
A Multilayer CARU Framework to Obtain Probability Distribution for Paragraph-Based Sentiment Analysis


1
School of Applied Sciences, Macao Polytechnic Institute, Macao, China
2
Engineering Research Centre of Applied Technology on Machine Translation and Artificial Intelligence, Ministry of Education, Macao Polytechnic Institute, Macao, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2021, 11(23), 11344; https://0-doi-org.brum.beds.ac.uk/10.3390/app112311344
Submission received: 18 September 2021
/
Revised: 15 November 2021
/
Accepted: 15 November 2021
/
Published: 30 November 2021
(This article belongs to the Special Issue Advances in Artificial Intelligence Methods for Natural Language Processing)
Abstract
:Paragraph-based datasets are hard to analyze by a simple RNN, because a long sequence always contains lengthy problems of long-term dependencies. In this work, we propose a Multilayer Content-Adaptive Recurrent Unit (CARU) network for paragraph information extraction. In addition, we present a type of CNN-based model as an extractor to explore and capture useful features in the hidden state, which represent the content of the entire paragraph. In particular, we introduce the Chebyshev pooling to connect to the end of the CNN-based extractor instead of using the maximum pooling. This can project the features into a probability distribution so as to provide an interpretable evaluation for the final analysis. Experimental results demonstrate the superiority of the proposed approach, being compared to the state-of-the-art models.
1. Introduction
Sentiments can be reflected as the voluntary or involuntary reactions of human beings to the outside world when they conduct behaviors, such as talking, thinking, communicating, learning, and decision making. Since all these and similar behaviors can be expressed in sentences and paragraphs, sentiment analysis tasks have great significance to our daily life. In order to extract the features and behaviors of emotions, there are a variety of studies on sentiment analysis. Generally, negative sentiments affect people’s bodies and minds, and positive sentiments make people more motivated in society and bring better, improving conditions [1]. However, sentiment analysis is a kind of abstract high-level pattern recognition without objective results, that makes such tasks challenging [2]. Moreover, there are often situations impacted by the current emotions, and the use of words and structures of the presented sentence also change accordingly. This kind of sequences makes the analysis process more difficult and time-consuming. For these reasons, a computer-based system with an effective neural network model is needed [3].
Natural language processing (NLP) methods require a lot of feature extraction and expression of a sentence. Recurrent neural networks (RNNs) are commonly involved for NLP in the neural network approaches. In RNN-based NLP research, sentiment analysis is one of the major topics. The sentiment reflected from a paragraph can be considered through some features, including part-of-speech, the length of a sentence, and the content of a structure. Mikolov et al. [4] was the first to apply a linear RNN for NLP tasks. However, this work reflects that each input feature has the same weight, and a feature often conflicts with the importance of various words. Since a word may have other meanings or a different importance level in various combinations, in particular, punctuations, prepositions, and postpositions are often less important than other words, the main information is almost always diluted if a linear RNN model is used. Therefore, deep learning-based approaches enable the learning of high-level features of the sentiment. An advanced RNN was proposed by Marcheggiani et al. [5] to deal with multiple aspects within a single sentence. Furthermore, Alborneen et al. [6] proposed a multilayer architecture that could obtain better accuracy on multiple benchmark datasets. In addition, Hazarika et al. [7] extracted multiple aspects per sentence by using long short-term memory (LSTM) networks. Further, to exploit the relationship between part-of-speech and sentiment terms, a Content-Adaptive Recurrent Unit (CARU) was designed by Chan et al. [8]. However, the above methods are targeted for the sentence-based input features, that perform poorly for the paragraph-based cases. Because all RNN models so far have only been able to consider the current and previous contents of a sequence, if we want to consider the trailing content to achieve a complete sentence understanding, we must find a new network model, which is beyond the capabilities of the RNN units.
In this article, we propose a hybrid neural network model stacking a multilayer CARU structure in the flow with the Chebyshev pooling in order to obtain the probability distribution of features for a better interpretability. We present the architecture and implementation in full detail, and provide the experiments to compare with the state-of-the-art approaches to sentiment analysis. The rest of this article is outlined as follows: Section 2 reviews the neural approaches to NLP and sentiment analysis tasks, together with their application. Section 3 first summarizes the overall architecture of our integration and the major contribution, then presents the details of the key components. We provide our concrete implementation of the network in Section 4 and discuss the experimental results in Section 5. Finally, Section 6 concludes the work.
2. Related Work
With the distinctive performance of the neural network [9], the vectorized representation of words as features has been proved to be effective in various NLP tasks, such as parsing [10] and language modeling [11]. In the field of sentiment analysis, Munikar et al. [12] first introduced the word embedding technology through a latent semantic analysis according to part-of-speech, and represented each sentence as a nonlinear weight of the multi-dimensional feature for classification. Wang et al. [13] proposed each word to map into a 2D vector forming a matrix, and the iterative multiplications of these matrices were used to combine the words. Havaei et al. [14] explored an adaptive stack noise reduction auto-encoder for a sentiment classification. Then, the matrix-vector [15] was proposed into the multilayer RNN architecture, which recursively learned phrase combinations of any lengths based on their representations. The signals are classified directly in the RNN architecture without preprocessing. The study was validated with a four-fold cross-validation and the performance of the RNN-based model was evaluated with the accuracy metric only. Each automatic encoder aims to recursively learn the combination classification syntax and sentence structures. In addition, it has been demonstrated that deeper network architectures were able to extract more complex features [16,17,18]. These types of architectures usually contain only two to four layers from the input, which can make better predictions.
