
A Survey of Artificial Intelligence Challenges: Analyzing the Definitions, Relationships, and Evolutions

 , , ,
, , , 
Abstract
:1. Introduction
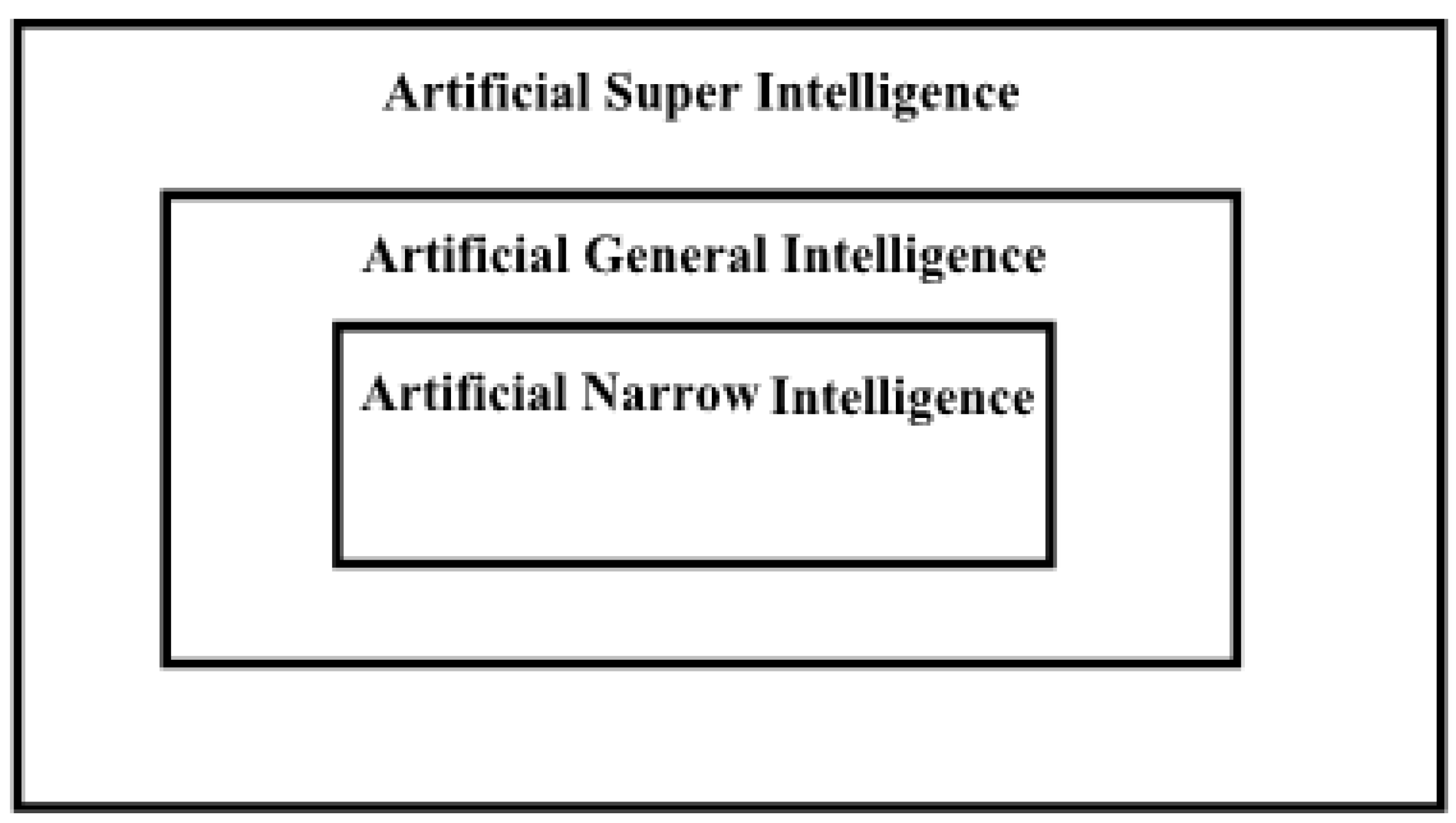
2. Preliminaries
- ANI: This type of intelligence refers to intelligent systems that do specific tasks. For example, an agent with capabilities such as face recognition and games playing. These agents are programmed to do tasks and cannot detect and formulate unknown tasks in a self-organized manner. We do not expect to see self-awareness in these agents.
- AGI: The concept of this type of intelligence does not refer to a unique thing in the mind of all leading scientists of AI. Most researchers use AGI for those agents whose intelligence is equivalent to human agents. AGI can be equivalent to HLI [14].
- ASI: In [16], Bostrom introduced three types of super intelligence: Speed ASI, collective ASI, and quality ASI. Speed ASI refers to an agent faster than a human, collective ASI refers to decision-making capabilities similar to a group of humans, and quality ASI refers to an agent that can do work that humans cannot.
3. Analyzing Challenges
3.1. Problem Identification and Formulation
3.2. Energy Consumption
- Investing in new paradigms with low energy consumption for HLI, such as quantum computing [24].
- Finding modern mathematical frameworks to find learning models with lower calculations, which leads to lower energy consumption [25].
- Sharing models to prevent energy consumption. A researcher can share a model with other researchers around the world.
3.3. Data Issues
- Cost is one of the main issues of data. Major sources of cost are gathering, preparing, and cleaning the data [28].
- Data incompleteness (or incomplete data) is another challenging problem in machine learning algorithms which leads to inappropriate learning of algorithms and uncertainties during data analysis. This issue should be handled during the pre-processing phase. Various approaches can be used for mitigating this problem. Filling missed (incomplete) data via most frequently observed values or developing learning algorithms to predict missed values are some examples of these approaches [32].
- Bias is a human feature that may affect data gathering and labeling. Sometimes, bias is present in historical, cultural, or geographical data. Consequently, bias may lead to biased models which can provide inappropriate analysis. Despite being aware of the existence of bias, avoiding biased models is a challenging task. For more information, please refer to [28].
