


Decision-Refillable-Based Two-Material-View Fuzzy Classification for Personal Thermal Comfort

Abstract
:1. Introduction
2. Introduction of Relevant Domain Knowledge
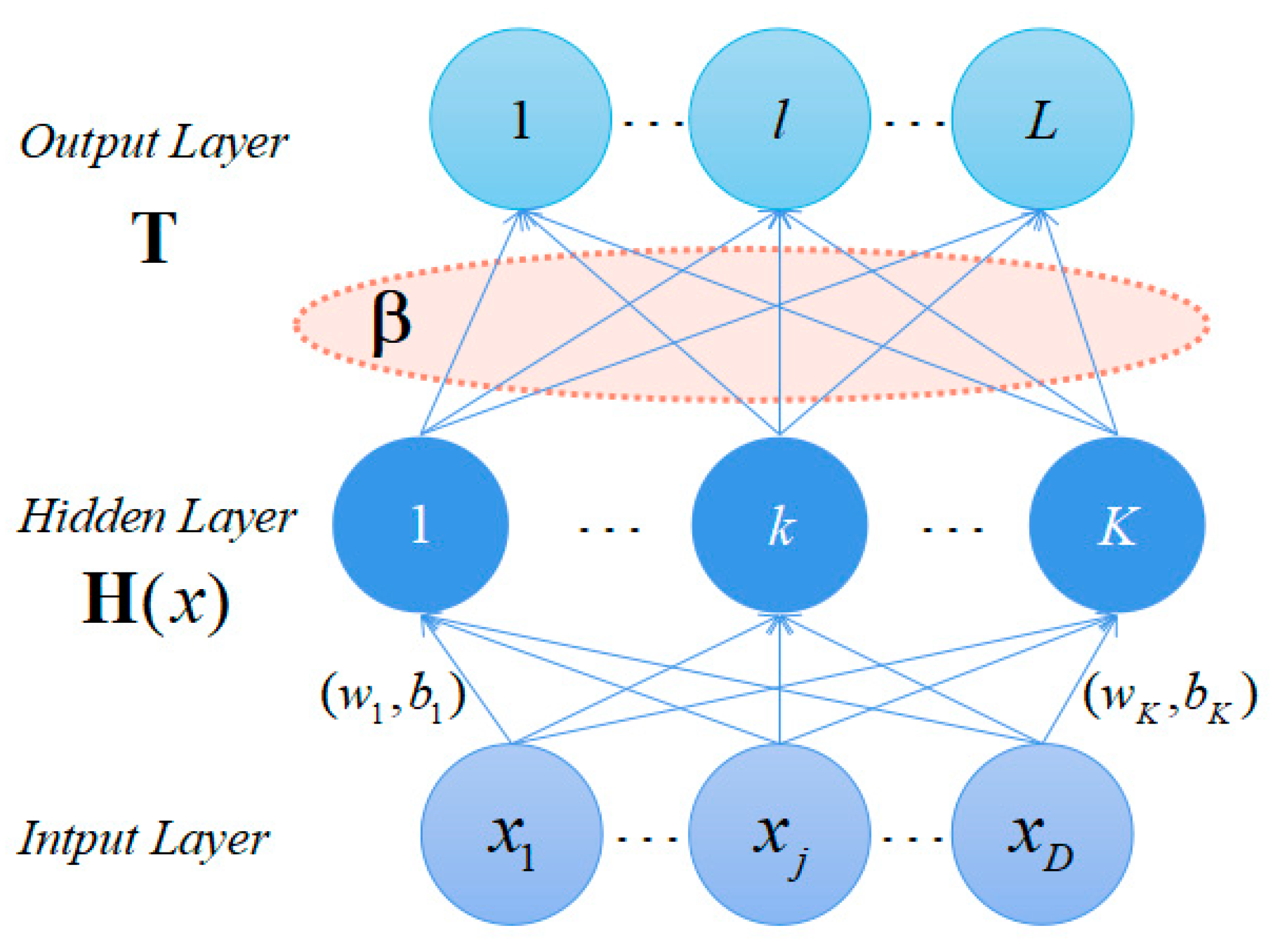
2.1. Classical Zero-Order TSK Fuzzy Classifier
2.2. ELM
3. Our Model
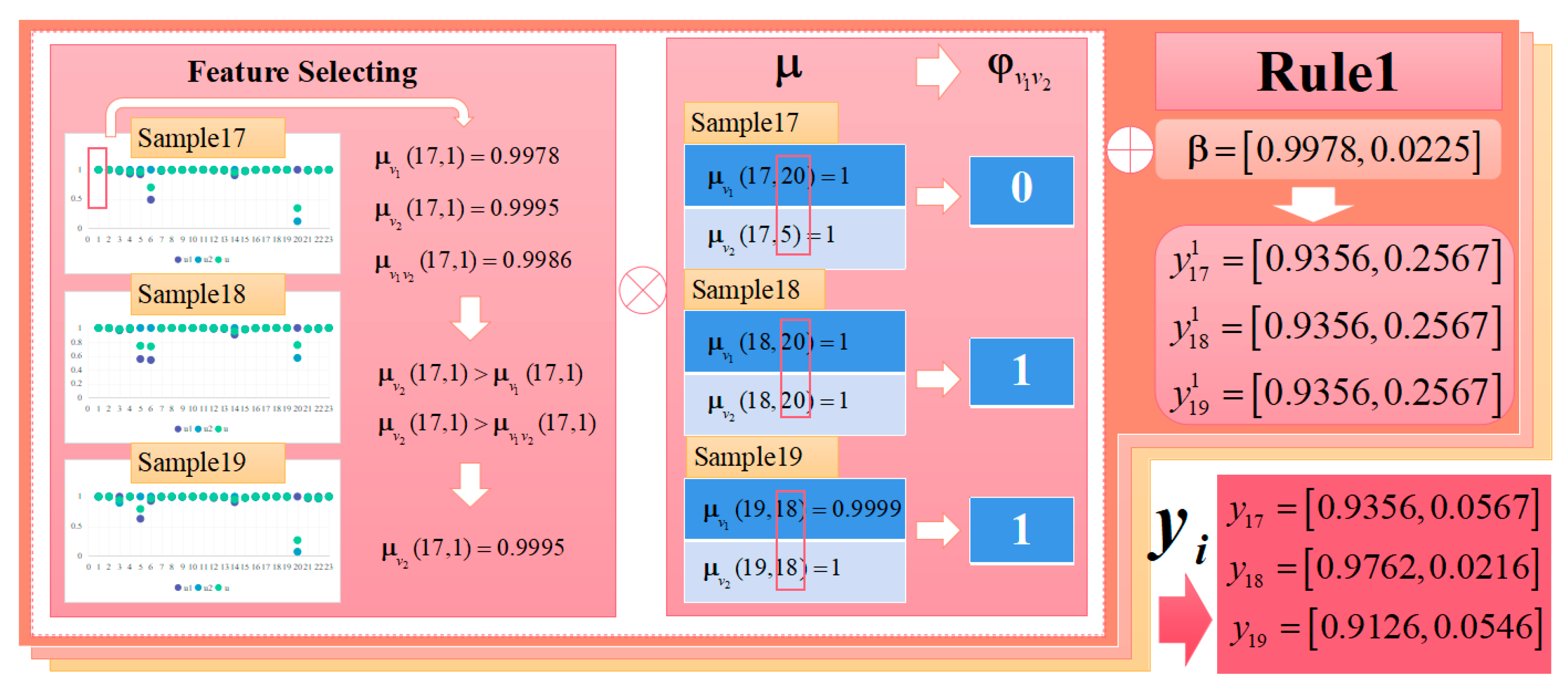
3.1. Construction of the Membership Function under the Joint View
3.2. Construction of the Decision Coefficient Matrix
3.3. Output Rules
3.4. The Algorithm
| Algorithm 1: Training Algorithm Of TMV-TSK-FC |
| Input: The training set , ; The corresponding class label set |
| Step 1: Compute the values of Gaussian membership functions Step 1(a): Compute the values of Gaussian membership functions for each view Step 1(b): Compute the maximum Gaussian membership functions for each view and the mix view |
| Step2: Compute the projection matrix |
| Step 3: For Choose optimized membership functions to compute the following value of the premise of each fuzzy rule Step 3(a): If , Then Step 3(b): If , Then Step 3(c): If , Then Step 3(d): If , Then End For |
| Step 4: Construct a rule layer output matrix H |
| Output: The prediction function of TMV-TSK-FC: |
3.5. Time Complexity Analysis
4. Experiment and Discussion
4.1. Experimental Setup
- a.
