
A Speech Preprocessing Method Based on Perceptually Optimized Envelope Processing to Increase Intelligibility in Reverberant Environments

Abstract
:1. Introduction
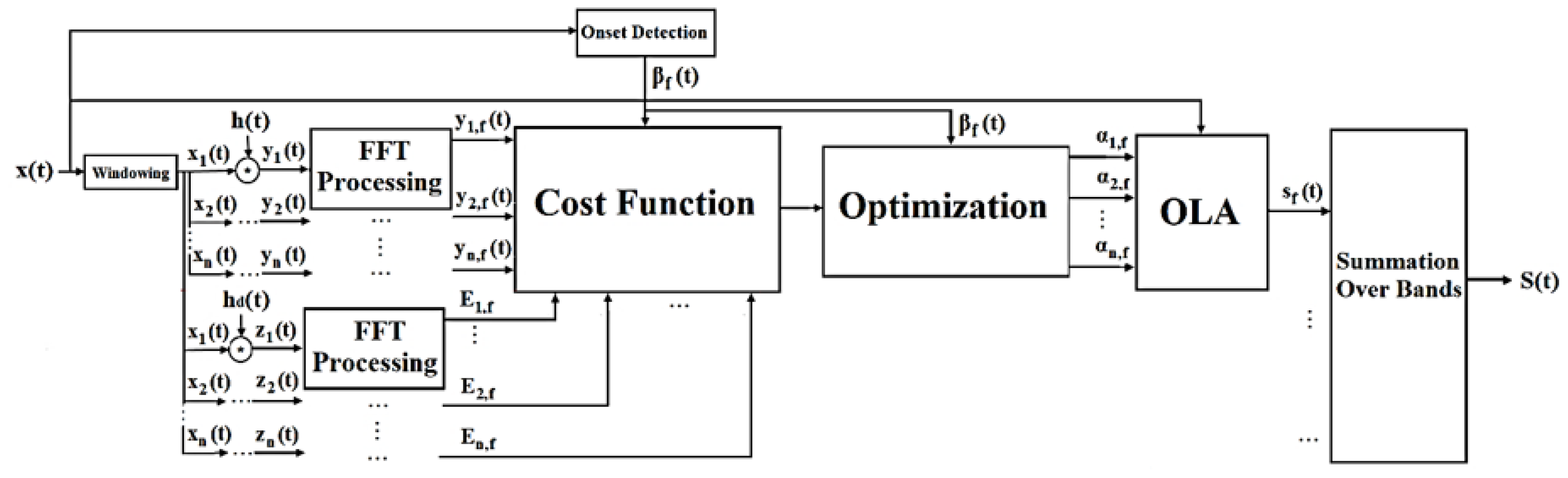
2. Proposed NELE Method
2.1. Preprocessing
2.2. Construction of a Cost Function for a Frame
2.3. Optimization Unit
| Algorithm 1. Example text of a theorem. Determination of weights , , ..., , …, in a one-third octave (f). |
| Step 1: k = 1 Step 2: The weight of frame number k is determined. All the upcoming CFs that are influ-enced by construct the according to Equation (12). For construction of , previous determined weights in CFs are used and the new weight is determined: For example, the is a function of , , ..., . All of these weights are determined in the first optimization. However, only is accepted as the final value: Step 3: All CFs that are influenced by are replaced by their numerical value. For example, for : Step 4: k = k + 1 If : go to Step 2 else finish |
3. Simulations and Measurements
3.1. Stimuli
3.2. Binaural Room Impulse Responses
3.3. Signal Processing Details
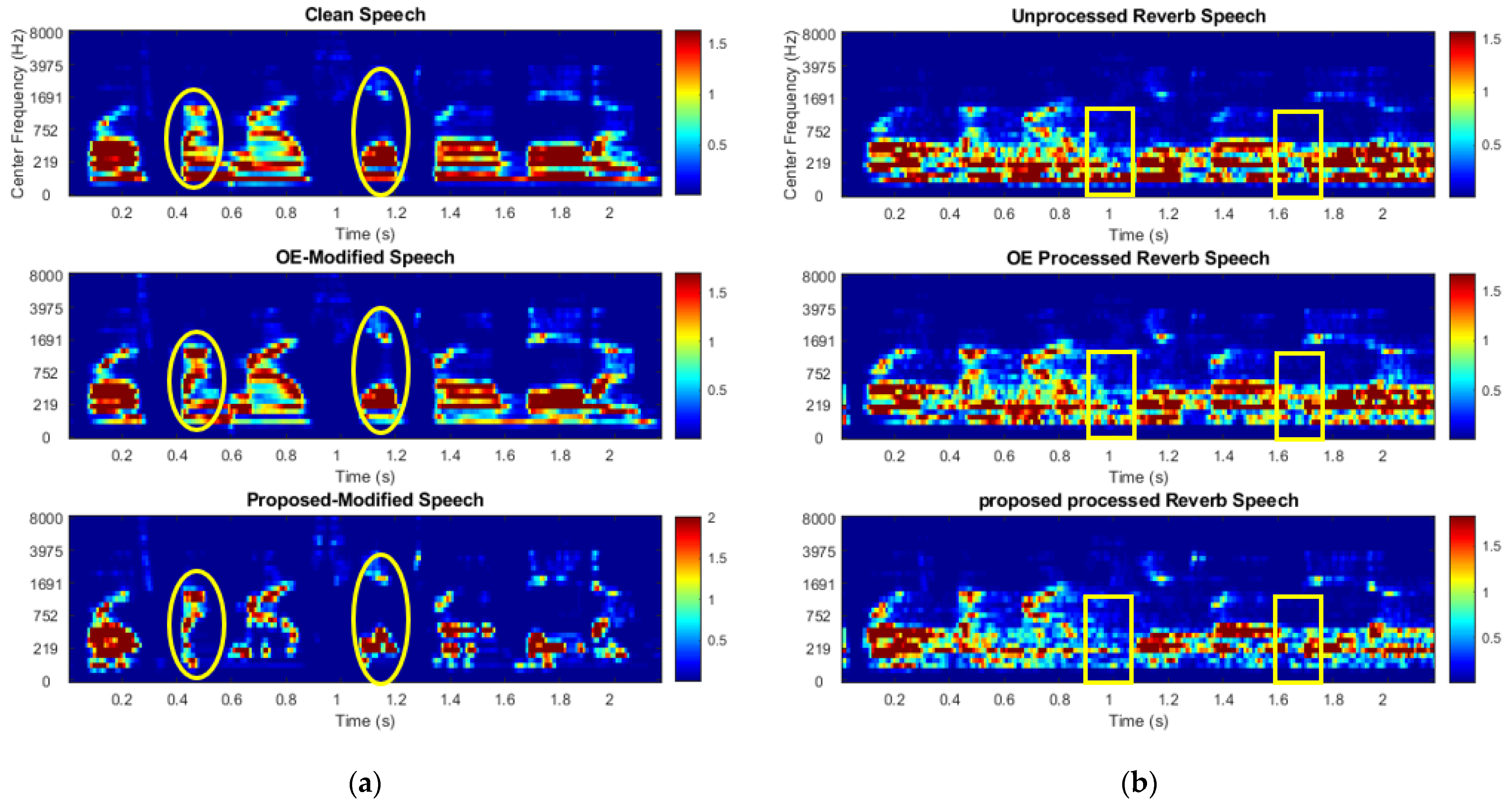
3.4. Effect of the Algorithm on Signal
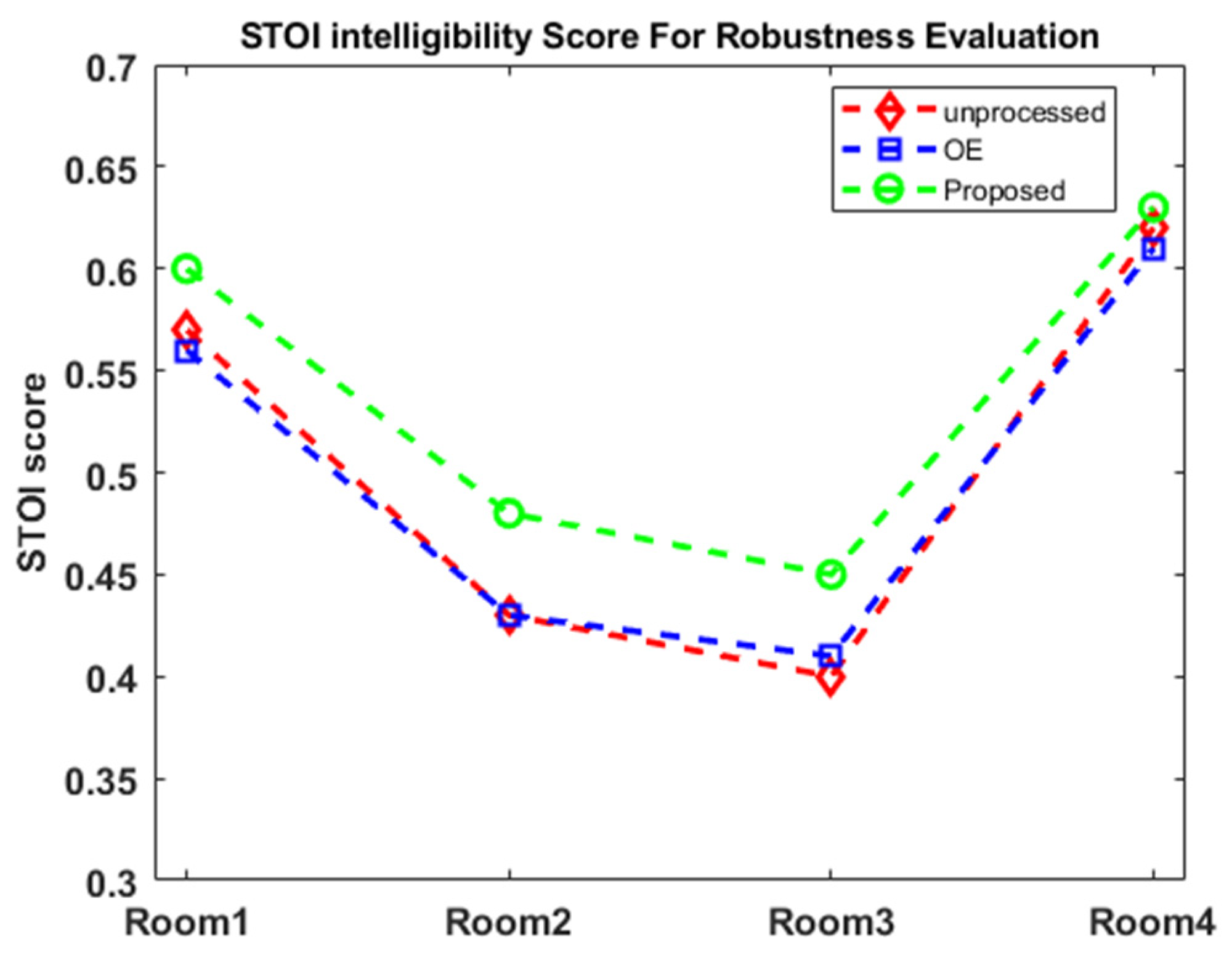
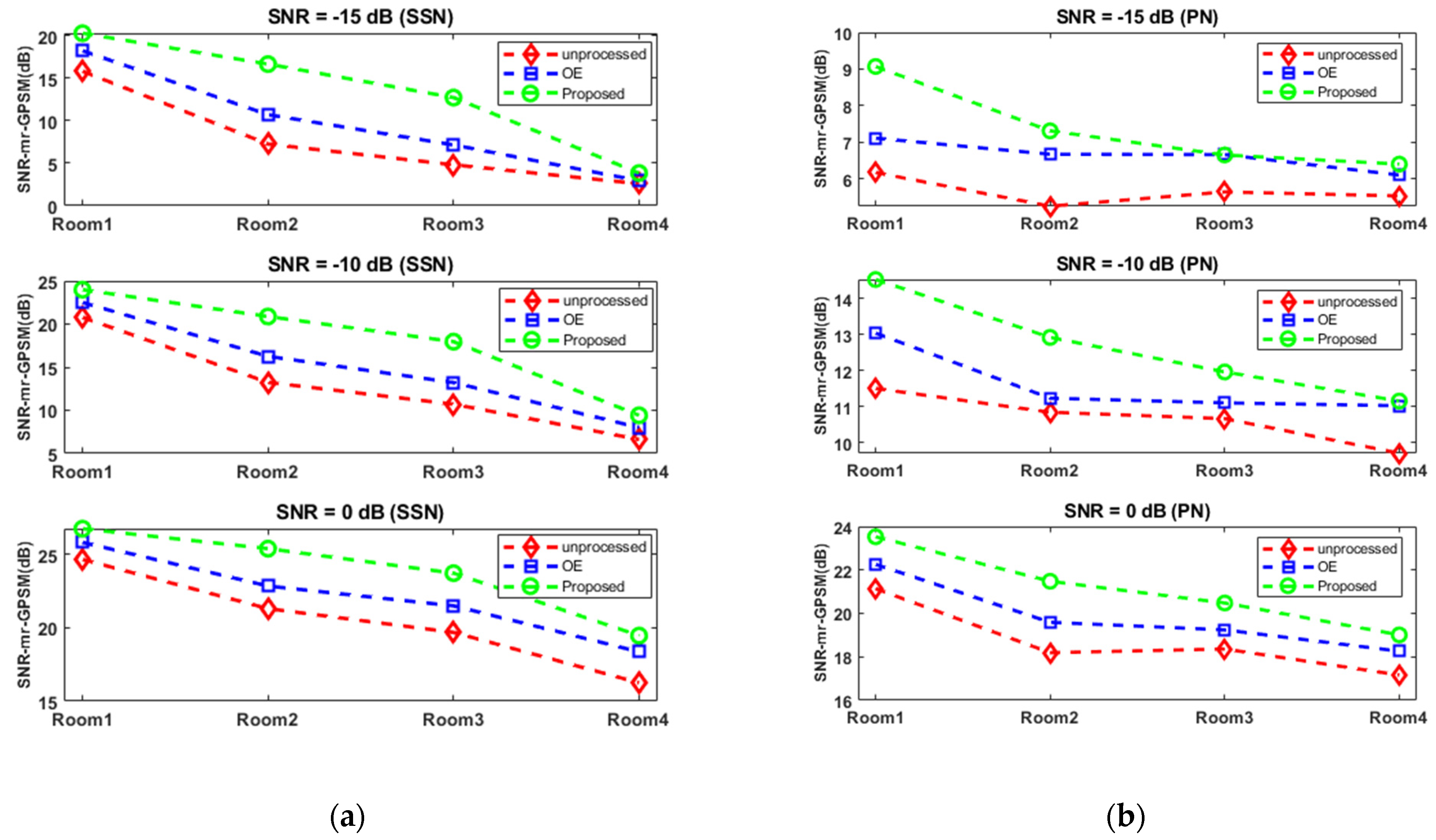
3.5. Objective Evaluation of the Algorithm Using Two Intelligibility Models
