
Finding the Differences in Capillaries of Taste Buds between Smokers and Non-Smokers Using the Convolutional Neural Networks



Abstract
:Featured Application
Abstract
1. Introduction
2. Methods
2.1. Experimental Environment and System
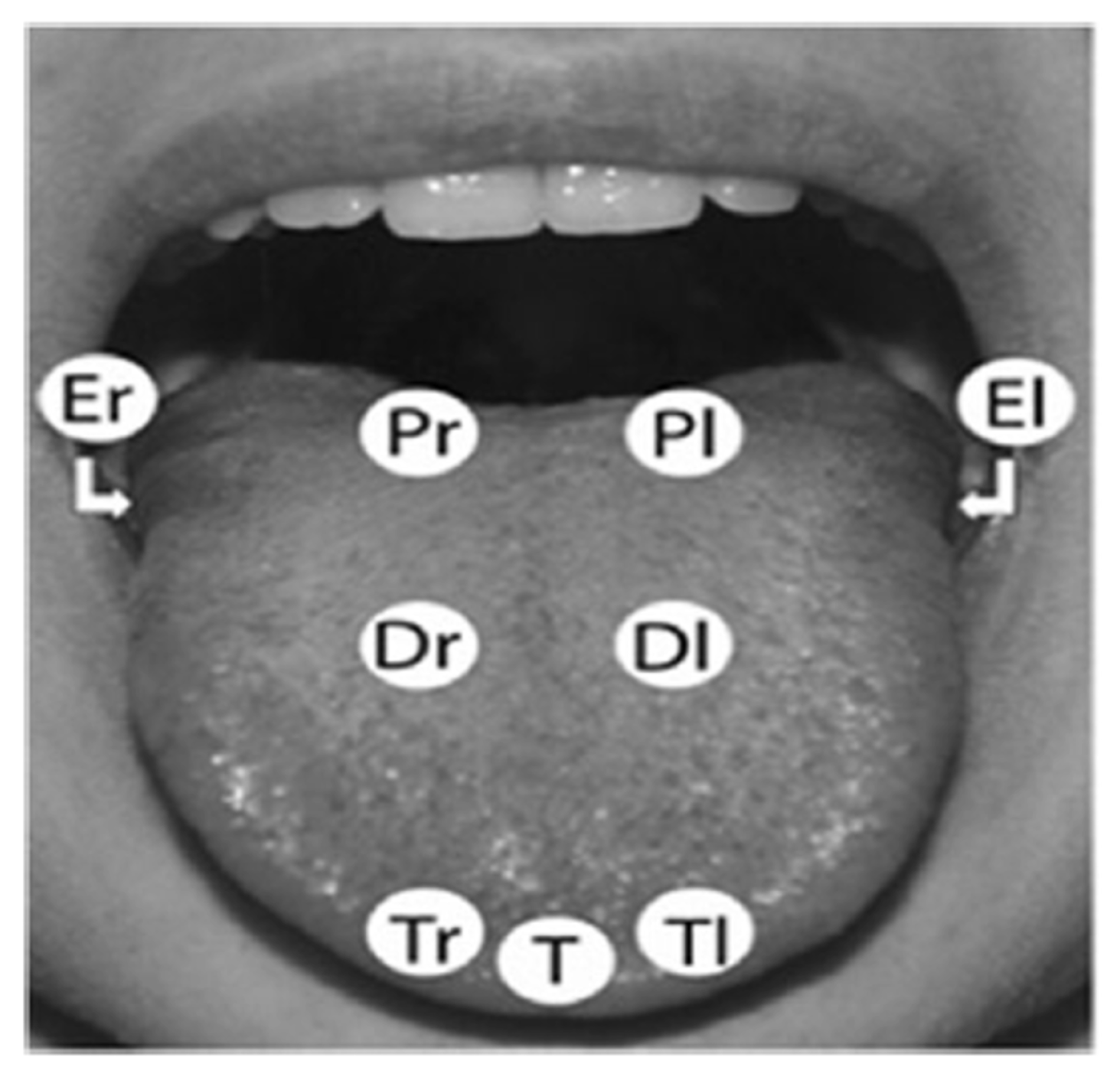
2.2. Data Acquisition
2.3. Data Training with Compound Model Scaling
2.3.1. Model Scaling
2.3.2. Compound Model Scaling
3. Results
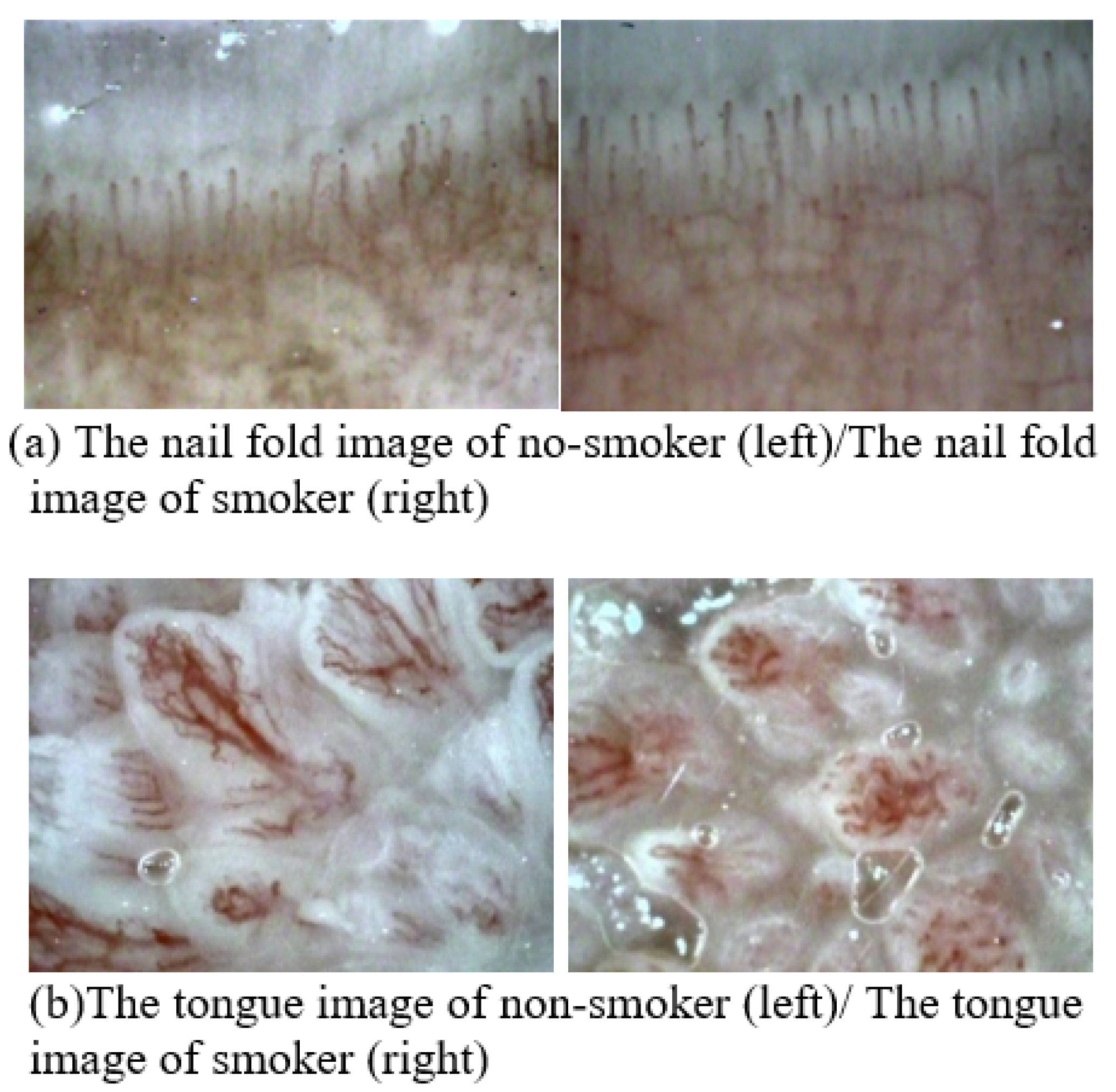
3.1. Example of Dataset
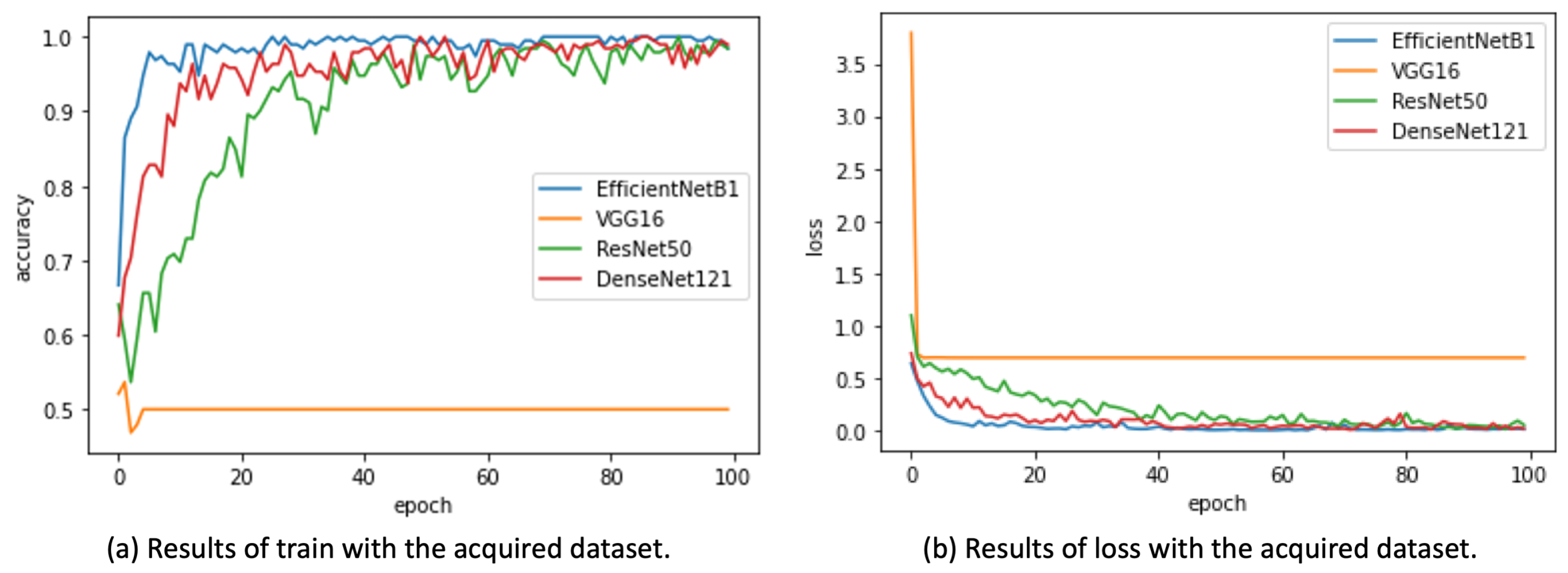
3.2. Results of the Training and Prediction
3.3. Results of the Class Activation Map
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chéruel, F.; Jarlier, M.; Sancho-Garnier, H. Effect of cigarette smoke on gustatory sensitivity, evalution of the deficit and of the recovery time-course after smoking cessation. Tob. Induc. Dis. 2017, 15, 1–8. [Google Scholar]
- Pavlos, P.; Vasilios, N.; Antonia, A.; Dimitrios, K.; Georgios, K.; Georgios, A. Evaluation of young smokers and non-smokers with Electrogustometry and Contact Endoscopy. BMC Ear Nose Throat Disord. 2009, 9, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- AI-Shammari, K.F.; Moussa, M.A.; AI-Ansari, J.M.; AI-Duwairy, Y.S.; Honkala, E.J. Dental patient awareness of smoking effects on oral health: Comparison of smokers and non-smokers. J. Dent. 2006, 34, 173–178. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.; Lee, D.; Joo, N. Reduction of the Nailfold Capillary Blood Velocity in Cigarette Smokers. Korean J. Fam. Med. 2012, 33, 398–405. [Google Scholar] [CrossRef] [PubMed]
