
Research on Chinese Medical Entity Recognition Based on Multi-Neural Network Fusion and Improved Tri-Training Algorithm

1
Zhengzhou Institute of Science and Technology, Zhengzhou 450001, China
2
Henan Grain Big Data Analysis and Application Engineering Research Center, Henan University of Technology, Zhengzhou 450001, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2022, 12(17), 8539; https://0-doi-org.brum.beds.ac.uk/10.3390/app12178539
Submission received: 8 August 2022
/
Revised: 23 August 2022
/
Accepted: 23 August 2022
/
Published: 26 August 2022
(This article belongs to the Special Issue Natural Language Processing (NLP) and Applications)
Abstract
:Chinese medical texts contain a large number of medically named entities. Automatic recognition of these medical entities from medical texts is the key to developing medical informatics. In the field of Chinese medical information extraction, annotated Chinese medical text data are very few. In the named entity recognition task, there is insufficient labeled data, which leads to low model recognition performance. Therefore, this paper proposes a Chinese medical entity recognition model based on multi-neural network fusion and the improved Tri-Training algorithm. The model performs semi-supervised learning by improving the Tri-Training algorithm. According to the characteristics of the medical entity recognition task and medical data, the method in this paper is improved in terms of the division of the initial sub-training set, the construction of the base classifier, and the integration of the learning voting method. In addition, this paper also proposes a multi-neural network fusion entity recognition model for base classifier construction. The model learns feature information jointly by combining Iterated Dilated Convolutional Neural Network (IDCNN) and BiLSTM. Through experimental verification, the model proposed in this paper outperforms other models and improves the performance of the Chinese medical entity recognition model by incorporating and improving the semi-supervised learning algorithm.
1. Introduction
In recent years, with the widespread promotion of medical information systems in China’s hospitals, a large amount of electronic medical text data has been generated as a result [1]. It is especially important to identify and integrate the huge amount of medical text data efficiently and accurately. This is of great practical significance for building professional medical knowledge graphs, conducting medical knowledge reasoning, and providing accurate medical services [2]. As medical entities are important carriers of medical information, efficient and accurate identification of the entities contained in medical texts is the focus of the research [3].
For the task of Chinese medical entity recognition, one of the most important problems encountered so far is the lack of labeling data. The tagged data can be obtained by processing the Chinese medical text. First, the Chinese medical text needs to be desensitized to remove some private information. Then, the medical text needs to be annotated. The medical field is a highly specialized field. Marking of medical texts requires professional medical staff after uniform training and obtaining the appropriate standards [4,5]. However, the work intensity of medical personnel is relatively high, and the annotation of medical data consumes a lot of resources. This increases the difficulty of medical data annotation, so it causes the problem of insufficient marked medical text data. In Chinese medical entity recognition tasks, the problem of low model recognition performance due to insufficient annotation data can occur, which seriously hinders the development of Chinese medical entity recognition.
To address the problem of poor model recognition due to insufficient labeled data in Chinese medical entity recognition tasks, this paper proposes a Chinese medical entity recognition model based on multi-neural network fusion and the improved Tri-Training algorithm. The model performs semi-supervised learning via the Tri-Training algorithm, which primarily uses a large unlabeled corpus to augment the labeled dataset to train a medical entity recognition model with superior performance. In addition, the BERT-IDCNN-BiLSTM-CRF (BIBC) model is proposed in this paper as a base classifier for entity recognition. The BIBC model performs entity recognition by fusing multiple neural networks, adding an IDCNN layer to the classical BiLSTM-CRF to focus more on the local information of the text. Further, the model uses the pre-trained model BERT to better represent the semantic information. However, during the training process, if the initial base classifier is mislabeled, the error will gradually amplify, causing error accumulation. When the error intensifies, the performance of the semi-supervised learning model also decreases. In order to reduce this error rate, this paper improves the Tri-Training algorithm in terms of the division of the initial sub-training set, the network model selection of the base classifier, and the voting method of ensemble learning according to the characteristics of the Chinese medical entity recognition task. Comparative experiments are conducted to verify the effects of the introduction of semi-supervised learning and the improvement of the Tri-Training algorithm on the model performance.
2. Related Work
Medical entity recognition has always been a research hotspot. More and more researchers have applied advanced models and methods to medical entity recognition and achieved good results. Among them, the research related to medical entity recognition in English is early. Competitions related to medical entity recognition in English also appear in some conferences, thus providing researchers with some needed data as well as communication opportunities. For example, the representative English-language conference I2B2 [6]. At present, there are also some meetings to evaluate the research on the recognition of Chinese medical entities, such as the annual CCKS conference [7] and the CHIP conference [8]. There are tasks related to Chinese medical information and provide some labeled data. These successful conferences will not only promote the research on medical entity recognition but also produce many new methods. The current research methods are based on unsupervised learning [9], supervised learning [10], and semi-supervised learning [11].
The method of medical entity recognition based on unsupervised learning is an entity recognition method based on domain correlation. With the help of domain knowledge, entity recognition is realized by using document frequency and word frequency as statistics. Roberto and Paola [12] proposed an entity recognition method based on domain relevance and considered the word frequency distribution and document distribution characteristics of candidate entities in the corpus to construct a relevance function so as to determine domain entities from the candidate entity set. Dong et al. [13] made full use of the linguistic and statistical features of entities and proposed a feature extraction method for entity recognition based on short text semantic distance metrics. This method represents the distribution of entities through the context information of entities in the corpus and integrates entity semantic information to obtain better feature expression.
Medical entity recognition based on supervised learning is the most studied method and can be divided into dictionary and rule-based methods, machine learning-based methods, and deep learning-based methods. Although the dictionary and rule-based methods are simple, they can only be used for specific data or specific fields due to their poor generalization and migration [14]. Machine learning-based approaches usually use various statistical models and algorithms for entity extraction. However, this approach is highly dependent on feature engineering, which is not only time-consuming but also requires extensive knowledge of the English medical field [15]. Unlike previous methods that require a lot of labor, deep learning-based methods use neural networks to extract features automatically. Various neural network model frameworks have achieved state-of-the-art performances on multiple English medical-related datasets [16].
