5.3.2. SFPI Dataset
We perform multiple experiments with the SFPI dataset by dividing the dataset in different ways. Before we dive deeper into different experiments and their details, first, we lay down some experiment labels for better understanding in
Table 3. These labels will be used throughout the paper. In general, the used naming convention is model_dataset_train_dataset_ test.
In our SFPI dataset, we have 10,000 images to perform experiments. First, we will present the results between the SESYD [
3] dataset and our SFPI dataset in
Table 4.
For our SFPI dataset, we followed the 70-15-15 rule to split the dataset. We take 7000 images for training and 1500 images for validation and testing. With the number of increased images and objects, we can see the improvement in the results of our proposed model. We achieve a 0.995 mAP score and 0.997 mAR score. This clearly shows that our model performs better on the SFPI dataset where we have sufficient images to train a model as compared to less number of images we have in SESYD [
3].
We further execute more experiments, including the SFPI and SESYD [
3] datasets, to get more generalized results from our end-to-end model.
In the second experiment Our_SFPI_train_SESYD_test mentioned in
Table 5, we use the full SFPI dataset for training, which means all 10,000 images are used to train our end-to-end model. We use the SESYD [
3] dataset for validation and testing. We perform a random split on the SESYD [
3] dataset and use 500 images for validation and 500 for testing. In this way, we can compare how our network performs with a generalized dataset. Moreover, we can establish similarities and dissimilarities between our SFPI dataset and the SESYD [
3] dataset. We can achieve good results in this experiment if we compare it to the results of Ziran et al. [
9].
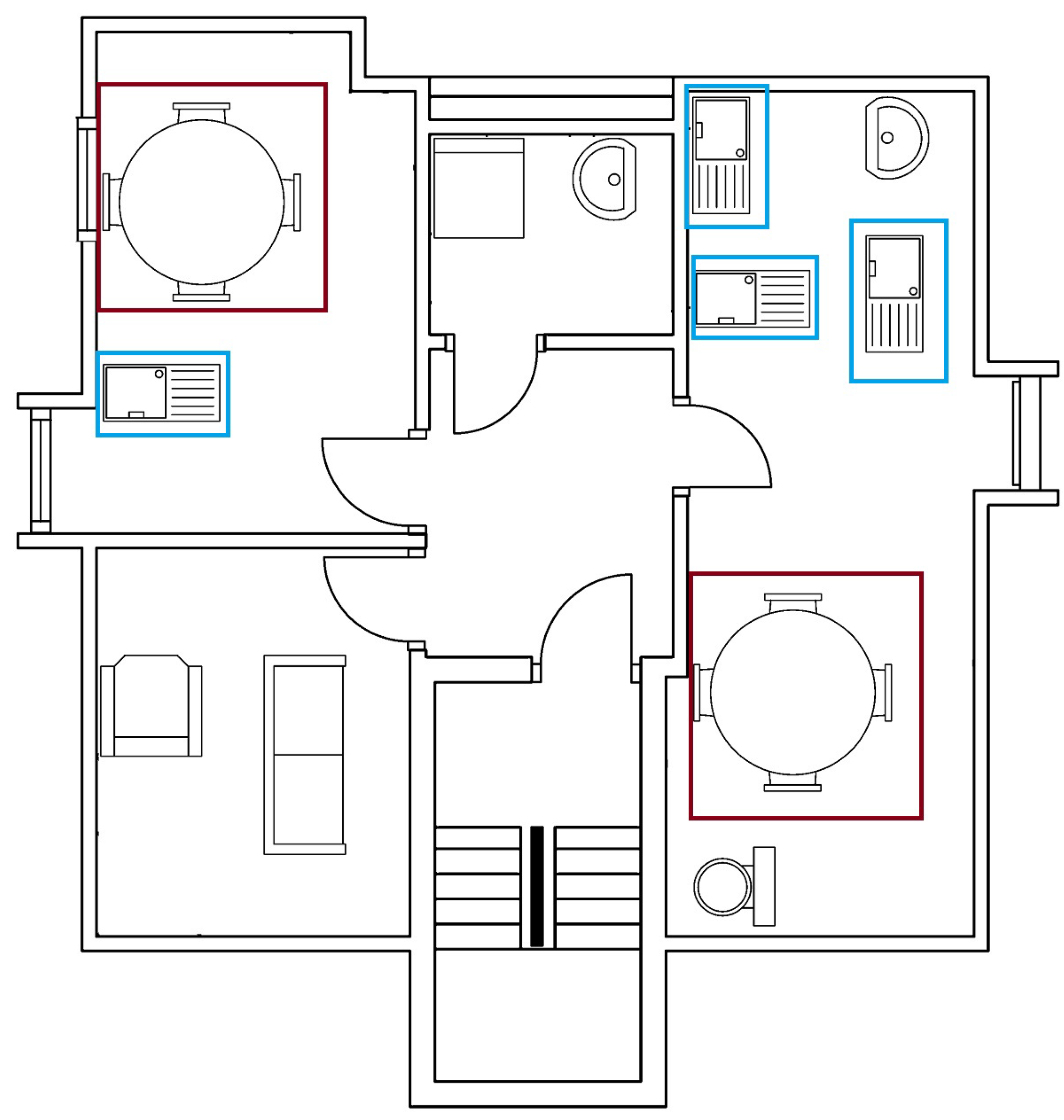
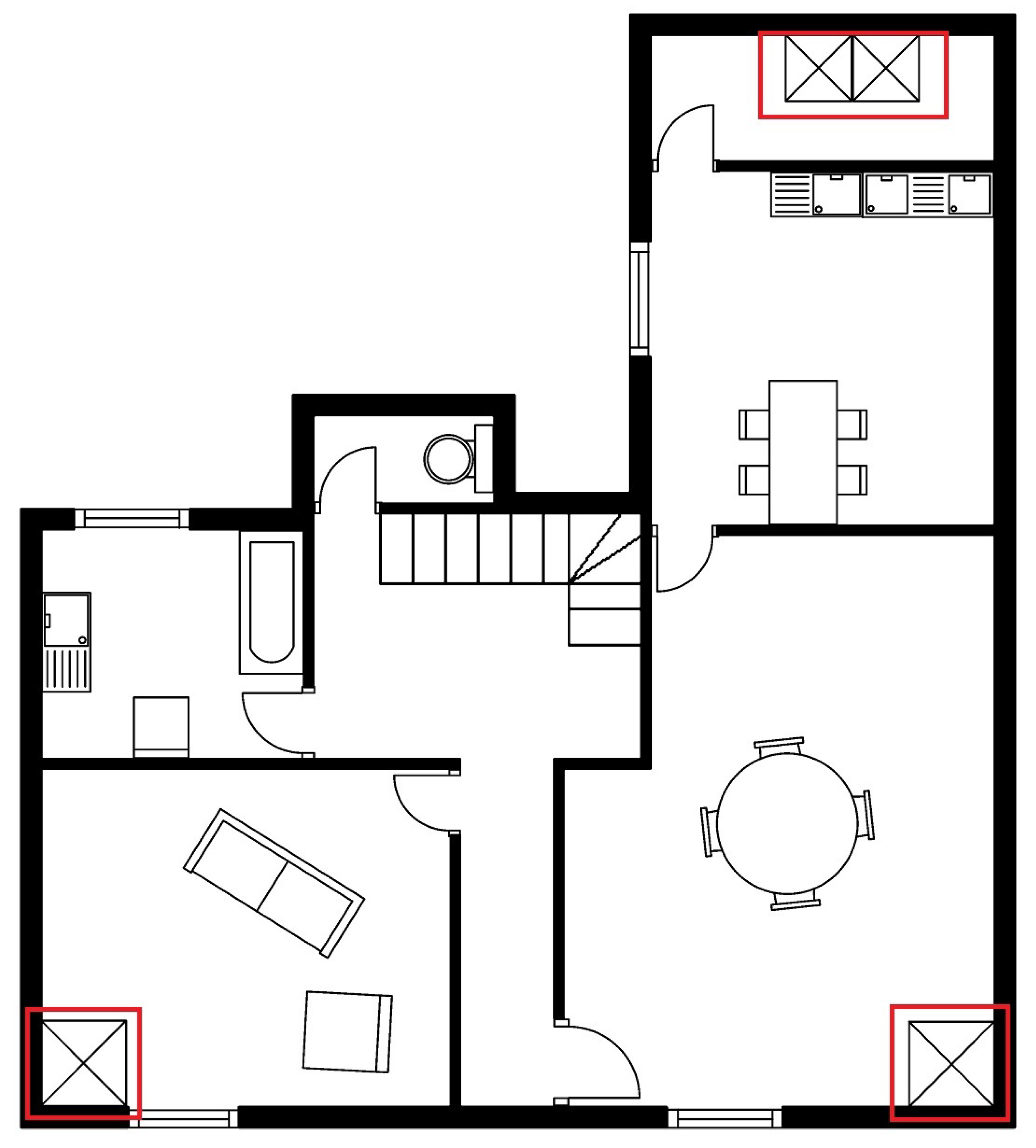
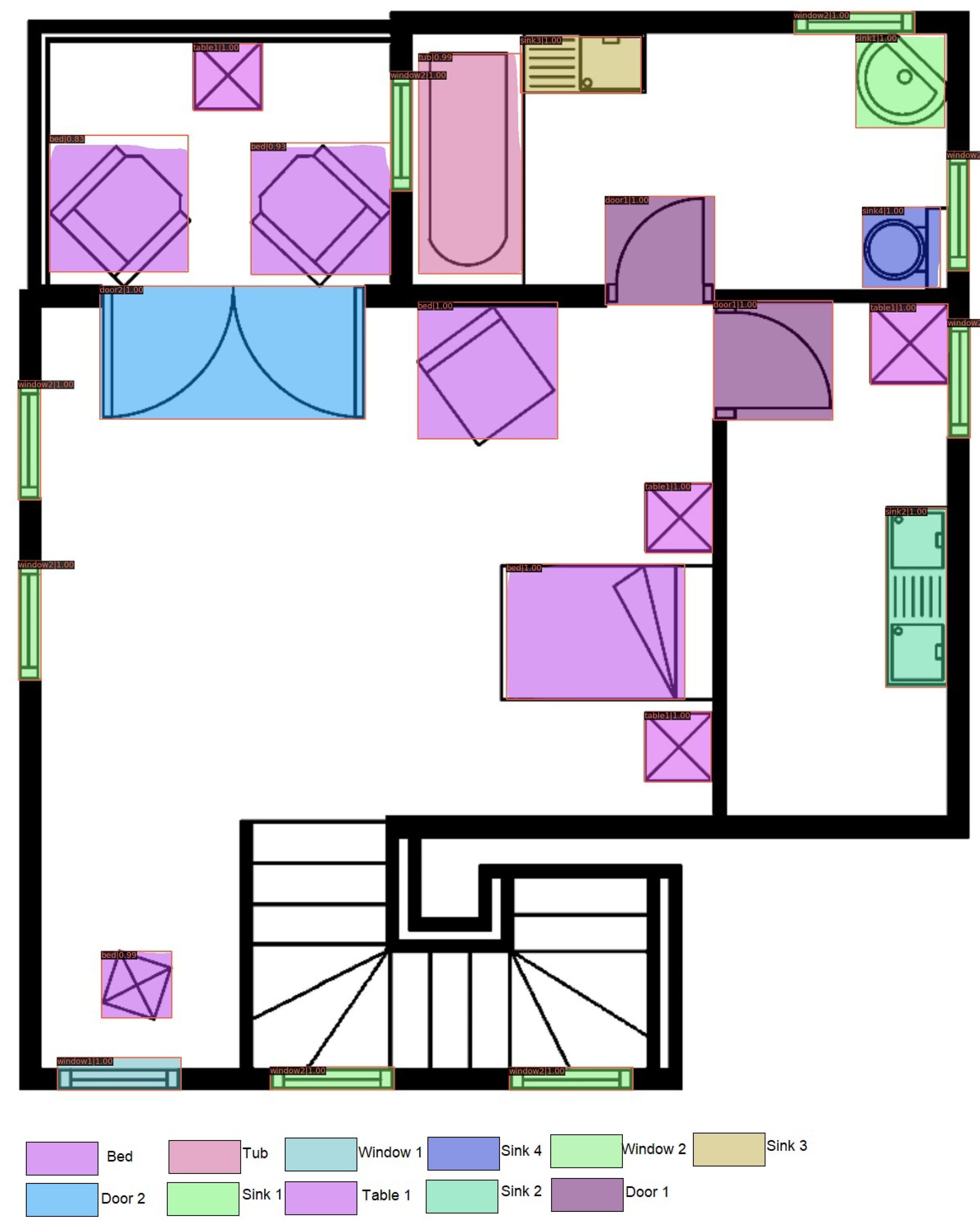
Figure 9 is the output of the experiment Our_SFPI_train_SESYD_test. Few classes are misclassified; for the most part, the network confuses between armchair, sofa, and bed classes. We see many instances where sofa or armchair classes are recognized as the bed. This might be because of the data augmentation we put in the SFPI dataset, whereas in SESYD [
3] furniture objects are not that much augmented, and in some scenarios sofa and armchair resembles a bed. To improve the results, we perform our next experiment, Our_SFPI_SESYD_train_SESYD_test, where we use close domain fine-tuning. In Close domain fine-tuning, we fine-tune models using datasets that are closer to the domain of our problem rather than using natural images, which we do when we apply fine-tuning.
