
Classification and Object Detection of 360° Omnidirectional Images Based on Continuity-Distortion Processing and Attention Mechanism

Abstract
:1. Introduction
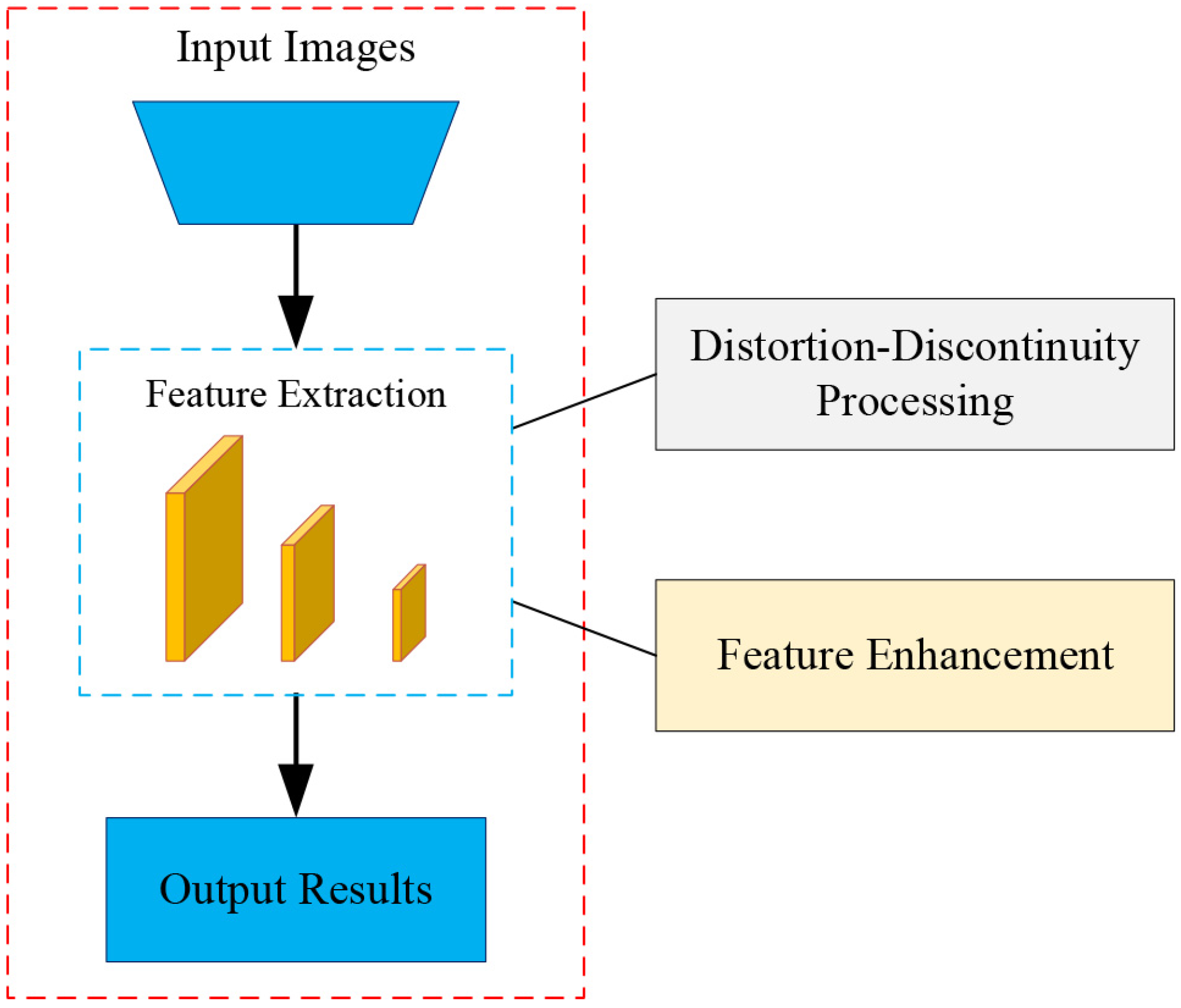
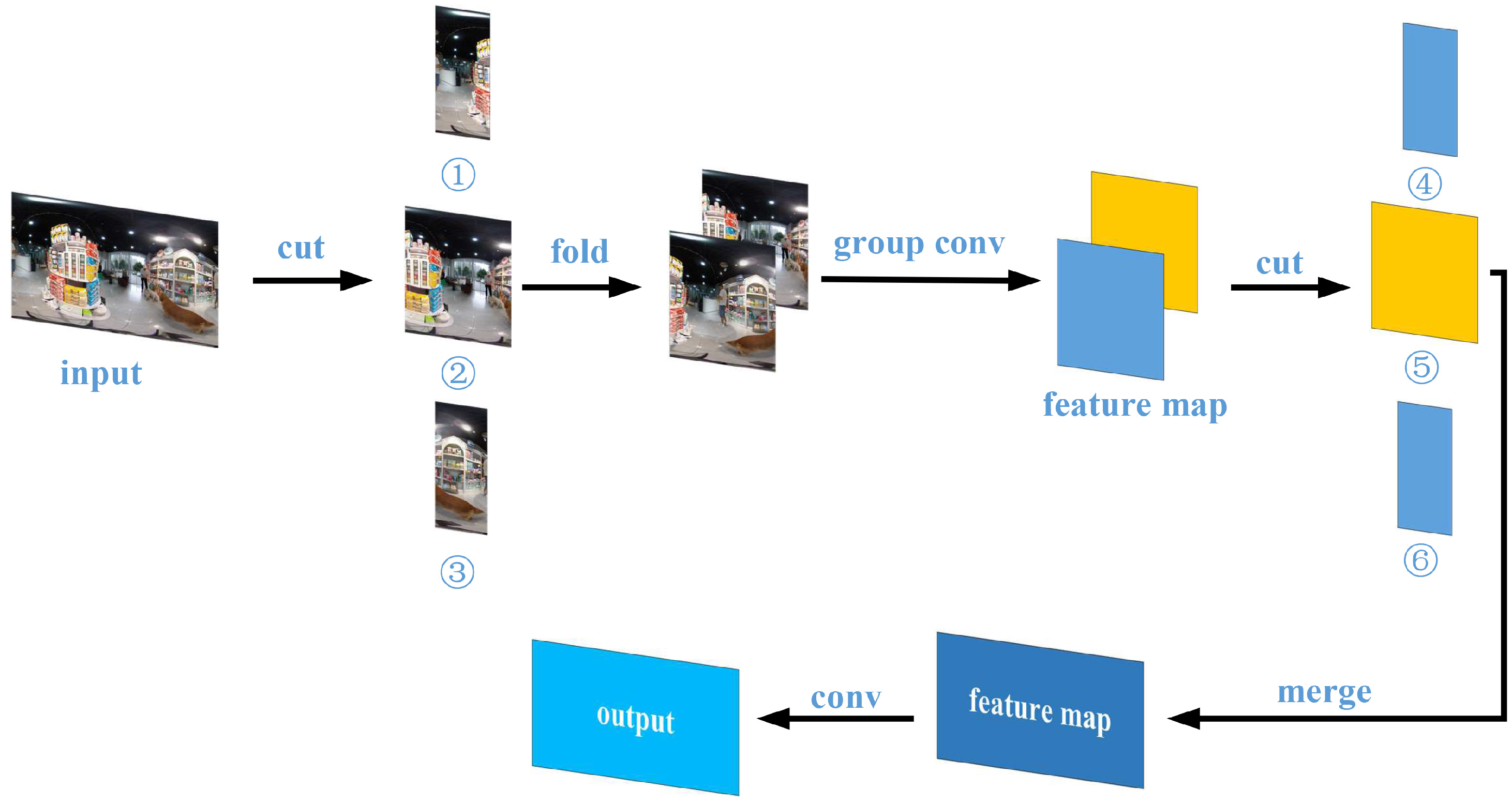
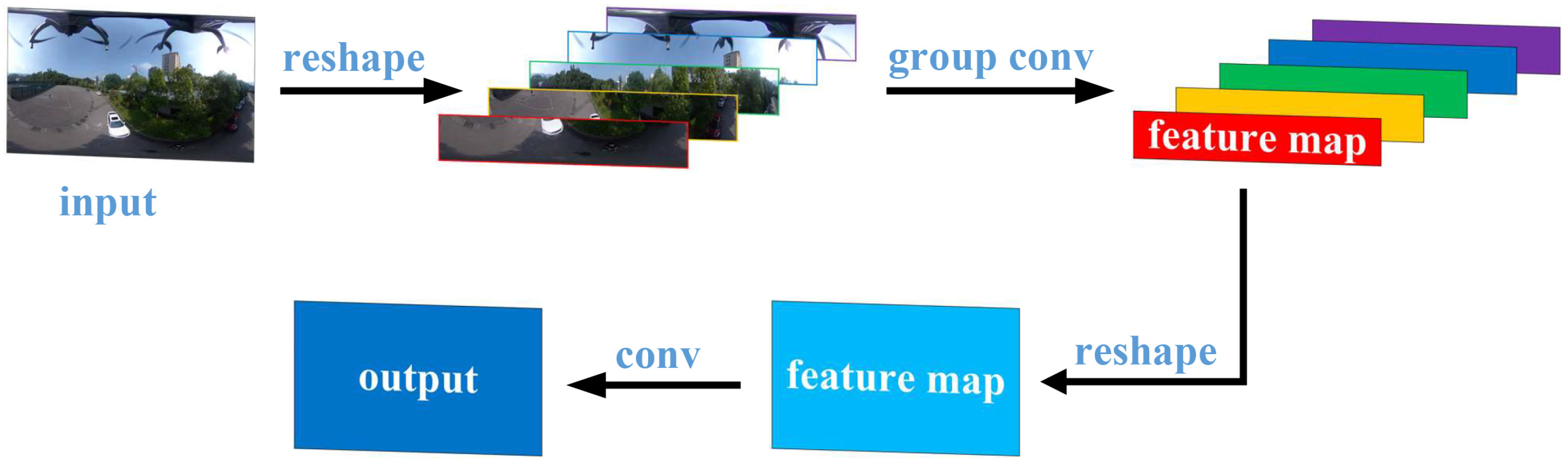
