
Zero-Shot Emotion Detection for Semi-Supervised Sentiment Analysis Using Sentence Transformers and Ensemble Learning

Abstract
:1. Introduction
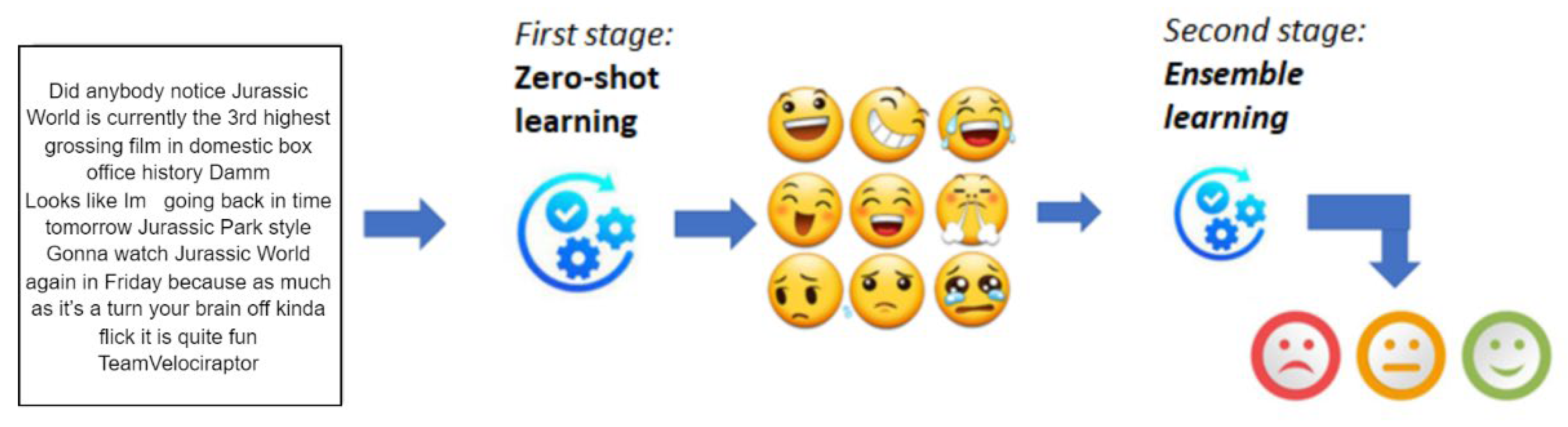
- The zero-shot model detects emotions first, and later they are used to assign positive, negative, and neutral sentiments. Such a method gradually decreases the dimensionality starting from the high-dimensional sentence transformer input (i.e., vectorized text) mapped into probability values of different emotions; probability values are further mapped into the sentiment labels.
- The second-stage input does not require complicated feature extraction or sophisticated machine learning methods able to catch sentiments directly from the text, which, in turn, speeds up the whole sentiment analysis process.
- The performance of the proposed method is evaluated on three benchmark datasets (IMDB, Sentiment140, and SemEval-2017) and using multiple classifiers, including machine learning, neural network, and ensemble learning.
- The proposed emotion-sentiment detection model requires fewer training data compared to traditional Sentiment analysis detection.
2. Related Work
3. Methodology
3.1. Outline
3.2. Emotions and Sentiments
3.3. Vectorization
3.4. First Stage Zero-Shot Classifiers (Sentence Transformers)
- The bart-large-mnli model [52] is a zero-shot sequence classifier proposed in [53]. The model was trained on tweets, emotional occurrences, fairy tales, and artificial sentences. It has nine emotions (anger, disgust, fear, guilt, joy, love, sadness, shame, surprise), as well as the “none” class (if no emotion applies). The approach offers the sequence to be categorized as the multi-genre natural language inference (MNLI) and creates a hypothesis from each possible label. Then, label probabilities are created from the entailment and contradiction probabilities.
- The COVID-Twitter-BERT (CT-BERT), a transformer-based model, is the foundation of the covid-twitter-bert-v2-mnli model [55], which was pre-trained on a corpus of Twitter conversations about COVID-19 [56]. CT-BERT was designed to work with the COVID-19 content, particularly from social media. The emotion toward vaccines is captured by the model. The dataset comprises three classes: positive (towards vaccinations), negative, and neutral/others.
- The bart-large-mnli-yahoo-answers model [57] refined the bart-large-mnli model on Yahoo Answers subject categorization. The model may be used to forecast whether the topic label can be assigned to a certain sequence.
3.5. Second Stage Machine Learning and Ensemble Learning Classifiers
3.5.1. Single-Model Machine Learning Classifiers
- Feed-forward neural network (FFNN) is suitable for solving tasks as it can learn relationships between independent features. In addition, it is a simple and fast network learning how to adapt the weights of connections between units until the correct output is produced. In this paper, we have used this architecture because of its simplicity of feature selection. The architecture of the model we used in our experiment has one layer of 64 neurons, Rectified Linear Unit (ReLU) activation function in the hidden layer, and sigmoid activation function in the output layer. During training, we used accuracy metrics and Adam optimizer with binary cross-entropy loss.
