
Automatic Generation of Aerial Orthoimages Using Sentinel-2 Satellite Imagery with a Context-Based Deep Learning Approach


Abstract
:1. Introduction
2. Materials and Methods
2.1. Training Datasets Generation and Site Selection
2.1.1. Study Area
2.1.2. Aerial Orthoimages
2.1.3. Sentinel-2A/B Satellite Imagery
2.1.4. Training Datasets Generation
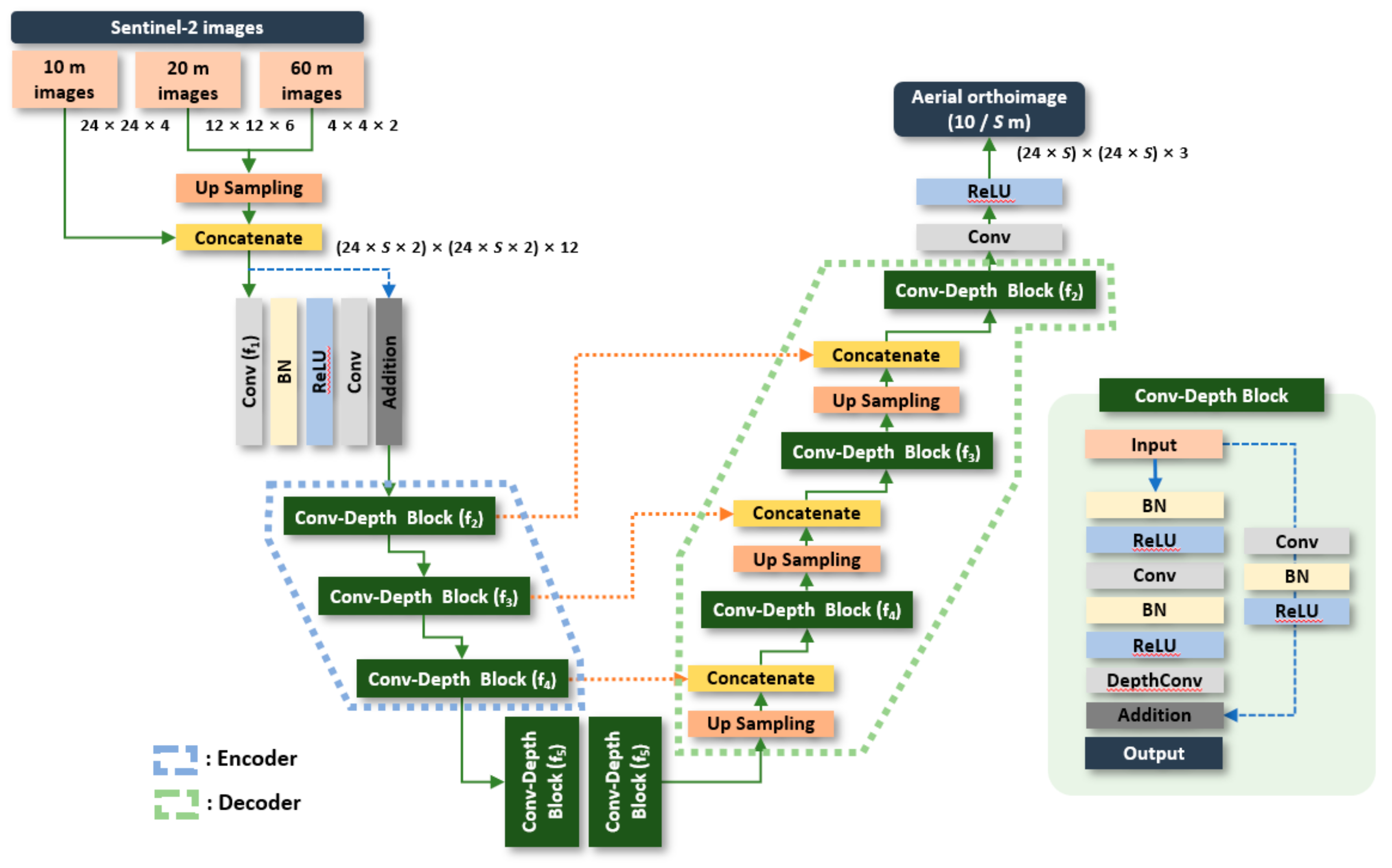
2.2. Methodology
