
MFHE: Multi-View Fusion-Based Heterogeneous Information Network Embedding


1
School of Mechanical and Information Engineering, Shandong University, Weihai 264209, China
2
Rushan Big Data Center, Shandong University, Weihai 264500, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2022, 12(16), 8218; https://0-doi-org.brum.beds.ac.uk/10.3390/app12168218
Submission received: 13 July 2022
/
Revised: 15 August 2022
/
Accepted: 16 August 2022
/
Published: 17 August 2022
(This article belongs to the Special Issue Advances in Artificial Intelligence: Machine Learning, Data Mining and Data Sciences)
Abstract
:Depending on the type of information network, information network embedding is classified into homogeneous information network embedding and heterogeneous information network (HIN) embedding. Compared with the homogeneous network, HIN composition is more complex and contains richer semantics. At present, the research on homogeneous information network embedding is relatively mature. However, if the homogeneous information network model is directly applied to HIN, it will cause incomplete information extraction. It is necessary to build a specialized embedding model for HIN. Learning information network embedding based on the meta-path is an effective approach to extracting semantic information. Nevertheless, extracting HIN embedding only from a single view will cause information loss. To solve these problems, we propose a multi-view fusion-based HIN embedding model, called MFHE. MFHE includes four parts: node feature space transformation, subview information extraction, multi-view information fusion, and training. MFHE divides HIN into different subviews based on meta-paths, models the local information accurately in the subviews based on the multi-head attention mechanism, and then fuses subview information through a spatial matrix. In this paper, we consider the relationship between subviews; thus, the MFHE is applicable to complex HIN embedding. Experiments are conducted on ACM and DBLP datasets. Compared with baselines, the experimental results demonstrate that the effectiveness of MFHE and HIN embedding has been improved.
1. Introduction
Information network embedding can be understood from the perspective of vector dimensionality reduction [1]. It transforms the representation of nodes and edges in the network from a high-dimensional and sparse vector space to a low-dimensional and dense vector space. Network embedding can be used for downstream tasks such as node classification [2], clustering [3], prediction [4], and recommendation [5]. According to the type of network, information network embedding can be divided into homogeneous information network embedding and heterogeneous information network (HIN) embedding.
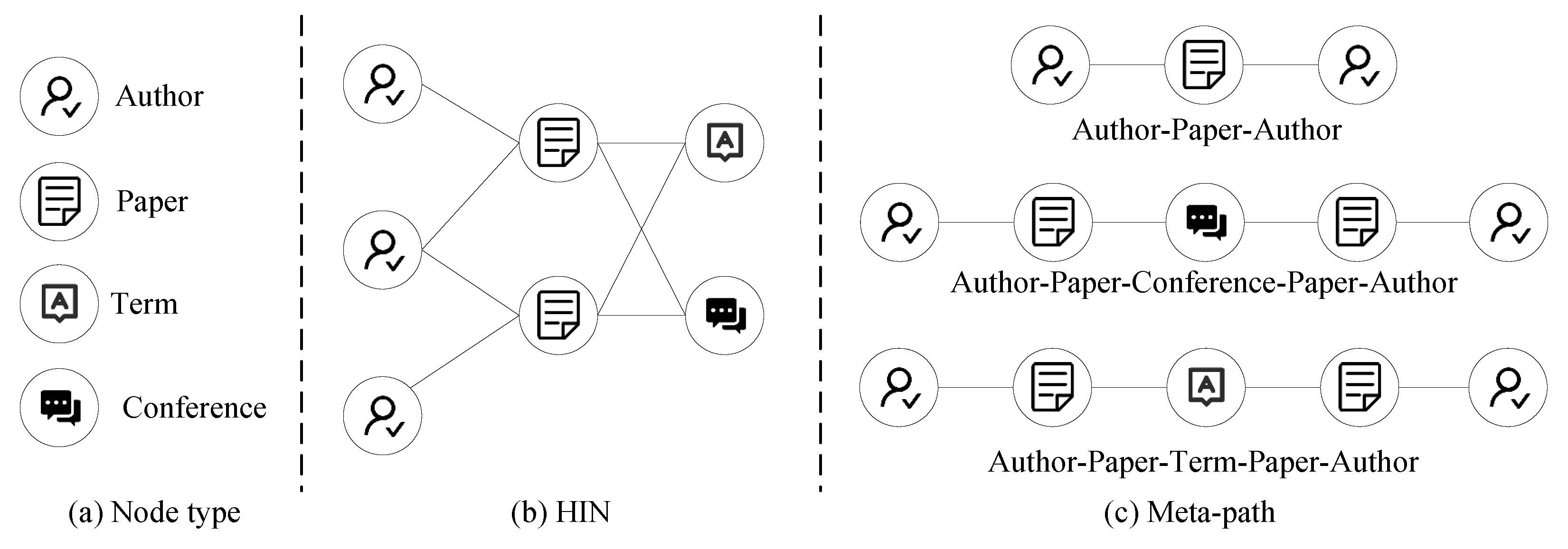
Homogeneous information network embedding, such as DeepWalk, LINE, and other classical models are widely used [6,7,8,9]. Infinitalk [10] learns based on the network topology. SANE [11] and CDAN [12] learn based on the network topology, taking into account the attribute information of nodes. With the advent of the era of big data, data sources are rich and diverse, and various data interactions constitute HIN. For example, paper datasets, social networks [13], and biomedical networks [14] are typical of HIN. As shown in Figure 1, we give an example of HIN for the paper dataset DBLP. The network contains four types of nodes and a variety of connection relationships or meta-paths. It shows that HINs contain richer semantics than homogeneous networks. Some researchers directly apply the homogeneous information network model to HIN, but inevitably encounter the problem of incomplete information extraction. The lack of HIN embedding will straightforwardly affect the performance of downstream tasks. Therefore, we need to consider the heterogeneity of nodes and edges to effectively fuse multiple information in HIN [15].
In recent years, many researchers have conducted in-depth research on HIN embedding [16,17,18,19]. In HIN embedding, meta-path has been proved to be an effective way to represent semantic information. Therefore, many research works extract network features and structure information based on meta-paths. Pathsim [20] introduces meta-path similarity to study the closeness between nodes of the same type in HIN on a symmetric meta-path. To address the problem of difficult meta-path mining and complex manual design, this method can be divided into two categories. One is automatic generate meta-paths, such as MGOHE [21], i.e., HGCN [22], and AutoPath [23]. Another is extracting network information through other methods without using meta-paths, such as RHINE [18], HetSANN [24], and HGT [25]. However, although discarding the meta-path reduces the complexity, it will inevitably result in incomplete information extraction. In comparison, the research on HIN representation based on meta-path learning still accounts for a large proportion.
On the one side, directly applying the homogeneous information network model to HIN leads to incomplete embedding; on the other side, HIN extracted only from a single view is also incomplete. HERec [26] generates sequences of nodes based on the meta-path random walk. It uses a simple linear fusion function, personalized linear fusion function, and personalized nonlinear fusion function to learn node representations, respectively. Then, it integrates them into the matrix decomposition model. For text HIN, Pte [27] divides HIN into three subviews for embedding based on the relationship between word and word, document, and label, respectively. SHINE [28] divides HIN into an emotional network, social network, and data network, learning different information representations of users, respectively, and then fuses embedding. Huang et al. [29] propose a novel robust multi-view clustering method to integrate heterogeneous representations of data. MVGAN [30] designs a hashtag-based multi-view graph attention mechanism to capture the intrinsic interaction across different views. All of the above studies demonstrate that aggregating network information in multiple aspects is more effective. Therefore, we can extract multiple subnetworks or subviews from the HIN, and then fuse them after learning the subview information, respectively.