Meanwhile, there are many applications of sentiment analysis in NLP tasks. Some studies employed social network information in LSTM [19], which used a deeper architecture that allowed information to be stored indefinitely in the linear RNN units. In order to overcome the problem of long short-time lags in connecting, Stewart et al. [20] showed that the social network relationships of opinion holders might bring influential biases to text models. Other approaches have used sentence features not commonly found in official documents, such as hashtags and emoticons [21]. Santos et al. [22] proposed a unified graph propagation model to utilize text features (such as emoticons) and social information. Furthermore, there are deep models for characterization learning. Bengio et al. [23,24] used distributed representations of words to combat the abuse of dimensionality when they trained neural probabilistic language models. Such word vectors reduce the syntax and semantic sparsity of the bag-of-words representation. Many recent studies have explored this representation [25] to a further extent. By stacking multiple RNNs, Graves et al. [26] introduced a hierarchical sequence processor equipped with concatenated time classification. In addition, Li et al. [27] performed sequence segmentation and recognition at the same time. Recently, the polarity information of emotional words have been effectively captured by modifying word vectors during training [28,29]. It is also insightful to analyze the embeddings that change the most during training. By comparing the initial and adjustment vectors, it shows how the adjustment vector of the task’s unique functional word can work with our proposed architecture to capture sequential information. Moreover, traditional methods are designed to detect local patterns for classification, but they are sensitive to environmental changes. Recent studies have used word vectors to alleviate the syntax and semantic sparsity of the bag-of-words representation [30]. These RNN-based methods achieved promising results and had a stronger ability to learn generalized features. Although effective, these methods still face the threat of an unstable accuracy if divergent, and it is worth exploring a better method to obtain information-rich and differentiated feature embeddings for a more accurate classification.
3. Framework
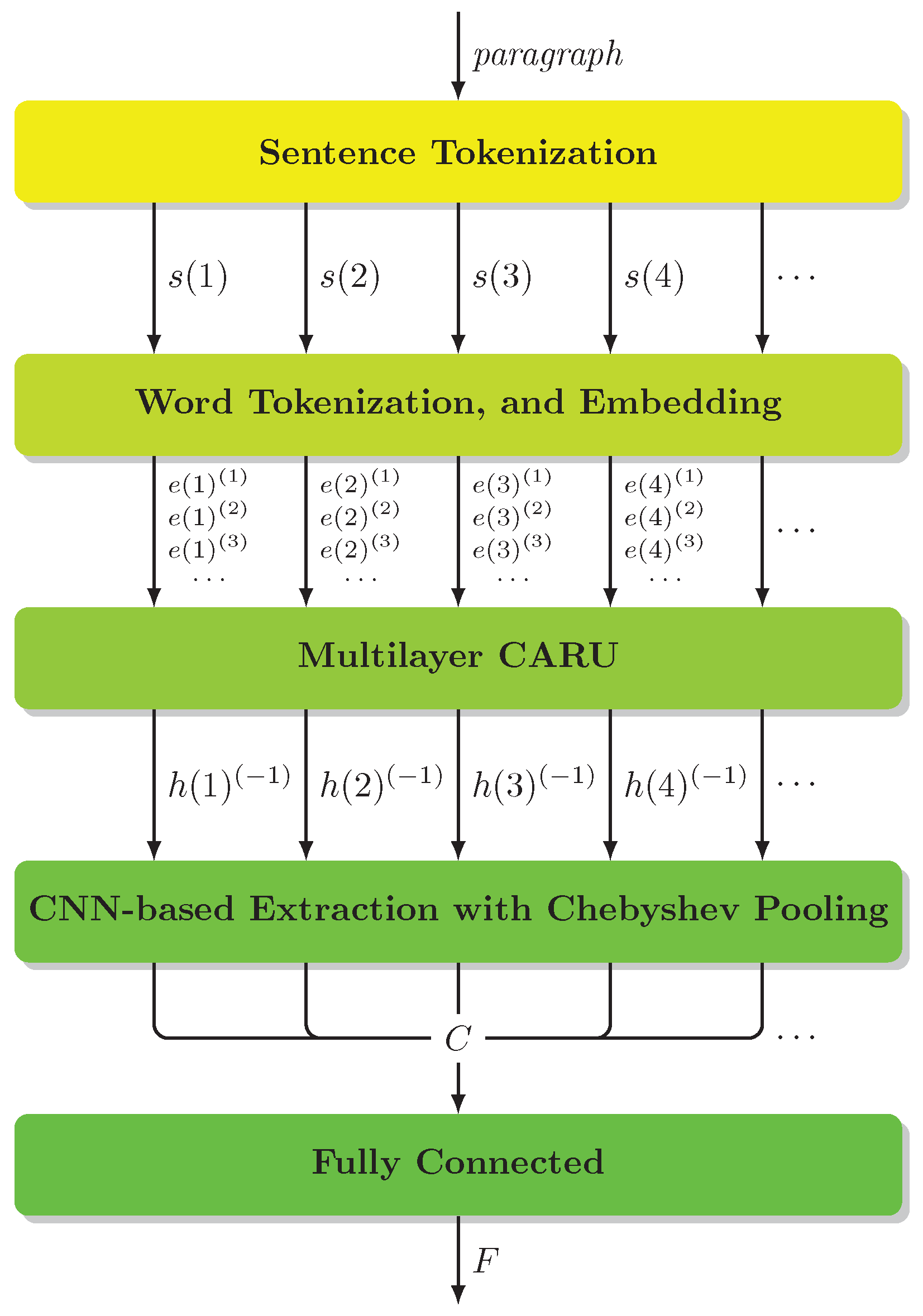
We setup a framework for our neural network that is able to embed word vectors and adapt to more situations. The overall design of the framework is illustrated in Figure 1. The framework incorporates two of our major modules, the Multilayer CARU and the Chebyshev pooling, whose details are discussed in the coming subsections.