- Linear regression (LR) is an algorithm used when you want to know how strong the relationship between two variables is and the value of a dependent variable at a certain value of the independent variables. The parameters of this classifier are set to their default values.
- K-nearest neighborhood (KNN). In KNN, similar class-type objects exist in closer proximity. KNN can be used for multiclass classification, and it is useful when the size of the labeled data is smaller. In our case, due to the small amount of data used for this experiment, we chose to test this method. The parameters of these classifiers were set into their default values.
- Support Vector Machine (SVM) is a supervised learning method that is used for classification, regression, and outlier detection. Default values were used in the parameters of this classifier.
- Naive Bayes (NB) predicts the probability of different classes based on several attributes. We use this algorithm because it is mostly used for text classification and multiple classes. We choose this classifier because it does not require much training data. We used the default values of its parameters in our experiment.
- Classifier and Regression Tree (CART). It is a decision tree algorithm used for the classification task. CART can capture non-linear relationships within the dataset, and there is no need for standardization of data when using this model. We used the default values for the parameters of this classifier.
3.5.2. Ensemble Learning Classifiers
- Adaptive Boosting (AdaBoost) classifier re-assigns weights to each data sample, i.e., higher weights are assigned to wrongly classified data. AdaBoost is less likely to overfit because input parameters are not optimized jointly.
- AdaBoost regressor is a meta-estimator that, first, fits a regressor on the original dataset, and then it fits subsequent copies of the regressor while the weights of the instances are changed in accordance with the error of the most recent prediction.
- Bagging classifier is used to lower a variance within the noisy dataset. A bagging classifier fits base classifiers on randomly selected subsets of the dataset and then combines their predictions (by averaging or by voting) to get a prediction.
- Bagging regressor is a meta-estimator that fits base regressors to individual random subsets of the dataset and then combines each prediction to get the final prediction. By adding randomization to the process of building a black-box estimator (such as a decision tree), a meta-estimator lowers the variance of the estimator.
- Extremely Randomized Trees (ExtraTress) classifier is similar to Random Forest but has two key differences: it samples without replacement; in this case, bootstrap is equal to False by default, and nodes are split based on random splits rather than best splits. The advantage of this estimator is its low variance.
- Histogram Gradient Boosting (HistGradientBoost) classifier buckets continuous feature values into discrete bins, and then it uses these bins to generate feature histograms during training. The histogram-based algorithm is very efficient in both memory consumption and training speed.
- Stacking classifier stacks several machine learning classifiers such as Random Forest Classifier, KNN, decision tree, SVM, NB, and Support Vector Regression.
3.6. Evaluation and Statistical Analysis of Performance
4. Experiments and Results
4.1. Settings
4.2. Datasets
- IMDB [65] is the English dataset that has 50K movie reviews (with ~300 words per review on average) annotated with positive or negative labels. This dataset contains only highly polarized reviews (with a score of ≤ 4 of 10 for negative and ≥ 7 of 10 for positive). It is highly researched, with more than 1000 research papers using it. The task analyzed in this paper differs from the traditional text classification, and it does not require a large, annotated dataset. Therefore, we have randomly selected 5000 samples of positive and negative classes to create a new dataset used for our experiments.
- Sentiment140 [66] is an English dataset has 1.6 million tweets extracted using the Twitter API and annotated with two classes (positive and negative). For our experiments, we randomly selected a subset of 5000 texts for each class.
- SemEval-2017 [67] is the dataset (the English version) that was first presented in the scientific SemEval competitions. It has three classes (positive, neutral, and negative), but it is imbalanced. For binary classification and comparison, we have omitted the neutral class and tested with the positive and negative classes only.