3.4. Robustness and Reliability
3.5. Cheating and Deception
3.6. Security
3.7. Privacy
3.8. Fairness
- In the first approach, data itself could be biased, which results in unfair decisions. Therefore, this problem should be solved on the data level and as a preprocessing step [53,54,55]. In [56], the problems of datasets and their issues that lead to unfair results are discussed. Some clues for preparing appropriate versions of existing datasets that were created during the last decade are given.
3.9. Explainable AI
3.10. Responsibility
3.11. Controllability
3.12. Predictability
3.13. Continual Learning
- Reply methods: These algorithms store samples in raw format or generate pseudo-samples using a generative model.
- Regularization-based methods: These algorithms provide an additional regularization term in the loss function while learning new data.
- Parameter isolation methods: This type of algorithm provides different model parameters for each task to prevent any possible forgetting.
3.14. Storage (Memory)
3.15. Semantic and Communication
3.16. Morality and Ethical
3.17. Rationality
- Perfect rationality: An agent with this type of rationality can generate maximal successful behavior based on its available information.
- Calculative rationality: An agent with this type of rationality can compute a perfectly rational decision given the initially available information.
- Metalevel rationality: An agent with this type of rationality can select the optimal combination of computation-sequence-plus-action. During this process, the constraint is that the action must be selected under which is computed.
- Bounded rationality: An agent with this type of rationality can behave successfully based on available information and computational resources.
3.18. Mind
3.19. Accountability
3.20. Transparency
- Similar to accountability, humans like to see transparent behavior from AI-based models. By increasing the use of AI for making decisions in public affairs, this challenge becomes more complicated. In addition, with the creation of self-organized learning systems that may be hurtful to people, this issue grabs more attention. In some applications, such as military and healthcare systems, a learning system as a black box may not be appropriate, and some features such as explainability and accountability may not be able to bring transparency abilities. This feature will be vital in HLI-based agents.
- Recently, we are faced with many papers that report the results of accuracy of data-driven machine learning models. It is obvious that the reported accuracies are obtained from best practices; thus, with increasing parameter space, finding the exact accuracy that is equal to the reported results may not be possible. This issue may lead to a confusing process in reproducing models when the model generator codes are not reported [107].
3.21. Reproduceability
- How a learning model can be reproduced when it is obtained based on various sets of data and a large space of parameters. This problem becomes more challenging in data-driven learning procedures without transparent instructions [107]. Many papers on the scope of applied machine learning are not well documented according to the report given in [111]. This problem becomes more serious when privacy-preserving concerns about data should be considered.
- How a learning model can reproduce itself when self-reproducibility is considered as a final destination of AI-based models [112].
3.22. Evolution
- From a programming perspective, existing structures for genes and chromosomes, and the evolution process are not naturally similar to evolutionary processes that happen in nature. It seems that computer worms and viruses that utilize some programming such as quine codes and polymorphic structure are more pioneers than existing evolutionary programs that may be found in repositories such as GitHub. In [113], a self-replicating neural network is presented that may be used in an evolutionary strategy.
- From the theory of evolutionary computation, the concept behind genetic and memetic computation is changing over time to better model the phenomena that happen in nature. These algorithms have many variations such as variable chromosomes, diverse crossover, and complex mutations. It should be noted that many of the existing evolutionary algorithms are based on a very simplified search process that happens in nature [114].
3.23. Beneficial
3.24. Exploration and Exploitation Balance
3.25. Verifiability
3.26. Safety
3.27. Complexity
3.28. Trustworthiness
4. Discussion
- Q1: What are fundamental problems, theoretical and machines limitations during the development of AI? Section 4.1 is dedicated to answering this question.
- Q2: What are the potential consequences of the evolution of challenges during the development of AI? Section 4.2 is dedicated to answering this question.
- Q3: What are combinations of challenges? Section 4.3 is dedicated to answering this question.
- Q4: What is the importance of the context of challenges during the development of AI? Section 4.4 is dedicated to answering this question.
- Q5: What is the role of analyzing only human intelligence during the development of AI? Section 4.5 is dedicated to answering this question.
4.1. Fundamental Problems, Theoretical and Machines Limitations
4.2. The Evolution and Transformation of Challenges
- Evolution of data challenges: With the creation of data-driven machine learning algorithms, we had rare data. Now, because of the use of cloud computing, we have big data. In the near future, because of the use of AI-based generative data, such as generative adversarial networks (GANs), we would need some technology to differentiate real-world and appropriate data from other types of data in a vast amount of data [136,137].
- Evolution of robustness and security challenges: If the noise of input data is synthetic and designated for changing the model’s behavior abnormally, we will face another challenge, known as security against adversarial attacks, studied in security challenges. Since the number of adversarial attacks is increasing, robustness will be connected to security in most cases soon [31].
- Evolution of energy consumption challenge: It was previously mentioned that energy consumption is a substantial challenge in the lifecycle of AI-based systems. This challenge may lead to other challenges, such as carbon emissions, environmental pollution, and global warming [138].
- Evolution of complexity challenges: A system with high complexity might lead to non-verifiable, unreliable, unaccountable, and nonreproducible AI-based systems. For example, a model with a large set of parameters and also a complex process for tunning them may lead to reproducibility problems, as explained in [107].
4.3. Combinations of Challenges
- According to [8], the security challenge implicitly arises from other challenges such as trust, confidentiality, and privacy.
- According to [109], the transparency challenge implicitly leads to other challenges such as accountability and explainability in the decision-making process of the learning model.
- According to [131], the trustworthiness challenge implicitly leads to other challenges such as fairness, explainability, accountability, and reliability.
- According to [122], the verification challenge implicitly results in other challenges such as safety and robustness.