As indicated in Figure 1, the as the input source was projected into embedded vectors by Support Vector Machine (SVM) technology [31], where Sentence/Word Tokenization could be finished in the pre-process operation. This meant each paragraph was tokenized into a sequence of sentences , and was further tokenized into a sequence of . In practice, was considered as the input tensor in size . In the terms of neural networks, t and i denote the and of the input feature passed to the Multilayer CARU (as a type of RNN layer), respectively. Then, the last hidden state produced from the Multilayer CARU was passed on to a CNN-based extractor. This part was implemented by using the VGGNet [32]. Note that, since represents the extracted information of the entire sentence , the kernel size of the convolutional layers had to cover the hidden states of each certain output size; for example, 256, was a total of in our practice. Furthermore, to perform a better extraction, we employed the Chebyshev pooling to connect to the end of the CNN-based extractor instead of using maximum pooling. Finally, the pooled result C in size was passed to the Fully Connected (FC) layer for classification and sentiment determination.
In view of this, the proposed network consisted of two stages, which also illustrated the main contribution of this work:
- The first step focused on the sentence analysis. We extended our previous work [8] to implement CARU in a multilayer architecture, where the output, i.e., a hidden state, of each CARU cell was connected to the input of the upper cell in a higher level. It also allowed different dynamic lengths of the data stream.
- The second step focused on feature extraction for the entire paragraph. After the multilayer CARU network, each sentence produced the latest hidden state for decision making. In order to extract the key information, we stacked a set of convolutional layers and then connected them through the Chebyshev pooling designed particularly for feature extraction.
3.1. Multilayer CARU
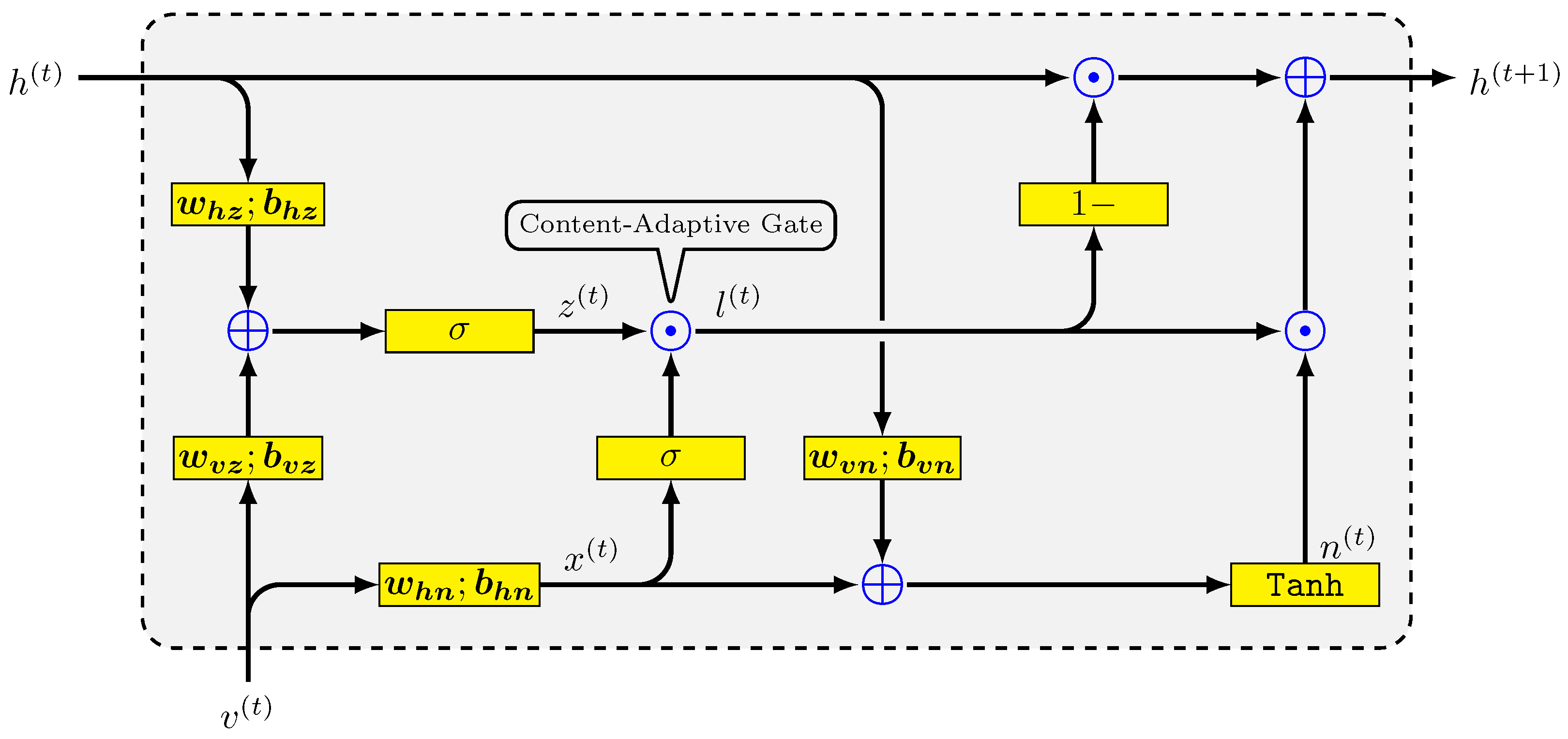
Well-designed feature extraction is crucial for the NLP tasks, having to be able to capture the subtle differences between the sentences in a paragraph. Some previous approaches leverage extra information, e.g., depth information [33], to train a more comprehensive feature extractor. To achieve this goal in our work, instead of considering extra information, we employed a multilayer CARU to obtain the discriminative embedding, because CARU and its variants have been the overall best performing RNN for NLP tasks. The multilayer CARU consisted of several stacking single CARU layers, with each layer expanding to the structure shown in Figure 2.
The single CARU architecture used the update gate and the content-adaptive gate, which required two hidden states as the input and one hidden state as the output. This could ensure the learning of the effective feature extraction for the discriminative word embedding. Based on the above considerations in multilayer CARU, each layer had its own unit, including the output features of each other. The number of layers used in the RNN could be considered as a “concrete” to “abstract” conversion in some sense, because it can be distributed in, potentially, a great many training steps. The reason we wanted to conduct this was that it may have allowed the network to calculate and fit more complex representations, which is usually the logic behind deep networks. It can be stated that the lower layer was calculating lower-level features, such as syntax, and discarding noise, and, then, the higher layer was determining high-level features, such as semantics.
