1. Introduction
The use of video and digital content has expanded due to smartphones and other available imaging equipment. The fast growth of video content on social media and the internet has led to the definition of issues such as selecting essential frames of a video to use as a video marker or summarizing and reducing the required memory. In addition, the use of the most important video frames to reduce their review time in different algorithms or to better train machine learning algorithms are among the other uses of selecting the best frames of a video [
1]. Due to the wide range of applications, the goal of selecting keyframes is essential. For example, in applications such as selecting keyframes to create a short film as a movie trailer, the goal is to assure an appealing trailer firm in order to prompt people to spend money, go to the cinema and watch the entire movie. In applications such as those related to machine vision systems, which use various videos for training, selecting a fixed length of a video is necessary to create a better training sample and to reduce the required training time based on relevant details of the system input [
2].
Machine learning methods designed to process videos use different features. In some applications, consistency is not necessary, and the method should only extract spatial features; however, in some applications—for example, in human action recognition (HAR)—frame continuity is critical [
3]. Among the research that tries to optimize a video as an input of machine learning systems, Ref. [
4] used keyframes for crowd counting, and, in [
5], the goal was to summarize video contents.
One of the growing topics in video processing, which is widely used, is HAR. Among its applications, these can be cited: traffic surveillance, smart city management, hospital management and security systems. Since video processing methods usually require fixed video lengths and frame dimensions, and training videos have variable lengths, choosing keyframes to cover maximum action-related information is highly demanded. A review of video-based human performance detection algorithms revealed that most of these methods use random frame selection throughout the input video [
6,
7], or a mixture of all processed frames [
8], which directly affects the efficiency of the training process and system accuracy, and increases the required training time. Obviously, if the most appropriate frames of a frame sequence are used in the training step, the HAR system will be better trained.
In a typical scene that includes regular actions, there are many frames with very little information due to a lack of movement that can be discarded in the training. On the other hand, HAR systems usually require many samples for training. Another challenge of most HAR systems is the mismatch between the dimensions of the input videos and the system input due to differences in the resolution of the sued acquisition cameras. Hence, common video-based HAR systems use methods, such as resizing or cropping frames, to match the different acquisition camera resolutions, which may reduce the system efficiency.
Due to the above explanations, this research proposes an optimal method to select a sequence of keyframes, and then to select the region of interest (ROI) in the selected keyframes from the input video that contains the most relevant information for HAR systems. The selected keyframes can be cropped using the founded ROI, and then can be used in the training step of the HAR system. The proposed method can be used as a pre-processing method in many HAR systems in order to enhance the training efficiencies, both in terms of accuracy and speed.
The organization of the rest of this article is as follows:
Section 2 provides a literature review;
Section 3 gives a detailed explanation of the theoretical framework and methodology of the proposed method;
Section 4 discusses simulation details and results. Finally, the conclusion is given in
Section 5.
2. Literature Review
The key goal of the proposed method is the pre-processing of input videos in order to remove unnecessary information at the beginning of the HAR system, so this section is mainly focused on keyframe selection and ROI finding at the input block of HAR systems. The existing methods for keyframe selection can be classified into the following groups: methods based on extracting temporal or spatial features, methods based on deep learning and hybrid methods. In all of these categories, the efficiency of the method is mainly defined based on the application.
The methods based on extracting temporal or spatial features use saliency features, such as edge or motion features, for keyframe selection. Zhenxing et al. [
9] used the Laplacian operator to select the appropriate sequences for short periods as the input of a deep learning scheme to identify Hong Kong sign language. Zayed and Rivaz [
10] performed elastomeric experiments using ultrasonic images taken from a pressurized mechanical object. The acquired images were first submitted to a multilayer perceptron (MLP) classifier, and any two consecutive frames that contain no relevant information are removed from the list of training frames. They decomposed the displacement into a linear combination of weighted principal components, which were used as an input for the MLP. Kyung and Yang [
11] proposed a method for selecting keyframes in RGB-Depth (RGB-D) video tracking systems, which uses the difference of frames and features extracted from the image depth information simultaneously. Lin et al. [
12] used the Kanade–Lucas–Tomasi (KLT) algorithm to select keyframes in an automated driving system. In this method, the main features, such as margins, road lines and other obstacles, are extracted from the frames, and then the difference between these features is used to discard or keep the frames. Rajpal et al. [
13] used a fuzzy method based on single-frame information, such as contrast, edges and luminescence, in order to select the best frames for watermarking. Chen et al. [
14] suggested a frame selection scheme for video-based person re-identification. The spatial and temporal characteristics are used simultaneously to select keyframes. None of the above research was designed for HAR systems, and none of them can be applied directly to a HAR system, but they have features and concepts that can be used in the development of a suitable method.
