1. Introduction
With the rapid progress of information technology, many Internet services and applications have been developing widely, resulting in an explosive increase in network traffic. However, the existing optical wavelength-division multiplexing (WDM) networks with fixed spectrum grid and modulation format that lead to low spectrum utilization in optical fiber links are failing to meet the growing and diversified traffic demands of the future. Therefore, it is urgent to develop a new high-capacity network with variable grids and scalable architecture. Elastic optical networks (EONs) based on orthogonal frequency division multiplexing (OFDM) technology, first proposed in 2008, use the narrow frequency slot (FS) as a unit of resource allocation, which makes it feasible for EONs to dynamically allocate spectrum resources and configure modulation formats according to user demands and traffic volume [
1].
However, with the ever-growing expansion of the current optical communication network coverage and the rapid growth of service requirements, the physical capacity of single-mode fiber (SMF) will approach its channel Shannon limit soon. Therefore, it is necessary to develop new optical fiber technologies, among which, space division multiplexing (SDM) technology that uses the space dimension to significantly increase transmission system capacity, is a promising solution [
2]. As one of the most easily implemented technologies in SDM with an obvious network expansion effect, multi-core fiber (MCF) aggregates multiple single-mode cores into fiber cladding to realize exponential growth in capacity over single-core fiber. MCF has found some applications in the centers [
3] and submarine scenarios [
4]. Therefore, EONs with multi-core fiber (MCF-EONs) have attracted extensive attention from researchers since their appearance, and their resource allocation has been a hotspot in recent years and remains more challenging than that of EONs.
Due to the increasing core dimension, the corresponding routing, spectrum and core assignment (RSCA) problem is more complicated and challenging, and we need to reconsider more constraints compared with EONs. Therefore, new algorithms should be used to solve this problem instead of directly employing the existing algorithms for tackling a routing and spectrum assignment (RSA) problem in EONs. In addition, crosstalk will occur when the RSA algorithm distributes connection requests on the same FSs between adjacent cores. Accordingly, inter-core crosstalk needs to be considered in solving this problem. To expand the routing space and further utilize the limited EON resources, cores on different links can be freely switched, i.e., core switching can be realized at each node of a network. Thus, it is significantly important to study the resource allocation problem and its solving algorithm when considering core switching and inter-core crosstalk for obtaining better MCF-EONs performance.
Through the above analysis, we find that some recent studies have some defects. However, Ref. [
2] did not consider inter-core crosstalk. Refs. [
5,
6,
7] considered inter-core crosstalk but did not consider core switching. Ref. [
8] studied the RSCA problem by considering both inter-core crosstalk and core switching and proposed a heuristic algorithm, however, they did not use an intelligent algorithm. For the static RSCA problem [
9,
10,
11,
12], used an intelligent algorithm, but there is no study that simultaneously considers core switching, constructs a true multiobjective optimization model, and designs corresponding multiobjective algorithms to tackle such a model. Therefore, we focus on considering the static RSCA problem that considers inter-core crosstalk and core switching in MCF-EONs, and use an intelligent algorithm to solve the problem.
To sum up, the single-objective algorithm either aims to reduce the blocking ratio or to reduce the crosstalk ratio. To reduce crosstalk, high-order modulation can be used to increase the transmission rate of services, but it will limit the allocation and use of frequency slot resources, thereby increasing the blocking ratio. In order to reduce the blocking ratio, it may increase the crosstalk ratio between cores, and high-order modulation cannot be used, thereby affecting the transmission rate of the service. Therefore, our algorithm comprehensively considers the blocking ratio and crosstalk ratio. We use a multi-objective method to balance the relationship between the two to obtain better solutions. Ref. [
12] established a multiobjective model and designed a corresponding multiobjective optimization algorithm to solve it. However, it does not consider core switching.
In this paper, we focus on solving the static RSCA problem that considers inter-core crosstalk and core switching in MCF-EONs. Our work makes three key contributions: (a) we consider simultaneously core switching and multiple optimization objectives, i.e., the static RSCA based on core switching (RSCA-CS) problem is formulated as a true multiobjective ILP model, which minimizes both the network requests blocking ratio and crosstalk ratio; (b) in contrast to previous works [
9,
10,
11,
12] that separately code the routing and core into two populations resulting in a time-consuming solution. We design a novel joint routing and core coding scheme under core switching for the first time. A single chromosome accurately expresses a solution to this complex problem in our work. The solution space encoded in this way is discrete and is beneficial to the global convergence of solutions; (c) a new adaptive hybrid multiobjective optimization algorithm with several key mechanisms designed especially is proposed to solve such a model efficiently on the basis of the novel joint routing and core coding scheme. To enable the algorithm to search uniformly in the objective space during the initial iteration and to evolve on the basis of a better solution set, we design a hybrid algorithm combining uniform design method and heuristic algorithm without core switching for simplification. Single-point crossover, hybrid mutation, and adaptive mechanisms will help the algorithm achieve a better balance between global exploitation and local exploration. The algorithm integrates multiple strategies into a multiobjective evolutionary algorithm based on the decomposition (MOEA/D) framework, which solves the problem from the perspective of multiple objectives and can provide network operators with multiple resource allocation schemes whose objective values are diversionary and not dominant, allowing the resource allocation to better meet the diversified goals of both operators and users.
The rest of this paper is organized as follows.
Section 2 is related work.
Section 3 introduces some prerequisite knowledge, including spectrum allocation in optical WDM networks versus EONs, MCF, MCF-EON architecture, core switching, and inter-core crosstalk.
Section 4 describes the RSCA-CS problem and formulates it as an ILP mathematical model.
Section 5 introduces the proposed key elements and mechanisms of our novel algorithm in detail. Simulation experiments and result analysis are addressed in
Section 6. A conclusion is finally drawn.
2. Related Work
Currently, many scholars or teams have been studying the RSCA problem. Among them are: (1) Fujii S, Hirota Y, and Tode H in Osaka, Japan; (2) Muhammad A in Sweden; (3) Zervas G in Britain; and (4) some scholars in China, such as Zhao Yongli, Zhu Zuqing, Liu Huanlin and Xu Zhanqi. They have proposed various algorithms for solving the static or dynamic RSCA problems and extended ones by adding modulation formats or core modes when considering crosstalk or core switching.
For dynamic network scenarios, existing works [
13,
14,
15] have studied the spectrum fragmentation problem in dynamic resource allocation. Specifically, Ref. [
13] proposed a crosstalk-aware spectrum defragmentation algorithm based on the spectrum compactness metric. To reduce crosstalk and spectrum fragmentation, Ref. [
14] investigated an RSCA algorithm based on spectrum partition, predefined core priority, and classification. To make full use of spectrum resources and minimize spectrum fragments, Ref. [
15] proposed a multi-core virtual connection scheme considering inter-core crosstalk to construct super-channels in the dimensions of core and spectrum. Aiming at using the frequency slot allocation patterns (FSAPs) with the least amount of wasted FSs and exploiting path diversity [
16], a set of new algorithms is proposed.
For the static RSCA problem, many works have investigated heuristic or intelligent algorithms. Ref. [
2] proposed several versions of a greedy algorithm based on different demand order strategies for solving the routing, space (i.e., optical fiber, core or mode), and spectrum allocation problems, in which inter-core crosstalk is not considered. Ref. [
5] studied the RSCA problem with the impairments and security vulnerabilities caused by inter-core crosstalk, specifically, in which the trust of some nodes in the network is lower than that of other nodes. The authors formulated an integer linear programming (ILP) model that optimizes spectrum utilization and crosstalk simultaneously and designed a corresponding heuristic algorithm. To study the anycast RSCA problem, Ref. [
6] established an ILP model that considers inter-core crosstalk to minimize the Maximum FS Index (MFSI, as defined in [
7]) of an EON, and then proposed a heuristic algorithm that mainly uses the shortest path first algorithm and the predefined core priority crosstalk reduction technique to solve the established model, in which core switching is not considered. Ref. [
17] proposed a programmable architecture on demand (AoD) node, which can provide a more flexible and scalable architecture for multi-dimensional switching including core switching, and studied the RSCA problem considering the modulation format under quasi-static traffic scenarios in SDM-EONs. To overcome the drawbacks in Ref. [
2] and Ref. [
6], M. Yang, et al. [
8] studied the RSCA problem by considering both inter-core crosstalk and core switching. The authors first analyzed three crosstalk constraint methods: XT-avoid, XT-WC and XT-aware, where XT denotes crosstalk and only XT-aware strictly considers the crosstalk FSs between adjacent cores. They established a hybrid ILP model to minimize the MFSI and proposed a heuristic algorithm with crosstalk awareness. Particularly, it calculates K-shortest paths (KSPs) for each connection request in advance, and then allocates routing, cores, and spectrum resources that meet the constraints of the spectrum and inter-core crosstalk for all requests.
Different from all the mentioned references that use heuristic algorithms for solving the RSCA problem, Refs. [
9,
10,
11,
12] proposed a corresponding intelligent algorithm that is based on some optimization and guidance mechanisms, and the obtained solutions are better than those resulting from heuristic algorithms. Concisely, these articles first established the mathematical model of the RSCA problem, then designed a reasonable chromosome coding scheme, and finally used a genetic algorithm to evolve the population to obtain the optimal solution. In these studies, only Ref. [
11] considered core switching on different links, and only Ref. [
12] established a multiobjective model and designed a corresponding multiobjective optimization algorithm to solve it. For the static RSCA problem, there is no study that simultaneously considers core switching, constructs a true multiobjective optimization model in which multiobjectives are not transformed into a single objective, and designs corresponding multiobjective algorithms to tackle such a model.
Table 1 is the summary of reference.
3. Preliminaries
Due to the increase of core dimension in MCF-EONs, the inter-core crosstalk needs to be considered when solving the RSCA problem, regardless of whether the core can be switched at each node. This section provides a basic knowledge of MCF-EONs, laying a foundation for solving the RSCA-CS problem. First, spectrum allocation in optical WDM networks and EONs is introduced. The MCF concept and MCF-EON node architecture are then given. Finally, we describe the concept, node architecture, and three spectrum constraints that are mentioned above and which need to be satisfied for core switching, as well as the calculation of inter-core crosstalk.
3.1. Spectrum Allocation in Optical WDM Networks and EONs
The spectrum allocations in optical Dense WDM (DWDM) networks and EONs with effective utilization are shown in
Figure 1a,b with a wavelength grid of 50 GHz and an FS of 12.5 GHz, respectively. We assume that each wavelength with binary phase shift key (BPSK) coding can transport 40 Gbps like STM-256, and here STM denotes synchronous transfer module in the synchronous digital hierarchy (SDH) used widely.
Figure 1a shows the effective spectrum usage of the DWDM network if traffic
1 is 10 Gbps and traffic
2 requests 100 Gbps which can be carried with three wavelengths in two-40 Gbps and one 20 Gbps. Note that the first 10 Gbps and the second 20 Gbps could not be transported within the same single wavelength since their destinations are not the same and only one optical switch is allowed without grooming in the electronic field.
In contrast, EONs use exactly one FS to transmit traffic 1. It employs OFDM technology to gather only eight continuous FSs into a super-wavelength for transferring traffic 2 with 100 Gbps, covering only 56.25 GHz. Here, GS denotes the guard FS that separates two different carriers for demodulation. Compared with WDM networks, EONs provide variable granularity units from one FS to serval FSs that are referred to as a superchannel and transmit requests by overlapping multiple FSs through OFDM technology, saving the network spectrum by as much as 59.4% ((4 × 50–6.5 × 12.5)/4 × 50).
3.2. MCF
SDM technology can significantly improve the current EON capacity by utilizing the space dimension. It mainly includes [
18] MCF, few-mode fiber, few-mode multi-core fiber, and SMF. MCF is the most intuitive and effective way to increase the capacity of a single fiber. Compared with the optical fiber cable that places multiple SMFs in the same cladding, MCF can effectively increase the spatial density of optical fiber [
19]. In terms of the parameter design and product manufacturing of an optical fiber, MCF is relatively mature compared with other technologies. Currently, there are commercial seven-core fiber products, whose characteristics are very close to those made by SMF. Therefore, we focus on the resource allocation in MCF-EONs.
As shown in
Figure 2, the RSCA-CS problem is studied with three-core, five-core, and seven-core optical fibers in our work.
3.3. MCF-EON Architecture
Figure 3 shows the node architecture [
17] in MCF-EONs, where the transmission medium (i.e., MCF) achieves multiple SMF capacities by increasing the spatial dimension of a core. Therefore, this architecture can easily multiply the network capacity of the original EON architecture and carry more connection requests.
Different cores on the same optical fiber link in
Figure 3 are demultiplexed and multiplexed first, and then the spectrum exchange module and transceiver pool in the figure middle are used to allocate an appropriate amount of spectrum resources to each connection request. The transceiver pool provides an appropriate number of sub-transceivers according to the sub-carrier bandwidth allocated for each request. These functions can be implemented by the sub-modules in the EON architecture, such as a bandwidth-variable transponder and a bandwidth-variable spectrum selection switch.
To allocate spectrum resources more flexibly, this architecture supports fiber switching, core switching, and spectrum switching, which means that each connection request can occupy different fibers, cores, and spectrum blocks on different links along its transmission path, respectively. However, the spectrum constraints, including continuity and consistency in this path, must be met by switching. These switching modules can make full use of network resources from a global perspective, thus reducing the network requests blocking ratio (RBR). As the focus of this paper, the basic idea and node architecture of core switching are introduced in the next subsection.