- Dallongeville, J.; Marecaux, N.; Fruchart, J.C.; Amouyel, P. Cigarette smoking is associated with unhealthy patterns of nutrient intake: A meta-analysis. J. Nutr. 1998, 128, 1450–1457. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Northrop-Clewes, C.A.; Thurnham, D.I. Monitoring micronutrients in cigarette smokers. Clin. Chim. Acta 2007, 377, 14–38. [Google Scholar] [CrossRef] [PubMed]
- Heckmann, J.; Heckmann, S.; Lang, C.; Hummel, T. Neurological Aspects of Taste Disorders. Arch. Neurol. 2003, 60, 667–671. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zuniga, J.; Chen, N.; Miler, I.J. Effects of chorda lingual nerve injury and repair on human-taste. Chem. Senses 1994, 19, 657–665. [Google Scholar] [CrossRef] [PubMed]
- Xiaoming, H.; Haiqiang, M.; Manquam, D.; Jianyong, S.; Yong, S.; Kela, L.; Xiaoman, L.; Tengbo, H. Examination of nasopharyngeal epithelium with contact endoscopy. Acta Otolaryngol. 2001, 121, 98–102. [Google Scholar]
- Wardrop, P.J.C.; Sim, S.; McLaren, K. Contact endoscopy of the larynx: A quantitative study. J. Laryngol. Otol. 2000, 114, 437–440. [Google Scholar] [CrossRef]
- Suga, S.; Otomo, A.; Jeong, H.; Ohno, Y. Image similarity check of nailfold capillary by template matching. In Proceedings of the IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 799–803. [Google Scholar]
- Bourquard, A.; Butterworth, I.; Sanchez-Ferro, A.; Giancardo, L.; Soenksen, L.; Cerrato, C.; Flores, R.; Castro-Gonzalez, C. Analysis of white blood cell dynamics in nailfold capillaries. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milano, Italy, 25–29 August 2015; pp. 7470–7473. [Google Scholar]
- Van den Hoogen, F.; Khanna, D.; Fransen, J.; Johnson, S.R.; Baron, M.; Tyndall, A.; Pope, J.E. 2013 classification criteria for systemic sclerosis: An American college of rheumatology/European league against rheumatism collaborative initiative. Ann. Rheum. Dis. 2013, 72, 1747–1755. [Google Scholar] [CrossRef] [Green Version]