Building models based on convolutional neural networks (CNN) [17] and cyclic neural networks (RNN) [18,19] are the most widely used methods in the field of deep learning. One of the most commonly used models for named entity recognition is the RNN variant long short-term memory (LSTM) [20], especially the bidirectional long short-term memory (BiLSTM). BiLSTM can extract the contextual feature information of the input data. The model can achieve better performance, so it has become a commonly used network model in the current named entity recognition task. For example, Hao Wei et al. [21] proposed a BiLSTM-CRF model fused with an attention mechanism. The model first uses BiLSTM to obtain the complete contextual feature information in the text and at the same time, adds an attention mechanism to the BiLSTM model to improve its vector representation, and finally, combined with the CRF layer effectively, the model achieved good performance on the JNLPBA corpus, obtaining an F1 value of 73.5%. Luka et al. [22] used transfer learning to bootstrap a neural network by feeding pre-trained word embedding to a secondary task on annotated electronic records, which achieved an F1-score of 94.7% on the I2B22009 Medical Information Extraction Challenge, 4.3% higher than the traditional method that initially won the challenge.
The performance of models based on deep learning methods depends, to a large extent, on the number and quality of samples in labeled datasets, so researchers propose pre-trained language models, which generate representations with prior knowledge in a large-scale corpus, achieving new results on various NLP tasks. The pre-training models for entity recognition mainly include the ELMO model [23], the BERT model [24], and the OpenAI GPT model [25], where the most commonly used pre-training model is the BERT model. Yongbin Li et al. [26] integrate the ELMO pre-trained model embedding into LSTM models and apply them to Chinese medical entity recognition tasks. Compared with other popular models, good performance was achieved on two datasets related to Chinese medical entities. Zhang et al. [27] took character-level features as input features, which were subsequently mapped to character embedding through an embedding layer using a bidirectional encoder representation from a transformer (BERT) model, a BiLSTM layer, and CRF was used to encode the character embedding and final output label.
In many practical problems, unlabeled data are abundant, but labeled data are less. One of the ways to improve the performance of supervised learning models is to provide a large amount of labeled data, but labeling data often requires a lot of labor and time costs. In addition to the widespread existence and easy collection of unlabeled data, the most important thing is that no labeling is required. However, supervised learning algorithms cannot use unlabeled data, and it is difficult to achieve strong generalization performance when there are few labeled data samples. Although unsupervised learning can use unlabeled data samples, the accuracy of its models is generally poor. In response to the above problems, scholars have proposed semi-supervised learning. Semi-supervised learning [28] is a learning method that combines supervised learning and unsupervised learning, which can use both labeled and unlabeled data.
At present, the self-training algorithm in the semi-supervised learning algorithm most commonly used in the field of medical entity recognition includes the Co-Training algorithm [29], Self-Training algorithm [30], and Tri-Training algorithm [31]. In addition to semi-supervised learning through these three algorithms, existing research also uses semi-supervised dictionary learning algorithms, label propagation algorithms, and semi-supervised learning algorithms based on graph theory. For example, Ioannis Livieris [32] proposed an integrated semi-supervised algorithm based on the maximum probability voting scheme, and the experimental results show that the algorithm outperforms the classical semi-supervised algorithm in terms of classification accuracy. Xia and Wang [33] used a Self-Training algorithm in semi-supervised learning for the Chinese medical entity recognition task. Further, an integrated learning algorithm was used in the proposed model, and a classifier model based on the BiLSTM-CRF network model was employed, which achieved good performance in the relevant medical dataset. Li et al. [34] proposed a pseudo-label-based semi-supervised learning algorithm that uses pre-trained modules to filter out erroneous pseudo-labels to create high-quality labeled data, achieving comparable performance to state-of-the-art models on the CoNLL-2003 and OntoNotes5.0 English NER task. In this paper, we mainly develop semi-supervised learning through the Tri-Training algorithm and apply it to the Chinese medical entity recognition task. According to the characteristics of the task and the data used, we improve the Tri-Training algorithm in terms of the division of the initial sub-training set, the construction of the base classifier, and the integrated learning voting method, and propose a Chinese medical entity recognition model based on the improved Tri-Training algorithm.
3. Model Structure
3.1. BIBC Model
The BIBC model is essentially a multi-neural network fusion model, which consists of four main components, namely the BERT layer, IDCNN layer, BiLSTM layer, and CRF layer. The CRF layer is computed to obtain the final labeling result. Convolutional and recurrent neural networks extract text information at different granularities and integrate the features extracted by these two neural networks, which can extract features more adequately for entity recognition compared to a single neural network model.
The Iterated Dilated Convolutional Neural Network (IDCNN) allows more local information to be obtained in a single convolutional operation. DCNN adds a dilation width after the filter of a standard CNN. When the input data are represented by a matrix, the filter skips all the intermediate input data of the expansion width and keeps its size constant so that the data information of a larger range of input matrices can be obtained. Compared to CNN, IDCNN can learn more contextual information faster.
As shown in Figure 1, the output of the BERT layer is a feature representation of each word of the medical text. After the output of the BERT layer is passed to the IDCNN layer, the convolutional kernel of IDCNN quickly scans the whole sequence by sliding and covers the whole sequence quickly. The output data from the BERT layer is passed through four DCNN layers, learning the features of the input data at each layer, and then the learned features from these four layers are output. These features mainly include local features and global features of the input text. These extracted features are then fed into the BiLSTM layer for further feature extraction to obtain more comprehensive feature information. Finally, the model outputs the best-labeled sequence through the CRF layer.
3.2. Tri-Training Algorithm
In the Tri-Training algorithm, the Bootstrap Sample method needs to be used to divide the labeled training dataset into three sub-training sample sets. Bootstrap Sample is a self-service sampling method that extracts the data in the sample set m times with replacement, resulting in m sample subsets. Since the extraction method is random with replacement, samples may be drawn multiple times into the same sample subset [35].