The second category includes methods based on deep learning; therefore, these methods use a type of deep learning such as long short-term memory (LSTM) and the convolutional neural network (CNN) for keyframe selection. Xu et al. [
15] proposed a method using an autoencoder for selecting the frame sequence of a movie to create an automatic thumbnail for the video, which is vital for, as an example, online video sharing sites that provide a short tag for each movie. Wu et al. [
16] proposed a dynamic method to remove unnecessary video information for video recognition. The authors used an LSTM network for selecting frames with the most relevant information. Pretuary and Pillay [
17] trained various CNN-based methods, such as ResNet, to select frames to create video thumbnails automatically. Zhao et al. [
18] proposed a hybrid visual tracking method based on deep and reinforcement learning. The suggested method only used frames where the object being tracked moved away from its previous location more than a specific threshold; the other frames were detected and removed from the training process. Xiang et al. [
19] used the ConvNet network with two different spatial and temporal approaches in order to select keyframes in a HAR system. The Xiang method maintains action consistency and selects frames with more spatial and temporal information as an input. Wu et al. [
20] used the LSTM to select keyframes in video recognition. The suggested method increases the training speed, reduces the frame length and improves the network performance. Deep learning methods show good results in keyframe selection in video recognition systems such as HAR, but require a complex and time-consuming training step. At the same time, they need a huge number of labeled training samples, which are usually not available in HAR applications.
The last group is hybrid methods, which use a combination of features and machine learning schemes for keyframe and ROI selection. Fasogbon et al. [
21] proposed an inertial measurement unit (IMU) to make a video depth map. The authors used keyframe selection to pick frames in an input video that involves minimal human movement. Usually, a smartphone needs 30 frames per second to create a depth map of the environment, but by selecting keyframes, a depth map can be made using just five frames. Kang [
22] proposed a robotic imaging system for selecting the best shot among several portraits. Rahimi et al. [
23] selected the minimum number of frames, i.e., keyframes, required in a high resolution (HR) imaging task. Jeyabharathi and Djey [
24] extracted the video background using a cut set by selecting keyframes from a sequence of frames. They found patches with a similarity between successive forms in a video, removed frames with less information and preserved keyframes. To select the best frames in a HAR video, Wang et al. [
25] counted the moving parts of the human body that form action in each frame. The frames where the number of moving parts or amount of movement in them are low were removed from the training process. Zhou et al. [
26] presented a video object segmentation scheme using deep learning that can be used for human detection in HAR systems. The suggested system showed good results in different applications, but its applicability in complex scenes with several humans simultaneously is still unclear. Jagtap et al. [
27] proposed two adaptive activation functions to accelerate deep learning method convergence. Jagtap et al. [
28,
29] showed the applicability and flexibility of the adaptive activation functions in various applications, such as video processing. The adaptive activation functions can be combined by keyframe selection in order to enhance the efficiency of deep-learning-based HAR systems. The hybrid methods are usually limited in terms of applications, and specifically in terms of the types of actions involved in HAR systems.
According to the literature review, previous methods to be used as a pre-processing step in HAR systems need to be redesigned or, at least, demand new examples for retraining. The proposed method selects a predefined number of frames, which should include a relatively complete expression of the human action, regardless of the type of action. After that, the proposed method crops the frames considering the input size of the HAR system and the maximum action information. The main advantage of the proposed method is the improvement of the learning process of any HAR system by pre-processing the input videos without the need for training.
3. System Overview
This section describes the architecture of the proposed method for shortening the video length and modifying video dimensions to optimize the training process of HAR systems. The flowchart of the proposed method is shown in
Figure 1. As can be seen, the proposed method consists of two separate main steps that are carried out hierarchically. In the first step, the length of the input video is modified based on the acceptable video length for the deep learning network: the video shortening step. Secondly, the shortened video is processed in terms of information within the frames and cropped to match the size of the system input: the adaptive frame cropping step.