- A novel edge continuity distortion-aware block (ECDAB) and a convolutional row-column attention block (CRCAB) are proposed. ECDAB extracts continuous features through recombination features and group convolution is performed through segmentation features using different convolution kernels between different blocks to alleviate distortion. CRCAB enables interaction of spatial information in a unique way to enhance the receptive field and capacity for feature expression.
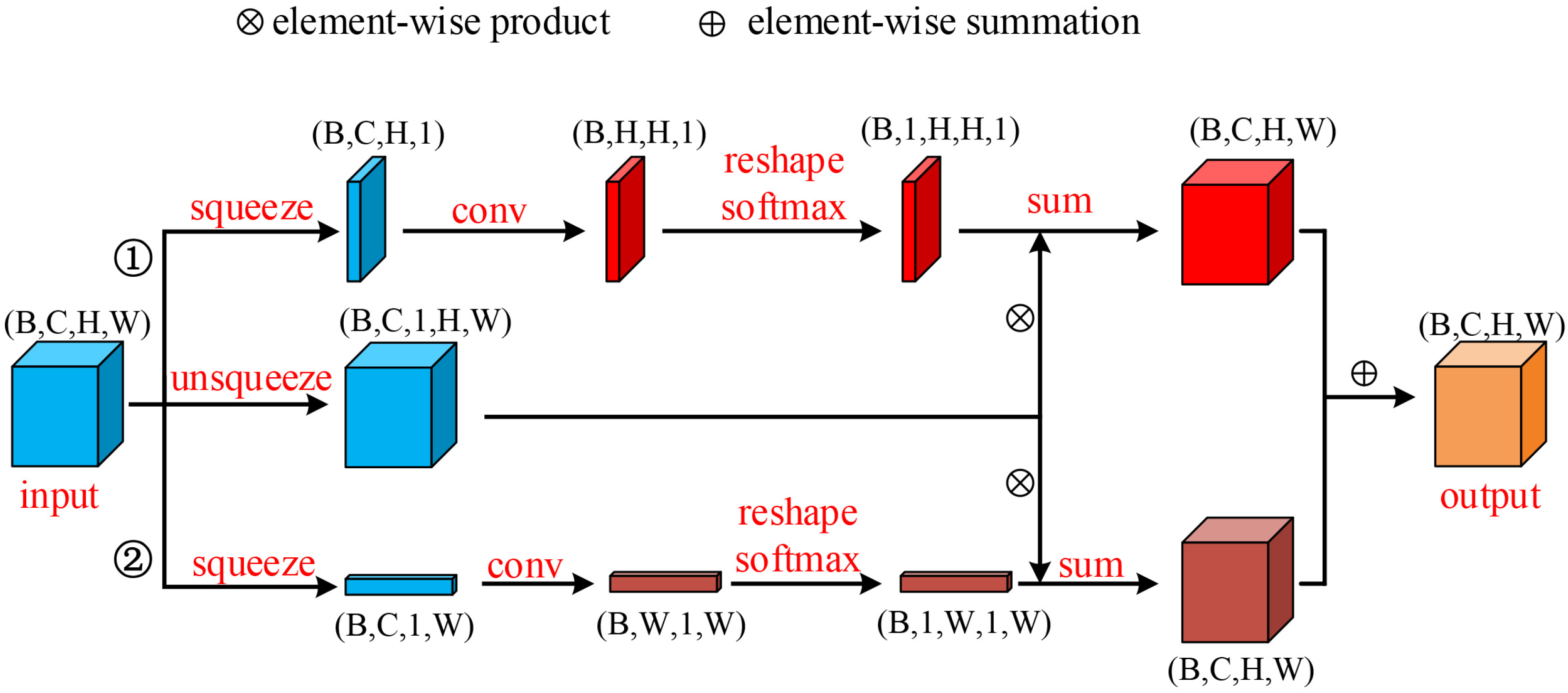
- To reduce the memory overhead of CRCAB for very high and wide images or features, we propose an improved convolutional row-column attention block (ICRCAB).
