
A Whole-Slide Image Managing Library Based on Fastai for Deep Learning in the Context of Histopathology: Two Use-Cases Explained

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
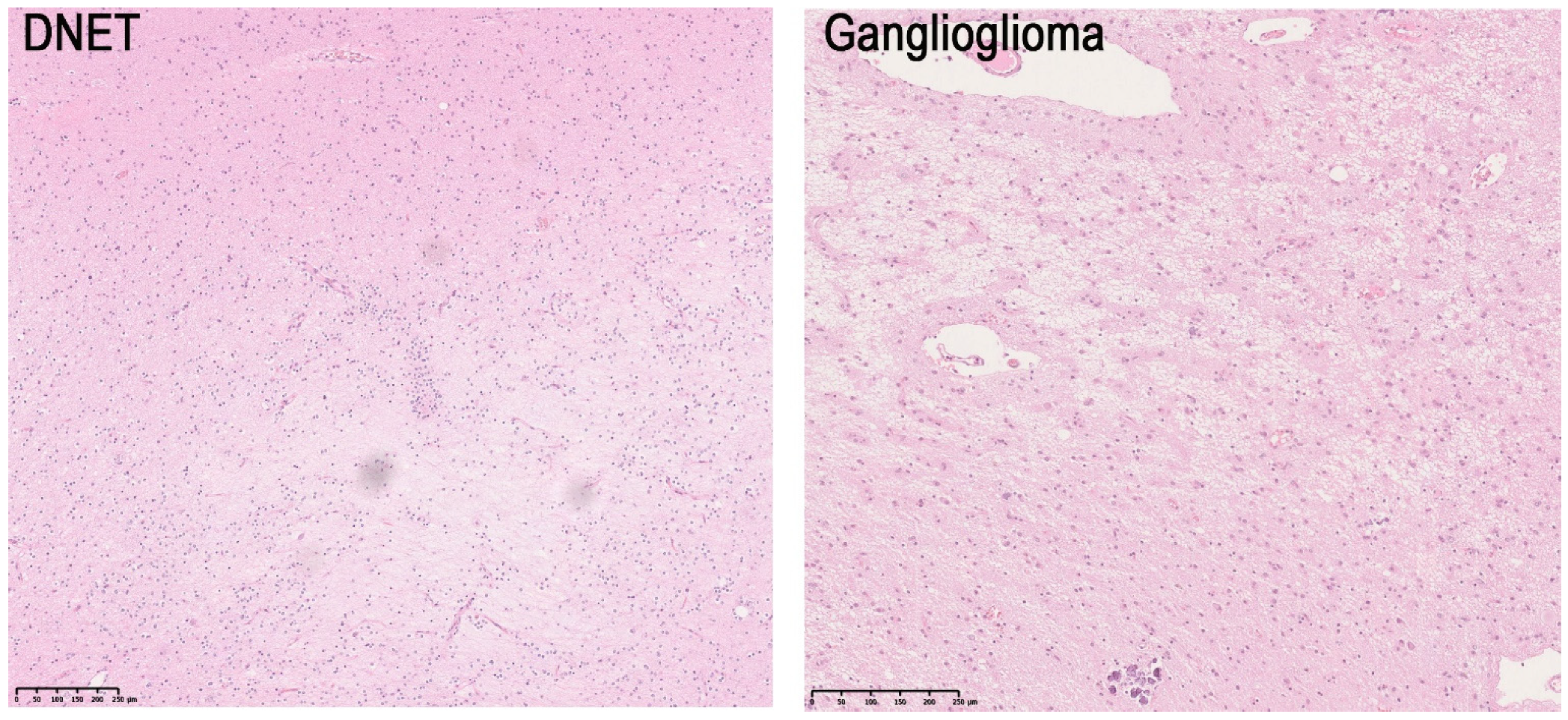
1.1. Use Case 1: Classifying Low-Grade Epilepsy-Associated Brain Tumors
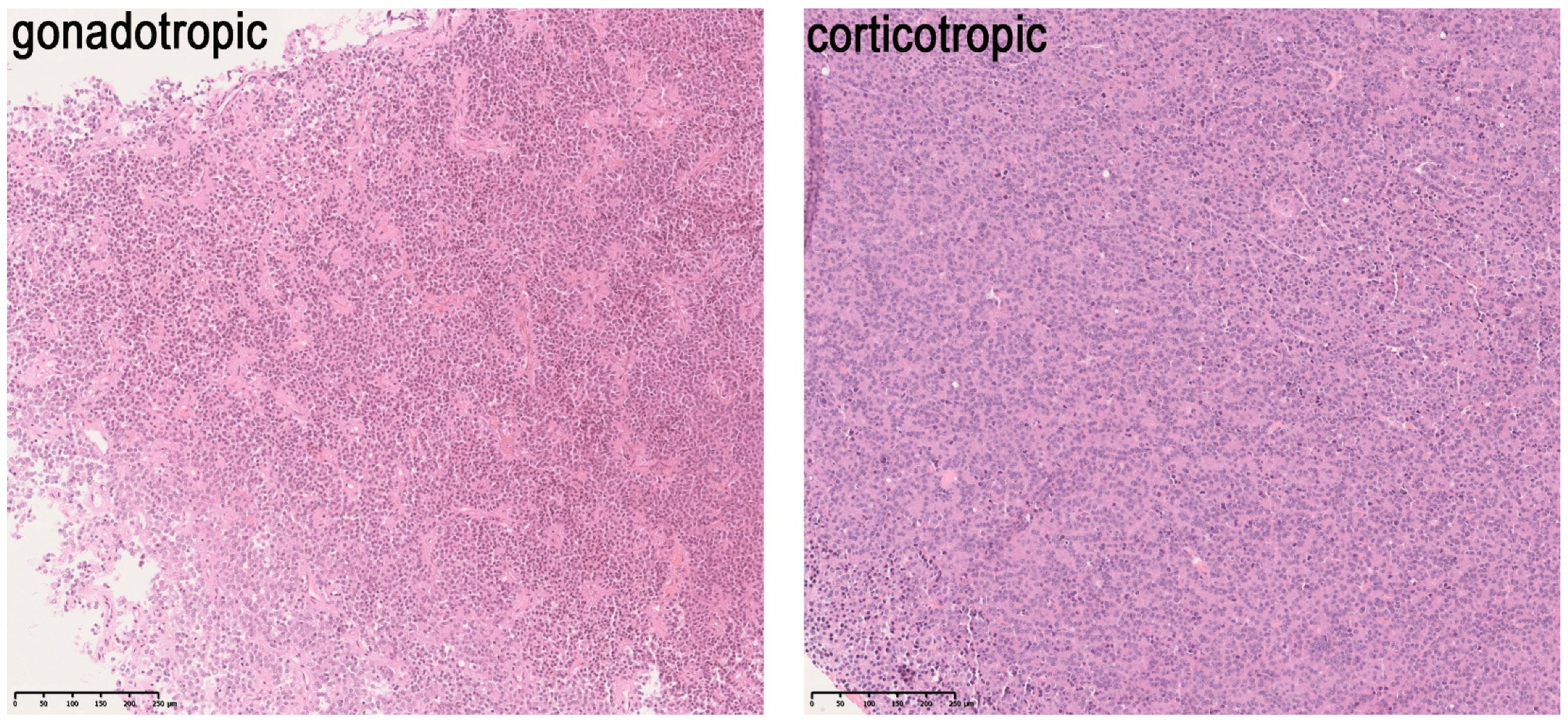
1.2. Use Case 2: Prediction of Pituitary Adenoma Subtypes and Their Neuroendocrine Features
2. Materials and Methods
2.1. The Library
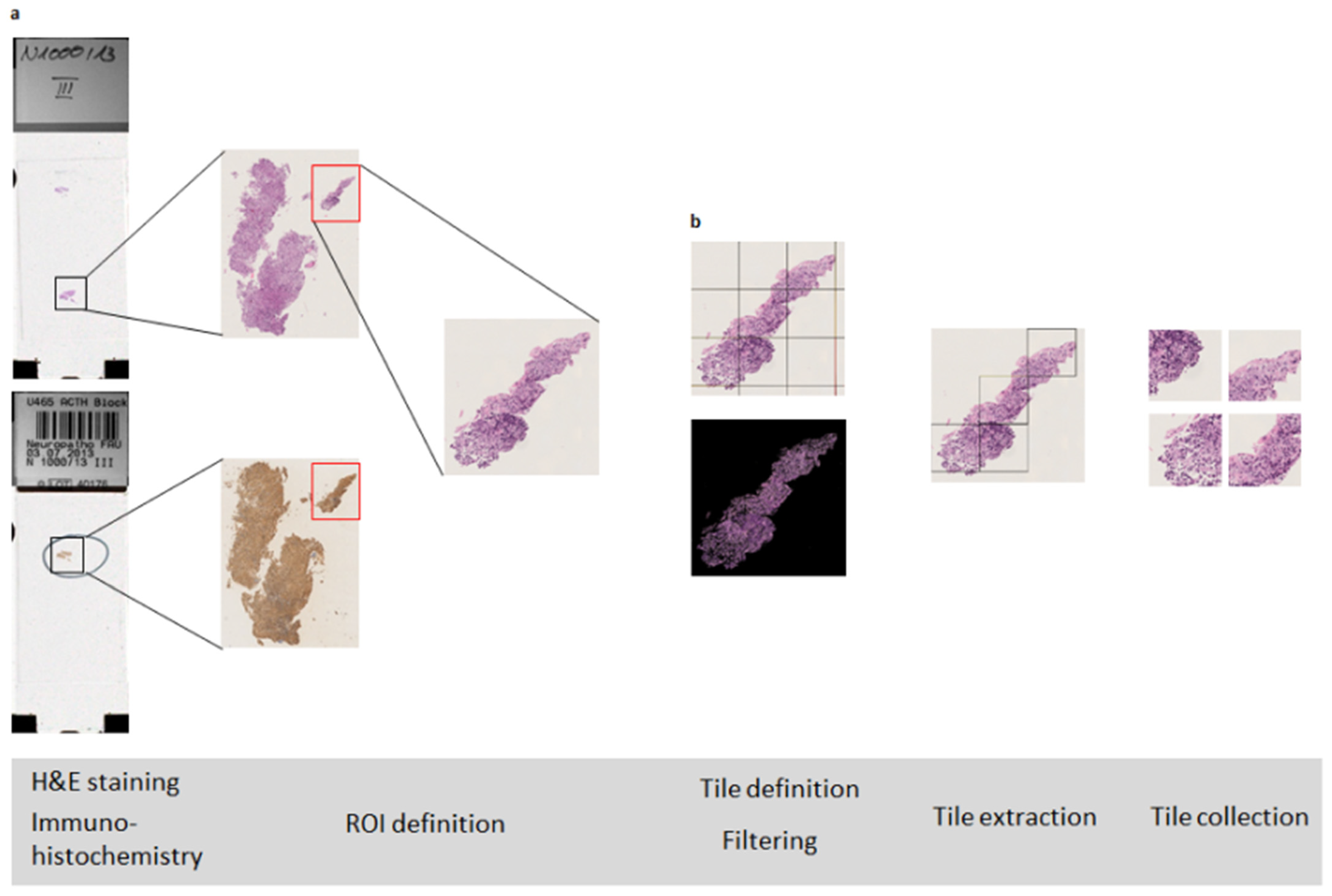
2.2. Tile Calculation
2.3. Filters Applied on Complete WSI
2.4. Calculation of Tile Locations
2.5. Tile Filtering
2.6. Dataset Preparation for Both Use-Cases
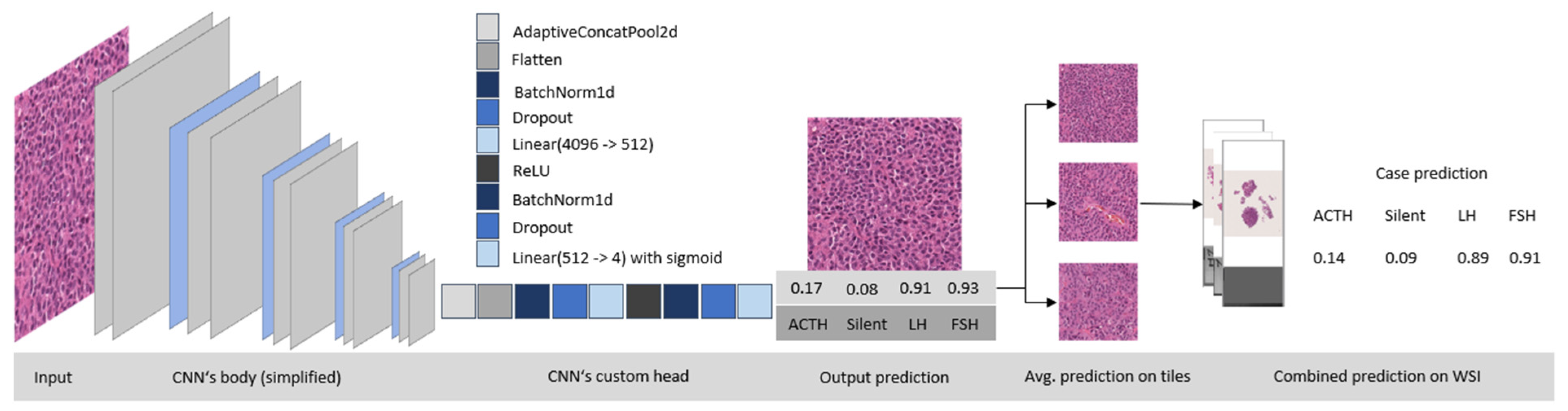
2.7. Convolutional Neural Network Architecture
2.8. Preprocessing and Data Augmentation
2.9. Training and Evaluation
2.10. Hardware
2.11. Availability and Implementation
3. Results
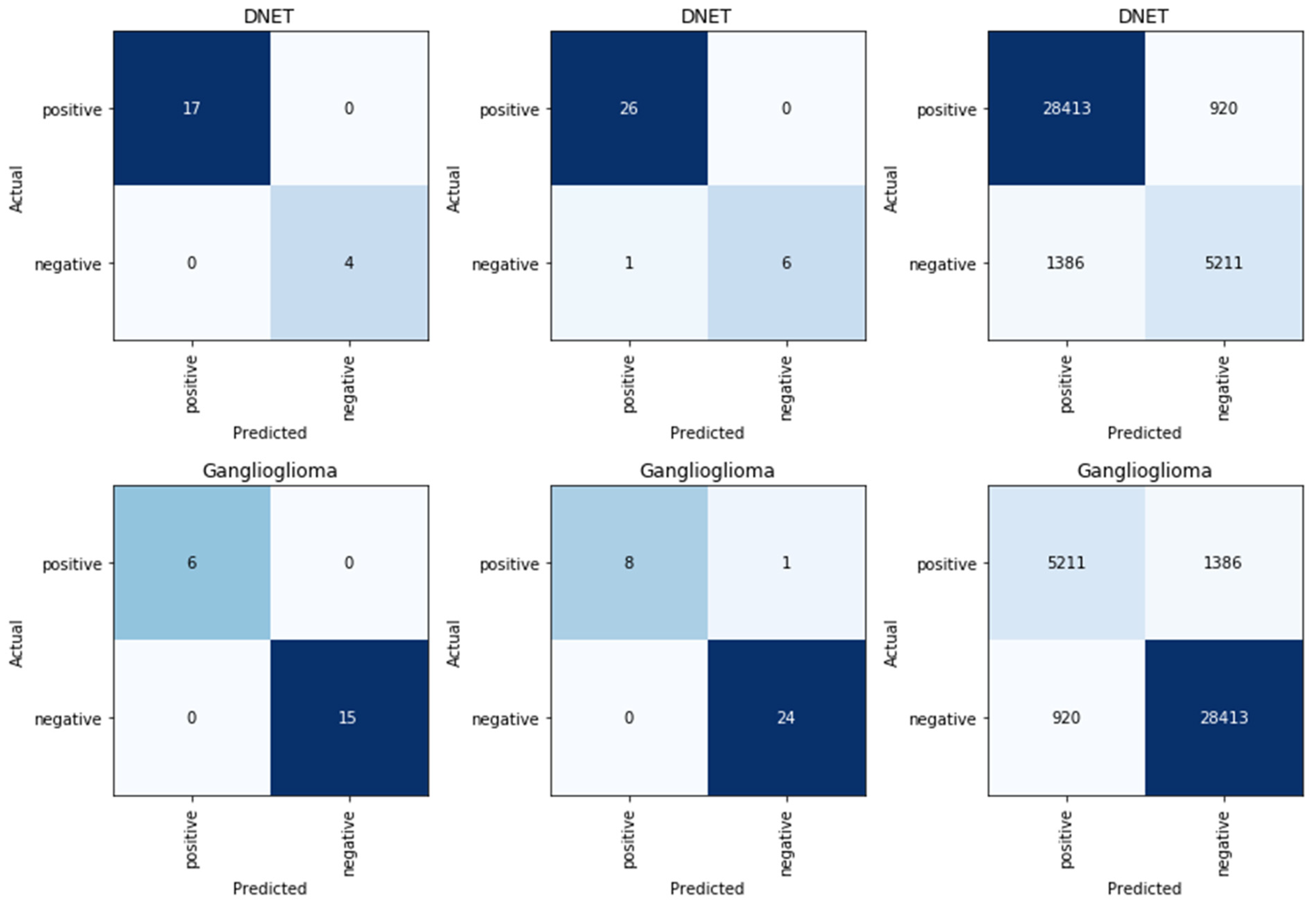
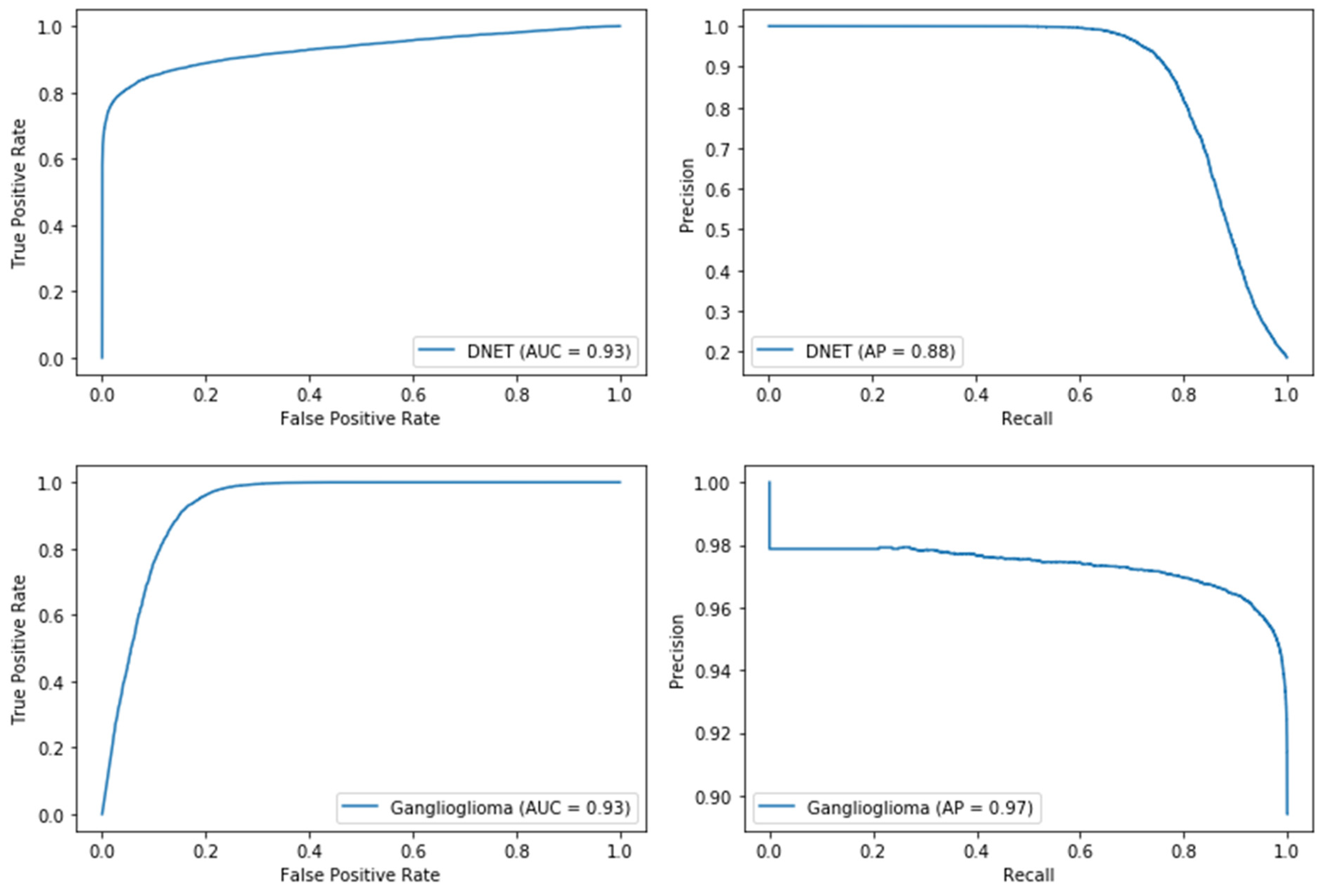
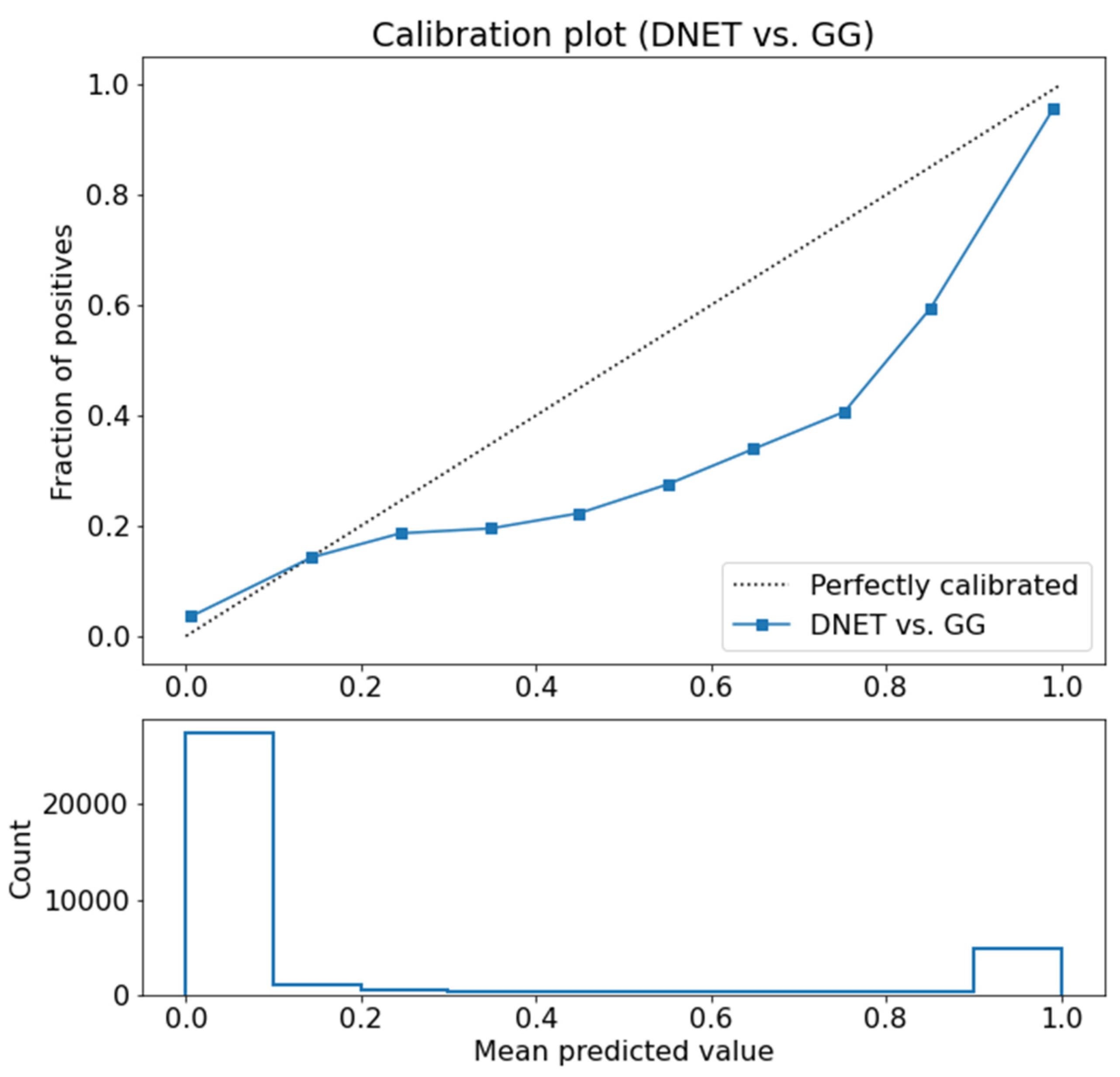
3.1. Use Case 1: DNET-GG Classifier
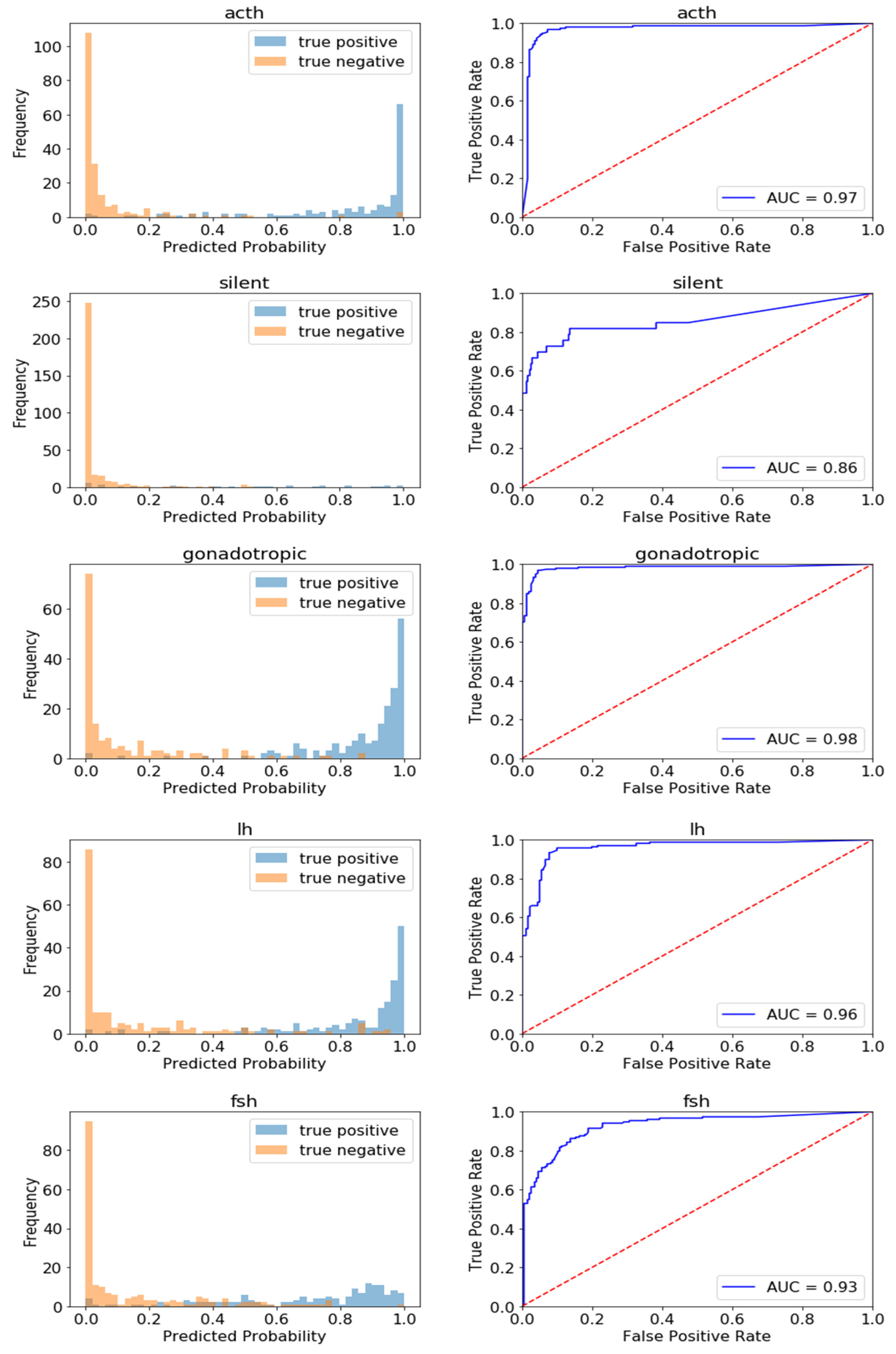
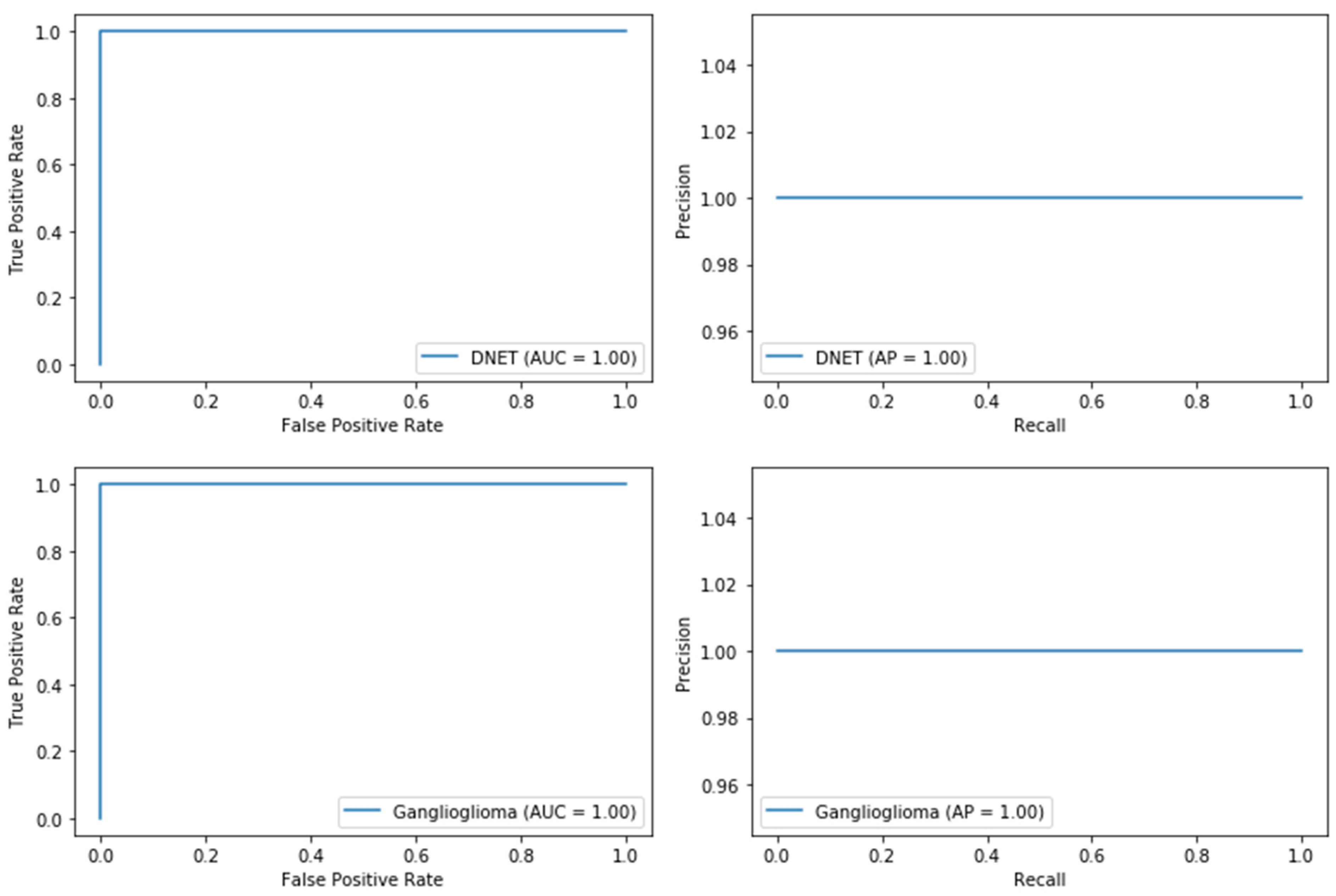
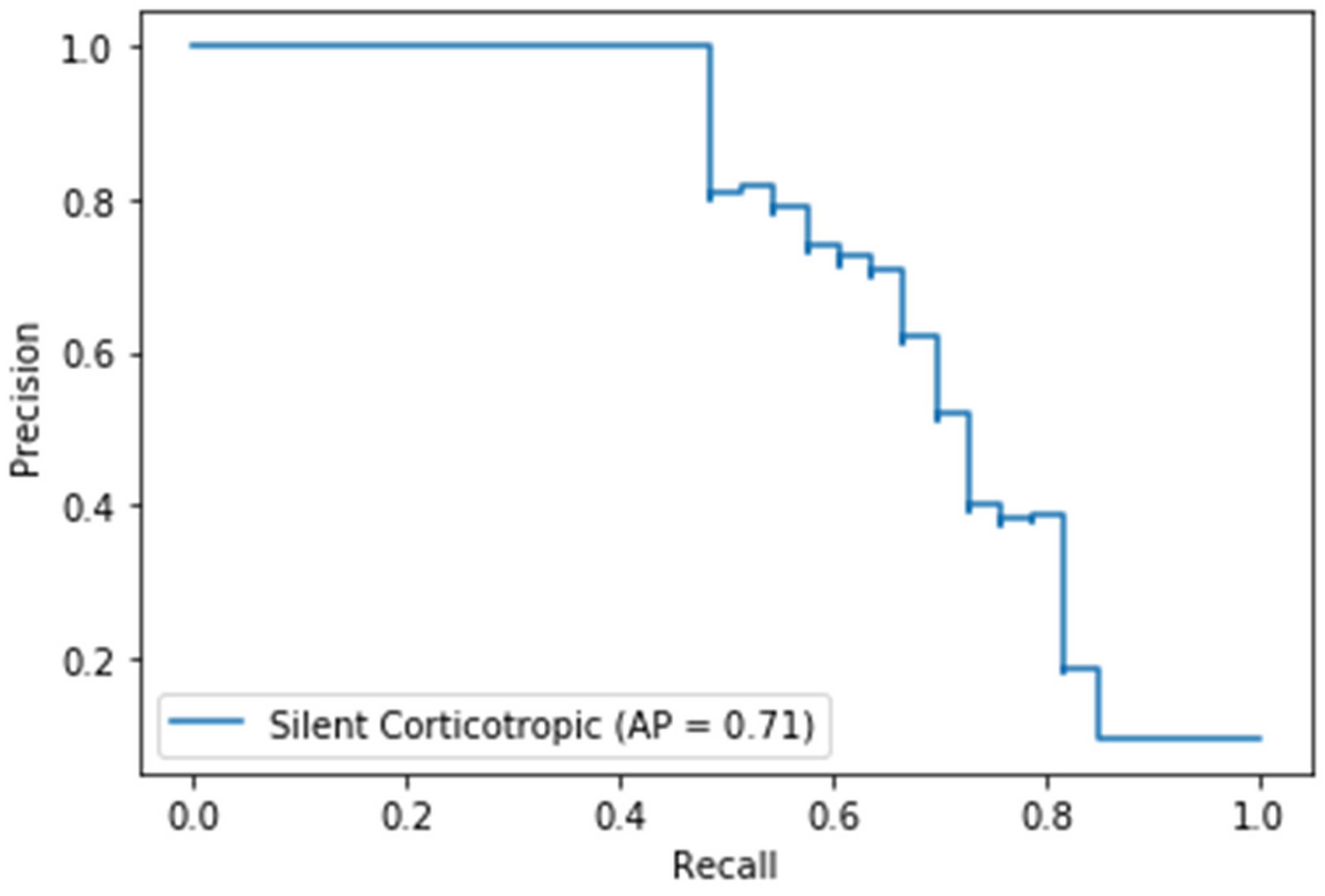
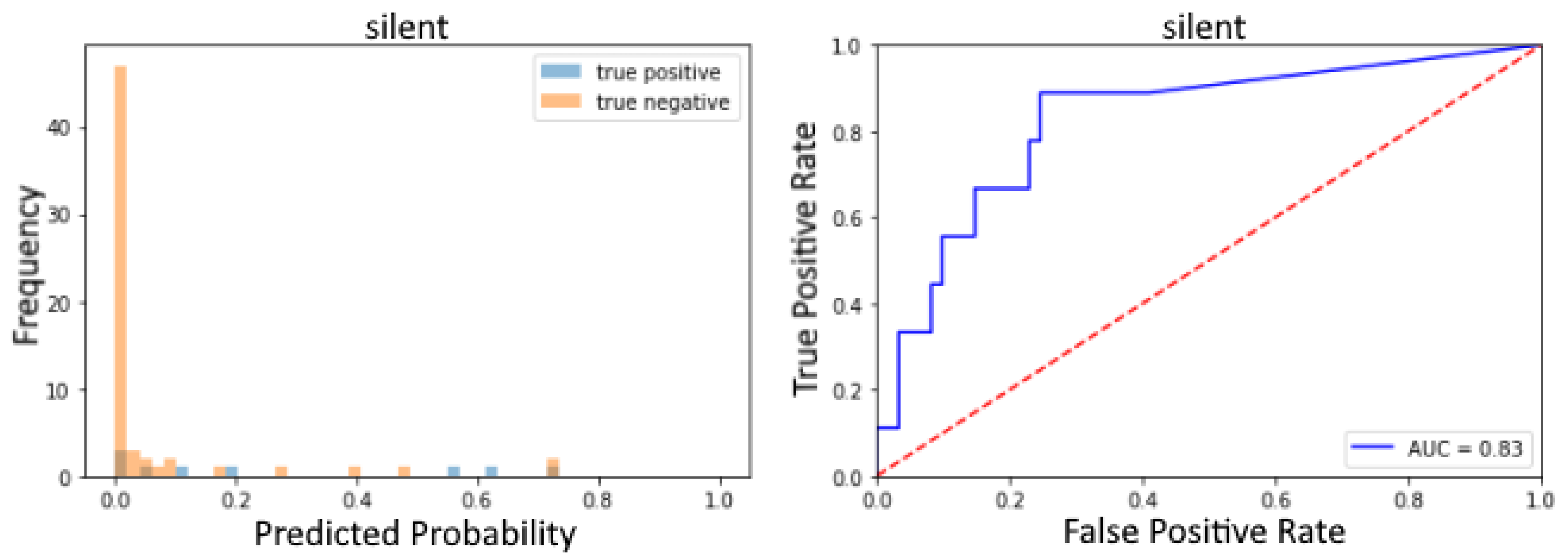
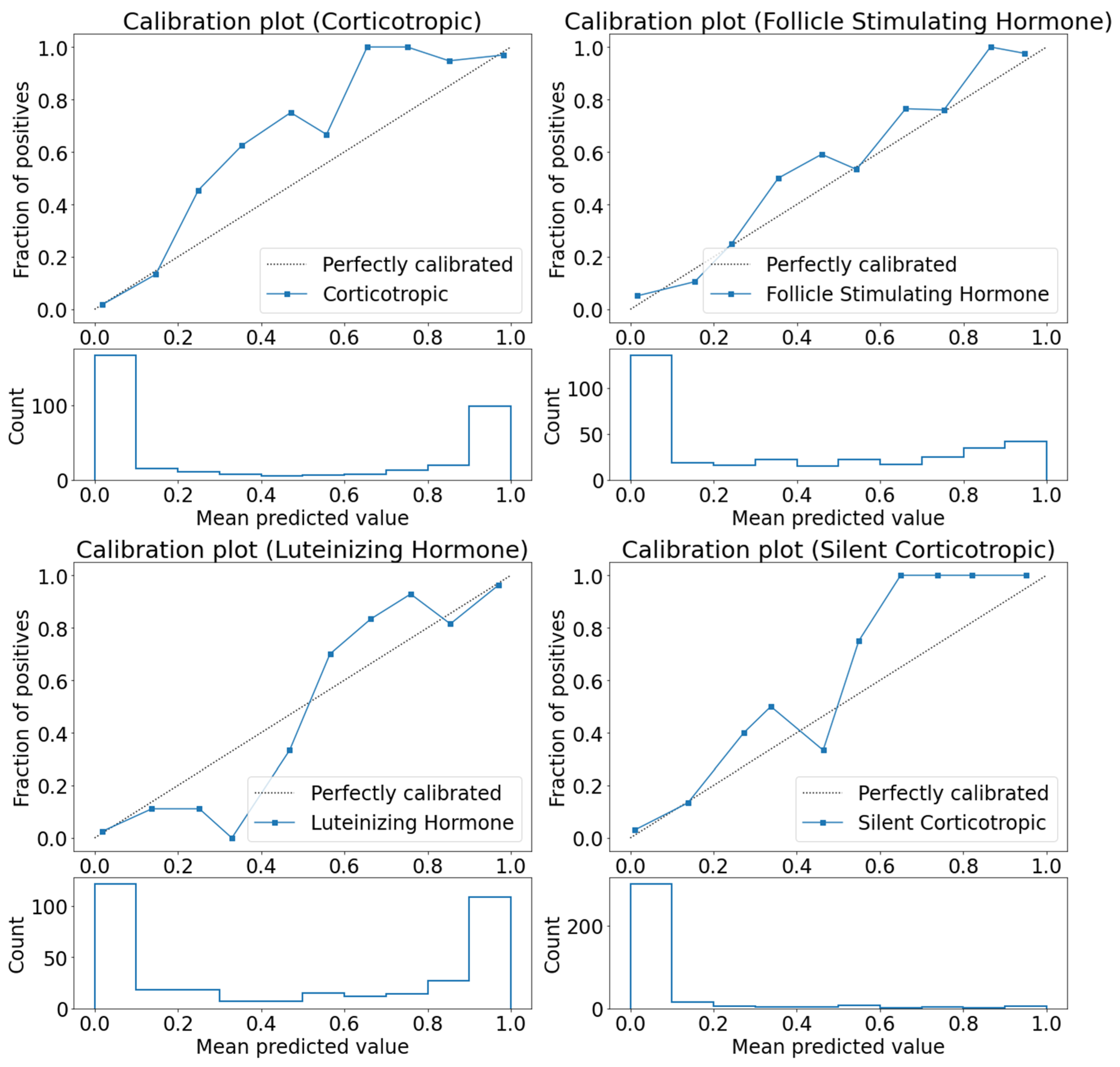
3.2. Use Case 2: Pituitary Adenoma Classifier
4. Discussion
Limitations and Potential Solutions Moving into the Future