- Cutolo, M. Capillaroscopy in rheumatic diseases from the XVIII to the XXI century. In Atlas of Capillaroscopy in Rheumatic Diseases; Elsevier: Amsterdam, The Netherlands, 2010. [Google Scholar]
- Smith, V.; Herrick, A.L.; Ingegnoli, F.; Damjanov, N.; De Angelis, R.; Denton, C.P.; Cutolo, M. Standardisation of nailfold capillaroscopy for the assessment of patients with Raynaud’s phenomenon and systemic sclerosis. Autoimmun. Rev. 2020, 19, 102458. [Google Scholar] [CrossRef]
- Hariyani, Y.; Eom, H.; Park, C. DA-CapNet: Dual Attention Deep Learning based on U-Net for Nailfold Capillary Segmentation. IEEE Access 2020, 8, 10543–10553. [Google Scholar] [CrossRef]
- Karbalaie, A.; Etehadtavakol, M.; Abtahi, F.; Fatemi, A.; Emrani, Z.; Erlandsson, B.E. Image enhancement effect on inter and intra-observer reliability of nailfold capillary assessment. Microvasc. Res. 2018, 120, 100–110. [Google Scholar] [CrossRef] [PubMed]
- Isgrò, F.; Pane, F.; Porzio, G.; Pennarola, R.; Pennarola, E. Segmentation of nailfold capillaries from microscopy video sequences. In Proceedings of the 26th IEEE International Symposium on Computer-Based Medical Systems (CBMS), Porto, Portugal, 20–22 June 2013; pp. 227–232. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional netwroks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Goko Imaging Devices, Co., Ltd. Imaging Products. Available online: https://www.gokocamera.com/english/ev/ (accessed on 11 March 2021).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556v6. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. arXiv 2018, arXiv:1608.06993. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Jason Brownlee: A Gentle Introduction to Channels-First and Channels-Last Image Formats. Available online: https://machinelearningmastery.com/a-gentle-introduction-to-channels-first-and-channels-last-image-formats-for-deep-learning/ (accessed on 12 September 2019).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 11, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Netwroks. arXiv 2017, arXiv:1611.05431. [Google Scholar]
- Hwang, Y.; Lee, H.H.; Park, C.; Tama, B.A.T.; Kim, J.S.; Cheung, D.Y.; Chung, W.C.; Cho, Y.; Lee, K.; Choi, M.; et al. Improved classification and localization approach to small bowel capsule endoscopy using convolutional neural network. Dig. Endosc. 2020. [Google Scholar] [CrossRef] [PubMed]
- Brunet, D.; Vass, J.; Vrscay, E.R.; Wang, Z. On the mathematical properties of the structural similarity index. IEEE Trans. Image Process. 2012, 21, 2324–2328. [Google Scholar] [CrossRef] [PubMed]
- Matthew, T.; William, M.W. SIFT-Rank: Ordinal descriptors for invariant feature correspondence. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 172–177. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Portability | Magnification | Costs |
|---|---|---|---|
| Stereomicroscopy | Not practical | Ranging between 10 and 200× | Medium to high |
| ophthalmoscopy | Very good | Up to 15× | Low |
| Dermatoscopy | Very good | Up to 10× | Low to medium |
| Smartphone devices | Very good | Up to 20× | Low |
| Digital USB microscopy | Good (laptop connection) | Up to 300× | Low to medium |
| Digital videocapillaroscopy | Good (laptop connection) | Raging between 50 and 500× | High |
| Feature | Descriptions |
|---|---|
| 2-ways-to-use | Desk and handheld. |