The process of the Tri-Training algorithm is as follows. First, the labeled training dataset L is divided into three training sample subsets, , and using the Bootstrap Sample classification method. Secondly, three initial base classifier models, , and are obtained by training on the classifier model. Next, the labeled data are used to expand the labeled dataset, while the training sample sets of base classifiers and are also expanded in the same way. Finally, the three base classifiers are retrained on each of the extended sample subsets. Repeat the above process to end model training when the unlabeled sample set is empty [36]. When predicting the sample instance labels, instead of selecting one of the three base classifiers for predictive classification, the Tri-Training algorithm uses the voting method commonly used in integrated learning, which means combining the three base classifier models to predict the labels of unknown instance samples [37].
3.3. Improvements to the Tri-Training Algorithm
The Chinese medical entity recognition model based on the improved Tri-Training algorithm proposed in this paper is mainly semi-supervised learning by the Tri-Training algorithm. The original Tri-Training algorithm has certain limitations, so the following three aspects of improvement are made to improve the overall performance of the model.
We change the way the original labeled training sample set constructs the sub-training sample set to get an even distribution. The original Tri-Training algorithm samples the original labeled data with Bootstrap Sample, which is a method for extracting the labeled training sample set with replacement to get three sub-training sample sets. On the one hand, this extraction method will lead to insufficient extraction of labeled samples resulting in the waste of labeled data. On the other hand, there may be a large amount of duplicate data among the three sub-training sample sets extracted by replacement. Using these repeated training samples and the same structure of the base classifier, the trained base classifier model may output the same labeled results when facing the same sample instances due to its own model, thus interfering with the performance of the model. In this paper, the original labeled training sample set is used to construct the sub-training sample set, and then the original labeled training sample set is divided equally. Specifically, the original labeled training sample set is divided into three sub-training sample sets, which are used for training the three base classifiers.
The base classifier selects three different neural network models. The original Tri-Training algorithm uses three base classifier models with the same structure. Although each base classifier uses different training data, the degree of discrimination between classifiers with the same structure is not high. It is easy to output the same wrong label when facing the same sample instance, which results in poor performance of the final integrated classifier. In view of this problem, the Chinese medical entity recognition model based on semi-supervised learning proposed in this paper adopts three deep neural network models as the network model of the base classifier. These three network models are the BERT-IDCNN-CRF model (BIC), BERT-BiLSTM-CRF model (BBC), and BERT-IDCNN-BiLSTM-CRF model (BIBC). Based on these three network models and three sub-training sample sets, three different base classifier models are trained.
Ensemble learning adopts a voting rule that combines minority-over-majority voting rules and weighted voting. The original Tri-Training algorithm uses the majority-over-minority method. If the three base classifiers have different labels for a sample instance in the integration learning stage, they will be counted according to the error at this time, which results in poor performance of the final integrated classifier. In view of this problem, this paper proposes a voting rule that combines the minority-over-majority voting rule and weighted voting. The rules are as follows, the labeling results generated by the three base classifiers , , and are analyzed, and if the labeling results of the three base classifiers are exactly the same, then the result is considered correct. We will select the minority-over-majority voting rule. If only two base classifiers mark the same result, then the two identical labeled results are considered correct. The weighted voting rule needs to be used for selection when the results marked by the three base classifiers are different. The rules of weighted voting are shown in Formula (1), where the performance weight of each classifier is considered during integration learning, and the weight is determined by the classification accuracy () of the three base classifiers on the initial labeled training dataset L.
3.4. Overall Model Implementation
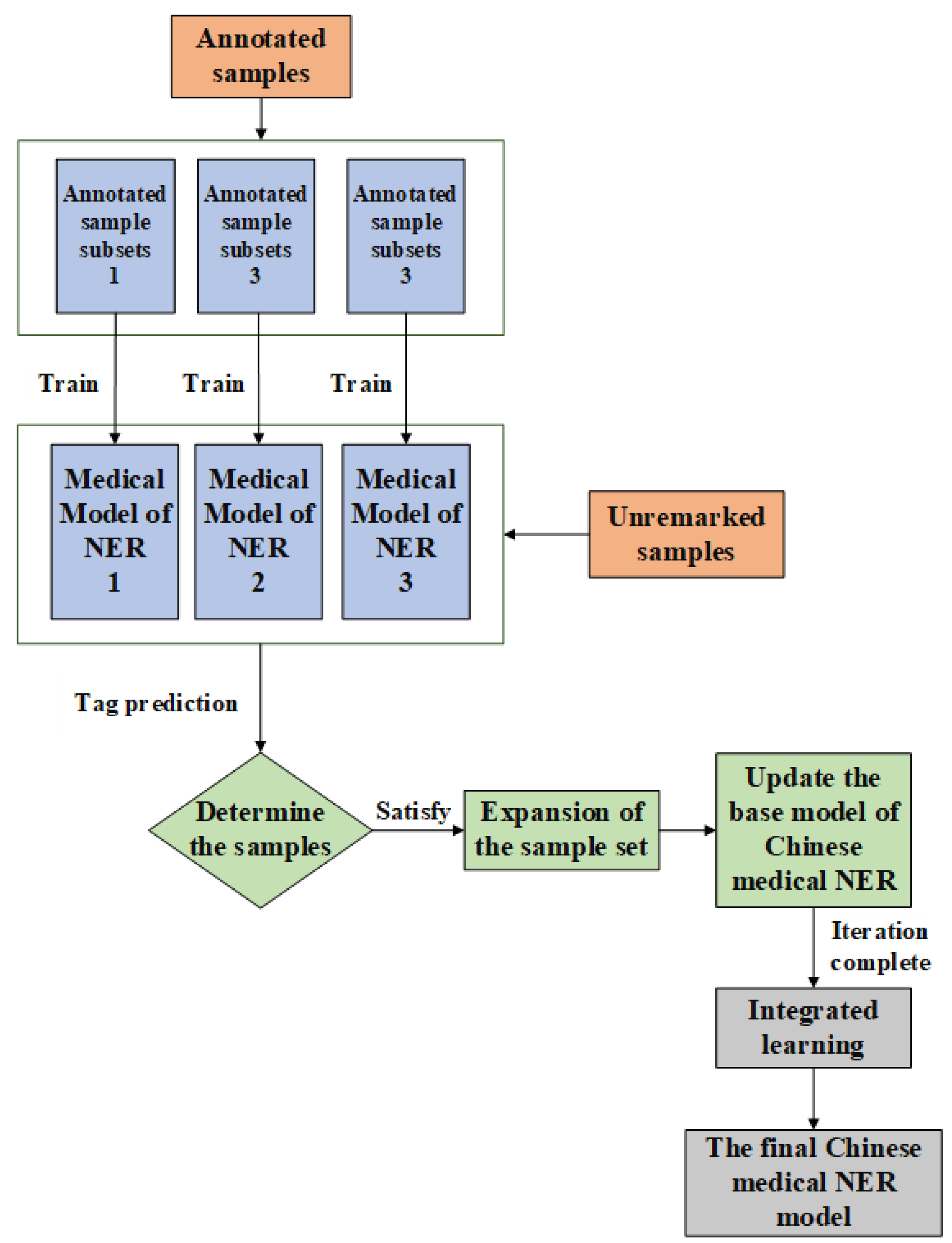
The overall flow chart of the Chinese medical entity recognition model of the improved Tri-Training algorithm proposed in this paper is shown in Figure 2 below: it mainly includes training of labeled data, expanding the sample set of labeled data with unlabeled data, and integrating learning to obtain the final classifier model.