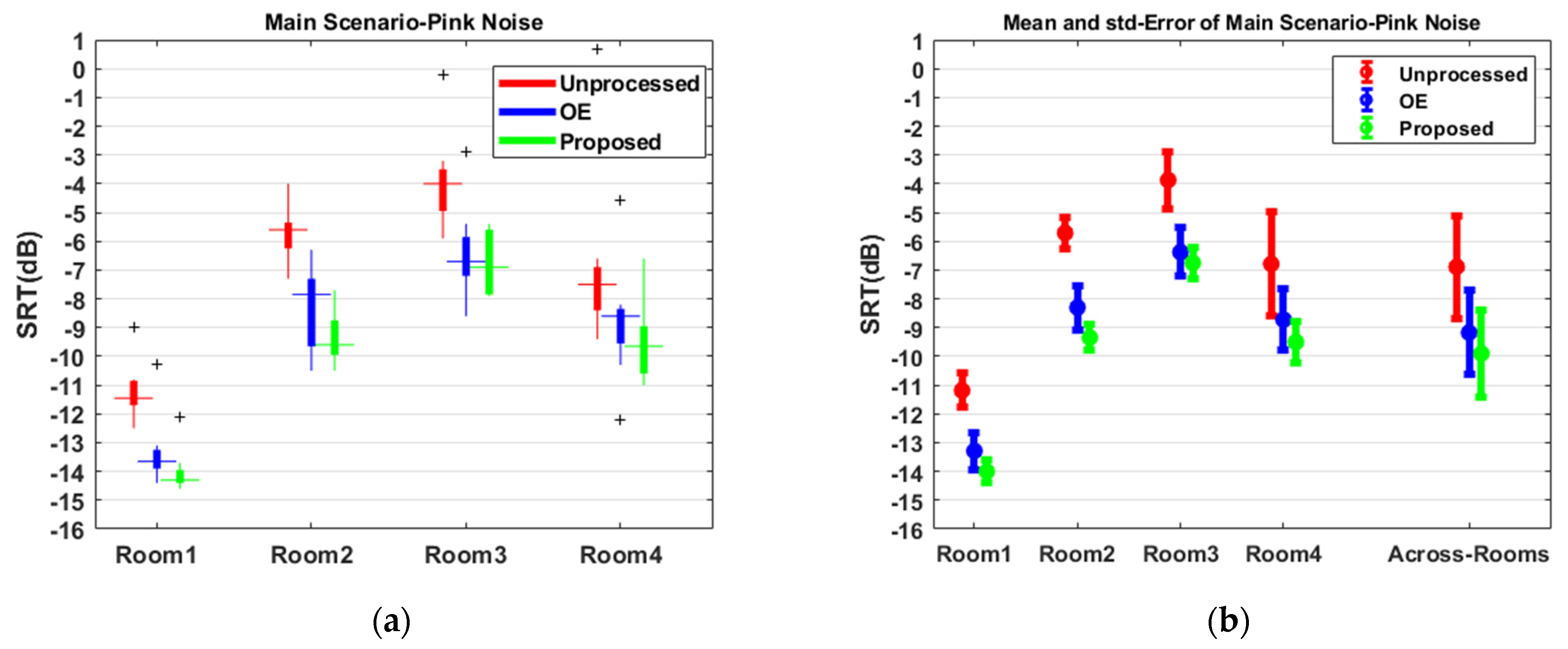
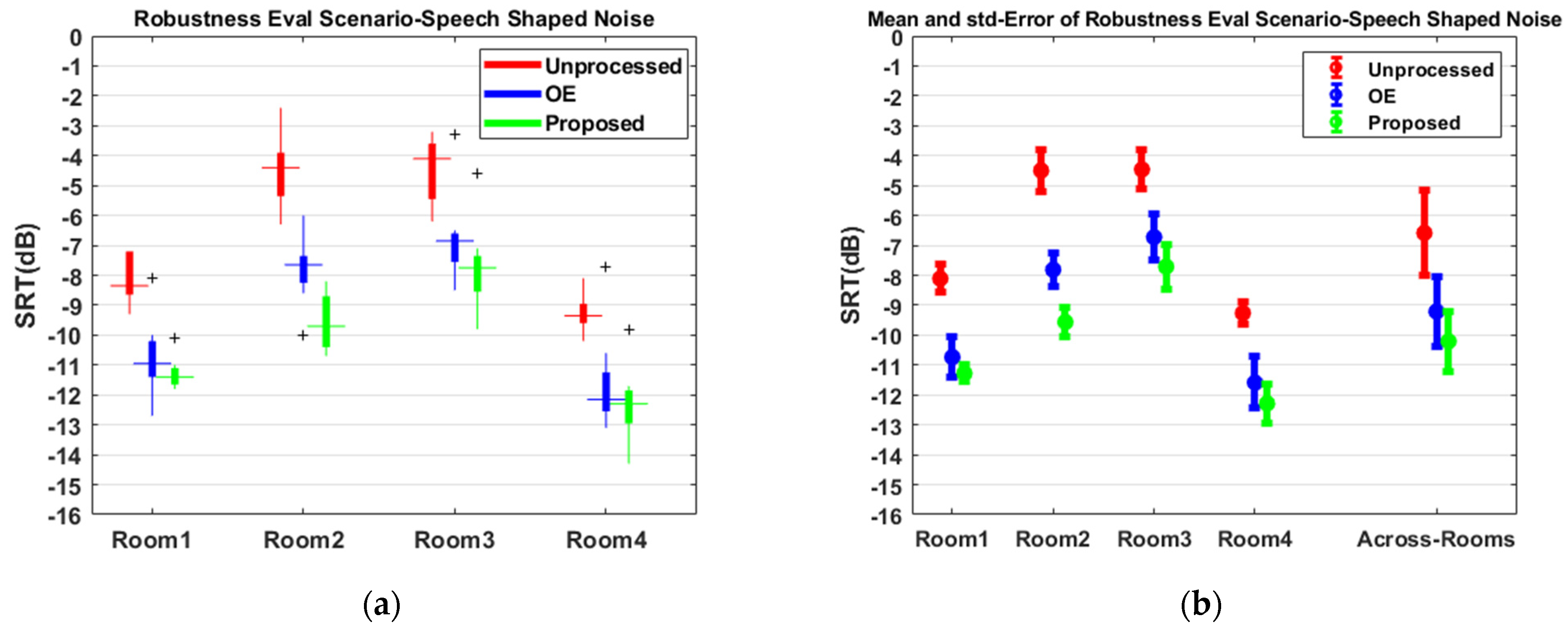
3.6. Subjective Evaluation
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sauert, B.; Vary, P. Near end listening enhancement: Speech intelligibility improvement in noisy environments. In Proceedings of the 2006 IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, Toulouse, France, 14–19 May 2006. [Google Scholar]
- Zorilă, T.-C.; Stylianou, Y.; Ishihara, T.; Akamine, M. Near and far field speech-in-noise intelligibility improvements based on a time–frequency energy reallocation approach. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1808–1818. [Google Scholar] [CrossRef]
- Zorila, T.-C.; Kandia, V.; Stylianou, Y. Speech-in-noise intelligibility improvement based on spectral shaping and dynamic range compression. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Gordon-Salant, S. Recognition of natural and time/intensity altered CVs by young and elderly subjects with normal hearing. J. Acoust. Soc. Am. 1986, 80, 1599–1607. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chermaz, C.; King, S. A sound engineering approach to near end listening enhancement. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020. [Google Scholar]
