1. Introduction
Word embedding maps a word into a vector space, playing an important role in natural language processing (NLP). Word vectors contain rich information, such as local contextual information [
1], global co-occurrence information [
2], and global contextual information [
3]. Moreover, word embedding can apply to many NLP tasks, such as sentiment analysis [
4,
5,
6,
7,
8], part-of-speech tagging [
9], and named entity recognition [
10]. It can also apply to many interdisciplinary tasks, such as influence maximization [
11] and emotion role identification [
12].
Word embedding learned by deep learning carries contextual semantic and syntactic information, which is beneficial for NLP tasks. Sitaula et al. [
13] evaluated many machine learning and deep learning methods on sentiment analysis tasks. However, for feature-based word embedding, such as Word2Vec [
1], if two words with opposite sentiment polarity have similar context in a corpus, the performance of word embedding may not be so good [
14,
15]. This is because feature-based word embeddings only assign a unique word embedding to each word and cannot generate word embeddings based on the context in downstream tasks. For example, the words “good” and “terrible” from two different sentences, i.e., “The weather is good today” and “The weather is terrible today,” have similar contexts in a corpus and have similar word embeddings. In this situation, sentiment classification models cannot determine which is a positive or negative sentence. Yu et al. [
15] concluded that about 30% of the top 10 semantically similar words have opposite sentiment orientations. In most tasks, sentiments could divide into two (positive, negative) or three dimensions (positive, neutral, and negative). Ekman [
16] even divided sentiments into six categories (anger, disgust, fear, happiness, sadness, and surprise). Based on the six categories, Xu [
17] further divided sentiments into seven categories (anger, disgust, fear, sadness, happiness, good, and surprise). The latest research of Google [
18] found that sentiments could divide into 28 categories. However, the sentiment dimensions are also much fewer than the dimensions of word embedding. The dimensions of Word2Vec [
1] and global vectors for word representation (GloVe) [
2] are usually 300; the dimensions of the bidirectional encoder representations from the transformers base (BERT-base) [
3] number 768; and the dimensions of BERT-large [
3] number 1024. Thus, the dimensions of sentiment and word embedding are different.
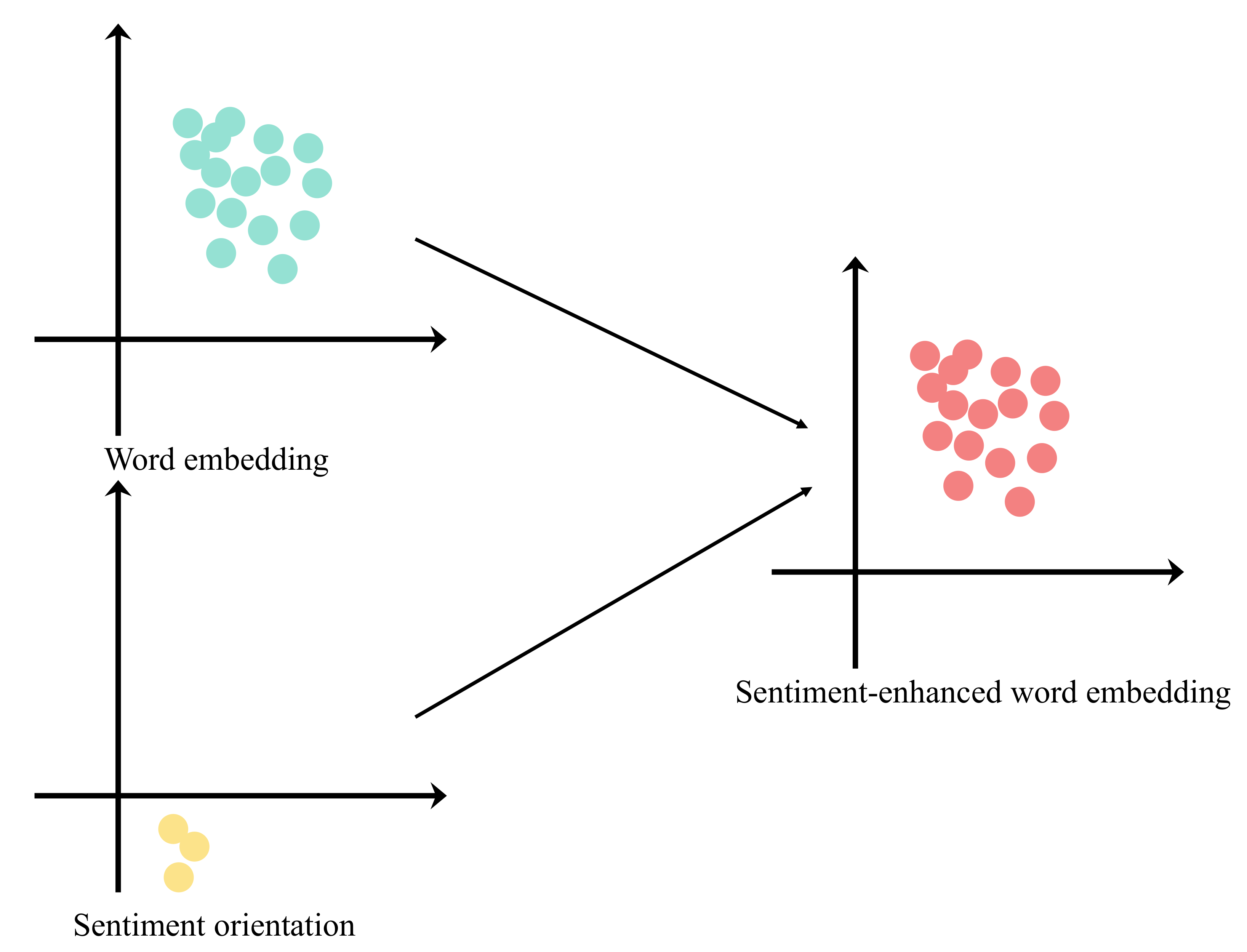
