
R Packages for Data Quality Assessments and Data Monitoring: A Software Scoping Review with Recommendations for Future Developments

 , , , and
, , , and
Abstract
:1. Introduction
2. Methods
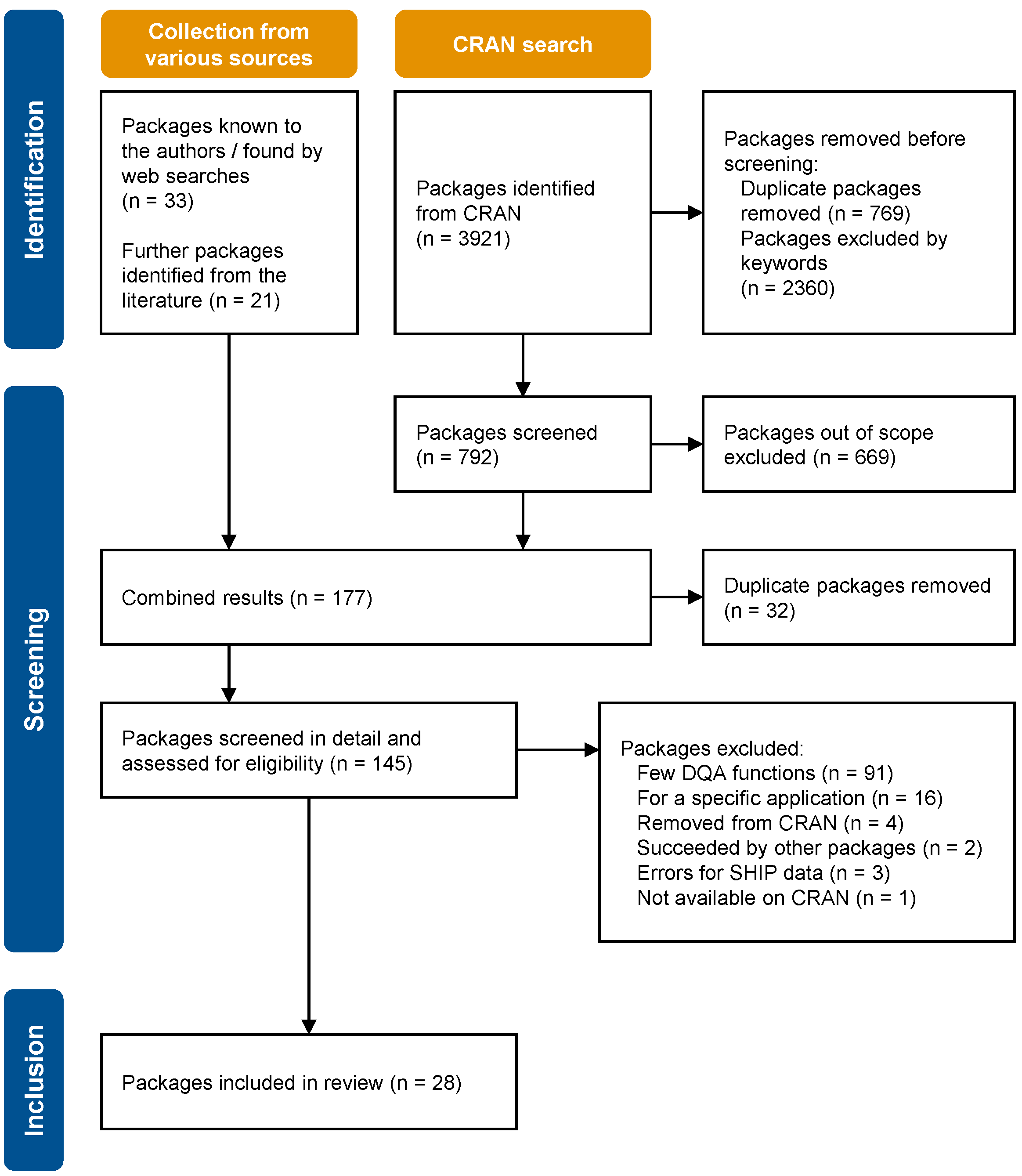
2.1. Search Strategy and Package Selection
- (1)
- The package is hosted on CRAN. CRAN is a global network of web servers that store up-to-date official releases of the R distribution, contributed packages, and documentation. By including only CRAN packages, we filter for packages that have passed basic technical quality control on different operating systems, i.e., Windows, macOS (Intel and ARM), and Linux.