3.4. Core Switching
3.4.1. Basic Idea
When allocating spectrum resources to a connection request, the spectrum constraints of continuity and consistency need to be satisfied, which will generate many discontinuous spectrum fragments. Such a small fragment cannot be used to carry the request with a higher bit rate, thus increasing the network RBR. Core switching can partially utilize the spectrum fragments on different links, allowing connection requests that could not be transported without core switching to be served. In this paper, it is assumed that core switching can be realized at each node, which is illustrated in
Figure 4. Request
1 occupies core
1 on link
1, and core
2 on link
2 after passing through the core switching at the node, which is more likely to utilize the spectrum resources on other cores that cannot be selected in the scenario of unswitched cores. Accordingly, the optical path from the source node to the destination node has a larger routing space, thus obtaining a higher utilization of resources.
3.4.2. Node Architecture
Figure 5 shows the node architecture of core switching [
17] known as architecture on demand (AoD). It realizes not only fiber switching but also core switching in the optical fiber. AoD includes an optical backplane, which can interconnect the input, output, add, drop, single device building module (e.g., the multiplexer and spectrum selection switch (SSS)), and composed building module (such as the optical amplifier and power divider or coupler) in any way by setting an appropriate cross-connection on it, so as to realize the software-programmable switching of optical fibers. This AoD is different from the reconfigurable optical add/drop multiplexers architecture based on an optical SSS module (for switching and filtering), which cannot achieve any combination of such components because of its hardwired inputs, modules and outputs. In addition, AoD also supports direct switching of optical signals from the input port to the output port, without using any demultiplexing and multiplexing modules. Therefore, AoD has higher flexibility in that it realizes the expansion of the new features and allows more light signals to be routed to different cores, thus making full use of the existing spectrum resources. More details can be found in [
17].
3.4.3. Spectrum Constraints
In MCF-EONs with core switching, although a connection request can occupy variable cores on different links of its selected path, the spectrum constraints of continuity, consistency, and overlapping still need to be satisfied. Spectrum continuity refers to each request occupying continuous spectrum resources on the selected core. All three requests in
Figure 4 occupy the continuous FSs. Spectrum consistency means that each request occupies the same FSs (location) on different links, and cores can be switched on these selected links. Taking request
2 of three FSs as an example, it is transmitted by FSs
4,
5, and
6 of core
3 on link
1. When it is transmitted on link
2, it can occupy different cores. To meet the constraints of spectrum consistency, the FSs
4,
5, and
6 on core
1 are allocated. Spectrum overlapping means that each FS on the specific core can only be occupied by one request at a time. Generally, there should be a protection FS between two adjacent spectrum segments allocated to requests on the same core, so as to ensure that the transmitted optical signal passes through the cross nodes in EONs without being damaged and is correctly received by the receiver. For example, an FS between request
2 and request
3 on link
1 is reserved as the protection bandwidth.
3.5. Inter-Core Crosstalk
Since MCF tightly encapsulates the spatial channel into each core, the effect of inter-core crosstalk on degrading the transmission signal should be considered in the relevant research. There are two ways to reduce this crosstalk. One is to keep the cores at an appropriate distance, which can be achieved by properly designing MCF. The other designs an effective spectrum allocation method to be studied in this paper. When allocating FSs to the current connection request, the crosstalk resulting from the possible FSs of other requests needs to be considered. If the crosstalk value of the allocated FSs on the selected transmission path is greater than the given crosstalk threshold, the crosstalk will seriously affect the recovery of the receiver signal and cause the current request to be blocked. Equation (2) is used to calculate the mean inter-core crosstalk (XT) [
1], which serves as the basis for calculating the crosstalk value for each request and is used widely in existing studies.
where
h in Equation (1) represents the mean increase in inter-core crosstalk per fiber length unit, and the parameters
are all related to MCF, denoting the coupling coefficient, bend radius, propagation constant, and core-pitch, respectively. We assume that these parameters cannot be changed. In Equation (2),
XT,
n, and
L denote the crosstalk, the number of adjacent cores, and the length of each fiber, respectively. For the seven-core fiber shown in
Figure 2c,
n equals 6 for the center core
7 but equals 3 for the other cores. Therefore, core
7 is most seriously affected by crosstalk from adjacent cores.
From the above equations, we can see that inter-core crosstalk is affected by the number of adjacent cores and the fiber length is disregarded in the algorithm design. Therefore, the main influencing factor is the first one, especially since crosstalk occurs only when the same FS is occupied on adjacent cores.
Figure 6 illustrates the inter-core crosstalk calculation using the seven-core fiber in
Figure 2c as an example.
For the FS f, represents the number of crosstalk FSs at link l on the selected path p for the connection request , and denotes the number of crosstalk FSs for .
Cores 1 and 2, and cores 2 and 3 are adjacent. Therefore, there are crosstalk FSs between them. Cores 1 and 3 are not adjacent, so there is no crosstalk between them. The numbers 1 through 9 in the upper part of each core are the FS index. For request 4, the selected path length is 3, i.e., it occupies links 1, 2, and 3. For FS 5 on core 2 of link 1, request 3 and request 5 occupy the same FS on cores 1 and 3 that are adjacent to core 2, so request 4 has crosstalk at FS 5 and . Analogously, for FS 5 on link 2, there is a crosstalk FS for request 4, which results from request 5, i.e., . There is no request occupying FS 5 on core 1 and core 3 of link 3, then . Therefore, the crosstalk value of request 4 at FS 5 equals . Similarly, the crosstalk value of request 4 at FS 6 is . The total crosstalk value of request 4 equals .
When the crosstalk value of each request is greater than the crosstalk threshold, the network cannot provide transport service to the request. Therefore, the setting of the crosstalk threshold is critical and depends on the modulation format, core distribution, and the number of FSs that are on adjacent cores and whether their FSs indexes are the same as those to be allocated to the current request. Different modulation formats can tolerate different amounts of crosstalk, and the tolerance decreases with the increase of the modulation order [
8]. To simplify the calculation, BPSK with the highest tolerance is adopted in this paper. Finally, the crosstalk threshold is set to an appropriate value in its value range (related to the distribution of cores) through several experiments.
4. Problem Formulation
Compared with solving the RSA problem in EONs with single-core fiber, solving the RSCA problem in MCF-EONs is more complex and challenging, since more constraints or influencing factors need to be considered, such as core switching, inter-core crosstalk, crosstalk threshold, the number of cores in each fiber, joint allocation of cores with routing and spectrum, etc. A common approach for solving the RSCA problem is to formulate an ILP model. Then we use three category methods of mathematical programming software (such as CPLEX), heuristic algorithms or intelligent algorithms to solve it. Crosstalk awareness is a process by which crosstalk between different requests affecting each other can be evaluated. There may be crosstalk between the FSs allocation to the current request and the previously allocated FSs for other requests, resulting in the generation of a certain degree of crosstalk. To study the impact of inter-core crosstalk on the overall network performance or service transmission in a limited network resource scenario, this section establishes a true bi-objective resource optimization model that minimizes both the network RBR and the crosstalk ratio for the RSCA-CS problem.
4.1. Network and Connection Requests Description
We use a connected graph to describe the MCF-EONs topology, where is the set of bandwidth-variable optical cross nodes with being the total number of nodes in the network topology, and represents the optical fiber links set with being the bidirectional fiber link between node and node . Let us denote the cores set on each optical fiber link by and the set of FSs on each optical fiber link by , where and are the number of cores in MCF and the total number of FSs on each core, respectively.
This paper studies static traffic, i.e., their arriving time, duration, and request bandwidth in the network are all known. It is assumed that the core occupied by each request can vary on different links along the selected path. Let denote the set of connection requests, where is the total number of requests. We use to represent the k-th request, where , , and are its source node, destination node, and the number of required FSs, respectively.
4.2. Mathematical Model
To describe the RSCA-CS problem clearly, we give the variables first and then formulate an ILP model including the optimization objectives and constraints in this subsection.
4.2.1. Variables
: the capacity of each core.
: the capacity of each FS.
: the set of K candidate paths in ascending order of path length for each request .
: the selected path of request , and .
: the core index selected by request if it passes through a link on the selected path .
: the start FS index on core occupied by the request as it passes through a link of the selected path .
: the Boolean variable equals 1 if the path bears the request , and 0 otherwise.
: the Boolean variable equals 1 if request occupies the core on a link , and 0 otherwise.
: the Boolean variable equals 1 if request occupies the FS on the core after passing through a link from the source node to the destination node , and 0 otherwise.
: the Boolean variable equals 1 if the FS on a core of link is occupied, and 0 otherwise.
: the Boolean variable equals 1 if request is to be allocated the FS on a core of link , while on adjacent to core is occupied at the same time, and 0 otherwise.
GF: the number of FSs needed for guardband.
: the crosstalk value of a single request in a network.
: the total number of blocked connection requests in a network.
: the total number of crosstalk FSs generated in a network.
: the total number of occupied FSs in a network.
: the crosstalk threshold for a given modulation format.
4.2.2. Objective Function
Our objectives are to minimize both RBR and crosstalk ratio simultaneously.
where
The former, shown in Equation (4), denotes the ratio of the total number of blocked requests to the number of all created requests. The latter, in Equation (5), equals the ratio of the total number of crosstalk FSs to the total number of occupied FSs, which are expressed by Equation (5a) and Equation (5b), respectively.
4.2.3. Constraints
- (1)
Core Capacity Constraint
- (2)
Routing and Core Selection Constraints
Equation (6) indicates that the available bandwidth of each link cannot exceed the capacity of each core. Equation (7) states that the selected core index for each request does not exceed the total number of cores. Equation (8) ensures that any connection request could only select at most one core on the selected link . Equation (9) ensures that the source and destination nodes of the generated request cannot be the same. Equation (10) means that each request can only select one path from its candidate path set for use.
- (3)
Spectrum Allocation Constraints
where
n in Equation (11) denotes the number of links in path
p. Equations (11)–(13) ensure the spectrum consistency, continuity, and non-conflict under core switching, which has been explained in
Section 3.3. Equation (14) indicates that the FSs occupied by each request
must be within the entire available spectrum domain.
- (4)
Inter-core Crosstalk Constraint
Equation (15) guarantees that the crosstalk value of each connection request on its selected optical path is less than the preset crosstalk threshold .
5. Proposed MOEA/D-AMSF Algorithm
In this section, we propose an MOEA/D with adaptation and multi-strategy fusion (MOEA/D-AMSF) for solving the optimization model effectively, in which a joint routing and core coding scheme with core switching is designed for the first time. The proposed scheme uses the variable core index along a path and encodes the routing and core index into a chromosome to co-evolve, resulting in a higher possibility of obtaining the globally optimized solution and increasing the algorithm convergence when compared with the bi-population coding scheme. As we stated in
Section 1 and
Section 2, research on a multi-objective optimization model and an algorithm with core switching has not been considered in existing works.
The key elements and advantages of the proposed MOEA/D-AMSF are as follows:
- (1)
The proposed algorithm adopts multiple-strategy fusion and adaptive mechanisms to accelerate the algorithm convergence and enhance solution diversity. It has the following characteristics:
- (a)
A hybrid algorithm combining a heuristic algorithm and uniform design method is used to generate the initial population, making the generated initial solution set distributed more uniformly;
- (b)
For the proposed coding scheme, the adaptive crossover and bi-layer mutation with repair operators are designed to solve each subproblem, and the crossover and mutation probabilities are adaptively adjusted according to the iteration status in different evolution stages;
- (c)
Simple single-point crossover and single-point mutation strategies are used in the early search stage of the algorithm, while multi-point mutation is employed after it evolves to a certain extent, which increases the probability that the search jumps out of the local optimum, finding more global solutions;
- (2)
The Tchebycheff (TCH) decomposition method is used to decompose the proposed bi-objective optimization problem into multiple single-objective optimization subproblems, which makes it easy to apply the single-objective optimization method to each subproblem and to solve all the subproblems in parallel, accelerating the algorithm convergence.
The chromosome coding and decoding strategy, initial population generation method, adaptive evolution operators, and the proposed algorithm flow are described in detail below.
5.1. Joint Routing and Core Coding Scheme
Many existing studies, such as [
10,
12,
18], encode routing and core into two independent populations, which are used in a co-evolutionary algorithm, resulting in a time-consuming solution. We assume that there are core switching devices at all nodes of a network, i.e., each connection request is allowed to select different cores on all links of the candidate path. Therefore, the core number index to be selected for each request depends on the path it has chosen, making it impossible for the core and routing to be encoded separately. Accordingly, the routing and core are jointly encoded. Each gene on the chromosome is composed of two layers: one layer represents the routing scheme, and the other layer denotes the core selection scheme. Thus, a single chromosome accurately expresses a solution to this complex problem. The solution space encoded in this way is discrete and is beneficial to the global convergence of solutions.
The path lengths selected for different requests may be different, and each individual in the routing population may have a different path for the same source–destination request. Therefore, the length of the core gene components (CGCs) is variable. To reduce the design difficulty of evolution operators, we adopt a fixed-length integer coding scheme based on the path length by taking advantage of the characteristics of routing and core in MCF-EONs.
For the details of the coding scheme,
Figure 7 shows the relevant gene, chromosome and population, respectively. Note that
represents the routing and core scheme of the connection request
from node
1 to node
6, and those of other requests are similar. As shown in
Figure 7b, all genes form a chromosome to denote a feasible routing and core solution to the RSCA problem. Each of the
lines represents an allocation scheme for one request. Each column in
Figure 7c represents one chromosome, and all chromosomes constitute a population with a total of
N (population size) columns. Here, we take
as an example to explain the composition and meaning of each gene.