In our next experiment Our_SFPI_SESYD_train_SESYD_test, we combine both the SFPI dataset and the SESYD [
3] dataset. For training, we use 10,500 images, out of which 10,000 images are from the SFPI dataset, and we pick 500 random images from SESYD [
3] dataset. Out of the remaining 500 images of the SESYD [
3] dataset, 250 are used for validation, and 250 are used for testing. With the close domain fine-tuning, our model improves, and we get better results. We can achieve a 0.997 mAP score and 0.998 mAR score, which is even better than our experiment Our_SESYD_train_test, where we used the SFPI dataset only for training, validation, and testing. This indicates the advantages of using closed domain fine-tuning.
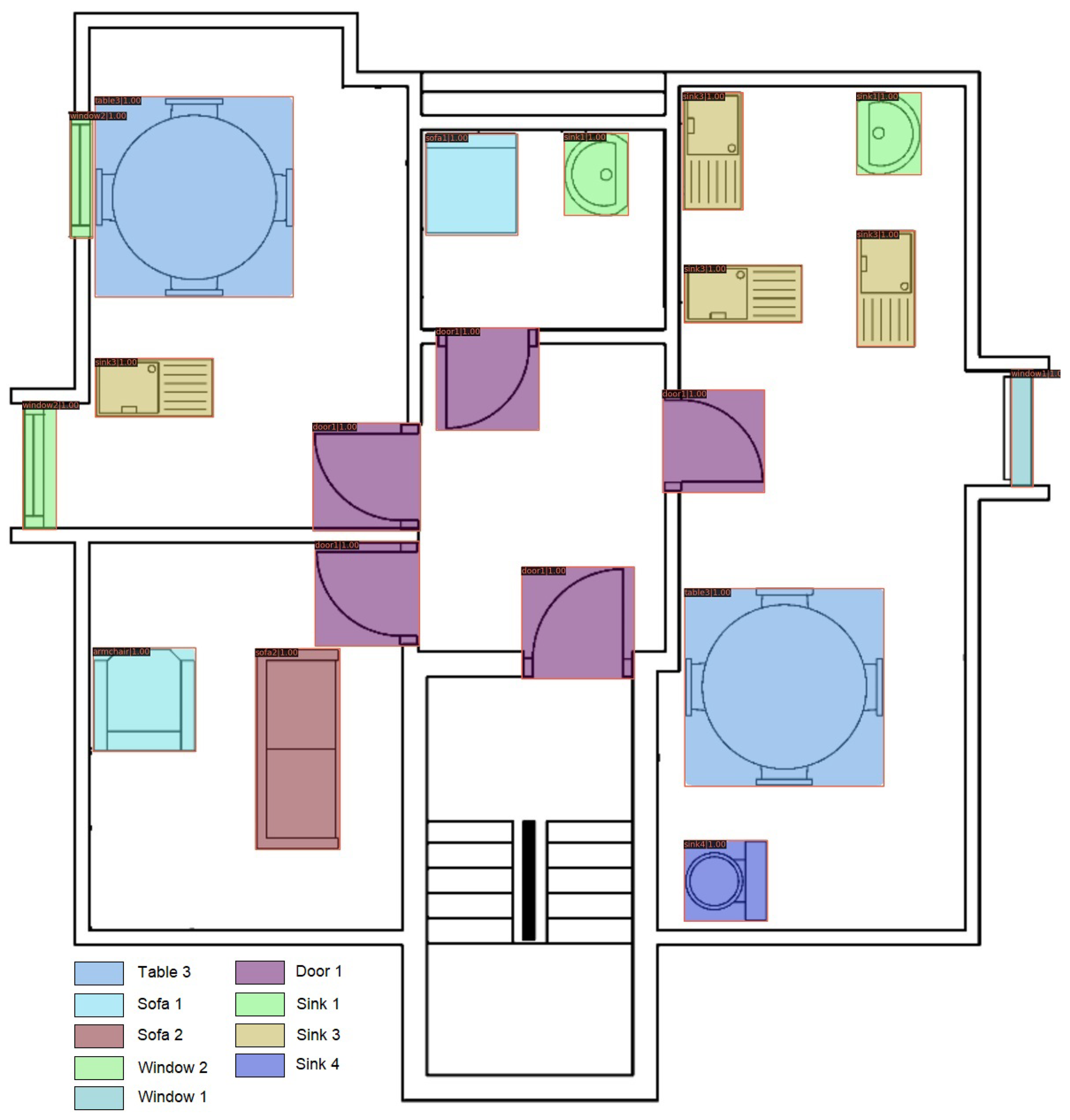
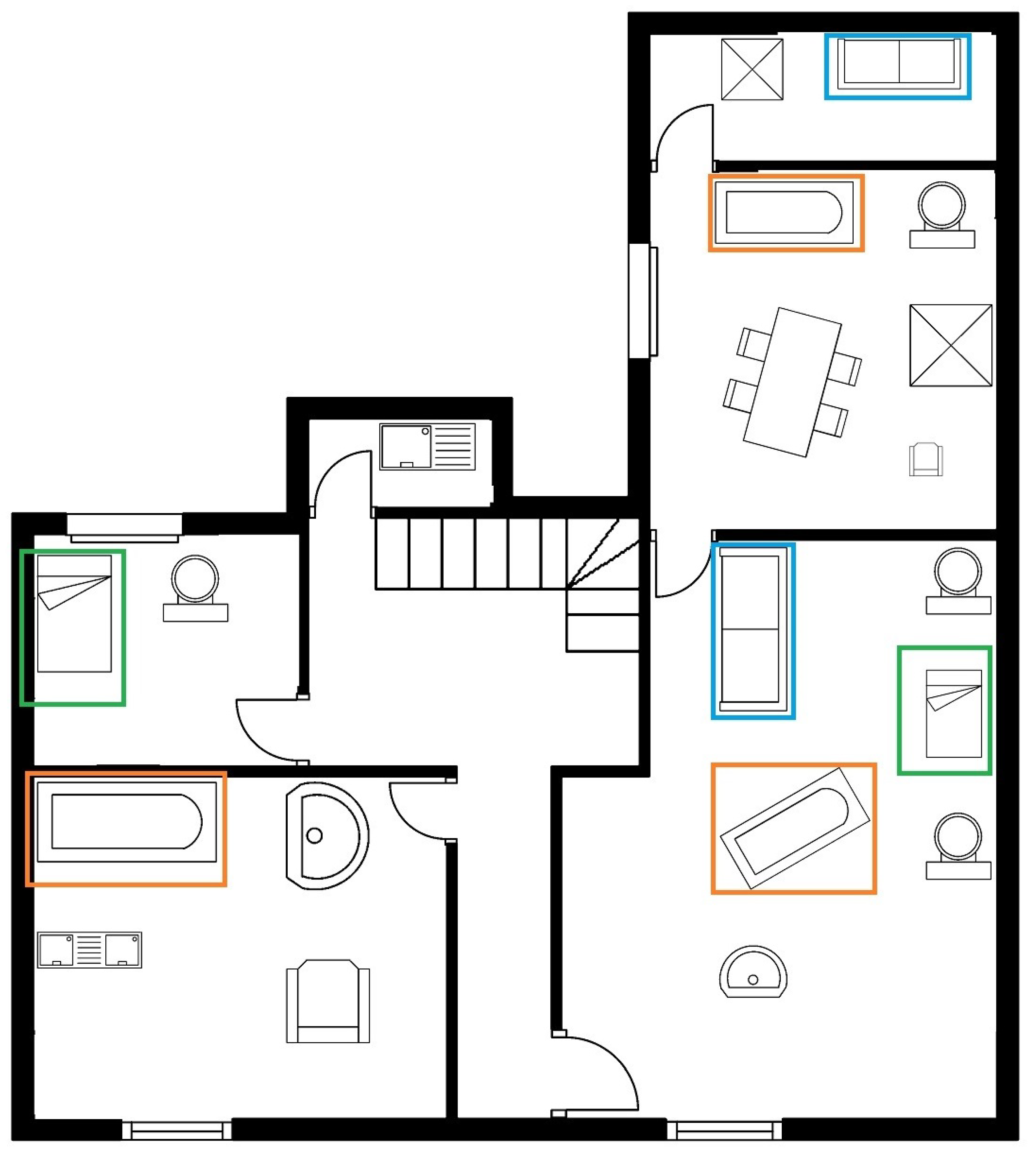
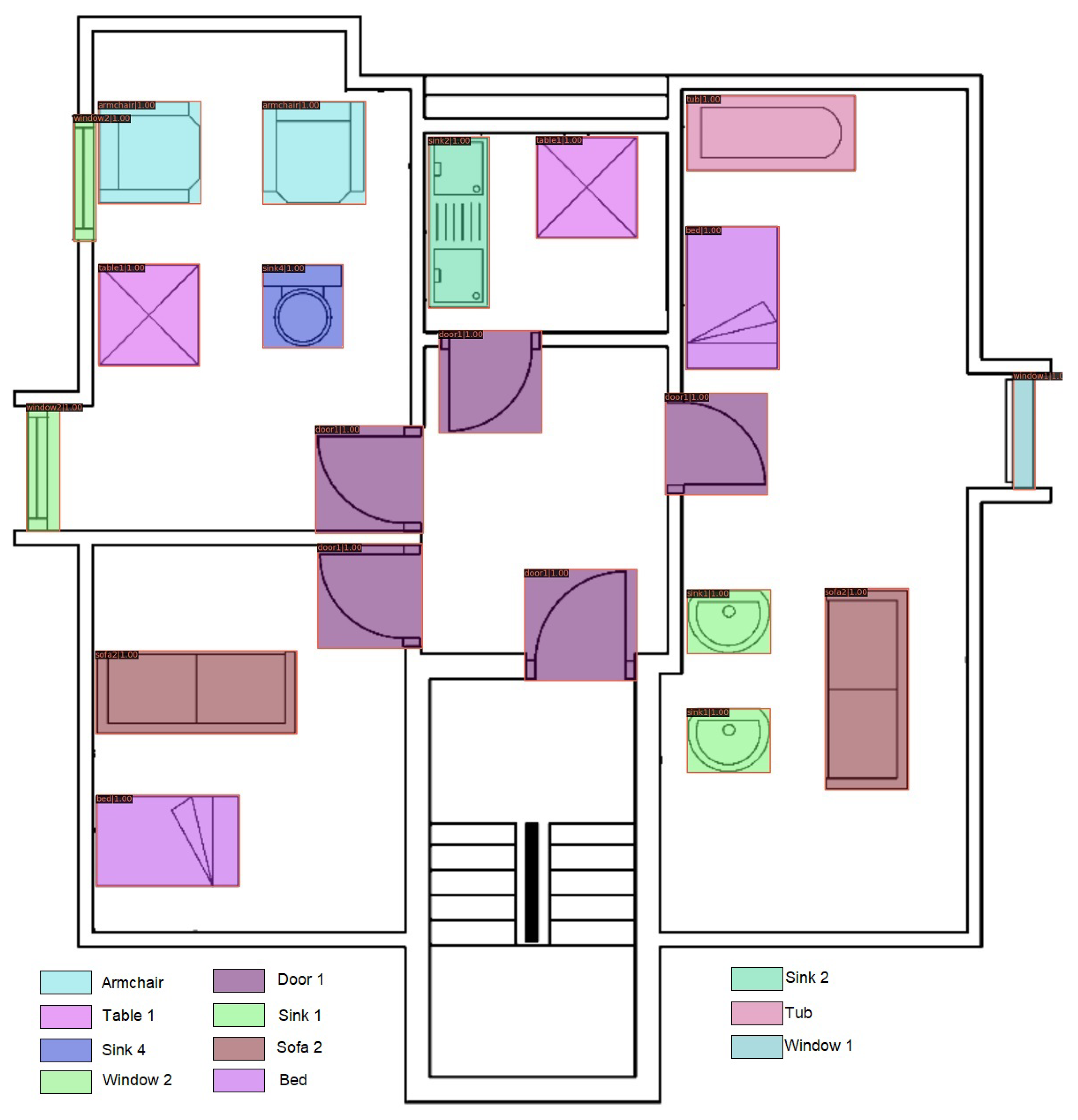
Figure 10 is the final output of our proposed model in the case of experiment Our_SFPI_ SESYD_train_SESYD_test. The image shows that all furniture objects are correctly classified with a good confidence score. In image
Figure 10 we can observe good furniture augmentation, as discussed earlier. Our proposed model can generalize well given the context of the two datasets SFPI and SESYD [
3] object detection and localization worked perfectly.
