
Efficient Diagnosis of Autism with Optimized Machine Learning Models: An Experimental Analysis on Genetic and Personal Characteristic Datasets


Abstract
:1. Introduction
- Is the proposed bio-inspired-based wrapper feature selection method able to enhance the accuracy results of ML classifiers in ASD prediction?
- Which one of the proposed 16 optimized models will give the best performance in ASD prediction in terms of accuracy and on which dataset?
- What is the type of dataset (PBC and GE) that will give the best accuracy result for predicting ASD?
- Will the deep learning approach give better results in the ASD prediction problem on PBC and GE datasets compared to the proposed bio-inspired-based wrapper feature selection method?
2. Background
2.1. Personal and Behavioral Characteristics (PBC)
2.2. Gene Expression Profile (GE)
2.3. Classification Algorithms
2.4. Feature Selection (FS)
2.5. Nature-Inspired Computation (NIC)
2.6. Bio-Inspired Algorithms
2.7. Grey Wolf Optimization (GWO)
2.8. Bat Algorithms (BA)
2.9. Flower Pollination Algorithms (FPA)
2.10. Artificial Bee Colony (ABC)
3. Related Work
3.1. ASD Prediction Using ML Approach
3.1.1. ASD Prediction Using ML without FS Methods
3.1.2. ASD Prediction Using ML with FS Methods
3.1.3. ASD Prediction Using ML with Optimized FS Methods
3.2. ASD Prediction Using DL Approach
- Two methods used for predicting ASD: ML and DL.
- Multiple ASD datasets such PBC, GE, and IMR brain images are widely used for ASD diagnosis.
- The 10-fold cross-validation was the most used for dataset partitioning.
- Bio-inspired algorithms proved their ability to enhance ASD prediction in three types of datasets.
- MRI brain datasets, compared with the two other datasets types, did not show a high performance in ASD prediction when using ML or DL approaches.
4. Materials and Methods
4.1. Anaconda Environment
4.2. Dataset Overview
4.2.1. PBC Dataset
4.2.2. GE Dataset
4.3. Data Preprocessing
4.3.1. PBC Dataset
4.3.2. GE Dataset
4.4. Proposed Predictive Models
4.4.1. The Feature Selection Phase
4.4.2. The Classification Phase
5. Implementation and Results
5.1. Experiment 1
5.2. Experiment 2
5.2.1. Comparison between Experiment 1 and Experiment 2
5.2.2. Comparison between the Proposed Models and Previous Work
5.2.3. Comparison between the Proposed Models and the DL Based Model
6. Conclusions and Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Definition |
| ASD | Autism spectrum disorder |
| ML | Machine learning |
| DL | Deep learning |
| GE | Gene expression |
| PBC | Personal and behavioral characteristics |
| GWO | Gray wolf optimization |
| FPA | Flower pollination algorithm |
| BA | Bat algorithms |
| ABC | Artificial bee colony |
| AUC | Area under the curve |
| SVM | Support vector machine |
| DT | Decision tree |
| NB | Naïve Bayes |
| KNN | K-nearest neighbor |
| FS | Feature selection |
| NIC | Nature-inspired computation |
| UCI | University of California, Irvine |
| LR | Linear regression |
| LDA | Linear discriminant analysis |
| RF | Random forest |
| SVC | Support vector classifier |
| RT | Random tree |
| CFS | Correlation feature selection |
| BT | Bagged tree feature selector |
| REF | Recursive feature elimination |
| IG | Information gain |
| SMO | Sequential minimal optimization |
| ABIDE | Autism brain imaging data exchange dataset |
| GBM | Gradient boosting machine |
| GBPSO | Geometric binary particle swarm optimization |
| WRS | Wilcoxon rank sum test |
| PSO | Particle swarm optimization |
