
Mixed-Flow Load-Balanced Scheduling for Software-Defined Networks in Intelligent Video Surveillance Cloud Data Center


Abstract
:1. Introduction
- A new cloud data center scheduling algorithm (MFLBS) is proposed and formulated to achieve the goal of maximizing throughput.
- Considering the characteristics of both large and small flows, we integrate active congestion control and real-time dynamic scheduling methods, and originally divide the traditional network into two sub-nets, performing network transmission according to the characteristics of different streams and different stages of scheduling. The two sub-nets can adjust the bandwidth allocation ratio V(α) on each link according to different transmission tasks and topological structures.
- A heuristic algorithm is designed for the MFLBS problem and tested on two highly versatile network topologies: the partial mesh model and the three-layer non-blocking fully populated network model.
- A simulation experiment is designed for the cloud data center, and the MFLBS algorithm is compared with two other algorithms: the dynamic scheduling algorithm one-hop DLBS [17] and the static load-balanced scheduling algorithm FCFS [18]. The result proves that our algorithm can significantly improve the throughput and effectively reduce the average delay of the flow.
2. Related Work
2.1. Flow Scheduling
2.2. OpenFlow-Based Schemes
3. Network Model and Problem Statement
3.1. Network Model
3.2. MFLBS Problem
4. Mixed-Flow Load-Balanced Scheduling (MFLBS)
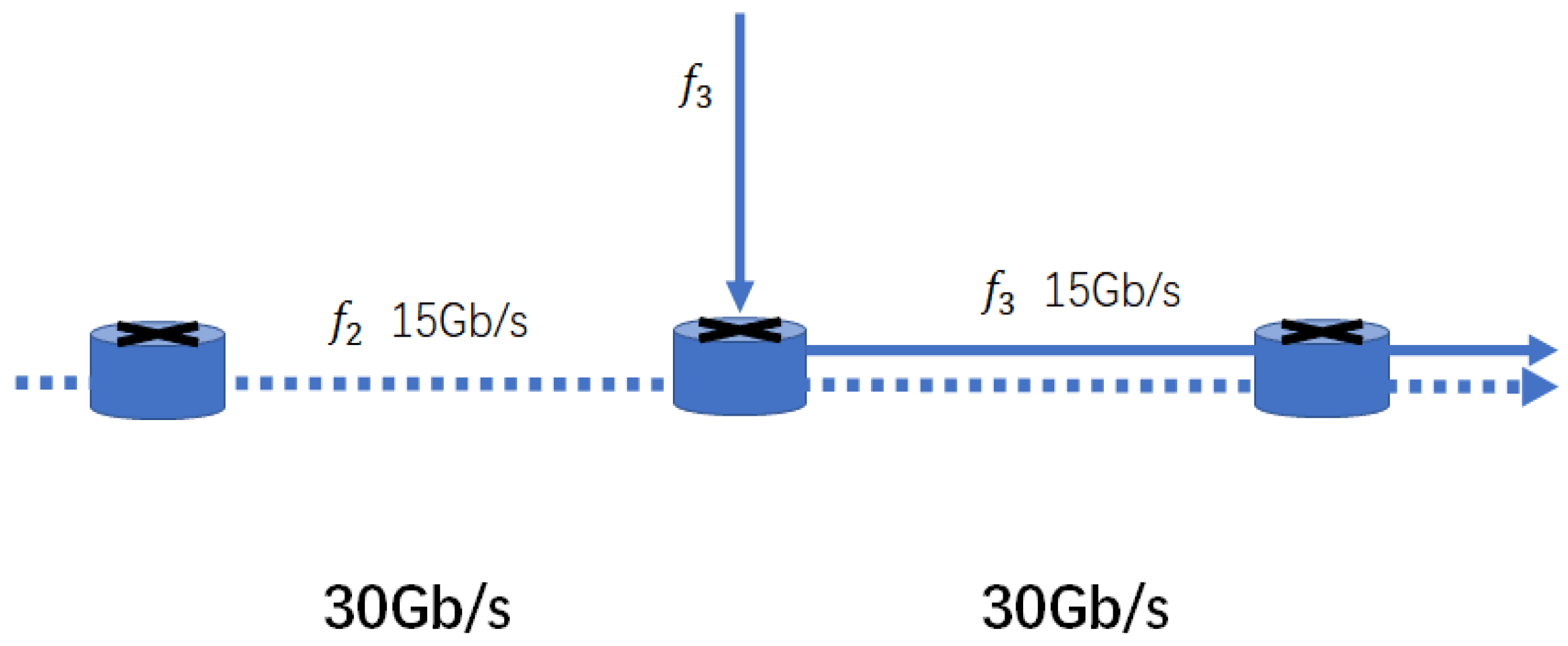
4.1. Dynamic Routing Network
4.1.1. Initial Path Selection
4.1.2. Dynamic Routing Mechanism
| Algorithm 1. Dynamic Routing Network Scheduling |