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bejnordi, B.E.; Veta, M.; Van Diest, P.J.; Van Ginneken, B.; Karssemeijer, N.; Litjens, G.; Van Der Laak, J.A.W.M.; Hermsen, M.; Manson, Q.F.; Balkenhol, M.; et al. Diagnostic Assessment of Deep Learning Algorithms for Detection of Lymph Node Metastases in Women With Breast Cancer. JAMA 2017, 318, 2199–2210. [Google Scholar] [CrossRef]
- Arvaniti, E.; Fricker, K.S.; Moret, M.; Rupp, N.; Hermanns, T.; Fankhauser, C.; Wey, N.; Wild, P.J.; Rüschoff, J.H.; Claassen, M. Automated Gleason grading of prostate cancer tissue microarrays via deep learning. Sci. Rep. 2018, 8, 12054. [Google Scholar] [CrossRef]
- Kubach, J.; Muhlebner-Fahrngruber, A.; Soylemezoglu, F.; Miyata, H.; Niehusmann, P.; Honavar, M.; Rogerio, F.; Kim, S.H.; Aronica, E.; Garbelli, R.; et al. Same same but different: A Web-based deep learning application revealed classifying features for the histopathologic distinction of cortical malformations. Epilepsia 2020, 61, 421–432. [Google Scholar] [CrossRef]
- Tang, Z.; Chuang, K.V.; DeCarli, C.; Jin, L.-W.; Beckett, L.; Keiser, M.J.; Dugger, B.N. Interpretable classification of Alzheimer’s disease pathologies with a convolutional neural network pipeline. Nat. Commun. 2019, 10, 2173. [Google Scholar] [CrossRef] [Green Version]