4.4. Importance of Context of Challenge: Deep Dive into Dark Sides
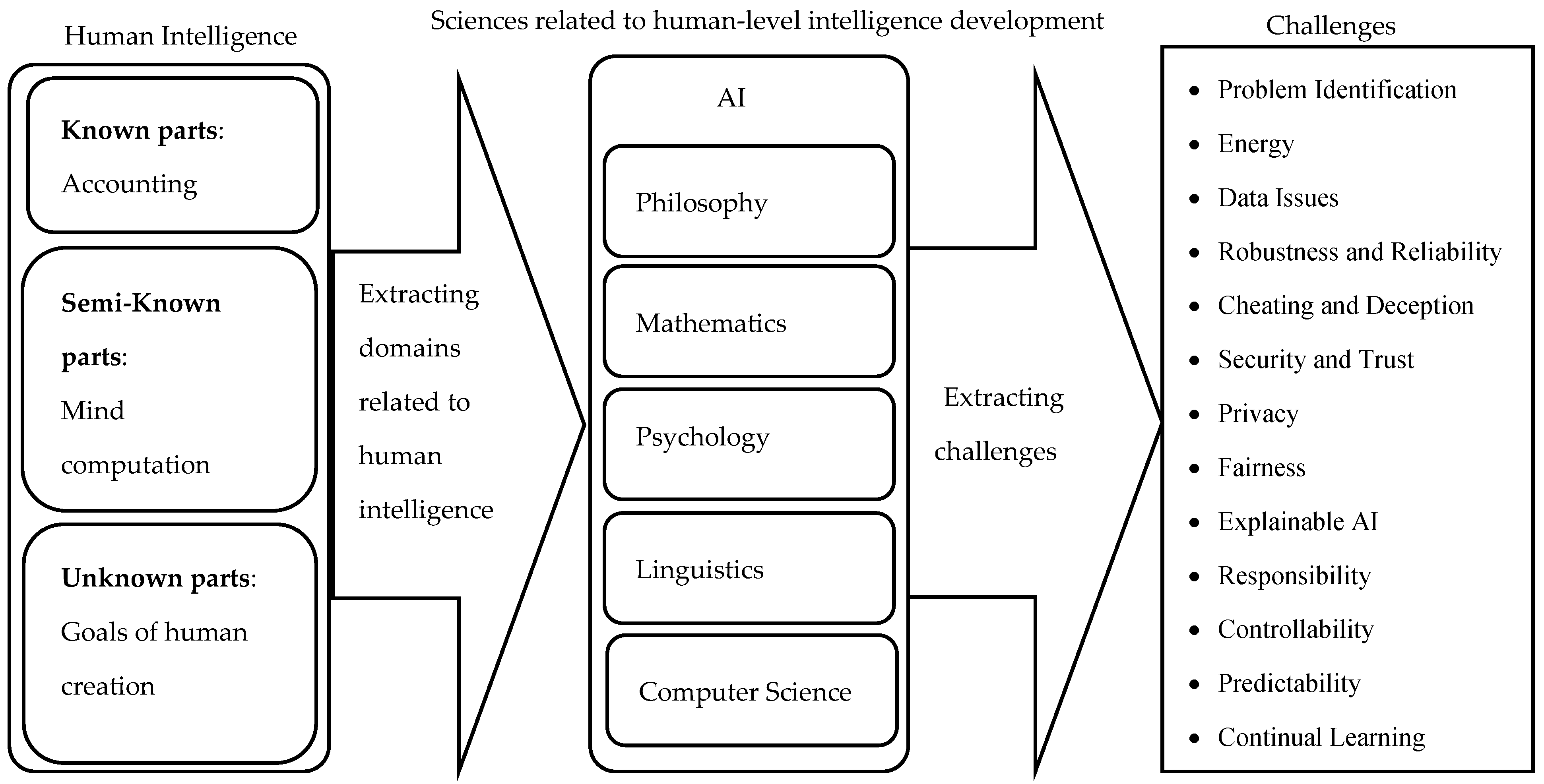
4.5. Human Intelligence Is Partially Known to Design HLI
- Some psychological concepts such as classification over self-awareness might be applicable to machines, such as the one reported in [143], but there is no literature on the evolution of this concept in machines. In other words, the context that leads to self-awareness in humans is based on limited information and limited sensors, but these assumptions might not be correct for machines. This means that there is little information about the type of self-awareness in machines that meet HLI, AGI, or ASI criteria. To the best of our knowledge, the connections among mind, cognitive science, learning capabilities, and self-awareness in humans and also animals are not totally understood in the literature [144,145,146].
- Pain and death are two key factors in analyzing cognitive concepts such as the theory of meaning management [147], psychology of souls [148], and religious understanding [149]. Since, machines might not face with death and pain, how can we expect to use computation behind the human mind to control machines?