- Schepker, H.; Rennies, J.; Doclo, S. Speech-in-noise enhancement using amplification and dynamic range compression controlled by the speech intelligibility index. J. Acoust. Soc. Am. 2015, 138, 2692–2706. [Google Scholar] [CrossRef] [PubMed]
- Schepker, H.; Hülsmeier, D.; Rennies, J.; Doclo, S. Model-based integration of reverberation for noise-adaptive near-end listening enhancement. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Resden, Germany, 6–10 September 2015. [Google Scholar]
- Chermaz, C.; Valentini-Botinhao, C.; Schepker, H.F.; King, S. Evaluating Near End Listening Enhancement Algorithms in Realistic Environments. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 1373–1377. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R. Speech energy redistribution for intelligibility improvement in noise based on a perceptual distortion measure. Comput. Speech Lang. 2014, 28, 858–872. [Google Scholar] [CrossRef]
- Li, H.; Fu, S.-W.; Tsao, Y.; Yamagishi, J. iMetricGAN: Intelligibility Enhancement for Speech-in-Noise using Generative Adversarial Network-based Metric Learning. arXiv 2020, arXiv:2004.00932. [Google Scholar]
- Schädler, M. Optimization and evaluation of an intelligibilityimproving signal processing approach (IISPA) for the Hurricane Challenge 2.0 with FADE. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 1331–1335. [Google Scholar]