| Stand unit | Robust and is attached, |
| - | Reduces the tremors. |
| Zoom and focus | Powerful zoom, |
| - | Easy to focus |
| - | No need to change lenses. |
| Live video | Capture smooth without time lags. |
| Magnification | 100× to 410× (on 14-inch monitor). |
| Dimensions | 45 (external diameter) × 96 (length) mm |
| - | without attachment, |
| - | 45 (external diameter) × 106 (length) mm |
| - | with attachment. |
| Model | Total Params | Trainable | Non-Trainable |
|---|---|---|---|
| EfficientNet-B1 | 6,576,513 | 6,514,465 | 62,048 |
| VGG16 | 14,715,201 | 14,715,201 | 0 |
| ResNet50 | 23,589,761 | 23,536,641 | 53,120 |
| DenseNet121 | 7,038,529 | 6,954,881 | 83,648 |
| Model | Accuracy [%] | Loss |
|---|---|---|
| EfficientNet-B1 | 79.68 | 1.39 |
| VGG16 | 50.00 | 0.69 |
| ResNet50 | 60.94 | 0.89 |
| DenseNet121 | 48.43 | 3.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen Thi Phuong, H.; Shin, C.-S.; Jeong, H.-Y. Finding the Differences in Capillaries of Taste Buds between Smokers and Non-Smokers Using the Convolutional Neural Networks. Appl. Sci. 2021, 11, 3460. https://0-doi-org.brum.beds.ac.uk/10.3390/app11083460
Nguyen Thi Phuong H, Shin C-S, Jeong H-Y. Finding the Differences in Capillaries of Taste Buds between Smokers and Non-Smokers Using the Convolutional Neural Networks. Applied Sciences. 2021; 11(8):3460. https://0-doi-org.brum.beds.ac.uk/10.3390/app11083460
Chicago/Turabian StyleNguyen Thi Phuong, Hang, Choon-Sung Shin, and Hie-Yong Jeong. 2021. "Finding the Differences in Capillaries of Taste Buds between Smokers and Non-Smokers Using the Convolutional Neural Networks" Applied Sciences 11, no. 8: 3460. https://0-doi-org.brum.beds.ac.uk/10.3390/app11083460