [37] | HS detection using deep learning | Random embeddings & glove embeddings | CNN, LTSM & Fast Text best accuracy is 93% f1-score CNN + Random &Glove Embeddings |
| Rule-based hate speech detection | |||
| Gitari et al. (2015) [38] | A lexicon-based approach for hate speech detection | Semantic features, subjectivity features, and grammatical patterns features | Subjectivity rule-based classifier called Subjclue lexicon F1-score 65.12% |
| No | Categories Name | Description |
|---|---|---|
| 1 | News media and broadcasting pages | Delivering news to the general public or a target public. |
| 2 | Bloggers’ and journalists’ pages | A person who regularly writes for blogs, newspapers, magazines. |
| 3 | Religious media and religious group pages | Delivering religious news, religious teachings to the followers of that religion or a target group. |
| 4 | Political party, politician and government official’s pages | A group of people who come together to contest elections. A group of politicians who have held the power of government. |
| 5 | Public figure: artists’ and authors’ pages | A person or public figure who creates song, painting or drawing, and a writer of a book, article, or document. |
| 6 | Activists’, general or interest community pages | A person who campaigns to bring about political or social change, and pages promoting different issues on political, religious, ethnic and other social issues. |
| Label | Annotator 1 | Annotator 2 | Annotator 3 | Annotator 4 | Total Unique Annotated |
|---|---|---|---|---|---|
| Offensive (OFS) | 484 | 628 | 304 | 619 | 2035 |
| Hate (HS) | 281 | 202 | 198 | 417 | 1098 |
| Neither (OK) | 235 | 170 | 498 | 464 | 1367 |
| Total annotated | 1000 | 1000 | 1000 | 1500 | 4500 |
| Label | Annotator 1 | Annotator 2 | Annotator 3 | Final Class by Voting |
|---|---|---|---|---|
| Offensive (OFS) | 251 | 227 | 221 | 264 |
| Hate (HS) | 93 | 114 | 151 | 95 |
| Neither (OK) | 156 | 159 | 128 | 141 |
| Total | 500 | 500 | 500 | 500 |
| Label or Class | Number of Post and Comments |
|---|---|
| Offensive (OFS) | 2299 |
| Hate (HS) | 1193 |
| Neither (OK) | 1508 |
| Total | 5000 |
| Features Extraction Method | Features Vectors Size |
|---|---|
| Word unigram | 10,282 |
| Word bigram | 14,298 |
| Word trigram | 14,830 |
| Word unigram + bigram + trigram (combined n-grams) | 39,410 |
| TF-IDF | 10,279 |
| TF-IDF + combined n-grams | 49,692 |
| Word2vec | 150 |
| Features | 5-Folds Accuracy (%) for SVM Model | Average Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | ||
| Word unigram | 72.12 | 70.72 | 68.10 | 73.27 | 73.07 | 71.46 |
| Word bigrams | 73.32 | 71.62 | 68.50 | 73.47 | 72.97 | 71.98 |
| Word trigrams | 73.22 | 71.52 | 68.40 | 73.47 | 73.07 | 71.94 |
| Combined n-grams | 72.82 | 70.72 | 68.20 | 72.27 | 73.47 | 71.50 |
| TF-IDF | 70.02 | 70.22 | 66.80 | 71.67 | 70.47 | 69.84 |
| TF-IDF+ Combined n-gram | 70.12 | 70.22 | 67.20 | 71.57 | 70.67 | 69.96 |
| Word2vec | 73.12 | 71.42 | 70.10 | 73.67 | 74.37 | 72.54 |
| Features | 5-Folds Accuracy (%) for NB Model | Average Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | ||
| Word unigram | 73.72 | 74.52 | 74.2 | 75.27 | 74.97 | 74.54 |
| Word bigrams | 74.62 | 74.22 | 72.80 | 75.97 | 75.37 | 74.60 |
| Word trigrams | 74.72 | 74.22 | 72.90 | 75.97 | 75.27 | 74.62 |
| Combined n-grams | 74.72 | 74.82 | 72.30 | 76.07 | 75.37 | 74.66 |