The flow of the multilayer CARU is shown in Figure 3, where denotes the hidden state produced from the l-th level of the CARU layer, and t denotes the index of the input feature. Commonly, represents the embedding vector trained use GloVe technology [31], which was performed on aggregated global word2word co-occurrence statistics from a corpus, and the resulting representations showcased interesting linear substructures of the vector space. In practice, it could also be considered as hidden state . Therefore, the current hidden state could be generated by the following formula,
After processing all the layers, the hidden state produced from the last unit of the highest level was passed to the subsequent module. In our design, the lower layer received the original features. This layer roughly determined the part-of-speech of each word, and also discarded the noise, such as punctuation. After extracting the major features, the states were further processed by higher layers. Since the advantage of CARU is the content analysis, its content-adaptive gate took into account both words and content. Therefore, it allowed every layer to perform its work clearly, and also alleviated the long-term dependency problem.
3.2. Chebyshev Pooling
The main idea of this pooling is to use a nonlinear filter by applying Chebyshev’s inequality as a layer to extract the probability state of the convoluted feature. In a pooling layer, the feature information in a tensor was presented, and its neighbors could be grouped into a set of sample data for the statistical analysis. In addition to the mean and variance, these samples may have initially had a completely arbitrary distribution. Generally speaking, the probability of the convolutional data belonging to the main feature was usually less than the probability of belonging to other features. Therefore, the concept of our method was to use probability to filter out/discard non-major features.
3.2.1. Chebyshev’s Inequality
As presented in our earlier work [34,35], Chebyshev’s inequality was not suitable for this kind of analysis, because this inequality usually provides a poor upper bound, and the bound becomes increasingly weaker as the selected feature goes up, and it would cause the result to exceed the unexpected value. We, thus, used a variant form of Chebyshev’s inequality, namely, the one-sided Chebyshev’s inequality [36] or Cantelli’s inequality [37], written as:
for any , where x is a randomly selected feature in a tensor of samples with a finite mean and variance . This inequality provided us with a way to deal with extreme situations, in which case, the only knowledge we had about the samples or probability distribution was the mean and standard deviation. It meant that, in any probability distribution, almost all values were close to the mean, and the chance of a value outside that range did not exceed . The useful property of Equation (2) is that it could provide a stronger bound . Since the distribution could be arbitrary, this reason could be applied to various general situations to obtain results within the effective range. For more general applications, let and x be a sample obtained from a distribution with mean and variance , and, then, for , Equation (2) could be rewritten as:
Suppose t was the current feature to be considered for pooling; then, Equation (3) would indicate that the probability of the sample was equal to or greater than t within its 2D kernel size (), not exceeding . Even for a tensor without normalization, since it was just a comparison of the values without considering other information, the bound could still provide a stable and better extraction of the number of interesting features within a given sample. Therefore, the Chebyshev pooling combined the function of maximum pooling and average pooling methods to calculate the probability distribution of the data to be extracted in the training process of CNN.