- Experimental procedure
- b.
- Characteristics and labels
- c.
- Parameter settings
4.2. Description of the Comparison Algorithm
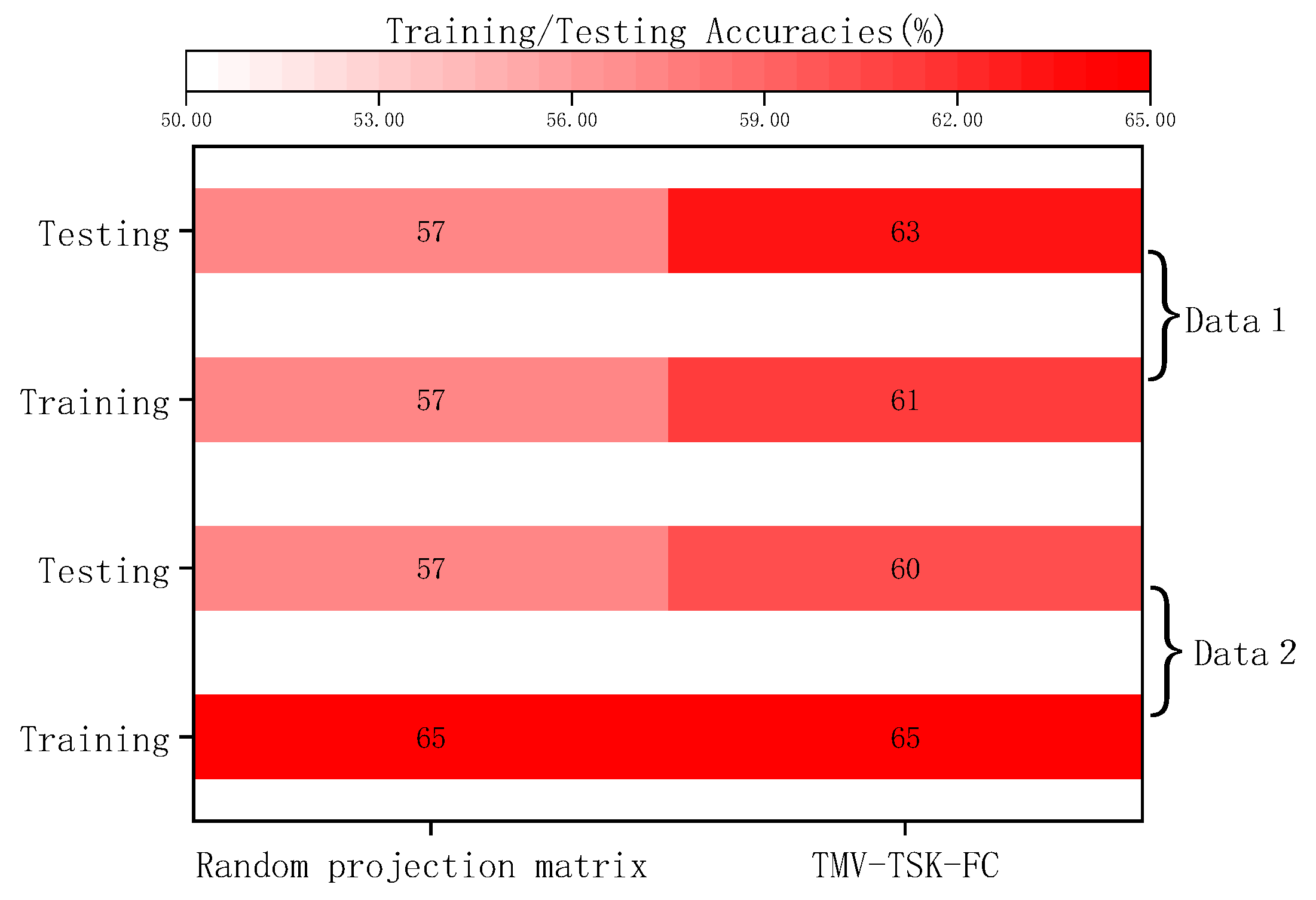
4.3. Performance Evaluation
- (1)
- Classification performance and generalization performance
- (2)
- Optimization method for feature selection
- (3)
- The optimization method of the decision coefficient matrix
4.4. Semantic Interpretability Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J. Integrating IAQ control strategies to reduce the risk of asymptomatic SARS-CoV-2 infections in classrooms and open plan offices. Sci. Technol. Built. Environ. 2020, 26, 1013–1018. [Google Scholar] [CrossRef]
- Tham, K.W.; Willem, H.C. Room air temperature affects occupants’ physiology, perceptions and mental alertness. Build. Environ. 2010, 45, 40–44. [Google Scholar] [CrossRef]
- Zhang, F.; de Dear, R.; Candido, C. Thermal comfort during temperature cycles induced by direct load control strategies of peak electricity demand management. Build. Environ. 2016, 103, 9–20. [Google Scholar] [CrossRef] [Green Version]
- Wargocki, P.; Wyon, D.P.; Sundell, J.; Clausen, G.; Fanger, P.O. The effects of outdoor air supply rate in an office on perceived air quality, sick building syndrome (SBS) symptoms and productivity. Indoor Air 2000, 10, 222–236. [Google Scholar] [CrossRef]
- Wyon, D.P. The effects of indoor air quality on performance and productivity. Indoor Air 2004, 14, 92–101. [Google Scholar] [CrossRef]
- Fisk, W.J.; Rosenfeld, A.H. Estimates of improved productivity and health from better indoor environments. Indoor Air 1997, 7, 158–172. [Google Scholar] [CrossRef]
- Allen, J.G.; Macnaughton, P.; Laurent, J.G.C.; Flanigan, S.S.; Eitland, E.S.; Spengler, J.D. Green buildings and health. Curr. Environ. Health Rep. 2015, 2, 250–258. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klepeis, N.E.; Nelson, W.C.; Ott, W.R.; Robinson, J.P.; Tsang, A.M.; Switzer, P.; Behar, J.V.; Hern, S.C.; Engelmann, W.H. The national human activity pattern survey (NHAPS): A resource for assessing exposure to environmental pollutants. J. Expo. Anal. Environ. Epidemiol. 2001, 11, 231–252. [Google Scholar] [CrossRef] [Green Version]
- Fanger, P.O. Thermal comfort analysis and applications in environmental engineering. In Thermal Comfort Analysis and Applications in Environmental Engineering; McGraw-Hill: New York, NY, USA, 1970. [Google Scholar]
- Yang, B.; Li, X.; Liu, Y.; Chen, L.; Guo, R.; Wang, F.; Yan, K. Comparison of models for predicting winter individual thermal comfort based on machine learning algorithms. Build. Environ. 2022, 215, 108970. [Google Scholar] [CrossRef]
- Wang, Z.; de Dear, R.; Luo, M.; Lin, B.; He, Y.; Ghahramani, A.; Zhu, Y. Individual difference in thermal comfort: A literature review. Build. Environ. 2018, 138, 181–193. [Google Scholar] [CrossRef]