| Input: remaining bandwidth and maximum allocation flow table |
| Output: load-balanced scheduling |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.2. Static Routing Network
4.2.1. Bandwidth Allocation
4.2.2. Bottleneck Bandwidth Calculation
| Algorithm 2. Static Routing Network Scheduling |
| Input: allocatable resource table |
| Output: load-balanced scheduling |
|
|
|
|
|
|
|
|
|
|
|
|
|
4.3. Mixed-Flow Load-Balanced Scheduled Network
4.3.1. Important Parameters
4.3.2. Mixed-Flow Load-Balanced Scheduled Network Algorithm
| Algorithm 3. MFLBS Algorithm |
| Input: λ, μ, V(α), |
| Output: load-balanced scheduling |
|
|
|
|
|
|
|
|
5. Performance Evaluation
5.1. Evaluation Schemes
- One-hop DLBS. This is an algorithm that dynamically adjusts the network load. Through real-time monitoring of the network status, the unbalanced flow on the link is dynamically scheduled to maximize the network throughput.
- First come first server, FCFS/first in first out, FIFO. This is a classic single-objective task algorithm, which gives priority to meeting the task requirements of the data flow that arrives at the network first.
- Uniform pattern. Each host is equally likely to send and receive data in each time slot. The flow is evenly distributed in the network.
- Semi-central pattern. Each experiment selects a fixed half of the number of hosts to send data packets and randomly sends them to each host on the network, that is, all hosts have the same probability of receiving data packets.
- We will evaluate our algorithm from the following three main evaluation indicators:
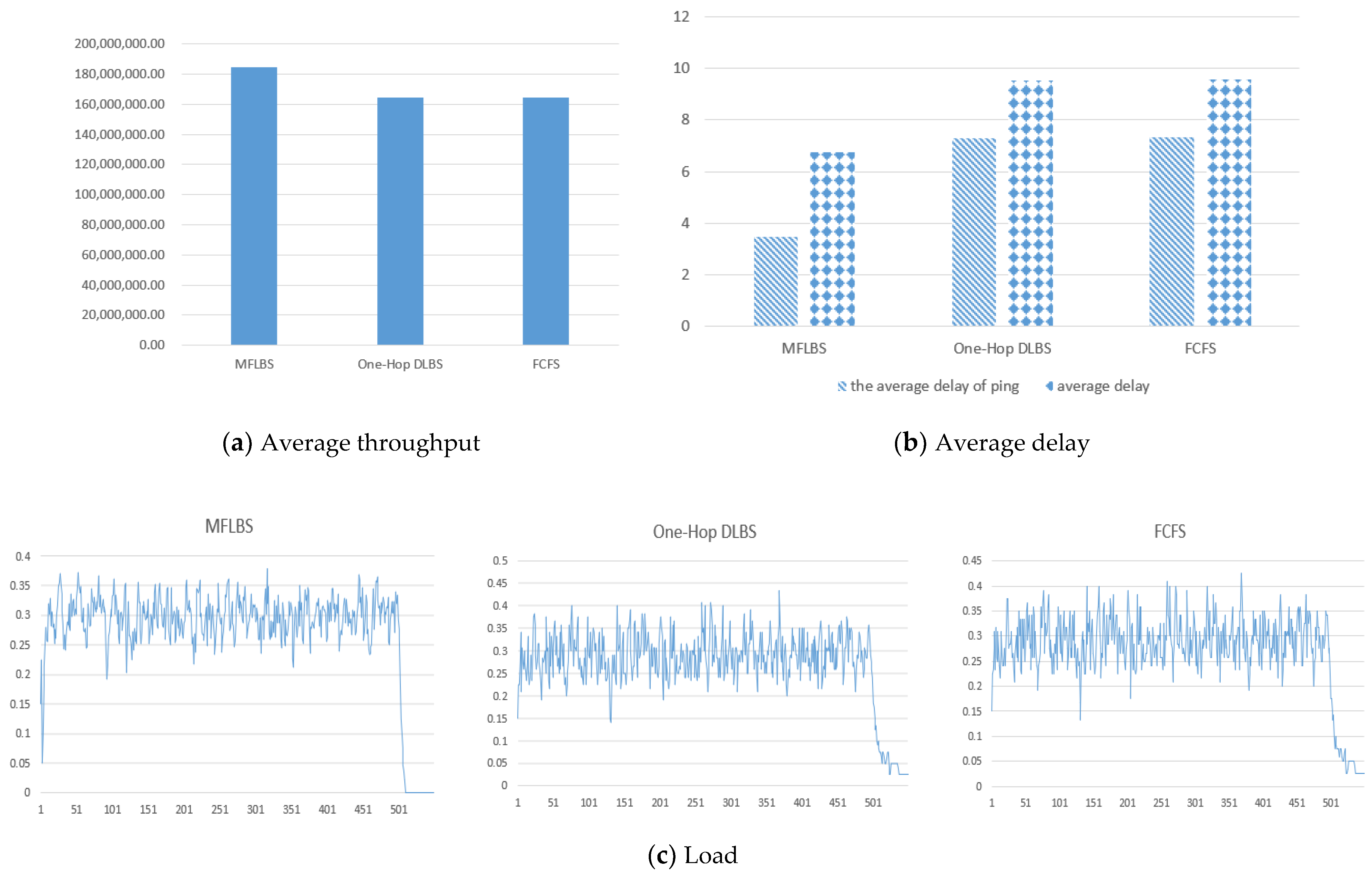