In
Table 6, we described the class-wise average precision score achieved in our experiment Our_SFPI_SESYD_train_SESYD_test. It is visible from the
Table 6 that for few classes, we have reached the average precision of one like Door, Bed, and Tub, whereas for the other remaining classes, the score is high, and except Window1 class, all other classes already reached above 0.90 average precision. This class-wise AP result gives us more clarity about model performance. We can identify where our model works well and what classes are causing problems.
For completeness of the paper, we computed the mAP score on various IoU thresholds ranging from 0.5 to 1.0. We performed this for all of our three experiments.
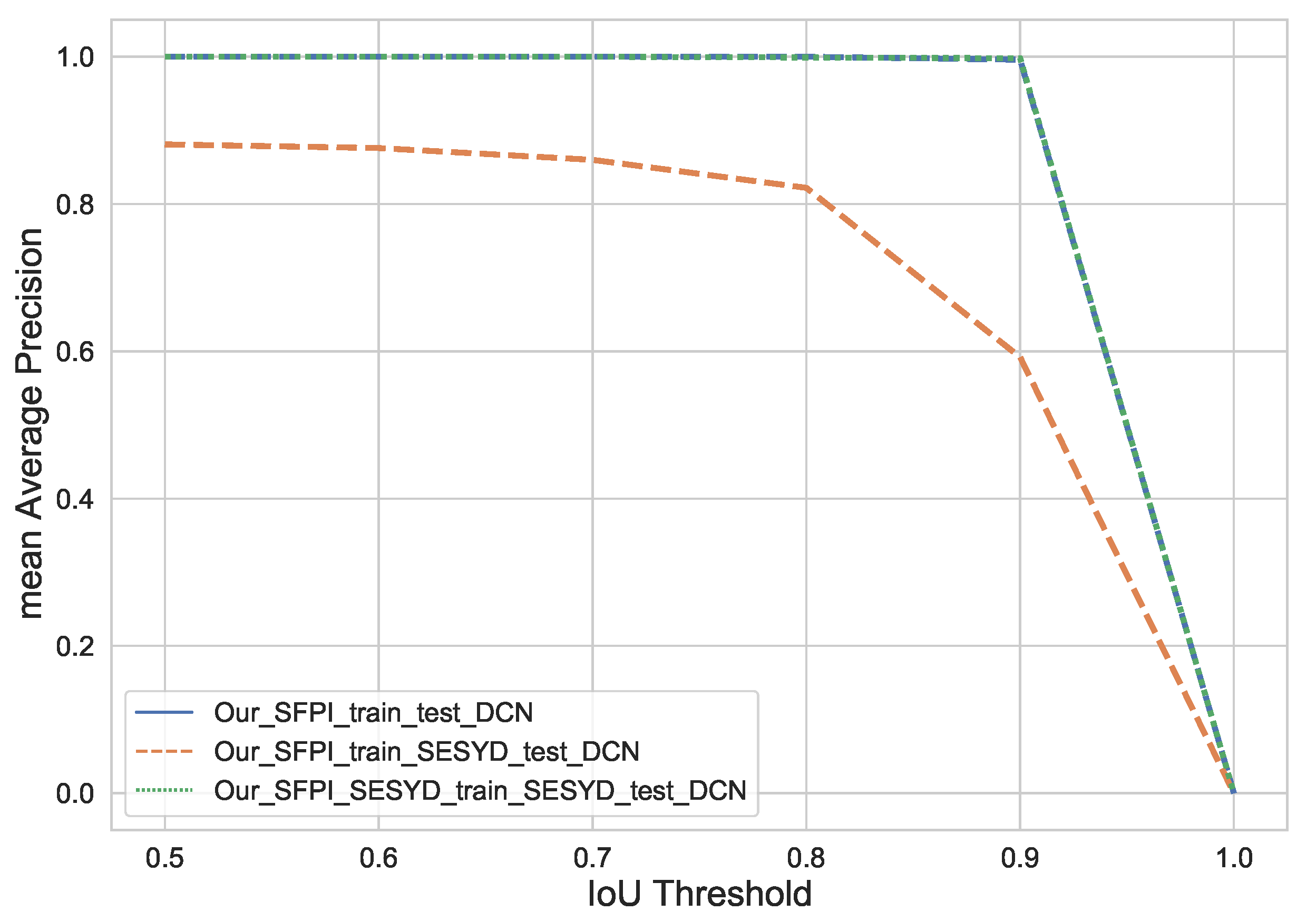
Figure 11 illustrates the performance of our approach in terms of mean average precision. We can see that we can achieve mAP score of one for Our_SESYD_train_test, 0.861 in the case of Our_SFPI_train_SESYD_test, and 0.936 for Our_SFPI_SESYD_train_SESYD_test when the IoU is set to 0.5. From this point onwards, as we increase, the IoU mAP is decreasing for the latter mentioned two experiments. For experiment Our_SFPI_train_SESYD_test and experiment Our_SFPI_SESYD_train_SESYD_after the IoU threshold of 0.8, mAP is equal. The mAP score eventually reaches zero when we set the IoU to 1 for all experiments.