Sentiment enhancement is a way of injecting sentiments into word embedding, making word embedding contain sentiment information. However, sentiment enhancement concerning sentiment and word embedding faces two challenges (see
Figure 1).
- 1.
Due to the different dimensions of sentiment word embeddings and sentiment orientations, they are hard to fuse into one vector.
- 2.
Since sentiment and word embeddings belong to two different vector spaces, sentiment classification models could not directly operate on them.
To solve the above problems, we expect to find a method to build the mapping relationship between words and their sentiment orientations in sentiment lexicons and fuse sentiment information into these words. Fortunately, we are inspired by translations in the embedding space (TransE) [
19] and contrastive learning [
20,
21]. TransE is a knowledge graph embedding method. It shortens the distance between two related entities and increases the distance between two unrelated entities in vector space. Meanwhile, contrastive learning narrows the distance between positive examples and increases the distance between negative examples in vector space. The bootstrap your own latent (BYOL) [
20] minimizes the distance between two similar images; the supervised contrastive pre-training (SCAPT) [
21] used supervised contrastive learning to cluster explicit and implicit positive sentiments, cluster explicit and implicit negative sentiments, and separated these two clusters. By borrowing these ideas, we propose a novel sentiment-enhanced word embedding (S-EWE) method to improve the performances of sentiment classification models. Specifically, we convert words in the sentiment lexicon to word embeddings and arrange each word embedding for a sentiment mapping vector. Then, we add original word embeddings and their sentiment mapping vectors to obtain the sentiment-enhanced word embeddings with the information of word and sentiment. Thirdly, we adopt one fully connected layer to reduce the dimensions of sentiment-enhanced word embedding to get the predicted sentiment orientations. Finally, we calculate the loss of the predicted and true sentiment orientations by the cross-entropy function. We further train the sentiment mapping vectors through backpropagating the loss so that the trained sentiment mapping vectors can find the mapping relationship between words in sentiment lexicons and their sentiment orientations. Under different sentiment classification models, we confirmed the effectiveness of the S-EWE method. The main contributions are as follows:
- 1.
A new sentiment-enhanced word embedding method is proposed. This method establishes the mapping relationship between words and their sentiment orientations by vector addition.
- 2.