- Average throughput. This is an important indicator to measure network throughput. Here, we divide the total task volume by the time when the scheduling ends to obtain the average throughput of the network. It is worth noting that the unit of the throughput characterization in the figure below is a bit.
- Average delay. Delay is a classic indicator to measure the scheduling algorithm. The calculation method of average delay in this article is the average time interval from a source node to a destination node of data packets. The small flow delay is the average of the sum of all ping delays.
- Global real-time load. The utilization of network bandwidth can be observed from the load. Here, we divide the throughput of the entire network per unit time by the sum of the bandwidth of each link in the topology.
5.2. Experimental Environment Settings
- FPN model. It consists of two core switches, four aggregation layer switches, and four access layer switches. This network is fully populated, and the access layer switch connects with the client host.
- Partial mesh network model. It is mainly composed of nine core switches, and its specific topology is shown in Figure 2. Each switch is connected to its access layer switch, and the access layer switch connects with the client. We will focus on the mesh topology, so the access layer switches are not interconnected.
5.3. Results and Analysis
5.3.1. Performance under the Topology
5.3.2. Performance under Oversized Tasks
6. Conclusions and Future Work
- Network model. The existing algorithms perform better in networks with higher node connectivity. Therefore, we hope to improve the bandwidth allocation method of the flow and improve the performance of the node in the network model with low connectivity.