As can be seen from
Figure 7a, the gene code for each request consists of two layers or fields used for the routing scheme and core scheme, respectively. We see that a gene of routing has only one component while a core gene consists of two subfields with several components, valid core gene components (VCGCs) and unused core gene components (UCGCs). Since the KSPs between any two nodes are calculated in advance, the value range of each routing gene component is
1 through
K. For the current request, such a value denotes the selected path index in the set in which all of its KSPs are prearranged in ascending order. For example, index
2 indicates that the request
selects the second shortest path: 1→3→5→6. Each gene component in the second layer represents the core selection scheme on the path just selected. The number of CGCs is the maximum hops of all candidate paths for all connection requests in a network. The link
in the figure denotes the
j-th link of the candidate path, instead of the actual link index of the physical network. Based on the selected path, the number of VCGCs is determined. For example, if the number of links in the selected second shortest path for
is three, then the VCGCs length equals three. As shown in the figure, the first three numbers in CGCs are valid, ranging from 1 to |
C|. The value of each CGC indicates the core index selected by the current connection request, where the core index is numbered in advance. However, we set the value of each UCGC to 0 if the connection request does not pass through the relevant link. Such coding design can greatly reduce the complexity of fitness function calculation, and avoid the difficulty caused by the variable length of core coding for designing crossover and mutation operators. The initial values of routing and core genes are generated by certain strategies, which are detailed in the initial population generation method in the next subsection.
Compared with the coding scheme without core switching, the current coding scheme is relatively complex, since the number of the CGCs varies from 1 to Lmax, where Lmax denotes the maximum number of the CGCs and depends on routing results. Accordingly, the algorithm search space related to core changes from |C| to , where is the selected path length for each connection request , resulting in a significant increase in the solution time. If the FS is encoded, the complexity of solving problems will increase greatly. Therefore, we consider the spectrum allocation at the decoding stage and adopt the first fit (FF) method which allocates the first spectrum block conforming to the constraints to the connection request. During decoding, the valid genes in a chromosome are read in turn, i.e., the path and core are selected for a connection request according to the relevant gene values, and spectrum occupation information on the core of the selected path is checked. If there are spectrum blocks meeting the constraints of the spectrum and inter-core crosstalk, the corresponding FSs are allocated to the request according to the FF method; otherwise, the request is blocked. After all connection requests have been served in turn, the fitness value of each chromosome under the current evolution generation is calculated.
5.2. Decomposition Method
The TCH decomposition method is used to convert the specific MOP into multiple single objective subproblems, thus solving all subproblems with optimization methods in parallel. The following is the subproblem aggregation function represented by any weight vector
(
) after decomposition [
20].
where
with
represents the reference point vector, and
m is the number of objective functions.
5.3. Hybrid Generation Method for Initial Population
It is important to generate a reasonable initial population. Therefore, we designed a hybrid algorithm combining the uniform design method and heuristic algorithm without core switching for simplification. To enable the algorithm to search uniformly in the objective space during the initial iteration and to evolve on the basis of a better solution set, we first used the uniform design method to generate the initial population. Since the cores on different links can be switched, the search space of the algorithm becomes very large. If the core gene values are generated randomly, there is not an appropriate basis and a guiding criterion for evolution, preventing the evolution startup. Therefore, the core should not change too much in the early search stage. After the initial population is generated, some solutions obtained by the heuristic algorithm without core switching are used to replace some individuals in the initial population. The following is a detailed description of the initial population hybrid generation (IPHG) algorithm.
5.3.1. Uniform Design Method
Each gene is composed of two layers of routing and core. Since routing is independent of each other in the selection between different connection requests, we used the uniform design method [
21] to generate the initial value of routing genes. This method can make the test points evenly distributed in the test domain, which is conducive to the uniform distribution of connection requests bearing on the network links. The value of each VCGC is randomly generated so that the VCG component values for the same gene on two different chromosomes are different even if the routing gene values are the same, which is beneficial to improving population diversity. Algorithm 1 presents the specific initialization process. For each gene, the VCGCs length (hops, line 3 of the algorithm) is obtained after the initialization of the routing gene, and then the value of each VCG component is randomly generated. The traffic_routing_matrix in the table is used to store the routing results, which has a total of three columns, corresponding to each of all connection requests, the nodes that pass through the selected KSP, and the hops of such a KSP.
| Algorithm 1 population initialization with uniform design |
![Applsci 12 07128 i001]() |
5.3.2. Heuristic Algorithm without Core Switching
This heuristic algorithm allocates the routing, core, and spectrum blocks for each connection request in turn, and rejects each request if there are no appropriate resources in the network. Specifically, it first selects the shortest path from the candidate paths set that is created by using the shortest path first algorithm and then uses the polling selection method that sorts cores in advance and rotates among all core indexes in a network for each connection request [
22]. If there are no suitable spectrum resources on any of all the available core indexes, it goes back to the routing module and selects the second shortest path to perform the above operations up to the
K-th candidate path. If there are still no feasible resources on all
K candidate paths, the request is blocked.
This proposed algorithm can obtain different RSCA schemes under varied crosstalk thresholds. The maximum value of the crosstalk threshold () is the ratio of the total number of 1′s in the core adjacency matrix (twice the number of adjacent core pairs) to the number of cores. For example, for the three-core fiber, the number of 1s in the core distribution matrix is 6, so = 6/3 = 2. Similarly, for the five-core fiber, and for the seven-core fiber. Therefore, ranges are (0, 2], (0, 2] and (0, 3] for fiber with 3-core, 5-core and 7-core, respectively. In these ranges, 0.1 is chosen as the crosstalk threshold step of different heuristic algorithms, so RSCA schemes are generated at most, where denotes the maximum crosstalk threshold of each MCF.
5.3.3. IPHG Algorithm
MOEA/D uses N (population size) weight vectors to represent individuals in the population. Since there are two objectives to be optimized, N two-dimensional weight vectors () are generated to be distributed evenly, where any weight vector is with and . Specifically, each individual is initialized according to the method shown in Algorithm 1, and then the individuals represented by these weight vectors, , are replaced with solutions generated by the heuristic algorithm. Accordingly, the values of the routing gene and VCG components of these individuals are replaced, thus implementing the generation of the initial population.
5.4. Adaptive Evolutionary Operators
To produce better offspring through genetic recombination, crossover operation exchanges some gene components on each chromosome of the selected parents in a certain way. While mutation operation changes some values of gene components of an individual, so as to probably produce an individual with higher fitness value. In this subsection, we address the application of some adaptive mechanisms to crossover and mutation operators.
5.4.1. Adaptive Single-Point Crossover Operator
In this paper, single-point crossover is adopted since it is necessary to ensure that the change of core index on different links cannot be significant in the early search stage. Otherwise, evolution does not have a basic guiding direction, and some better solutions will be missed. After the solutions have evolved to a certain extent, some more complex strategies will be specially designed to make genes on the chromosome mutate with a higher probability at a time in the evolution iteration, which is helpful for enabling the algorithm to jump out of the local search and to generate global optimal solutions.
Figure 8 shows the principle of single-point crossover based on the proposed coding scheme. For each subproblem
i, the following operations are performed: the random number
in (0, 1) is first generated and then we compare it with the crossover probability
; If
is less than
, two distinct individuals
and
are selected from the neighborhood B(
i) of
i as the crossover parents. Then, a gene component site is randomly selected on
and
as the crossover point. Notice that each gene
in
Figure 7a includes two fields of routing and core, and both fields of a gene need to be regarded as a whole. As shown in
Figure 8, the genes located to the right site in
and
are interchanged to produce two offspring
and
. If
is not less than
, no crossover operation will be performed.
To accelerate algorithm convergence and improve population diversity,
, shown in Equation (17) is adaptively adjusted according to the current generation counter
i.
We see that Pc depends on the preset minimum crossover probability , maximum crossover probability , and maximum evolutionary generations . In the early search stage, Pc stays small, and the individuals change to a small extent as evolution iterates, preserving the better individuals. While in the later search stage, the solution may fall into the local optimum, i.e., it has not changed much within several generations. Therefore, a larger Pc is needed to make the algorithm jump out of the local search, so as to generate new solutions and accelerate the algorithm convergence. The adaptive setting of Pc will help the algorithm achieve a better balance between global exploitation and local exploration.
Algorithm 2 shows the specific flow of the proposed adaptive single-point crossover. For each subproblem, the crossover probability is first calculated in terms of Equation (17), and the crossover operation is then performed according to the principle described above. The symbol
(
i,
j) (
k = 1,2) denotes the
j-th gene on the chromosome for subproblem
i.
| Algorithm 2 adaptive single-point crossover operator |
![Applsci 12 07128 i002]() |
5.4.2. Adaptive Bi-Layer Mutation with Repair Operator
Compared with gene recombination of crossover operation, mutation operation can produce new genotypes through gene mutation. Therefore, the mutation operator determines the local search ability of a genetic algorithm. It not only prevents the algorithm from being premature but also maintains the population diversity, thus making the solution to the problem tend to be optimal.
In this paper, a single-point mutation is adopted in the early search stage, the reason is similar to that for the crossover operator. When the algorithm evolves to a certain extent, the search may fall into the local optimum (the generation at this point is denoted as GLO). Therefore, when the evolution generation is greater than GLO, multi-point mutation is used to increase the probability, which enables the search to jump out of the local optimum and produce more new solutions.
The mutation probability
Pm Equation (18), an adaptive mutation strategy similar to Equation (17), is designed with the aim of achieving the same as described above.
where
and
are the minimum and maximum mutation probabilities, respectively.
Based on the designed joint routing and core coding scheme with core switching, and combined with the adaptive mechanism mentioned above, we design an adaptive bi-layer mutation with the repair operator. Bi-layer mutation requires that the two-layer genes of routing and core in
be mutated separately. The principle and specific process are shown in
Figure 9 and Algorithm 3, respectively, which is explained as follows.
When the number of evolutions is not greater than
GLO, the single-point mutation on
or
is performed (lines 3–17). For a single-point mutation, it first generates a random number
in (0,1). If
is less than the mutation probability
, a gene site on the chromosome is randomly selected and we set the routing component to a value selected randomly from the remaining legal values. By this rule, we randomly select a gene site denoted by
msite (line 5) on the chromosome, i.e., Gene2 located in
Figure 9. First, the routing gene in Gene2 is mutated (lines 7–12), and then the path hop (line 13) is updated, which corresponds to the VCGCs length after the routing gene mutation and may be different from the length before mutation. Therefore, we need to perform the specific repair operation for the core gene to ensure that the individuals generated after the final mutation are feasible (line 14).
Specifically, we compare the number of hops in the updated path (after mutation) with that before the mutation of routing genes. If the former is less than the latter, then the redundant CGCs are UCGCs, and their values should be set to 0. If the two numbers are equal, the repair operation is not conducted. If the former is greater than the latter, some values are randomly selected in [1, |
C|] as the values of supplementary VCGCs. In
Figure 9, the blue line box part is VCGCs, and its length increases by one after the routing gene component mutation, shown as the yellow filled part. Finally, a single-point mutation (line 16) is performed on the repaired VCGCs. The process is similar to that of the routing gene component mutation, except that one gene is selected from the VCGCs for mutation, and the mutation value is generated in [1, |
C|]. The location of the orange number in
Figure 9 represents the gene sites where the routing and core mutation have occurred, and its value corresponds to the routing or core gene value after mutation. When the evolutionary generation is greater than
GLO, the multipoint mutation is performed (lines 18–23). The process is similar to that of single-point mutation except that multiple gene sites are randomly selected from the chromosome, and then the single-point mutation is performed on each selected gene.
| Algorithm 3 adaptive bi-layer mutation with repair operators |
| Input: individual (, ) obtained by crossover operator, : minimum mutation probability, : maximum mutation probability, traffic_routing_matrix |
| Output: offspring (, ) obtained by the mutation operator |
| 01 | Compute based on the Equation (18); |
| 02 | Set ; |
| {: Single-point mutation} |
| 03 | if |
| 04 | | Set maker = 0; |
| 05 | | An integer msite is generated randomly in [1, |R|]; |
| 06 | | {routing gene mutation} |
| 07 | | while marker = 0 do |
| 08 | | | if |
| 09 | | | | Set marker = 1; |
| 10 | | | end if |
| 11 | | end while |
| 12 | | |
| 13 | | hop = traffic_routing_matrix{msite, 3}(q); |
| 14 | | Repair: Ensure that each VCGC has the value of ([1, |C|]) and each UCGC is 0 based on the updated hop; |
| 15 | | {core gene mutation} |
| 16 | | Similar to the routing gene single-point mutation, except and , which should be and , where and are generated randomly in [2, hop + 1] and [1, |C|], respectively; |
| 17 | end if |
| {: Multi-point mutation} |
| 18 | if |
| 19 | | An integer array is generated randomly in [1, |R|]; |
| 20 | | fori = 1 to do |
| 21 | | | Execute 3–17 lines that are the main steps for single-point mutation; |
| 22 | | end for |
| 23 | end if |
5.5. Fitness Evaluation
The fitness function is used to evaluate the quality of individuals in the population. It mainly includes two objective functions in this paper: network RBR and crosstalk ratio. For each individual, we first allocate the appropriate routing, core, and spectrum blocks that satisfy the constraints of continuity, consistency, and inter-cross crosstalk, and then calculate the fitness value for evaluating the quality of N RSCA schemes. Finally, nondominated solution vectors are screened out according to Pareto dominance relation to form PF.