Abundant experiments were performed on TextCNN [
22], TextRNN [
23], TextRCNN [
24], TextBiRCNN [
24], an attention-based bidirectional CNN-RNN deep model (ABCDM) [
25], and CNN-LSTM [
26] using Word2Vector [
1]; and GloVe [
2] with or without sentiment-enhanced word embeddings on the semantic evaluation 2013 (SemEval-2013) dataset [
27] and the Stanford sentiment treebank (SST-2) dataset [
28]. Experimental results show that sentiment-enhanced word embeddings can improve the ability of these models’ sentiment classification.
The subsequent parts of this paper are organized as follows.
Section 2 introduces the related work. The sentiment-enhanced word embedding method is shown in
Section 3. Datasets, empirical results, and model analysis are presented in
Section 4. Finally, we summarize our paper and put forward a future outlook in
Section 5.
3. The Proposed Method and Its Applications on Downstream Tasks
This section illustrates a novel sentiment-enhanced word embedding method and its applications on downstream tasks.
Figure 2 shows their workflows. For example, in the pre-training stage, given the word “happy” and its sentiment orientation “1” in a sentiment lexicon, we assign “happy” a randomly initialized sentiment mapping vector
. Then, we add the word embedding of “happy” to the sentiment mapping vector and obtain a sentiment-enhanced word embedding. We feed it to a fully connected layer, predicting the probability of the “happy” sentiment label. By making a loss between the predicted sentiment label and the gold standard (i.e., 1), we can train
by backpropagation. The
will be the unique sentiment mapping vector for “happy.” In the application stage, we add the well-trained
and the original word embedding of “happy”; we obtain the sentiment-enhanced embedding of “happy” and apply the sentiment-enhanced embedding into the embedding layer of the downstream tasks.
3.1. The Sentiment-Enhanced Word Embedding Method
The S-EWE method aims to establish the mapping relationship between words in sentiment lexicons and their sentiment orientations to obtain trained sentiment-enhanced word embeddings for downstream tasks. When we convert one word to a word embedding, the dimensions of the word embedding are much larger than those of the sentiment orientation, and they belong to two different vector spaces. Therefore, we assign a sentiment mapping vector to the word embedding. This sentiment mapping vector can help word embedding find the mapping relationship between it and its sentiment orientation.
Let the
be a set of all words in a sentiment lexicon, and
be a set of sentiment orientations of all words in the sentiment lexicon. Given a word
, its word embedding
, and its sentiment orientation
, we assign a sentiment mapping vector
to the word embedding
. Then, the goal of the S-EWE method is to solve the mapping relationship function among
and
, denoted by
.
Figure 3 shows the running process of the S-EWE method. The method implements
by four modules, including the embedding layer, addition layer, MLP layer, and loss function as follows.
3.1.1. Embedding Layer
The embedding layer converts words to word embeddings, which is the first step in finding the relationship between
and
. Let sentiment words
where
, and
n is the total number of sentiment words, and their sentiment orientations
. Then, we first turn words into word embeddings as follows.
where
is the word embedding of the word
(
is the dimension of the embedding size), and
is the function that turns words into their word embeddings.
3.1.2. Addition Layer
The addition layer implements simple addition between vectors. We define a sentiment mapping matrix
, where
is the mapping relationship vector between
and
. Let
be the sentiment-enhanced word embeddings of sentiment words
, where
. Then, by adding word embedding
to its sentiment mapping vector
, we can obtain the sentiment-enhanced word embedding
of the word
as follows.
Then, the sentiment-enhanced word embedding of
is as follows.
3.1.3. MLP Layer
The MLP layer contains one fully connected network. It will reduce the dimensions of sentiment-enhanced word embeddings and map them and their sentiment orientation labels into the same vector space. Considering that the addition of vectors does not change the vectors’ dimensions, the dimensions of
are still much more than those of
. We use one MLP to reduce the dimensionality of the sentiment-enhanced word vector. The MLP will map the sentiment-enhanced word embedding and label to the same vector space [
38]. The predicted sentiment orientation label of the word
, denoted by
, is as follows.
where
and
are the weight matrix and bias of the output layer, respectively.