2.2.1. Context-Based ResU-Net
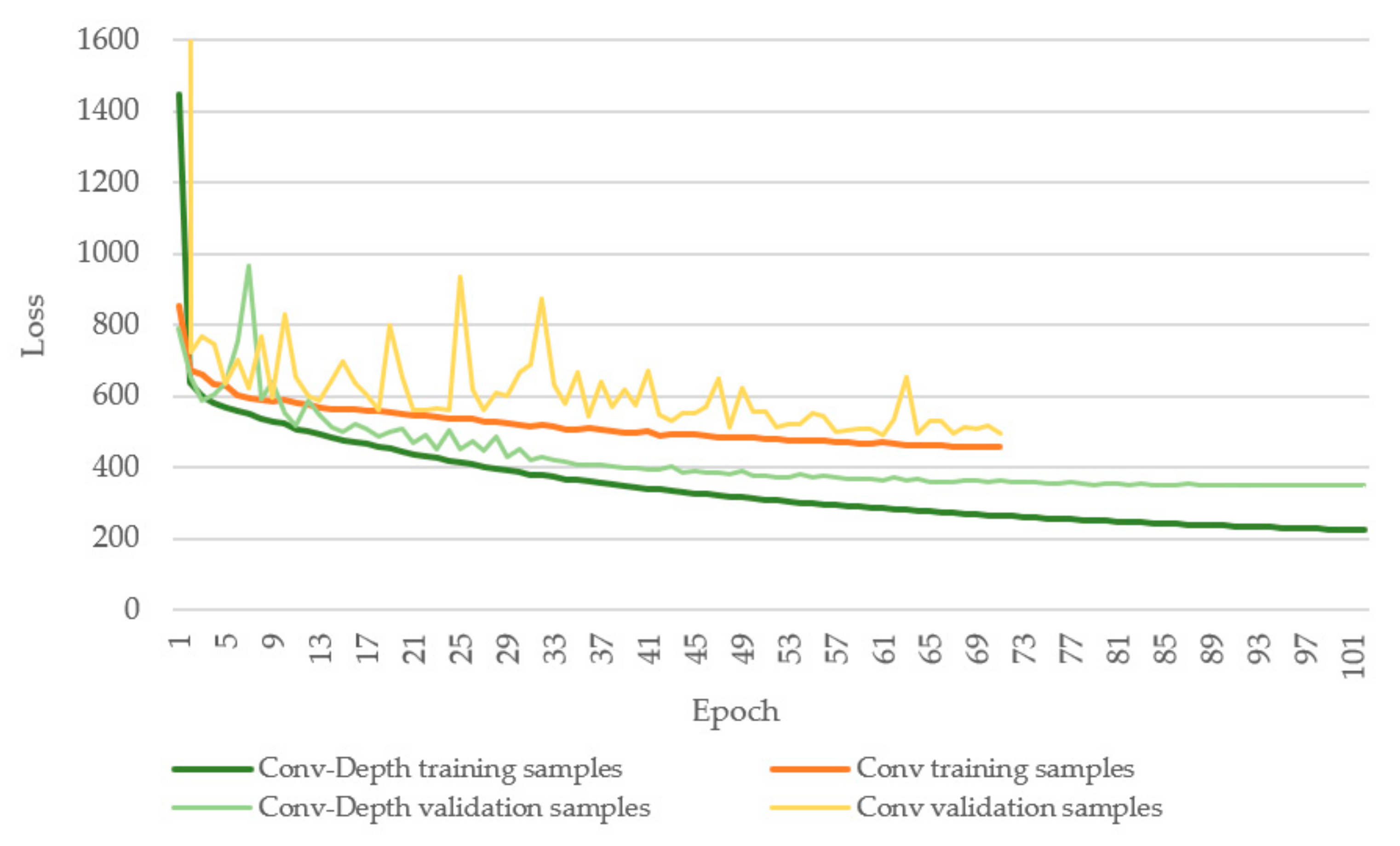
2.2.2. Hyperparameter Optimization
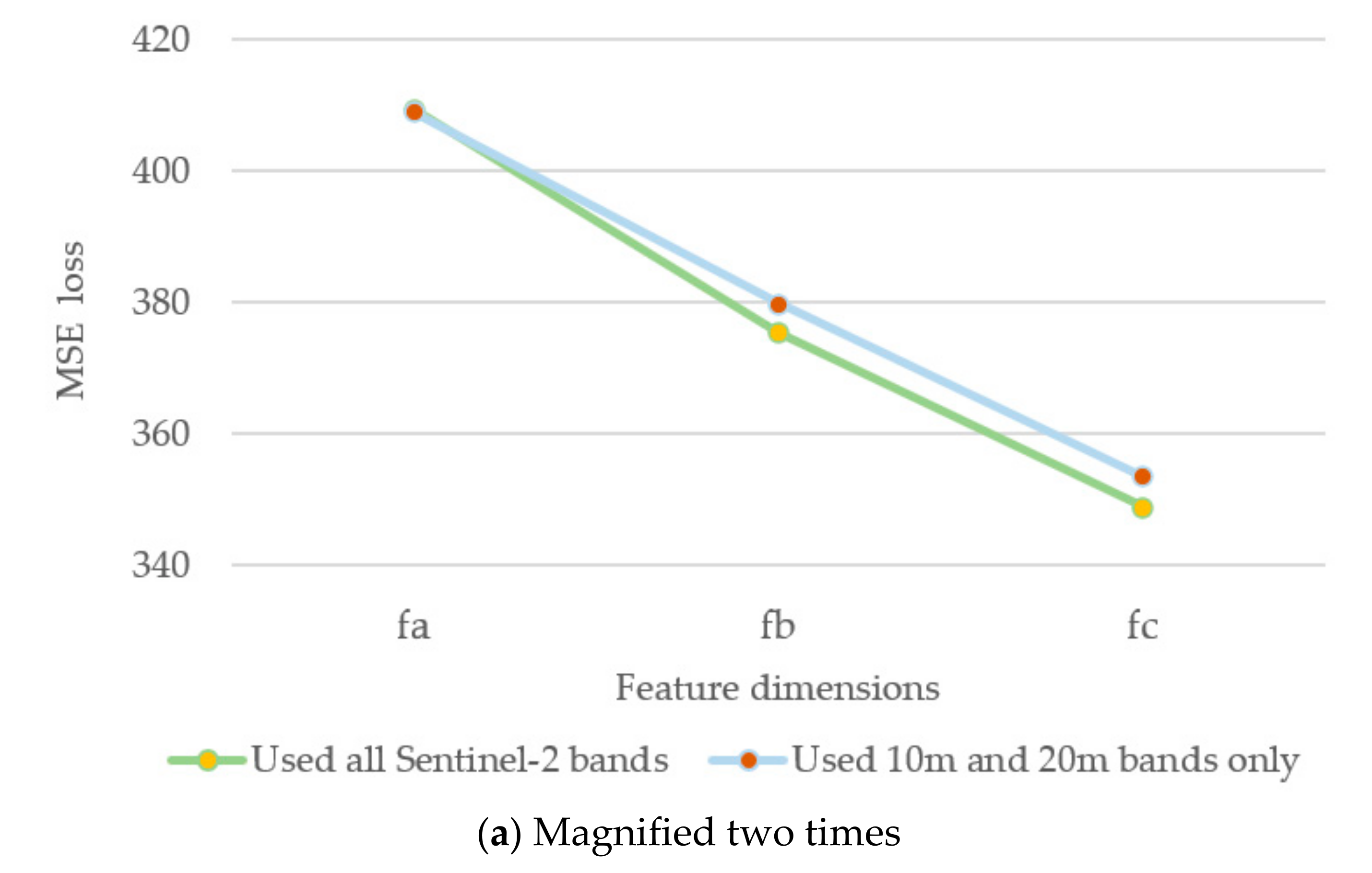
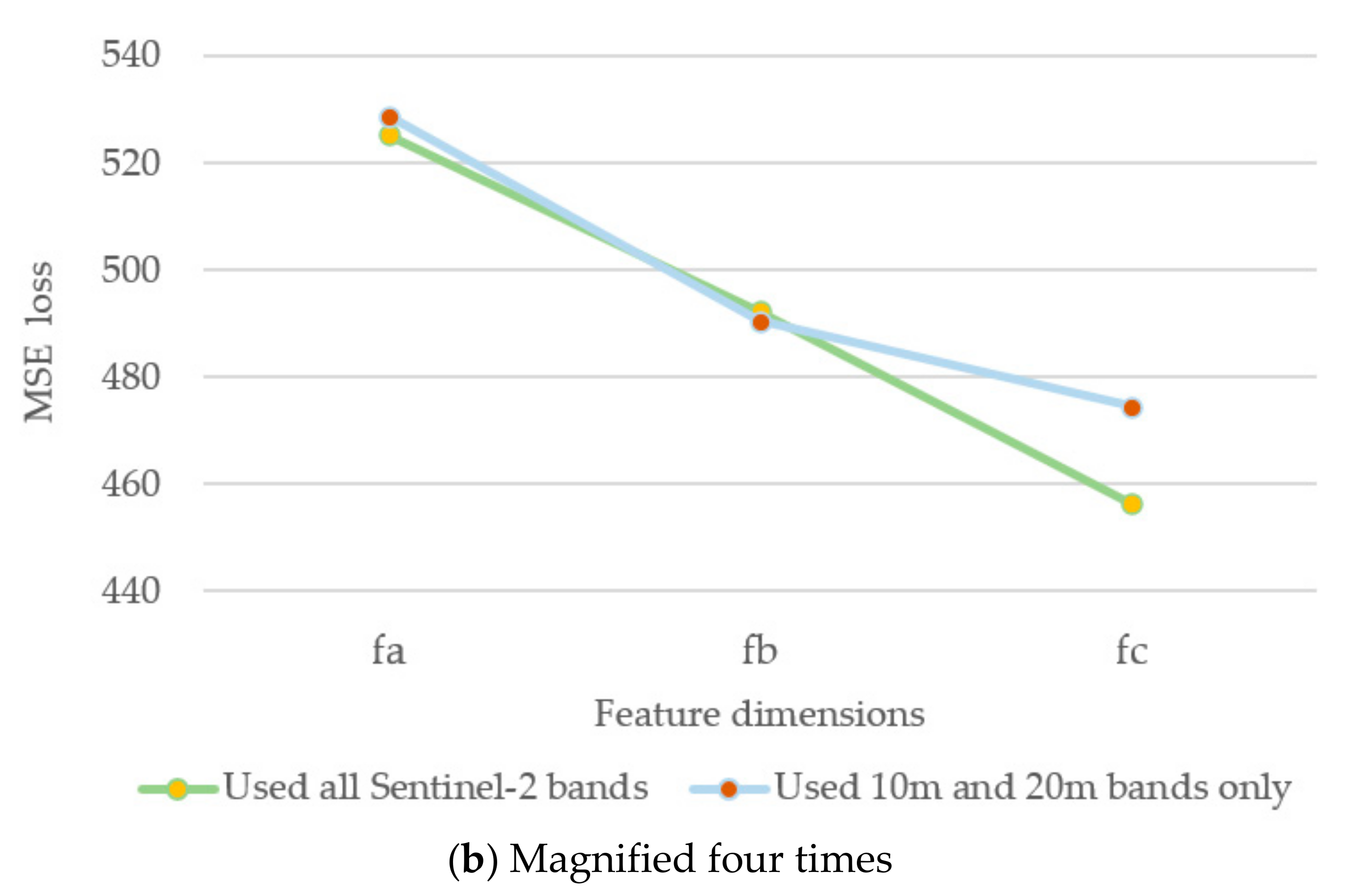
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- National Geographic Information Institute National Territory Information Platform. Available online: http://map.ngii.go.kr/mn/mainPage.do (accessed on 31 December 2020).