- Mertins, A.; Mei, T.; Kallinger, M. Room impulse response shortening/reshaping with infinity-and $ p $-norm optimization. IEEE Trans. Audio Speech Lang. Process. 2009, 18, 249–259. [Google Scholar] [CrossRef]
- Kusumoto, A.; Arai, T.; Kinoshita, K.; Hodoshima, N.; Vaughan, N. Modulation enhancement of speech by a pre-processing algorithm for improving intelligibility in reverberant environments. Speech Commun. 2005, 45, 101–113. [Google Scholar] [CrossRef]
- Arai, T.; Hodoshima, N.; Yasu, K. Using steady-state suppression to improve speech intelligibility in reverberant environments for elderly listeners. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 1775–1780. [Google Scholar] [CrossRef] [Green Version]
- Petkov, P.N.; Stylianou, Y. Adaptive gain control for enhanced speech intelligibility under reverberation. IEEE Signal Process. Lett. 2016, 23, 1434–1438. [Google Scholar] [CrossRef]
- Grosse, J.; van de Par, S. A speech preprocessing method based on overlap-masking reduction to increase intelligibility in reverberant environments. J. Audio Eng. Soc. 2017, 65, 31–41. [Google Scholar] [CrossRef]
- Arai, T.; Kinoshita, K.; Hodoshima, N.; Kusumoto, A.; Kitamura, T. Effects of suppressing steady-state portions of speech on intelligibility in reverberant environments. Acoust. Sci. Technol. 2002, 23, 229–232. [Google Scholar] [CrossRef] [Green Version]