3.1.4. Loss Function
The loss function measures the difference between true sentiment orientation labels in a sentiment lexicon and predicted sentiment orientation labels of words at the final module of the S-EWE method. We use the cross-entropy function
to calculate the loss, where
N is the total number of samples.
In order to better learn the mapping relationship between original word embeddings and their true sentiment orientation labels in the S-EWE method, we freeze the word embedding layer. All word embeddings and true sentiment orientation labels are fixed in this case. The parameters
W,
b, and sentiment mapping matrix are trainable. By backpropagation, the method can better learn the sentiment mapping matrix and find the mapping relationship between original word embeddings and their corresponding sentiment orientations. After training, we can obtain the well-trained sentiment mapping matrix, denoted as
. Finally, the well-trained sentiment-enhanced word embeddings, denoted by
, are obtained as follows.
The detailed running procedure of the S-EWE method is described in Algorithm 1.
| Algorithm 1 The S-EWE algorithm. |
| Input: Set of words in a sentiment lexicon , set of sentiment orientations in the sentiment lexicon Y, number of epochs denoted by , batches denoted by |
| Output: Well-trained sentiment-enhanced word embeddings |
| 1: Initialization xavier Gaussian initialization |
| 2: // Equation (1) |
| 3: |
| 4: while do |
| 5: for do |
| 6: // Equation (2) |
| 7: // Equation (4) |
| 8: // Equation (5) |
| 9: Backpropagation |
| 10: Optimize parameters |
| 11: end for |
| 12: |
| 13: Obtain well-trained sentiment-enhanced word embeddings |
| 14: end while |
| 15: return well-trained sentiment mapping matrix // Equation (6)
|
3.2. Applications of the Sentiment-Enhanced Word Embedding Method on Downstream Tasks
Since the S-EWE method needs to work with a sentiment lexicon, we need a robust sentiment lexicon. We selected the extended version of Affective Norms of English Words (E-ANEW) [
50] and the Subjectivity Clue Lexicon [
51] as our base sentiment lexicons, for they are well-known English sentiment lexicons. For the E-ANEW [
50], we define sentiment words with sentiment intensity between
as negative, sentiment words with sentiment intensity of 5 as neutral, and sentiment words with sentiment intensity between
as positive. For the Subjectivity Clue Lexicon [
51], we directly extract the sentiment orientation (positive, neutral, negative).
To improve the robustness of these two lexicons, we adopted the following four rules to integrate them: (1) if a word appears in only one lexicon, then the word is directly added into the fused lexicon; (2) if a word has the same sentiment orientation in the two lexicons, then the word is directly added into the fused lexicon; (3) if the sentiment orientation of a word is neutral in one lexicon and the sentiment orientation is not neutral in another lexicon, then the word is assigned with non-neutral sentiment orientation and added into the fused lexicon; and (4) if a word has opposite sentiment orientations (positive and negative) in the two lexicons, then the word is discarded and does not belong to the fused lexicon. After finishing the above four rules, we can obtain
the fused lexicon.
Table 1 shows the details of the E-ANEW, Subjectivity Clue Lexicon, and fused lexicon, respectively.
The words in the sentiment lexicon may not all appear in the corpus in most cases. Meanwhile, the S-EWE method will waste some storage space to train the words in the lexicon and may not obtain good sentiment-enhanced word embeddings. Inspired by sentiment-aware word embeddings (SAWE) [
14], we extract all words from the corpus and build a
final lexicon by the following two rules. (1) If a word appears in both the corpus and the fused lexicon, we directly add it and its corresponding sentiment orientation in the fused lexicon to the final lexicon. (2) If a word appears in the corpus but not in the fused lexicon, we add it to the final lexicon with the neutral sentiment.
Based on the fused and final lexicons, the sentiment-enhanced word embeddings are applied to downstream tasks for sentiment analysis, as shown in
Figure 4. When the sentiment-enhanced word embeddings are trained by the S-EWE method on the fused lexicon (respectively, the final lexicon), we denote the well-trained embeddings by
(respectively,
).
Figure 4 shows the applications of the sentiment-enhanced word embeddings trained by the S-EWE method based on the final and fused lexicons for downstream tasks.