- Van der Laak, J.; Litjens, G.; Ciompi, F. Deep learning in histopathology: The path to the clinic. Nat. Med. 2021, 27, 775–784. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Janowczyk, A.; Madabhushi, A. Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases. J. Pathol. Inform. 2016, 7, 29. [Google Scholar] [CrossRef]
- Coudray, N.; Ocampo, P.S.; Sakellaropoulos, T.; Narula, N.; Snuderl, M.; Fenyö, D.; Moreira, A.L.; Razavian, N.; Tsirigos, A. Classification and mutation prediction from non–small cell lung cancer histopathology images using deep learning. Nat. Med. 2018, 24, 1559–1567. [Google Scholar] [CrossRef]
- Steiner, D.F.; Macdonald, R.; Liu, Y.; Truszkowski, P.; Hipp, J.D.; Gammage, C.; Thng, F.; Peng, L.; Stumpe, M.C. Impact of Deep Learning Assistance on the Histopathologic Review of Lymph Nodes for Metastatic Breast Cancer. Am. J. Surg. Pathol. 2018, 42, 1636–1646. [Google Scholar] [CrossRef]
- Blümcke, I.; Coras, R.; Wefers, A.K.; Capper, D.; Aronica, E.; Becker, A.; Honavar, M.; Stone, T.J.; Jacques, T.S.; Miyata, H.; et al. Review: Challenges in the histopathological classification of ganglioglioma and DNT: Microscopic agreement studies and a preliminary genotype-phenotype analysis. Neuropathol. Appl. Neurobiol. 2018, 45, 95–107. [Google Scholar] [CrossRef]
- Majores, M.; von Lehe, M.; Fassunke, J.; Schramm, J.; Becker, A.J.; Simon, M. Tumor recurrence and malignant progression of gangliogliomas. Cancer 2008, 113, 3355–3363. [Google Scholar] [CrossRef] [PubMed]