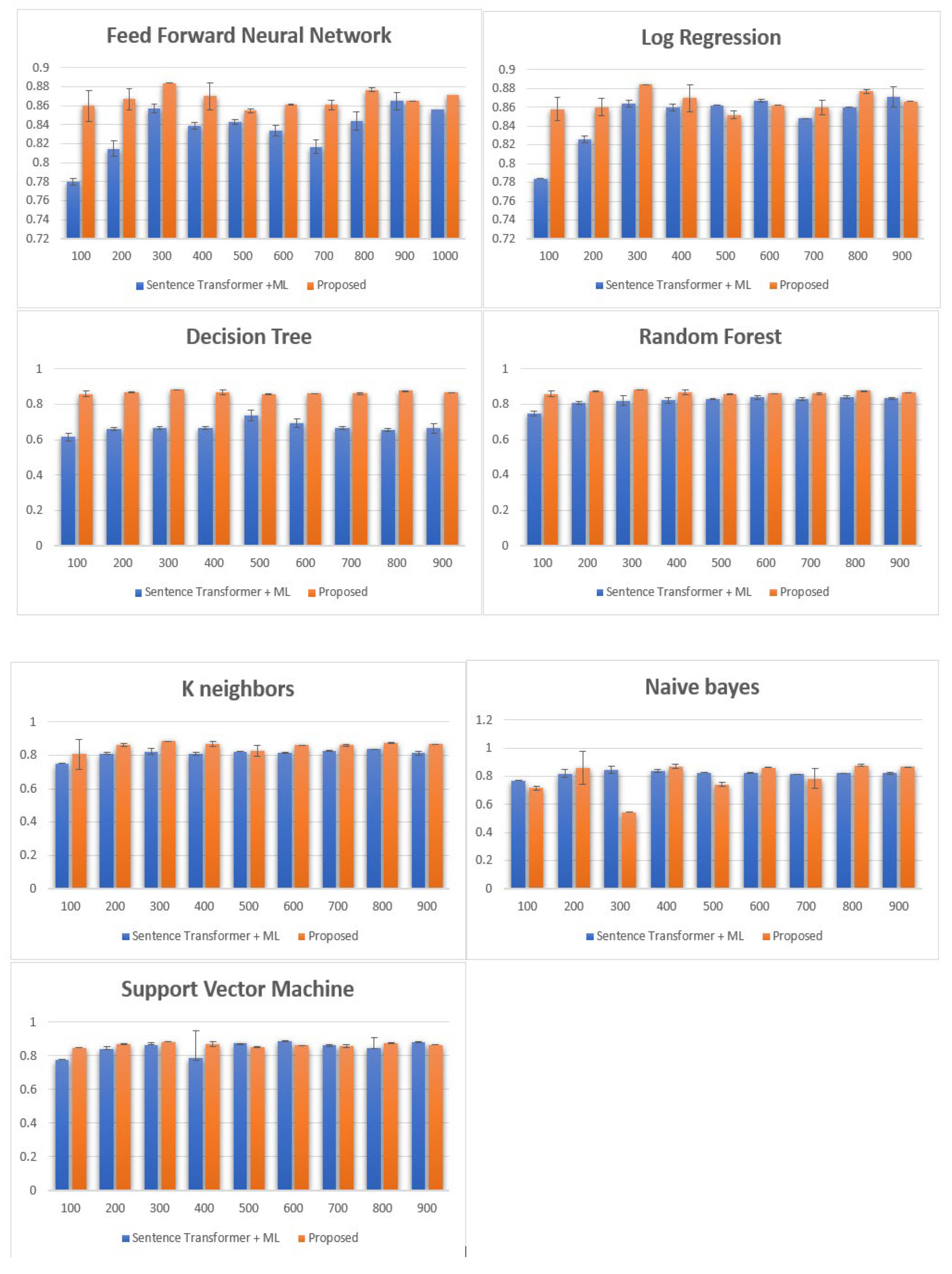
4.3. Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | bart-large-mnli-yahoo-answers | bart-large-mnli | covid-twitter-bert-v2-mnli | Fb_improved_zeroshot |
|---|---|---|---|---|
| Linear regression | 0.727 | 0.740 | 0.670 | 0.693 |
| KNN | 0.650 | 0.747 | 0.740 | 0.663 |
| CART | 0.700 | 0.730 | 0.677 | 0.693 |
| SVM | 0.727 | 0.733 | 0.670 | 0.693 |
| Naïve Bayes | 0.513 | 0.723 | 0.680 | 0.523 |
| Classification Methodology | Method | First Set | Second Set | Third Set | Fourth Set |
|---|---|---|---|---|---|
| Single-model machine learning | FFNN | 0.338 | 0.433 | 0.484 | 0.458 |
| Linear regression | 0.611 | 0.546 | 0.575 | 0.516 | |
| KNN | 0.577 | 0.501 | 0.541 | 0.484 | |
| SVM | 0.611 | 0.546 | 0.575 | 0.516 | |
| Naïve Bayes | 0.555 | 0.538 | 0.575 | 0.520 | |
| CART | 0.611 | 0.544 | 0.574 | 0.516 | |
| Ensemble learning | AdaBoost Classifier | 0.611 | 0.551 | 0.578 | 0.519 |
| AdaBoost regressor | 0.292 | 0.256 | 0357 | 0.219 | |
| Bagging classifier | 0.611 | 0.551 | 0.578 | 0.519 | |
| Bagging regressor | 0.263 | 0.266 | 0.270 | 0.207 | |
| ExtraTrees classifier | 0.611 | 0.551 | 0.578 | 0.519 | |
| HistGradientBoost classifier | 0.611 | 0.551 | 0.578 | 0.519 | |
| Stacking classifier | 0.627 | 0.544 | 0.578 | 0.509 |
| Classification Methodology | Method | First Set | Second Set | Third Set | Fourth Set |
|---|---|---|---|---|---|
| Single-model machine learning | FFNN | 0.82 | 0.826 | 0.873 | 0.776 |
| Linear regression | 0.845 | 0.801 | 0.863 | 0.790 | |
| KNN | 0.830 | 0.782 | 0.823 | 0.639 | |
| SVM | 0.845 | 0.801 | 0.863 | 0.790 | |
| Naïve Bayes | 0.845 | 0.801 | 0.854 | 0.790 | |
| CART | 0.845 | 0.801 | 0.863 | 0.790 | |
| Ensemble learning | AdaBoost classifier | 0.844 | 0.800 | 0.863 | 0.790 |
| AdaBoost regressor | 0.519 | 0.404 | 0.506 | 0.315 | |
| Bagging classifier | 0.844 | 0.800 | 0.863 | 0.790 | |
| Bagging regressor | 0.460 | 0.318 | 0.519 | 0.284 | |
| ExtraTrees classifier | 0.844 | 0.800 | 0.863 | 0.790 | |
| HistGradientBoost classifier | 0.844 | 0.800 | 0.863 | 0.790 | |
| Stacking classifier | 0.819 | 0.826 | 0.873 | 0.776 |
| Classification Methodology | Method | IMDB | Sentiment140 | SemEval-2017 (w/o Neutral Class) |
|---|---|---|---|---|
| Single-model machine learning | FFNN | 0.773 | 0.728 | 0.873 |
| Linear regression | 0.767 | 0.715 | 0.863 | |
| KNN | 0.760 | 0.655 | 0.823 | |
| SVM | 0.767 | 0.715 | 0.863 | |
| Naïve Bayes | 0.766 | 0.715 | 0.854 | |
| CART | 0.767 | 0.715 | 0.863 | |
| Ensemble learning | AdaBoost classifier | 0.767 | 0.714 | 0.863 |
| AdaBoost regressor | 0.423 | 0.177 | 0.506 | |
| Bagging classifier | 0.767 | 0.714 | 0.863 | |
| Bagging regressor | 0.332 | 0.047 | 0.519 | |
| ExtraTrees classifier | 0.767 | 0.714 | 0.863 | |
| HistGradientBoost classifier | 0.767 | 0.714 | 0.863 | |
| Stacking classifier | 0.772 | 0.728 | 0.873 |
| Precision | Recall | F1-Score | Accuracy | |
|---|---|---|---|---|
| Binary classification | 0.863 | 0.908 | 0.884 | 0.873 |
| 3-class classification | 0.562 | 0.627 | 0.554 | 0.627 |
| Text | Score | Labels | Predicted | True Class |
|---|---|---|---|---|
| Did anybody notice Jurassic World is currently the 3rd highest grossing film in domestic box office history Damm | 0.082 | Fear | Positive | Negative |
| Looks like Im going back in time tomorrow Jurassic Park style | 0.3746 | Fear | Positive | Negative |
| Gonna watch Jurassic World again in Friday because as much as it’s a turn your brain off kinda flick it is quite fun TeamVelociraptor | 0.9961 | Pleasure | Positive | Positive |
| Justin is lost in the 1st minute No experience | 0.7968 | Horror | Negative | Negative |
4.4. Ablation Study
4.5. Statistical Analysis
5. Discussion