| RFE | Recursive feature elimination |
| PDD | Pervasive developmental disorder |
References
- Hirvikoski, T.; Mittendorfer-Rutz, E.; Boman, M.; Larsson, H.; Lichtenstein, P.; Bölte, S. Premature mortality in autism spectrum disorder. Br. J. Psychiatry 2016, 208, 232–238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. Feature selection for high-dimensional data. Prog. Artif. Intell. 2016, 5, 65–75. [Google Scholar] [CrossRef]
- Vaishali, R.; Sasikala, R. A machine learning based approach to classify autism with optimum behavior sets. Int. J. Eng. Technol. 2018, 7, 1–6. [Google Scholar] [CrossRef]
- Al-Baity, H.H.; Al-Mutlaq, N. A New Optimized Wrapper Gene Selection Method for Breast Cancer Prediction. Comput. Mater. Contin. 2021, 67, 3089–3106. [Google Scholar] [CrossRef]
- Erkan, U.; Thanh, D. Autism Spectrum Disorder Detection with Machine Learning Methods. Curr. Psychiatry Rev. 2019, 15, 297–308. [Google Scholar] [CrossRef]
- Raza, K. Analysis of Microarray Data Using Artificial Intelligence Based Techniques; IGI Global: Hershey, PA, USA, 2016; pp. 216–239. [Google Scholar]
- Suthaharan, S. Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Springer: New York, NY, USA, 2015; p. 36. [Google Scholar]
- Almugren, N.; Alshamlan, H. A Survey on Hybrid Feature Selection Methods in Microarray Gene Expression Data for Cancer Classification. IEEE Access 2019, 7, 78533–78548. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. ACM Comput. Surv. 2017, 50, 94:1–94:45. [Google Scholar] [CrossRef] [Green Version]
- Lazar, C.; Taminau, J.; Meganck, S.; Steenhoff, D.; Coletta, A.; Molter, C.; de Schaetzen, V.; Duque, R.; Bersini, H.; Nowe, A. A survey on filter techniques for feature selection in gene expression microarray analysis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2012, 9, 1106–1119. [Google Scholar] [CrossRef]
- Sheikhpour, R.; Sarram, M.A.; Sheikhpour, R. Particle swarm optimization for bandwidth determination and feature selection of kernel density estimation based classifiers in diagnosis of breast cancer. Appl. Soft Comput. 2016, 40, 113–131. [Google Scholar] [CrossRef]
- Fan, X.; Sayers, W.; Zhang, S.; Han, Z.; Ren, L.; Chizari, H. Review and Classification of Bio-inspired Algorithms and Their Applications. J. Bionic Eng. 2020, 17, 611–631. [Google Scholar] [CrossRef]
- Fister, I., Jr.; Yang, X.-S.; Fister, I.; Brest, J.; Fister, D. A Brief Review of Nature-Inspired Algorithms for Optimization. Elektrotehniski Vestn./Electrotech. Rev. 2013, 80, 116–122. [Google Scholar]
- Applying Grey Wolf Optimizer-Based Decision Tree Classifer for Cancer Classification on Gene Expression Data | IEEE Conference Publication | IEEE Xplore. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/7365818 (accessed on 17 April 2021).
- Yang, X.-S. A New Metaheuristic Bat-Inspired Algorithm. In Nature Inspired Cooperative Strategies for Optimization (NICSO 2010); González, J.R., Pelta, D.A., Cruz, C., Terrazas, G., Krasnogor, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 65–74. [Google Scholar]
- Dankolo, N.; Radzi, N.; Sallehuddin, R.; Mustaffa, N. Hybrid Flower Pollination Algorithm and Support Vector Machine for Breast Cancer Classification. J. Technol. Manag. Bus. 2018, 5, 1. [Google Scholar] [CrossRef] [Green Version]
- A Simple and Efficient Artificial Bee Colony Algorithm. Math. Probl. Eng. 2013, 2013, 526315. Available online: https://www.hindawi.com/jour-nals/mpe/2013/526315/ (accessed on 3 December 2020).