- Rahmani, S.; Strait, M.; Merkurjev, D.; Moeller, M.; Wittman, T. An adaptive IHS pan-sharpening method. IEEE Geosci. Remote Sens. Lett. 2010, 7, 746–750. [Google Scholar] [CrossRef] [Green Version]
- Ghadjati, M.; Moussaoui, A.; Boukharouba, A. A novel iterative PCA–based pansharpening method. Remote Sens. Lett. 2019, 10, 264–273. [Google Scholar] [CrossRef]
- Liebel, L.; Körner, M. Single-image super resolution for multi-spectral remote sensing data using convolutional neural networks. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 883–890. [Google Scholar] [CrossRef]
- Gargiulo, M.; Mazza, A.; Gaetano, R.; Ruello, G.; Scarpa, G. A CNN-Based Fusion Method for Super-Resolution of Sentinel-2 Data. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4713–4716. [Google Scholar]
- Lanaras, C.; Bioucas-Dias, J.; Galliani, S.; Baltsavias, E.; Schindler, K. Super-resolution of Sentinel-2 images: Learning a globally applicable deep neural network. ISPRS J. Photogramm. Remote Sens. 2018, 146, 305–319. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Cai, J.; Fu, P.; Hu, L.; Liu, T. Deep learning-based fusion of Landsat-8 and Sentinel-2 images for a harmonized surface reflectance product. Remote Sens. Environ. 2019, 235, 111425. [Google Scholar] [CrossRef]
- Tai, Y.; Yang, J.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Pouliot, D.; Latifovic, R.; Pasher, J.; Duffe, J. Landsat super-resolution enhancement using convolution neural networks and Sentinel-2 for training. Remote Sens. 2018, 10, 394. [Google Scholar] [CrossRef] [Green Version]
- Galar, M.; Sesma, R.; Ayala, C.; Aranda, C. Super-Resolution for Sentinel-2 Images. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences—ISPRS Archives, Nanjing, China, 25–27 October 2019; Volume 42, pp. 95–102. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Thanh Noi, P.; Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using Sentinel-2 imagery. Sensors 2018, 18, 18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.; Shi, W.; Li, Z.; Atkinson, P.M. Fusion of Sentinel-2 images. Remote Sens. Environ. 2016, 187, 241–252. [Google Scholar] [CrossRef] [Green Version]
- Gašparović, M.; Jogun, T. The effect of fusing Sentinel-2 bands on land-cover classification. Int. J. Remote Sens. 2018, 39, 822–841. [Google Scholar] [CrossRef]
- European Space Agency (ESA) Copernicus. Available online: https://scihub.copernicus.eu/dhus/#/home (accessed on 31 December 2020).
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Sun, Y.; Xu, W.; Zhang, J.; Xiong, J.; Gui, G. Super-Resolution Imaging Using Convolutional Neural Networks. Lecture Notes in Electrical Engineering; Springer: Berlin/Heidelberg, Germany, 2020; Volume 516, pp. 59–66. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Platform | Sensing Start Time |
|---|---|
| Sentinel-2A | 2018/04/18 02:16:01 |
| 2018/04/28 02:16:11 | |
| 2018/05/28 02:16:51 | |
| Sentinel-2B | 2018/05/23 02:16:49 |
| Total | 4 images |
| Feature Dimensions | Compositions | Number of Parameters | |
|---|---|---|---|
| Trainable Parameters | Total Parameters | ||
| fa | Using convolutional layer only | 4,718,035 | 4,725,331 |
| Using DepthConv layer | 3,159,955 | 3,167,251 | |
| fb | Using convolutional layer only | 18,845,091 | 18,859,683 |
| Using DepthConv layer | 12,595,491 | 12,610,083 | |