- Identification of the stream. As the number of tasks increases and the types of mixed flows increase, we plan to further distinguish and identify different types of flows and perform network scheduling in consideration of transmission requirements in detail.
Author Contributions
Funding
Conflicts of Interest
Notations
| Notations | Descriptions |
| Switches | |
| Link between switches | |
| The numbers of the flows passing through the link at this moment | |
| The survival time of the in the network | |
| Capacity of the link between and | |
| The required bandwidth of flow in time slot t | |
| Priority of | |
| E() | The collection of paths the flow passes through |
References
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile edge computing: A survey. IEEE Internet Things J. 2018, 5, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Cai, L.; Pan, J.; Zhao, L.; Shen, X. Networked electric vehicles for green intelligent transportation. IEEE Commun. Stand. Mag. 2017, 1, 77–83. [Google Scholar] [CrossRef]
- Li, Y.; Sun, K.; Cai, L. Cooperative device-to-device communication with network coding for machine type communication devices. IEEE Trans. Wirel. Commun. 2018, 17, 296–309. [Google Scholar] [CrossRef]
- Chen, J.; Hu, K.; Wang, Q.; Sun, Y.; Shi, Z.; He, S. Narrowband Internet of Things: Implementations and applications. IEEE Internet Things J. 2017, 4, 2309–2314. [Google Scholar] [CrossRef]
- Peng, B.; Lei, J.; Fu, H.; Jia, Y.; Zhang, Z.; Li, Y. Deep video action clustering via spatio-temporal feature learning. Neurcomputing 2021, 456, 519–527. [Google Scholar] [CrossRef]
- Lei, J.; Li, X.; Peng, B.; Fang, L.; Ling, N.; Huang, Q. Deep Spatial-Spectral Subspace Clustering for Hyperspectral Image. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2686–2697. [Google Scholar] [CrossRef]
- Pan, Z.; Yu, W.; Lei, J.; Ling, N.; Kwong, S. TSAN: Synthesized View Quality Enhancement via Two-Stream Attention Network for 3D-HEVC. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 345–358. [Google Scholar] [CrossRef]
- Kachris, C.; Tomkos, I. A Survey on Optical Interconnects for Data Centers. IEEE Commun. Surv. Tutor. 2012, 14, 1021–1036. [Google Scholar] [CrossRef]
- Kreutz, D.; Ramos, F.M.V.; Veríssimo, P.E.; Rothenberg, C.E.; Azodolmolky, S.; Uhlig, S. Software-Defined Networking: A Comprehensive Survey. Proc. IEEE 2015, 103, 14–76. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Hao, Q.; Bao, K. A Survey on Software-Defined Network and OpenFlow: From Concept to Implementation. IEEE Commun. Surv. Tutor. 2014, 16, 2181–2206. [Google Scholar] [CrossRef]
- Cardellini, V.; Colajanni, M.; Yu, P.S. Dynamic load balancing on Web-server systems. IEEE Internet Comput. 1999, 3, 28–39. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.; Chen, Z.; Quan, W.; Wen, M. A Performance Study of Static Task Scheduling Heuristics on Cloud-Scale Acceleration Architecture. In Proceedings of the 2019 5th International Conference on Computing and Data Engineering, Shanghai, China, 4–6 May 2019; Association for Computing Machinery: New York, NY, USA; pp. 81–85. [Google Scholar] [CrossRef]
