
Comparative Agent-Based Simulations on Levels of Multiplicity Using a Network Regression: A Mobile Dating Use-Case

 ,
,
Abstract
:1. Introduction
1.1. Online Dating
1.2. Our Approach
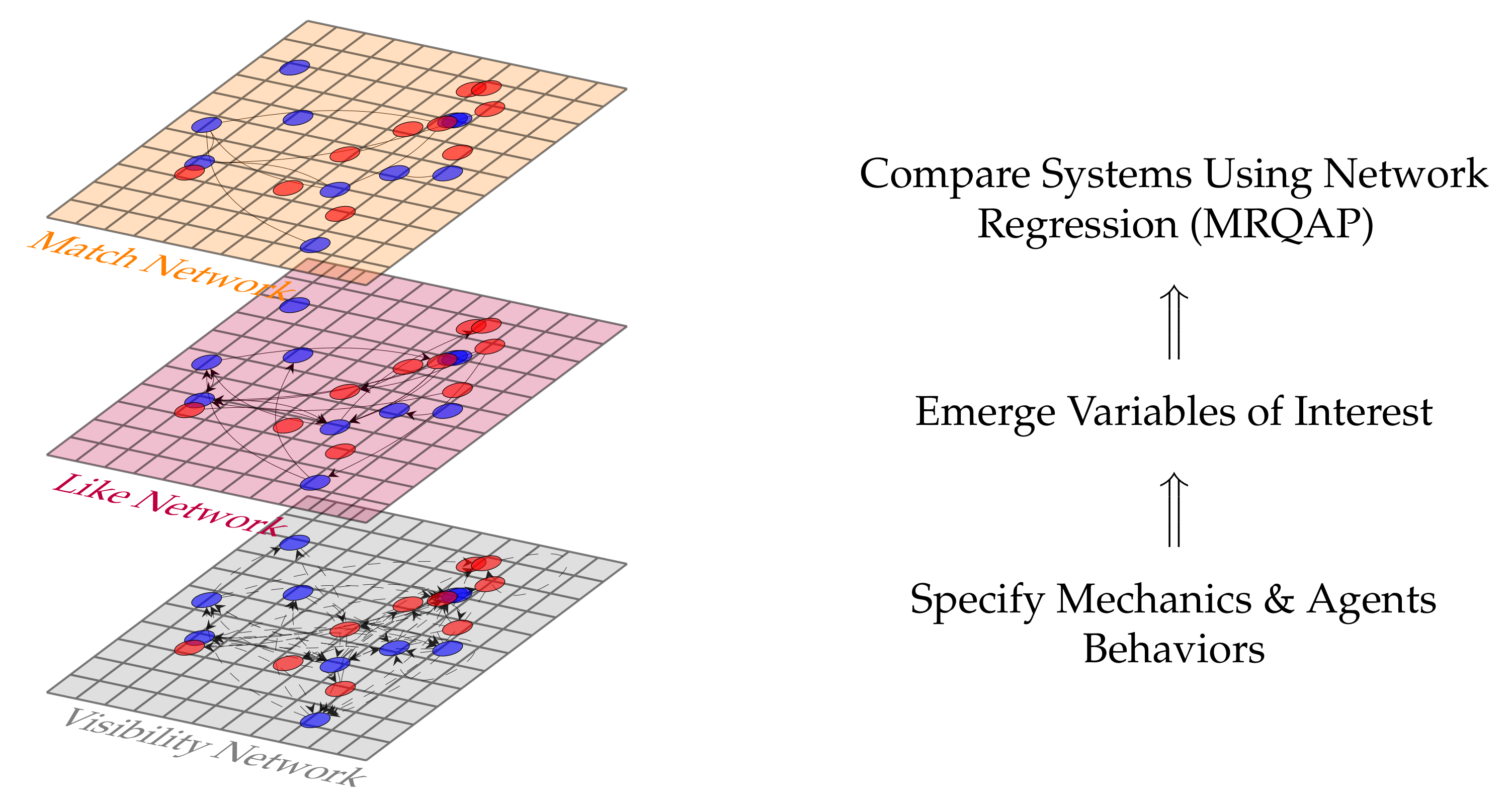
2. Materials and Methods
2.1. Principal Model Mechanics
2.2. Agent Preferences
- Female agents threshold for a ‘like’ are higher than male agents [82]. [M1 & M2]
- The probability of a ‘like’ when the compatibility threshold is not achieved ( < ) is non-zero. It is reduced but a reject, like, and like/message may still occur. [M1 & M2]
- A like with a message is still subject to the same aforementioned compatibility thresholds, but increases the probability of a reciprocal like event. [M2]
- Previous positive interactions (reciprocity) increases the probability values of like and like/message. [M2]
3. Model Comparison
Internal Validation
4. Results
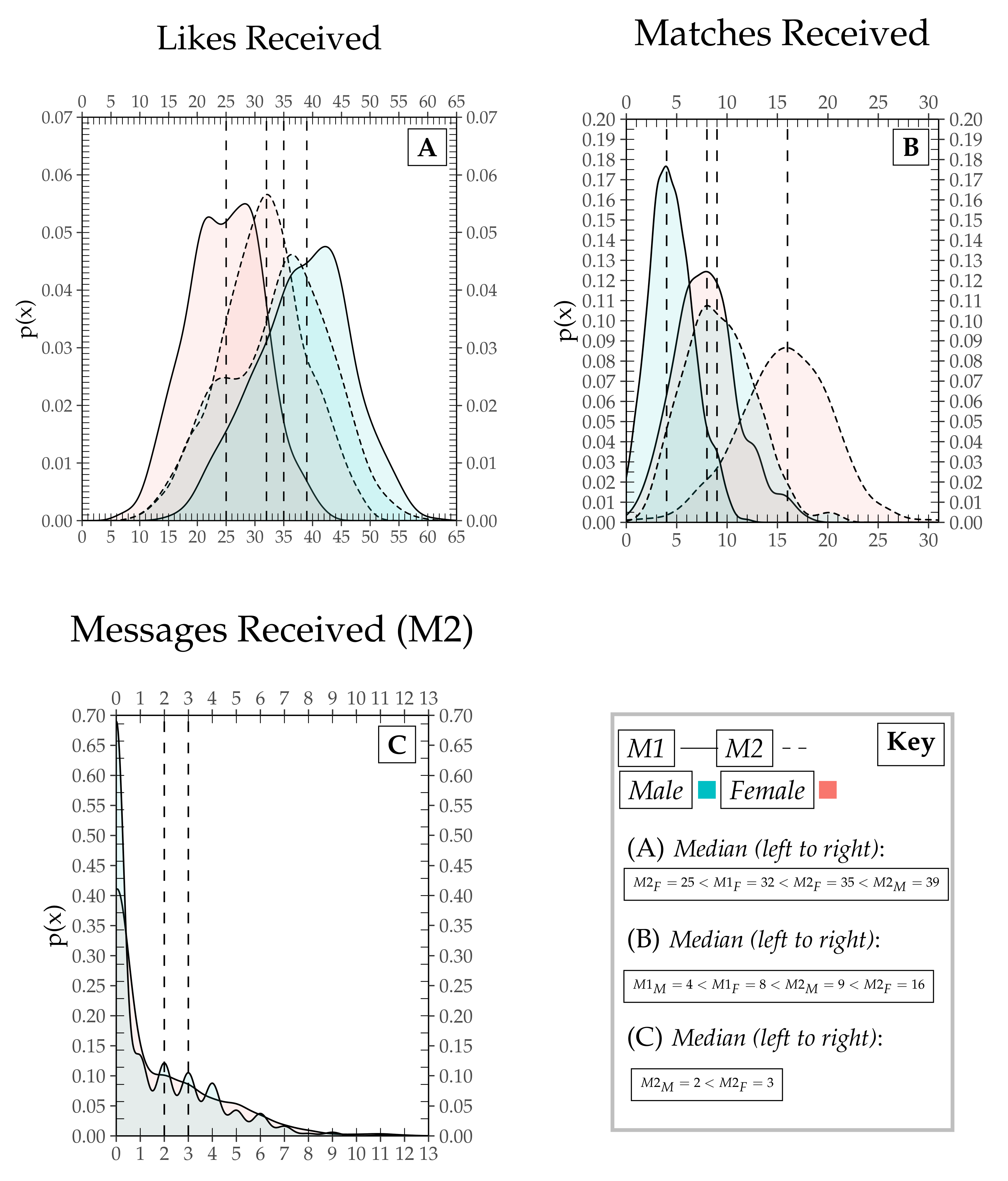
4.1. Networks & Regression Models
4.2. Sensitivity Analysis
5. Discussion
Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MRQAP | Multiple Regression Quadratic Assignment Procedure |
References
- Epstein, J.M. Agent-based Computational Models and Generative Social Science. Complexity 1999, 4, 41–60. [Google Scholar] [CrossRef]
- Axtell, R. Why Agents? On the Varied Motivations for Agent Computing in the Social Sciences. Cent. Soc. Econ. Dyn.-Brook. Inst. 2000, 1–23. [Google Scholar] [CrossRef]
- Janssen, S.; Sharpanskykh, A.; Curran, R.; Langendoen, K. Using Causal Discovery to Analyze Emergence in Agent-Based Models. Simul. Model. Pract. Theory 2019, 96, 101940. [Google Scholar] [CrossRef]
- DeAngelis, D.L.; Diaz, S.G. Decision-Making in Agent-Based Modeling: A Current Review and Future Prospectus. Front. Ecol. Evol. 2019, 6, 237. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zhang, H.; Zhou, L.; Li, Y. Analyzing the Coevolution of Mobile Application Diffusion and Social Network: A Multi-Agent Model. Entropy 2021, 23, 521. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Lin, J.; Li, Y.; Zhang, Z. Innovation Diffusion of Mobile Applications in Social Networks: A Multi-Agent System. Sustainability 2020, 12, 2884. [Google Scholar] [CrossRef] [Green Version]