- Applying a classification threshold. We have performed an error analysis of the misclassified instances, and most of them received the lowest probability score for certain emotions (see Table 9). Correctly classified emotions have the highest probability score when classified using the zero-shot model. Therefore, setting a certain threshold for emotions can increase the accuracy of the model, then emotions with a lower score than the threshold might potentially be in the neutral class. In our classification, the highest misclassified class was the neutral class (see Figure 6), which can be confused either with a positive or a negative class.
- Skipping one-hot vectorization. The current method transforms the outputs of the zero-shot method into one-hot encoding vectors used as features in the supervised training. We may expect possible improvement if, instead of determining one dominant emotion, we provide the whole spectrum of their influence (i.e., returned probabilities). Then the supervised machine learning model can be trained on the real values instead of binary (i.e., one-hot encoded) vectors.
- Choosing more specific emotions. In our experiments, we tested four sets of emotions. The third set achieved the best result compared to all other tested sets (see Table 6). Using a larger set of emotions and a different split of emotions into subsets may allow for improving the result.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sagnika, S.; Pattanaik, A.; Mishra, B.S.P.; Meher, S.K. A review on multi-lingual sentiment analysis by machine learning methods. J. Eng. Sci. Technol. Rev. 2020, 13, 154–166. [Google Scholar] [CrossRef]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 54, 5789–5829. [Google Scholar] [CrossRef]
- Kanclerz, K.; Milkowski, P.; Kocon, J. Cross-lingual deep neural transfer learning in sentiment analysis. Procedia Comput. Sci. 2020, 176, 128–137. [Google Scholar] [CrossRef]
- Mutanov, G.; Karyukin, V.; Mamykova, Z. Multi-class sentiment analysis of social media data with machine learning algorithms. Comput. Mater. Contin. 2021, 69, 913–930. [Google Scholar] [CrossRef]
- Krishnan, H.; Elayidom, M.S.; Santhanakrishnan, T. A comprehensive survey on sentiment analysis in twitter data. Int. J. Distrib. Syst. Technol. 2022, 13, 52. [Google Scholar] [CrossRef]
- Kilimci, Z.H.; Omurca, S.I. Extended feature spaces based classifier ensembles for sentiment analysis of short texts. Inf. Technol. Control. 2018, 47, 457–470. [Google Scholar] [CrossRef]
- Alonso, M.A.; Vilares, D.; Gómez-Rodríguez, C.; Vilares, J. Sentiment analysis for fake news detection. Electronics 2021, 10, 1348. [Google Scholar] [CrossRef]
- Aldjanabi, W.; Dahou, A.; Al-Qaness, M.A.A.; Elaziz, M.A.; Helmi, A.M.; Damaševičius, R. Arabic offensive and hate speech detection using a cross-corpora multi-task learning model. Informatics 2021, 8, 69. [Google Scholar] [CrossRef]
- Karayiğit, H.; Akdagli, A.; Aci, Ç.İ. Homophobic and hate speech detection using multilingual-BERT model on turkish social media. Inf. Technol. Control. 2022, 51, 356–375. [Google Scholar] [CrossRef]
- Tesfagergish, S.G.; Damaševičius, R.; Kapočiūtė-Dzikienė, J. Deep fake recognition in tweets using text augmentation, word embeddings and deep learning. In Proceedings of the 21st International Conference on Computational Science and Its Applications, ICCSA 2021, Cagliari, Italy, 13–16 September 2021; Part VI. pp. 523–553. [Google Scholar] [CrossRef]
- Anstead, N.; O’Loughlin, B. Social media analysis and public opinion: The 2010 UK general election. J. Comput. Mediat. Commun. 2015, 20, 204–220. [Google Scholar] [CrossRef]
- Lampert, J.; Lampert, C.H. Overcoming rare-language discrimination in multi-lingual sentiment analysis. In Proceedings of the 2021 IEEE International Conference on Big Data, Big Data 2021, Orlando, FL, USA, 15–18 December 2021; pp. 5185–5192. [Google Scholar]
- Liang, M.; Zhou, J.; Sun, Y.; He, L. Working with few samples: Methods that help analyze social attitude and personal emotion. In Proceedings of the 2021 IEEE 24th International Conference on Computer Supported Cooperative Work in Design, CSCWD 2021, Dalian, China, 5–7 May 2021; pp. 1135–1140. [Google Scholar] [CrossRef]