- Based on experimental investigation of classification and object detection using 360° omnidirectional images, it is demonstrated that better performance than for the baseline model is obtained by the network using ECDAB or CRCAB. Moreover, it is shown that CRCAB also performs well when using traditional images.
2. Related Studies
3. Research Methodology
3.1. Edge Continuity Distortion-Aware Block (ECDAB)
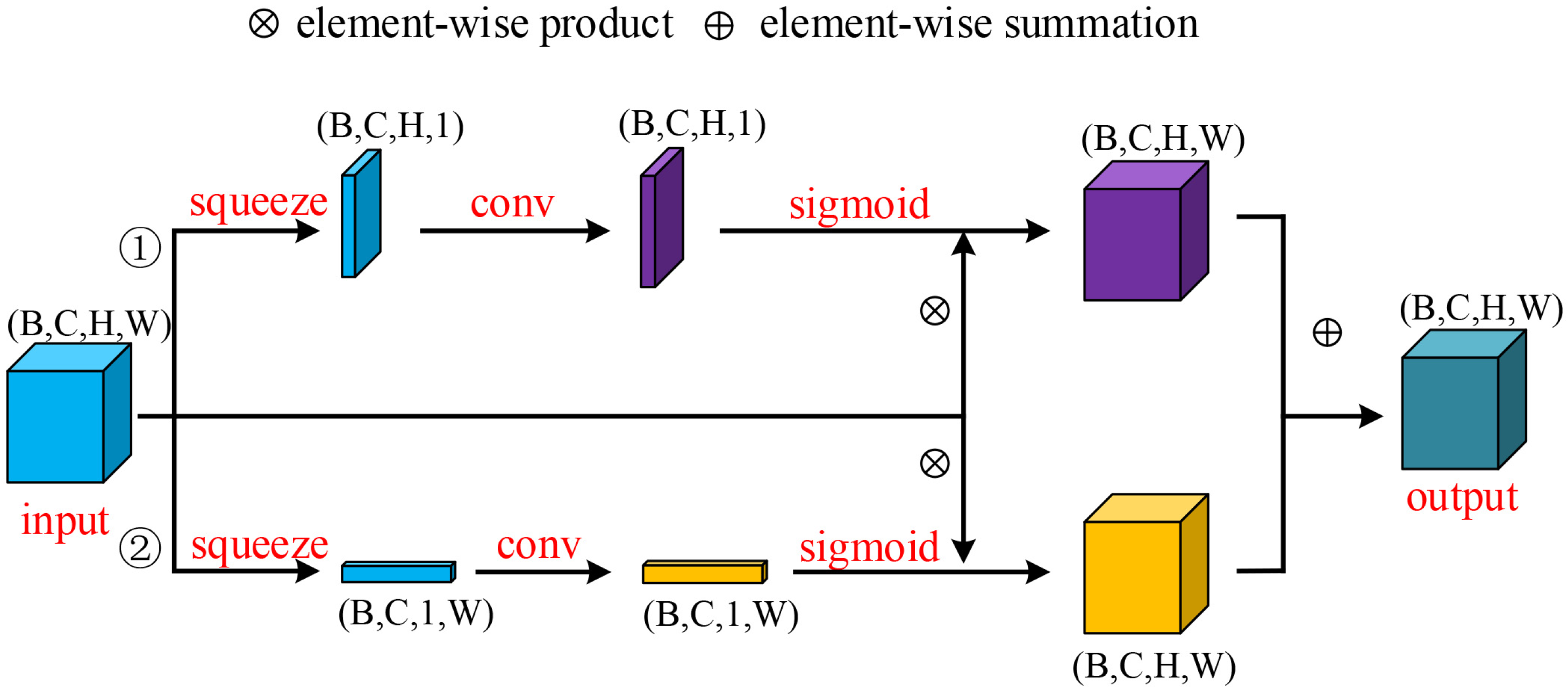
3.2. Convolutional Row-Column Attention Block (CRCAB)
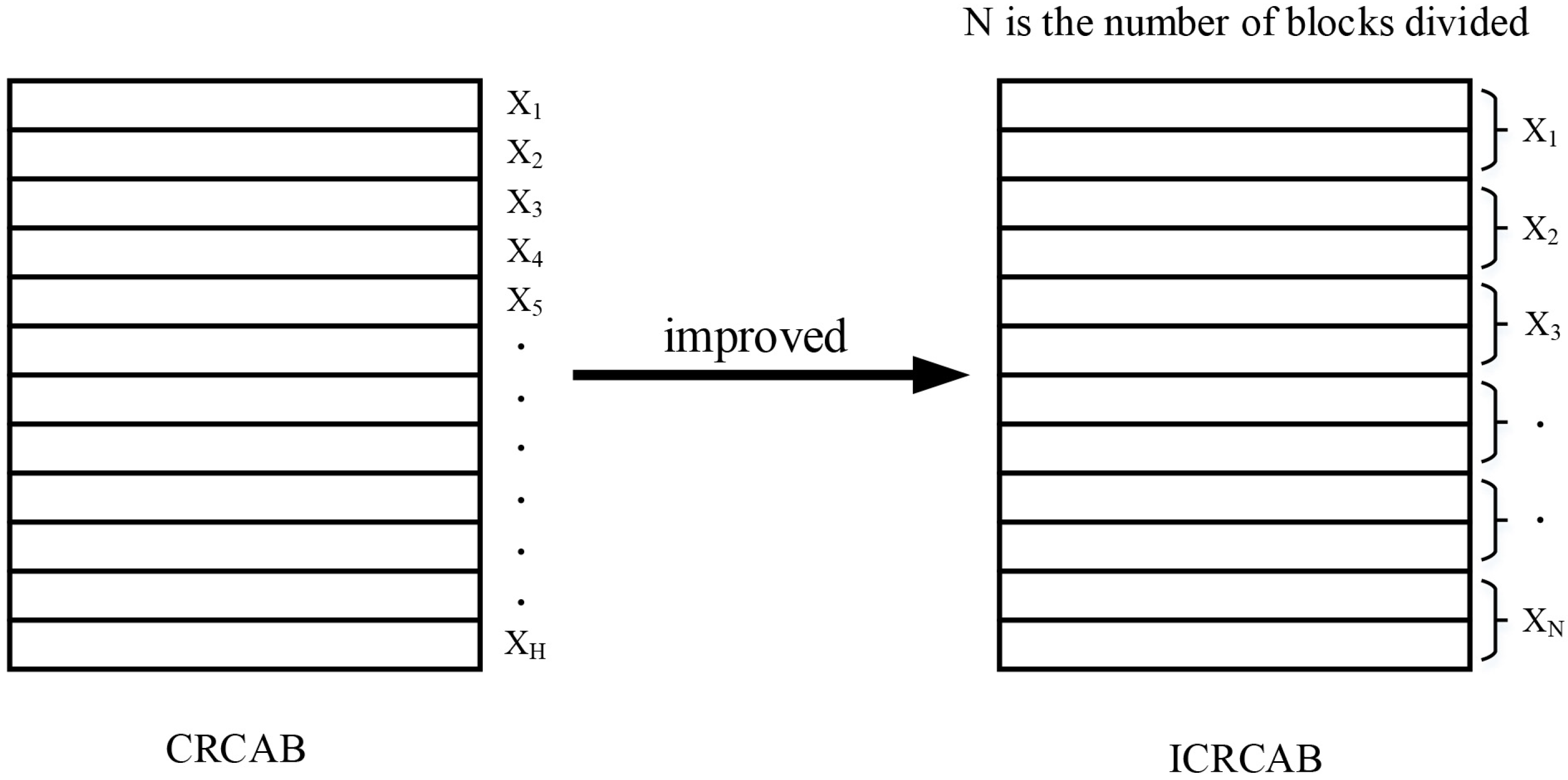
3.3. Improved Convolutional Row-Column Attention Block (ICRCAB)
4. Experiments
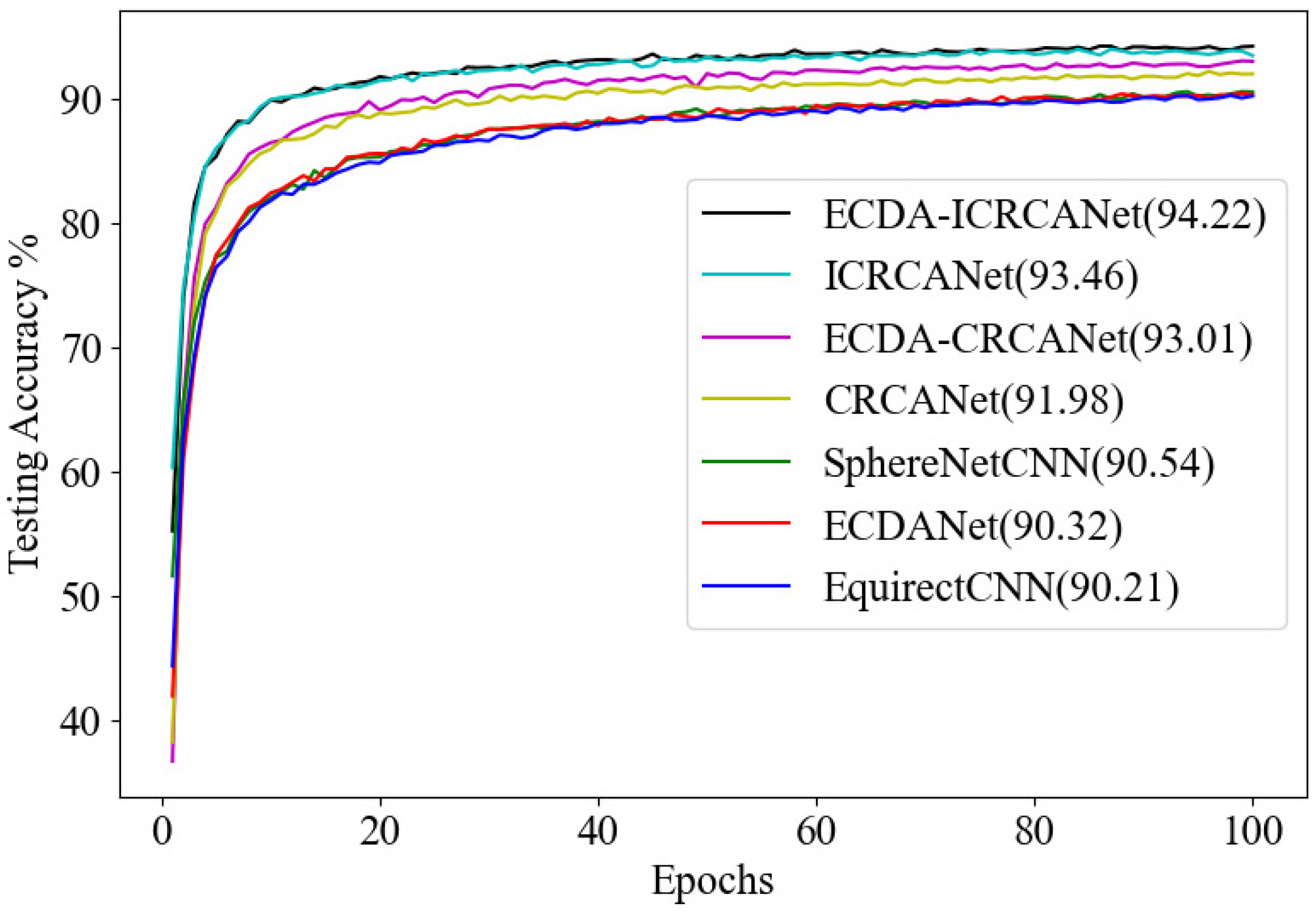
4.1. Classification
4.2. Object Detection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arena, F.; Ticali, D. The development of autonomous driving vehicles in tomorrow’s smart cities mobility. AIP Conf. Proc. 2018, 2040, 140007. [Google Scholar]
- Guo, H.; Peng, S.; Lin, H.; Wang, Q.; Zhang, G.; Bao, H.; Zhou, X. Neural 3D scene reconstruction with the manhattan-world assumption. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5511–5520. [Google Scholar]
- Schuemie, M.J.; Van Der Straaten, P.; Krijn, M.; Van Der Mast, C.A. Research on presence in virtual reality: A survey. CyberPsychol. Behav. 2001, 4, 183–201. [Google Scholar] [CrossRef] [PubMed]
- Harvey, C.D.; Collman, F.; Dombeck, D.A.; Tank, D.W. Intracellular dynamics of hippocampal place cells during virtual navigation. Nature 2009, 461, 941–946. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pradhan, K.S.; Chawla, P.; Tiwari, R. HRDEL: High ranking deep ensemble learning-based lung cancer diagnosis model. Expert Syst. Appl. 2023, 213, 118956. [Google Scholar] [CrossRef]
- Mishra, A.M.; Harnal, S.; Gautam, V.; Tiwari, R.; Upadhyay, S. Weed density estimation in soya bean crop using deep convolutional neural networks in smart agriculture. J. Plant Dis. Prot. 2022, 129, 593–604. [Google Scholar] [CrossRef]