The contributions of this paper are as follows:
1. We propose a novel MFHE model that includes four parts: node feature space transformation, subview information extraction, multi-view information fusion, and training. HIN extraction is divided into different subviews based on meta-paths, and then the subview information is fused through the spatial matrix. MFHE takes into account the relationship between subviews and is suitable for complex HIN extraction.
2. We conduct experiments on the ACM and DBLP datasets, and compare results with baselines. The experimental results indicate that MFHE model is effective and can improve the embedding representation of HIN.
The remainder of the paper is organized as follows. Section 2 briefly introduce the related work. Section 3 illustrates the definition of the problem. Section 4 describes the specific components of the MFHE model. Section 5 evaluates our model on datasets, compares results with baselines, and proposes the experimental analysis. Finally, we present a comprehensive summary of the whole paper and a prospect for the future research direction in Section 6.
2. Related Work
2.1. Network Embedding
Early embedding learning was based on spectral analysis, representing the network as a low-dimensional representation of the adjacency matrix input model to obtain nodes [31,32]. However, this method does not take into account the information inside the node, and the quality of the learned network embedding is poor. With the development of deep learning, representative models have gradually emerged in the field of network embedding, such as Deepwalk [6] and LINE [7] models. The above two models are inspired by word2Vec [33], a classic model in natural language processing. DeepWalk and LINE models replace the input of word2Vec model with network input from a text corpus. DeepWalk regards nodes as words and random walk paths as sentences, and learns network representation based on random walk strategy. Given the shortcomings of DeepWalk that are not applicable to the weighted network, then the LINE model is proposed. However, LINE focuses too much on the critical characteristics and does not consider the features of the meta-path. Therefore, Grover et al. [8] propose Node2Vec, which combines a depth-first search and breadth-first search to design a more flexible random walk strategy. In addition to the above methods based on the random walk strategy, SDNE [34] designs the autoencoder dimensionality reduction vector representation. GraphGAN [35] applies the idea of GAN to graph representation learning, allowing the generator to fit or estimate the true probability of the connection distribution as much as possible, and the discriminator calculates the possibility of edges between nodes. If considering the network more carefully, we will find that many nodes in the network carry attribute information, such as commodity category, citation text information, etc. Thus, Thomas et al. [36] propose GCN jointly to learn the attributes of vertices and the topology of the graph. GCN first proposes a convolutional approach to fuse graph structure features, providing a whole new perspective. However, GCN only learns the representation of nodes in a given network, and its scalability is poor. Therefore, Hamilton et al. [37] propose GraphSAGE, which represents unknown vertices in the training by using the attribute information of vertices, that is, inductive learning. However, its sampling increases exponentially with the increase in order depth. The number of samples needs to be limited; however, this will result in the loss of some node information. To solve the problem that GCN has the same weight value when fusing neighbor nodes, Velickovic et al. [38] propose a GAT model and design a multi-head attention mechanism. However, the above methods are all designed for homogeneous information network, and cannot be directly used for HIN embedding.
2.2. HIN Embedding
In reality, various types of network data, different sources, and complex relationships constitute HIN. To capture multiple semantic relationships in HIN, a significant amount of research work is devoted to HIN embedding, including research on the node and meta-path aggregation methods, and research on network attribute completion [39]. Metapath2Vec [40] is similar to Deepwalk [6], but used in heterogeneous graphs. It works with a meta-path based random walk strategy to construct heterogeneous neighbourhoods of vertices, and then completes the vertex embedding with the Skip-Gram model. Wang et al. [41] believe that different types of edges in HIN have different weights, and different neighbor nodes of the same type of edges have different weights, so they employ node-level and semantic-level attention to learn the importance of different nodes and meta-paths, respectively. HERec [26] utilises a random walk strategy to generate node sequences based on the meta-path, and then fuses the node representations of the multiple meta-path. HetGNN [42] introduces a random walk strategy with restart, samples strongly correlated heterogeneous neighbors for nodes, and classifies them according to node types. They design two encoding modules to learn the attribute information and types of nodes, respectively, and aggregate the information of nodes. Heco [43] introduces synergistic contrastive learning and view mask mechanisms to synergistically learn node representations from the network architecture and meta-path perspectives. In the aspect of attribute completion, Jin et al. [44] propose HGNN-AC to complete the attribute information of heterogeneous graphs. However, the above methods either ignore the features within the node or only use a single meta-path, and ignore the correlation between views, so there is still room for improvement in semantic retention.
3. Preliminary
3.1. HIN
The constructed HIN is expressed as , where and represent the set of nodes and edges, respectively. Let the node type mapping function and the connection edge type mapping function be , , respectively. represents the set of node types, represents the set of edge types. If the number of object types and relation types of the information network satisfy , then the information network is HIN.
3.2. Meta-Path
Nodes are connected through paths according to different relationships in HIN. Meta-path is a path defined in and describes the relationship between node and node .
3.3. Meta-Path Based Neighbors
Given a node i and a meta-path p, neighbors of the meta-path is defined as a group of nodes connected to the node i through the meta-path p in HIN . In this paper, we refer to , which does not include the node i itself and only includes the first-order neighbor nodes of the target node.
3.4. Subview Based on Meta-Path
Given a meta-path p and a target node i, i.e., . A subview is defined as a heterogeneous information sub-network, which is composed of a group of nodes connected to the node through the meta-path and the node i itself on HIN .
3.5. Multi-View Fusion
The multi-view in this paper refers to the information from multiple perspectives or meta-paths under the same data source. The data contained in different views complement each other and can learn more information than a single view. are the network embeddings from N subviews for the same HIN . After the fusion of multiple subviews, we can obtain the final HIN embedding .