- Todd, P.M. Searching for the Next Best Mate. In Simulating Social Phenomenon; Springer Publishing: Berlin/Heidelberg, Germany, 1997; pp. 419–436. [Google Scholar] [CrossRef]
- Butts, C.T. A Dynamic Process Interpretation of the Sparse ERGM Reference Model. J. Math. Sociol. 2018, 43, 40–57. [Google Scholar] [CrossRef]
- Hunter, D.R.; Handcock, M.S.; Butts, C.T.; Goodreau, S.M.; Morris, M. Ergm: A Package to Fit, Simulate and Diagnose Exponential-Family Models for Networks. J. Stat. Softw. 2008, 24, nihpa54860. [Google Scholar] [CrossRef] [PubMed]
- Snijders, T.A.B.; Pattison, P.E.; Robins, G.L.; Handcock, M.S. New Specifications for Exponential Random Graph Models. Sociol. Methodol. 2006, 36, 99–153. [Google Scholar] [CrossRef]
- Ligmann-Zielinska, A.; Siebers, P.O.; Magliocca, N.; Parker, D.C.; Grimm, V.; Du, J.; Cenek, M.; Radchuk, V.; Arbab, N.N.; Li, S.; et al. ‘One Size Does Not Fit All’: A Roadmap of Purpose-Driven Mixed-Method Pathways for Sensitivity Analysis of Agent-Based Models. J. Artif. Soc. Soc. Simul. 2020, 23, 6. [Google Scholar] [CrossRef] [Green Version]
- Carrella, E.; Bailey, R.; Madsen, J. Calibrating Agent-Based Models with Linear Regressions. J. Artif. Soc. Soc. Simul. 2020, 23, 7. [Google Scholar] [CrossRef]
- Borgatti, S.P.; Everett, M.G.; Johnson, J.C. Analyzing Social Networks; Sage: Los Angeles, CA, USA, 2018. [Google Scholar]
- Krackhardt, D. Predicting with Networks: Nonparametric Multiple Regression Analysis of Dyadic Data. Soc. Netw. 1988, 10, 359–381. [Google Scholar] [CrossRef]
- Mantel, N. The Detection of Disease Clustering and a Generalized Regression Approach. Cancer Res. 1967, 27, 209–220. [Google Scholar]
- Hubert, L.J. Combinatorial Data Analysis: Association and Partial Association. Psychometrika 1985, 50, 449–467. [Google Scholar] [CrossRef]
- Krackhardt, D. QAP Partialling as a Test of Spuriousness. Soc. Netw. 1987, 9, 171–186. [Google Scholar] [CrossRef]
- Dekker, D.; Krackhardt, D.; Snijders, T.A.B. Multicollinearity Robust QAP for Multiple Regression. In Proceedings of the NAACSOS Conference, Pittsburgh, PA, USA, 17 July 2003; pp. 1–5. [Google Scholar]