- Mittal, U.; Chawla, P.; Tiwari, R. EnsembleNet: A hybrid approach for vehicle detection and estimation of traffic density based on faster R-CNN and YOLO models. Neural Comput. Appl. 2022, 1–20. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; Volume 25. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Piciarelli, C. MS-Faster R-CNN: Multi-stream backbone for improved faster R-CNN object detection and aerial tracking from UAV images. Remote Sens. 2021, 13, 1670. [Google Scholar]
- Gu, P. A multi-source data fusion decision-making method for disease and pest detection of grape foliage based on ShuffleNet V2. Remote Sens. 2021, 13, 5102. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the inherence of convolution for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12321–12330. [Google Scholar]
- Yin, L.; Hong, P.; Zheng, G.; Chen, H.; Deng, W. A novel image recognition method based on densenet and dprn. Appl. Sci. 2022, 12, 4232. [Google Scholar] [CrossRef]
- Esteves, C.; Allen-Blanchette, C.; Makadia, A.; Daniilidis, K. Learning so(3) equivariant representations with spherical cnns. Int. J. Comput. Vis. 2020, 128, 588–600. [Google Scholar] [CrossRef] [Green Version]
- Coors, B.; Condurache, A.P.; Geiger, A. Spherenet: Learning spherical representations for detection and classification in omnidirectional images. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 518–533. [Google Scholar]
- Lee, Y.; Jeong, J.; Yun, J.; Cho, W.; Yoon, K.J. Spherephd: Applying cnns on a spherical polyhedron representation of 360deg images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9181–9189. [Google Scholar]
- Orhan, S.; Bastanlar, Y. Semantic segmentation of outdoor panoramic images. Signal Image Video Process. 2022, 16, 643–650. [Google Scholar] [CrossRef]
- Khasanova, R.; Frossard, P. Graph-based classification of omnidirectional images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 869–878. [Google Scholar]