3.1. Video Shortening
According to previous research in this field, various methods have been used to find keyframes and to select a suitable sequence according to the application. The proposed method does not necessarily need to find the best sequence, but only the frames that convey the relevant information about human actions. The computational speed of the proposed method is an essential feature because many HAR systems work online. Based on these specifications, the proposed method uses a gradient operator to extract the images edges, i.e., the relevant places of each image frame, and then the difference between the edges of consecutive frames, i.e., the movement that is modeled by the difference between the edges of two consecutive frames, is taken into account in order to calculate an approximate estimate of the action information. The gradient difference of the frames can indicate the amount of movement in main locations. Due to the low calculations of the gradient operator relative to the usual motion detection operators, such as optical flow, this approach shows a lower runtime. The pseudo-code of the proposed method is given by Algorithm 1.
| Algorithm 1: Gradient Best Frame Selection (Shortening Video) |
Input: Input Video V, length of shortened video - 1-
Separate Video to frames (i is the number of frame), - 2-
Apply Gradient to all frames, - 3-
Compute absolute difference between frame gradients All pixel values lower than are assumed to be 0, - 4-
Compute energy belong to each difference as (p is the pixel value) Discard frames with energy lower than , - 5-
Calculate sum of remained energies using a sliding window with length as , - 6-
Select the maximum S and its index as the start of shortened video,
Output: Merge frames from to + and create the Shortened Video
|
Firstly, the input video is separated into its frames (
). In the next step, the gradient operator extracts the edges of all of the frames
. The gradient operator can use different masks. In the Sobel and Prewitt masks, the gradient of each pixel is a weighted sum of a 3-by-3 neighborhood; the Roberts mask uses a 2-by-2 neighborhood; and the “central difference” and “intermediate difference” masks are column vectors.
Figure 2 shows the different gradient masks in the vertical direction; in the horizontal direction, the masks are transposed.
The results of different gradient masks are presented in the “Result and Discussion” section. The absolute value of the gradient difference of the consecutive frames is used as a fast, relatively low and simple operator in order to calculate the motion information ().
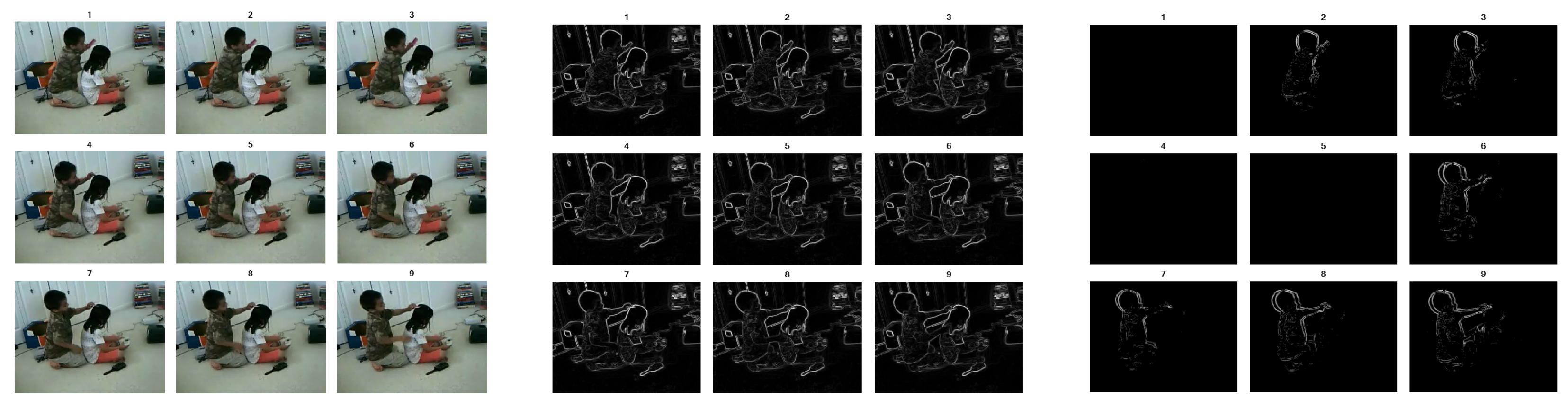
Figure 3 shows nine different frames of an input video, their gradient and the absolute value of the difference between consecutive frame gradients after normalization. The normalization is carried out based on the maximum value of all differences; in addition, if the gradient difference in a pixel is less than the specified threshold, it is discarded.