- (2)
- The package is active on CRAN. CRAN runs regular tests on the hosted packages to ensure their technical functionality and stability across platforms and R versions. Packages that do not pass these tests and are not timely maintained are removed from CRAN. Considering active CRAN packages also means that they are ready-to-use, and the users can install them directly with base R (i.e., via the install.packages function or through the RStudio interface). We considered a package active if it was not “archived” on CRAN.
- (3)
- The package either explicitly targets DQ or has functionalities that are suitable for DQA. To evaluate and compare the scope of the packages, we matched their functionalities to a reference DQ framework for observational health research data [6]. We included packages that target at least three dimensions and four domains of the reference DQ framework (see Section 2.2.1 for explanations on the framework).
- (4)
- The package is not restricted to a specific field of application (e.g., air or water quality) nor a particular type of data (e.g., RNA-sequencing data, process data) to ensure applicability to a broad audience.
- (5)
- The package does not produce errors on basic output, such as a wrong number of observations when applied to real-world data, or stops unexpectedly due to possible internal errors.
2.2. Package Assessment and Feature Comparison
2.2.1. Data Quality Framework
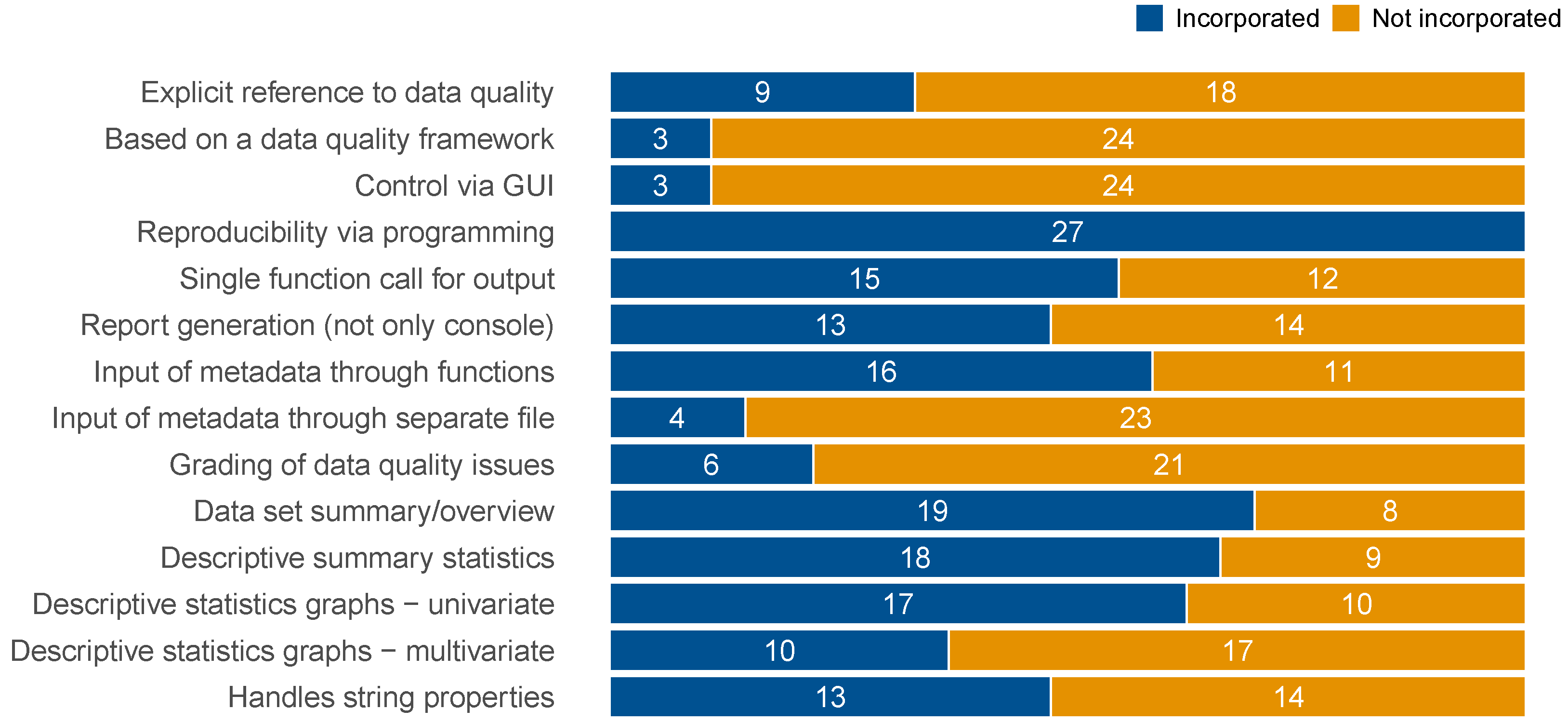
2.2.2. General Evaluation Criteria
- To assess whether DQ was at the root of a package, we checked if (i) the package description mentioned DQ in general and (ii) if the package was developed following a specific DQ concept.