| TF-IDF | 70.62 | 71.52 | 71.40 | 73.97 | 73.77 | 72.26 |
| TF-IDF+ Combined n-gram | 73.12 | 72.72 | 71.90 | 75.27 | 75.37 | 73.68 |
| Word2vec | 71.32 | 67.33 | 69.5 | 72.97 | 72.77 | 70.78 |
| Features | 5-Folds Accuracy (%) for RF Model | Average Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | ||
| Word unigram | 74.44 | 72.12 | 72.80 | 73.97 | 72.87 | 73.24 |
| Word bigram | 73.82 | 71.62 | 71.80 | 74.17 | 72.57 | 72.80 |
| Word trigram | 73.52 | 71.92 | 72.10 | 73.67 | 73.47 | 72.92 |
| Combined n-gram | 73.32 | 72.02 | 72.40 | 74.97 | 71.87 | 72.92 |
| TF-IDF | 74.52 | 71.92 | 71.7 | 73.87 | 71.97 | 72.79 |
| TF-IDF+ combined n-gram | 71.23 | 71.63 | 70.60 | 71.77 | 72.27 | 71.50 |
| Word2vec | 75.32 | 76.12 | 74.3 | 76.07 | 75.17 | 75.39 |
| Feature | SVM | NB | RF | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| Word unigram | 0.72 | 0.71 | 0.72 | 0.73 | 0.75 | 0.71 | 0.71 | 0.73 | 0.70 |
| Word bigrams | 0.72 | 0.72 | 0.72 | 0.73 | 0.75 | 0.72 | 0.71 | 0.73 | 0.70 |
| Word trigrams | 0.72 | 0.72 | 0.72 | 0.73 | 0.75 | 0.72 | 0.71 | 0.73 | 0.70 |
| Combined n-grams | 0.72 | 0.71 | 0.72 | 0.73 | 0.75 | 0.72 | 0.70 | 0.72 | 0.70 |
| TF-IDF | 0.70 | 0.70 | 0.70 | 0.70 | 0.72 | 0.71 | 0.71 | 0.73 | 0.70 |
| TF-IDF+ combined n-grams | 0.70 | 0.71 | 0.70 | 0.72 | 0.74 | 0.72 | 0.70 | 0.72 | 0.70 |
| Word2vec | 0.76 | 0.73 | 0.73 | 0.73 | 0.71 | 0.72 | 0.75 | 0.75 | 0.72 |
| Extracted Feature | 5-Folds Accuracy Scores (%) for SVM Model | Average Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | ||
| Word unigram | 52.6 | 51.7 | 46.9 | 50.7 | 52.5 | 50.88 |
| Word bigrams | 53.5 | 51.1 | 48.5 | 50.7 | 52.4 | 51.24 |
| Word trigrams | 53.3 | 51.7 | 48.7 | 51.0 | 52.2 | 51.40 |
| Combined n-grams | 53.3 | 53.2 | 48.4 | 50.1 | 52.8 | 51.56 |
| TF-IDF | 50.2 | 50.0 | 45.5 | 48.0 | 48.8 | 48.51 |
| TF-IDF+ combined | 50.8 | 50.4 | 45.5 | 47.8 | 50.0 | 48.73 |
| Word2vec | 57.1 | 55.7 | 49.5 | 51.5 | 53.0 | 53.35 |
| Feature Models | 5-Folds Accuracy Scores (%) for NB Model | Average Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | ||
| Word unigram | 40.2 | 42.8 | 44.3 | 38.8 | 43.5 | 41.89 |
| Word bigrams | 41.8 | 44.1 | 47.2 | 42.6 | 43.8 | 43.87 |
| Word trigrams | 41.9 | 44.5 | 47.6 | 42.7 | 43.8 | 44.07 |
| Combined n-grams | 52.7 | 51.4 | 48.8 | 47.1 | 48.6 | 49.73 |
| TF-IDF | 48.4 | 48.3 | 47.4 | 45.9 | 47.4 | 47.45 |
| TF-IDF+ combined | 49.5 | 49.3 | 48.4 | 46.9 | 48.0 | 48.39 |
| Word2vec | 54.0 | 51.0 | 49.5 | 46.0 | 47.3 | 49.57 |
| Extracted Feature | 5-Folds Accuracy Scores (%) for the RF Model | Average Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | ||
| Word unigram | 52.6 | 50.6 | 50.4 | 52.8 | 48.9 | 51.07 |
| Word bigrams | 52.9 | 50.4 | 51.1 | 51.0 | 48.7 | 50.08 |
| Word trigrams | 52.4 | 51.7 | 49.0 | 51.4 | 49.0 | 50.69 |
| Combined n-grams | 53.3 | 50.5 | 50.6 | 50.9 | 48.4 | 50.75 |
| TF-IDF | 52.2 | 50.0 | 48.2 | 52.2 | 49.3 | 50.38 |
| TF-IDF+ combined | 52.9 | 50.1 | 49.7 | 49.9 | 50.3 | 50.59 |
| Word2vec | 56.0 | 56.7 | 53.0 | 54.3 | 55.2 | 55.05 |
| Extracted Feature | SVM | NB | RF | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| Word unigram | 0.51 | 0.51 | 0.51 | 0.43 | 0.42 | 0.42 | 0.51 | 0.51 | 0.50 |
| Word bigrams | 0.51 | 0.51 | 0.51 | 0.45 | 0.44 | 0.44 | 0.51 | 0.51 | 0.50 |
| Word trigrams | 0.51 | 0.51 | 0.51 | 0.45 | 0.44 | 0.44 | 0.51 | 0.51 | 0.50 |