- Hodoshima, N.; Arai, T.; Kusumoto, A.; Kinoshita, K. Improving syllable identification by a preprocessing method reducing overlap-masking in reverberant environments. J. Acoust. Soc. Am. 2006, 119, 4055–4064. [Google Scholar] [CrossRef]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time–frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Masri, P.; Bateman, A. Imroved Modelling of Attack Transients in Music Analysis-Resynthesis. In Proceedings of the ICMC, Hong Kong, 19–24 August 1996. [Google Scholar]
- Collins, N. A comparison of sound onset detection algorithms with emphasis on psychoacoustically motivated detection functions. In Proceedings of the Audio Engineering Society Convention 118, Barcelona, Spain, 28–31 May 2005. [Google Scholar]
- Nocedal, J.; Wright, S. Numerical Optimization; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Fletcher, R. Practical Methods of Optimization; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Wagener, K.; Brand, T.; Kollmeier, B. Development and evaluation of a German sentence test part III: Evaluation of the Oldenburg sentence test. Z. Fur Audiol. 1999, 38, 86–95. [Google Scholar]
- Aspöck, L.; Vorländer, M.; Brinkmann, F.; Ackermann, D.; Weinzierl, S. Benchmark for Room Acoustical Simulation (BRAS). DOI 2020, 10, 14279. [Google Scholar]