4. The Proposed Model
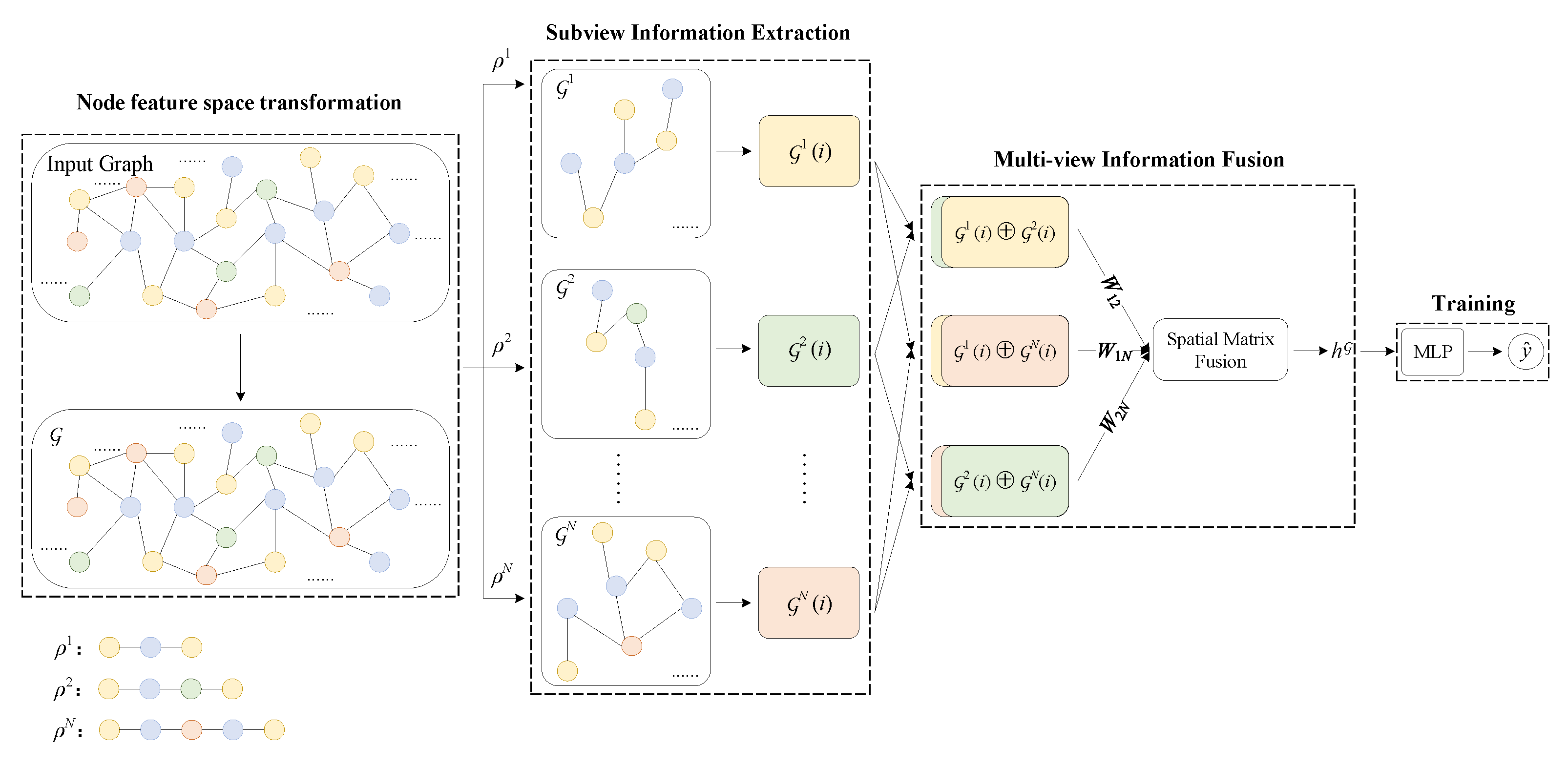
To solve the problems of incomplete HIN information extraction and neglect of the correlation between subviews, this paper proposes a multi-view fusion based HIN embedding model MFHE. As shown in Figure 2, the MFHE framework consists of four parts: node feature space transformation, subview information extraction, multi-view information fusion, and training.
4.1. Node Feature Space Transformation
Since there are many types of nodes in HIN, different types of nodes have different embedding dimensions. To better learn node embedding, we design a transformation matrix for specific node types and represent the node feature vectors in the same and lower dimension feature space. Given the node type , the transformed feature of the node i is expressed . The formula is as follows:
where is the initial feature of the node i, is the node feature transform function, is the vector deviation, and is the activation function.
4.2. Subview Information Extraction
After the node feature space transformation, all node embeddings are in the same dimension feature space. To learn the rich semantic information of HIN, we first extract subview HINs based on different meta-paths and accurately model local information.
Given the meta-path generation rule , construct the subview HIN , where the mapping functions of node and edge types are and .
Taking the ACM dataset as an example, this paper defines two meta-path rules: is a P-A-P meta-path, which extracts paper–author interactions; is a P-S-P meta-path, which extracts paper–subject interactions.
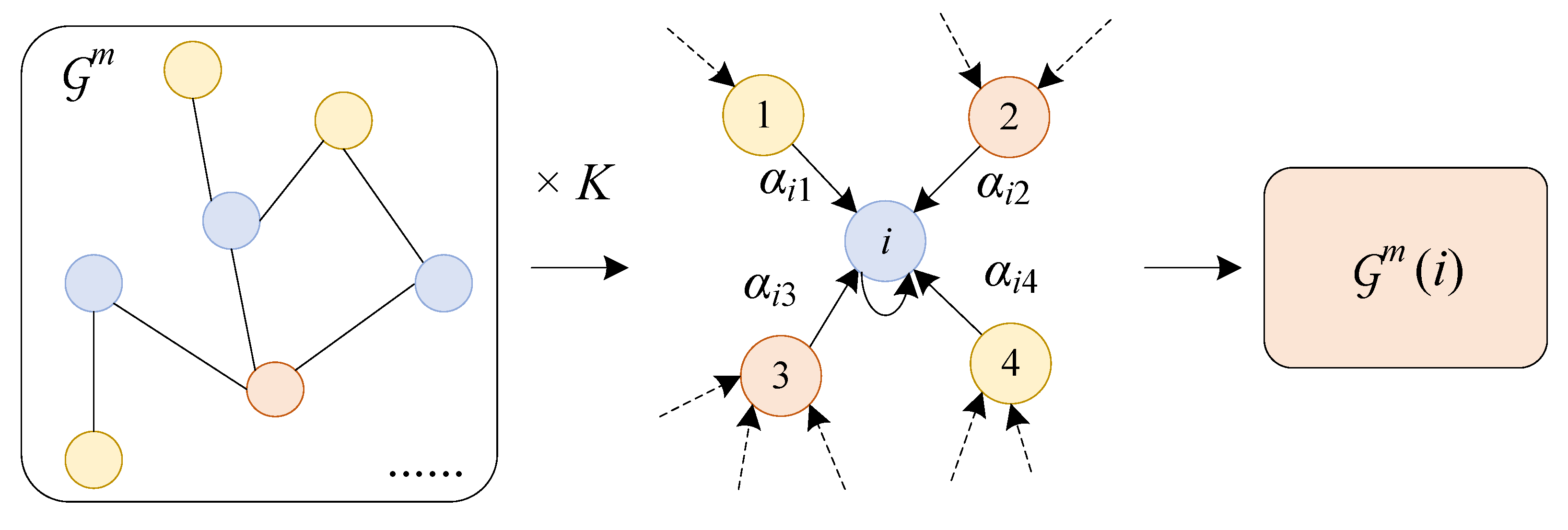
For each subview, input the node information related to the subview according to the meta-path rules. Since the data variance of HIN is generally large, to ensure the effect of the model, we apply the multi-head attention mechanism in the subview. We aggregate the information of nodes on the meta-path and then splice the node embeddings of K times. As shown in Figure 3, the embedding of the node i on the subview is expressed as :
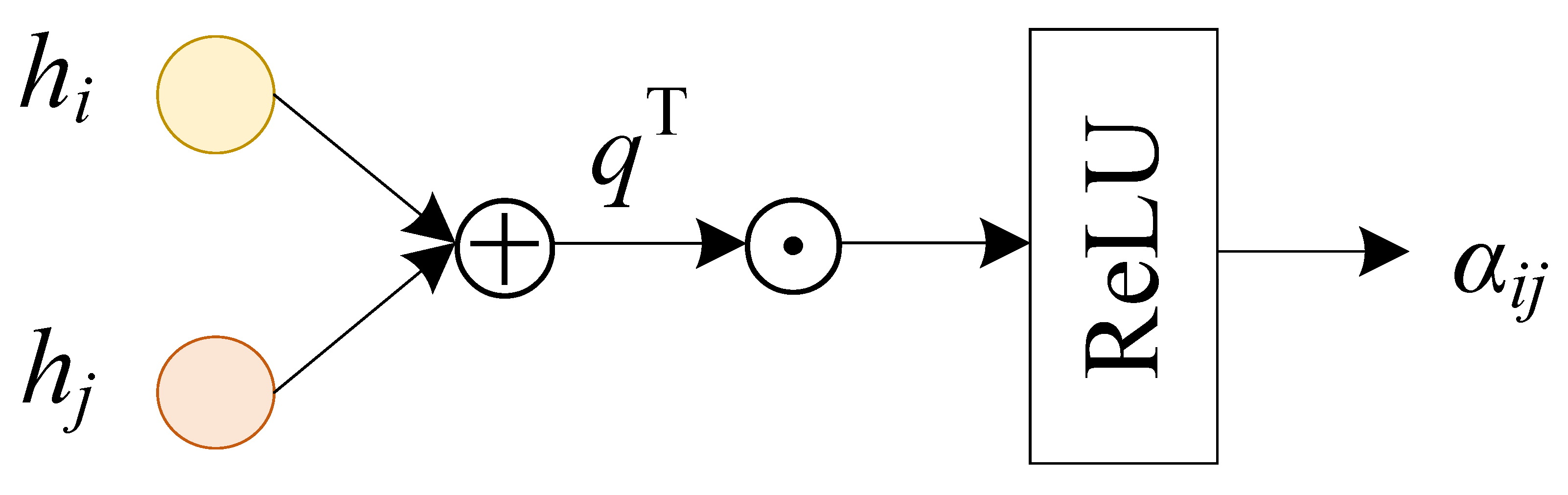
where the attention mechanism of the node is used K times, is the set of neighbor nodes for node i in the subview . is the normalized attention value between the node i and its neighbor node j, and the calculation method is shown in Figure 4, specifically:
where is the attention value between the node i and its neighbor node j in the subview , the activation function uses ReLU, q is the attention vector, represents the connection of the vector, and represents the vector transpose.