- Yang, B.; Li, X.; Hou, Y.; Meier, A.; Cheng, X.; Choi, J.; Wang, F.; Wang, H.; Wagner, A.; Yan, D.; et al. Non-invasive (non-contact) measurements of human thermal physiology signals and thermal comfort/discomfort poses—A review. Energy Build. 2020, 224, 110261. [Google Scholar] [CrossRef]
- Cheung, T.; Schiavon, S.; Parkinson, T.; Li, P.; Brager, G. Analysis of the accuracy on PMV—PPD model using the ASHRAE Global Thermal Comfort Database II. Build. Environ. 2019, 153, 205–217. [Google Scholar] [CrossRef] [Green Version]
- De Dear, R.J.; Brager, G.S. Developing an adaptive model of thermal comfort and preference. ASHRAE Trans. 1998, 104, 145–167. [Google Scholar]
- Zhou, X.; Xu, L.; Zhang, J.; Niu, B.; Luo, M.; Zhou, G.; Zhang, X. Data-driven thermal comfort model via support vector machine algorithms: Insights from ASHRAE RP-884 database. Energy Build. 2020, 211, 109795. [Google Scholar] [CrossRef]
- Rupp, R.F.; de Dear, R.; Ghisi, E. Field study of mixed-mode office buildings in Southern Brazil using an adaptive thermal comfort framework. Energy Build. 2018, 158, 1475–1486. [Google Scholar] [CrossRef]
- Luo, M.; Cao, B.; Damiens, J.; Lin, B.; Zhu, Y. Evaluating thermal comfort in mixed-mode buildings: A field study in a subtropical climate. Build. Environ. 2015, 88, 46–54. [Google Scholar] [CrossRef]
- Zhang, R.; Liu, D.; Shi, L. Thermal-comfort optimization design method for semi-outdoor stadium using machine learning. Build. Environ. 2022, 215, 108890. [Google Scholar] [CrossRef]
- Irshad, K.; Habib, K.; Kareem, M.W.; Basrawi, F.; Saha, B.B. Evaluation of thermal comfort in a test room equipped with a photovoltaic assisted thermo-electric air duct cooling system. Int. J. Hydrogen Energy 2017, 42, 26956–26972. [Google Scholar] [CrossRef] [Green Version]
- Irshad, K.; Algarni, S.; Jamil, B.; Ahmad, M.T.; Khan, M.A. Effect of gender difference on sleeping comfort and building energy utilization: Field study on test chamber with thermoelectric air-cooling system. Build. Environ. 2019, 152, 214–227. [Google Scholar] [CrossRef]
- Megri, A.C.; El Naqa, I. Prediction of the thermal comfort indices using improved support vector machine classifiers and nonlinear kernel functions. Indoor Built Environ. 2016, 25, 6–16. [Google Scholar] [CrossRef] [Green Version]
- Choi, J.; Yeom, D. Study of data-driven thermal sensation prediction model as a function of local body skin temperatures in a built environment. Build. Environ. 2017, 121, 130–147. [Google Scholar] [CrossRef]
- Li, D.; Menassa, C.C.; Kamat, V.R. Personalized human comfort in indoor building environments under diverse conditioning modes. Build. Environ. 2017, 126, 304–317. [Google Scholar] [CrossRef]
- Chaudhuri, T.; Zhai, D.; Soh, Y.C.; Li, H.; Xie, L. Random forest based thermal comfort prediction from gender-specific physiological parameters using wearable sensing technology. Energy Build. 2018, 166, 391–406. [Google Scholar] [CrossRef]