- Biberger, T.; Ewert, S.D. The role of short-time intensity and envelope power for speech intelligibility and psychoacoustic masking. J. Acoust. Soc. Am. 2017, 142, 1098–1111. [Google Scholar] [CrossRef] [PubMed]
- Ewert, S.D. AFC—A modular framework for running psychoacoustic experiments and computational perception models. In Proceedings of the international conference on acoustics AIA-DAGA, Merano, Italy, 18–21 March 2013; pp. 1326–1329. [Google Scholar]
- Van De Par, S.; Kot, V.; Van Schijndel, N. Scalable noise coder for parametric sound coding. In Audio Engineering Society 118; Audio Engineering Society: Barcelona, Spain, 2005; p. 699. [Google Scholar]
- Rennies, J.; Schepker, H.; Valentini-Botinhao, C.; Cooke, M. Intelligibility-enhancing speech modifications–the hurricane challenge 2.0. In Proceedings of the 2020 Interspeech, Shanghai, China, 25–29 October 2020; pp. 3552–3556. [Google Scholar]
- Bederna, F.; Schepker, H.; Rollwage, C.; Doclo, S.; Pusch, A.; Bitzer, J.; Rennies, J. Adaptive compressive onset-enhancement for improved speech intelligibility in noise and reverberation. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Room | Name in Database | Length of P Frames (s) | Main BRIR | BRIR for Robustness Evaluation | BRIR of Noise | |