| fc | Using convolutional layer only | 75,326,275 | 75,355,459 |
| Using DepthConv layer | 50,293,315 | 50,322,499 | |
| Scale | Neural Networks | Use of 60 m | Feature Dimensions | Epoch | RMSE | PSNR | SSIM |
|---|---|---|---|---|---|---|---|
| 2 | Baseline (EDSR) | Y | 64 | 120 | 22.9871 | 22.2210 | 0.4750 |
| N | 100 | 23.1250 | 22.1883 | 0.4738 | |||
| EDSR | Y | 256 | 70 | 22.5078 | 22.3772 | 0.4834 | |
| N | 100 | 21.9486 | 22.6070 | 0.4935 | |||
| Context-based ResU-Net (Ours) | Y | fa | 180 | 20.2371 | 23.3116 | 0.5010 | |
| fb | 19.3775 | 23.6701 | 0.5233 | ||||
| fc | 18.6816 | 23.9578 | 0.5437 | ||||
| N | fa | 20.2274 | 23.3333 | 0.5005 | |||
| fb | 19.4900 | 23.6332 | 0.5234 | ||||
| fc | 18.8066 | 23.8895 | 0.5439 | ||||
| 4 | Baseline (EDSR) | Y | 64 | 180 | 24.6372 | 21.5330 | 0.3675 |
| N | 24.7514 | 21.5305 | 0.3648 | ||||
| EDSR | Y | 256 | 30 | 26.4536 | 20.9607 | 0.3516 | |
| N | 40 | 26.7308 | 20.9715 | 0.3572 | |||
| Context-based ResU-Net (Ours) | Y | fa | 180 | 22.9141 | 22.1295 | 0.3770 | |
| fb | 22.1827 | 22.3758 | 0.3888 | ||||
| fc | 120 | 21.3574 | 22.6966 | 0.4101 | |||
| N | fa | 22.9897 | 22.1006 | 0.3774 | |||
| fb | 22.1444 | 22.3971 | 0.3912 | ||||
| fc | 21.7778 | 22.5278 | 0.4018 |
| Scale | Neural Networks | Use of 60 m | Feature Dimensions | RMSE | PSNR | SSIM |
|---|---|---|---|---|---|---|
| 2 | Baseline (EDSR) | Y | 64 | 30.3523 | 19.3793 | 0.4034 |
| N | 30.5805 | 19.3052 | 0.4009 | |||
| EDSR | Y | 256 | 30.3873 | 19.4050 | 0.4086 | |
| N | 30.0645 | 19.4856 | 0.4110 | |||
| Context-based ResU-Net (Ours) | Y | fa | 30.4532 | 19.4819 | 0.4125 | |
| fb | 30.8639 | 19.3829 | 0.4122 | |||
| fc | 30.4220 | 19.5121 | 0.4182 | |||
| N | fa | 30.5115 | 19.4902 | 0.4183 | ||
| fb | 30.3297 | 19.5689 | 0.4173 | |||
| fc | 30.4948 | 19.5190 | 0.4151 | |||
| 4 | Baseline (EDSR) | Y | 64 | 31.5568 | 18.9689 | 0.3287 |
| N | 31.4554 | 18.9719 | 0.3270 | |||
| EDSR | Y | 256 | 32.4436 | 18.7164 | 0.3188 | |
| N | 33.1779 | 18.5482 | 0.3250 | |||
| Context-based ResU-Net (Ours) | Y | fa | 31.3203 | 19.0943 | 0.3357 | |
| fb | 31.5619 | 19.0178 | 0.3357 | |||
| fc | 31.6259 | 19.0225 | 0.3387 | |||
| N | fa | 31.8976 | 18.9556 | 0.3368 | ||
| fb | 31.4533 | 19.1072 | 0.3382 | |||
| fc | 31.3686 | 19.0990 | 0.3407 |
| Scale | Use of 60 m | Predicted Images | Input Images per Each Resolution (Sentinel-2) | |||
|---|---|---|---|---|---|---|
| Baseline and EDSR | Context-Based ResU-Net (Ours) | |||||
| 2 | Yes | 64 |  | fa |  |  < Band 01 (60 m) >  < Band 02 (10 m) >  < Band 05 (20 m) > |
| fb |  | |||||
| 256 | | |||||
| fc | | |||||
| No | 64 | | fa |  | ||
| fb |  | GT image | ||||
 < Orthoimage (5.0 m) > | ||||||
| 256 | | |||||
| fc |  | |||||
| 4 | Yes | 64 | | fa |  | < Band 01 (60 m) > < Band 02 (10 m) > < Band 05 (20 m) > |
| fb |  | |||||
| 256 |  | |||||
| fc |  | |||||
| No | 64 |  | fa |  | ||
| fb |  | GT image | ||||
 < Orthoimage (2.5 m) > | ||||||
| 256 |  | |||||
| fc |  | |||||
| Scale | Use of 60 m | Predicted Images | Input Images per Each Resolution (Sentinel-2) | |||
|---|---|---|---|---|---|---|
| Baseline and EDSR | Context-Based ResU-Net (Ours) | |||||
| 2 | Yes | 64 |  | fa |  |  < Band 01 (60 m) >  < Band 02 (10 m) >  < Band 05 (20 m) > |
| fb |  | |||||
| 256 |  | |||||
| fc |  | |||||