- Altman, E.; De Pellegrini, F.; Wang, H. Activation Games in Online Dating Platforms. In Proceedings of the 2015 IEEE International Conference on Communication Workshop (ICCW), London, UK, 8–12 June 2015; pp. 1593–1599. [Google Scholar] [CrossRef] [Green Version]
- Hitsch, G.J.; Hortaçsu, A.; Ariely, D. What Makes You Click? Mate Preferences in Online Dating. Quant. Mark. Econ. 2010, 8, 393–427. [Google Scholar] [CrossRef]
- Simão, J.; Todd, P.M. Emergent Patterns of Mate Choice in Human Populations. Artif. Life 2003, 9, 403–417. [Google Scholar] [CrossRef]
- Roth, A.E.; Sotomayor, M. Chapter 16. Two-sided Matching. In Games and Economic Behavior; Elsevier: Amsterdam, The Netherlands, 1992; Volume 4, pp. 485–541. [Google Scholar] [CrossRef]
- Mumcu, A.; Saglam, I. Marriage Formation/Dissolution and Marital Distribution in a Two-Period Economic Model of Matching with Cooperative Bargaining. J. Artif. Soc. Soc. Simul. 2008, 11, 3. [Google Scholar]
- Shiba, N. Analysis of Asymmetric Two-Sided Matching: Agent-based Simulation with Theorem-Proof Approach. J. Artif. Soc. Soc. Simul. 2013, 16, 1–14. [Google Scholar] [CrossRef]
- Bennett, E. Consistent Bargaining Conjectures in Marriage and Matching. J. Econ. Theory 1988, 45, 392–407. [Google Scholar] [CrossRef]
- Ismail, S. The Mutual Sequential Mate Search Model under Nonhomogenous Preferences. Marriage Fam. Rev. 2019, 55, 530–543. [Google Scholar] [CrossRef]
- Mortensen, D.T. The Matching Process as a Noncooperative Bargaining Game. In The Economics of Information and Uncertainty; National Bureau of Economic Research: Washington, DC, USA, 1982; Volume I, pp. 173–203. [Google Scholar]
- Becker, G.S. A Theory of Marriage. Econ. Fam. Marriage Child. Hum. Cap. 1974, 1, 299–351. [Google Scholar] [CrossRef]
- Koch, L. Dating App Growth Slows, but Advertisers Should Not Ignore Hopeful Singles. 2019. Available online: https://www.emarketer.com/content/dating-app-growth-slows-but-advertisers-shouldnt-ignore-hopeful-single-users (accessed on 1 February 2022).