- Tyagi, B.; Mishra, R.; Bajpai, N. Machine Learning Techniques to Predict Autism Spectrum Disorder. In Proceedings of the 2018 IEEE Punecon, Pune, India, 30 November–2 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Chinnaiyan, R. Optimized Machine Learning Classification Approaches for Prediction of Autism Spectrum Disorder. Ann. Autism. Dev. Disord. 2020, 1, 1–6. [Google Scholar]
- ALARIFI, H.S.; YOUNG, G.S. Using multiple machine learning algorithms to predict autism in children. In Proceedings of the International Conference on Artificial Intelligence (ICAI). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), Las Vegas, NV, USA, 30 July–2 August 2018; pp. 464–467. [Google Scholar]
- Oh, D.H.; Kim, I.B.; Kim, S.H.; Ahn, D.H. Predicting Autism Spectrum Disorder Using Blood-based Gene Expression Signatures and Machine Learning. Clin. Psychopharmacol. Neurosci. 2017, 15, 47–52. [Google Scholar] [CrossRef]
- Sudha, V.P.; Vijaya, M.S. Machine Learning-Based Model for Identification of Syndromic Autism Spectrum Disorder. In Integrated Intelligent Computing, Communication and Security; Krishna, A.N., Srikantaiah, K.C., Naveena, C., Eds.; Springer: Singapore, 2019; Volume 771, pp. 141–148. [Google Scholar]
- Asif, M.; Martiniano, H.F.M.C.M.; Vicente, A.M.; Couto, F.M. Identifying disease genes using machine learning and gene functional similarities, assessed through Gene Ontology. PLoS ONE 2018, 13, e0208626. [Google Scholar] [CrossRef] [Green Version]
- Katuwal, G.J.; Cahill, N.D.; Baum, S.A.; Michael, A.M. The predictive power of structural MRI in Autism diagnosis. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 4270–4273. [Google Scholar] [CrossRef]
- Selvaraj, S.; Palanisamy, P.; Parveen, S. Monisha. Autism Spectrum Disorder Prediction Using Machine Learning Algorithms. In Computational Vision and Bio-Inspired Computing; Smys, S., Tavares, J.M.R.S., Balas, V.E., Iliyasu, A.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 1108, pp. 496–503. [Google Scholar]
- Hossain, M.D.; Kabir, M.A.; Anwar, A.; Islam, M.Z. Detecting Autism Spectrum Disorder using Machine Learning. arXiv 2020, arXiv:2009.14499. [Google Scholar]
- Samy, N.; Fathalla, R.; Belal, N.A.; Badawy, O. Classification of Autism Gene Expression Data Using Deep Learning. Intelligent Data Communication Technologies and Internet of Things 2019, 583–596. [Google Scholar]
- Jin, Y.; Wee, C.Y.; Shi, F.; Thung, K.H.; Ni, D.; Yap, P.T.; Shen, D. Identification of infants at high-risk for autism spectrum disorder using multiparameter multiscale white matter connectivity networks. Hum. Brain Mapp. 2015, 36, 4880–4896. [Google Scholar] [CrossRef] [Green Version]
- Katuwal, G.J. Machine Learning Based Autism Detection Using Brain Imaging; Rochester Institute of Technology: Rochester, NY, USA, 2017. [Google Scholar]
- Hameed, S.S.; Hassan, R.; Muhammad, F.F. Selection and classification of gene expression in autism disorder: Use of a combination of statistical filters and a GBPSO-SVM algorithm. PLoS ONE 2017, 12, e0187371. [Google Scholar] [CrossRef] [Green Version]
- Latkowski, T.; Osowski, S. Developing Gene Classifier System for Autism Recognition. In Advances in Computational Intelligence; Springer: Cham, Switzerland, 2015; pp. 3–14. [Google Scholar] [CrossRef]
- Chen, C.P.; Keown, C.L.; Jahedi, A.; Nair, A.; Pflieger, M.E.; Bailey, B.A.; Müller, R.A. Diagnostic classification of intrinsic functional connectivity highlights somatosensory, default mode, and visual regions in autism. NeuroImage Clin. 2015, 8, 238–245. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thomas, R.M.; Gallo, S.; Cerliani, L.; Zhutovsky, P.; El-Gazzar, A.; van Wingen, G. Classifying Autism Spectrum Disorder Using the Temporal Statistics of Resting-State Functional MRI Data With 3D Convolutional Neural Networks. Front. Psychiatry 2020, 11, 440. [Google Scholar] [CrossRef] [PubMed]
- Dvornek, N.C.; Ventola, P.; Duncan, J.S. Combining phenotypic and resting-state fMRI data for autism classification with recurrent neural networks. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 725–728. [Google Scholar] [CrossRef]
- Dashtban, M.; Balafar, M.; Suravajhala, P. Gene selection for tumor classification using a novel bio-inspired multi-objective approach. Genomics 2018, 110, 10–17. [Google Scholar] [CrossRef] [PubMed]
- Musheer, R.; Verma, C.K.; Srivastava, N. Dimension reduction methods for microarray data: A review. AIMS Bioeng. 2017, 4, 179–197. [Google Scholar] [CrossRef]
- Introduction to Data Science: A Python Approach to Concepts, Techniques and Applications. 2017. Available online: https://www.worldcat.org/title/introduction-to-data-science-a-python-approach-to-concepts-techniques-and-applications/oclc/986740318 (accessed on 17 April 2021).