4.3. Multi-View Information Fusion
Since the subviews are all divided by the same HIN, the information of each subview is intersecting and complementary. Through the multi-view fusion module to fuse the node information in each subview, we can obtain rich and complete HIN embedding.
For multi-view information fusion, we use spatial matrix fusion. By introducing the weight space matrix W, we can learn the pairwise correlation of the same node among subviews. For a HIN with N subviews, firstly concatenate the embeddings of the node i in subviews and . Then, multiply the concatenated representations with the spatial matrix and sum all subviews. After the multi-view information fusion, the embedding of the node i is represented as :
where is the corresponding value of the subview and in the spatial matrix W, indicating the correlation between subviews and . The weight space matrix W is composed of and is constructed by two-dimensional correlation coefficients:
where, and are the weight matrices of subviews and , respectively, and are the values of row i and column j, and are the mean values of the entire matrices of and , respectively, and calculated as:
is the final embedding of HIN . Then, we can combine different downstream tasks, design different loss functions to optimize the model, and obtain the most suitable heterogeneous graph representation.
4.4. Training
When the downstream task is semi-supervised node classification, the loss function is set as:
where C is the parameter of the classifier, is the set of labeled nodes, and are the labels of labeled nodes and the representation of the model output, respectively.
When the downstream task is unsupervised node clustering, the loss function is set as:
where is the positive sample set and is the negative sample set.
5. Experiment
5.1. Datasets
In this paper, we use the ACM dataset and DBLP dataset [45] to verify the effectiveness of the proposed algorithm. ACM contains 3025 papers, 5835 authors, and 56 subjects. We select two types of meta-paths: P-A-P and P-S-P. DBLP contains 14,328 papers, 4057 authors, 20 conferences, and 8789 terms. We select three types of meta-paths: A-P-A, A-P-C-P-A and A-P-T-P-A. The detailed descriptions of datasets used here are shown in Table 1.
5.2. Comparative Experiment
5.2.1. Baselines
To verify the effect of MFHE on HIN information extraction and aggregation, we use the following algorithms to compare with our algorithm.
DeepWalk [6]: Deepwalk is the first algorithm that applies the learning idea in NLP to network embedding. It samples nodes in the graph by random walk and obtains a sufficient number of node access sequences, and then performs vector learning via the Skip-Gram model. Note that the heterogeneity of HIN is ignored when using DeepWalk.
HERec [26]: HERec generates a node sequence based on the meta-path random walk, which is represented by learning nodes with fusion function, and then integrated into the matrix decomposition model. In this paper, HERec experiments are carried out on all meta-paths.
GraphSAGE [37]: GraphSAGE optimizes the sampling of the whole graph to the sampling of the current neighbor nodes. At the same time, it exploits the node feature information and structure information to learn the embedding based on changes in the neighbor relationship of nodes. In this paper, we transform HIN into multiple homogeneous information networks based meta-paths for GraphSAGE experiments.