- Dey, N.S.; Gunasekhar, T. A Comprehensive Survey of Load Balancing Strategies Using Hadoop Queue Scheduling and Virtual Machine Migration. IEEE Access 2019, 7, 92259–92284. [Google Scholar] [CrossRef]
- Zhang, J.; Yu, F.R.; Wang, S.; Huang, T.; Liu, Z.; Liu, Y. Load Balancing in Data Center Networks: A Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2324–2352. [Google Scholar] [CrossRef]
- Lee, Y.; Zomaya, A. A Novel State Transition Method for Metaheuristic-Based Scheduling in Heterogeneous Computing Systems. IEEE Trans. Parallel Distrib. Syst. 2008, 19, 1215–1223. [Google Scholar] [CrossRef]
- Singh, R.; Dewra, S. Performance evaluation of star, tree & mesh optical network topologies using optimized Raman-EDFA Hybrid Optical Amplifier. In Proceedings of the 2015 International Conference on Trends in Automation, Communications and Computing Technology (I-TACT-15), Bangalore, India, 21–22 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Tang, F.; Yang, L.T.; Tang, C.; Li, J.; Guo, M. A Dynamical and Load-Balanced Flow Scheduling Approach for Big Data Centers in Clouds. IEEE Trans. Cloud Comput. 2018, 6, 915–928. [Google Scholar] [CrossRef]
- Champati, J.P.; Al-Zubaidy, H.; Gross, J. Statistical Guarantee Optimization for AoI in Single-Hop and Two-Hop FCFS Systems with Periodic Arrivals. IEEE Trans. Commun. 2021, 69, 365–381. [Google Scholar] [CrossRef]
- Dogar, F.R.; Karagiannis, T.; Ballani, H.; Rowstron, A. Decentralized task-aware scheduling for data center networks. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 431–442. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhani, M.F.; Yang, Y.; Boutaba, R.; Wong, B. PRISM: Fine-grained resource-aware scheduling for MapReduce. IEEE Trans. Cloud Comput. 2015, 3, 182–194. [Google Scholar] [CrossRef]
- Wang, Y.; Shi, W. Budget-Driven Scheduling Algorithms for Batches of MapReduce Jobs in Heterogeneous Clouds. IEEE Trans. Cloud Comput. 2014, 2, 306–319. [Google Scholar] [CrossRef]
- Carpio, F.; Engelmann, A.; Jukan, A. DiffFlow: Differentiating Short and Long Flows for Load Balancing in Data Center Networks. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Xu, Q. Load balancing researches in SDN: A survey. In Proceedings of the 2017 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC), Macau, China, 21–23 July 2017; pp. 403–408. [Google Scholar] [CrossRef]
- Tang, W.; Fu, Y.; Dong, P.; Yang, W.; Yang, B.; Xiong, N. A MPTCP Scheduler Combined with Congestion Control for Short Flow Delivery in Signal Transmission. IEEE Access 2019, 7, 116195–116206. [Google Scholar] [CrossRef]
- Shi, J.; Quan, W.; Gao, D.; Liu, M.; Liu, G.; Yu, C.; Su, W. Flowlet-Based Stateful Multipath Forwarding in Heterogeneous Internet of Things. IEEE Access 2020, 8, 74875–74886. [Google Scholar] [CrossRef]
- Cao, X.; Yoshikane, N.; Tsuritani, T.; Morita, I.; Suzuki, M.; Miyazawa, T.; Shiraiwa, M.; Wada, N. Dynamic Openflow-Controlled Optical Packet Switching Network. J. Lightwave Technol. 2015, 33, 1500–1507. [Google Scholar] [CrossRef]