In the process of this algorithm, L denotes the labeled training dataset, U denotes the unlabeled dataset, and denotes the base classifier model, where base classifier is the BERT-IDCNN-CRF model (BIC), base classifier is the BERT-BiLSTM-CRF model (BBC), and base classifier is the BERT-IDCNN-BiLSTM-CRF model (BIBC).
According to the model structure proposed in this paper, the specific algorithmic procedure is as follows.
(1) The labeled training set L is evenly divided into three sub-training sample sets .
(2) The three base classifiers are trained using three labeled sub-training samples , where the three base classifier models are different.
(3) Use the unlabeled dataset U to expand the sub-training set of the base classifier; for the base classifier , randomly select sample instances from U if the labeled results of the base classifiers and on the sample instance are the same, the prediction result is considered to be credible, the sample instance is removed from U and placed in the sub-training sample set to form a new sub-training set . If the labeled results of and are different, the sample instance is removed from U.
(4) Repeat step (3) for base classifiers and to expand their sub-training sets to obtain new sub-training sets and .
(5) Retrain the base classifiers , , and using the new sub-training sets , , and , respectively.
(6) When the unlabeled sample set U is empty, terminate the algorithm to obtain three final classifier models, , , and ; otherwise, repeat steps 3–6 for training.
(7) In the final model recognition stage, the integrated learning strategy adopted is a voting method that combines the simple voting method and weighted voting method. The three base classifiers are integrated into the final classifier model according to this voting method.
4. Experiments and Analysis
4.1. Experimental Data and Evaluation Metrics
The data used in this paper are divided into labeled datasets and unlabeled datasets. The labeled dataset is derived from the CCKS2019 evaluation task “Medical Entity Recognition and Attribute Extraction for Chinese Electronic Medical Records”. Among them, the training set is 1000 Chinese medical texts, and the test set contains 379 Chinese medical texts for evaluating the performance of the final model. The unlabeled data used the medical texts provided at the 6th China Health Information Processing Conference, and a total of 3000 medical records were collected in the “Love and Love Doctor” medical network Chinese medical texts. As shown in Table 1, medical entities in the dataset are divided into six categories, namely disease and diagnosis, imaging examination, laboratory, operation, drug, and anatomy. As shown in Figure 3, the labeled medical text data are used as experimental data for subsequent experiments according to the BIO labeling method.
We use the precision rate (P), recall rate (R), and F1 value (F1) to evaluate the performance of the model proposed in this paper. The accuracy rate measures the ability of the model to identify the correct entities, the recall rate measures the ability of the model to identify all entities in the dataset, and the F1 value is the summed average of the accuracy rate and recall rate. The calculation formulae are as follows.
4.2. Experimental Design
In order to verify the performance of the Chinese medical entity recognition model proposed in this paper based on the improved Tri-Training algorithm in related tasks, in this paper, four groups of experiments are selected to compare the performance of the model by comparing the supervised learning model, the original Tri-Training algorithm model, and the improved Tri-Training algorithm in different aspects.
(1) Model 1: Supervised Hybrid Deep Learning Model BERT-IDCNN-BiLSTM-CRF Model (BIBC).
(2) Model 2: The deep neural network model used by the three base classifiers of the original Tri-Training algorithm is the BERT-IDCNN-BiLSTM-CRF model (BIBC).
(3) Model 3: The deep neural network models used in the three base classifiers of the improved Tri-Training algorithm are all BERT-IDCNN-BiLSTM-CRF models (BIBC).
(4) Model 4: The improved Tri-Training algorithm proposed in this paper, in which the deep neural network models used in the three base classifiers are the BERT-IDCNN-CRF model (BIC), BERT-BiLSTM-CRF model (BBC), and BERT-IDCNN-BiLSTM-CRF model (BIBC).
4.3. Hyper Parameter Settings
The hyperparameters of the model are set before the experiment. Suitable parameters can make the validity of the model better tested. According to the comparison of the experimental results of the model under different hyperparameters, the following hyperparameters can be selected to make the model performance reach the best. The specific hyperparameter settings are shown in Table 2 below.