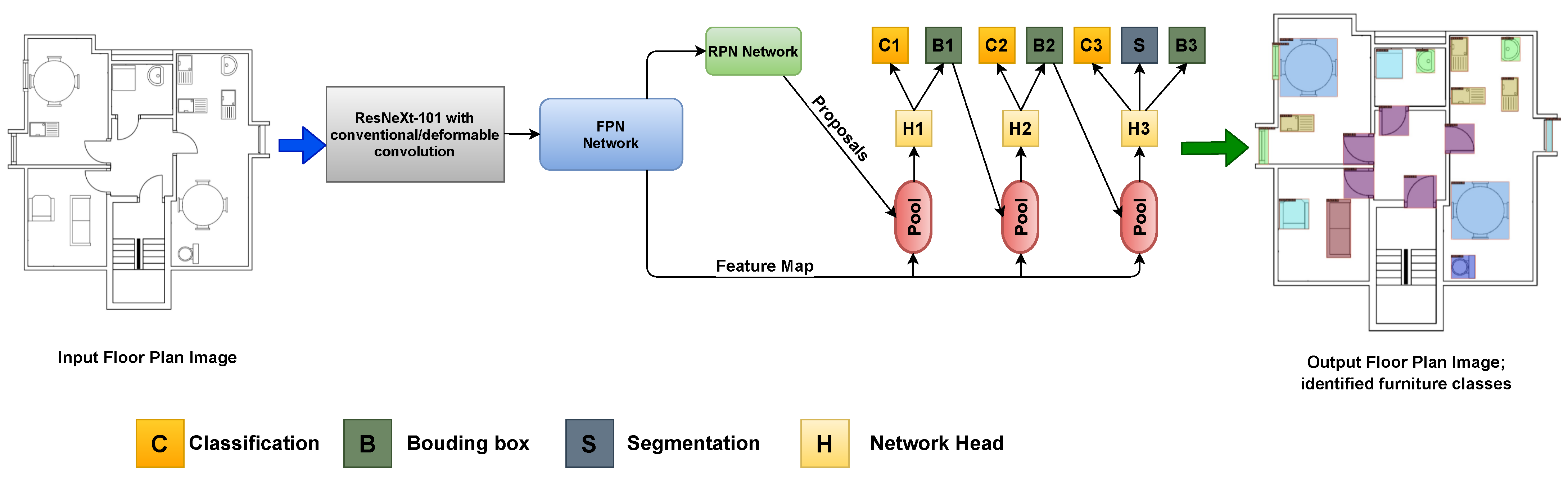
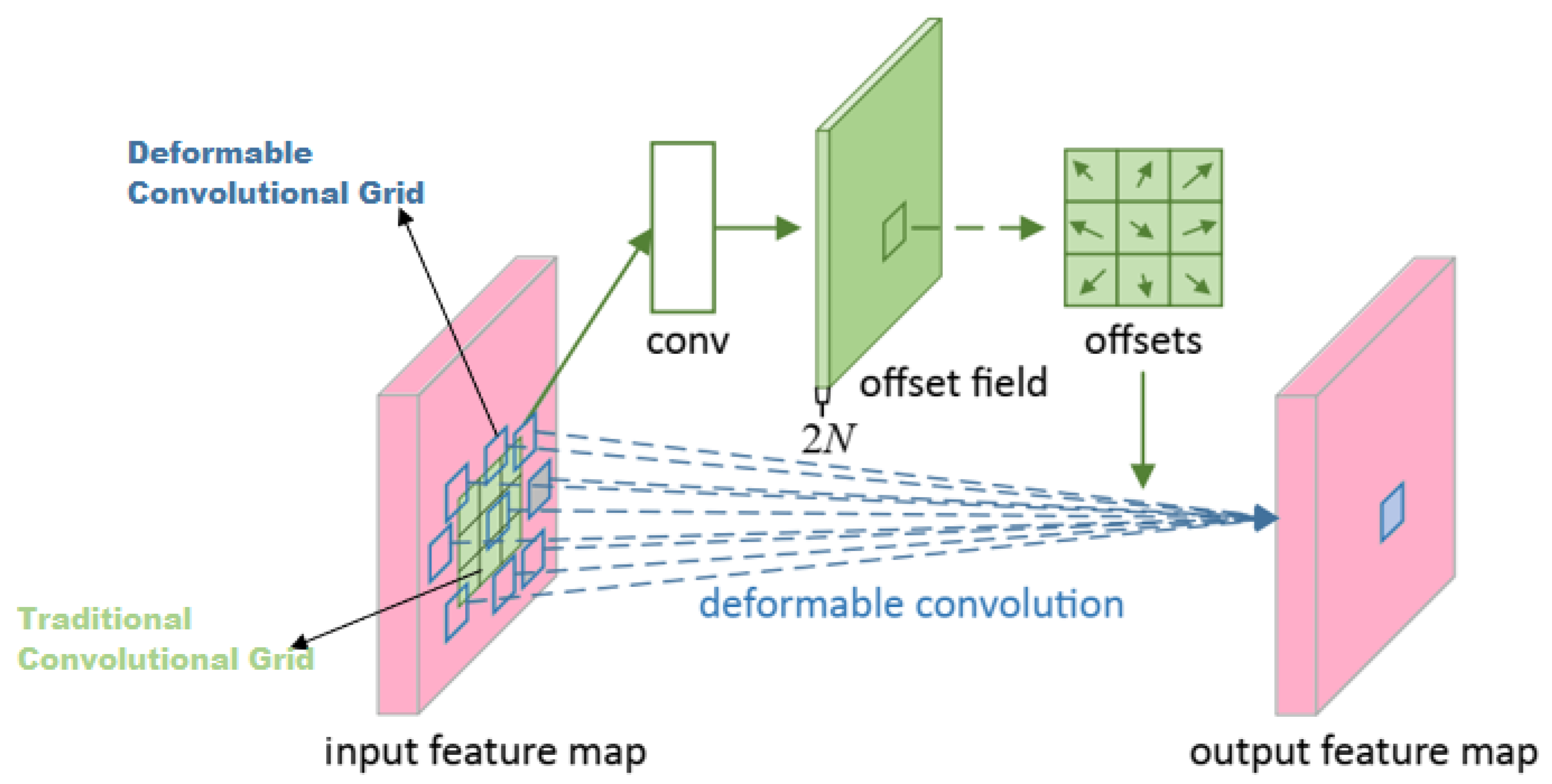
Until this point, we were only deploying conventional convolutional networks, but we want to apply our model with deformable convolution network (DCN) [
16] as well. DCN [
16] could be useful for our datasets as they can easily adapt the shape of unknown complex transformations in the input. DCN’s [
16] are helpful when we have huge data augmentation in the dataset, to identify different transformations of the same objects. We performed all three experiments with backbone ResNeXt-101 [
17] along with deformable convolutions [
16]. All other specifications of the experiments such as dataset split and Cascade Mask R-CNN [
15] remain the same as they are for backbone ResNeXt-101 [
17] with traditional convolution (CNN).