Figure 4a shows how we apply
to downstream tasks, and
Figure 4b represents how we apply
to downstream tasks. When the fused lexicon does not contain some words in the corpus, we adopt the following two methods to get the embedding layer of the downstream sentiment analysis models (
Figure 4a). (1) If a word is in the fused lexicon, we input the well-trained sentiment-enhanced word embedding by the S-EWE method in the fused lexicon as the word embedding with sentiment information into the embedding layer of the downstream tasks. (2) If a word is not in the fused lexicon, we use the original word embedding as the word embedding with sentiment information into the embedding layer of the downstream tasks. When the final lexicon contains all words in the corpus (
Figure 4b), we can directly input the well-trained sentiment-enhanced word embeddings by the S-EWE method in the final lexicon as the word embedding with sentiment information into the embedding layer of the downstream tasks.
4. Experiment
4.1. Datasets and Evaluation Metrics
The SemEval-2013 [
27] and SST-2 (the preprocessed SST-2 dataset was selected as an experimental dataset; the preprocessed data are at
https://github.com/clairett/pytorch-sentiment-classification, accessed on 26 November 2021) [
28] datasets were selected as experimental datasets. The SemEval-2013 dataset is a Tweet sentiment analysis dataset containing five categories of labels (positive, negative, neutral, objective, and objective-or-neutral). Our experiment only considered the positive and negative data by SemEval-2013 (binary). The SST-2 dataset contains movie reviews containing two labels: (1) positive and negative, and (2) very negative, negative, neutral, positive, and very positive. From this dataset, our experiment only used the positive and negative data.
Table 2 and
Table 3 show the details of all the datasets.
The accuracy and macro-F1 score [
14] were adopted to evaluate the performance of the proposed S-EWE method. Let
(resp.
) be the number of samples whose true labels and model prediction labels are both positive (resp. negative), and let
(resp.
) be the number of samples whose true labels are positive (resp. negative) and model prediction labels are negative (resp. positive). Accuracy and macro-F1 score are defined as
and
where
and
stand for the precision, recall, and F1 scores of the category
i; and
k is the total number of categories.
4.2. Comparison Experimental Models and Their Training Details
TextCNN [
22], TextRNN [
23], TextRCNN (our main reference codes come from:
https://github.com/649453932/Chinese-Text-Classification-Pytorch, accessed on 5 December 2021) [
24], ABCDM [
25], and CNN-LSTM [
26] were selected as sentiment classification models to verify the effectiveness of trained sentiment-enhanced word embeddings by the S-EWE method in fused and final lexicons.
TextCNN. TextCNN [
22] convolves word vectors in the convolution kernel. It obtains the feature maps of these convolution results through max pooling.
TextRNN. TextRNN [
23] is a bidirectional LSTM. It inputs word embeddings and outputs the hidden state of each word.
TextRCNN. TextRCNN [
24] uses LSTM (resp. BiLSTM) to obtain the forward (resp. bidirectional) hidden state. It applies max pooling to get sentence embeddings.
ABCDM. ABCDM [
25] adopts BiLSTM and BiGRU to encode one sentence to obtain long-term and short-term hidden states. Then, it uses two parallel attention layers to obtain the attention score of each hidden state. Finally, ABCDM applies 1D-CNN, 1D-max pooling, and 1D-average pooling to get the final sentence embedding.
CNN-LSTM. CNN-LSTM [
26] uses TextCNN [
22] to obtain local sentence embedding, and adopts LSTM to get the long-term information.
4.3. Experimental Results
Let the sentiment classification (SC) models enhanced by
and
be denoted by SC
and SC
, respectively. When Word2Vec was used to pre-train word embeddings for sentiment classification tasks on SemEval-2013 [
27] and SST-2 [
28] datasets, the accuracies and macro-F1 scores under the sentiment classification models TextCNN, TextRNN, TextRCNN, TextBiRCNN, ABCDM, and CNN-LSTM with and without
and
are shown in
Table 5. We conclude that: (1) the sentiment classification models with Word2Vec enhanced by
and
had higher accuracies and macro-F1 than the original Word2Vec except for TextRNN and CNN-LSTM; (2) in most cases, the sentiment classification models with Word2Vec enhanced by
achieved the best accuracies and macro-F1 scores on two datasets; (3) TextRNN with Word2Vec enhanced by
and
achieved the same accuracies and macro-F1 scores of the TextRNN with original Word2Vec—that is, the S-EWE method did not improve the performance of TextRNN on the two datasets; and (4) on the two datasets, the variance of the results obtained by the model using the proposed method was minor, indicating that using S-EWE method can make the model more stable.