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Binu, D.; Rajakumar, B.R. Artificial Intelligence in Data Mining: Theories and Applications; Academic Press: Cambridge, MA, USA, 2021. [Google Scholar]
- Ahmadi, A.; Meybodi, M.R.; Saghiri, A.M. Adaptive search in unstructured peer-to-peer networks based on ant colony and Learning Automata. In Proceedings of the 2016 Artificial Intelligence and Robotics, Qazvin, Iran, 9 April 2016. [Google Scholar]
- Cheng, X.; Lin, X.; Shen, X.-L.; Zarifis, A.; Mou, J. The dark sides of AI. Electron. Mark. 2022, 1–5. [Google Scholar] [CrossRef]
- Jabbarpour, M.R.; Saghiri, A.M.; Sookhak, M. A framework for component selection considering dark sides of artificial intelligence: A case study on autonomous vehicle. Electronics 2021, 10, 384. [Google Scholar] [CrossRef]
- Kumar, G.; Singh, G.; Bhatanagar, V.; Jyoti, K. Scary dark side of artificial intelligence: A perilous contrivance to mankind. Humanit. Soc. Sci. Rev. 2019, 7, 1097–1103. [Google Scholar] [CrossRef] [Green Version]
- Mahmoud, A.B.; Tehseen, S.; Fuxman, L. The dark side of artificial intelligence in retail innovation. In Retail Futures; Emerald Publishing Limited: Bingley, UK, 2020. [Google Scholar]
- Wirtz, B.W.; Weyerer, J.C.; Sturm, B.J. The dark sides of artificial intelligence: An integrated AI governance framework for public administration. Int. J. Public Adm. 2020, 43, 818–829. [Google Scholar] [CrossRef]
- Hanif, M.A.; Khalid, F.; Putra, R.V.W.; Rehman, S.; Shafique, M. Robust machine learning systems: Reliability and security for deep neural networks. In Proceedings of the 2018 IEEE 24th International Symposium on On-Line Testing and Robust System Design (IOLTS), Platja d’Aro, Spain, 2–4 July 2018; pp. 257–260. [Google Scholar]
- Varshney, K.R. Engineering safety in machine learning. In Proceedings of the 2016 Information Theory and Applications Workshop (ITA), La Jolla, CA, USA, 31 January–5 February 2016; pp. 1–5. [Google Scholar]
- Bellamy, R.K.; Dey, K.; Hind, M.; Hoffman, S.C.; Houde, S.; Kannan, K.; Lohia, P.; Martino, J.; Mehta, S.; Mojsilović, A. AI Fairness 360: An extensible toolkit for detecting and mitigating algorithmic bias. IBM J. Res. Dev. 2019, 63, 4:1–4:15. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and policy considerations for deep learning in NLP. arXiv 2019, arXiv:1906.02243. [Google Scholar]
- Smuha, N.A. The EU approach to ethics guidelines for trustworthy artificial intelligence. Comput. Law Rev. Int. 2019, 20, 97–106. [Google Scholar] [CrossRef]
- Legg, S.; Hutter, M. A collection of definitions of intelligence. Front. Artif. Intell. Appl. 2007, 157, 17. [Google Scholar]
- Legg, S. Machine Super Intelligence. Ph.D. Thesis, University of Lugano, Lugano, Switzerland, 2008. [Google Scholar]
- Saghiri, A.M. A Survey on Challenges in Designing Cognitive Engines. In Proceedings of the 2020 6th International Conference on Web Research (ICWR), Tehran, Iran, 22–23 April 2020; pp. 165–171. [Google Scholar]
- Boström, N. Superintelligence: Paths, Dangers, Strategies; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Chollet, F. On the measure of intelligence. arXiv 2019, arXiv:1911.01547. [Google Scholar]
- Yampolskiy, R.V. Human is not equal to AGI. arXiv 2020, arXiv:2007.07710. [Google Scholar]
- Searle, J.R. Minds, brains, and programs. Behav. Brain Sci. 1980, 3, 417–424. [Google Scholar] [CrossRef] [Green Version]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall: Hoboken, NJ, USA, 1994. [Google Scholar]
- Linz, P. An Introduction to Formal Languages and Automata; Jones & Bartlett Learning: Burlington, MA, USA, 2006. [Google Scholar]
- Lenat, D.B.; Guha, R.V.; Pittman, K.; Pratt, D.; Shepherd, M. Cyc: Toward programs with common sense. Commun. ACM 1990, 33, 30–49. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Steane, A. Quantum computing. Rep. Prog. Phys. 1998, 61, 117. [Google Scholar] [CrossRef]
- Wheeldon, A.; Shafik, R.; Rahman, T.; Lei, J.; Yakovlev, A.; Granmo, O.-C. Learning automata based energy-efficient AI hardware design for IoT applications. Philos. Trans. R. Soc. A 2020, 378, 20190593. [Google Scholar] [CrossRef] [PubMed]
- Priya, S.; Inman, D.J. Energy Harvesting Technologies; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Kamalinejad, P.; Mahapatra, C.; Sheng, Z.; Mirabbasi, S.; Leung, V.C.; Guan, Y.L. Wireless energy harvesting for the Internet of Things. IEEE Commun. Mag. 2015, 53, 102–108. [Google Scholar] [CrossRef] [Green Version]
- Baig, M.I.; Shuib, L.; Yadegaridehkordi, E. Big Data Tools: Advantages and Disadvantages. J. Soft Comput. Decis. Support Syst. 2019, 6, 14–20. [Google Scholar]
- Sivarajah, U.; Kamal, M.M.; Irani, Z.; Weerakkody, V. Critical analysis of Big Data challenges and analytical methods. J. Bus. Res. 2017, 70, 263–286. [Google Scholar] [CrossRef] [Green Version]
- Qiu, J.; Wu, Q.; Ding, G.; Xu, Y.; Feng, S. A survey of machine learning for big data processing. EURASIP J. Adv. Signal Process. 2016, 2016, 67. [Google Scholar] [CrossRef] [Green Version]
- Qayyum, A.; Qadir, J.; Bilal, M.; Al-Fuqaha, A. Secure and robust machine learning for healthcare: A survey. IEEE Rev. Biomed. Eng. 2020, 14, 156–180. [Google Scholar] [CrossRef]
- Bhagoji, A.N.; Cullina, D.; Sitawarin, C.; Mittal, P. Enhancing robustness of machine learning systems via data transformations. In Proceedings of the 2018 52nd Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 21–23 March 2018; pp. 1–5. [Google Scholar]