- UCI Machine Learning Repository: Autistic Spectrum Disorder Screening Data for Children Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/Autistic+Spectrum+Disorder+Screening+Data+for+Children++ (accessed on 2 December 2020).
- ASD. Autism Spectrum Disorder Tests App. Available online: http://www.asdtests.com/ (accessed on 2 December 2020).
- National Center for Biotechnology Information. Available online: https://0-www-ncbi-nlm-nih-gov.brum.beds.ac.uk/ (accessed on 18 November 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Ref | ML Classifier | Classification Accuracy |
|---|---|---|---|
| PBC | [18] | KNN LR SVM LDA NB | 67.5% 72% 70.5% 72.2% 70.7% |
| [5] | K-NN SVM RF | 86.8% 90.9% 99.5% | |
| [19] | K-NN LR RF | 69.2% 68.60% 67.78% | |
| [20] | RF SVC | 55% 62% | |
| GE | [21] | SVM K-NN LDA | 93.7% 93.8% 68.8% |
| [22] | DT SVM | 98% 96% | |
| [23] | RF | 80% | |
| MRI Images | [24] | RF | 59% |
| Data Type | Ref | FS | ML Classifier | Classification Accuracy |
|---|---|---|---|---|
| PBC | [25] | Chi Square RFE CFS IG BT | RT | 94.9% 95.2% 93.5% 95.1% 95.7% |
| [26] | Relief Attribute | SMO | 100% | |
| GE | [27] | IG | DT K-NN NB | 53.3% 83.3% 86.67% |
| MRI Images | [28] | t-test filter LASSO logistic regression | SVM | 76% |
| [29] | RFE | RF | 60% |
| Data Type | Ref | FS | ML Classifier | Classification Accuracy |
|---|---|---|---|---|