- Lin, M. Online Dating Industry: The Business of Love. 2019. Available online: https://www.toptal.com/finance/business-model-consultants/online-dating-industry (accessed on 1 February 2022).
- Wendel, M. An Analysis of the Online Dating Industry and How Startups Can Compete. Ph.D. Thesis, Copenhagen Business School, Copenhagen, Denmark, 2015. [Google Scholar]
- Suler, J. The Online Disinhibition Effect. Cyberpsychol. Behav. 2004, 7, 321–326. [Google Scholar] [CrossRef] [PubMed]
- Whitty, M.T. Online Dating. In International Encyclopedia of the Social & Behavioral Sciences; Elsevier: Amsterdam, The Netherlands, 2015; pp. 212–216. [Google Scholar] [CrossRef]
- McGrath, F. What to Know about Tinder in 5 Charts. 2015. Available online: https://blog.globalwebindex.com/trends/what-to-know-about-tinder/ (accessed on 1 February 2022).
- Zytko, D.; Grandhi, S.A.; Jones, Q. Frustrations with Pursuing Casual Encounters through Online Dating. In Proceedings of the 33rd Annual ACM Conference Extended Abstracts on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 1935–1940. [Google Scholar] [CrossRef]
- Brozovsky, L.; Petricek, V. Recommender System for Online Dating Service. arXiv 2007, arXiv:cs/0703042. [Google Scholar]
- Pizzato, L.; Rej, T.; Chung, T.; Koprinska, I.; Kay, J. RECON: A Reciprocal Recommender for Online Dating. In Proceedings of the 4th ACM Conference on Recommender Systems (RecSys’10), Barcelona, Spain, 26–30 September 2010; pp. 207–214. [Google Scholar] [CrossRef]
- Ellison, N.; Heino, R.; Gibbs, J. Managing Impressions Online: Self-Presentation Processes in the Online Dating Environment. J. Comput.-Mediat. Commun. 2006, 11, 415–441. [Google Scholar] [CrossRef]
- Miller, G.F.; Todd, P.M. Mate Choice Turns Cognitive. Trends Cogn. Sci. 1998, 2, 190–198. [Google Scholar] [CrossRef]
- Hancock, J.T.; Toma, C.L. Putting Your Best Face Forward: The Accuracy of Online Dating Photographs. J. Commun. 2009, 59, 367–386. [Google Scholar] [CrossRef]
- Hall, J.A.; Park, N.; Song, H.; Cody, M.J. Strategic Misrepresentation in Online Dating: The Effects of Gender, Self-Monitoring, and Personality Traits. J. Soc. Pers. Relatsh. 2010, 27, 117–135. [Google Scholar] [CrossRef] [Green Version]
- Guadagno, R.E.; Okdie, B.M.; Kruse, S.A. Dating Deception: Gender, Online Dating, and Exaggerated Self-Presentation. Comput. Hum. Behav. 2012, 28, 642–647. [Google Scholar] [CrossRef]
- Toma, C.L.; Hancock, J.T.; Ellison, N.B. Separating Fact from Fiction: An Examination of Deceptive Self-Presentation in Online Dating Profiles. Personal. Soc. Psychol. Bull. 2008, 34, 1023–1036. [Google Scholar] [CrossRef]
- Simão, J.; Todd, P.M. Modeling Mate Choice in Monogamous Mating Systems with Courtship. Adapt. Behav. 2002, 10, 113–136. [Google Scholar] [CrossRef] [Green Version]
- Sumter, S.R.; Vandenbosch, L.; Ligtenberg, L. Love Me Tinder: Untangling Emerging Adults’ Motivations for Using the Dating Application Tinder. Telemat. Inform. 2017, 34, 67–78. [Google Scholar] [CrossRef]
- Silva, R.R.; Koch, M.L.; Rickers, K.; Kreuzer, G.; Topolinski, S. The Tinder Stamp: Perceived Trustworthiness of Online Daters and Its Persistence in Neutral Contexts. Comput. Hum. Behav. 2019, 94, 45–55. [Google Scholar] [CrossRef]
- Gillett, R. Intimate Intrusions Online: Studying the Normalisation of Abuse in Dating Apps. Women’s Stud. Int. Forum 2018, 69, 212–219. [Google Scholar] [CrossRef] [Green Version]