- Selvanathan, S.K.; Hammouche, S.; Salminen, H.J.; Jenkinson, M. Outcome and prognostic features in anaplastic ganglioglioma: Analysis of cases from the SEER database. J. Neuro-Oncol. 2011, 105, 539–545. [Google Scholar] [CrossRef]
- Thom, M.; Toma, A.; An, S.; Martinian, L.; Hadjivassiliou, G.; Ratilal, B.; Dean, A.; McEvoy, A.; Sisodiya, S.M.; Brandner, S. One Hundred and One Dysembryoplastic Neuroepithelial Tumors: An Adult Epilepsy Series With Immunohistochemical, Molecular Genetic, and Clinical Correlations and a Review of the Literature. J. Neuropathol. Exp. Neurol. 2011, 70, 859–878. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Slegers, R.J.; Blumcke, I. Low-grade developmental and epilepsy associated brain tumors: A critical update 2020. Acta Neuropathol. Commun. 2020, 8, 27. [Google Scholar] [CrossRef] [PubMed]
- Ezzat, S.; Asa, S.L.; Couldwell, W.T.; Barr, C.E.; Dodge, W.E.; Vance, M.L.; McCutcheon, I.E. The prevalence of pituitary adenomas. Cancer 2004, 101, 613–619. [Google Scholar] [CrossRef]
- Aflorei, E.D.; Korbonits, M. Epidemiology and etiopathogenesis of pituitary adenomas. J. Neuro-Oncol. 2014, 117, 379–394. [Google Scholar] [CrossRef]
- Inoshita, N.; Nishioka, H. The 2017 WHO classification of pituitary adenoma: Overview and comments. Brain Tumor Pathol. 2018, 35, 51–56. [Google Scholar] [CrossRef]