4.4. Experimental Results and Analysis
4.4.1. BIBC Model Comparison Experiment
As shown in Table 3, we compare different baseline models with the BIBC model proposed in this paper. The IDCNN-CRF model (IC), which combines the IDCNN model and the CRF model, first performs local feature extraction through the IDCNN layer and then obtains the best output sequence through the CRF layer. The BERT-IDCNN-CRF model (BIC), with the addition of the pre-trained model, can better represent the before and after information of the text, thus improving the performance of the model. The BiLSTM-CRF model (BC) is a classical named entity recognition model. The BERT-BiLSTM-CRF model (BBC) is currently the most commonly used deep learning model for natural language processing tasks and has good performance. From the experimental results, it can be seen that the precision, recall, and F1 values of the BIBC model are 1.77%, 0.45%, and 1.11% higher than those of the BBC model, respectively. This is because, after adding the IDCN model, the BIBC model can better represent the information of Chinese medical texts, thus achieving relatively better model recognition results. By comparing the experimental results, it is found that adding the pre-trained model BERT to the model can better represent the deep information contained in the text, which can improve the entity recognition rate to some extent. The F1 value of the BIC model is lower than that of the BBC model because the BiLSTM can better extract the long-range context of the input text information, which makes it more advantageous than the inflated convolutional neural network. However, the advantage of the expanded convolutional neural network is that it is faster. Experimentally, it is proven that the BIBC model has a significant advantage over other baseline models in Chinese medical entity extraction. Moreover, in the improved Tri-Training algorithm, the three base classifiers use the better-performing BIC model, BBC model, and BIBC model.
4.4.2. Comparison Experiments of Different Improved Tri-Training Algorithm Models
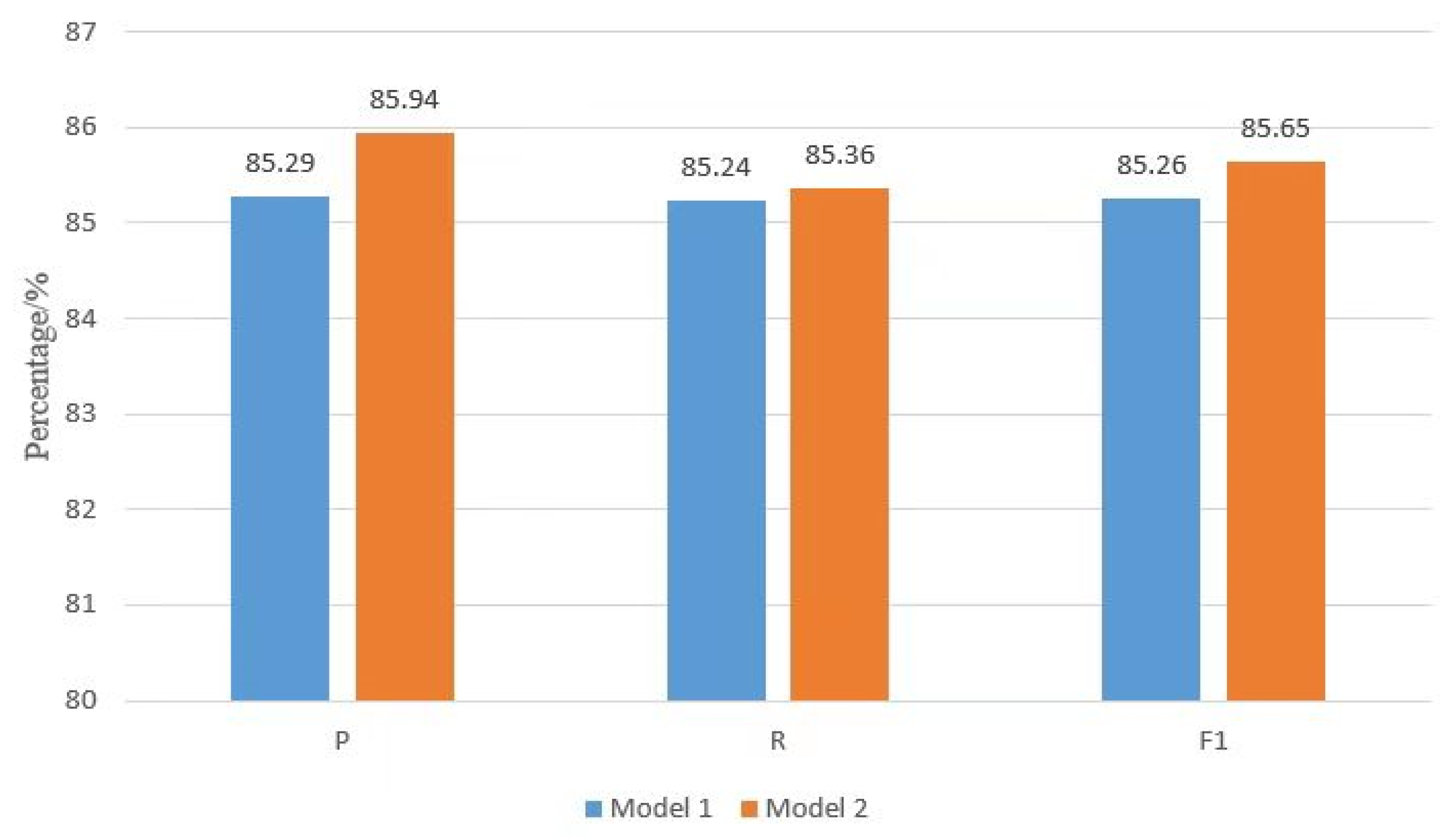
First, the experiments are conducted to compare the effect of the introduction of the semi-supervised learning Tri-Training algorithm on the model performance. The results are shown in Figure 4, where the accuracy, recall, and F1 values of Model 2 with semi-supervised learning are improved compared to Model 1 with supervised learning. This is because the semi-supervised learning approach introduces a large amount of unlabeled data and increases the number of labeled training data samples by selectively expanding the labeled sample set. By adding semi-supervised learning, Model 2 can solve the problem of having only a small amount of labeled data in the Chinese medical dataset, thus improving the generalization ability of the model. The experiments verify that the semi-supervised learning approach can improve the performance of Chinese medical entity recognition models.