5.6. Algorithm Flowchart
Based on the description of the key mechanisms and steps above, Algorithm 4 shows the specific flowchart of the proposed MOEA/S-AMSF. Before the execution of this algorithm, we sorted all the connection requests according to the minimum bandwidth request priority criterion (aiming at reducing the RBR), and then calculate KSPs for all source-destination-node pairs. Then the routing result is stored in a data structure named “traffic_routing_matrix”. Finally, the maximum path length (
) and
geneLen (
) are calculated according to the
K shortest paths of all the requests, with traffic_routing_matrix and
geneLen as the algorithm inputs.
| Algorithm 4 MOEA/D-AMSF |
![Applsci 12 07128 i003]() |
MOEA/D-AMSF mainly includes three stages of initialization, evolution, and iteration stop judgment. The initialization process consists of four steps. First, set EP to empty for storing the nondominated solutions found in the search process (line 1); Second, calculate the Euclidean distance between any two weight vectors (line 3), and select several nearest subproblems of each subproblem to form its neighborhood (line 6); Third, generate the initial population {
x1,…,
xN} by IPHG algorithm designed in
Section 5.3 (line 8), and each individual in it is assigned an appropriate spectrum block by the FF method. Its fitness value
(line 9) is calculated, where
and
are the objective functions
and
defined in
Section 3.2, respectively. Finally, the reference point vector is initialized (line 10).
The evolution Stage two mainly performs crossover, mutation, reference point update, and neighborhood replacement on each individual in turn. Specifically, the adaptive crossover operator in Algorithm 2 and the adaptive bi-layer mutation with repair operator in Algorithm 3 are first used to generate feasible offspring and (lines 12 and 13). Second, the FF method is used to allocate the spectrum blocks for the generated two offspring, the fitness values and are calculated, and the offspring with better fitness value is selected as the new solution of the current subproblem i (line 14). Third, the reference point is updated by comparing it with the aggregation function value of (lines 15–19). Next, the neighborhood of subproblem i is updated by comparing the aggregation function value of with the old solution in the neighborhood and replacing the old one if has a better value (lines 20–24). Finally, EP is updated by removing all the solution vectors dominated by from EP and adding to EP if there is no solution vector dominating it in EP (lines 25–28). If the evolution iteration reaches , terminate the algorithm and output EP; otherwise, return to Stage two to continue the evolution (lines 30–34).
5.7. Conclusions
Compared with the commonly used linear weighted summation method, this algorithm is really to solve the problem from a multiobjective perspective, and it can provide users with resource allocation schemes with multiple objectives that are not dominated by each other. The proposed algorithm with various strategies is more flexible and effective than the traditional multiobjective optimization algorithms. However, the algorithm evolves slowly due to the exponential growth of the search space and cannot adapt to more complex network scenarios or optimize models.
6. Simulations and Result Analysis
This section conducts simulations of the proposed MOEA/D-AMSF and analyzes the experiment results. We first give the specific values of simulation parameters including the network topology and the proposed algorithm. The simulation results are then analyzed from the perspectives of algorithm convergence, solution domination, and solution diversity to verify the effectiveness of the proposed algorithm.
6.1. Simulation Parameters
In our simulation experiments, the NSFNET shown in
Figure 10 with 14 nodes and 21 links is adopted as the physical network topology, in which each node is capable of core switching. We assume that each fiber link is bidirectional and configured with MCF. Three connection request groups with different (300, 400, 500) requests are generated as representatives of light, medium, and heavy traffic loads, respectively. The number of FSs required for each connection request in each group is generated in [1, 10] uniformly and randomly, and all requests are evenly distributed among source-destination nodes pairs. To avoid the linear and/or nonlinear impairment of MCF, the guardband requires one FS, so that the total number of FSs required for each request is actually in [2, 11]. We set the number of shortest paths
K = 5. The number of cores of each fiber |
C| equals 3, 5, and 7, and the total number of FSs on each core |
F| is set to 30. We assume that the bandwidth of each FS is 12.5 GHz, and the modulation format for all requests is BPSK with a transmission distance of 9600 km. The crosstalk threshold
.
Table 2 presents the list of physical parameters and their values used in the proposed algorithm.
The baseline algorithm is the bi-objective genetic algorithm based on Tchebycheff decomposition (BOGA/TD) proposed in reference [
12]. Specifically, it encodes the routing and core into two populations to evolve, uses uniform design and random method to generate the initial routing and core populations, respectively, and sets evenly distributed weight vectors to decompose the bi-objective optimization problem into a series of single-objective optimization sub-problems on the basis of Tchebycheff decomposition. The values of
N,
and
are consistent with the proposed algorithm in this paper. The differential evolution probability, the mutation probability, and the differential coefficient are 0.5, 0.7, and 0.5.
6.2. Simulation Results and Analysis
We evaluate the proposed algorithm in terms of algorithm convergence, solution dominance, and solution diversity.
6.2.1. Algorithm Convergence
Shown in
Figure 11 and
Figure 12 are the PFs obtained by the baseline algorithm BOGA/TD and the proposed MOEA/D-AMSF with the increase of evolution generation, respectively. It can be seen from
Figure 11 that BOGA/TD algorithm evolves drastically from 1000 to 5000 generations, but it evolves slowly from 5000 to 50,000 generations and hardly evolves from 50,000 to 100,000 generations, which implies that the algorithm has converged around 50,000 generations. As shown in
Figure 12, the proposed MOEA/D-AMSF continues to evolve from 5000 to 100,000 generations, which shows its convergence is gradual. The difference in convergence speed between the two algorithms is mainly due to their different search spaces. The core coding on the links along the selected path is considered in this paper, and the core search space for each connection request changes from
to
(
). Therefore, the search space of the proposed algorithm becomes larger than that of the baseline algorithm, resulting in its gradual evolution and a larger number of generations required for convergence.
Figure 13 compares PFs obtained by the two algorithms with two evolution generations of 5000 and 50,000. Note that legends
A and
B in
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17,
Figure 18 and
Figure 19 denote the abbreviations of MOEA/D-AMSF and BOGA/TD, respectively. It can be seen from
Figure 13 that the proposed algorithm has a lower search speed in the early evolution stage (e.g., 5000 generations), and about 2/3 of the resulting solutions are not as good as those by the baseline algorithm. However, we can see that MOEA/D-AMSF has a better diversity compared to BOGA/TD; about 1/3 of the MOEA/D-AMSF solutions dominate those of BOGA/TD. In the later evolution stage, MOEA/D-AMSF can search for more dominated and diverse solutions. This result stems from the initial population generation method and the adaptive crossover and bi-layer mutation strategies designed in this paper. Some individuals in the initial population are solutions generated by the heuristic algorithm without core switching. In the early stage, single-point crossover and mutation with small crossover and mutation probabilities are adopted. Such mechanisms are designed to reduce the probability that the cores on different links change simultaneously in the early evolution stage so that the algorithm has a good evolutionary basis and guides itself to search for solutions in the global solution space, lowering the evolution speed of the algorithm. While the probabilities of crossover and mutation in the later evolution stage are increased and multi-point mutation is adopted, which makes the algorithm jump out of the local search and find fo more solutions, accelerating algorithm convergence and enhancing solution diversity.
6.2.2. Influence of the Number of Cores
To study the influence of the number of cores on algorithm performance,
Figure 14,
Figure 15 and
Figure 16 exhibit the PFs obtained by two algorithms with different numbers and cores when requests equal 400, 500, and 600, respectively. We discuss the simulation results and give relevant explanations of PFs obtained by the two algorithms in terms of three aspects: the whole change trend, solution dominance, and solution diversity.
- (a)
Change Trend of PFs
As the number of cores increases, the PFs obtained by the two algorithms are getting better, i.e., PFs evolve towards the origin of coordinates. This is because MCF-EONs with more cores can provide more spectrum resources for connection requests, and both metrics will be smaller.
- (b)
Solutions Dominance
It can be seen from the three figures that the proposed algorithm can obtain a majority of solutions that dominate those obtained by the baseline algorithm (called dominated solutions) except in the case of |
R| = 500 and |
C| = 3, and it dominated almost all solutions in
Figure 14 for |
C| = 5. This is because core switching can alleviate the spectrum constraints for requests, thus reducing the blocking ratio to a certain extent. Due to the introduction of the IPHG strategy and the adaptive mechanism, the proposed algorithm can evolve a better solution set. In addition, under the same evolutionary generation, as the number of cores increases, the core search space (
) of the proposed algorithm grows exponentially, leading to a gradual decrease in the dominant solutions.
Figure 15 and
Figure 16 demonstrate this rule clearly. For optical fibers with three cores, five cores, and seven cores, the ratio of dominant solutions to the total number of solutions obtained by the proposed algorithm (called dominant ratio) in
Figure 15 is 81%, 73%, and 17%, respectively, while in
Figure 16 it is 67%, 42%, and 10%, respectively.
- (c)
Solution Diversity
The solution diversity of the proposed algorithm is better than that of the baseline algorithm because of the adaptive crossover and mutation strategies and the introduction of multi-point mutation at the later search stage which can increase the probability of the algorithm finding new solutions, thus enabling it to find more solutions in the global search space. Moreover, from the perspective of each core, the proposed algorithm can search for the solutions that the baseline algorithm cannot find in the range of lower blocking ratio but higher crosstalk ratio (left half of the figures), i.e., core switching can expand the search range of available spectrum resources, so that the MOEA/D-AMSF has better performance in terms of blocking ratio.
6.2.3. Effect of Traffic Loads
To investigate the influence of traffic loads on algorithm performance, we present the PFs obtained by two algorithms with different traffic loads and the same core numbers, as shown in
Figure 17,
Figure 18 and
Figure 19.
First, we can see the whole variant trend of PFs obtained by the two algorithms. As the number of connection requests increases, the PFs obtained by the two algorithms become worse (away from the origin of coordinates), i.e., the blocking ratio and crosstalk ratio are getting higher. This is because network resources are limited. When the number of requests increases, the average resource that the network can provide for each latter request decreases, causing some requests to be blocked, and the allocation of unblocked requests leads to an increase in the crosstalk ratio.
Second, we compare the dominant performance of the solutions obtained by the two algorithms under different traffic loads. For the same number of cores, the proposed algorithm can obtain a certain number of dominant solutions under both light and heavy traffic loads. This is due to the influence of core switching and the multiple adaptive strategies proposed, which enable the algorithm to conduct a comprehensive and efficient search in the overall resource space of the network. In addition, it can be seen from the first two figures that as the number of requests increases, the number of dominant solutions obtained by the proposed algorithm decreases, i.e., the efficiency of core switching gradually weakens. This results from core switching under light traffic loads which can consider the available spectrum resources of each core from the perspective of the entire network, so that more requests can be served under the spectrum constraints, thus reducing the network RBR. However, under heavy traffic loads, the efficiency of core switching becomes weak, since the negative impact of network spectrum fragments is the main factor in the algorithm’s performance, i.e., many spectrum fragments will appear on all cores. Even if the core can be switched on different links, the spectrum constraints of continuity and consistency cannot be satisfied, resulting in an increase in both the network RBR and crosstalk ratio.
Finally, the performances of the two algorithms in terms of solution diversity are compared. It can be seen from the figures that the diversity of the solutions obtained by the proposed algorithm is better, and it can find solutions that cannot be obtained by the baseline algorithm in the objective space with a smaller blocking ratio (left half of figures), which shows the same rule as that in
Figure 14,
Figure 15 and
Figure 16.
With the increase in both the number of connection requests in
Figure 14,
Figure 15 and
Figure 16 and the number of cores in the last two figures, we can see that, except for the scenarios with 7-core, most of the solutions of MOEA/D-AMSF dominate those from the baseline algorithm. Each lower right part of the three pair-curve shows that the baseline algorithm obtains more solutions, particularly in the case of three cores. However, such solutions have a blocking ratio of 0.4 or even higher, and thus are infeasible in real systems.
6.3. Conclusions
As the number of cores increases, MCF-EONs with more cores can provide more spectrum resources for connection requests, and both metrics will be smaller. As the number of connection requests increases, the PFs obtained by the two algorithms become worse (away from the origin of coordinates), i.e., the blocking ratio and crosstalk ratio are getting higher.
7. Conclusions
In this paper, a static bi-objective resource optimization model is established for MCF-EONs with limited resources. To effectively solve the model, a joint routing and core coding scheme with core switching is designed for the first time, and a new hybrid algorithm called MOEA/D-AMSF is proposed. The algorithm integrates multiple strategies, such as the IPHG, single-point crossover and bi-layer single and multiple mutations with repair operators into the MOEA/D framework. An adaptive mechanism is distinctively designed to adjust both crossover and mutation probabilities to accelerate algorithm convergence and enhance solution diversity. Finally, the algorithm performance is evaluated in NSFNET topology. The results show that, compared with the baseline algorithm, the proposed algorithm can obtain more dominated and diverse solutions in most cases. It can also search for solutions that the baseline algorithm cannot find in such an objective space with a smaller blocking ratio. However, it evolves slowly due to the exponential growth of the search space as the number of requests and cores increases. The research has also shown that core switching has a significant effect on reducing the network RBR and crosstalk ratio under lighter traffic loads. In the case of a heavier traffic load, spectrum fragments become the main factor affecting the network service performance, and the performance with core switching deteriorates a little since the number of solutions dominated by the baseline algorithm increases.
There are still many scenarios to be studied further: (a) only static connection requests are studied in this paper, and dynamic connection requests that arrive randomly to the network can be studied in the next work, for example, the RSCA problem modeling and algorithm design considering spectrum fragments; (b) considering the cost of the network node with core switching, an optimization model that minimizes cost and blocking probability simultaneously can be established to make research more realistic; and (c) facing more complex network scenarios or optimization models, the introduction of computer parallelism, clustering algorithms, prediction algorithms, and machine learning into MOEA/D-AMSF could further accelerate algorithm convergence.