- Gatter, K.; Hodkinson, K. On the Differences between Tinder™ versus Online Dating Agencies: Questioning a Myth. An Exploratory Study. Cogent Psychol. 2016, 3, 1162414. [Google Scholar] [CrossRef]
- Zytko, D.; Grandhi, S.A.; Jones, Q. Online Dating Coaches’ User Evaluation Strategies. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 1337–1343. [Google Scholar] [CrossRef]
- Zang, X.; Yamasaki, T.; Aizawa, K.; Nakamoto, T.; Kuwabara, E.; Egami, S.; Fuchida, Y. How Competitive Are You: Analysis of People’s Attractiveness in an Online Dating System. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 973–978. [Google Scholar] [CrossRef]
- Potârcă, G.; Mills, M. Racial Preferences in Online Dating across European Countries. Eur. Sociol. Rev. 2015, 31, 326–341. [Google Scholar] [CrossRef]
- Ong, D.; Wang, J. Income Attraction: An Online Dating Field Experiment. J. Econ. Behav. Organ. 2015, 111, 13–22. [Google Scholar] [CrossRef]
- Ong, D. Education and Income Attraction: An Online Dating Field Experiment. Appl. Econ. 2016, 48, 1816–1830. [Google Scholar] [CrossRef]
- McGloin, R.; Denes, A. Too Hot to Trust: Examining the Relationship between Attractiveness, Trustworthiness, and Desire to Date in Online Dating. New Media Soc. 2018, 20, 919–936. [Google Scholar] [CrossRef]
- Xia, P.; Ribeiro, B.; Chen, C.; Liu, B.; Towsley, D. A Study of User Behavior on an Online Dating Site. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Niagara Falls, ON, Canada, 25–28 August 2013; p. 5. [Google Scholar]
- Wotipka, C.D.; High, A.C. An Idealized Self or the Real Me? Predicting Attraction to Online Dating Profiles Using Selective Self-Presentation and Warranting. Commun. Monogr. 2016, 83, 281–302. [Google Scholar] [CrossRef]
- Wiederhold, B.K. Twenty Years of Online Dating: Current Psychology and Future Prospects. Cyberpsychol. Behav. Soc. Netw. 2015, 18, 695–696. [Google Scholar] [CrossRef]
- Whyte, S.; Torgler, B. Things Change with Age: Educational Assortment in Online Dating. Personal. Individ. Differ. 2017, 109, 5–11. [Google Scholar] [CrossRef]
- Tsunokai, G.T.; McGrath, A.R.; Kavanagh, J.K. Online Dating Preferences of Asian Americans. J. Soc. Pers. Relatsh. 2014, 31, 796–814. [Google Scholar] [CrossRef]
- Suna, T.; Hardey, M.; Huhtinen, J.; Hiltunen, Y.; Kaski, K.; Heikkonen, J.; Ala-Korpela, M. Self-Organising Map Approach to Individual Profiles: Age, Sex and Culture in Internet Dating. Sociol. Res. Online 2006, 11, 114–129. [Google Scholar] [CrossRef] [Green Version]
- Sritharan, R.; Heilpern, K.; Wilbur, C.J.; Gawronski, B. I Think I like You: Spontaneous and Deliberate Evaluations of Potential Romantic Partners in an Online Dating Context. Eur. J. Soc. Psychol. 2010, 40, 1062–1077. [Google Scholar] [CrossRef]
- McGrath, A.R.; Tsunokai, G.T.; Schultz, M.; Kavanagh, J.; Tarrence, J.A. Differing Shades of Colour: Online Dating Preferences of Biracial Individuals. Ethn. Racial Stud. 2016, 39, 1920–1942. [Google Scholar] [CrossRef]
- Lee, S. Effect of Online Dating on Assortative Mating: Evidence from South Korea: Effect of Online Dating on Assortative Mating. J. Appl. Econom. 2016, 31, 1120–1139. [Google Scholar] [CrossRef]
- Klofstad, C.A.; McDermott, R.; Hatemi, P.K. The Dating Preferences of Liberals and Conservatives. Political Behav. 2013, 35, 519–538. [Google Scholar] [CrossRef]
- Huber, G.A.; Malhotra, N. Political Homophily in Social Relationships: Evidence from Online Dating Behavior. J. Politics 2017, 79, 269–283. [Google Scholar] [CrossRef] [Green Version]