Selecting a proper value for
is important. If the gradient of the two consecutive frames difference in a pixel after normalization is less than
, it is assumed that no motion has occurred at that point between the two frames. The effect of
on the accuracy of the HAR system that used the proposed pre-processing method in the input is given in the “Result and Discussion” section. The total energy of each difference is calculated in line 5 of Algorithm 1, and frames with energy lower than
are discarded. In the case of
Figure 1, the proposed algorithm eliminated frames 2, 5 and 6. In step 6 (the last one) of Algorithm 1, the energy of the remaining frames is added together in a sliding window with length
. The window where the summation is maximum is the sequence with maximum motion information. This is because the zero-energy frames have been removed, and the selected window will contain more edge motion information than any other parts of the video. This edge motion, with an acceptable approximation, can include action information. Based on the simulation results, almost all of the videos that were separated from the original human action video in this way had relatively complete information about the involved action. After this step, the frames belonging to the selected window are submitted to the second part of the algorithm.
3.2. Adaptive Frame Cropping
In the second part of the proposed method, the frames selected in the previous step must be resized or cropped to the input size of the HAR system. In some methods, the input video is resized using conventional image resizing methods. However, in these methods, the performance of the HAR system may be reduced due to the small size of the human image in the resultant frames. The proposed method was designed to estimate the movement region, i.e., the region related to a human action, in the input video with a low computational burden.
Selecting the cropping region randomly is also a weak and too simple approach. On the other hand, the best approach is to identify the human location in the frame and to select the cropped region using human location and action-related features. However, this approach is not desirable due to a high computational burden. In the related step of the proposed method, which is described in Algorithm 2, all of the calculated differences between the normalized frames are transferred from the previous step to this step, which decreases the needed computations, and are used to build an energy map of the shortened video. In this map, the value of each pixel represents the sum of the pixel motion information in the entire frames. After this step, an average filter is applied to the built energy map. The window size of the average filter is defined as equal to the input size of the used HAR system, and the final image is obtained.
| Algorithm 2: Adaptive Frame cropping |
Input: Shortened Video V, The desired size of final video - 1-
Separate Video to frames (i is the number of frame), - 2-
Apply Gradient to all frames , - 3-
Compute absolute difference between frame gradients , - 4-
Add all together and made an energy map for video, , - 5-
Apply Average (or mean) filter with size to , - 6-
Select the maximum pixel value index of filtered image as the center of cropping area, - 7-
Crop frames using as center and as crop size,
Output: Merge cropped frames and create the Shortened cropped Video |
Finally, the pixel that has the highest value in the filtered image is selected as the center of the cropping region. It is easy to argue that this window contains more relevant motion information, which was found based on the gradient difference between frames, than any other window than can be defined in the video.
Figure 4 shows the overall energy map of a sample shortened video and the result of applying a average filter with dimensions equal to [111,111] on it.
Figure 5 shows the original frames, the result of applying the proposed method and the result of a bad random selection. Hence, it is possible to conclude from
Figure 5 that a randomly cropped video, in some cases, does not contain valuable information for training HAR systems due to the wrongly cropped regions. Contrary to random selection, the result of the proposed method contains complete information about the involved action.
4. Result and Discussion
To evaluate the efficiency of the proposed method, it was applied to the input of some current HAR systems. The accuracy obtained by the studied HAR systems before and after the proposed method application indicates its efficiency over other existing methods. Four different HAR methods that used random approaches to select the training input [
30,
31,
32,
33] were chosen to evaluate the performance of the proposed method. The two UCF101 [
34] and HMDB51 [
35] public HAR datasets based on [
30,
31,
32,
33] were used in the evaluation. In addition to accuracy, the execution time of the algorithms is also compared.