- Vizcarra, J.C.; Gearing, M.; Keiser, M.J.; Glass, J.D.; Dugger, B.N.; Gutman, D.A. Validation of machine learning models to detect amyloid pathologies across institutions. Acta Neuropathol. Commun. 2020, 8, 59. [Google Scholar] [CrossRef]
- Signaevsky, M.; Prastawa, M.; Farrell, K.; Tabish, N.; Baldwin, E.; Han, N.; Iida, M.A.; Koll, J.; Bryce, C.; Purohit, D.; et al. Artificial intelligence in neuropathology: Deep learning-based assessment of tauopathy. Lab. Investig. 2019, 99, 1019–1029. [Google Scholar] [CrossRef]
- Koga, S.; Ikeda, A.; Dickson, D.W. Deep learning-based model for diagnosing Alzheimer’s disease and tauopathies. Neuropathol. Appl. Neurobiol. 2021. [Google Scholar] [CrossRef]
- Vega, A.R.; Chkheidze, R.; Jarmale, V.; Shang, P.; Foong, C.; Diamond, M.I.; White, C.L.; Rajaram, S. Deep learning reveals disease-specific signatures of white matter pathology in tauopathies. Acta Neuropathol. Commun. 2021, 9, 170. [Google Scholar] [CrossRef] [PubMed]
- Jin, L.; Shi, F.; Chun, Q.; Chen, H.; Ma, Y.; Wu, S.; Hameed, N.U.F.; Mei, C.; Lu, J.; Zhang, J.; et al. Artificial intelligence neuropathologist for glioma classification using deep learning on hematoxylin and eosin stained slide images and molecular markers. Neuro-Oncology 2020, 23, 44–52. [Google Scholar] [CrossRef]
- Neuner, C. Python-Wsi-Preprocessing. GitHub. 2019. Available online: https://github.com/FAU-DLM/python-wsi-preprocessing (accessed on 16 December 2021).