3.2.2. Derivative and Gradient
As usual, a CNN-based classifier was trained by using the back-propagation algorithm. For error propagation and weight adaptation in the fully connected layer and the convolutional layer, the standard back-propagation procedures could be employed before the pooling layer. In the network design, the pooling layer did not actually conduct any learning. On the contrary, it just reduced the sizes of the tensor after the Chebyshev pooling, leaving the feature t. This t value obtained an error calculated from back-propagation, and the error was forwarded to the entire pooling block by processing Equation (3), then divided by . The result was further forwarded to its source, and all the units in the block affected its value. In addition to the error consideration, we also found the first derivative of Equation (3) about t as follows,
where becomes zero if . This meant the gradient was vanishingly small and the training processes would stagnate somewhere. In order to alleviate this worst-case scenario, we proposed to employ the non-linear function Softplus as the activation function to activate the gradient by applying it to t. The reason for choosing Softplus was that it could ensure the output within the activated range of , and it is monotonic and differentiable, having a positive first-order derivative in . Meanwhile, there were several ways for the t selection, including taking the minimum or maximum value, and random selection. In our practice, the maximum and random selection could both cause the training convergence to be successful, but the minimum way could not, and the convergence of the maximum selection was faster than that of the random selection. Thus, we recommend using the maximum value as the sample t. By stacking the aforementioned layers, we completed the feature extraction with the proposed pooling.
4. Implementation
In order to implement our proposed network, we used the scientific deep learning framework PyTorch [38] to accomplish our task. The architecture could be implemented in the Constructor and Forward functions, which are the interface provided by PyTorch. As mentioned in Section 3.1 and the single-layer CARU [8], a CARU unit can be composed of several Linear layers as presented in Algorithm 1. The hidden state and current input feature were first processed by the Linear layer that focuses on the calculation of the states and weight, and their results were passed on to the content-adaptive gate for the transition of the hidden state. The gate was used to combine all the obtained weights and produced the next hidden state directly. Note that there were two Sigmoid functions which we added (line:11 in Algorithm 1) to ensure that the produced state could be clamped in the range of , providing a more stable feature for the subsequent processing.
| Algorithm 1: Pseudo code of CARU unit architecture, with regard to Figure 2. |
 |
Once we prepared the CARU unit, it could be directly embedded in our flow. We only focused on the design of stacking layers, and the multilayer CARU could also be implemented by Algorithm 2, such as in Figure 3.
| Algorithm 2: Pseudo code for complete multilayer CARU. |
 |
On the other hand, the Chebyshev pooling could be achieved by using average pooling and maximum pooling as standard modules. The complete implementation was presented in Algorithm 3. In addition, there was an exceptional case we had to handle. It could cause the denominator in Equation (3) to be zero when the entire tensor contained the same value, that would make the result become NaN (not a number) as shown below,
This issue would always occur in the early stage of training, and we had to replace the NaN to 0 through a function nan_to_num provided by PyTorch to ensure smooth learning.
| Algorithm 3: Pseudo code for the whole processing of Chebyshev pooling. |
 |
5. Experiment
Our targets were to perform several experiments for the sentiment analysis. As indicated in Figure 1, the input was paragraphs or sets of content-related sentences , which came from four different text classification datasets: SST-5 [39], IMDB [40], Sentiment140 [41], and AMAZON [42]. All our experiments were conducted on an NVIDIA GeForce RTX 2080Ti with 11.0 GB of video memory. We first evaluated the proposed multilayer CARU framework with related methods; we also re-implemented the multilayer MTGRU [43] and RNN-LM [44] in PyTorch and compared it with CARU with different numbers of layers used. Furthermore, we evaluated the performance on the same environment with and without the use of the Chebyshev pooling, and with the same configuration and the same number of neural nodes as indicated in Table 1 and Table 2.
On the other hand, to compare the proposed model with the original networks, we also re-implemented several state-of-the-art baselines found in recent years—L-MIXED [45], EFL [46], and Variable-Depth [3]—, also including the traditional models CNN+LSTM [47] and CEN-tpc [48] in PyTorch. All experiments used the same dataset in each test with a batch size of 100 per iteration set, and with the same configuration. In addition, there was a scheduler for adjusting the learning rate. It reduced the learning rate when the loss became stagnant.