We next test whether the improvement of the Tri-Training algorithm in this paper improves the performance of the model, and the models used in this group of comparison experiments are Model 2, Model 3, and Model 4 mentioned above. The experimental results are shown in Figure 5, where Model 3 has improved recall and F1 values compared with Model 2. This is because Model 3 changes the way of selecting the labeled sub-training set and the voting rule of the final integrated learning in the Tri-Training algorithm compared to Model 2. The use of an evenly distributed selection of sample sets prevents the waste of labeled sample data on the one hand and makes full use of the labeled sample sets on the other. This method can use three sample subsets with no overlap at all for training and better differentiate the base classifier model, thus improving the performance of the final obtained classifier model. Compared with Model 3, the biggest change in Model 4 is to change the structure of the three base classifiers. The three base classifiers in Model 4 are different from each other, which can avoid the problem that the three same classifiers also give wrong answers for the same sample instance. Three different base classifiers can avoid this problem to a certain extent, thereby improving the performance of the final model. It can be seen from the experimental data that the model proposed in this paper, compared with the entity recognition model of the original Tri-Training algorithm, has a certain degree of improvement in the three evaluation indicators of accuracy rate, recall rate, and F1 value, which proves that this paper’s improvement to the model is effective.
The Chinese medical entity recognition model based on semi-supervised learning proposed in this paper has the results of entity recognition for each type, as shown in Figure 6. The recognition effect of six types of medical entities is improved relative to the supervised learning model. Among them, the F1 value of anatomical sites is 92.71%, which is much higher than the remaining entities. The reason for this result is that the entity boundaries of anatomical sites are generally clearer and do not have particularly indistinguishable boundaries. Another reason is that the number of medical entities in anatomical sites is also a bit higher in comparison, and the combination of the two reasons makes its recognition result leading among the six categories.
As shown in Table 4, we compare the experimental results of the different improved Tri-Training algorithm models proposed in this paper with other models for comparison. By comparing the experimental results, the F1 value of Model 4 with the improved Tri-Training algorithm is higher than the other models. Model 1 is a novel multi-neural network fusion entity recognition model proposed in this paper, which has good results for medical entity recognition. We improve the division of sub-datasets, the selection of base classifiers, and the voting rules for ensemble learning on the Tri-Training algorithm. In addition, the base classifier of Model 4 is selected from the BIBC model of Model 1. Model 4 incorporates a hybrid neural network model with strong entity recognition performance while making various improvements to the Tri-Training algorithm to achieve the best recognition results. Overall, the model proposed in this paper is advanced and novel. In the field of low-resource medicine, semi-supervised learning can improve the performance of the model compared with supervised learning, and the various improvements to the Tri-Training algorithm in this paper further enhance the entity recognition ability of the model.
4.4.3. Error Analysis
In order to explore the factors affecting the improved Tri-Training algorithm model to identify medical entities, we analyzed the prediction performance of different models in Table 4. Among them, Model 1 is the supervised hybrid deep learning model BIBC proposed in this paper. The results of Model 1 are all lower than the other models, which is because the performance of supervised learning models is limited in the case of low-resource labeled data, while the semi-supervised learning approach can fully utilize the labeled data for learning. Meanwhile, compared with other supervised hybrid neural network models in Table 3, the results of the semi-supervised learning-based models are all higher than the results of other mainstream entity recognition models. In addition, the results of Model 2 with the original Tri-Training algorithm are poorer compared to Model 3 and Model 4 with the improved Tri-Training algorithm. This is because the original Tri-Training algorithm has the problem of error propagation and inadequate sample extraction. This demonstrates that the errors arising from sample extraction in semi-supervised learning algorithms and the prediction labeling errors caused by ensemble learning can lead to degraded model recognition performance. The improved model addresses these issues and improves the model entity recognition performance. Experiments validate the effectiveness of the improved Tri-Training algorithm. In this paper, the overall performance of the model is judged by the F1 value, and Model 4 achieves the highest F1 value. Compared with Model 3, which also incorporates the improved Tri-Training algorithm, Model 4 selects three different entity recognition models as base classifiers, further avoiding the problem of errors caused by low discrimination of the same classifiers. We also assign weights to the classifiers of different models to identify entities more accurately. Overall, all our improvements address the shortcomings of the original method and improve the performance of the Chinese medical entity recognition model.
5. Conclusions
In this paper, a semi-supervised learning method is applied to the field of medical entity recognition, and a Chinese medical entity recognition model based on multi-neural network fusion and an improved Tri-Training algorithm is proposed. The model is mainly used to solve the problem of low model recognition performance caused by insufficient labeling data in the medical field. This paper focuses on semi-supervised learning through the Tri-Training algorithm and makes improvements based on the characteristics of Chinese medical entity recognition tasks and data. In this paper, the BIBC model is first proposed as an entity classifier, and it is experimentally verified that the BIBC model has better performance on the medical entity relationship extraction task. In order to avoid the error transfer caused by the same classifier, three different hybrid neural network models are selected for the three base classifiers. In addition, this paper adopts an equal distribution method in the division of sub-training sets to make full use of the labeled data. Finally, the model adopts a novel voting rule in ensemble learning, which is a good solution to the impact of the classifier’s prediction error on the same samples. Through experimental validation, the results of this paper’s method are improved to a certain extent compared with other models. The experiments demonstrate that our proposed improved training algorithm is effective for the low-resource Chinese medical entity recognition task.
Although our model achieves good results, the model is only trained on a single dataset, which limits the generalization ability of the model. In future work, we plan to better improve the performance of the Chinese medical entity recognition model by combining external knowledge and considering training the model’s entity recognition capability in different low-resource domains.