- Given the central role metadata has in DQA to compute indicators and not only descriptors, it is essential to evaluate if and how a package can handle metadata. We classify metadata, for instance, as any decision rule for a given data element (e.g., admissible values or ranges), the definition of missing value codes, or expectations on distributions. We looked at whether users can (iii) enter metadata through function calls or (iv) by importing a separate file. Entering metadata through a function call normally requires more programming skills compared to the use of separate files, where metadata could, for example, be provided in a spreadsheet type format.
- As R users have different backgrounds and needs, we considered the mode of operation a key feature of the packages. We checked whether the packages (v) offer a graphical user interface (GUI), (vi) if they can be fully used via coding and enable a reproducible workflow, and (vii) allow triggering extensive output based on a single function.
- We further evaluated the output formats for the DQA results, highlighting (viii) whether automatically generated reports can be produced. As reports, we considered all stand-alone files that the user can also view outside of R or RStudio. Useful features of such reports might include (ix) a dataset overview, (x) descriptive summary statistics, (xi) univariate graphs (e.g., histograms), and (xii) multivariate graphs (e.g., scatter plots and correlation heat maps).
- Another desirable feature of a DQ report is (xiii) a grading or scoring of DQ issues to judge their severity automatically. A grading requires either preset or user defined categorization rules (e.g., the proportion of range violations per variable) to make a decision on whether the encountered number of findings is considered a problem.
- We further noted whether a package offers (xiv) functionalities to handle string properties, such as checks for string lengths and upper or lower case.
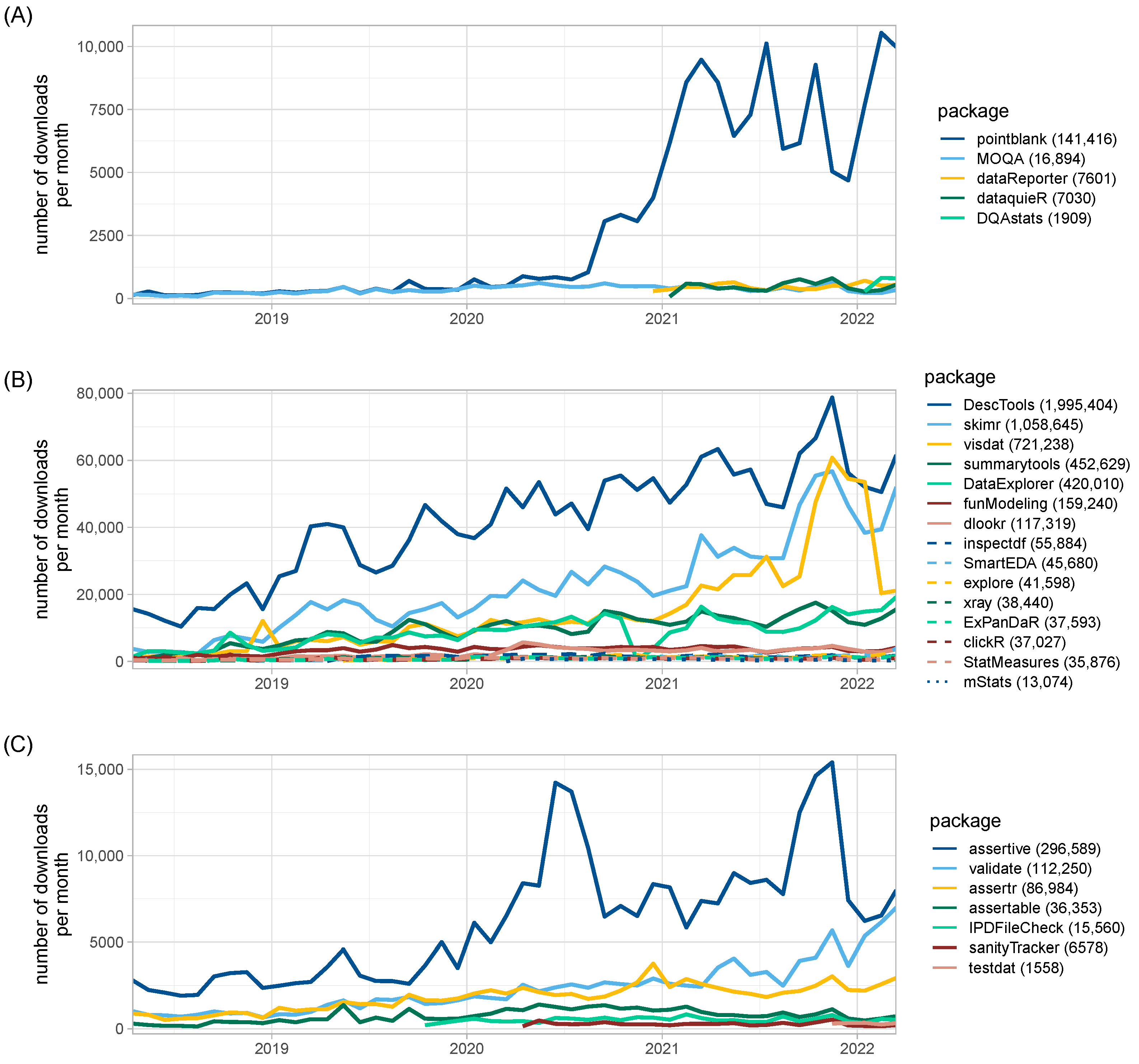
2.3. Data and Application Example
3. Results
3.1. Selected Data Quality R Packages
| assertable [37] | assertive [38] | assertr [39] | clickR [40] |
| DataExplorer [41] | dataquieR [42] | dataReporter [16] | DescTools [43] |
| dlookr [44] | DQAstats [45] | errorlocate [46] | ExPanDaR [47] |
| explore [48] | funModeling [49] | inspectdf [50] | IPDFileCheck [51] |
| MOQA [52] | mStats [53] | pointblank [54] | sanityTracker [55] |
| skimr [56] | SmartEDA [57] | StatMeasures [58] | summarytools [59] |
| testdat [60] | validate [18] | visdat [61] | xray [62] |
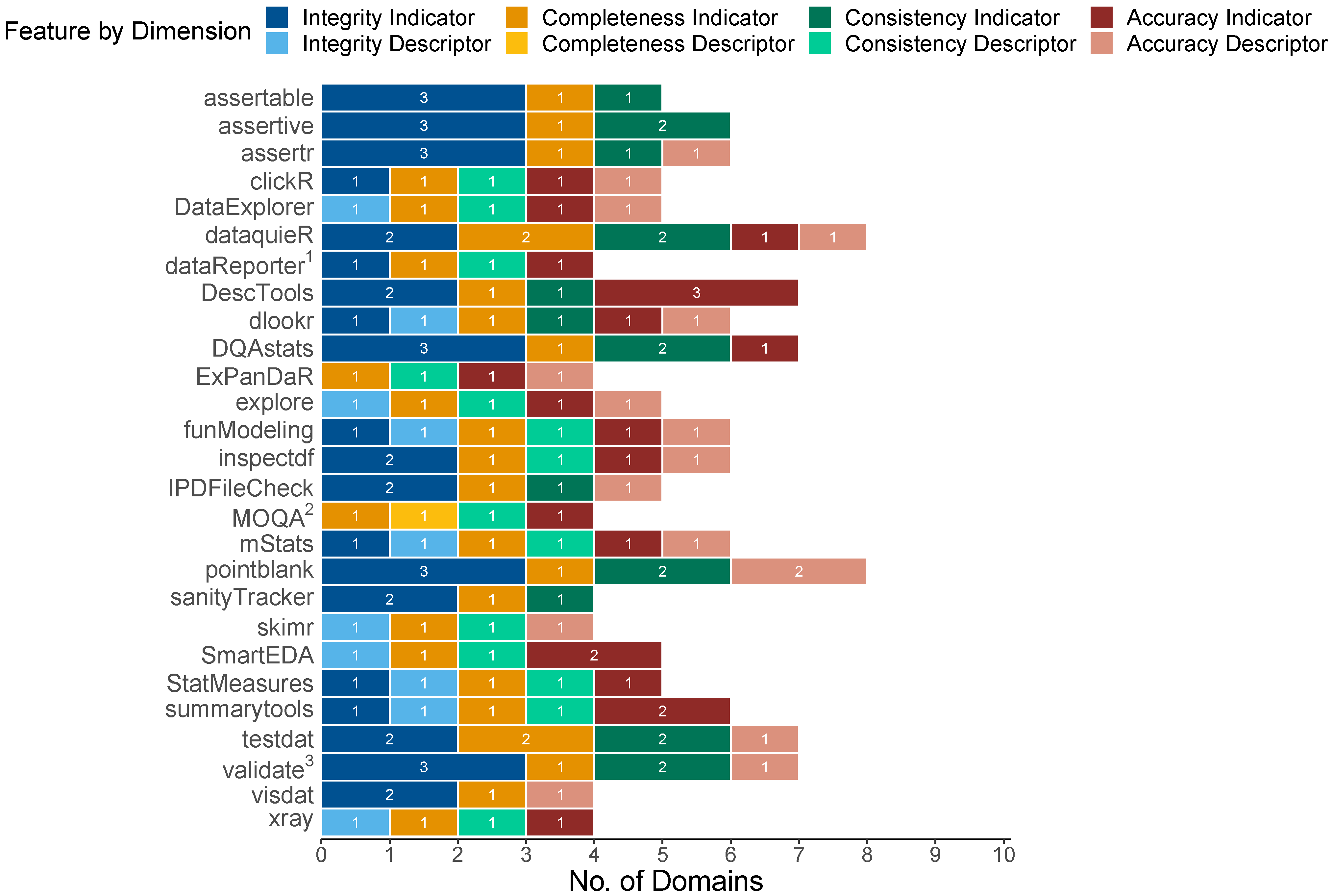
3.2. Data Quality Capabilities Comparison
3.3. General Feature Comparison
3.4. Package Characteristics

4. Discussion
4.1. Fast Results vs. Thorough Analysis