- Nazir, A.; Rao, Y.; Wu, L.; Sun, L. Issues and challenges of aspect-based sentiment analysis: A comprehensive survey. IEEE Trans. Affect. Comput. 2022, 13, 845–863. [Google Scholar] [CrossRef]
- Pelicon, A.; Pranjić, M.; Miljković, D.; Škrlj, B.; Pollak, S. Zero-shot learning for cross-lingual news sentiment classification. Appl. Sci. 2020, 10, 5993. [Google Scholar] [CrossRef]
- Choi, H.; Kim, J.; Joe, S.; Min, S.; Gwon, Y. Analyzing zero-shot cross-lingual transfer in supervised NLP tasks. In Proceedings of the International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2020; pp. 9608–9613. [Google Scholar] [CrossRef]
- Phan, K.T.; Ngoc Hao, D.; Thin, D.V.; Luu-Thuy Nguyen, N. Exploring zero-shot cross-lingual aspect-based sentiment analysis using pre-trained multilingual language models. In Proceedings of the 2021 International Conference on Multimedia Analysis and Pattern Recognition, MAPR, Hanoi, Vietnam, 15–16 October 2021. [Google Scholar] [CrossRef]
- Kumar, A.; Albuquerque, V.H.C. Sentiment analysis using XLM-R transformer and zero-shot transfer learning on resource-poor indian language. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–13. [Google Scholar] [CrossRef]
- Pribán, P.; Steinberger, J. Are the multilingual models better? Improving czech sentiment with transformers. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP, Online, 1–3 September 2021; pp. 1138–1149. [Google Scholar] [CrossRef]
- Musa, I.H.; Xu, K.; Liu, F.; Zamit, I.; Abro, W.A.; Qi, G. A cross-lingual sentiment topic model evolution over time. Intell. Data Anal. 2020, 24, 253–266. [Google Scholar] [CrossRef]
- Wang, D.; Jing, B.; Lu, C.; Wu, J.; Liu, G.; Du, C.; Zhuang, F. Coarse alignment of topic and sentiment: A unified model for cross-lingual sentiment classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 736–747. [Google Scholar] [CrossRef]
- Nandwani, P.; Verma, R. A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Min. 2021, 11, 81. [Google Scholar] [CrossRef]
- Al-Saffar, A.; Awang, S.; Tao, H.; Omar, N.; Al-Saiagh, W.; Al-bared, M. Malay sentiment analysis based on combined classification approaches and senti-lexicon algorithm. PLoS ONE 2018, 13, e0194852. [Google Scholar] [CrossRef]
- Balaguer, P.; Teixidó, I.; Vilaplana, J.; Mateo, J.; Rius, J.; Solsona, F. CatSent: A catalan sentiment analysis website. Multimed. Tools Appl. 2019, 78, 28137–28155. [Google Scholar] [CrossRef]
- Smetanin, S. The applications of sentiment analysis for russian language texts: Current challenges and future perspectives. IEEE Access 2020, 8, 110693–110719. [Google Scholar] [CrossRef]
- Osorio Angel, S.; Peña Pérez Negrón, A.; Espinoza-Valdez, A. Systematic literature review of sentiment analysis in the spanish language. Data Technol. Appl. 2021, 55, 461–479. [Google Scholar] [CrossRef]
- Pota, M.; Ventura, M.; Catelli, R.; Esposito, M. An effective bert-based pipeline for twitter sentiment analysis: A case study in italian. Sensors 2021, 21, 133. [Google Scholar] [CrossRef] [PubMed]
- Ranathunga, S.; Liyanage, I.U. Sentiment analysis of sinhala news comments. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–23. [Google Scholar] [CrossRef]
- Kydros, D.; Argyropoulou, M.; Vrana, V. A content and sentiment analysis of greek tweets during the pandemic. Sustainability 2021, 13, 16150. [Google Scholar] [CrossRef]
- Obiedat, R.; Al-Darras, D.; Alzaghoul, E.; Harfoushi, O. Arabic aspect-based sentiment analysis: A systematic literature review. IEEE Access 2021, 9, 152628–152645. [Google Scholar] [CrossRef]
- Aydln, C.R.; Güngör, T. Sentiment analysis in Turkish: Supervised, semi-supervised, and unsupervised techniques. Nat. Lang. Eng. 2021, 27, 455–483. [Google Scholar] [CrossRef]
- Khan, L.; Amjad, A.; Afaq, K.M.; Chang, H. Deep sentiment analysis using CNN-LSTM architecture of English and Roman Urdu text shared in social media. Appl. Sci. 2022, 12, 2694. [Google Scholar] [CrossRef]
- Fujihira, K.; Horibe, N. Multilingual sentiment analysis for web text based on word to word translation. In Proceedings of the 2020 9th International Congress on Advanced Applied Informatics, IIAI-AAI, Kitakyushu, Japan, 1–15 September 2020; pp. 74–79. [Google Scholar] [CrossRef]