Author Contributions
Conceptualization, Z.X. and Q.X.; methodology, Z.X.; software, Q.X.; validation, Q.X. and T.M.; formal analysis, Q.X.; investigation, Q.X.; resources, T.C.; data curation, J.L.; writing—original draft preparation, Q.X.; writing—review and editing, Z.X.; visualization, Q.X. and T.C.; supervision, Z.X.; project administration, J.L.; funding acquisition, J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Key Research and Development Program of China (2019YFB1803605, 2020YFB1805601) and the National Science Foundation of China (No. 61572391).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We thank the National Key Research and Development Program of China (2019YFB1803605, 2020YFB1805601) and the National Science Foundation of China (No. 61572391) for their funding.
Conflicts of Interest
The authors declare no conflict of interest.
Nomenclature
| B(i) | neighborhood of subproblem i. |
| capacity of each core. |
| capacity of each FS. |
| core n. |
| core index selected by request if it passes through a link on the selected path . |
| destination node. |
| f | FS index. |
| start FS index on core occupied by the request if it passes through a link of the selected path . |
| GF | number of FSs needed for guardband. |
| GLO | search may fall into the local optimum at this generation. |
| maximum evolutionary generations. |
| h | mean increase in inter-core crosstalk per fiber length unit. |
| k | coupling coefficient. |
| L | length of each fiber. |
| bidirectional fiber link between node and node . |
| n | number of adjacent cores. |
| total number of blocked connection requests in a network. |
| total number of crosstalk FSs generated in a network. |
| total number of occupied FSs in a network. |
| selected path of request . |
| crossover probability. |
| minimum crossover probability. |
| maximum crossover probability. |
| mutation probability. |
| minimum mutation probability. |
| maximum mutation probability. |
| the random number in (0, 1). |
| r | bend radius. |
| k-th request. |
| source node for . |
| number of required FSs for . |
| core-pitch. |
| inter-core crosstalk. |
| number of crosstalk FSs at link l on the selected path p for the connection request . |
| number of crosstalk FSs for . |
| crosstalk value of a single request in a network. |
| Boolean variable equals 1 if the path bears the request , and 0 otherwise. |
| propagation constant. |
| Boolean variable equals 1 if request is to be allocated the FS on a core of link , while on adjacent to core is occupied at the same time. |
| Boolean variable equals 1 if request occupies the core on a link . |
| Boolean variable equals 1 if the FS on a core of link is occupied. |
| crosstalk threshold for a given modulation format. |
| cores set on each optical fiber link. |
| set of FSs on each optical fiber link. |
| set of optical fiber links. |
| set of K candidate paths in ascending order of path length for each request . |
| set of all connection requests. |
| set of bandwidth-variable optical cross nodes. |
| reference point vector. |
| weight vector. |
References
- Liu, H.; Xiong, Q.; Chen, Y. Routing Core and Spectrum Allocation Algorithm for Inter-Core Crosstalk and Energy Efficiency in Space Division Multiplexing Elastic Optical Networks. IEEE Access 2020, 8, 70453–70464. [Google Scholar] [CrossRef]
- Lechowicz, P.; Walkowiak, K.; Klinkowski, M. Selection of spectral-spatial channels in SDM flexgrid optical networks. In Proceedings of the 2017 International Conference on Optical Network Design and Modeling (ONDM), Budapest, Hungary, 15–18 May 2017; pp. 1–6. [Google Scholar]
- Downie, J.D.; Liang, X.; Makovejs, S. On the potential application space of multicore fibres in submarine cables. In Proceedings of the 45th European Conference on Optical Communication (ECOC 2019), Dublin, Ireland, 22–26 September 2019; pp. 1–4. [Google Scholar]
- Li, M.; Xiong, W.; Stone, J.S.; Li, K.; Chen, X.; Hurley, J.E.; Garner, S.C. High bandwidth coupled multicore fibre for data centre applications. In Proceedings of the 45th European Conference on Optical Communication (ECOC 2019), Dublin, Ireland, 22–26 September 2019; pp. 1–4. [Google Scholar]
- Zhu, J.; Zhu, Z. Physical-Layer Security in MCF-Based SDM-EONs: Would Crosstalk-Aware Service Provisioning be Good Enough? J. Lightwave. Technol. 2017, 35, 4826–4837. [Google Scholar] [CrossRef]
- Zhang, L.; Ansari, N.; Khreishah, A. Anycast Planning in Space Division Multiplexing Elastic Optical Networks with Multi-Core Fibers. IEEE Commun. Lett. 2016, 20, 1983–1986. [Google Scholar] [CrossRef]
- Fang, W.; Zeng, M.; Liu, X.; Lu, W.; Zhu, Z. Joint Spectrum and IT Resource Allocation for Efficient VNF Service Chaining in Inter-Datacenter Elastic Optical Networks. IEEE Commun. Lett. 2016, 20, 1539–1542. [Google Scholar] [CrossRef]
- Yang, M.; Zhang, Y.; Wu, Q. Routing, spectrum, and core assignment in SDM-EONS with MCF: Node-arc ILP/MILP methods and an efficient XT-aware heuristic algorithm. J. Opt. Commun. Netw. 2018, 10, 195–208. [Google Scholar] [CrossRef]
- Zhai, B.; Xu, Z.; Ding, Z. A co-evolution algorithm for resource allocation in elastic optical networks with multi-core fibers. Study Opt. Commun. 2017, 6, 52–55+74. [Google Scholar] [CrossRef]
- Xuan, H.; Wang, Y.; Hao, S.; Xu, Z.; Li, X.; Gao, X. Security-Aware Routing and Core Allocation in Elastic Optical Network with Multi-core. In Proceedings of the 2016 12th International Conference on Computational Intelligence and Security (CIS), Wuxi, China, 16–19 December 2016; pp. 294–298. [Google Scholar]
- Hu, Y.; Xiao, S.; Feng, J. Model and algorithm for routing and fiber-core assignment in multi-core elastic optical networks. Laser Optoelectron. Prog. 2019, 56, 105–111. [Google Scholar] [CrossRef]
- Zhai, B. Research on resource allocation model and new optimization algorithms in elastic optical networks with multi-core fibers. Master’s Thesis, Xidian University, Xi’an, China, 2017. [Google Scholar]
- Zhao, Y.; Hu, L.; Zhu, R.; Yu, X.; Wang, X.; Zhang, J. Crosstalk-Aware Spectrum Defragmentation Based on Spectrum Compactness in Space Division Multiplexing Enabled Elastic Optical Networks with Multicore Fiber. IEEE Access 2018, 6, 15346–15355. [Google Scholar] [CrossRef]
- Tode, H.; Hirota, Y. Routing, spectrum and core assignment for space division multiplexing elastic optical networks. In Proceedings of the 2014 16th International Telecommunications Network Strategy and Planning Symposium (Networks), Funchal, Portugal, 17–19 September 2014; pp. 1–7. [Google Scholar]
- Zhao, Y.; Hu, L.; Wang, C.; Zhu, R.; Yu, X.; Zhang, J. Multi-core virtual concatenation scheme considering inter-core crosstalk in spatial division multiplexing enabled elastic optical networks. China Commun. 2017, 14, 108–117. [Google Scholar] [CrossRef]
- Zhang, S.; Yeung, K.L. Dynamic service provisioning in space-division multiplexing elastic optical networks. J. Opt. Commun. Netw. 2020, 12, 335–343. [Google Scholar] [CrossRef]
- Muhammad, A.; Zervas, G.; Forchheimer, R. Resource Allocation for Space-Division Multiplexing: Optical White Box Versus Optical Black Box Networking. J. Lightwave Technol. 2015, 33, 4928–4941. [Google Scholar] [CrossRef] [Green Version]
- Tode, H.; Hirota, Y. Routing, spectrum, and core and/or mode assignment on space-division multiplexing optical networks [invited]. J. Opt. Commun. Netw. 2017, 9, A99–A113. [Google Scholar] [CrossRef]
- Lai, J.; Tang, R.; Wu, B.; Wu, W.; Li, H.; Liu, G.J.; Zhao, W.Y.; Zhang, H.Y. Analysis on the research progress of space division multiplexing in optical fiber communication. Telecommun. Sci. 2017, 33, 118–135. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, R.; Zuo, J.; Jing, X. Enhancing MOEA/D with uniform population initialization, weight vector design and adjustment using uniform design. J. Syst. Eng. Electron. 2015, 26, 1010–1022. [Google Scholar] [CrossRef]
- Xuan, H.; Wang, Y.; Xu, Z.; Hao, S. Core Selection Algorithm for Multi-Core Elastic Optical Networks. Acta Optica Sin. 2016, 36, 67–73. [Google Scholar] [CrossRef]
Figure 1.
Spectrum allocation and utilization in optical WDM networks and EONs.
Figure 1.
Spectrum allocation and utilization in optical WDM networks and EONs.
Figure 2.
Cross-section of a multi-core fiber.
Figure 2.
Cross-section of a multi-core fiber.
Figure 3.
Node architecture in MCF-EONs.
Figure 3.
Node architecture in MCF-EONs.
Figure 4.
Core switching principle.
Figure 4.
Core switching principle.
Figure 5.
Node architecture of core switching with modification to [
17]. (Reprinted with permission from Ref. [
17]. 2015, Ajmal Muhammad).
Figure 5.
Node architecture of core switching with modification to [
17]. (Reprinted with permission from Ref. [
17]. 2015, Ajmal Muhammad).
Figure 6.
Example of inter-core crosstalk.
Figure 6.
Example of inter-core crosstalk.
Figure 7.
Coding schemes of gene, chromosome, and population. (a) gene coding scheme; (b) chromosome coding scheme; (c) population coding scheme.
Figure 7.
Coding schemes of gene, chromosome, and population. (a) gene coding scheme; (b) chromosome coding scheme; (c) population coding scheme.
Figure 8.
Single-point crossover under the proposed coding scheme.
Figure 8.
Single-point crossover under the proposed coding scheme.
Figure 9.
Bi-layer single-point mutation.
Figure 9.
Bi-layer single-point mutation.
Figure 10.
NSFNET topology.
Figure 10.
NSFNET topology.
Figure 11.
PFs evolution of baseline BOGA/TD (|R| = 300, |C| = 5).
Figure 11.
PFs evolution of baseline BOGA/TD (|R| = 300, |C| = 5).
Figure 12.
PFs evolution of MOEA/D-AMSF (|R| = 300, |C| = 5).
Figure 12.
PFs evolution of MOEA/D-AMSF (|R| = 300, |C| = 5).
Figure 13.
PFs evolution comparison of two algorithms (|R| = 300, |C| = 5).
Figure 13.
PFs evolution comparison of two algorithms (|R| = 300, |C| = 5).
Figure 14.
Comparison of PFs under different cores (|R| = 300).
Figure 14.
Comparison of PFs under different cores (|R| = 300).
Figure 15.
Comparison of PFs under different cores (|R| = 400).
Figure 15.
Comparison of PFs under different cores (|R| = 400).
Figure 16.
Comparison of PFs under different cores (|R| = 500).
Figure 16.
Comparison of PFs under different cores (|R| = 500).
Figure 17.
Comparison of PFs under different traffic volumes (|C| = 3).
Figure 17.
Comparison of PFs under different traffic volumes (|C| = 3).
Figure 18.
Comparison of PFs under different traffic volumes (|C| = 5).
Figure 18.
Comparison of PFs under different traffic volumes (|C| = 5).
Figure 19.
Comparison of PFs under different traffic volumes (|C| = 7).
Figure 19.
Comparison of PFs under different traffic volumes (|C| = 7).
Table 1.
Summary of References.
Table 1.
Summary of References.
| References | The Modulation
Format Is Variable? | Dynamic/Static Network Scenarios | Considering Inter-Core Crosstalk? | Multi-Objective Joint Optimization? | Innovation |
|---|
| [13] | √ | dynamic | √ | ✕ | A crosstalk-aware spectrum defragmentation algorithm based on a metric. |
| [14] | ✕ | dynamic | √ | ✕ | An RSCA algorithm based on spectrum partition, predefined core priority, and classification. |
| [15] | ✕ | dynamic | √ | ✕ | It first proposed considering inter-core crosstalk to solve the spectrum fragmentation issue in SDM-EONs. |
| [16] | √ | dynamic | ✕ | ✕ | A set of new algorithms were proposed to solve the RMSCA problem. |
| [5] | ✕ | static | √ | ✕ | It proposed a time-efficient heuristic Aa-RSCA to balance the tradeoff between spectrum utilization and inter-core crosstalk. |
| [6] | ✕ | static | √ | ✕ | It investigated the anycast problem in space division multiplexing elastic optical networks overlaid on multicore fibers. |
| [17] | √ | static | √ | ✕ | It proposed a programmable architecture on demand (AoD) node. |
| [8] | ✕ | static | √ | ✕ | It proposed a heuristic algorithm with crosstalk awareness. |
| [9] | ✕ | static | √ | ✕ | It proposed an optimization algorithm based on co-evolution to solve the RSCA problem for the first time. |
| [10] | √ | static | √ | ✕ | It investigated the RSCA problem with the guaranteed secure level in elastic optical network with multi-core. |
| [11] | √ | static | √ | ✕ | An intelligent algorithm is proposed, and the influence of the exchange of cores on network performance is considered in the mode. |
| [12] | ✕ | static | √ | √ | It established a multiobjective model and designed a corresponding multiobjective optimization algorithm to solve it. |
Table 2.
The List of Physical Parameters and Their Values used in MOEAD/AMSF Algorithm.
Table 2.