- Al-Fares, M.; Radhakrishnan, S.; Raghavan, B.; Huang, N.; Vahdat, A. Hedera: Dynamic flow scheduling for data center networks. In Proceedings of the 7th USENIX Symposium on Networked Systems Design and Implementation (NSDI′10), San Jose, CA, USA, 28–30 April 2010. [Google Scholar]
- Chowdhury, M.; Zhong, Y.; Stoica, I. Efficient coflow scheduling with varys. In Proceedings of the SIGCOMM’14: ACM SIGCOMM 2014 Conference, Chicago, IL, USA, 17–12 August 2014; pp. 443–454. [Google Scholar]
- Ramos, R.M.; Martinello, M.; Rothenberg, C.E. Slickflow: Resilient source routing in data center networks unlocked by openflow. In Proceedings of the 38th Annual IEEE Conference on Local Computer Networks, Sydney, Australia, 21–24 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 606–613. [Google Scholar]
- Bhattacharyya, R.; Bura, A.; Rengarajan, D.; Rumuly, M.; Xia, B.; Shakkottai, S.; Kalathil, D.; Mok, R.K.P.; Dhamdhere, A. QFlow: A Learning Approach to High QoE Video Streaming at the Wireless Edge. IEEE/ACM Trans. Netw. 2022, 30, 32–46. [Google Scholar] [CrossRef]
- Ma, T.; Rong, H.; Hao, Y.; Cao, J.; Tian, Y.; Al-Rodhaan, M. A Novel Sentiment Polarity Detection Framework for Chinese. IEEE Trans. Affect. Comput. 2022, 13, 60–74. [Google Scholar] [CrossRef]
- Raniwala, A.; Chiueh, T.C. Architecture and algorithms for an IEEE 802.11-based multi-channel wireless mesh network. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; Volume 3, pp. 2223–2234. [Google Scholar] [CrossRef]
- Jain, N.; Bhatele, A.; Howell, L.H.; Böhme, D.; Karlin, I.; León, E.A.; Mubarak, M.; Wolfe, N.; Gamblin, T.; Leininger, M.L. Predicting the performance impact of different fat-tree configurations. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 12–17 November 2017; Association for Computing Machinery: New York, NY, USA Article 50. ; pp. 1–13. [Google Scholar] [CrossRef] [Green Version]
- Ma, T.; Wang, H.; Zhang, L.; Tian, Y.; Al-Nabhan, N. Graph classification based on structural features of significant nodes and spatial convolutional neural networks. Neurocomputing 2021, 423, 639–650. [Google Scholar] [CrossRef]
- Estrada, R.; Tomasi, C.; Schmidler, S.C.; Farsiu, S. Tree Topology Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1688–1701. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Wang, X.; Tornatore, M.; Kim, K.J.; Kim, S.M.; Kim, D.U.; Han, K.E.; Mukherjee, B. Scheduling with machine-learning-based flow detection for packet-switched optical data center networks. J. Opt. Commun. Netw. 2018, 10, 365–375. [Google Scholar] [CrossRef]
- Hu, B.; Yeung, K.L. Feedback-Based Scheduling for Load-Balanced Two-Stage Switches. IEEE/ACM Trans. Netw. 2010, 18, 1077–1090. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Links | Remaining Available Bandwidth | |||
|---|---|---|---|---|
| t = 1 | t = 2 | t = 3 | … | |
| S1→S5 | 300 | 280 | 132 | … |
| S1→S6 | 300 | 300 | 240 | … |
| S1→S7 | 300 | 120 | 54 | … |
| S1→S8 | 300 | 84 | 84 | … |
| S2→S5 | 300 | 210 | 260 | … |
| S2→S6 | 300 | 140 | 20 | … |
| … | … | … | … | … |
| Links | The Flow Allocation with Max Bandwidth | |||