- Baliyan, A.; Batra, A.; Singh, S.P. Multilingual sentiment analysis using RNN-LSTM and neural machine translation. In Proceedings of the 2021 8th International Conference on Computing for Sustainable Global Development, INDIACom, New Delhi, India, 17–19 March 2021; pp. 710–713. [Google Scholar] [CrossRef]
- Ji, Z.; Pi, H.; Wei, W.; Xiong, B.; Wozniak, M.; Damasevicius, R. Recommendation based on review texts and social communities: A hybrid model. IEEE Access 2019, 7, 40416–40427. [Google Scholar] [CrossRef]
- Omoregbe, N.A.I.; Ndaman, I.O.; Misra, S.; Abayomi-Alli, O.O.; Damaševičius, R. Text messaging-based medical diagnosis using natural language processing and fuzzy logic. J. Healthc. Eng. 2020, 2020, 8839524. [Google Scholar] [CrossRef]
- Liapis, C.M.; Karanikola, A.; Kotsiantis, S. A multi-method survey on the use of sentiment analysis in multivariate financial time series forecasting. Entropy 2021, 23, 1603. [Google Scholar] [CrossRef]
- Agüero-Torales, M.M.; Abreu Salas, J.I.; López-Herrera, A.G. Deep learning and multilingual sentiment analysis on social media data: An overview. Appl. Soft Comput. 2021, 107, 107373. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Sattar, K.; Umer, Q.; Vasbieva, D.G.; Chung, S.; Latif, Z.; Lee, C. A multi-layer network for aspect-based cross-lingual sentiment classification. IEEE Access 2021, 9, 133961–133973. [Google Scholar] [CrossRef]
- Kapočiūtė-Dzikienė, J.; Damaševičius, R.; Woźniak, M. Sentiment analysis of Lithuanian texts using traditional and deep learning approaches. Computers 2019, 8, 4. [Google Scholar] [CrossRef] [Green Version]
- Kapočiūtė-Dzikienė, J.; Damaševičius, R.; Woźniak, M. Sentiment Analysis of Lithuanian Texts using Deep Learning Methods. Proceedings of the ICIST 2018: Information and Software Technologies, Vilnius, Lithuania, 4–6 October 2018; Communications in Computer and Information Science Book Series; Springer: Cham, Switzerland, 2018; Volume 920. [Google Scholar] [CrossRef]
- Sarkar, A.; Reddy, S.; Iyengar, R.S. Zero-shot multilingual sentiment analysis using hierarchical attentive network and BERT. In Proceedings of the NLPIR 2019: 2019 the 3rd International Conference on Natural Language Processing and Information Retrieval, Tokushima, Japan, 28–30 June 2019; ACM International Conference Proceeding Series. pp. 49–56. [Google Scholar] [CrossRef]
- Xu, Y.; Cao, H.; Du, W.; Wang, W. A survey of cross-lingual sentiment analysis: Methodologies, models and evaluations. Data Sci. Eng. 2022. [Google Scholar] [CrossRef]
- Syed, A.A.; Gaol, F.L.; Matsuo, T. A survey of the state-of-the-art models in neural abstractive text summarization. IEEE Access 2021, 9, 13248–13265. [Google Scholar] [CrossRef]
- Tiwari, D.; Nagpal, B. KEAHT: A Knowledge-Enriched Attention-Based Hybrid Transformer Model for Social Sentiment analysis. New Gener. Comput. 2022, 11, 1–38. [Google Scholar] [CrossRef]
- Jebbara, S.; Cimiano, P. Zero-shot cross-lingual opinion target extraction. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 2486–2495. [Google Scholar] [CrossRef]
- Sitaula, C.; Basnet, A.; Maintali, A.; Shahi, T.B. Deep Learning-Based Methods for Sentiment Analysis on Nepali COVID-19-Related Tweets. Comput. Intell. Neurosci. 2021, 2021, 215884. [Google Scholar] [CrossRef]
- Ekman, P. Basic Emotions. In Handbook of Cognition and Emotion; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 1999; Chapter 3; pp. 45–60. [Google Scholar] [CrossRef]
- Plutchik, R. A general psychoevolutionary theory of emotion. In Theories of Emotion; Elsevier: Amsterdam, The Netherlands, 1980. [Google Scholar]
- Romera-Paredes, B.; Torr, P.H.S. An embarrassingly simple approach to zero-shot learning. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 3, pp. 2142–2151. [Google Scholar]
- Facebook/Bart-Large-Mnli Hugging Face. Available online: https://huggingface.co/facebook/bart-large-mnli (accessed on 26 March 2022).