| Combined n-grams | 0.52 | 0.52 | 0.52 | 0.52 | 0.50 | 0.50 | 0.50 | 0.51 | 0.50 |
| TF-IDF | 0.49 | 0.49 | 0.49 | 0.50 | 0.47 | 0.48 | 0.50 | 0.51 | 0.50 |
| TF-IDF+ combined n-grams | 0.49 | 0.49 | 0.49 | 0.50 | 0.48 | 0.49 | 0.50 | 0.51 | 0.50 |
| Word2vec | 0.53 | 0.53 | 0.53 | 0.51 | 0.50 | 0.49 | 0.57 | 0.54 | 0.50 |
| Model | Extracted Features | P | R | F1 | Average Accuracy (%) |
|---|---|---|---|---|---|
| LR | Word unigram | 0.50 | 0.50 | 0.50 | 50.01 |
| Word bigrams | 0.50 | 0.50 | 0.50 | 50.02 | |
| Word trigrams | 0.50 | 0.50 | 0.50 | 49.65 | |
| DT | Word unigram | 0.45 | 0.43 | 0.44 | 43.34 |
| Word bigrams | 0.47 | 0.45 | 0.46 | 43.09 | |
| Word trigrams | 0.49 | 0.45 | 0.47 | 42.17 | |
| GB | Word unigram | 0.50 | 0.50 | 0.50 | 49.11 |
| Word bigrams | 0.49 | 0.50 | 0.49 | 48.23 | |
| Word trigrams | 0.50 | 0.50 | 0.50 | 48.52 | |
| KNN | Word unigram | 0.44 | 0.44 | 0.44 | 41.32 |
| Word bigrams | 0.45 | 0.45 | 0.45 | 42.31 | |
| Word trigrams | 0.45 | 0.45 | 0.45 | 42.89 |
| Reference/Year | Name/Language | Number of Instances | Labels in Dataset | Source | Features | Model | Performance | |
|---|---|---|---|---|---|---|---|---|
| A | F1 | |||||||
| [24], 2017 | English | 25000 | Hate, offensive and neither | Unigram, bigram, and trigram features with TF-IDF | LR, NB, DT, RF and linear SVM | -- | 0.90 | |
| [29], 2017 | Indonesian | 1100 | HS and non-HS | BOW, word n-gram and character n-gram | NB, SVM, Bayesian LR, RFDT | -- | 0.935 | |
| [33], 2018 | English | 45,645—training, 22,820—testing | Not labelled | Unigram, Bigram | NB | 0.70 | -- | |
| [22], 2018 | Ahmaric in Ethiopia | 6,120 | Hate and not hate | word2vec and TF-IDF | NB, RF | 0.798 | 0.853 | |
| [44], 2018 | English | 5143 | Hate and not hate | Comments from videos posted in YouTube and Facebook | n-grams, semantic and syntactic, TF-IDF, word2vec embeddings, doc2vec embeddings | LR, DT, RF, Adabost, SVM | -- | 0.79 |
| [35], 2018 | Crowdflower (Public) | 14509 | Hateful, offensive and clean | N-gram and TF-IDF | LR, NB, SVM | 0.956 | 0.96 | |
| [18], 2018 | Hindi-English code mixed data | 4575 | Hate and normal | Character n-gram, word n-gram, punctuations, lexicon, all features | SVM, RF | 0.717 | -- | |
| [20], 2020 | Hindi-English code mixed data | 10000 | Hate and non-hate | Twitter, HASOC | FastText, word2vec | SVM- linear, SVM-RBF, RF | 0.8581 | 0.8580 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohapatra, S.K.; Prasad, S.; Bebarta, D.K.; Das, T.K.; Srinivasan, K.; Hu, Y.-C. Automatic Hate Speech Detection in English-Odia Code Mixed Social Media Data Using Machine Learning Techniques. Appl. Sci. 2021, 11, 8575. https://0-doi-org.brum.beds.ac.uk/10.3390/app11188575
Mohapatra SK, Prasad S, Bebarta DK, Das TK, Srinivasan K, Hu Y-C. Automatic Hate Speech Detection in English-Odia Code Mixed Social Media Data Using Machine Learning Techniques. Applied Sciences. 2021; 11(18):8575. https://0-doi-org.brum.beds.ac.uk/10.3390/app11188575
Chicago/Turabian StyleMohapatra, Sudhir Kumar, Srinivas Prasad, Dwiti Krishna Bebarta, Tapan Kumar Das, Kathiravan Srinivasan, and Yuh-Chung Hu. 2021. "Automatic Hate Speech Detection in English-Odia Code Mixed Social Media Data Using Machine Learning Techniques" Applied Sciences 11, no. 18: 8575. https://0-doi-org.brum.beds.ac.uk/10.3390/app11188575