GAT [38]: GAT classifies the nodes of the homogeneous information network based on the self-attention mechanism and convolution network. Each node in the graph can assign different attention values according to the feature of neighbor nodes. In this paper, we transform HIN into multiple homogeneous information networks-based meta-paths for GAT experiments.
Metapath2Vec [40]: Metapath2Vec constructs a heterogeneous neighborhood of each vertex based on random walks of meta-paths, and then completes the embedding of the vertices using the Skip-Gram model. Note that Metapath2Vec can only walk based on a single meta-path, and cannot fuse the semantic information of multiple meta-paths. In this paper, Metapath2Vec experiments are performed on all meta-paths.
5.2.2. Experimental Setup
The experimental settings of the algorithms are shown in Table 2. The division of the training set, validation set, and test set of datasets is shown in Table 3. Models based on random walk, such as DeepWalk, HERec, and Metapath2Vec, have the random walk window of 5, the walk length of 100, the number of walks of 40, and the number of negative samples of 5.
5.3. Experimental Results and Analysis
5.3.1. Node Classification Experiment
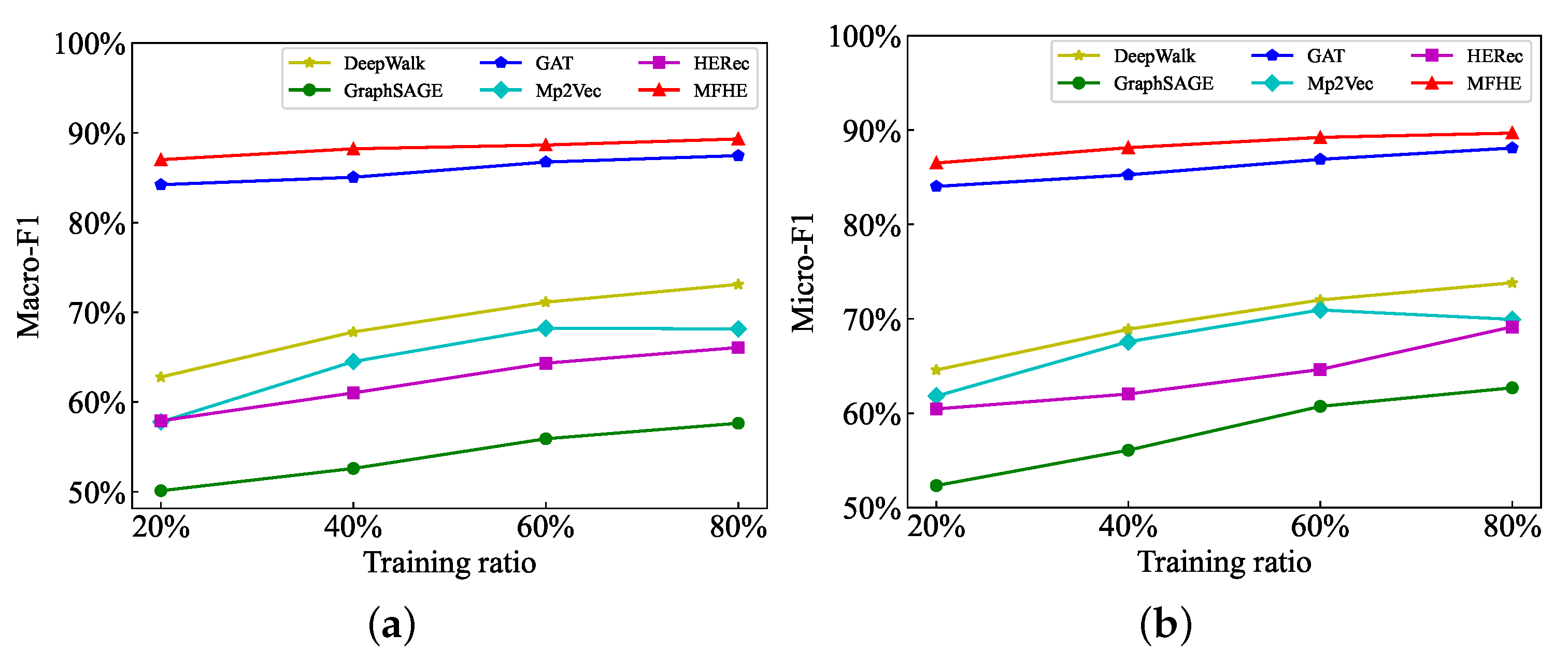
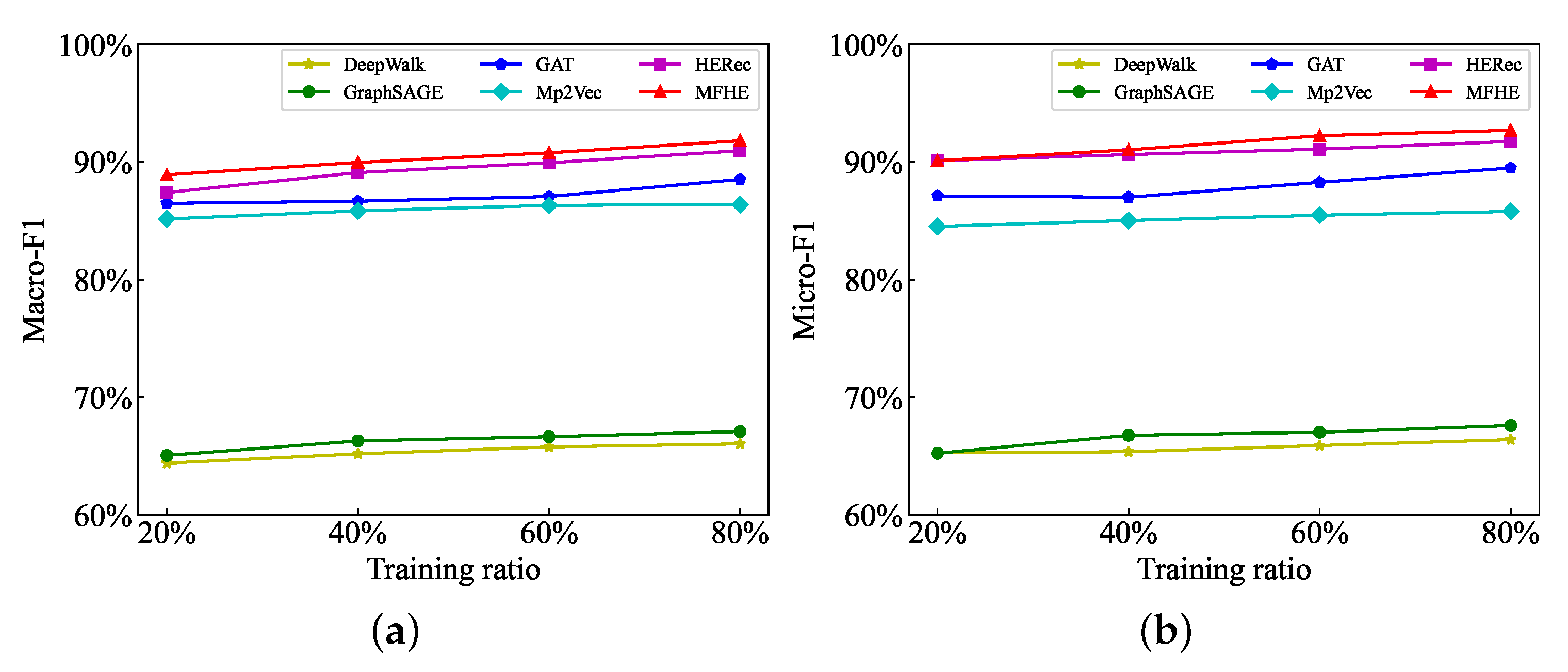
In the task, we evaluate the node classification effect with Macro-F1 and Micro-F1. KNN algorithm is used for node classification experiments. The results of node classification are shown in Table 4. All experimental results are the average values obtained after five experiments on each model. Figure 5 and Figure 6 more intuitively show the advantages of MFHE in the node classification task.
By observing the experimental results, we have the following findings:
- The node classification results of MFHE on ACM and DBLP datasets are better than all baselines, with a 1.72% and 0.9% improvement in classification performance, respectively.
- On the ACM dataset, MFHE performs best, followed by GAT algorithm. DeepWalk, Metapath2Vec, HERec, and GraphSAGE perform worse in turn. GAT and MFHE consider the influence of neighbor nodes in the view of information extraction stage and use the multi-head attention mechanism to calculate the normalized attention value between nodes. However, MFHE introduces multi-view information fusion compared with GAT, and GAT directly learns the node representation on the graph, without considering the weight information of each subview.
- On the DBLP dataset, MFHE performance is also improved. Compared to the effect on the ACM dataset, the node classification performance of HERec is significantly improved, even better than GAT. The reason is that the meta-path A-P-C-P-A in subviews is more important in DBLP. And HERec is the best result of experimental records on all meta-paths. It is equivalent to giving the maximum weight to A-P-C-P-A in the settings, while the same weight in GAT does not extract the most important information. At this time, MFHE calculates weights when considering correlations between subviews, extracting the significant and complete HIN embedding, and hence has an improved classification of the DBLP dataset.