- Yin, W.; Hay, J.; Roth, D. Benchmarking Zero-shot Text Classification: Datasets, Evaluation and Entailment Approach. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP/IJCNLP), Hong Kong, China, 3–7 November 2019; Volume 1, pp. 3912–3921. [Google Scholar] [CrossRef]
- Oigele/Fb_Improved_Zeroshot Hugging Face. Available online: https://huggingface.co/oigele/Fb_improved_zeroshot (accessed on 26 March 2022).
- Digitalepidemiologylab/Covid-Twitter-Bert-V2-Mnli Hugging Face. Available online: https://huggingface.co/digitalepidemiologylab/covid-twitter-bert-v2-mnli (accessed on 26 March 2022).
- Müller, M.; Salathé, M.; Kummervold, P.E. COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter. arXiv 2020, arXiv:2005.07503. [Google Scholar]
- Joeddav/Bart-Large-Mnli-Yahoo-Answers Hugging Face. Available online: https://huggingface.co/joeddav/bart-large-mnli-yahoo-answers (accessed on 26 March 2022).
- Rosenthal, S.; Nakov, P.; Kiritchenko, S.; Mohammad, S.M.; Ritter, A.; Stoyanov, V. SemEval-2015 task 10: Sentiment analysis in Twitter. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval), Denver, CO, USA, 4–5 June 2015; pp. 451–463. [Google Scholar]
- Robnik-Šikonja, M.; Reba, K.; Mozetic, I. Cross-lingual transfer of sentiment classifiers. Slovenscina 2.0 2021, 9, 1–25. [Google Scholar] [CrossRef]
- Peng, S.; Cao, L.; Zhou, Y.; Ouyang, Z.; Yang, A.; Li, X.; Yu, S. A survey on deep learning for textual emotion analysis in social networks. Digit. Commun. Netw. 2021, in press. [Google Scholar] [CrossRef]
- Sharma, T.; Kaur, K. Benchmarking deep learning methods for aspect level sentiment classification. Appl. Sci. 2021, 11, 542. [Google Scholar] [CrossRef]
- Etaiwi, W.; Suleiman, D.; Awajan, A. Deep learning based techniques for sentiment analysis: A survey. Informatica 2021, 45, 89–95. [Google Scholar] [CrossRef]
- Luo, S.; Gu, Y.; Yao, X.; Fan, W. Research on text sentiment analysis based on neural network and ensemble learning. Rev. Intell. Artif. 2021, 35, 63–70. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Christopher Potts, C. Learning Word Vectors for Sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL 2011), Portland, OR, USA, 19–24 June 2011. [Google Scholar]
- Go, A.; Bhayani, R.; Huang, L. Twitter Sentiment Classification Using Distant Supervision; CS224N Project Report; Stanford: Stanford, CA, USA, 2009. [Google Scholar]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 Task 4: Sentiment analysis in Twitter. arXiv 2019, arXiv:1912.00741. [Google Scholar]
- Tesfagergish, S.G.; Kapočiūtė-Dzikienė, J. Part-of-speech tagging via deep neural networks for northern-ethiopic languages. Inf. Technol. Control. 2020, 49, 482–494. [Google Scholar] [CrossRef]









| Method | Benefit | Solution | Complexity |
|---|---|---|---|
| BERT | Pre-trained model in more than 100 languages and it can be tuned by adding one output layer | Question answering, Abstract summarization | Learns contextual relation between words in a sentence/text |
| XLM-R | Trained in around 100 different languages | Cross-lingual transfer tasks | It does not require lang tensor to understand which language is used, and should be able to determine the correct language from input ids |
| ELMo | Improves functions across vast NLP tasks | Answer questions, Textual entailment, Sentiment Analysis | Pre-trained on a huge text-corpus and learned functions from deep bi-directional models (biLM) |
| XLNet | Unlike BERT it does not need to undergo pre-train fine tuning. | Sentiment Analysis, Question answering, Text classification | Large bidirectional transformer with improved training methodology in terms of large amount data and more computational power to achieve better than BERT prediction |
| Zero-Shot classification | No training data needed | Text Classification | It classifies objects to a different label that the classifier has not been trained on. |
| Paper | Dataset | Methods | Results |
|---|---|---|---|