When GloVe is used to pre-train word embeddings for sentiment classification tasks on SemEval-2013 [
27] and SST-2 [
28] datasets, the accuracy and maro-F1 scores under sentiment classification models, including TextCNN, TextRNN, TextRCNN, TextBiRCNN, ABCDM, and CNN-LSTM, enhanced by
and
are shown in
Table 6. Compared with these results, we can conclude that: (1) the sentiment classification models with GloVe enhanced by
and
had higher accuracies and macro-F1 scores than the original GloVe except for TextRNN; (2) in most cases, the sentiment classification models with GloVe enhanced by
achieved the best accuracies and macro-F1 scores on two datasets; (3) TextRNN is not trainable on these two datasets with the proposed method; and (4) models using our method achieved more robust results on both datasets.
As shown in
Table 5 and
Table 6, TextCNN, TextRCNN, TextBiRCNN, ABCDM, and CNN-LSTM with Word2Vec or GloVe, enhanced by
and
, achieved better classification performances than these models without the sentiment-enhanced word embeddings on the two datasets. In particular, these models with
obtained better classification performances than those with
. TextRNN with Word2Vec or GloVe enhanced by
and
kept the same classification performance as the model without the sentiment-enhanced word embedding on the two datasets. Meanwhile, models using
and
can achieve more robust results on the two datasets.
4.4. Analysis of Convergence Time for Downstream Tasks
Under TextCNN, TextRNN, TextRCNN, TextBiRCNN, ABCDM, and CNN-LSTM using Word2Vec and GloVe with or without
and
on SemEval-2013 and SST-2 datasets, their convergence times were analyzed on one NVIDIA 2080Ti (12GB), as shown in
Table 7. For all baseline models using Word2Vec enhanced by S-EWEs on the SemEval-2013 dataset, the convergence times of TextCNN
, TextRCNN
, and TextBiRCNN
were on average increased by 22.56% over their original models; however, the convergence times of TextRNN
, ABCDM
, and CNN-LSTM
on average decreased by 31.16%. Meanwhile, for all baseline models using Word2Vec enhanced by S-EWEs on the SST-2 dataset, the convergence time of CNN-LSTM
was the most significant increase, by 440.32% over CNN-LSTM; the convergence time of TextRNN
decreased the convergence time of TextRNN by 0.35%; and the convergence times of TextCNN
, TextRCNN
, TextBiRCNN
, and ABCDM
were on average increased by 21.98% of their original models.
For all baseline models using GloVe enhanced by S-EWEs on the SemEval-2013 dataset, the convergence times of TextCNN, TextRCNN, TextBiRCNN, and ABCDM were on average increased by 50.17% compared to their original models. The convergence time of CNN-LSTM was decreased by 26.24% compared to CNN-LSTM. Meanwhile, using GloVe enhanced by S-EWEs on the SST-2 dataset, the convergence times of TextBiRCNN and ABCDM were on average increased by 19.67% compared to their original models; the convergence times of TextCNN, TextRCNN, and CNN-LSTM were on average decreased by 25.34% compared to their original models.
In all baseline models with the S-EWE method, the convergence time of ABCDM was significantly decreased by 51.21% compared to ABCDM on the SemEval-2013 dataset, and the convergence time of CNN-LSTM vastly decreased by 41.34% compared to CNN-LSTM on the SST-2 dataset.
Based on the performances of various sentiment classification models and models’ convergence times, we conclude that the proposed S-EWE method can enhance the ability of sentiment classification on SemEval-2013 and SST-2 datasets.
4.5. Comparisons with the Contextualized Word Embedding Models and the BERT with/without the S-EWEs
The contextualized word embedding models, including BERT [
3] and CoSE-T [
6], were selected to compare with the sentiment-enhanced word embedding method.