- Plumm, K.M.; Sommer, S.; Uhl, C.; Stone, K. Single Parent Seeking Single Parent? The Effects of Parental and Previous Relationship Status on Perceptions of Online Dating Profiles. J. Relatsh. Res. 2016, 7, e9. [Google Scholar] [CrossRef]
- Hills, T.; Todd, P. Population Heterogeneity and Individual Differences in an Assortative Agent-Based Marriage and Divorce Model (MADAM) Using Search with Relaxing Expectations. J. Artif. Soc. Soc. Simul. 2008, 11, 5. [Google Scholar]
- Aral, S.; Muchnik, L.; Sundararajan, A. Distinguishing Influence-Based Contagion from Homophily-Driven Diffusion in Dynamic Networks. Proc. Natl. Acad. Sci. USA 2009, 106, 21544–21549. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reagans, R.E. Close Encounters: Analyzing How Social Similarity and Propinquity Contribute to Strong Network Connections. Organ. Sci. 2011, 22, 835–849. [Google Scholar] [CrossRef] [Green Version]
- Centola, D. The Social Origins of Networks and Diffusion. Am. J. Sociol. 2015, 120, 1295–1338. [Google Scholar] [CrossRef] [Green Version]
- McPherson, M.; Smith-Lovin, L.; Cook, J.M. Birds of a Feather: Homophily in Social Networks. Annu. Rev. Sociol. 2001, 27, 415–444. [Google Scholar] [CrossRef] [Green Version]
- Fiore, A.T.; Donath, J.S. Homophily in Online Dating: When Do You like Someone like Yourself? In Proceedings of the Conference on Human Factors in Computing Systems, Portland, OR, USA, 2–7 April 2005; pp. 1371–1374. [Google Scholar] [CrossRef]
- Ibarra, H. Homophily and Differential Returns: Sex Differences in Network Structure and Access in an Advertising Firm. Adm. Sci. Q. 1992, 37, 422. [Google Scholar] [CrossRef]
- Gibbons, D.; Olk, P.M. Individual and Structural Origins of Friendship and Social Position among Professionals. J. Personal. Soc. Psychol. 2003, 84, 340–351. [Google Scholar] [CrossRef]
- Griffin, E.M.; Fingerman, K.L. Online Dating Profile Content of Older Adults Seeking Same- and Cross-Sex Relationships. J. GLBT Fam. Stud. 2018, 14, 446–466. [Google Scholar] [CrossRef]
- Tyson, G.; Perta, V.C.; Haddadi, H.; Seto, M.C. A First Look at User Activity on Tinder. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM 2016, Davis, CA, USA, 18–21 August 2016; pp. 461–466. [Google Scholar] [CrossRef] [Green Version]
- Hagberg, A.A.; Schult, D.A.; Swart, P.J.; Varoquaux, G.; Vaught, T.; Millman, J. Exploring Network Structure, Dynamics, and Function Using NetworkX. In Proceedings of the 7th Python in Science Conference (SciPy2008), Pasadena, CA, USA, 19–24 August 2008; pp. 11–15. [Google Scholar]
- Granovetter, M. Threshold Models of Collective Behavior. Am. J. Sociol. 1978, 83, 1420–1443. [Google Scholar] [CrossRef] [Green Version]
- Conway, J.R.; Noë, N.; Stulp, G.; Pollet, T.V. Finding Your Soulmate: Homosexual and Heterosexual Age Preferences in Online Dating. Pers. Relatsh. 2015, 22, 666–678. [Google Scholar] [CrossRef]
- Greenlees, I.A.; Mcgrew, W.C. Sex and Age Differences in Preferences and Tactics of Mate Attraction: Analysis of Published Advertisements. Ethol. Sociobiol. 1994, 15, 59–72. [Google Scholar] [CrossRef]
- Fisman, R.; Iyengar, S.S.; Kamenica, E.; Simonson, I. Gender Differences in Mate Selection: Evidence from a Speed Dating Experiment. Q. J. Econ. 2006, 121, 673–697. [Google Scholar] [CrossRef] [Green Version]
- Bruch, E.E.; Newman, M.E.J. Aspirational Pursuit of Mates in Online Dating Markets. Sci. Adv. 2018, 4, eaap9815. [Google Scholar] [CrossRef] [Green Version]
- Altman, I. Reciprocity of Interpersonal Exchange. J. Theory Soc. Behav. 1973, 3, 249–261. [Google Scholar] [CrossRef]