In
Table 7, we present the quantitative analysis of all experiments we have performed with our end-to-end model. We can identify that using deformable convolution [
16] enhances the results of our model. In our experiment Our_SESYD_train_test with conventional convolution (CNN), we can achieve a mAP of 0.995 and a mAR of 0.997, whereas when we changed the backbone to use deformable convolution [
16], the overall score improved to 0.998 for mAP and 0.999 for mAR, which is close to the perfect score. For our experiment, our_SFPI_train_SESYD_test, where we are using the SFPI dataset for training and the SESYD [
3] dataset for testing and validation, with CNN backbone, we get a score of 0.750 for mAP and 0.775 for mAR, whereas when we used a deformable convolution [
16], the score improved, and we obtained 0.763 for mAP and 0.783 for mAR. This indicates that deformable convolution can be helpful to get more generalized object detection. In our experiment Our_SFPI_SESYD_train_SESYD_test, we performed closed domain fine-tuning on our model and achieved our best result until now, which was a 0.997 score for mAP and 0.998 score for mAR. This further improves when we use a deformable convolution [
16] for closed domain fine-tuning; we achieved a score of 0.998 for mAP and 0.999 for mAR. This is the best result among all experiments we performed on the SFPI dataset, as well as other experiments we came across during the literature survey for object detection in floor plan images.
We perform all our experiments with backbone ResNeXt-101 [
17] combining deformable convolutions (DCN) [
16] on different IoU thresholds.
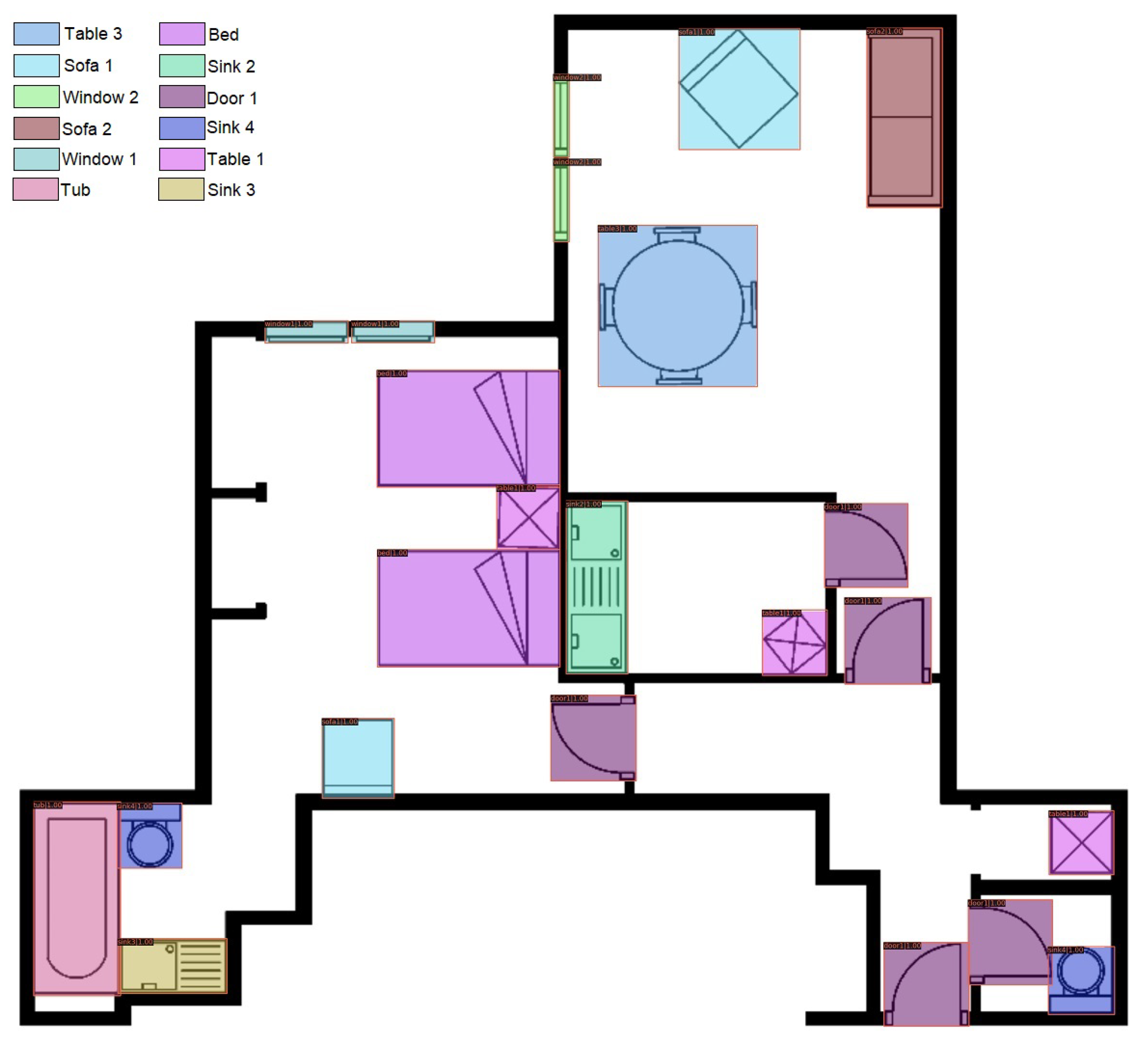
Figure 12 depicts the performance of our model during each experiment on different IoU thresholds. Our_SFPI_train_test and Our_SFPI_SESYD_train_SESYD_test result in the same mAP score, whereas for Our_SFPI_train_SESYD_test, we start with a mAP score of 0.881 for 0.5 IoU threshold. Our_SFPI_train_test and Our_SFPI_SESYD_train_SESYD_test gives a constant mAP score until the IoU threshold 0.9, whereas we see a constant decrease in the mAP score of Our_SFPI_train_SESYD_test. Eventually, all three experiments will end up on a mAP score of zero when we set the IoU to 1. The final output of experiment Our_SFPI_SESYD_train_ SESYD_test_DCN is available in the
Figure 13.