- Salehi, B.; Ghanbaran, A.H.; Maerefat, M. Intelligent models to predict the indoor thermal sensation and thermal demand in steady state based on occupants’ skin temperature. Build. Environ. 2020, 169, 106579. [Google Scholar] [CrossRef]
- Katić, K.; Li, R.; Zeiler, W. Machine learning algorithms applied to a prediction of personal overall thermal comfort using skin temperatures and occupants’ heating behavior. Appl. Ergon. 2020, 85, 103078. [Google Scholar] [CrossRef] [PubMed]
- Ma, N.; Chen, L.; Hu, J.; Perdikaris, P.; Braham, W.W. Adaptive behavior and different thermal experiences of real people: A Bayesian neural network approach to thermal preference prediction and classification. Build. Environ. 2021, 198, 107875. [Google Scholar] [CrossRef]
- Aryal, A.; Becerik-Gerber, B. Thermal comfort modeling when personalized comfort systems are in use: Comparison of sensing and learning methods. Build. Environ. 2020, 185, 107316. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, H.; Li, B.; Kosonen, R.; Wei, S.; Jokisalo, J.; Cheng, Y. Individual thermal comfort prediction using classification tree model based on physiological parameters and thermal history in winter. Build. Simul. 2021, 14, 1651–1665. [Google Scholar] [CrossRef]
- Zhang, W.; Wu, Y.; Calautit, J.K. A review on occupancy prediction through machine learning for enhancing energy efficiency, air quality and thermal comfort in the built environment. Renew. Sustain. Energy. Rev. 2022, 167, 112704. [Google Scholar] [CrossRef]
- Irshad, K.; Khan, A.I.; Irfan, S.A.; Alam, M.M.; Almalawi, A.; Zahir, M.H. Utilizing artificial neural network for prediction of occupants thermal comfort: A case study of a test room fitted with a thermoelectric air-conditioning system. IEEE Access 2020, 8, 99709–99728. [Google Scholar] [CrossRef]
- Kim, J.; Schiavon, S.; Brager, G. Personal comfort models—A new paradigm in thermal comfort for occupant-centric environmental control. Build. Environ. 2018, 132, 114–124. [Google Scholar] [CrossRef]
- Arakawa Martins, L.; Soebarto, V.; Williamson, T.; Pisaniello, D. Personal thermal comfort models: A deep learning approach for predicting older people’s thermal preference. Smart Sustain. Built Environ. 2022, 11, 245–270. [Google Scholar] [CrossRef]
- Liu, S.; Schiavon, S.; Das, H.P.; Jin, M.; Spanos, C.J. Personal thermal comfort models with wearable sensors. Build. Environ. 2019, 162, 106281. [Google Scholar] [CrossRef] [Green Version]
- Cosma, A.C.; Simha, R. Machine learning method for real-time non-invasive prediction of individual thermal preference in transient conditions. Build. Environ. 2019, 148, 372–383. [Google Scholar] [CrossRef]