- Rozsa, A.; Günther, M.; Boult, T.E. Are accuracy and robustness correlated. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 227–232. [Google Scholar]
- Pérez-Rosas, V.; Abouelenien, M.; Mihalcea, R.; Burzo, M. Deception detection using real-life trial data. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 59–66. [Google Scholar]
- Krishnamurthy, G.; Majumder, N.; Poria, S.; Cambria, E. A deep learning approach for multimodal deception detection. arXiv 2018, arXiv:1803.00344. [Google Scholar]
- Randhavane, T.; Bhattacharya, U.; Kapsaskis, K.; Gray, K.; Bera, A.; Manocha, D. The Liar’s Walk: Detecting Deception with Gait and Gesture. arXiv 2019, arXiv:1912.06874. [Google Scholar]
- Zhao, S.; Jiang, G.; Huang, T.; Yang, X. The deception detection and restraint in multi-agent system. In Proceedings of the 17th IEEE International Conference on Tools with Artificial Intelligence (ICTAI’05), Hong Kong, China, 14–16 November 2005; pp. 44–48. [Google Scholar]
- Zlotkin, G.; Rosenschein, J.S. Incomplete Information and Deception in Multi-Agent Negotiation. In Proceedings of the IJCAI, Sydney, Australia, 24–30 August 1991; Volume 91, pp. 225–231. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Blitz, M.J. Lies, Line Drawing, and Deep Fake News. Okla. Law Rev. 2018, 71, 59. [Google Scholar]
- Tsai, C.-F.; Hsu, Y.-F.; Lin, C.-Y.; Lin, W.-Y. Intrusion detection by machine learning: A review. Expert Syst. Appl. 2009, 36, 11994–12000. [Google Scholar] [CrossRef]
- Pawar, S.N.; Bichkar, R.S. Genetic algorithm with variable length chromosomes for network intrusion detection. Int. J. Autom. Comput. 2015, 12, 337–342. [Google Scholar] [CrossRef]
- Kinsner, W. Towards cognitive security systems. In Proceedings of the 11th International Conference on Cognitive Informatics and Cognitive Computing, Kyoto, Japan, 22–24 August 2012; p. 539. [Google Scholar]
- Biggio, B.; Fumera, G.; Roli, F. Security evaluation of pattern classifiers under attack. IEEE Trans. Knowl. Data Eng. 2014, 26, 984–996. [Google Scholar] [CrossRef] [Green Version]
- Barreno, M.; Nelson, B.; Sears, R.; Joseph, A.D.; Tygar, J.D. Can machine learning be secure? In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, Taipei, Taiwan, 21–24 March 2006; pp. 16–25. [Google Scholar]
- Yampolskiy, R.V. Artificial Intelligence Safety and Security; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Huang, L.; Joseph, A.D.; Nelson, B.; Rubinstein, B.I.; Tygar, J. Adversarial machine learning. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 21 October 2011; pp. 43–58. [Google Scholar]
- Ateniese, G.; Felici, G.; Mancini, L.V.; Spognardi, A.; Villani, A.; Vitali, D. Hacking smart machines with smarter ones: How to extract meaningful data from machine learning classifiers. arXiv 2013, arXiv:1306.4447. [Google Scholar] [CrossRef]
- Tucker, C.; Agrawal, A.; Gans, J.; Goldfarb, A. Privacy, algorithms, and artificial intelligence. In The Economics of Artificial Intelligence: An Agenda; Oxford University Press: Oxford, UK, 2018; pp. 423–437. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Zhang, W.; Ntoutsi, E. Faht: An adaptive fairness-aware decision tree classifier. arXiv 2019, arXiv:1907.07237. [Google Scholar]
- Kamani, M.M.; Haddadpour, F.; Forsati, R.; Mahdavi, M. Efficient fair principal component analysis. In Machine Learning; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–32. [Google Scholar]
- Dwork, C.; Hardt, M.; Pitassi, T.; Reingold, O.; Zemel, R. Fairness through awareness. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, Cambridge, MA, USA, 8–10 January 2012; pp. 214–226. [Google Scholar]
- Kamiran, F.; Calders, T. Classifying without discriminating. In Proceedings of the 2009 2nd International Conference on Computer, Control and Communication, Karachi, Pakistan, 17–18 February 2009; pp. 1–6. [Google Scholar]
- Calders, T.; Kamiran, F.; Pechenizkiy, M. Building classifiers with independency constraints. In Proceedings of the 2009 IEEE International Conference on Data Mining Workshops, Miami, FL, USA, 6 December 2009; pp. 13–18. [Google Scholar]
- Quy, T.L.; Roy, A.; Iosifidis, V.; Ntoutsi, E. A survey on datasets for fairness-aware machine learning. arXiv 2021, arXiv:2110.00530. [Google Scholar]
- Hardt, M.; Price, E.; Srebro, N. Equality of opportunity in supervised learning. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Kamishima, T.; Akaho, S.; Sakuma, J. Fairness-aware learning through regularization approach. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December 2011; pp. 643–650. [Google Scholar]
- Goh, G.; Cotter, A.; Gupta, M.; Friedlander, M.P. Satisfying real-world goals with dataset constraints. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Calders, T.; Verwer, S. Three naive Bayes approaches for discrimination-free classification. Data Min. Knowl. Discov. 2010, 21, 277–292. [Google Scholar] [CrossRef] [Green Version]
- Donini, M.; Oneto, L.; Ben-David, S.; Shawe-Taylor, J.S.; Pontil, M. Empirical risk minimization under fairness constraints. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Morgenstern, J.; Samadi, S.; Singh, M.; Tantipongpipat, U.; Vempala, S. Fair dimensionality reduction and iterative rounding for sdps. arXiv 2019, arXiv:1902.11281. [Google Scholar]
- Samadi, S.; Tantipongpipat, U.; Morgenstern, J.H.; Singh, M.; Vempala, S. The price of fair pca: One extra dimension. Adv. Neural Inf. Process. Syst. 2018, 31, 1–12. [Google Scholar]
- Pleiss, G.; Raghavan, M.; Wu, F.; Kleinberg, J.; Weinberger, K.Q. On fairness and calibration. Adv. Neural Inf. Process. Syst. 2017, 30, 1–10. [Google Scholar]