5.3.2. Node Clustering Experiment
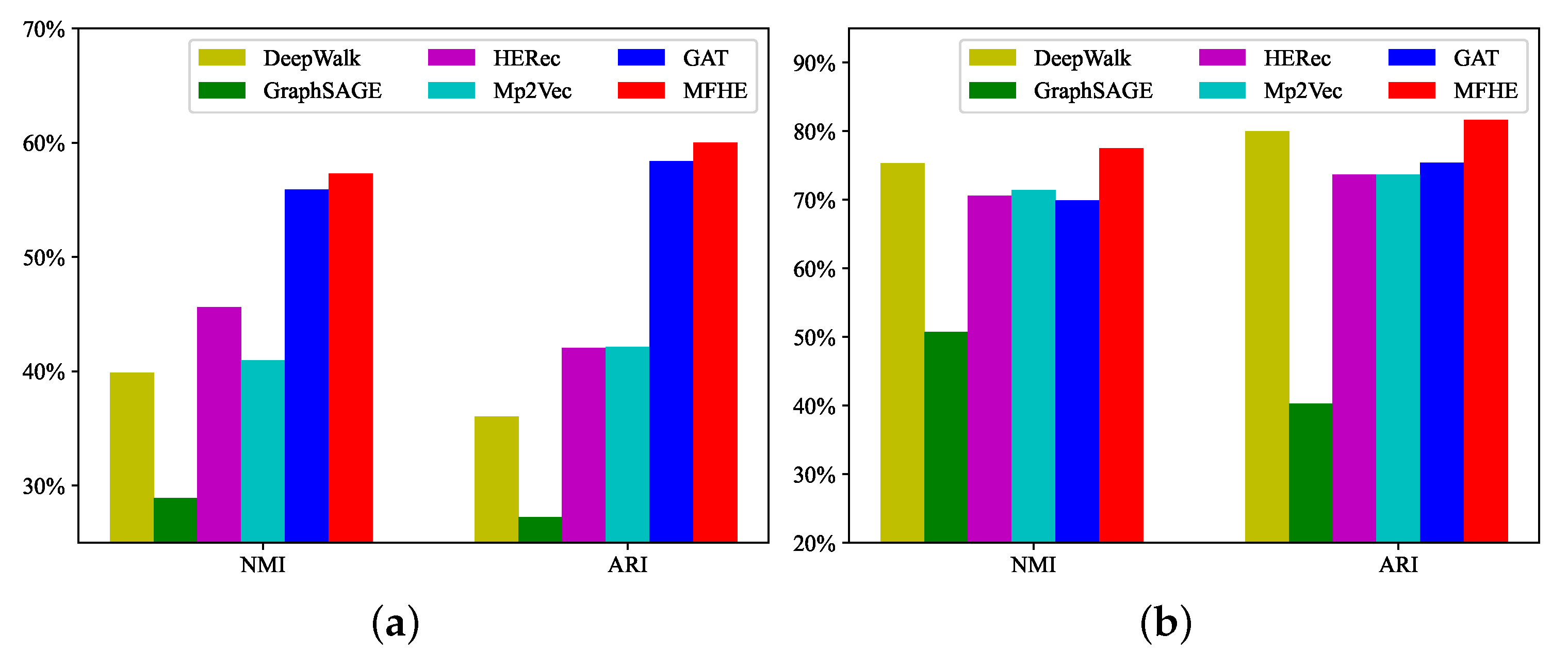
In the task, we evaluate the node clustering effect with NMI and ARI. KMeans algorithm is used for node clustering experiments. The results of node clustering are shown in Table 5. All experimental results are the average values obtained after five experiments on each model. Figure 7 more intuitively show the advantages of MFHE in the node clustering task.
By observing the experimental results, we have the following findings:
- MFHE performs best on ACM and DBLP datasets for node clustering, with 1.34% and 1.97% higher clustering performance, respectively.
- On the ACM dataset, MFHE clusters best, followed by GAT algorithm, and GraphSAGE is the least effective. Both GraphSAGE and GAT convert HIN into multiple homogeneous networks experiments. However, GraphSAGE cannot capture the different weights between nodes and nodes in the aggregation process. GAT solves this problem based on a self-attention mechanism. Therefore, although both experiments are conducted on homogeneous networks, GAT algorithm outperforms GraphSAGE. MFHE, similar to GAT, introduces the multi-head attention mechanism in the extraction of subview information and also captures the inter-node weights. Thus, it apparently surpasses GraphSAGE. In addition, due to the introduction of the multi-view fusion module, node clustering is improved over GAT.
- On the DBLP dataset, MFHE shows the best performance, followed by the DeepWalk algorithm, with smaller differences in the effectiveness of GAT, Metapath2vec, and HERec clustering, and GraphSAGE works the worst. As with the node classification task, meta-path A-P-C-P-A in subviews has the greatest weight in DBLP. This contributes to most baselines with results above 70%. In spite of this, MFHE still outperforms other algorithms, which also demonstrates the importance of considering the correlation between subviews.
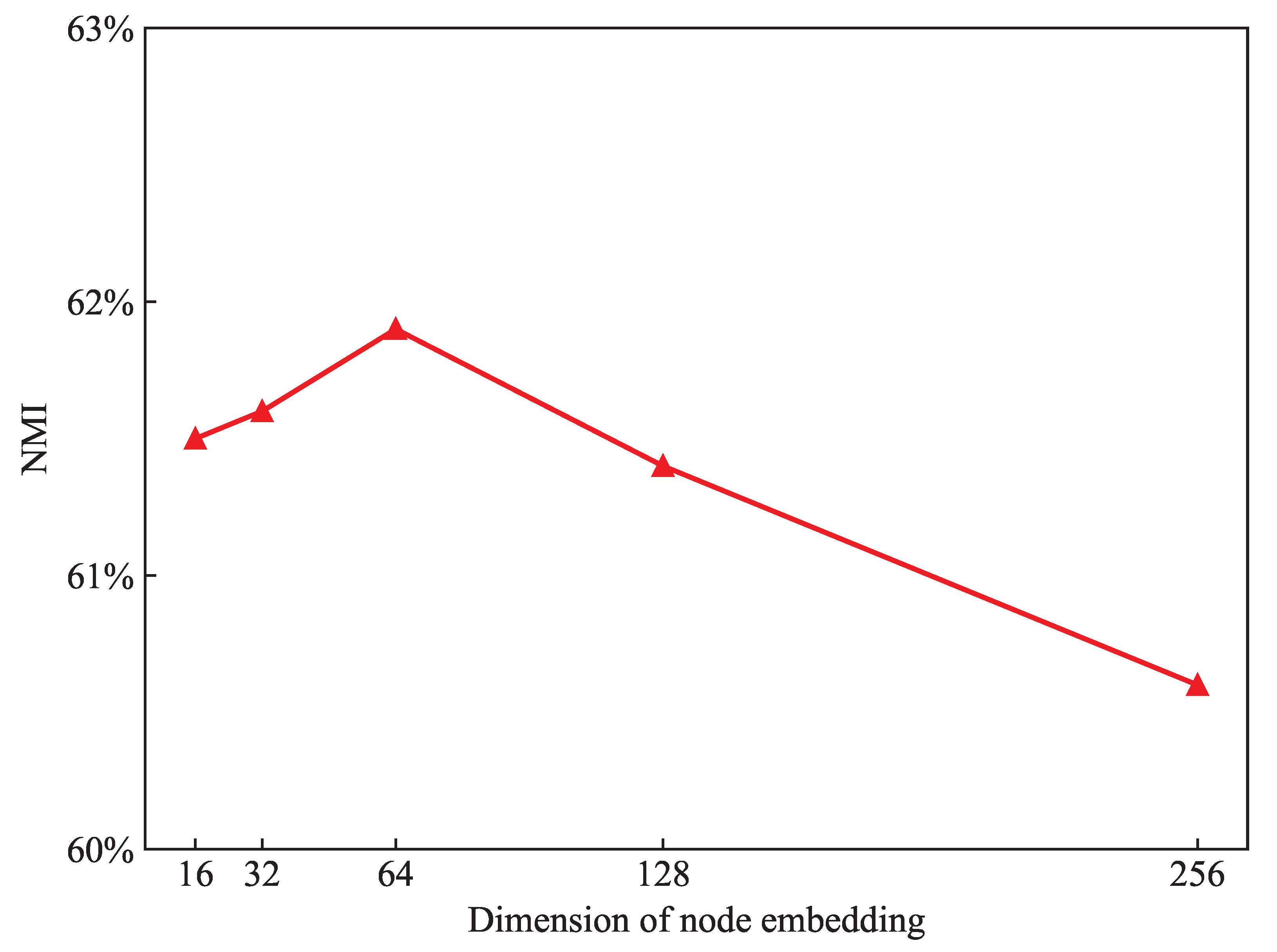
5.3.3. Node Embedding Dimension Experiment
To select the node dimension with the best performance for MFHE, we aggregate the node representation dimensions on 16, 32, 64, 128, and 256, respectively. The extracted HIN embedding results are assessed by NMI. Figure 8 demonstrates that 64 dimensions have the best performance on MFHE.