- Lu, S.; Wang, W.; Lin, C.; Hameen, E.C. Data-driven simulation of a thermal comfort-based temperature set-point control with ASHRAE RP884. Build. Environ. 2019, 156, 137–146. [Google Scholar] [CrossRef]
- Yang, B.; Cheng, X.; Dai, D.; Olofsson, T.; Li, H.; Meier, A. Real-time and contactless measurements of thermal discomfort based on human poses for energy efficient control of buildings. Build. Environ. 2019, 162, 106284. [Google Scholar] [CrossRef]
- Xie, J.; Li, H.; Li, C.; Zhang, J.; Luo, M. Review on occupant-centric thermal comfort sensing, predicting, and controlling. Energy Build. 2020, 226, 110392. [Google Scholar] [CrossRef]
- De Dear, R.; Xiong, J.; Kim, J.; Cao, B. A review of adaptive thermal comfort research since 1998. Energy Build. 2020, 214, 109893. [Google Scholar] [CrossRef]
- Burnard, M.D.; Kutnar, A. Wood and human stress in the built indoor environment: A review. Wood Sci. Technol. 2015, 49, 969–986. [Google Scholar] [CrossRef]
- Kaplan, R.; Kaplan, S. The Experience of Nature: A Psychological View; Cambridge University Press: Cambridge, UK, 1989. [Google Scholar]
- Tsunetsugu, Y.; Miyazaki, Y.; Sato, H. Physiological effects in humans induced by the visual stimulation of room interiors with different wood quantities. J. Wood Sci. 2007, 53, 11–16. [Google Scholar] [CrossRef]
- Tsunetsugu, Y.; Miyazaki, Y.; Sato, H. Visual effects of interior design in actual-size living rooms on physiological responses. Build. Environ. 2005, 40, 1341–1346. [Google Scholar] [CrossRef]
- Ulrich, R.S. Effects of interior design on wellness: Theory and recent scientific research. Health Care. Inte. Des. 1991, 3, 97–109. [Google Scholar]
- Ulrich, R.S.; Robert, F.S.; Barbara, D.L.; Evelyn, F.; Milest, M.A.; Zelsont, M. Stress recovery during exposure to natural and urban environments. Environ. Psychol. 1991, 11, 201–230. [Google Scholar] [CrossRef]
- Zhang, X.; Lian, Z.; Wu, Y. Human physiological responses to wooden indoor environment. Physoi. behav. 2017, 174, 27–34. [Google Scholar] [CrossRef] [PubMed]
- Zhao, T.; Chen, C.; Cao, H. Evolutionary self-organizing fuzzy system using fuzzy-classification-based social learning particle swarm optimization. Inf. Sci. 2022, 606, 92–111. [Google Scholar] [CrossRef]
- Zhao, T.; Chen, C.; Cao, H.; Dian, S.; Xie, X. Multiobjective Optimization design of interpretable evolutionary fuzzy systems with type self-organizing learning of fuzzy sets. IEEE Trans. Fuzzy Syst. 2022, 3207318. [Google Scholar] [CrossRef]
- Zhao, T.; Cao, H.; Dian, S. A self-organized method for a hierarchical fuzzy logic system based on a fuzzy autoencoder. IEEE Trans. Fuzzy Syst. 2022, 3165690. [Google Scholar] [CrossRef]
- Jiang, Y.; Chung, F.L.; Ishibuchi, H.; Deng, Z.; Wang, S. Multitask TSK fuzzy system modeling by mining intertask common hidden structure. IEEE Trans. Cybern. 2015, 45, 548–561. [Google Scholar]