- Li, Y.; Guo, Y.; Yan, Z.; Huang, X.; Duan, Y.; Ren, L. Omnifusion: 360 monocular depth estimation via geometry-aware fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2801–2810. [Google Scholar]
- Eder, M.; Shvets, M.; Lim, J.; Frahm, J.M. Tangent images for mitigating spherical distortion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12426–12434. [Google Scholar]
- Zhang, C.; Liwicki, S.; Smith, W.; Cipolla, R. Orientation-aware semantic segmentation on icosahedron spheres. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3533–3541. [Google Scholar]
- Zhao, P.; You, A.; Zhang, Y.; Liu, J.; Bian, K.; Tong, Y. Spherical criteria for fast and accurate 360 object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12959–12966. [Google Scholar]
- Zhao, Q.; Zhu, C.; Dai, F.; Ma, Y.; Jin, G.; Zhang, Y. Distortion-aware CNNs for Spherical Images. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 1198–1204. [Google Scholar]
- Goodarzi, P.; Stellmacher, M.; Paetzold, M.; Hussein, A.; Matthes, E. Optimization of a cnn-based object detector for fisheye cameras. In Proceedings of the 2019 IEEE International Conference on Vehicular Electronics and Safety, Cairo, Egypt, 4–6 September 2019; pp. 1–7. [Google Scholar]
- Zhao, C.; Sun, Q.; Zhang, C.; Tang, Y.; Qian, F. Monocular depth estimation based on deep learning: An overview. Sci. China Technol. Sci. 2020, 63, 1612–1627. [Google Scholar] [CrossRef]
- Yang, W.; Qian, Y.; Kämäräinen, J.K.; Cricri, F.; Fan, L. Object detection in equirectangular panorama. In Proceedings of the 2018 24th International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 2190–2195. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Monroy, R.; Lutz, S.; Chalasani, T.; Smolic, A. Salnet360: Saliency maps for omni-directional images with cnn. Signal Process. Image Commun. 2018, 69, 26–34. [Google Scholar] [CrossRef] [Green Version]