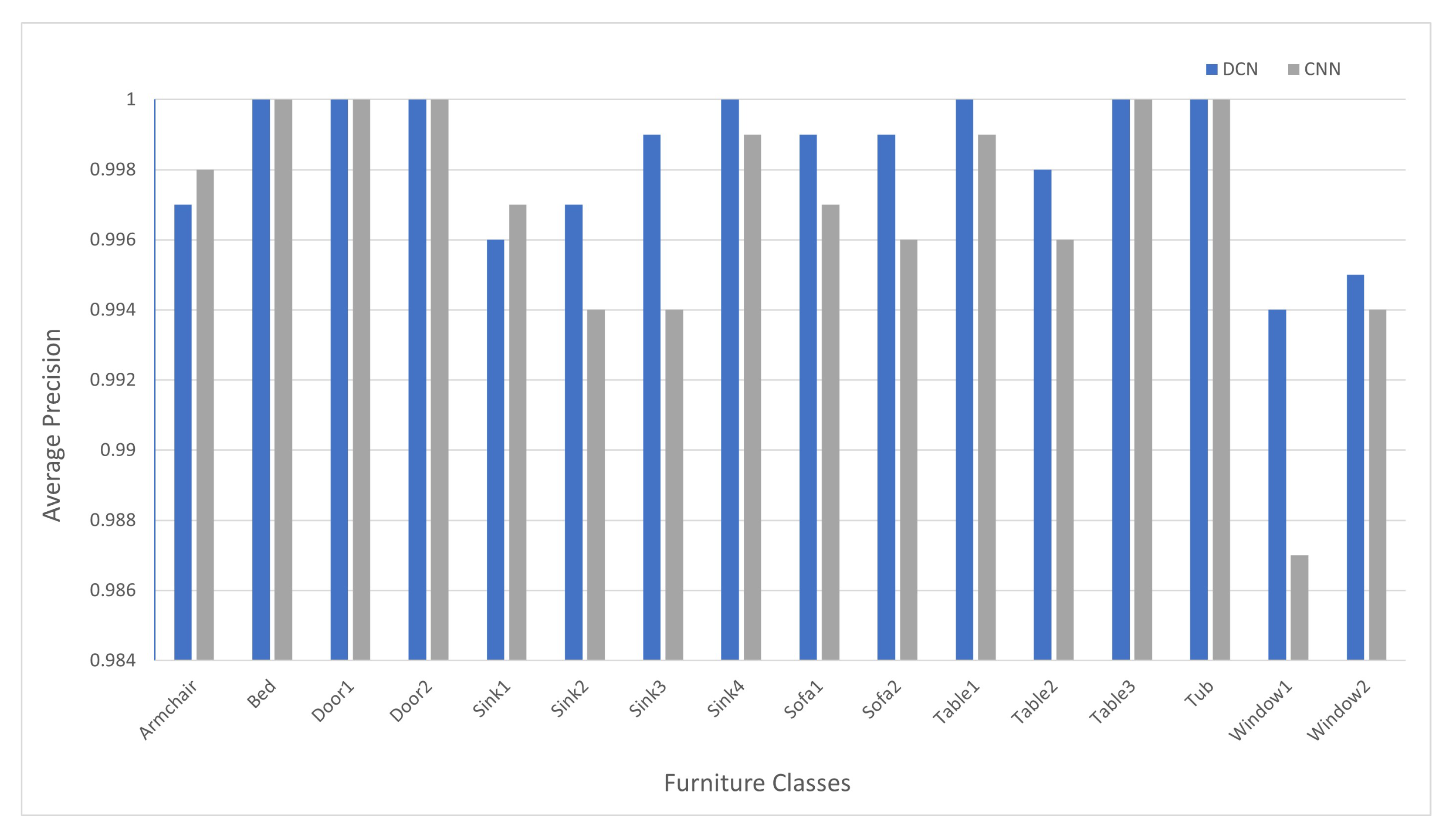
We can take a better look at individual furniture classes with respective accuracy in
Table 8. Comparing this result
Table 8 with the class-wise result we have obtained in
Table 6 improvements are clearly visible. Comparison of these two class-wise results is available in
Figure 14. The figure illustrates that scores for Sink2 and Sink3 furniture classes have been improved. When we verify the images of these two classes, we can recognize that these classes have many similarities, and using DCN helps our model differentiate and recognize each class more precisely. We can also see the major improvement in Window1 and Window2 classes; these classes are also difficult to distinguish, and that is where we take advantage of deformable convolution [
16] to improve the overall score. In conclusion, we can see that most of the furniture classes either have a score of one or close to one.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}