- Veta, M.; Heng, Y.J.; Stathonikos, N.; Bejnordi, B.E.; Beca, F.; Wollmann, T.; Rohr, K.; Shah, M.A.; Wang, D.; Rousson, M.; et al. Predicting breast tumor proliferation from whole-slide images: The TUPAC16 challenge. Med. Image Anal. 2019, 54, 111–121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eriksson, D. Python-Wsi-Preprocessing. GitHub. 2018. Available online: https://github.com/deroneriksson/python-wsi-preprocessing (accessed on 28 December 2019).
- Bankhead, P.; Loughrey, M.B.; Fernández, J.A.; Dombrowski, Y.; McArt, D.G.; Dunne, P.D.; McQuaid, S.; Gray, R.T.; Murray, L.J.; Coleman, H.G.; et al. QuPath: Open source software for digital pathology image analysis. Sci. Rep. 2017, 7, 16878. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paeng, K.; Hwang, S.; Park, S.; Kim, M. A Unified Framework for Tumor Proliferation Score Prediction in Breast Histopathology. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 231–239. [Google Scholar] [CrossRef] [Green Version]
- Pascale, D. A Reviw of RGB Color Spaces. 6 October 2003. Available online: https://www.babelcolor.com/index_htm_files/A%20review%20of%20RGB%20color%20spaces.pdf (accessed on 28 November 2021).
- Zenil, H. HSV Colors. 1 March 2011. Available online: https://demonstrations.wolfram.com/HSVColors/ (accessed on 28 November 2021).