- Ruder, M.; Dosovitskiy, A.; Brox, T. Artistic style transfer for videos and spherical images. Int. J. Comput. Vis. 2018, 126, 1199–1219. [Google Scholar] [CrossRef]
- Coxeter, H.S.M. Introduction to Geometry; John Wiley & Sons: New York, NY, USA; London, UK, 1961. [Google Scholar]
- Su, Y.; Grauman, K. Kernel transformer networks for compact spherical convolution. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9442–9451. [Google Scholar]
- Su, Y.; Grauman, K. Learning spherical convolution for fast features from 360 imagery. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Yang, K.; Zhang, J.; Reiß, S.; Hu, X.; Stiefelhagen, R. Capturing omni-range context for omnidirectional segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1376–1386. [Google Scholar]
- Deng, X.; Wang, H.; Xu, M.; Guo, Y.; Song, Y.; Yang, L. Lau-net: Latitude adaptive upscaling network for omnidirectional image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9189–9198. [Google Scholar]
- Vaswani, A.; Ramachandran, P.; Srinivas, A.; Parmar, N.; Hechtman, B.; Shlens, J. Scaling local self-attention for parameter efficient visual backbones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12894–12904. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 8–11 September 2014; pp. 740–755. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Works | Year | Processing Methods |
|---|---|---|
| Su et al. [37] | 2017 | Transformation of the network obtained in the plane into ERP images |
| Yang et al. [31] | 2018 | Sub-area perspective projection to obtain multiple sub-planes |
| Monroy et al. [33] | 2018 | Using the cube mapping method |
| Coors et al. [20] | 2018 | Gnomonic projection to obtain a new convolutional kernel picking position |
| Su et al. [36] | 2019 | Learn to convert kernel functions for efficient conversion |