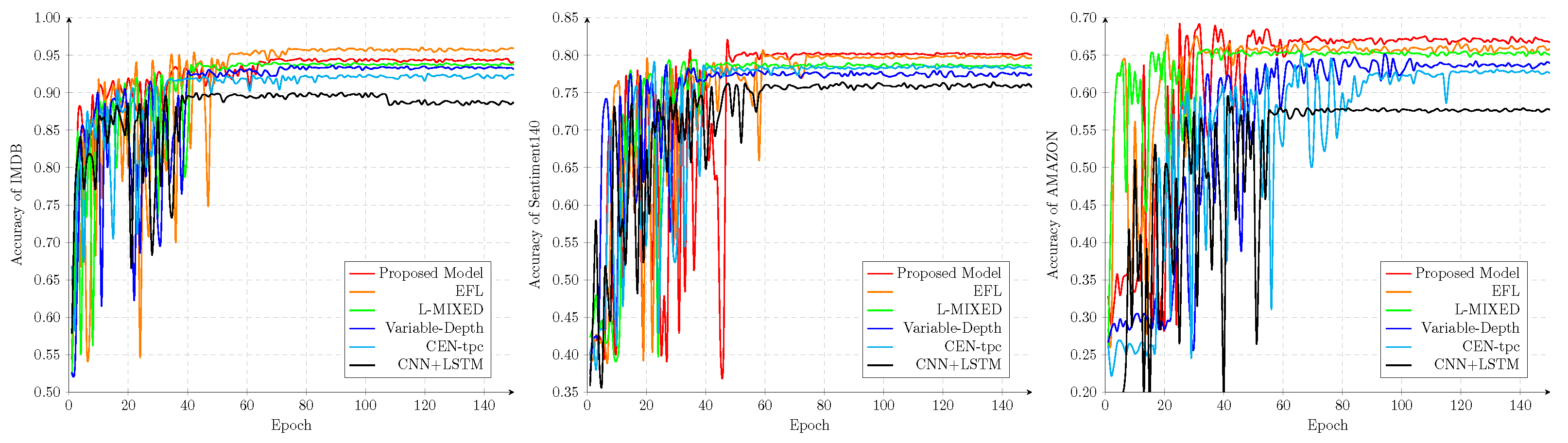
The comparison results are given in Table 3; it can be seen that the proposed model was better than the others used in their studies. While 80.90% and 66.49% accuracy values were achieved for the Sentiment140 and AMAZON datasets, respectively, by a gap of 1.0%, in contrast, the result of the IMDB test with the proposed model was very close to the best, but did not exceed it. The reason was that the contents of the IMDB dataset were mainly comments, which tend to be mostly neutral and objective, and it was difficult to reflect the expression of emotion. Based on these results, it could be inferred that the proposed model was at least as successful as, or even better than, the other existing models.
Corresponding to Table 3, Figure 4 shows the complete tendency of accuracy for the selected datasets trained by the various model. Obviously, these accuracy values were usually unstable before 60 epochs, and they were quite stable after 60 epochs. The reason we considered this was that the proposed model first prioritized to train the multilayer CARU to extract some useful features, so the difference was always presented with a larger value in order to contribute a larger gradient for the rollback used. Once the training of the multilayer CARU was almost complete, the gradient would only be contributed by the faster and more stable CNN-based extractor like [49]. Therefore, the training in the later stage became stable and converged faster.
6. Conclusions
In this work, we proposed a novel effective model to perform the sentiment analysis in NLP tasks, that was able to obtain pattern information and discriminative embedding vectors. The proposed multilayer CARU aimed to extract the main information by using a layered mechanism and integrate multi-level information for effective feature extraction. In addition, we used the VGGNet to explore and capture the useful information in the set of hidden states representing the entire paragraph. We introduced the Chebyshev pooling to calculate probability distribution for a further analysis in applications. Our experiments demonstrated that the proposed model could achieve a comparable result with the state-of-the-art models. For future work, this model could also be examined in more detail and comparisons could be determined for use in different NLP tasks or other classification applications.
Author Contributions
Conceptualization, W.K. and K.-H.C.; Methodology, W.K. and K.-H.C.; Software, W.K.; Validation, W.K. and K.-H.C.; Formal analysis, W.K. and K.-H.C.; Investigation, W.K. and K.-H.C.; Resources, K.-H.C.; Data curation, W.K. and K.-H.C.; Writing—original draft preparation, K.-H.C.; Writing—review and editing, W.K.; Visualization, K.-H.C.; Supervision, W.K.; Project administration, W.K.; Funding acquisition, W.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was part of the research project (RP/ESCA-03/2020) funded by the Macao Polytechnic Institute, Macau SAR.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Alakus, T.B.; Gonen, M.; Türkoglu, I. Database for an emotion recognition system based on EEG signals and various computer games—GAMEEMO. Biomed. Signal Process. Control. 2020, 60, 101951. [Google Scholar] [CrossRef]
- Alakus, T.B.; Turkoglu, I. Emotion recognition with deep learning using GAMEEMO data set. Electron. Lett. 2020, 56, 1364–1367. [Google Scholar] [CrossRef]
- Chan, K.H.; Im, S.K.; Ke, W. Variable-Depth Convolutional Neural Network for Text Classification. ICONIP (5). In Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1333, pp. 685–692. [Google Scholar]
- Mikolov, T.; Kombrink, S.; Burget, L.; Cernocký, J.; Khudanpur, S. Extensions of recurrent neural network language model. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5528–5531. [Google Scholar]
- Marcheggiani, D.; Täckström, O.; Esuli, A.; Sebastiani, F. Hierarchical Multi-label Conditional Random Fields for Aspect-Oriented Opinion Mining. ECIR. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8416, pp. 273–285. [Google Scholar]
- Alboaneen, D.A.; Tianfield, H.; Zhang, Y. Sentiment analysis via multi-layer perceptron trained by meta-heuristic optimisation. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 4630–4635. [Google Scholar]
- Hazarika, D.; Poria, S.; Vij, P.; Krishnamurthy, G.; Cambria, E.; Zimmermann, R. Modeling Inter-Aspect Dependencies for Aspect-Based Sentiment Analysis; NAACL-HLT (2); Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 266–270. [Google Scholar]
- Chan, K.H.; Ke, W.; Im, S.K. CARU: A Content-Adaptive Recurrent Unit for the Transition of Hidden State in NLP. ICONIP (1). In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12532, pp. 693–703. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Mu, L.; Zan, H.; Zhang, K. Research on Chinese Parsing Based on the Improved Compositional Vector Grammar. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 649–658. [Google Scholar] [CrossRef]