- Tantardini, M.; Ieva, F.; Tajoli, L.; Piccardi, C. Comparing Methods for Comparing Networks. Sci. Rep. 2019, 9, 1–19. [Google Scholar] [CrossRef]
- Dekker, D.; Krackhardt, D.; Snijders, T.A.B. Sensitivity of MRQAP Tests to Collinearity and Autocorrelation Conditions. Psychometrika 2007, 72, 563–581. [Google Scholar] [CrossRef] [Green Version]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast Unfolding of Communities in Large Networks. J. Stat. Mech. Theory Exp. 2008, 10008, 6. [Google Scholar] [CrossRef] [Green Version]
- Gode, D.K.; Sunder, S. Allocative Efficiency of Markets with Zero-Intelligence Traders: Market as a Partial Substitute for Individual Rationality. J. Political Econ. 1993, 101, 119–137. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [Green Version]
- Kreager, D.A.; Cavanagh, S.E.; Yen, J.; Yu, M. “Where Have All the Good Men Gone?” Gendered Interactions in Online Dating: Gendered Interactions in Online Dating. J. Marriage Fam. 2014, 76, 387–410. [Google Scholar] [CrossRef] [Green Version]
- Fiore, A.R.T. Romantic Regressions: An Analysis of Behavior in Online Dating Systems. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2004. [Google Scholar]
- Hamilton, N.F. Romantic Relationships and Online Dating. In Applied Cyberpsychology; Attrill, A., Fullwood, C., Eds.; Palgrave Macmillan: London, UK, 2016; pp. 144–160. [Google Scholar] [CrossRef]
- Best, K.; Delmege, S. The Filtered Encounter: Online Dating and the Problem of Filtering through Excessive Information. Soc. Semiot. 2012, 22, 237–258. [Google Scholar] [CrossRef]
- Grazzini, J.; Richiardi, M.G.; Tsionas, M. Bayesian Estimation of Agent-Based Models. J. Econ. Dyn. Control 2017, 77, 26–47. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Variable Type | Assignment |
|---|---|---|
| Gender () | Discrete Binary | |
| Ethnicity () | Discrete Uniform | |
| Age () | Continuous Uniform | |
| Physical Attractiveness () | Continuous Uniform | |
| Compatibility Threshold () | Constant | |
| Model Attribute | Condition | Value | Description | |
|---|---|---|---|---|
| Compatibility Score (ethnicity) |  | |||
| Compatibility Score (age) |  | |||
| Compatibility Score (age) |  | |||
| Compatibility Score (attractiveness) |  | |||
| Total Score | | |||
| Statistic | N | 0th | 25th | 75th | 100th | ||
|---|---|---|---|---|---|---|---|
| Attractiveness | 1000 | 0.512 | 0.293 | 0.001 | 0.257 | 0.778 | 0.999 |
| Age | 1000 | 42.088 | 13.063 | 19 | 31 | 54 | 64 |
| Ethnicity | 1000 | 2.462 | 1.122 | 1 | 1 | 3 | 4 |
| Statistic | N | 0th | 25th | 75th | 100th | ||
|---|---|---|---|---|---|---|---|
| Attractiveness | 1000 | 0.483 | 0.284 | 0.001 | 0.229 | 0.723 | 1.000 |
| Age | 1000 | 40.879 | 13.989 | 18 | 28 | 53 | 65 |
| Ethnicity | 1000 | 2.495 | 1.101 | 1 | 2 | 3 | 4 |
| Relation Type | t | p | 95% CI | |
|---|---|---|---|---|
| ‘Like’ | 0.001 | 0.002 | 1.00 | [−0.81, 0.8] |
| ‘Dislike’ | 3.901 | 1.53 | 0.12 | [−1.07, 8.87] |
| ‘Match’ | 5.85 | 31.35 | p < 0.001 | [5.48, 6.21] |
| ‘Like Message’ | −2.874 | −43.57 | p < 0.001 | [−3.00, −2.7] |
| Statistic | N | 0th | 25th | 75th | 100th | ||
|---|---|---|---|---|---|---|---|
| ‘Like’ Count | 1000 | 33.030 | 8.504 | 10 | 27 | 39 | 58 |
| ‘Dislike’ Count | 1000 | 146.600 | 60.624 | 48 | 105 | 207.2 | 264 |
| ‘Match’ Count | 1000 | 11.694 | 5.029 | 0 | 8 | 15 | 31 |
| ‘Message’ Count | 1000 | 0.000 | 0.000 | 0 | 0 | 0 | 0 |
| Statistic | N | 0th | 25th | 75th | 100th | ||