BERT [
3]. It is a classic transformer-based [
30] model. Its backbone is the encoder in a transformer. It adopts the masked language model (MLM) and next sentence prediction (NSP) as the pre-training objectives. When it is doing the downstream sentiment analysis task, the hidden state of the special token (CLS) it outputs will go through a pooler layer and output the classification result. We adopt the BERT base as our experimental model.
CoSE-T [
6]. It has two BiGRU layers. In the pre-training stage, the target words, word sentiment, and sentence sentiment are predicted by training on the labeled sentiment corpus with a sentiment lexicon. In the fine-tuning stage, the pre-trained word embedding and the hidden states of the two BiGRUs are concatenated as the sentiment representation. Finally, the representation will be fed into one fully connected layer with a softmax function to predict sentence sentiment.
BERT with S-EWEs. We extract the weights in the embedding layer of BERT and use S-EWE and S-EWE to enhance these weights. After enhancing the sentiment of the BERT embeddings, we replace these weights with the S-EWEs. Finally, we feed them into the BERT model.
Table 8 shows the accuracies and macro-F1 values of the BERT and CoSE-T models on SemEval-2013 and SST-2 datasets. From these results, we can observe that: (1) Contextualized word embedding can achieve better results than feature-based word embedding (shown in
Table 5 and
Table 6) in sentiment analysis tasks. Specifically, CoSE-T achieved 90.80% accuracy on the SemEval-2013 dataset and 89.80% accuracy on the SST-2 dataset; BERT achieved 90.80% accuracy and 88.88% macro-F1 on the SemEval-2013 dataset, and 90.38% accuracy and 90.38% macro-F1 on the SST-2 dataset. (2) BERT with S-EWE embeddings performs worse than BERT and CoSE-T without S-EWE embeddings. Specifically, on the SemEval-2013 dataset, BERT
was 9.14% less accurate than BERT and CoSE-T, and 11.34% lower than BERT in macro-F1; BERT
was 14.97% less accurate than BERT and CoSE-T and 20.21% lower than BERT in macro-F1. On the SST-2 dataset, BERT
was 10.39% lower than CoSE-T and 10.97% lower than BERT in accuracy, and 11.34% lower than BERT in macro-F1; BERT
was 17.14% lower than CoSE-T and 17.72% lower than BERT in accuracy, and 17.73% lower than BERT in macro-F1. From these observations, we can conclude that the S-EWE method is unsuitable for enhancing contextualized word embedding. The main reasons are that the S-EWE method only enhances the embedding layer of the model and has no effect on the model itself.
5. Conclusions
This paper proposes a sentiment enhancement method, i.e., the sentiment-enhanced word embedding method. This model finds the relationship between the words in the sentiment lexicon and their corresponding sentiment orientations. After training the sentiment mapping matrix, this matrix and word embeddings are fused as sentiment-enhanced word embeddings. Then, the sentiment-enhanced word embeddings are fed into sentiment classification models to classify the sentiment orientations of sentences on SemEval-2013 and SST-2 datasets. Experimental results show that these models using Word2Vec and GloVe enhanced by the sentiment-enhanced word embeddings perform better than those with original Word2Vec and GloVe embeddings. Moreover, the convergence times of the models using Word2Vec and GloVe enhanced by the sentiment-enhanced word embeddings were acceptable. Since the S-EWE method only enhances the embedding layer of the model and has no effect on the model itself, it does not effectively enhance contextualized word embedding.
In the future, there will be some sustainable research directions. (1) The proposed sentiment mapping embeddings could be considered external knowledge in other sentiment classification models. (2) Since sentiment orientations contain less information than sentiment intensity, sentiment intensity could be considered in the S-EWE method. (3) Since Chinese words contain one or more tokens, various Chinese sentiment-enhanced word embedding methods need further study by expanding the S-EWE method. (4) The methods of injecting sentiment into contextualized word embeddings, such as BERT, need to be used in sentiment analysis.








{kind=link}
{kind=link}
{kind=link}
{kind=link}