- Wang, S.; Chung, F.L.; Hongbin, S.; Dewen, H. Cascaded centralized TSK fuzzy system: Universal approximator and high interpretation. Appl. Soft. Comput. 2005, 5, 131–145. [Google Scholar] [CrossRef]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its application to modeling and control. Trans. System. Man. Cybern. 1985, 15, 116–132. [Google Scholar] [CrossRef]
- Deng, Z.; Cao, L.; Jiang, Y.; Wang, S. Minimax probability TSK fuzzy system classifier: A more transparent and highly interpretable classification model. IEEE Trans. Fuzzy Syst. 2015, 23, 813–826. [Google Scholar] [CrossRef]
- Bayindir, R.; Gok, M.; Kabalci, E.; Kaplan, O. An intelligent power factor correction approach based on linear regression and ridge regression methods. In Proceedings of the 2011 10th International Conference on Machine Learning and Applications and Workshops, Honolulu, HI, USA, 18–21 December 2011; pp. 313–315. [Google Scholar]
- Kasun, L.L.C.; Zhou, H.; Huang, G. Representational learning with ELMs for big data. Intell. Syst. 2013, 28, 31–34. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G. Extreme learning machine for multilayer perceptron. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 809–821. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Huang, G.; Song, S.; You, K. Trends in extreme learning machines: A review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Zhou, T.; Chung, F.; Wang, S. Deep TSK fuzzy classifier with stacked generalization and triplely concise interpretability guarantee for large data. IEEE Trans. Fuzzy Syst. 2017, 25, 1207–1221. [Google Scholar] [CrossRef]
- Zhou, T.; Zhou, Y.; Gao, S. Quantitative-integration-based TSK fuzzy classification through improving the consistency of multi-hierarchical structure. Appl. Soft. Comput. 2021, 106, 107350. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Characteristics |
|---|---|
| Basic information | Information such as gender, height, age, new city metabolism, clothing thermal resistance, and BMI |
| Sampling conditions | The weather of the day, the materials of the sampling chamber, the opening and closing of the windows, etc. |
| Physiological parameters | High pressure, low pressure, pulse, perspiration rate, and multipart body surface temperature |
| Physical environment | Indoor and outdoor air temperature, relative humidity, indoor surface temperature, and black bulb temperature |
| Environmental awareness | Subjective feelings such as environmental coldness and heat, comfort, and expectation |
| Self-assessment | Health, mood, performance, fatigue, etc. |
| Groups | Visual Angle | No. of Selected Samples | No. of Total Samples | No. of Features | No. of Classes |
|---|---|---|---|---|---|
| Data 1 * | Timber | 27 | 48 | 23 | 2 |
| Concrete | 27 | 48 | 23 | 2 | |
| Data 2 * | Timber | 76 | 109 | 34 | 2 |
| Concrete | 76 | 109 | 34 | 2 |
| Parameter | Value |