- Goldberg, Y. Neural Network Methods for Natural Language Processing. Synth. Lect. Hum. Lang. Technol. 2017, 10, 1–309. [Google Scholar] [CrossRef]
- Munikar, M.; Shakya, S.; Shrestha, A. Fine-grained Sentiment Classification using BERT. In Proceedings of the 2019 Artificial Intelligence for Transforming Business and Society (AITB), Kathmandu, Nepal, 5 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Xu, B.; Xu, J.; Tian, G.; Liu, C.L.; Hao, H. Semantic expansion using word embedding clustering and convolutional neural network for improving short text classification. Neurocomputing 2016, 174, 806–814. [Google Scholar] [CrossRef]
- Havaei, M.; Davy, A.; Warde-Farley, D.; Biard, A.; Courville, A.; Bengio, Y.; Pal, C.; Jodoin, P.M.; Larochelle, H. Brain tumor segmentation with Deep Neural Networks. Med. Image Anal. 2017, 35, 18–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Takase, S.; Okazaki, N.; Inui, K. Modeling semantic compositionality of relational patterns. Eng. Appl. Artif. Intell. 2016, 50, 256–264. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016. [Google Scholar] [CrossRef] [Green Version]
- Zia, T. Hierarchical recurrent highway networks. Pattern Recognit. Lett. 2019, 119, 71–76. [Google Scholar] [CrossRef]
- Chan, K.H.; Im, S.K.; Ke, W. Multiple classifier for concatenate-designed neural network. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Stewart, I.; Arendt, D.; Bell, E.; Volkova, S. Measuring, Predicting and Visualizing Short-Term Change in Word Representation and Usage in VKontakte Social Network; ICWSM; AAAI Press: Palo Alto, CA, USA, 2017; pp. 672–675. [Google Scholar]
- Khan, M.; Malviya, A. Big data approach for sentiment analysis of twitter data using Hadoop framework and deep learning. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020. [Google Scholar] [CrossRef]
- dos Santos, C.N.; Gatti, M. Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In Proceedings of the COLING 2014, The 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 69–78. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Bengio, Y.; Senecal, J.S. Adaptive Importance Sampling to Accelerate Training of a Neural Probabilistic Language Model. IEEE Trans. Neural Netw. 2008, 19, 713–722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, E.H.; Socher, R.; Manning, C.D.; Ng, A.Y. Improving Word Representations via Global Context and Multiple Word Prototypes; ACL (1); The Association for Computer Linguistics: Stroudsburg, PA, USA, 2012; pp. 873–882. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification. In Proceedings of the 23rd International Conference on Machine Learning—ICML ’06; ACM Press: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Li, X.; Wu, X. Labeling unsegmented sequence data with DNN-HMM and its application for speech recognition. In Proceedings of the 9th International Symposium on Chinese Spoken Language Processing, Singapore, 12–14 September 2014. [Google Scholar] [CrossRef]
- Tang, D.; Wei, F.; Yang, N.; Zhou, M.; Liu, T.; Qin, B. Learning Sentiment-Specific Word Embedding for Twitter Sentiment Classification; ACL (1); The Association for Computer Linguistics: Stroudsburg, PA, USA, 2014; pp. 1555–1565. [Google Scholar]
- Chan, K.H.; Im, S.K.; Zhang, Y. A Self-Weighting Module to Improve Sentiment Analysis. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021. [Google Scholar] [CrossRef]
- Zhao, R.; Mao, K. Fuzzy Bag-of-Words Model for Document Representation. IEEE Trans. Fuzzy Syst. 2018, 26, 794–804. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; LeCun, Y. Very Deep Convolutional Networks for Text Classification; EACL (1); Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 1107–1116. [Google Scholar]
- Ren, R.; Liu, Z.; Li, Y.; Zhao, W.X.; Wang, H.; Ding, B.; Wen, J.R. Sequential Recommendation with Self-Attentive Multi-Adversarial Network. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 89–98. [Google Scholar]
- Chan, K.H.; Im, S.K.; Ke, W. Fast Binarisation with Chebyshev Inequality. In Proceedings of the 2017 ACM Symposium on Document Engineering, Valletta, Malta, 4–7 September 2017; pp. 113–116. [Google Scholar]
- Chan, K.H.; Pau, G.; Im, S.K. Chebyshev Pooling: An Alternative Layer for the Pooling of CNNs-Based Classifier. In Proceedings of the 2021 IEEE 4th International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 13–15 August 2021. [Google Scholar] [CrossRef]
- Ghosh, B. Probability inequalities related to Markov’s theorem. Am. Stat. 2002, 56, 186–190. [Google Scholar] [CrossRef]