| PBC | [3] | Binary Firefly | NB SVM K-NN | 95.55% 97.95% 93.84% |
| GE | [30] | (TT)+ (COR)+ (WRS)+ GBPSO | SVM | 92.1% |
| [31] | GA | RF | 87% | |
| MRI Images | [32] | PSO | SVM RF | 81% 91% |
| Data Type | Ref | ML Classifier | Classification Accuracy |
|---|---|---|---|
| GE | [27] | DBN | 98.64% |
| MRI Images | [33] | CNN | 63% |
| [34] | RNN | 70.1% |
| Data Type | PBC | GE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Eva. Metrix | Acc | F1-Score | Precision | Recall | AUC | Acc | F1-Score | Precision | Recall | AUC |
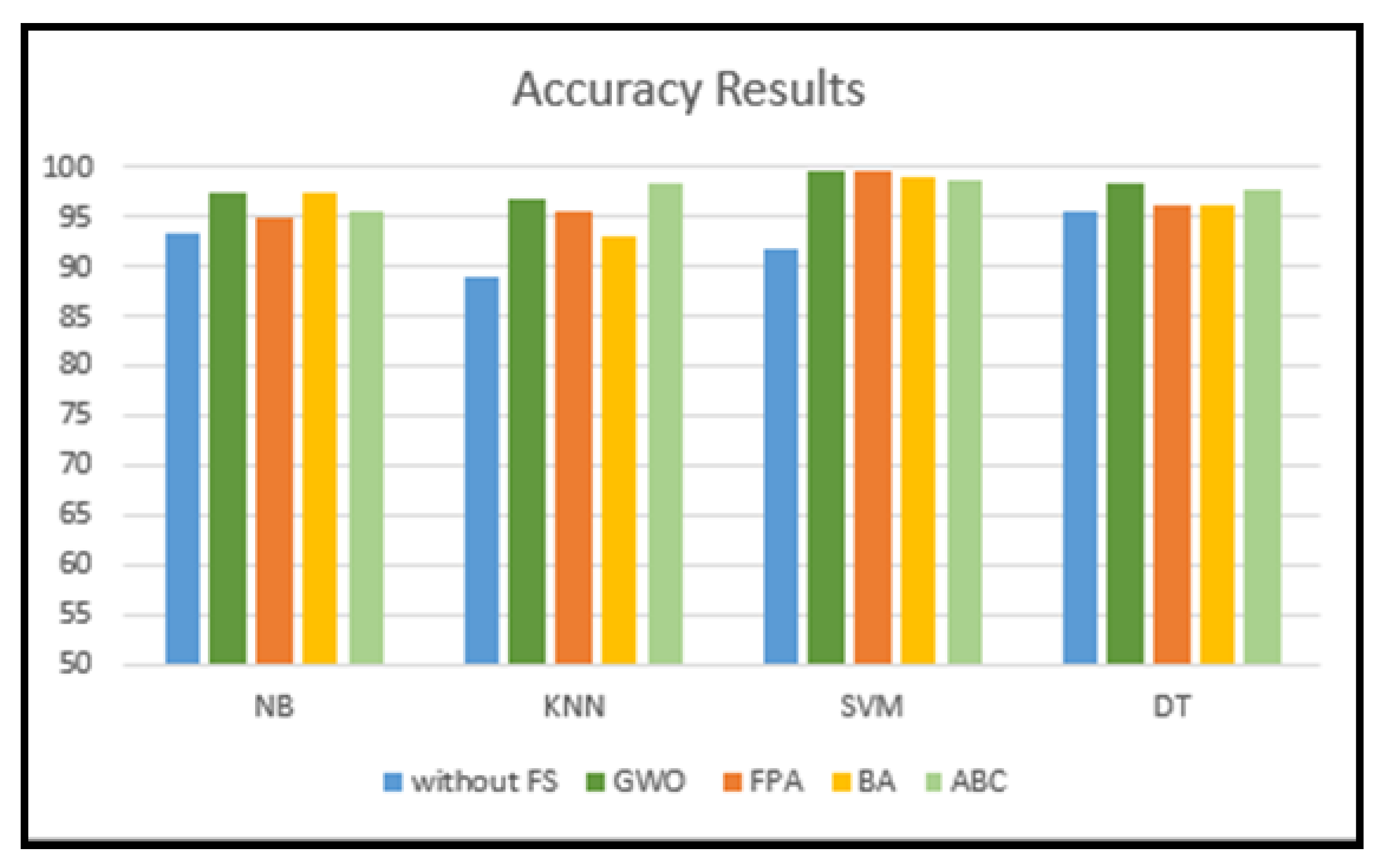
| NB | 93.49 | 93.0 | 94.0 | 93.0 | 93.52 | 66.7 | 64.0 | 73.0 | 67.0 | 67.0 |
| KNN | 89.03 | 89.0 | 89.0 | 89.0 | 90.0 | 56.66 | 57.0 | 77.0 | 57.0 | 59.9 |
| SVM | 91.7 | 92.0 | 92.0 | 92.0 | 92.2 | 80.0 | 80.0 | 82.0 | 80.0 | 80.3 |
| DT | 95.5 | 96.0 | 96.0 | 96.0 | 95.9 | 86.6 | 87.0 | 87.0 | 87.0 | 88.1 |
| Data Type | PBC | GE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Grey Wolf Optimization | ||||||||||
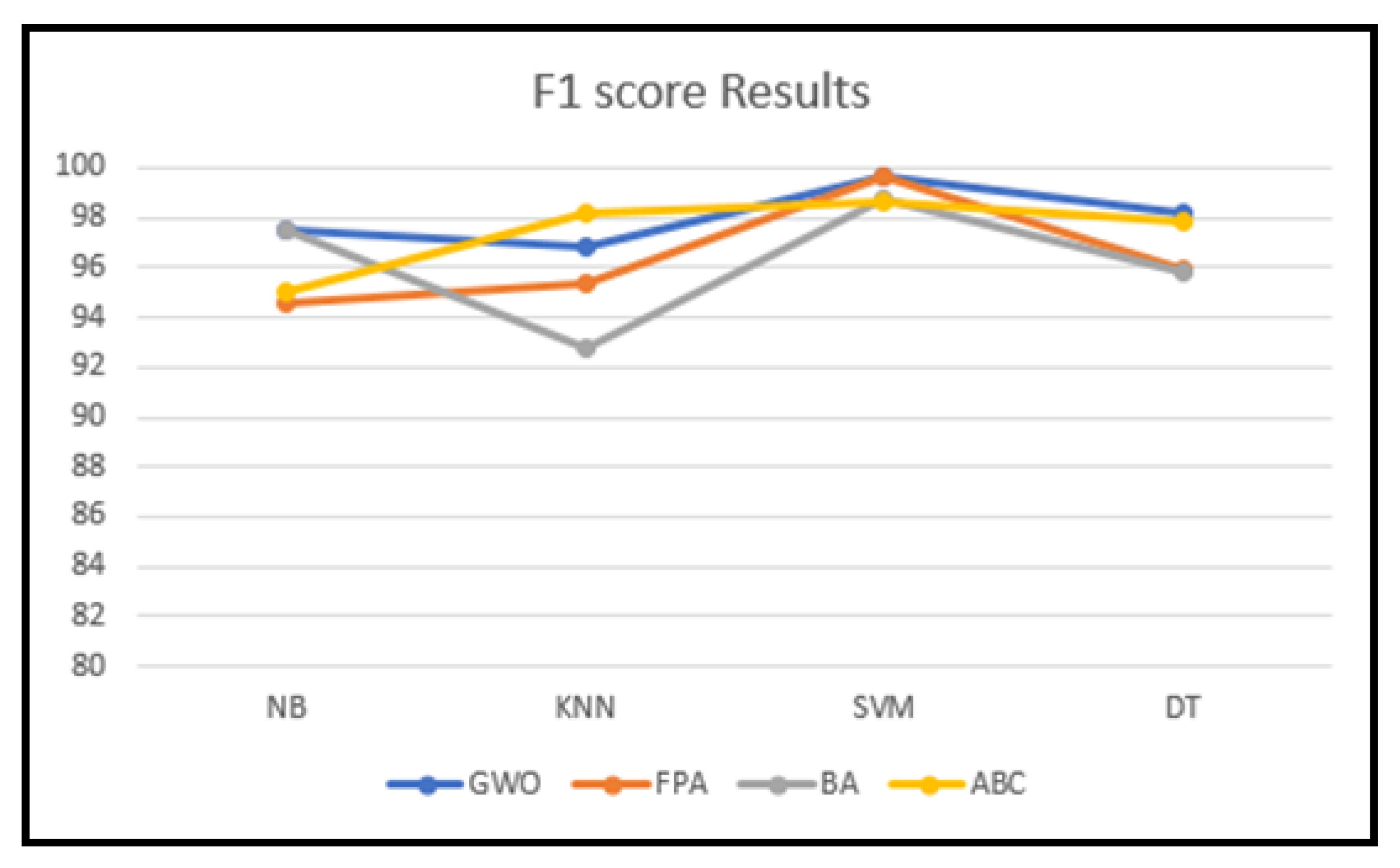
| AUC | Recall | Precision | F1-Score | Acc | AUC | Recall | Precision | F1-Score | Acc | |
| NB | 97.58 | 97.48 | 97.89 | 97.14 | 97.57 | 63.34 | 43.0 | 46.66 | 45.0 | 60.0 |
| KNN | 96.89 | 96.79 | 97.23 | 96.42 | 96.88 | 63.33 | 72.0 | 58.33 | 100 | 62.5 |
| SVM | 99.66 | 99.67 | 99.33 | 100 | 99.69 | 99.34 | 96.0 | 100 | 92.66 | 99.33 |