The List of Physical Parameters and Their Values used in MOEAD/AMSF Algorithm.
| Parameters | Values | Parameters | Values |
|---|
| Population size (N) | 100 | neighborhood size () | 15 |
| ) | 100,000 | gene length (geneLen) | |
| 0.4 | | 0.9 |
| 0.3 | | 0.9 |
| 10,000 | multi-point mutation | three-point |
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).

























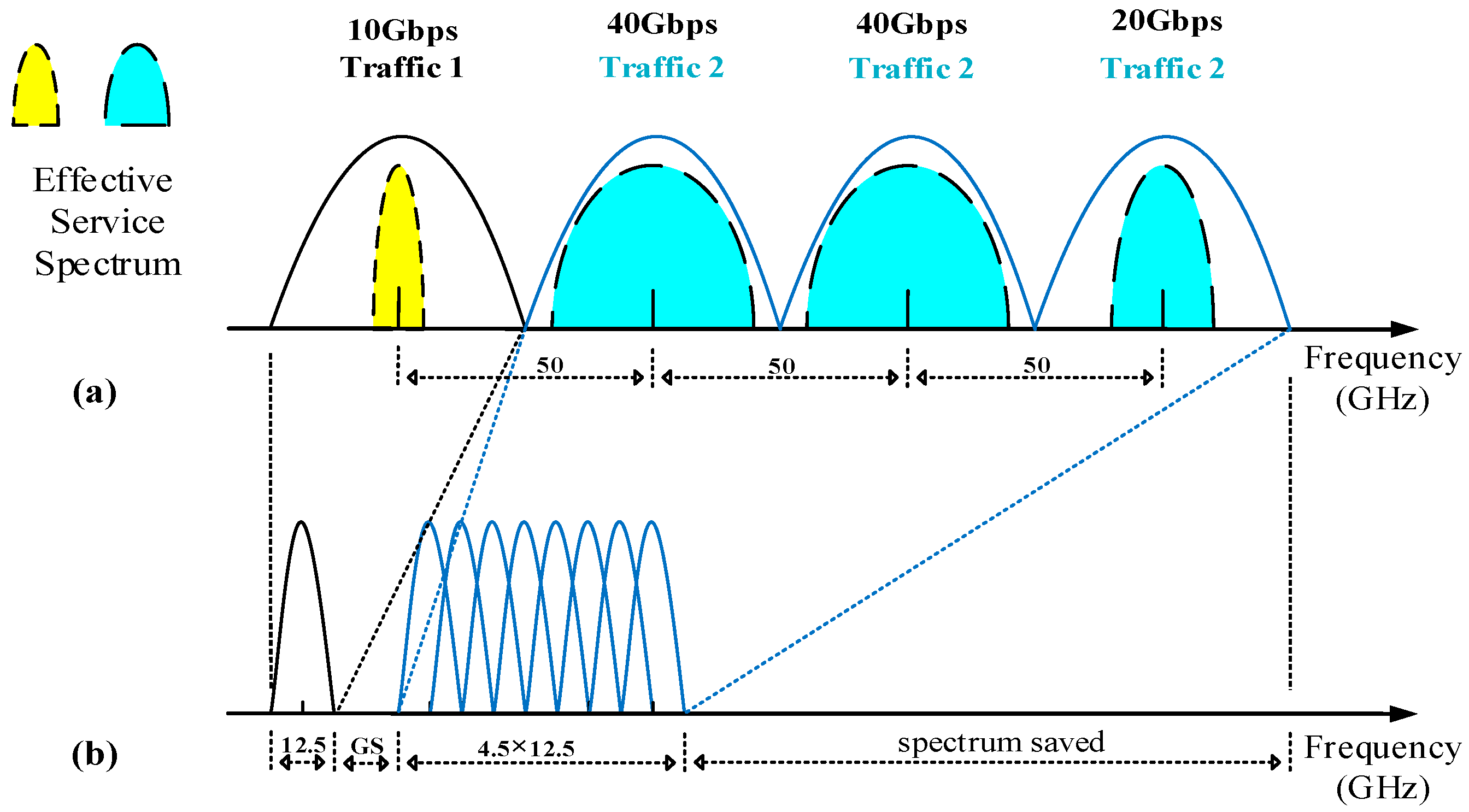{kind=link}
{kind=link}
{kind=link}
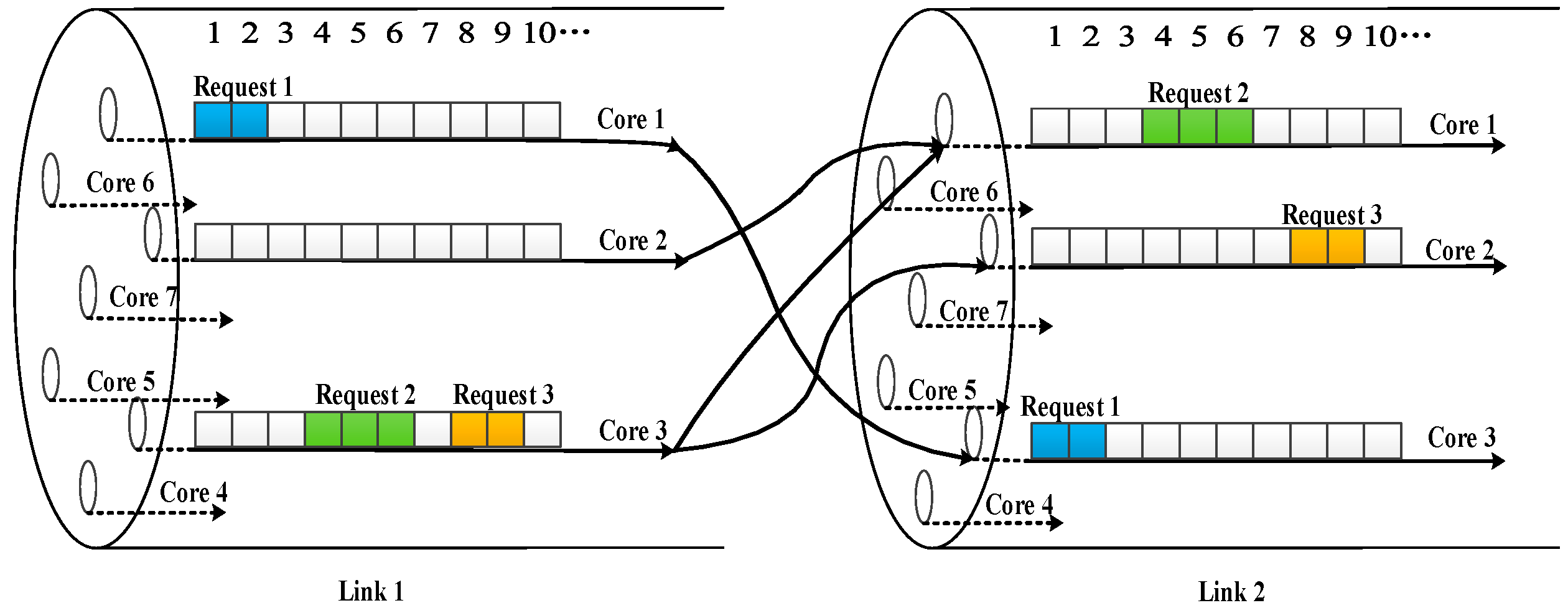{kind=link}
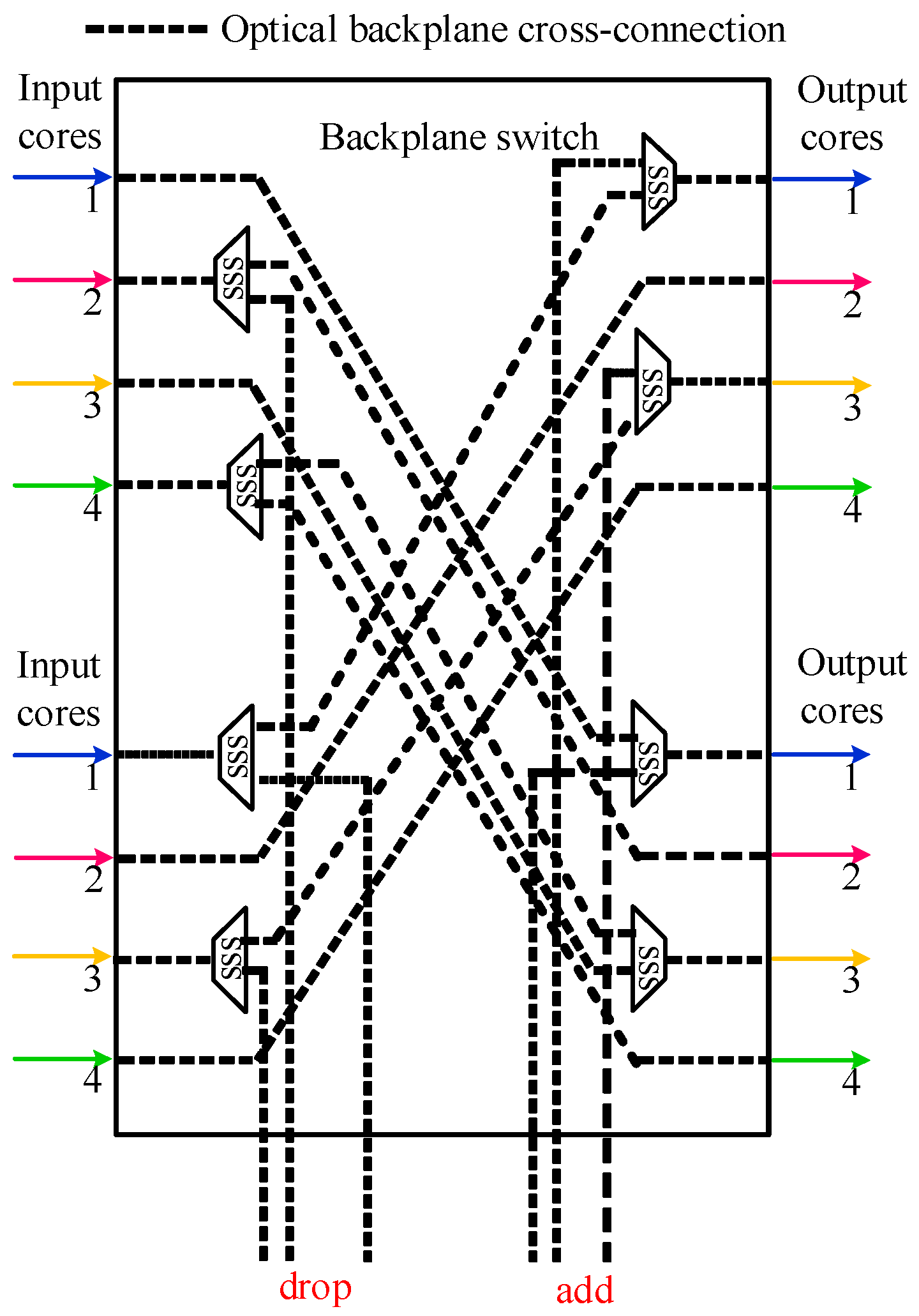{kind=link}
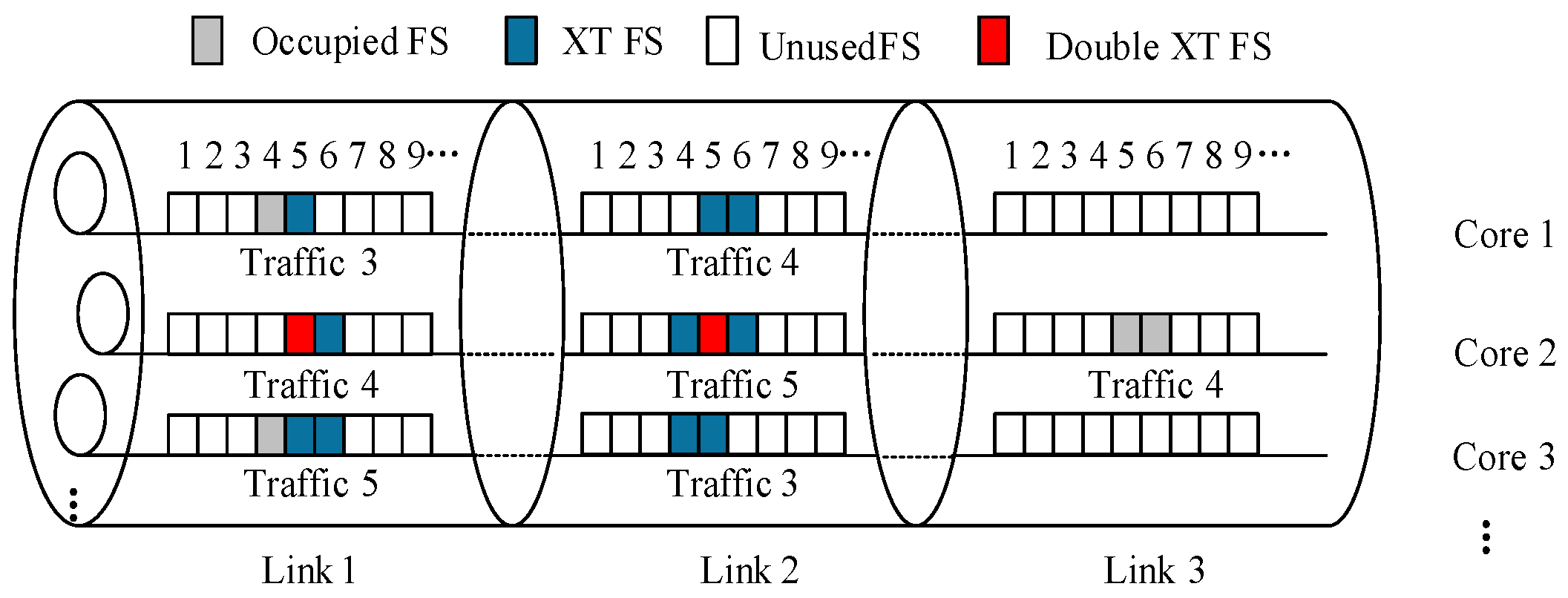{kind=link}
{kind=link}
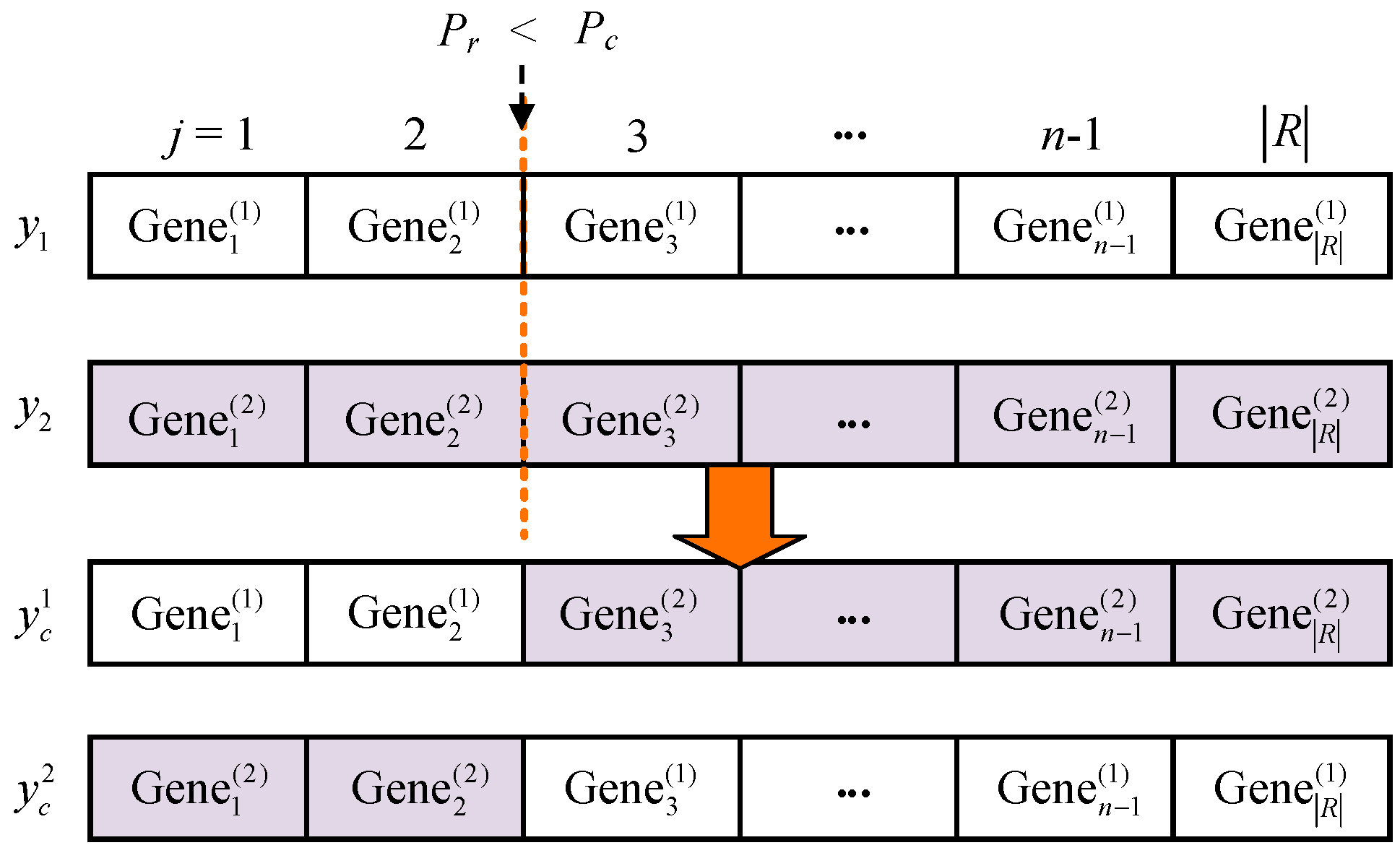{kind=link}