- Ogasawara, H. The multiple Cantelli inequalities. Stat. Methods Appl. 2019, 28, 495–506. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library; NeurIPS: San Diego, CA, USA, 2019; pp. 8024–8035. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning Word Vectors for Sentiment Analysis; The Association for Computer Linguistics: Stroudsburg, PA, USA, 2011; pp. 142–150. [Google Scholar]
- Go, A.; Bhayani, R.; Huang, L. Twitter sentiment classification using distant supervision. CS224N Proj. Rep. Stanf. 2009, 1, 2009. [Google Scholar]
- Majumder, B.P.; Li, S.; Ni, J.; McAuley, J.J. Interview: Large-scale Modeling of Media Dialog with Discourse Patterns and Knowledge Grounding; EMNLP (1); Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8129–8141. [Google Scholar]
- Kim, M.; Moirangthem, D.S.; Lee, M. Towards Abstraction from Extraction: Multiple Timescale Gated Recurrent Unit for Summarization; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Chai, J.; Li, A. Deep Learning in Natural Language Processing: A State-of-the-Art Survey. In Proceedings of the 2019 International Conference on Machine Learning and Cybernetics (ICMLC), Kobe, Japan, 7–10 July 2019. [Google Scholar] [CrossRef]
- Sachan, D.S.; Zaheer, M.; Salakhutdinov, R. Revisiting LSTM Networks for Semi-Supervised Text Classification via Mixed Objective Function; AAAI Press: Palo Alto, CA, USA, 2019; pp. 6940–6948. [Google Scholar]
- Wang, S.; Fang, H.; Khabsa, M.; Mao, H.; Ma, H. Entailment as Few-Shot Learner. arXiv 2021, arXiv:2104.14690. [Google Scholar]
- Camacho-Collados, J.; Pilehvar, M.T. On the Role of Text Preprocessing in Neural Network Architectures: An Evaluation Study on Text Categorization and Sentiment Analysis; BlackboxNLP@EMNLP; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 40–46. [Google Scholar]
- Al-Shedivat, M.; Dubey, A.; Xing, E.P. Contextual Explanation Networks. J. Mach. Learn. Res. 2020, 21, 194:1–194:44. [Google Scholar]
- Chan, K.H.; Im, S.K.; Ke, W. VGGreNet: A Light-Weight VGGNet with Reused Convolutional Set. In Proceedings of the 2020 IEEE/ACM 13th International Conference on Utility and Cloud Computing (UCC), Leicester, UK, 7–10 December 2020. [Google Scholar] [CrossRef]
Figure 1.
Diagram of our proposed model. Multilayer CARU is able to extract information and discriminative feature embedding to perform sentiment analysis for NLP, and the Chebyshev pooling projects the feature into a type of probability distribution in order to extract more effective features for better decision making.
Figure 1.
Diagram of our proposed model. Multilayer CARU is able to extract information and discriminative feature embedding to perform sentiment analysis for NLP, and the Chebyshev pooling projects the feature into a type of probability distribution in order to extract more effective features for better decision making.

Figure 2.
Architecture of single CARU [8].
Figure 2.
Architecture of single CARU [8].

Figure 3.
Three-level stacking implementation of multilayer CARU.

Figure 4.
Complete tendency of accuracy for selected dataset trained by various model.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Average accuracy of SST-5 test data with the error range.
| Layer | MTGRU [43] | RNN-LM [44] | Multilayer CARU |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| Chebyshev Pooling |
Table 2.
Average accuracy of IMDB test data with the error range.
| Layer | MTGRU [43] | RNN-LM [44] | Multilayer CARU |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| Chebyshev Pooling |
Table 3.
Comparison with other state-of-the-art methods. Bold values are used to emphasize that the model can achieve better accuracy (%).
Table 3.
Comparison with other state-of-the-art methods. Bold values are used to emphasize that the model can achieve better accuracy (%).
| IMDB [40] | Sentiment140 [41] | AMAZON [42] | |
|---|---|---|---|
| Proposed Model | 94.89 | 80.90 | 66.49 |
| EFL [46] | 95.14 | 80.06 | 65.84 |
| L-MIXED [45] | 94.72 | 78.49 | 65.07 |
| Variable-Depth [3] | 93.57 | 77.42 | 63.51 |
| CEN-tpc [48] | 93.20 | 78.20 | 62.52 |
| CNN+LSTM [47] | 88.01 | 75.69 | 57.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ke, W.; Chan, K.-H. A Multilayer CARU Framework to Obtain Probability Distribution for Paragraph-Based Sentiment Analysis. Appl. Sci. 2021, 11, 11344. https://0-doi-org.brum.beds.ac.uk/10.3390/app112311344
AMA Style
Ke W, Chan K-H. A Multilayer CARU Framework to Obtain Probability Distribution for Paragraph-Based Sentiment Analysis. Applied Sciences. 2021; 11(23):11344. https://0-doi-org.brum.beds.ac.uk/10.3390/app112311344
Chicago/Turabian StyleKe, Wei, and Ka-Hou Chan. 2021. "A Multilayer CARU Framework to Obtain Probability Distribution for Paragraph-Based Sentiment Analysis" Applied Sciences 11, no. 23: 11344. https://0-doi-org.brum.beds.ac.uk/10.3390/app112311344
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.