| DT | 98.29 | 98.16 | 98.54 | 97.85 | 98.27 | 80.0 | 83.33 | 81.66 | 95.0 | 85.0 |
| Flower Pollination Algorithm | ||||||||||
| NB | 94.88 | 94.61 | 94.56 | 95.04 | 94.87 | 70.0 | 59.66 | 61.66 | 60.0 | 61.0 |
| KNN | 95.52 | 95.33 | 95.10 | 95.76 | 95.54 | 60.0 | 70.33 | 56.66 | 100 | 60.0 |
| SVM | 99.56 | 99.65 | 99.33 | 100 | 99.66 | 96.67 | 97.14 | 95.0 | 100 | 96.67 |
| DT | 96.21 | 95.98 | 97.10 | 95.0 | 96.16 | 76.66 | 69.33 | 68.33 | 75.0 | 72.5 |
| Bat Algorithm | ||||||||||
| NB | 97.60 | 97.50 | 98.61 | 96.47 | 97.57 | 63.33 | 43.33 | 50.0 | 40.0 | 57.5 |
| KNN | 93.14 | 92.82 | 93.63 | 92.85 | 93.09 | 56.66 | 68.33 | 53.33 | 100 | 55.0 |
| SVM | 98.97 | 98.78 | 98.01 | 100 | 99.0 | 97.43 | 97.33 | 97.33 | 97.33 | 97.34 |
| DT | 96.22 | 95.83 | 97.75 | 94.22 | 96.11 | 89.99 | 91.66 | 93.33 | 95.0 | 92.0 |
| Artificial Bee Colony | ||||||||||
| NB | 95.54 | 95.02 | 97.90 | 92.85 | 95.42 | 56.66 | 48.33 | 55.0 | 45.0 | 52.5 |
| KNN | 98.27 | 98.22 | 97.90 | 98.57 | 98.28 | 53.33 | 66.67 | 51.66 | 100 | 52.5 |
| SVM | 98.63 | 98.61 | 98.08 | 99.28 | 98.66 | 96.66 | 96.0 | 100 | 93.33 | 96.67 |
| DT | 97.73 | 97.89 | 98.06 | 97.85 | 97.92 | 93.33 | 94.66 | 91.66 | 100 | 92.5 |
| Data Type | Before Optimized FS | After Optimized FS | |||
|---|---|---|---|---|---|
| Algorithm | |||||
| GWO | FPA | BA | ABC | ||
| PBC | 20 | 6 | 13 | 4 | 12 |