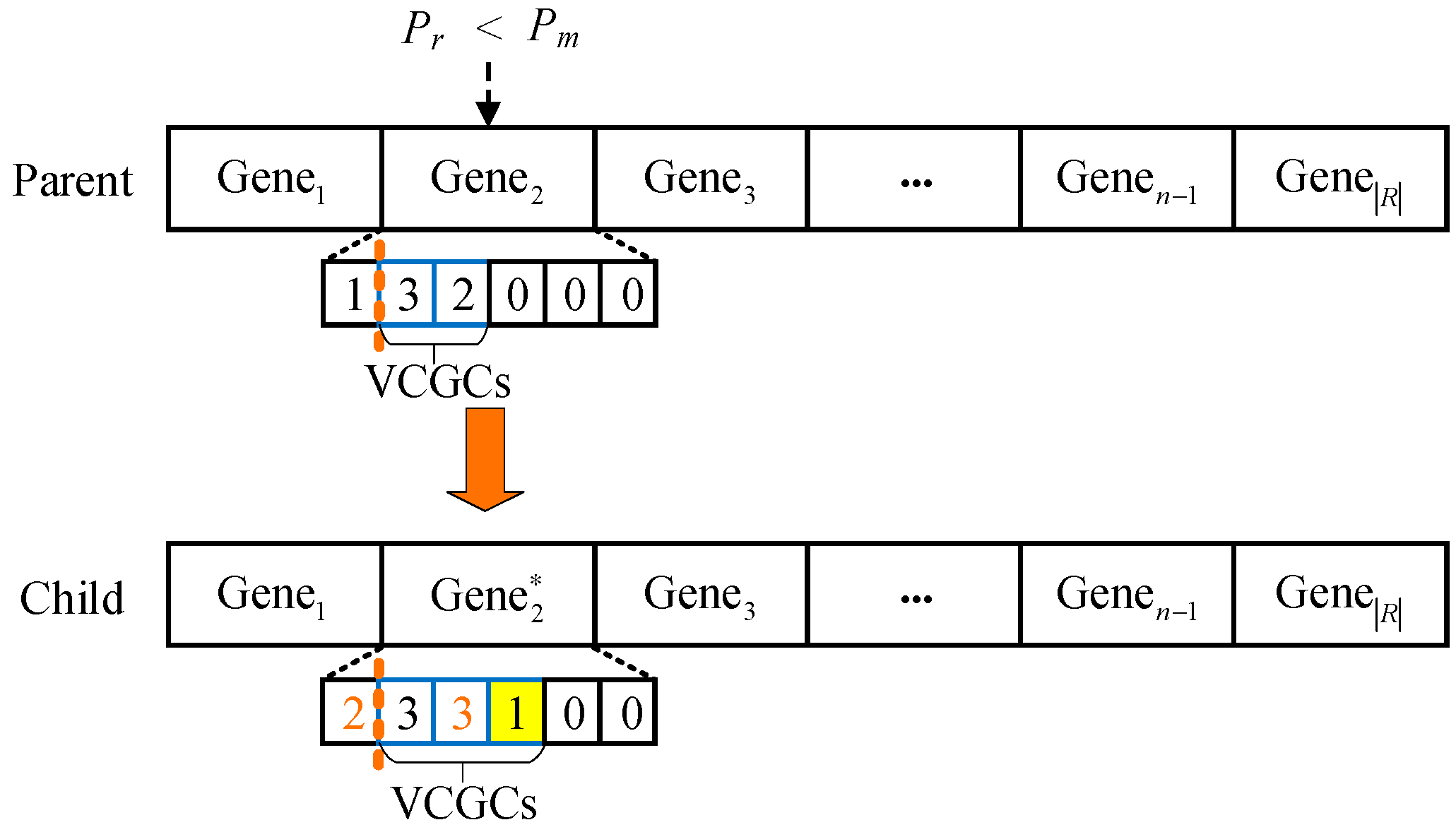{kind=link}
{kind=link}
{kind=link}
{kind=link}
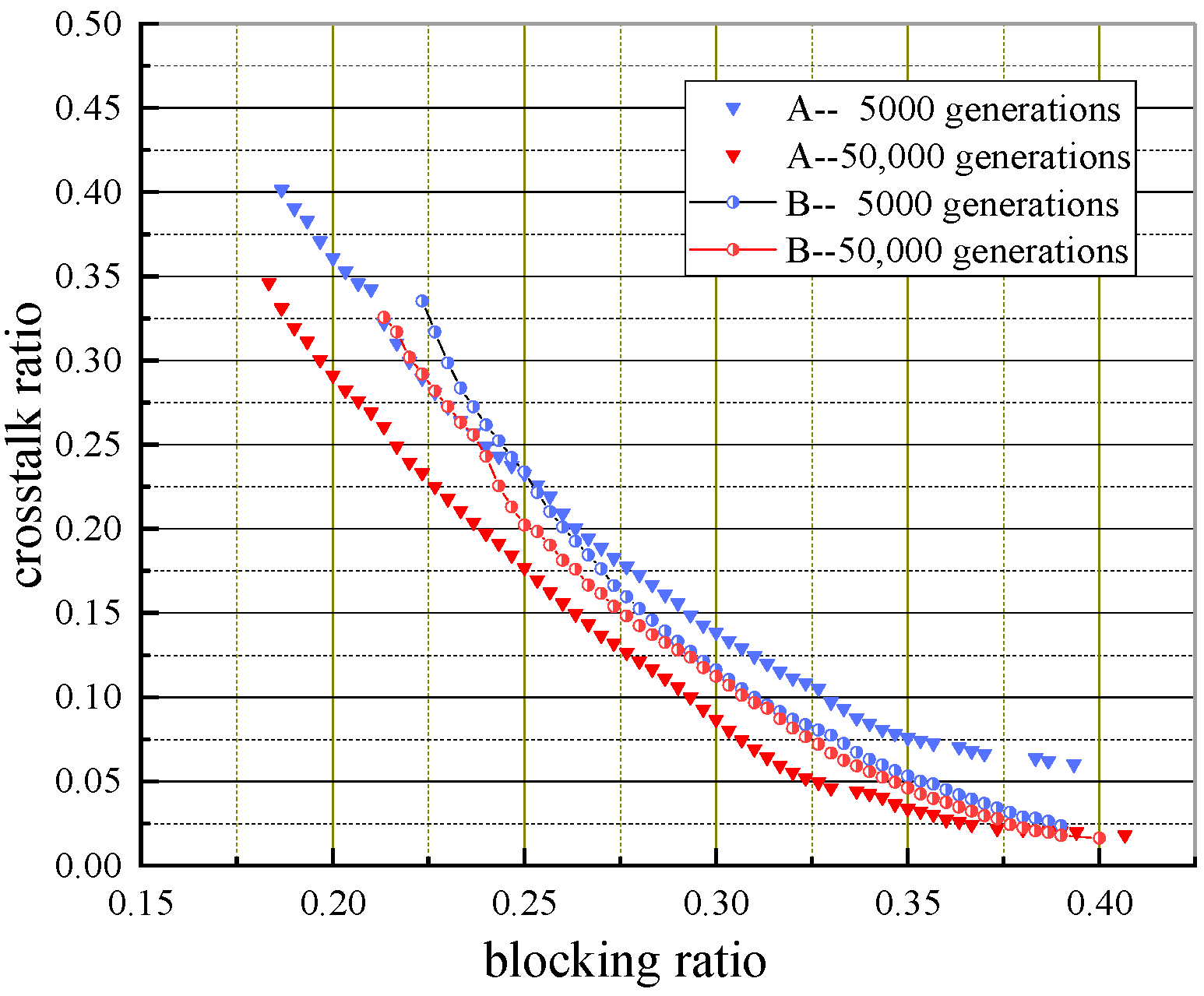{kind=link}
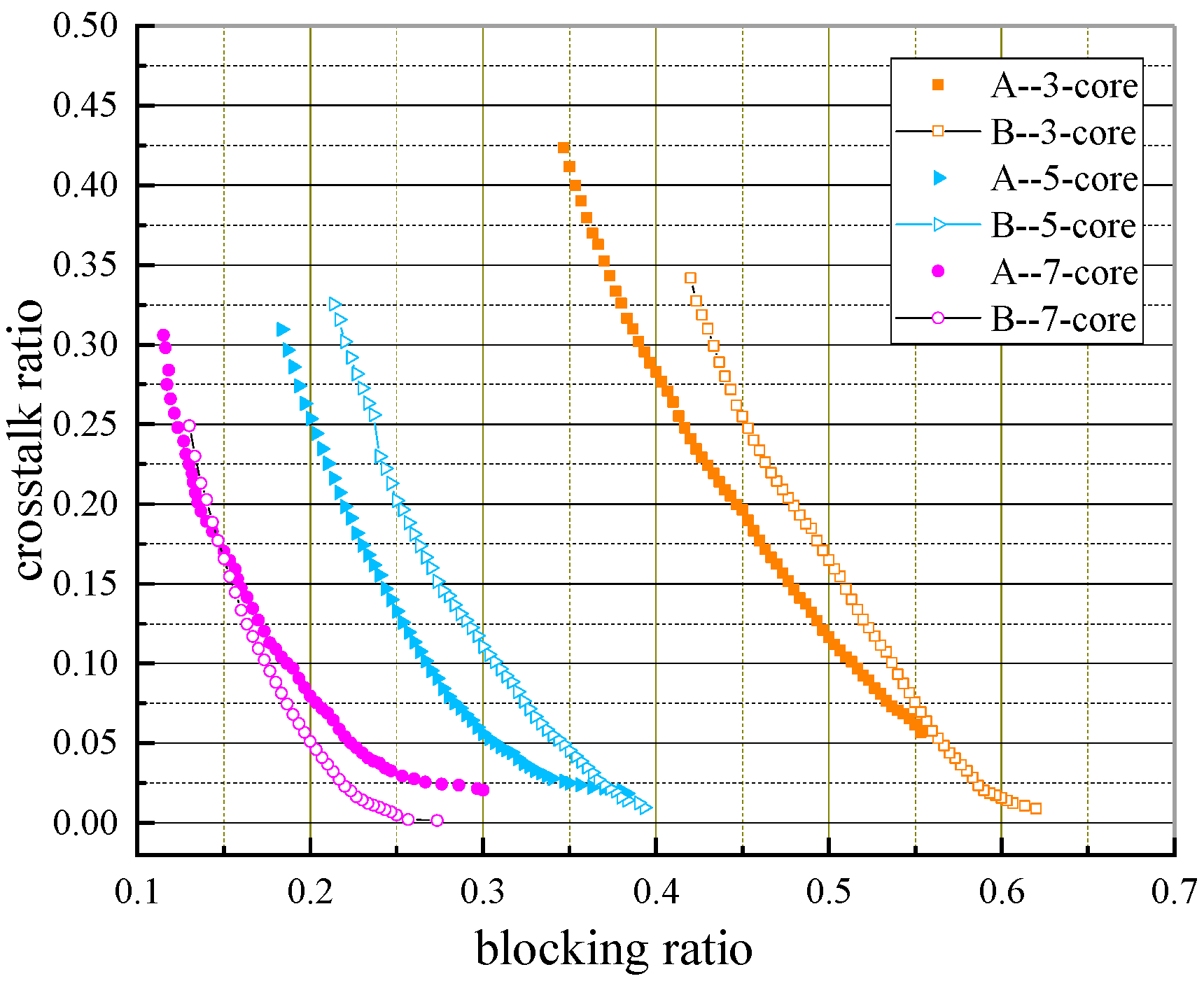{kind=link}
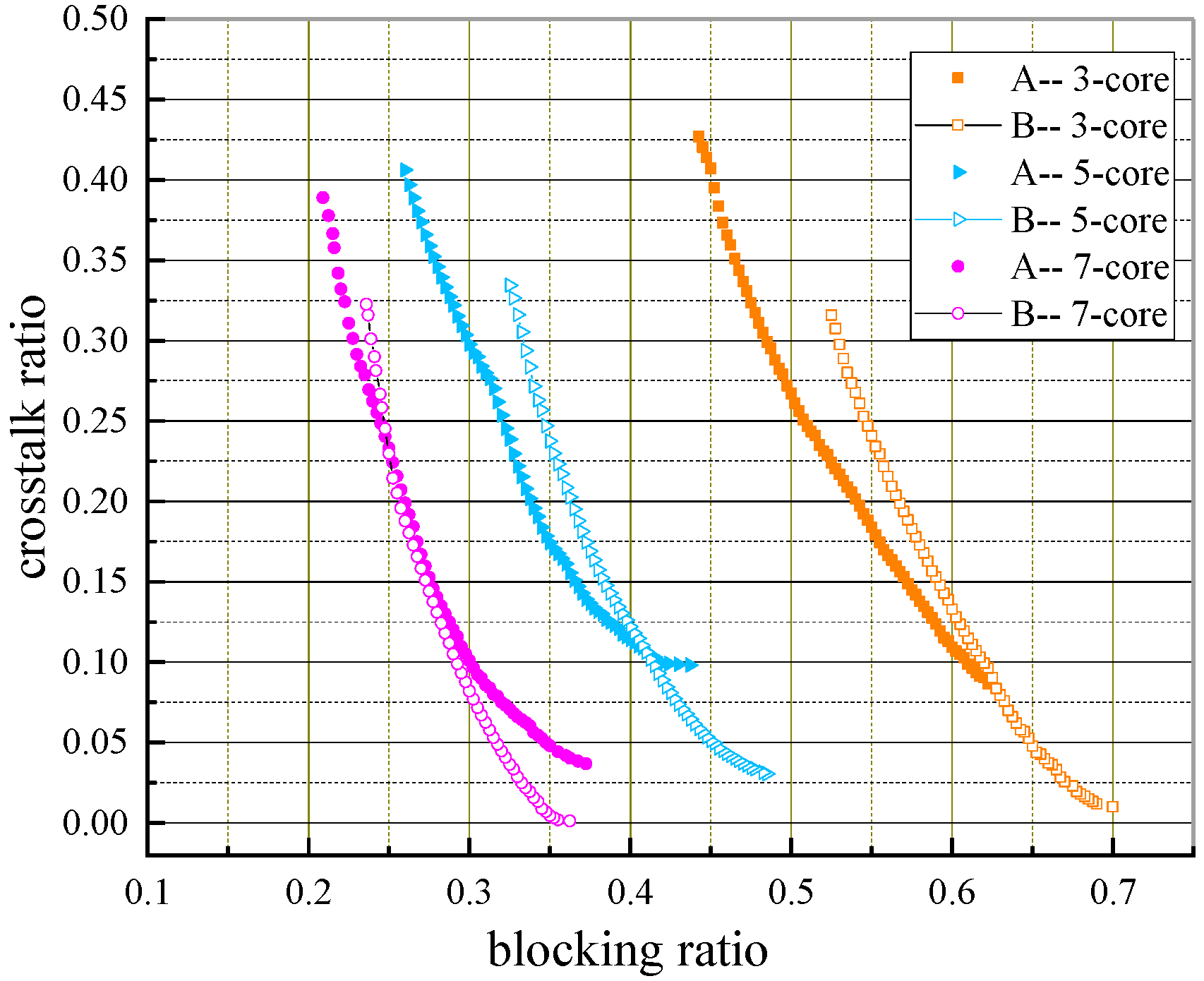{kind=link}
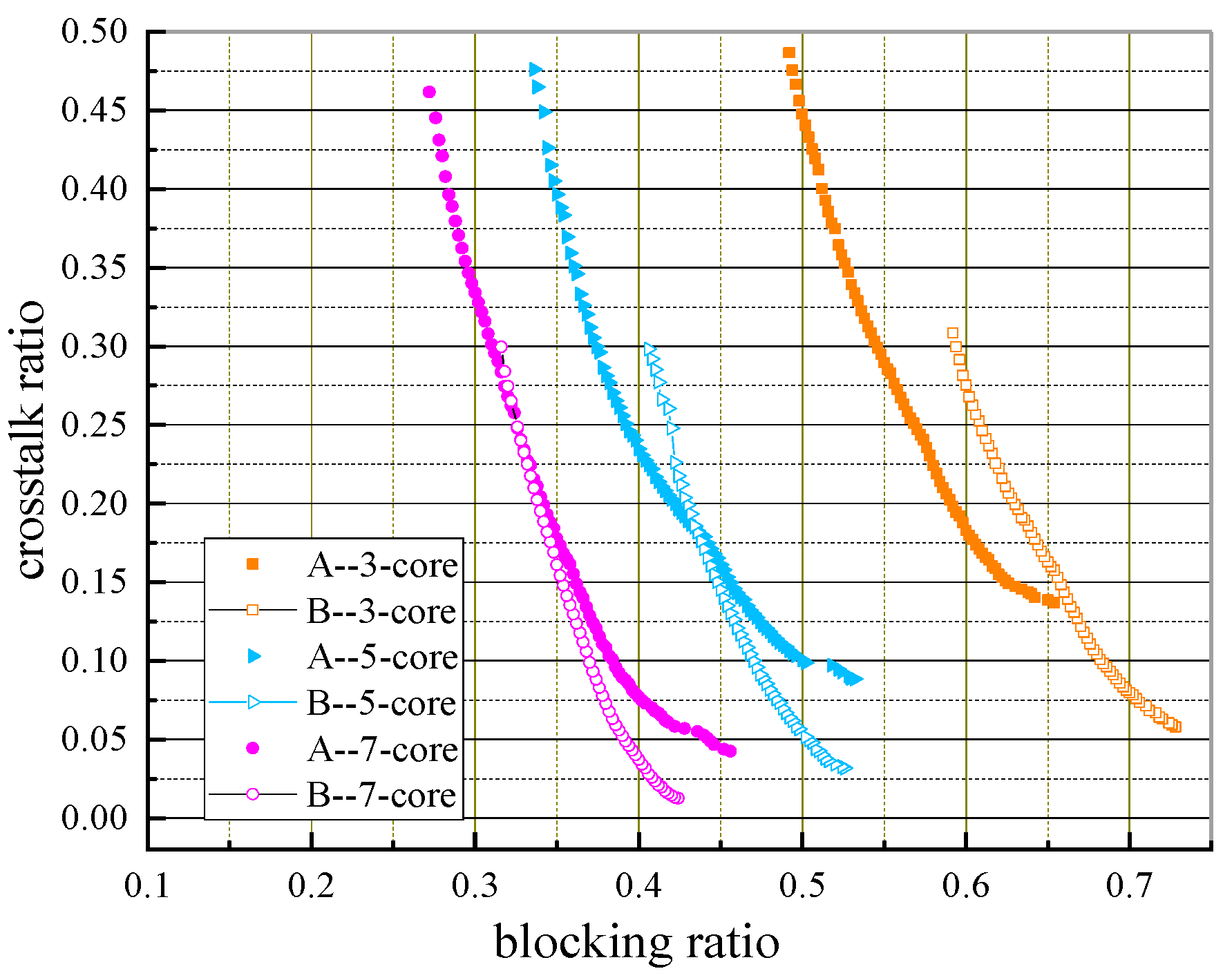{kind=link}
{kind=link}
{kind=link}
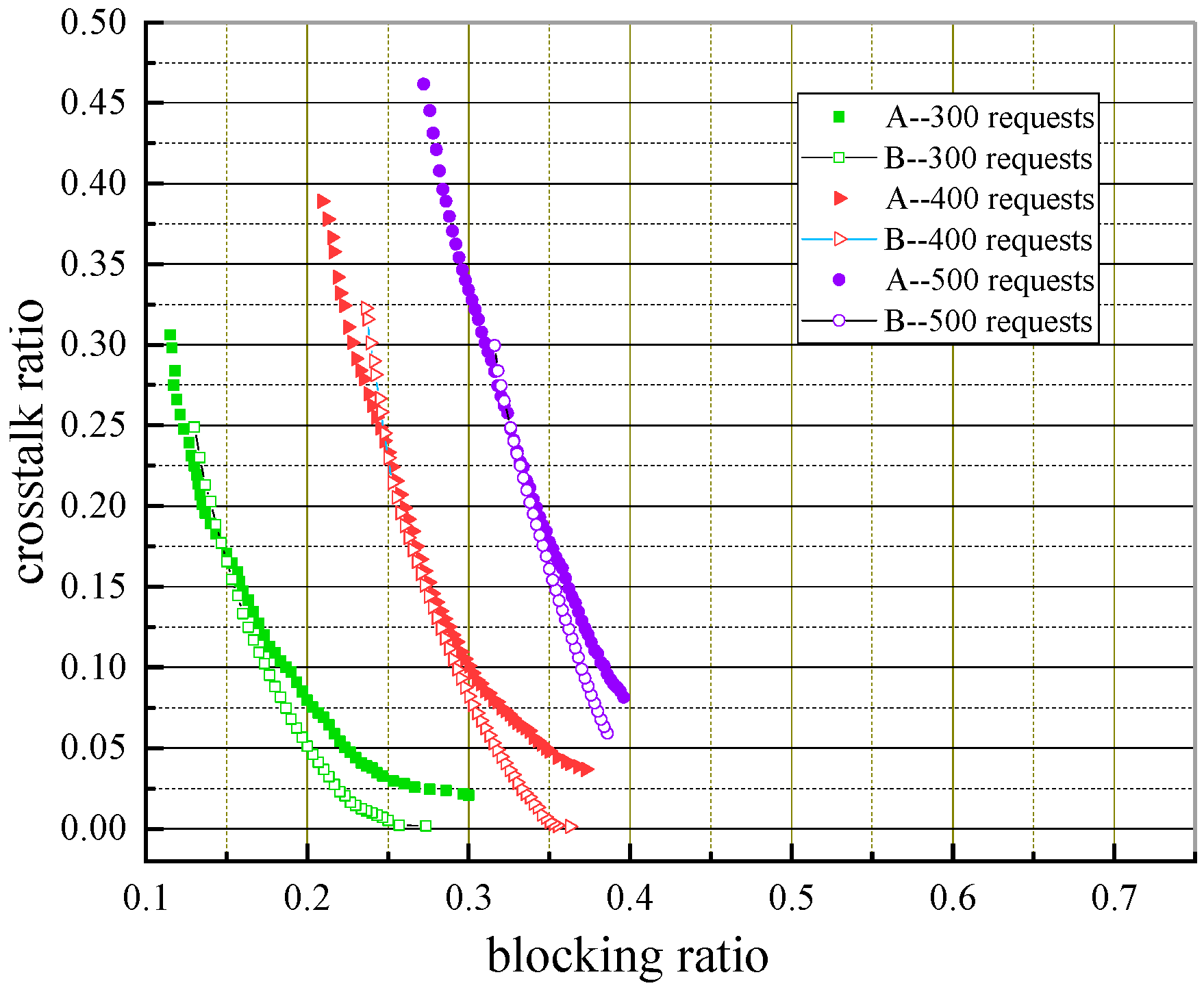{kind=link}