- Howard, J.; Gugger, S. Fastai: A Layered API for Deep Learning. Information 2020, 11, 108. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://proceedings.neurips.cc/paper/2019/file/bdbca288fee7f92f2bfa9f7012727740-Paper.pdf (accessed on 16 December 2021).
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? arXiv 2016, arXiv:1611.07450. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Saining, X.; Ross, G.; Piotr, D.; Zhuowen, T.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2016, arXiv:1611.05431. [Google Scholar]
- Cadene, R. Pretrained PyTorch Models. GitHub. 2019. Available online: https://github.com/Cadene/pretrained-models.pytorch (accessed on 16 December 2021).
- Wu, R.; Yan, S.; Shan, Y.; Dang, Q.; Sun, G. Deep Image: Scaling up Image Recognition. arXiv 2015, arXiv:1501.02876. [Google Scholar]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding Data Augmentation for Classification: When to Warp? arXiv 2016, arXiv:1609.08764. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed Precision Training. arXiv 2017, arXiv:1710.03740. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. arXiv 2015, arXiv:1506.01186. [Google Scholar]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arxiv 2017, arXiv:1712.04621. [Google Scholar]
- Madabhushi, A.; Lee, G. Image analysis and machine learning in digital pathology: Challenges and opportunities. Med. Image Anal. 2016, 33, 170–175. [Google Scholar] [CrossRef] [Green Version]