| Choi et al. [16] | STS benchmark (STSb), Korean (KorSTS), SemEval-2017 Spanish and SemEval-2017 Arabic | SLM RoBERTa (SLM-R) that extend semantic textual similarity (STS), Machine reading comprehension (MRC), Sentiment analysis, and Alignment of sentence embeddings under various cross-lingual settings. | 86.38% when the Korean language-tuned model is evaluated using the English dataset. |
| Pelicon et al. [15] | Slovene: SentiNews dataset and Croatian dataset | Multilingual BERT model for 3-class sentiment classification | The Slovene language-trained model achieved the precision of 59.00 ± 1.62 and F1-score of 52.41 ± 2.58, when evaluated on the Croatian language dataset. |
| Phan et al. [17] | 6 languages in Restaurant Domain: English, Russian, Dutch, Spanish, Turkish and French (SemEval 2016-Task 5) | Two main sub-tasks of aspect-based sentiment analysis task are aspect category detection, and opinion target expression using mBERT and XLM-R models | 78.94% using the XLM-R English-trained model on the Dutch dataset. |
| Priban et al. [19] | Movie review dataset (CSFD) Facebook dataset (FB) and Product review dataset (Mallcz) | A binary classification task using BERT-based models (eight models, five of them are multilingual). In the cross-lingual experiment, they tested the ability of four multilingual models to transfer knowledge between English and Czech sentiment classification | 91.61 ± 0.06% when trained on English and tested on Czech, and 93.98 ± 0.10% when trained on Czech and tested on English |
| Kumar et al. [18] | SemEval 2017 dataset Task 4 (3-class: Positive, Negative and Neutral) and two Hindi movie and Product reviews | Fine-tuned XLM-RoBERTa model | Cross lingual contextual word embedding and zero-shot transfer learning in projection prediction from resource-rich English to resource-poor Hindi language achieved 60.93% accuracy. |
| Liang et al. [13] | 9 emotion labels: sadness, joy, anger, disgust, fear, surprise, shame, guilt and love. | Unsupervised lexicon-based learning. Top-K based: selects most representative words and designs a distance weighted word vector method to calculate similarity. Weight-based: gives more weight to emotional words and lower weight to noisy words | F1-score is 14.20 (Top-k based), and 16.30 (weigh-based) |
| Jebbara et al. [47] | SemEval 2016 Task-5. 5 languages: Dutch, English, Russian, Spanish and Turkish | Multilayer CNN for the sequence tagging model. Trained in one language and tested in another language that shares a common vector space. | F1-score for the zero-shot cross-language (from English to Spanish) learning from a single source to a target is 0.5 |
| Sitaula et al. [48] | NepCOV19Tweets (3-class: positive, neutral and negative) | Ensemble CNN of three CNN models CNNft = CNNfastText(X) CNNds = CNNdomainSpecific(X) CNNda = CNNdomainAgnostic(X) | The ensemble of the three CNN models achieves the highest accuracy of 68.7% |
| Emotion Sets | Emotions |
|---|---|
| First Set | Anger, sadness, disgust, fear, joy, happiness |
| Second Set | Admiration, affection, anguish, caution, confusion, desire, disappointment, attraction, envy, excitement |
| Third Set | Grief, hope, horror, joy, love, loneliness, pleasure, fear, generosity, pleasure |
| Fourth Set | Rage, relief, sadness, satisfaction, sorrow, wonder, sympathy, shame, terror, panic |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tesfagergish, S.G.; Kapočiūtė-Dzikienė, J.; Damaševičius, R. Zero-Shot Emotion Detection for Semi-Supervised Sentiment Analysis Using Sentence Transformers and Ensemble Learning. Appl. Sci. 2022, 12, 8662. https://0-doi-org.brum.beds.ac.uk/10.3390/app12178662
Tesfagergish SG, Kapočiūtė-Dzikienė J, Damaševičius R. Zero-Shot Emotion Detection for Semi-Supervised Sentiment Analysis Using Sentence Transformers and Ensemble Learning. Applied Sciences. 2022; 12(17):8662. https://0-doi-org.brum.beds.ac.uk/10.3390/app12178662
Chicago/Turabian StyleTesfagergish, Senait Gebremichael, Jurgita Kapočiūtė-Dzikienė, and Robertas Damaševičius. 2022. "Zero-Shot Emotion Detection for Semi-Supervised Sentiment Analysis Using Sentence Transformers and Ensemble Learning" Applied Sciences 12, no. 17: 8662. https://0-doi-org.brum.beds.ac.uk/10.3390/app12178662