Author Contributions
Conceptualization, R.Q.; methodology, R.Q.; software, P.L.; validation, Q.Z., M.W., and P.L.; formal analysis, M.W.; investigation, R.Q.; resources, Q.Z.; data curation, M.W.; writing—original draft preparation, R.Q.; writing—review and editing, P.L. and M.W.; visualization, P.L.; supervision, Q.Z.; project administration, R.Q.; funding acquisition, Q.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (62073123) and Major Public Welfare Project of Henan Province (201300311200).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, Y.; Wang, X.; Hou, Z.; Li, J. Clinical named entity recognition from Chinese electronic health records via machine learning methods. JMIR Med. Inform. 2022, 1, 40–43. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Sun, A.; Han, J. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef]
- Yin, M.; Mou, C.; Xiong, K.; Ren, J. Chinese clinical named entity recognition with radical-level feature and self-attention mechanism. J. Biomed. Inform. 2019, 98, 103289. [Google Scholar] [CrossRef] [PubMed]
- Prokosch, H.U.; Ganslandt, T. Perspectives for Medical Informatics Reusing the Electronic Medical Record for Clinical Research. Methods Inf. Med. 2009, 48, 38–44. [Google Scholar] [PubMed]
- Zhao, Q.; Wang, D.; Li, J. Exploiting the concept level feature for enhanced name entity recognition in Chinese EMRs. J. Supercomput. 2020, 76, 6399–6420. [Google Scholar] [CrossRef]
- Uzuner, Ö.; Stubbs, A.; Filannino, M. A natural language processing challenge for clinical records: Research Domains Criteria (RDoC) for psychiatry. J. Biomed. Inform. 2017, 75, S1–S3. [Google Scholar] [CrossRef]
- Gong, L.; Zhang, Z.; Chen, S. Clinical Named Entity Recognition from Chinese Electronic Medical Records Based on Deep Learning Pertaining. J. Healthc. Eng. 2020, 2020, 8829219. [Google Scholar] [CrossRef]
- Lei, J.; Tang, B.; Lu, X.; Gao, K.; Jiang, M.; Xu, H. A comprehensive study of named entity recognition in Chinese clinical text. J. Am. Med. Inform. Assoc. 2014, 5, 808–814. [Google Scholar] [CrossRef]
- Wang, Q.; Zhou, Y.; Ruan, T.; Gao, D.; Xia, Y.; He, P. Incorporating dictionaries into deep neural networks for the Chinese clinical named entity recognition. J. Biomed. Inform. 2019, 92, 103133. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Z.; Hui, Z. Named Entity Recognition Based on A Machine Learning Model. Res. J. Appl. Sci. Eng. Technol. 2012, 4, 3973–3980. [Google Scholar]
- Liu, L.; Wu, X.; Liu, H.; Cao, X.Y.; Wang, H.T.; Zhou, H.W.; Xie, Q. A semi-supervised approach for extracting TCM clinical terms based on feature words. BMC Med. Inform. Decis. Mak. 2020, 20, 118. [Google Scholar] [CrossRef]
- Navigli, R.; Velardi, P. Learning domain ontologies from document warehouses and dedicated web sites. Comput. Linguist. 2004, 30, 151–179. [Google Scholar] [CrossRef]
- Dong, G.; Chen, J.; Wang, H.; Zhong, N. A Narrow-domain Entity Recognition Method Based on Domain Relevance Measurement and Context Information. In Proceedings of the International Conference on Web Intelligence, Leipzig, Germany, 23–26 August 2017; pp. 623–628. [Google Scholar]
- Roberts, A.; Gaizauskas, R.; Hepple, M. Extracting clinical relationships from patient narratives. In Proceedings of the Workshop on Current Trends in Biomedical Natural Language Processing, Columbus, OH, USA, 19 June 2008. [Google Scholar]
- Patrick, J.; Li, M. High accuracy information extraction of medication information from clinical notes: 2009 i2b2 medication extraction challenge. J. Am. Med. Inform. Assoc. 2010, 17, 524–527. [Google Scholar] [CrossRef]
- Clark, C.; Aberdeen, J.; Coarr, M.; Tresner-Kirsch, D.; Wellner, B.; Yeh, A.; Hirschman, L. MITRE system for clinical assertion status classification. J. Am. Med. Inform. Assoc. 2011, 563–567. [Google Scholar] [CrossRef]
- Wang, C.; Wei, C.; Bo, X. Named Entity Recognition with Gated Convolutional Neural Networks. In Proceedings of the China National Conference on Chinese Computational Linguistics International Symposium on Natural Language Processing Based on Naturally Annotated Big Data, Nanjing, China, 13–15 October 2017. [Google Scholar]
- Li, L.; Jin, L.; Huang, D. Exploring Recurrent Neural Networks to Detect Named Entities from Biomedical Text; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Wang, J.; Xu, W.; Fu, X.; Xu, G.; Wu, Y. ASTRAL: Adversarial Trained LSTM-CNN for Named Entity Recognition. Knowl.-Based Syst. 2020, 197, 105842–105849. [Google Scholar] [CrossRef]
- Li, X.; Fu, C.; Zhong, R.; Zhong, D.; He, T.; Jiang, X. A hybrid deep learning framework for bacterial named entity recognition with domain features. BMC Bioinform. 2019, 20, 583. [Google Scholar] [CrossRef]
- Wang, X.; Yang, C.; Guan, R. A comparative study for biomedical named entity recognition. Int. J. Mach. Learn. Cybern. 2018, 9, 373–382. [Google Scholar] [CrossRef]