- Adadi, A.; Berrada, M. Explainable AI for healthcare: From black box to interpretable models. In Embedded Systems and Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2020; pp. 327–337. [Google Scholar]
- Gade, K.; Geyik, S.C.; Kenthapadi, K.; Mithal, V.; Taly, A. Explainable AI in industry. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 3203–3204. [Google Scholar]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215. [Google Scholar]
- Samek, W.; Müller, K.-R. Towards explainable artificial intelligence. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Berlin/Heidelberg, Germany, 2019; pp. 5–22. [Google Scholar]
- Sharma, S.; Nag, A.; Cordeiro, L.; Ayoub, O.; Tornatore, M.; Nekovee, M. Towards explainable artificial intelligence for network function virtualization. In Proceedings of the 16th International Conference on Emerging Networking EXperiments and Technologies, Barcelona, Spain, 1–4 December 2020; pp. 558–559. [Google Scholar]
- Matthias, A. The responsibility gap: Ascribing responsibility for the actions of learning automata. Ethics Inf. Technol. 2004, 6, 175–183. [Google Scholar] [CrossRef]
- Neri, E.; Coppola, F.; Miele, V.; Bibbolino, C.; Grassi, R. Artificial Intelligence: Who Is Responsible for the Diagnosis? Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Stannett, M. X-machines and the halting problem: Building a super-Turing machine. Form. Asp. Comput. 1990, 2, 331–341. [Google Scholar] [CrossRef]
- Rybalov, A. On the strongly generic undecidability of the Halting Problem. Theor. Comput. Sci. 2007, 377, 268–270. [Google Scholar] [CrossRef] [Green Version]
- Yampolskiy, R.V. On Controllability of AI. arXiv 2020, arXiv:2008.04071. [Google Scholar]
- Russell, S. Human Compatible: Artificial Intelligence and the Problem of Control; Penguin: London, UK, 2019. [Google Scholar]
- Yampolskiy, R. On Controllability of Artificial Intelligence; Technical Report; University of Louisville: Louisville, KY, USA, 2020. [Google Scholar]
- Dawson, J. Logical Dilemmas: The Life and Work of Kurt Gödel; AK Peters: Natick, MA, USA; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- Yampolskiy, R.V. Unpredictability of AI. arXiv 2019, arXiv:1905.13053. [Google Scholar]
- Hofstadter, D.R. I Am a Strange Loop; Basic Books: New York, NY, USA, 2007. [Google Scholar]
- Musiolik, G. Predictability of AI Decisions. In Analyzing Future Applications of AI, Sensors, and Robotics in Society; IGI Global: Hershey, PA, USA, 2021; pp. 17–28. [Google Scholar]
- Delange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual learning with deep generative replay. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2990–2999. [Google Scholar]
- Hassani, H.; Silva, E.S.; Unger, S.; TajMazinani, M.; Mac Feely, S. Artificial intelligence (AI) or intelligence augmentation (IA): What is the future? AI 2020, 1, 143–155. [Google Scholar] [CrossRef]
- Widrow, B.; Aragon, J.C. Cognitive Memory. Neural Netw. 2013, 41, 3–14. [Google Scholar] [CrossRef]
- Kumar, A.; Boehm, M.; Yang, J. Data management in machine learning: Challenges, techniques, and systems. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 1717–1722. [Google Scholar]
- Kotseruba, I.; Tsotsos, J.K. 40 years of cognitive architectures: Core cognitive abilities and practical applications. Artif. Intell. Rev. 2020, 53, 17–94. [Google Scholar] [CrossRef] [Green Version]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 28–37. [Google Scholar] [CrossRef]
- Feigenbaum, L.; Herman, I.; Hongsermeier, T.; Neumann, E.; Stephens, S. The semantic web in action. Sci. Am. 2007, 297, 90–97. [Google Scholar] [CrossRef]
- Cambria, E.; White, B. Jumping NLP curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Chaib-Draa, B.; Dignum, F. Trends in agent communication language. Comput. Intell. 2002, 18, 89–101. [Google Scholar] [CrossRef]
- Maedche, A.; Staab, S. Ontology learning for the semantic web. IEEE Intell. Syst. 2001, 16, 72–79. [Google Scholar] [CrossRef] [Green Version]
- Teslya, N.; Smirnov, A. Blockchain-based framework for ontology-oriented robots’ coalition formation in cyberphysical systems. In Proceedings of the MATEC Web of Conferences, Anyer, Indonesia, 4–5 September 2018; Volume 161, pp. 03–18. [Google Scholar]
- Luccioni, A.; Bengio, Y. On the Morality of Artificial Intelligence. IEEE Technol. Soc. Mag. 2020, 39, 16–25. [Google Scholar] [CrossRef]
- Abdel-Fattah, A.M.; Besold, T.R.; Gust, H.; Krumnack, U.; Schmidt, M.; Kuhnberger, K.-U.; Wang, P. Rationality-guided AGI as cognitive systems. In Proceedings of the Annual Meeting of the Cognitive Science Society, Sapporo, Japan, 1–4 August 2012; Volume 34. [Google Scholar]
- Gigerenzer, G.; Selten, R. Rethinking rationality. Bounded Rationality: The Adaptive Toolbox; MIT Press: Cambridge, MA, USA, 2001; Volume 1, p. 12. [Google Scholar]
- Halpern, J.Y.; Pass, R. Algorithmic rationality: Game theory with costly computation. J. Econ. Theory 2015, 156, 246–268. [Google Scholar] [CrossRef] [Green Version]
- Russell, S.J. Rationality and intelligence. Artif. Intell. 1997, 94, 57–77. [Google Scholar] [CrossRef] [Green Version]
- Cuzzolin, F.; Morelli, A.; Cirstea, B.; Sahakian, B.J. Knowing me, knowing you: Theory of mind in AI. Psychol. Med. 2020, 50, 1057–1061. [Google Scholar] [CrossRef]
- Rabinowitz, N.; Perbet, F.; Song, F.; Zhang, C.; Eslami, S.A.; Botvinick, M. Machine theory of mind. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 10–15 July 2018; pp. 4218–4227. [Google Scholar]