6. Summary and Future Work
In this paper, we propose a multi-view fusion-based HIN embedding model MFHE. The model consists of four parts: node feature space transformation, subview information extraction, multi-view information fusion, and training. We adopt multi-head attention mechanism and spatial matrix fusion to solve the problems of incomplete HIN information extraction and the neglect of correlation between subviews. MFHE performs node classification and node clustering tasks on ACM and DBLP datasets, which is superior to all baselines. In addition, low-dimensional models generalise better when labelled data is lacking. Thus, we also conducted node embedding dimension experiment to determine the 64 dimensions best suited. The results indicate that MFHE has a certain improvement on HIN embedding.
In future work, we will consider designing various attention mechanisms to extract subview information separately for a more comprehensive learning of embeddings. We will also try a variety of multi-view fusion functions and an in-depth analysis of the correlation between the subviews.
Author Contributions
Conceptualization, T.L.; methodology, T.L.; software, T.L.; validation, T.L.; formal analysis, T.L.; writing—original draft preparation, T.L.; writing—review and editing, T.L.; supervision, J.Y.; funding acquisition, J.Y.; resources, Q.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under Grant 61971268.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We thank the National Natural Science Foundation of China for funding our work, grant number 61971268.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Chen, H.; Bryan, P.; Al-Rfou, R.; Skiena, S. A Tutorial on Network Embeddings. arXiv 2018, arXiv:1808.02590. [Google Scholar]
- Shen, X.; Dai, Q.; Mao, S.; Chung, F.L.; Choi, K.S. Network Together: Node Classification via Cross-Network Deep Network Embedding. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1935–1948. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Pi, D.; Lin, Y.; Cui, L. DNC: A Deep Neural Network-based Clustering-oriented Network Embedding Algorithm. J. Netw. Comput. Appl. 2021, 173, 102854. [Google Scholar] [CrossRef]
- Chen, X.; Kang, B.; Lijffijt, J.; De Bie, T. ALPINE: Active Link Prediction Using Network Embedding. Appl. Sci. 2021, 11, 5043. [Google Scholar] [CrossRef]
- Zhu, D.; Cui, P.; Zhang, Z.; Pei, J.; Zhu, W. High-Order Proximity Preserved Embedding for Dynamic Networks. IEEE Trans. Knowl. Data Eng. 2018, 30, 2134–2144. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar] [CrossRef]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale Information Network Embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. Node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar] [CrossRef]
- Tu, C.; Zeng, X.; Wang, H.; Zhang, Z.; Liu, Z.; Sun, M.; Zhang, B.; Lin, L. A Unified Framework for Community Detection and Network Representation Learning. IEEE Trans. Knowl. Data Eng. 2019, 31, 1051–1065. [Google Scholar] [CrossRef]
- Chanpuriya, S.; Musco, C. Infinitewalk: Deep Network Embeddings as Laplacian Embeddings with A Nonlinearity. In Proceedings of the the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Electr Network, Virtual Event, 6–10 July 2020; pp. 1325–1333. [Google Scholar] [CrossRef]
- Liu, W.; Liu, Z.; Yu, F.; Chen, P.y.; Suzumura, T.; Hu, G. A Scalable Attribute-Aware Network Embedding System. Neurocomputing 2019, 339, 279–291. [Google Scholar] [CrossRef]
- Zhou, T. Progresses and Challenges in Link Prediction. IScience 2021, 24, 103217. [Google Scholar] [CrossRef]
- Su, C.; Hu, Z.; Xie, X. Heterogeneous Social Recommendation Model With Network Embedding. IEEE Access 2020, 8, 209483–209494. [Google Scholar] [CrossRef]
- Davis, A.P.; Grondin, C.J.; Johnson, R.J.; Sciaky, D.; King, B.L.; McMorran, R.; Wiegers, J.; Wiegers, T.C.; Mattingly, C.J. The Comparative Toxicogenomics Database: Update 2017. Nucleic Acids Res. 2017, 45, 972–978. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, C. HINE: Heterogeneous Information Network Embedding. In Proceedings of the 22nd International Conference on Database Systems for Advanced Applications, Suzhou, China, 27–30 March 2017; pp. 180–195. [Google Scholar] [CrossRef]
- Wang, W.; Liu, J.; Tang, T.; Tuarob, S.; Xia, F.; Gong, Z.; King, I. Attributed Collaboration Network Embedding for Academic Relationship Mining. ACM Trans. Web 2021, 15, 4. [Google Scholar] [CrossRef]
- Wang, X.; Lu, Y.; Shi, C.; Wang, R.; Cui, P.; Mou, S. Dynamic Heterogeneous Information Network Embedding With Meta-Path Based Proximity. IEEE Trans. Knowl. Data Eng. 2022, 34, 1117–1132. [Google Scholar] [CrossRef]
- Shi, C.; Lu, Y.; Hu, L.; Liu, Z.; Ma, H. RHINE: Relation Structure-aware Heterogeneous Information Network Embedding. IEEE Trans. Knowl. Data Eng. 2022, 34, 433–447. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, H.; Li, J.; Zhang, Q.; Tang, Y. CKGAT: Collaborative Knowledge-Aware Graph Attention Network for Top-N Recommendation. Appl. Sci. 2022, 12, 1669. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. Pathsim: Meta Path-Based Top-K Similarity Search in Heterogeneous Information Network. In Proceedings of the VLDB Endowment, New York, NY, USA, 29 August–3 September 2011; pp. 992–1003. [Google Scholar] [CrossRef]
- Liang, T.; Liu, J. Meta-Path Generation Online for Heterogeneous Network Embedding. In Proceedings of the 2020 International Joint Conference on Neural Networks, Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Yang, Y.; Guan, Z.; Li, J.; Zhao, W.; Cui, J.; Wang, Q. Interpretable and Efficient Heterogeneous Graph Convolutional Network. IEEE Trans. Knowl. Data Eng. 2021, 1–14. [Google Scholar] [CrossRef]
- Yang, C.; Liu, M.; He, F.; Zhang, X.; Peng, J.; Han, J. Similarity Modeling on Heterogeneous Networks via Automatic Path Discovery. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Dublin, Ireland, 13–17 September 2019; pp. 37–54. [Google Scholar] [CrossRef]
- Hong, H.; Guo, H.; Lin, Y.; Yang, X.; Li, Z.; Ye, J. An Attention-Based Graph Neural Network for Heterogeneous Structural ALearning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 4132–4139. [Google Scholar] [CrossRef]
- Hu, Z.; Dong, Y.; Wang, K.; Sun, Y. Heterogeneous Graph Transformer. In Proceedings of the 29th World Wide Web Conference, New York, NY, USA, 20–24 April 2020; pp. 2704–2710. [Google Scholar] [CrossRef]
- Shi, C.; Hu, B.; Zhao, W.X.; Yu, P.S. Heterogeneous Information Network Embedding for Recommendation. IEEE Trans. Knowl. Data Eng. 2019, 31, 357–370. [Google Scholar] [CrossRef]
- Tang, J.; Qu, M.; Mei, Q. PTE: Predictive Text Embedding through Large-Scale Heterogeneous Text Networks. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1165–1174. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Hou, M.; Xie, X.; Guo, M.; Liu, Q. Shine: Signed Heterogeneous Information Network Embedding for Sentiment Link Prediction. In Proceedings of the 11th ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 592–600. [Google Scholar] [CrossRef]
- Huang, S.; Ren, Y.; Xu, Z. Robust Multi-View Data Clustering with Multi-View Capped-Norm K-means. Neurocomputing 2018, 311, 197–208. [Google Scholar] [CrossRef]
- Cui, W.; Du, J.; Wang, D.; Kou, F.; Xue, Z. MVGAN: Multi-View Graph Attention Network for Social Event Detection. ACM Trans. Intell. Syst. Technol. 2021, 12, 1–24. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef]
- Brodhead, K. Link Prediction Schemes Contra Weisfeiler-Leman Models. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 1–9. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar] [CrossRef]
- Wang, D.; Cui, P.; Zhu, W. Structural Deep Network Embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar] [CrossRef]
- Wang, H.; Wang, J.; Wang, J.; Zhao, M.; Zhang, W.; Zhang, F.; Xie, X.; Guo, M. GraphGAN: Graph Representation Learning with Generative Adversarial Nets. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 2508–2515. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar] [CrossRef]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar] [CrossRef]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–12. [Google Scholar] [CrossRef]
- Xie, Y.; Yu, B.; Lv, S.; Zhang, C.; Wang, G.; Gong, M. A Survey on Heterogeneous Network Representation Learning. Pattern Recogn. 2021, 116, 1–14. [Google Scholar] [CrossRef]
- Dong, Y.; Chawla, N.V.; Swami, A. Metapath2vec: Scalable Representation Learning for Heterogeneous Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar] [CrossRef]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Cui, P.; Yu, P.; Ye, Y. Heterogeneous Graph Attention Network. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar] [CrossRef]
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous Graph Neural Network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 4–8 August 2019; pp. 793–803. [Google Scholar] [CrossRef]
- Wang, X.; Liu, N.; Han, H.; Shi, C. Self-Supervised Heterogeneous Graph Neural Network with Co-contrastive Learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 14–18 August 2021; pp. 1726–1736. [Google Scholar] [CrossRef]
- Jin, D.; Huo, C.; Liang, C.; Yang, L. Heterogeneous Graph Neural Network via Attribute Completion. In Proceedings of the 30th World Wide Web Conference, Electr Network, Virtual Event, 19–23 April 2021; pp. 391–400. [Google Scholar] [CrossRef]
- The Source Code of Heterogeneous Graph Attention Network. Available online: https://github.com/Jhy1993/HAN (accessed on 11 July 2022).