- Anghel, A.; Stanisavljevic, M.; Andani, S.; Papandreou, N.; Rüschoff, J.H.; Wild, P.; Gabrani, M.; Pozidis, H. A High-Performance System for Robust Stain Normalization of Whole-Slide Images in Histopathology. Front. Med. 2019, 6, 193. [Google Scholar] [CrossRef] [PubMed]
- Mete, O.; Lopes, M.B. Overview of the 2017 WHO Classification of Pituitary Tumors. Endocr. Pathol. 2017, 28, 228–243. [Google Scholar] [CrossRef]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neuner, C.; Coras, R.; Blümcke, I.; Popp, A.; Schlaffer, S.M.; Wirries, A.; Buchfelder, M.; Jabari, S. A Whole-Slide Image Managing Library Based on Fastai for Deep Learning in the Context of Histopathology: Two Use-Cases Explained. Appl. Sci. 2022, 12, 13. https://0-doi-org.brum.beds.ac.uk/10.3390/app12010013
Neuner C, Coras R, Blümcke I, Popp A, Schlaffer SM, Wirries A, Buchfelder M, Jabari S. A Whole-Slide Image Managing Library Based on Fastai for Deep Learning in the Context of Histopathology: Two Use-Cases Explained. Applied Sciences. 2022; 12(1):13. https://0-doi-org.brum.beds.ac.uk/10.3390/app12010013
Chicago/Turabian StyleNeuner, Christoph, Roland Coras, Ingmar Blümcke, Alexander Popp, Sven M. Schlaffer, Andre Wirries, Michael Buchfelder, and Samir Jabari. 2022. "A Whole-Slide Image Managing Library Based on Fastai for Deep Learning in the Context of Histopathology: Two Use-Cases Explained" Applied Sciences 12, no. 1: 13. https://0-doi-org.brum.beds.ac.uk/10.3390/app12010013