4.1. Dataset
The two selected datasets are the UCF101 and HMDB51 datasets. The UCF101 dataset contains 13,320 videos of 101 actions, and the HMDB51 dataset contains 6766 videos of 51 human actions. The length of the videos varies, and all videos involve just one action.
4.2. Implementation Details
All HAR methods [
30,
31,
32,
33] were trained using random frames and video cropping with static or blind cropping regions. All of these methods were implemented on a system with the following hardware specifications:
and using the MATLAB 2020 software. A total of 70% of the videos in each dataset were used for training, and the remaining 30% were used as test data. The training and test data were the same in all comparisons. In all implementations, the number of input frames was set to 20, and the video dimensions were set to 111 by 111. The remaining part is the data augmentation used in previous methods, which could not be used in the proposed method due to the optimal selection of frames and cropping regions.
To generate different data without losing optimality, a total of four different time intervals with or without overlap with a difference of at least five frames were selected based on the computed energy (Part 5 of Algorithm 1, and 200 different cropping regions were selected from the maximum values obtained in
Section 3 of Algorithm 2. Hence, 800 quasi-random candidates could be created for each video as data augmentation.
In the first step of the implementation, a constant
equal to 0.1 was assumed, and different gradient masks were tested in the proposed method Part 2 of Algorithm 2. The obtained results are given in
Table 1 and
Table 2. The results show that the Sobel mask is the best choice as the gradient operator for adaptive frame cropping in both datasets. In some cases, especially in the training phase of HMDB51, the other masks showed better accuracy, but in the overall evaluation, due to the test set results, the Sobel mask was found as the best choice.
In the second step of the implementation, the Sobel mask was chosen as the gradient operator, and the
effect in the proposed method was analyzed (Part 3 of Algorithm 1. The obtained results are presented in
Table 3 and
Table 4, which show that the
value directly affects the accuracy, and that the value of 0.1 was the best candidate. In some cases, especially in the training phase of HMDB51, the other values showed a better accuracy, but in the overall evaluation in both datasets, the value of 0.1 was the best choice. The results obtained with the selected parameters are given in
Table 5. In addition, the relative change in the training time was calculated according to:
Accordingly, the results of
Table 6 show the advantage of the proposed method in terms of
.
The best improvement occurred in the [
31] method, where a 7.05% improvement in the training set of the HMDB51 database was achieved. In the UCF101 dataset, the best improvement in the training sets was related to the spatiotemporal network [
32], where the system accuracy was improved by 2.85%. According to the results, the improvement in the HMDB51 dataset was more remarkable. Based on the results of
Table 6, using the proposed method for pre-processing at the beginning of the HAR systems led, in most cases, to a reduction in the training time, which was due to the elimination of irrelevant inputs in the network training process that sped up the convergence of the training process.
Therefore, it is possible to conclude that the proposed method can be added to the beginning of any HAR system that uses random frame selection in order to improve the accuracy of the final system.
5. Conclusions
This research proposed a method for selecting the keyframes and suitable regions in a video to increase the speed and accuracy of HAR systems. The proposed method achieves its goals by removing unnecessary data from the video and creating a HAR-compatible input. The proposed hierarchical method identifies the moving areas in a video using the gradient operator, edge extraction and the difference of the gradients between frames, and extracts the frame sequence with more relevant motion information.
The best compatible edge detection method for the proposed method was found using simulations. The threshold value for keyframe selection was found by analyzing its effect on the system accuracy. After this step, a region that includes the most relevant motion information, based on the built motion energy map of the selected frames, is found. The selected frames are then cropped using the founded region, and the final video is used as an input to the HAR system. A high speed, being applicable to all actions and an appropriate approximation in selecting the action area are the main advantages of the proposed method. Finally, the proposed method was combined with several new HAR methods, and it was verified that, by adding its pre-processing to the HAR input, the system accuracy was improved, and its training time decreased.
An interesting research area in HAR systems is the extension of the pre-processing method to remove unnecessary parts from input videos. The unnecessary parts can be defined as unnecessary frames or unnecessary objects in the video scene. Future work can focus on human semantic analysis [
36] or human parsing methods [
37] to increase the efficiency of the pre-processing method of HAR systems, mainly in their training process.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}