Figure 1.
HIN example of paper dataset DBLP. (a) Four types of nodes (i.e., Author, Paper, Term, Conference); (b) HIN; (c) Meta-paths (i.e., Author-Paper-Author, Author-Paper-Conference-Paper-Author and Author-Paper-Term-Paper-Author).
Figure 1.
HIN example of paper dataset DBLP. (a) Four types of nodes (i.e., Author, Paper, Term, Conference); (b) HIN; (c) Meta-paths (i.e., Author-Paper-Author, Author-Paper-Conference-Paper-Author and Author-Paper-Term-Paper-Author).

Figure 2.
The framework of MFHE.

Figure 3.
Subview information extraction.

Figure 4.
Calculation of normalized attention value .

Figure 5.
Node classification results on the ACM dataset. (a) Macro-F1. (b) Micro-F1.

Figure 6.
Node classification results on the DBLP dataset. (a) Macro-F1. (b) Micro-F1.

Figure 7.
Node clustering results on the ACM and DBLP datasets. (a) ACM. (b) DBLP.

Figure 8.
Node embedding dimension.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Statistics of the datasets.
| Type | ACM | DBLP |
|---|---|---|
| Node | Paper-P: 3025 Author-A: 5835 Subject-S: 56 | Paper-P: 14328 Author-A: 4057 Conf-C: 20 Term-T: 8789 |
| Edge | P-A: 9744 P-S: 3025 | P-A: 19645 P-C: 14328 P-T: 88420 |
| Meta-path | P-A-P P-S-P | A-P-A A-P-C-P-A A-P-T-P-A |
Table 2.
Experiment parameter setting.
| Parameters | Value |
|---|---|
| Optimizer | Adam |
| Learning rate | 0.005 |
| Regularization | 0.001 |
| Dimension of node | 64 |
| Dimension of q | 128 |
| Attention head K | 8 |
| Dropout | 0.6 |
| Early stop | 100 |
Table 3.
The division of datasets.
| Type | ACM | DBLP |
|---|---|---|
| Training | 600 | 800 |
| Validation | 300 | 400 |
| Test | 2125 | 2857 |
Table 4.
Results of the node classification task (%).
| Datasets | Metrics | Training | DeepWalk | HERec | GraphSAGE | GAT | Mp2Vec | MFHE |
|---|---|---|---|---|---|---|---|---|
| ACM | Ma-F1 | 20 | 62.79 | 57.91 | 50.12 | 84.22 | 57.78 | 87.01 |
| 40 | 67.81 | 61.02 | 52.6 | 85.05 | 64.51 | 88.22 | ||
| 60 | 71.13 | 64.33 | 55.91 | 86.74 | 68.23 | 88.64 | ||
| 80 | 73.11 | 66.08 | 57.64 | 87.46 | 68.15 | 89.32 | ||
| Mi-F1 | 20 | 64.58 | 60.45 | 52.33 | 84.03 | 61.81 | 86.51 | |
| 40 | 68.89 | 62.03 | 56.08 | 85.26 | 67.57 | 88.14 | ||
| 60 | 72 | 64.63 | 60.72 | 86.9 | 70.94 | 89.23 | ||
| 80 | 73.82 | 69.15 | 62.69 | 88.1 | 69.94 | 89.68 | ||
| DBLP | Ma-F1 | 20 | 64.39 | 87.41 | 65.05 | 86.49 | 85.16 | 88.92 |
| 40 | 65.18 | 89.11 | 66.28 | 86.67 | 85.85 | 89.97 | ||
| 60 | 65.77 | 89.94 | 66.64 | 87.07 | 86.32 | 90.79 | ||
| 80 | 66.03 | 90.97 | 67.08 | 88.53 | 86.39 | 91.82 | ||
| Mi-F1 | 20 | 65.27 | 90.12 | 65.23 | 87.12 | 84.53 | 90.12 | |
| 40 | 65.36 | 90.64 | 66.76 | 87.01 | 85.03 | 91.04 | ||
| 60 | 65.89 | 91.1 | 67.02 | 88.28 | 85.48 | 92.25 | ||
| 80 | 66.39 | 91.76 | 67.59 | 89.5 | 85.8 | 92.71 |
Table 5.
Results of the node clustering task (%).
| Datasets | Metrics | DeepWalk | HERec | GraphSAGE | GAT | Mp2Vec | MFHE |
|---|---|---|---|---|---|---|---|
| ACM | NMI | 39.85 | 45.61 | 28.91 | 55.88 | 40.96 | 57.31 |
| ARI | 36.04 | 42.03 | 27.23 | 58.37 | 42.12 | 60.02 | |
| DBLP | NMI | 75.3 | 70.57 | 50.7 | 69.89 | 71.41 | 77.52 |
| ARI | 79.96 | 73.64 | 40.25 | 75.42 | 73.65 | 81.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, T.; Yin, J.; Qin, Q. MFHE: Multi-View Fusion-Based Heterogeneous Information Network Embedding. Appl. Sci. 2022, 12, 8218. https://0-doi-org.brum.beds.ac.uk/10.3390/app12168218
AMA Style
Liu T, Yin J, Qin Q. MFHE: Multi-View Fusion-Based Heterogeneous Information Network Embedding. Applied Sciences. 2022; 12(16):8218. https://0-doi-org.brum.beds.ac.uk/10.3390/app12168218
Chicago/Turabian StyleLiu, Tingting, Jian Yin, and Qingfeng Qin. 2022. "MFHE: Multi-View Fusion-Based Heterogeneous Information Network Embedding" Applied Sciences 12, no. 16: 8218. https://0-doi-org.brum.beds.ac.uk/10.3390/app12168218
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.