- Gligic, L.; Kormilitzin, A.; Goldberg, P.; Nevado-Holgado, A. Named Entity Recognition in Electronic Health Records Using Transfer Learning Bootstrapped Neural Networks. Neural Netw. 2020, 121, 132–139. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Ma, Z.; Gao, L.; Xu, Y.; Sun, T. Application of Pre-training Models in Named Entity Recognition. In Proceedings of the 2020 12th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 22–23 August 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Lee, J.S.; Hsiang, J. Patent claim generation by fine-tuning OpenAI GPT-2. World Pat. Inf. 2020, 62, 101983. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Hui, L.; Zou, L.; Li, H.; Xu, L.; Liu, W. Chinese Clinical Named Entity Recognition in Electronic Medical Records: Development of a Lattice Long Short-Term Memory Model With Contextualized Character Representations. JMIR Med. Inform. 2020, 8, e19848. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, J.; Zhang, X. Using a Pre-Trained Language Model for Medical Named Entity Extraction in Chinese Clinic Text. In Proceedings of the 2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 17–19 July 2020. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Helwe, C.; Elbassuoni, S. Arabic named entity recognition via deep co-learning. Artif. Intell. Rev. 2019, 52, 197–215. [Google Scholar] [CrossRef]
- Gao, S.; Kotevska, O.; Sorokine, A.; Christian, J.B. A pre-training and self-training approach for biomedical named entity recognition. PLoS ONE 2021, 16, e0246310. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, C.; Li, T.; Wu, H.; Zhao, X.; Ye, K.; Liao, J. Named Entity Recognition from Chinese Adverse Drug Event Reports with Lexical Feature based BiLSTM-CRF and Tri-training. J. Biomed. Inform. 2019, 96, 103252. [Google Scholar] [CrossRef]
- Livieris, I.E. A new ensemble semi-supervised self-labeled algorithm. Informatica 2019, 43, 221–234. [Google Scholar] [CrossRef]
- Xia, Y.; Wang, Q. Clinical named entity recognition: ECUST in the CCKS-2017 shared task 2. Proc. CEUR Workshop 2017, 1976, 43–48. [Google Scholar]
- Li, Z.Z.; Feng, D.W.; Li, D.S.; Lu, X.C. Learning to select pseudo labels: A semi-supervised method for named entity recognition. Front. Inf. Technol. Electron. Eng. 2020, 21, 903–916. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef]
- Wang, R.Q.; Guan, Y. Research on entity recognition of Chinese electronic medical records based on Tri-Training algorithm. Intell. Comput. Appl. 2017, 7, 132–134, 138. [Google Scholar]
- Qian, T.; Liu, B.; Chen, L.; Peng, Z.; Zhong, M.; He, G.; Li, X.; Xu, G. Tri-Training for authorship attribution with limited training data: A comprehensive study. Neurocomputing 2016, 171, 798–806. [Google Scholar] [CrossRef]
Figure 1.
BIBC model structure diagram.

Figure 2.
Structure of Chinese medical entity recognition model based on semi-supervised learning.

Figure 3.
Example diagram of data annotated by BIO. (The example sentences: Cardiac ultrasound indicates right ventricular and biventricular enlargement. “B-IMA” indicates that the element is in a segment of the entity type Imaging Examination, and that the element is at the beginning of the segment. “I-IMA” means that the element is in a segment of entity type Imaging Examination and the element is in the middle of the segment. “O” indicates that the element does not belong to any type.)
Figure 3.
Example diagram of data annotated by BIO. (The example sentences: Cardiac ultrasound indicates right ventricular and biventricular enlargement. “B-IMA” indicates that the element is in a segment of the entity type Imaging Examination, and that the element is at the beginning of the segment. “I-IMA” means that the element is in a segment of entity type Imaging Examination and the element is in the middle of the segment. “O” indicates that the element does not belong to any type.)

Figure 4.
The performance statistics of the semi-supervised learning model.

Figure 5.
The performance statistics of the improved semi-supervised learning algorithm model.

Figure 6.
Statistics of various entity recognition performances.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Statistics on the number of different types of entities (unit: %).
| Medical Entities | Test Set | Training Set |
|---|---|---|
| Disease and Diagnosis | 2116 | 682 |
| Imaging Examination | 222 | 91 |
| Laboratory Test | 318 | 193 |
| Operation | 765 | 140 |
| Drug | 456 | 263 |
| Anatomy | 1486 | 447 |
| Total | 5363 | 1816 |
Table 2.
Experimental hyperparameter settings (unit: %).
| Super Parameter | Value |
|---|---|
| BERT max input size | 128 |
| Fitter | 100 |
| LSTM dim | 128 |
| Dropout rate | 0.5 |
| Learning rate | 0.005 |
| Batch size | 50 |
| Epoch | 25 |
| Optimizer | Adam |
Table 3.
Comparison of BIBC model and different baseline model results (Unit: %).
| Model | Precision (P) | Recall (R) | F1 |
|---|---|---|---|
| IC | 78.45 | 77.62 | 78.03 |
| BIC | 82.36 | 83.65 | 83.00 |
| BC | 81.85 | 80.23 | 81.03 |
| BBC | 83.52 | 84.79 | 84.15 |
| BIBC | 85.29 | 85.24 | 85.26 |
Table 4.
Experimental hyperparameter settings (unit: %).
| Model | Precision Rate (P) | Recall Rate (R) | F1 Value (F1) |
|---|---|---|---|
| Model 1 | 85.29 | 85.24 | 85.26 |
| Model 2 | 85.94 | 85.36 | 85.65 |
| Model 3 | 85.61 | 86.13 | 85.87 |
| Model 4 | 86.36 | 85.84 | 86.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Qi, R.; Lv, P.; Zhang, Q.; Wu, M. Research on Chinese Medical Entity Recognition Based on Multi-Neural Network Fusion and Improved Tri-Training Algorithm. Appl. Sci. 2022, 12, 8539. https://0-doi-org.brum.beds.ac.uk/10.3390/app12178539
AMA Style
Qi R, Lv P, Zhang Q, Wu M. Research on Chinese Medical Entity Recognition Based on Multi-Neural Network Fusion and Improved Tri-Training Algorithm. Applied Sciences. 2022; 12(17):8539. https://0-doi-org.brum.beds.ac.uk/10.3390/app12178539
Chicago/Turabian StyleQi, Renlong, Pengtao Lv, Qinghui Zhang, and Meng Wu. 2022. "Research on Chinese Medical Entity Recognition Based on Multi-Neural Network Fusion and Improved Tri-Training Algorithm" Applied Sciences 12, no. 17: 8539. https://0-doi-org.brum.beds.ac.uk/10.3390/app12178539
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.