| GE | 43,931 | 15,392 | 21,714 | 21,556 | 21,469 |
| Previous Work [3] | Proposed Models | ||||
|---|---|---|---|---|---|
| FA-SVM | GWO-SVM | FPA-SVM | BA-SVM | ABC-SVM | |
| Accuracy | 97.95% | 99.66% | 99.5% | 98.9% | 98.63% |
| Previous Work [27] | Proposed Models | ||||
|---|---|---|---|---|---|
| DBN-IG | GWO-SVM | FPA-SVM | BA-SVM | ABC-SVM | |
| Accuracy | 98.64% | 99.34% | 96.6% | 97.4% | 96.66% |
| PBC | GE | |||
|---|---|---|---|---|
| CNN | GWO-SVM | CNN | GWO-SVM | |
| Accuracy | 98.64% | 99.66% | 99.98% | 99.34% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsuliman, M.; Al-Baity, H.H. Efficient Diagnosis of Autism with Optimized Machine Learning Models: An Experimental Analysis on Genetic and Personal Characteristic Datasets. Appl. Sci. 2022, 12, 3812. https://0-doi-org.brum.beds.ac.uk/10.3390/app12083812
Alsuliman M, Al-Baity HH. Efficient Diagnosis of Autism with Optimized Machine Learning Models: An Experimental Analysis on Genetic and Personal Characteristic Datasets. Applied Sciences. 2022; 12(8):3812. https://0-doi-org.brum.beds.ac.uk/10.3390/app12083812
Chicago/Turabian StyleAlsuliman, Maraheb, and Heyam H. Al-Baity. 2022. "Efficient Diagnosis of Autism with Optimized Machine Learning Models: An Experimental Analysis on Genetic and Personal Characteristic Datasets" Applied Sciences 12, no. 8: 3812. https://0-doi-org.brum.beds.ac.uk/10.3390/app12083812