|---|---|---|---|---|---|---|
| R1 | VarEcoic | 0.60 | 0.25 | kas_none_r00_az000 | kas_none_r00_az060 | kas_none_r00_az030 |
| R2 | Music Hall | 1.1 | 0.45 | CR3_BRIR_LS7_MP6_HATO0 | CR3_BRIR_LS5_MP6_HATO0 | CR3_BRIR_LS3_MP6_HATO0 |
| R3 | Seminar Room | 1.5 | 0.6 | CR2_BRIR_LS7_MP6_HATO0 | CR2_BRIR_LS4_MP6_HATO0 | CR2_BRIR_LS3_MP6_HATO0 |
| R4 | Church | 5.0 | 1 | air_binaural_aula_carolina_1_1_3_90 | air_binaural_aula_carolina_1_1_2_90_3 | air_binaural_aula_carolina_1_1_3_135_3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fallah, A.; van de Par, S. A Speech Preprocessing Method Based on Perceptually Optimized Envelope Processing to Increase Intelligibility in Reverberant Environments. Appl. Sci. 2021, 11, 10788. https://0-doi-org.brum.beds.ac.uk/10.3390/app112210788
Fallah A, van de Par S. A Speech Preprocessing Method Based on Perceptually Optimized Envelope Processing to Increase Intelligibility in Reverberant Environments. Applied Sciences. 2021; 11(22):10788. https://0-doi-org.brum.beds.ac.uk/10.3390/app112210788
Chicago/Turabian StyleFallah, Ali, and Steven van de Par. 2021. "A Speech Preprocessing Method Based on Perceptually Optimized Envelope Processing to Increase Intelligibility in Reverberant Environments" Applied Sciences 11, no. 22: 10788. https://0-doi-org.brum.beds.ac.uk/10.3390/app112210788