|---|---|---|---|---|---|---|---|
| ‘Like’ Count | 1000 | 33.029 | 9.983 | 7 | 26 | 41 | 61 |
| ‘Dislike’ Count | 1000 | 142.699 | 53.134 | 55 | 108.8 | 198.2 | 251 |
| ‘Match’ Count | 1000 | 5.844 | 3.112 | 0 | 4 | 8 | 18 |
| ‘Message’ Count | 1000 | 2.874 | 2.086 | 0 | 1 | 4 | 12 |
| M1 | M2 (False) | M2 (True) | |
|---|---|---|---|
| like network | 2.55 × 10 | −6.05 × 10 | −6.06 × 10 |
| Pr(<=b) | (1.0) | (0.0) | (0.0) |
| Pr(>=b) | (0.0) | (1.0) | (1.0) |
| Pr(>=|b|) | (0.0) | (0.0) | (0.0) |
| message network | −4.35 × 10 | ||
| Pr(<=b) | (0.0) | ||
| Pr(>=b) | (1.0) | ||
| Pr(>=|b|) | (0.0) | ||
| attractiveness (difference) | 2.04 × 10 | −6.87 × 10 | 1.64 × 10 |
| Pr(<=b) | (0.8) | (0.93) | (0.92) |
| Pr(>=b) | (0.2) | (0.07) | (0.01) |
| Pr(>=|b|) | (0.45) | (0.14) | (0.1) |
| age (difference) | 2.02 × 10 | 1.64 × 10 | −4.96 × 10 |
| Pr(<=b) | (0.55) | (0.01) | (0.01) |
| Pr(>=b) | (0.45) | (0.99) | (0.99) |
| Pr(>=|b|) | (0.99) | (0.03) | (0.03) |
| ethnicity (difference) | 1.24 × 10 | −4.00 × 10 | 2.14 × 10 |
| Pr(<=b) | (0.70) | (0.78) | (0.8) |
| Pr(>=b) | (0.30) | (0.22) | (0.2) |
| Pr(>=|b|) | (0.65) | (0.38) | (0.42) |
| intercept | 3.15 × 10 | 5.88 × 10 | 5.90 × 10 |
| Pr(<=b) | (1.0) | (1.0) | (1.0) |
| Pr(>=b) | (0.0) | (0.0) | (0.0) |
| Pr(>=|b|) | (0.0) | (0.0) | (0.0) |
| Permutation(s) | 100 | 100 | 100 |
| R | 0.1809 | 0.000205 | 0.000218 |
| Adjusted R | 0.1809 | 0.00020 | 0.00021 |
| Residual Std. Error (df = 998,995) | 0.097 | 0.25 | 0.076 |
| F Statistic (df = 4; 998,995) | 55,170 | 51.24 | 43.59 |
| Order of Contribution | Rank by Magnitude | |||||
|---|---|---|---|---|---|---|
| M1 | M2-F | M2-T | M1 | M2-F | M2-T | |
| like network | ① | ④ | ⑤ |  | | |
| message network | — | — | ④ | — | — | |
| attractiveness (difference) | ② | ③ | ② |  | | |
| age (difference) | ④ | ① | ③ |  | | |
| ethnicity (difference) | ③ | ② | ① | | | |
| intercept | X | X | X | X | X | X |
| Statistic | N | 0th | 25th | 75th | 100th | ||
|---|---|---|---|---|---|---|---|
| ‘Like’ Count | 1000 | 11.365 | 3.900 | 1 | 9 | 14 | 26 |
| ‘Dislike’ Count | 1000 | 146.581 | 61.168 | 49 | 108 | 203.2 | 268 |
| ‘Match’ Count | 1000 | 12.810 | 5.558 | 0 | 9 | 16 | 32 |
| ‘Message’ Count | 1000 | 0.000 | 0.000 | 0 | 0 | 0 | 0 |
| Statistic | N | 0th | 25th | 75th | 100th | ||
|---|---|---|---|---|---|---|---|
| ‘Like’ Count | 1000 | 32.875 | 9.645 | 10 | 26 | 40 | 61 |
| ‘Dislike’ Count | 1000 | 140.707 | 56.232 | 50 | 103 | 200 | 251 |
| ‘Match’ Count | 1000 | 5.682 | 3.036 | 0 | 3 | 7 | 16 |
| ‘Message’ Count | 1000 | 2.841 | 2.068 | 0 | 1 | 4 | 14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shaheen, J.A.E.; Henley, C.; McKenna, L.; Hoang, S.; Abdulwahab, F. Comparative Agent-Based Simulations on Levels of Multiplicity Using a Network Regression: A Mobile Dating Use-Case. Appl. Sci. 2022, 12, 1982. https://0-doi-org.brum.beds.ac.uk/10.3390/app12041982
Shaheen JAE, Henley C, McKenna L, Hoang S, Abdulwahab F. Comparative Agent-Based Simulations on Levels of Multiplicity Using a Network Regression: A Mobile Dating Use-Case. Applied Sciences. 2022; 12(4):1982. https://0-doi-org.brum.beds.ac.uk/10.3390/app12041982
Chicago/Turabian StyleShaheen, Joseph A. E., Collin Henley, Liam McKenna, Steven Hoang, and Fatma Abdulwahab. 2022. "Comparative Agent-Based Simulations on Levels of Multiplicity Using a Network Regression: A Mobile Dating Use-Case" Applied Sciences 12, no. 4: 1982. https://0-doi-org.brum.beds.ac.uk/10.3390/app12041982