|---|---|
| 55~60 | |
| 7 | |
| (0, 0.1) | |
| (0, 0.1) |
| Algorithms | Main Descriptions of Compared Algorithms | Main Descriptions of TMV-TSK-FC |
|---|---|---|
| DBN | (1) Hierarchical structure with multiple hidden layers; only the nodes of adjacent layers are connected. (2) The process of feature learning has better feature expression. | (1) Dataset input: bi-view information input. (2) Feature selection and rule output: By constructing a membership function from a joint view, comparing the size of its membership value, select the membership function value that contributes the most to decision making, so that the feature information of the two views can be effectively processed. Fusion, and by constructing a decision coefficient matrix, select the features that are closely related to information decision making for rule output. (3) Fuzzy rules: TMV-TSK-FC has high usability and interpretability. |
| QI-TSK | (1) The basic building blocks of QI-TSK-fc (td > 1) are all composed of optimized zero-order TSK fuzzy classifiers. Each base building unit is aligned with the adjacent base building unit. (2) Fuzzy rules and features have high interpretability. (3) The algorithm does not need to iterate. | |
| JADE-C | (1) The optimal mutation strategy is randomly selected. (2) Self-adaptive parameter control and control parameters. | |
| SADE-C | For a single training set, there is no feature selection ability. Influence the mutation strategy of the next generation according to the success rate of the recorded mutation strategy. | |
| GFS-ADABOOST-C | (1) Use a single training set to train different fuzzy classifiers. (2) High classification performance, no feature filtering, but long training time. | |
| GFS-MAXLOGITBOOST-C | (1) The loss function is derived by maximizing the log-likelihood function. (2) Optimize in a way similar to Newton iteration. |
| Sample1 | Feature 1 | Feature 2 | Feature 3 | ... | |
|---|---|---|---|---|---|
| Rule1 in view1 | … | 0.7236 | |||
| Rule1 in view2 | ... | 0.2489 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Lu, W.; Hu, Z.; Zhou, T.; Zhou, Y.; Yan, W.; Jiang, F. Decision-Refillable-Based Two-Material-View Fuzzy Classification for Personal Thermal Comfort. Appl. Sci. 2022, 12, 11700. https://0-doi-org.brum.beds.ac.uk/10.3390/app122211700
Xu Z, Lu W, Hu Z, Zhou T, Zhou Y, Yan W, Jiang F. Decision-Refillable-Based Two-Material-View Fuzzy Classification for Personal Thermal Comfort. Applied Sciences. 2022; 12(22):11700. https://0-doi-org.brum.beds.ac.uk/10.3390/app122211700
Chicago/Turabian StyleXu, Zhaofei, Weidong Lu, Zhenyu Hu, Ta Zhou, Yi Zhou, Wei Yan, and Feifei Jiang. 2022. "Decision-Refillable-Based Two-Material-View Fuzzy Classification for Personal Thermal Comfort" Applied Sciences 12, no. 22: 11700. https://0-doi-org.brum.beds.ac.uk/10.3390/app122211700