- Estes, D.; Bartsch, K. Theory of mind: A foundational component of human general intelligence. Behav. Brain Sci. 2017, 40, 1–3. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kortz, M.; Budish, R.; Bavitz, C.; Gershman, S.; O’Brien, D.; Scott, K.; Schieber, S.; Waldo, J.; Weinberger, D. Accountability of AI under the law: The role of explanation. arXiv 2017, arXiv:1711.01134. [Google Scholar] [CrossRef] [Green Version]
- Porayska-Pomsta, K.; Rajendran, G. Accountability in human and artificial intelligence decision-making as the basis for diversity and educational inclusion. In Artificial Intelligence and Inclusive Education; Springer: Berlin/Heidelberg, Germany, 2019; pp. 39–59. [Google Scholar]
- Liu, H.-W.; Lin, C.-F.; Chen, Y.-J. Beyond State v Loomis: Artificial intelligence, government algorithmization and accountability. Int. J. Law Inf. Technol. 2019, 27, 122–141. [Google Scholar] [CrossRef]
- Habli, I.; Lawton, T.; Porter, Z. Artificial intelligence in health care: Accountability and safety. Bull. World Health Organ. 2020, 98, 251. [Google Scholar] [CrossRef]
- Lepri, B.; Oliver, N.; Letouzé, E.; Pentland, A.; Vinck, P. Fair, transparent, and accountable algorithmic decision-making processes. Philos. Technol. 2018, 31, 611–627. [Google Scholar] [CrossRef] [Green Version]
- van Nuenen, T.; Ferrer, X.; Such, J.M.; Coté, M. Transparency for whom? assessing discriminatory artificial intelligence. Computer 2020, 53, 36–44. [Google Scholar] [CrossRef]
- Haibe-Kains, B.; Adam, G.A.; Hosny, A.; Khodakarami, F.; Waldron, L.; Wang, B.; McIntosh, C.; Goldenberg, A.; Kundaje, A.; Greene, C.S. Transparency and reproducibility in artificial intelligence. Nature 2020, 586, E14–E16. [Google Scholar] [CrossRef] [PubMed]
- Wischmeyer, T. Artificial intelligence and transparency: Opening the black box. In Regulating Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2020; pp. 75–101. [Google Scholar]
- Larsson, S.; Heintz, F. Transparency in artificial intelligence. Internet Policy Rev. 2020, 9, 1–16. [Google Scholar] [CrossRef]
- Felzmann, H.; Villaronga, E.F.; Lutz, C.; Tamò-Larrieux, A. Transparency you can trust: Transparency requirements for artificial intelligence between legal norms and contextual concerns. Big Data Soc. 2019, 6, 2053951719860542. [Google Scholar] [CrossRef]
- Gundersen, O.E.; Kjensmo, S. State of the art: Reproducibility in artificial intelligence. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Vollmar, R. John von Neumann and Self-Reproducing Cellular Automata. J. Cell. Autom. 2006, 1, 353–376. [Google Scholar]
- Gabor, T.; Illium, S.; Zorn, M.; Linnhoff-Popien, C. Goals for Self-Replicating Neural Networks. In Proceedings of the ALIFE 2021: The 2021 Conference on Artificial Life, Prague, Czech Republic, 19–23 July 2021. [Google Scholar]
- Spector, L. Evolution of artificial intelligence. Artif. Intell. 2006, 170, 1251–1253. [Google Scholar] [CrossRef] [Green Version]
- Russell, S.; Dewey, D.; Tegmark, M. Research priorities for robust and beneficial artificial intelligence. AI Mag. 2015, 36, 105–114. [Google Scholar] [CrossRef] [Green Version]
- Osugi, T.; Kim, D.; Scott, S. Balancing exploration and exploitation: A new algorithm for active machine learning. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; p. 8. [Google Scholar]
- Črepinšek, M.; Liu, S.-H.; Mernik, M. Exploration and exploitation in evolutionary algorithms: A survey. ACM Comput. Surv. 2013, 45, 1–33. [Google Scholar] [CrossRef]
- Lin, L.; Gen, M. Auto-tuning strategy for evolutionary algorithms: Balancing between exploration and exploitation. Soft Comput. 2009, 13, 157–168. [Google Scholar] [CrossRef]
- Sledge, I.J.; Príncipe, J.C. Balancing exploration and exploitation in reinforcement learning using a value of information criterion. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2816–2820. [Google Scholar]
- Menzies, T.; Pecheur, C. Verification and validation and artificial intelligence. Adv. Comput. 2005, 65, 153–201. [Google Scholar]
- Xiang, W.; Musau, P.; Wild, A.A.; Lopez, D.M.; Hamilton, N.; Yang, X.; Rosenfeld, J.; Johnson, T.T. Verification for machine learning, autonomy, and neural networks survey. arXiv 2018, arXiv:1810.01989. [Google Scholar]
- Wu, T.; Dong, Y.; Dong, Z.; Singa, A.; Chen, X.; Zhang, Y. Testing Artificial Intelligence System Towards Safety and Robustness: State of the Art. IAENG Int. J. Comput. Sci. 2020, 47, 1–14. [Google Scholar]
- Zhang, J.; Wang, H.-S.; Zhou, H.-Y.; Dong, B.; Zhang, L.; Zhang, F.; Liu, S.-J.; Wu, Y.-F.; Yuan, S.-H.; Tang, M.-Y. Real-world verification of artificial intelligence algorithm-assisted auscultation of breath sounds in children. Front. Pediatr. 2021, 9, 152. [Google Scholar] [CrossRef] [PubMed]
- Gordon-Spears, D.F. Asimov’s laws: Current progress. In Proceedings of the International Workshop on Formal Approaches to Agent-Based Systems, Greenbelt, MD, USA, 29–31 October 2002; pp. 257–259. [Google Scholar]
- Haddadin, S. Towards Safe Robots: Approaching Asimov’s 1st Law; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Murphy, R.; Woods, D.D. Beyond Asimov: The three laws of responsible robotics. IEEE Intell. Syst. 2009, 24, 14–20. [Google Scholar] [CrossRef]
- Yampolskiy, R.; Fox, J. Safety engineering for artificial general intelligence. Topoi 2013, 32, 217–226. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. Knowl.-Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Sinha, A.; Tiwari, S.; Deb, K. A population-based, steady-state procedure for real-parameter optimization. In Proceedings of the 2005 IEEE Congress on Evolutionary Computation, Edinburgh, UK, 2–5 September 2005; Volume 1, pp. 514–521. [Google Scholar]