| Lee et al. [21] | 2019 | Icosahedral projection, new convolution, and pooling methods |
| Deng et al. [41] | 2021 | Various upscaling factors for different latitudes, automatic selection strategy |
| Yang et al. [40] | 2021 | Attention network that captures global contextual information |
| Li et al. [24] | 2022 | Transformer feature extractor, sub-area gnomonic projection |
| Methods | Test Error Rate (%) |
|---|---|
| EquirectCNN | 9.79 |
| SphereNetCNN | 9.46 |
| ECDANet | 9.68 |
| CRCANet | 8.02 |
| ICRCANet | 6.54 |
| ECDA-CRCANet | 6.99 |
| ECDA-ICRCANet | 5.78 |
| Methods | Building | Car | Motor | Person | mAP |
|---|---|---|---|---|---|
| EquirectYOLO | 83.66 | 90.75 | 43.25 | 79.61 | 74.32 |
| SphereNetYOLO | 83.88 | 91.61 | 43.86 | 78.77 | 74.53 |
| ECDAYOLO | 84.85 | 90.61 | 46.37 | 78.56 | 75.09 |
| CRCAYOLO | 86.87 | 91.43 | 48.46 | 79.02 | 76.45 |
| ICRCAYOLO | 85.75 | 91.67 | 53.31 | 78.78 | 77.38 |
| ECDA-CRCAYOLO | 82.92 | 92.03 | 52.48 | 80.23 | 76.92 |
| ECDA-ICRCAYOLO | 84.60 | 90.85 | 54.49 | 80.21 | 77.54 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Yang, D.; Song, T.; Ye, Y.; Zhou, J.; Song, Y. Classification and Object Detection of 360° Omnidirectional Images Based on Continuity-Distortion Processing and Attention Mechanism. Appl. Sci. 2022, 12, 12398. https://0-doi-org.brum.beds.ac.uk/10.3390/app122312398
Zhang X, Yang D, Song T, Ye Y, Zhou J, Song Y. Classification and Object Detection of 360° Omnidirectional Images Based on Continuity-Distortion Processing and Attention Mechanism. Applied Sciences. 2022; 12(23):12398. https://0-doi-org.brum.beds.ac.uk/10.3390/app122312398
Chicago/Turabian StyleZhang, Xin, Degang Yang, Tingting Song, Yichen Ye, Jie Zhou, and Yingze Song. 2022. "Classification and Object Detection of 360° Omnidirectional Images Based on Continuity-Distortion Processing and Attention Mechanism" Applied Sciences 12, no. 23: 12398. https://0-doi-org.brum.beds.ac.uk/10.3390/app122312398