| No | 64 |  | fa |  | ||
| fb |  | GT image | ||||
 < Orthoimage (5.0 m) > | ||||||
| 256 |  | |||||
| fc |  | |||||
| 4 | Yes | 64 |  | fa |  | < Band 01 (60 m) > < Band 02 (10 m) > < Band 05 (20 m) > |
| fb |  | |||||
| 256 |  | |||||
| fc |  | |||||
| No | 64 |  | fa |  | ||
| fb |  | GT image | ||||
 < Orthoimage (2.5 m) > | ||||||
| 256 |  | |||||
| fc |  | |||||
| Scale | Use of 60 m | Predicted Images | Input Images per Each Resolution (Sentinel-2) | |||
|---|---|---|---|---|---|---|
| Baseline and EDSR | Context-Based ResU-Net (Ours) | |||||
| 2 | Yes | 64 |  | fa |  |  < Band 01 (60 m) >  < Band 02 (10 m) >  < Band 05 (20 m) > |
| fb |  | |||||
| 256 |  | |||||
| fc |  | |||||
| No | 64 | | fa |  | ||
| fb |  | GT image | ||||
 < Orthoimage (5.0 m) > | ||||||
| 256 | | |||||
| fc |  | |||||
| 4 | Yes | 64 |  | fa |  | < Band 01 (60 m) > < Band 02 (10 m) > < Band 05 (20 m) > |
| fb |  | |||||
| 256 |  | |||||
| fc |  | |||||
| No | 64 |  | fa |  | ||
| fb |  | GT image | ||||
 < Orthoimage (2.5 m) > | ||||||
| 256 |  | |||||
| fc |  | |||||
| Scale | Use of 60 m | Predicted Images | Input Images per Each Resolution (Sentinel-2) | |||
|---|---|---|---|---|---|---|
| Baseline and EDSR | Context-Based ResU-Net (Ours) | |||||
| 2 | Yes | 64 |  | fa |  |  < Band 01 (60 m) >  < Band 02 (10 m) >  < Band 05 (20 m) > |
| fb |  | |||||
| 256 |  | |||||
| fc |  | |||||
| No | 64 |  | fa |  | ||
| fb |  | GT image | ||||
 < Orthoimage (5.0 m) > | ||||||
| 256 |  | |||||
| fc |  | |||||
| 4 | Yes | 64 |  | fa |  | < Band 01 (60 m) > < Band 02 (10 m) > < Band 05 (20 m) > |
| fb |  | |||||
| 256 |  | |||||
| fc |  | |||||
| No | 64 |  | fa |  | ||
| fb |  | GT image | ||||
 < Orthoimage (2.5 m) > | ||||||
| 256 |  | |||||
| fc |  | |||||
| Scale | Use of 60 m | Predicted Images | Input Imagesper Each Resolution (Sentinel-2) | |||
|---|---|---|---|---|---|---|
| Baseline and EDSR | Context-Based ResU-Net (Ours) | |||||
| 2 | Yes | 64 |  | fa |  |  < Band 01 (60 m) >  < Band 02 (10 m) >  < Band 05 (20 m) > |
| fb |  | |||||
| 256 |  | |||||
| fc |  | |||||
| No | 64 |  | fa |  | ||
| fb |  | GT image | ||||
 < Orthoimage (5.0 m) > | ||||||
| 256 |  | |||||
| fc |  | |||||
| 4 | Yes | 64 |  | fa |  | < Band 01 (60 m) > < Band 02 (10 m) > < Band 05 (20 m) > |
| fb |  | |||||
| 256 |  | |||||
| fc |  | |||||
| No | 64 |  | fa |  | ||
| fb |  | GT image | ||||
 < Orthoimage (2.5 m) > | ||||||
| 256 |  | |||||
| fc |  | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, S.; Lee, J.; Bae, J.; Jang, H.; Sohn, H.-G. Automatic Generation of Aerial Orthoimages Using Sentinel-2 Satellite Imagery with a Context-Based Deep Learning Approach. Appl. Sci. 2021, 11, 1089. https://0-doi-org.brum.beds.ac.uk/10.3390/app11031089
Yoo S, Lee J, Bae J, Jang H, Sohn H-G. Automatic Generation of Aerial Orthoimages Using Sentinel-2 Satellite Imagery with a Context-Based Deep Learning Approach. Applied Sciences. 2021; 11(3):1089. https://0-doi-org.brum.beds.ac.uk/10.3390/app11031089
Chicago/Turabian StyleYoo, Suhong, Jisang Lee, Junsu Bae, Hyoseon Jang, and Hong-Gyoo Sohn. 2021. "Automatic Generation of Aerial Orthoimages Using Sentinel-2 Satellite Imagery with a Context-Based Deep Learning Approach" Applied Sciences 11, no. 3: 1089. https://0-doi-org.brum.beds.ac.uk/10.3390/app11031089