- Thiebes, S.; Lins, S.; Sunyaev, A. Trustworthy artificial intelligence. Electron. Mark. 2021, 31, 447–464. [Google Scholar] [CrossRef]
- Kaur, D.; Uslu, S.; Rittichier, K.J.; Durresi, A. Trustworthy Artificial Intelligence: A Review. ACM Comput. Surv. (CSUR) 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Berner, J.; Grohs, P.; Kutyniok, G.; Petersen, P. The modern mathematics of deep learning. arXiv 2021, arXiv:2105.04026. [Google Scholar]
- Wang, Y. A cognitive informatics reference model of autonomous agent systems (AAS). Int. J. Cogn. Inform. Nat. Intell. 2009, 3, 1–16. [Google Scholar]
- Wang, Y. The theoretical framework of cognitive informatics. Int. J. Cogn. Inform. Nat. Intell. 2007, 1, 1–27. [Google Scholar] [CrossRef]
- Wang, Y. Concept algebra: A denotational mathematics for formal knowledge representation and cognitive robot learning. J. Adv. Math. Appl. 2015, 4, 61–86. [Google Scholar] [CrossRef]
- Chen, R.J.; Lu, M.Y.; Chen, T.Y.; Williamson, D.F.; Mahmood, F. Synthetic data in machine learning for medicine and healthcare. Nat. Biomed. Eng. 2021, 5, 493–497. [Google Scholar] [CrossRef] [PubMed]
- El Emam, K.; Mosquera, L.; Hoptroff, R. Practical Synthetic Data Generation: Balancing Privacy and the Broad Availability of Data; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- Patterson, D.; Gonzalez, J.; Le, Q.; Liang, C.; Munguia, L.-M.; Rothchild, D.; So, D.; Texier, M.; Dean, J. Carbon emissions and large neural network training. arXiv 2021, arXiv:2104.10350. [Google Scholar]
- Yampolskiy, R.V. Artificial intelligence safety engineering: Why machine ethics is a wrong approach. In Philosophy and Theory of Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2013; pp. 389–396. [Google Scholar]
- Papernot, N.; McDaniel, P.; Sinha, A.; Wellman, M.P. Sok: Security and privacy in machine learning. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 399–414. [Google Scholar]
- Goertzel, B. Human-level artificial general intelligence and the possibility of a technological singularity: A reaction to Ray Kurzweil’s The Singularity Is Near, and McDermott’s critique of Kurzweil. Artif. Intell. 2007, 171, 1161–1173. [Google Scholar] [CrossRef] [Green Version]
- Yampolskiy, R.V. AI-complete, AI-hard, or AI-easy–classification of problems in AI. In Proceedings of the the 23rd Midwest Artificial Intelligence and Cognitive Science Conference, Cincinnati, OH, USA, 21–22 April 2012. [Google Scholar]
- Lewis, P.R.; Chandra, A.; Parsons, S.; Robinson, E.; Glette, K.; Bahsoon, R.; Torresen, J.; Yao, X. A survey of self-awareness and its application in computing systems. In Proceedings of the 2011 Fifth IEEE Conference on Self-Adaptive and Self-Organizing Systems Workshops, Ann Arbor, MI, USA, 3–7 October 2011; pp. 102–107. [Google Scholar]
- Carden, J.; Jones, R.J.; Passmore, J. Defining self-awareness in the context of adult development: A systematic literature review. J. Manag. Educ. 2022, 46, 140–177. [Google Scholar] [CrossRef]
- Cook, S.H. The self in self-awareness. J. Adv. Nurs. 1999, 29, 1292–1299. [Google Scholar] [CrossRef]
- Gallup, G.G., Jr. Self-awareness and the emergence of mind in primates. Am. J. Primatol. 1982, 2, 237–248. [Google Scholar] [CrossRef]
- Wong, P.T. Meaning management theory and death acceptance. In Existential and Spiritual Issues in Death Attitudes; Taylor & Francis Group: Milton Park, UK, 2008; pp. 65–87. [Google Scholar]
- Bering, J.M. The folk psychology of souls. Behav. Brain Sci. 2006, 29, 453–462. [Google Scholar] [CrossRef]
- Park, C.L. Religion and meaning. In Handbook of the Psychology of Religion and Spirituality; The Guilford Press: New York, NY, USA, 2013; pp. 357–379. [Google Scholar]



{kind=link}
{kind=link}
| No. | Challenges | No. | Challenges |
|---|---|---|---|
| 1 | Problem Identification and Formulation | 2 | Energy Consumption |
| 3 | Data Issues | 4 | Robustness and Reliability |
| 5 | Cheating and Deception | 6 | Security |
| 7 | Privacy | 8 | Fairness |
| 9 | Explainable AI | 10 | Responsibility |
| 11 | Controllability | 12 | Predictability |
| 13 | Continual Learning | 14 | Storage (limited memory) |
| 15 | Semantic and Communication | 16 | Morality and Ethics |
| 17 | Rationality | 18 | Mind |
| 19 | Accountability | 20 | Transparency |
| 21 | Reproducibility | 22 | Evolution |
| 23 | Beneficial | 24 | Exploration and Exploitation Balance |
| 25 | Verifiability | 26 | Safety |
| 27 | Complexity | 28 | Trustworthy |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saghiri, A.M.; Vahidipour, S.M.; Jabbarpour, M.R.; Sookhak, M.; Forestiero, A. A Survey of Artificial Intelligence Challenges: Analyzing the Definitions, Relationships, and Evolutions. Appl. Sci. 2022, 12, 4054. https://0-doi-org.brum.beds.ac.uk/10.3390/app12084054
Saghiri AM, Vahidipour SM, Jabbarpour MR, Sookhak M, Forestiero A. A Survey of Artificial Intelligence Challenges: Analyzing the Definitions, Relationships, and Evolutions. Applied Sciences. 2022; 12(8):4054. https://0-doi-org.brum.beds.ac.uk/10.3390/app12084054
Chicago/Turabian StyleSaghiri, Ali Mohammad, S. Mehdi Vahidipour, Mohammad Reza Jabbarpour, Mehdi Sookhak, and Agostino Forestiero. 2022. "A Survey of Artificial Intelligence Challenges: Analyzing the Definitions, Relationships, and Evolutions" Applied Sciences 12, no. 8: 4054. https://0-doi-org.brum.beds.ac.uk/10.3390/app12084054