|---|---|---|---|---|
| t = 1 | t = 2 | t = 3 | … | |
| S1→S5 | f1 | f2 | f2 | … |
| S1→S6 | f2 | f1 | f1 | … |
| S1→S7 | f4 | f4 | f6 | … |
| S1→S8 | f5 | f8 | f8 | … |
| S2→S5 | f9 | f9 | f9 | … |
| S2→S6 | f7 | f10 | f10 | … |
| … | … | … | … | … |
| Links | Remaining Available Bandwidth and Unallocated Flow Numbers | |||
|---|---|---|---|---|
| ∅ | f1 | f7 | … | |
| S1→S5 | 6300 | 5180 | 5180 | … |
| S1→S6 | 7300 | 7300 | 7300 | … |
| S1→S7 | 3300 | 3300 | 3300 | … |
| S1→S8 | 2300 | 2300 | 1210 | … |
| S2→S5 | 5300 | 5300 | 5300 | … |
| S2→S6 | 4300 | 4300 | 4300 | … |
| … | … | … | … | … |
| Parameter | Value |
|---|---|
| Time slot | 1 (s) |
| Link bandwidth | 15 (MBps) |
| Duration of flow generation | 500 (s) |
| The number of new generating flows per time slot | 10 |
| The number of pings per time slot | 1 |
| Size | MFLBS | One-Hop DLBS | FCFS |
|---|---|---|---|
| 5 | 47,050,514 | 47,238,341 | 47,238,341 |
| 6 | 56,448,090 | 56,560,537 | 56,560,537 |
| 7 | 65,944,101 | 65,683,967 | 65,683,967 |
| 8 | 74,353,672 | 69,931,149 | 69,931,149 |
| 9 | 83,871,673 | 69,231,756 | 69,231,756 |
| 10 | 92,123,527 | 68,790,931 | 68,991,780 |
| Size | MFLBS | One-Hop DLBS | FCFS |
|---|---|---|---|
| 5 | 46,343,422 | 36,381,752 | 36,381,752 |
| 6 | 55,448,964 | 36,797,292 | 36,797,292 |
| 7 | 55,700,158 | 36,177,649 | 36,177,649 |
| 8 | 47,494,114 | 35,966,003 | 35,966,003 |
| 9 | 48,504,502 | 36,400,611 | 36,400,611 |
| 10 | 43,418,924 | 35,534,674 | 35,534,674 |
| Size | MFLBS | One-Hop DLBS | FCFS |
|---|---|---|---|
| 15 | 139,907,132 | 140,184,725 | 140,184,725 |
| 16 | 149,922,066 | 149,046,504 | 149,046,504 |
| 17 | 156,089,605 | 153,972,110 | 153,972,110 |
| 18 | 168,041,654 | 152,381,859 | 152,109,261 |
| 19 | 174,644,435 | 157,415,945 | 157,415,945 |
| 20 | 183,855,203 | 154,583,258 | 154,583,258 |
| Size | MFLBS | One-Hop DLBS | FCFS |
|---|---|---|---|
| 15 | 138,298,465 | 122,962,006 | 122,962,006 |
| 16 | 143,945,056 | 117,622,948 | 117,258,790 |
| 17 | 143,836,667 | 124,642,008 | 124,448,464 |
| 18 | 128,924,876 | 115,946,286 | 115,946,286 |
| 19 | 135,906,736 | 124,005,139 | 124,005,139 |
| 20 | 139,260,103 | 125,773,262 | 125,773,262 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, B.; Chang, Y.; Zhang, X.; Al-Dhelaan, A.; Al-Dhelaan, M. Mixed-Flow Load-Balanced Scheduling for Software-Defined Networks in Intelligent Video Surveillance Cloud Data Center. Appl. Sci. 2022, 12, 6475. https://0-doi-org.brum.beds.ac.uk/10.3390/app12136475
Song B, Chang Y, Zhang X, Al-Dhelaan A, Al-Dhelaan M. Mixed-Flow Load-Balanced Scheduling for Software-Defined Networks in Intelligent Video Surveillance Cloud Data Center. Applied Sciences. 2022; 12(13):6475. https://0-doi-org.brum.beds.ac.uk/10.3390/app12136475
Chicago/Turabian StyleSong, Biao, Yue Chang, Xinchang Zhang, Abdullah Al-Dhelaan, and Mohammed Al-Dhelaan. 2022. "Mixed-Flow Load-Balanced Scheduling for Software-Defined Networks in Intelligent Video Surveillance Cloud Data Center" Applied Sciences 12, no. 13: 6475. https://0-doi-org.brum.beds.ac.uk/10.3390/app12136475