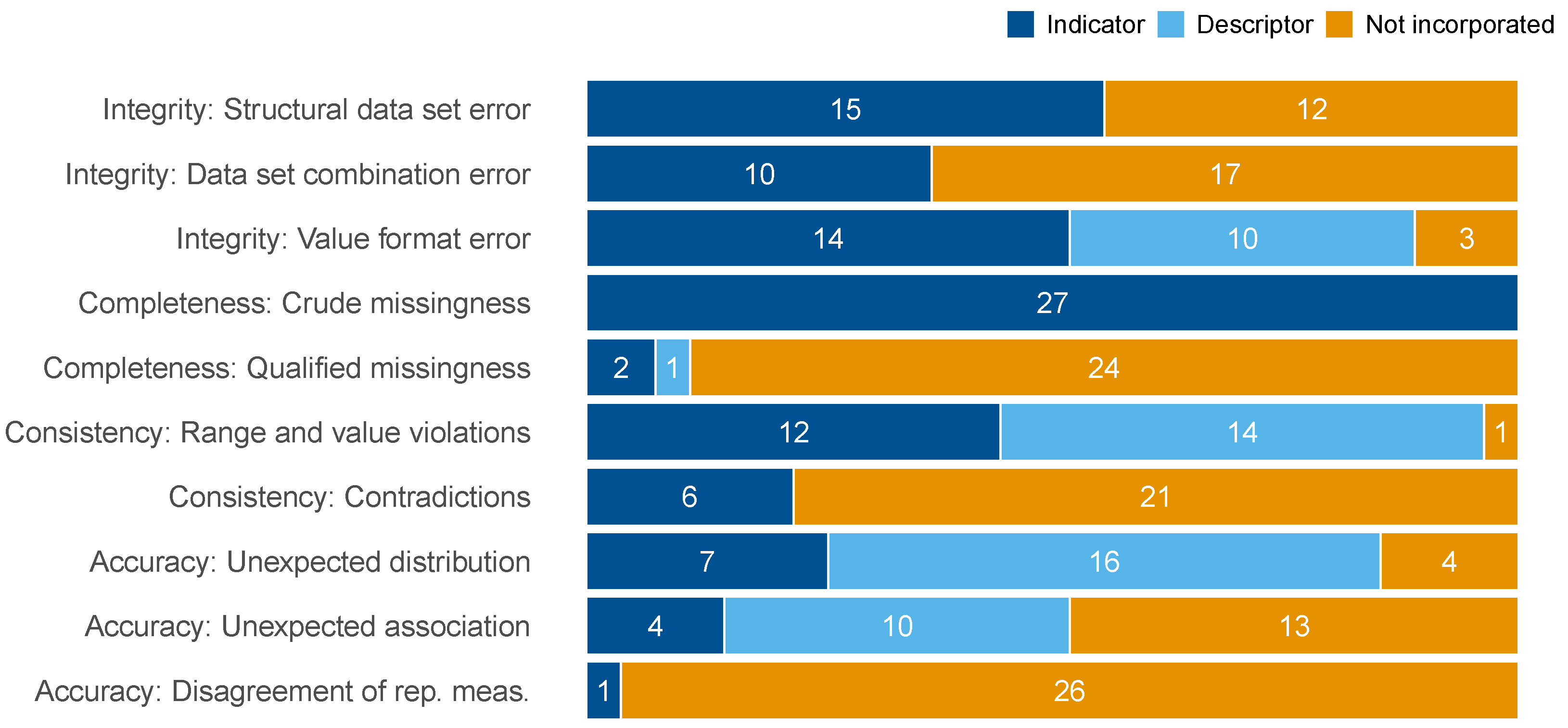
4.2. Coverage of Data Quality Aspects
4.2.1. Missing Related Implementations
4.2.2. Consistency-Related Implementations
4.2.3. Accuracy-Related Implementations
4.3. Data Quality in Electronic Health Records
4.4. Strengths and Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CRAN | Comprehensive R Archive Network |
| CDM | Common Data Model |
| DQ | Data Quality |
| DQA | Data Quality Assessment |
| GUI | Graphical User Interface |
Appendix A. Search Queries
- (data OR dataset) AND quality
- quality AND indicator
- (data OR dataset OR quality) AND (assessment OR control OR check OR monitor OR manage OR report OR summary OR summarise OR curation OR screening OR visualise)
- (data OR dataset) AND (clean OR validate OR preprocess OR process OR consistent OR inconsistent)
- exploration OR exploratory
- metadata
Appendix B. Reference Data Quality Framework
Integrity: The degree to which the data conforms to structural and technical requirements.
Completeness: The degree to which expected data values are present.
Consistency: The degree to which data values are free of breaks in conventions or contradictions.
Accuracy: The degree of agreement between observed and expected distributions and associations.
The integrity dimension entails three domains:
Structural dataset error: The observed structure of a dataset differs from the expected structure.
Dataset combination error: The observed correspondence between different datasets differs from the expected correspondence.
Value format error: The technical representation of data values within a dataset does not conform to the expected representation.
The completeness dimension consists of two domains:
Crude missingness: Metrics of missing data values that ignore the underlying reasons for missing data.
Qualified missingness: Metrics of missing data values that use reasons underlying missing data.
The consistency dimension entails the following two domains:
Range and value violations: Observed data values do not comply with admissible data values or value ranges.
Contradictions: Observed data values appear in impossible or improbable combinations.
Lastly, the accuracy dimension contains three domains:
Unexpected distribution: Observed distributional characteristics differ from expected distributional characteristics.
Unexpected association: Observed associations differ from expected associations.
Disagreement of repeated measurements: Disagreement between repeated measurements of the same or similar objects under specified conditions.
Appendix C. Package Assessment Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | assertable | assertive | assertr | clickR |
|---|---|---|---|---|
| Explicit reference to data quality | yes | |||
| Based on a data quality framework | ||||
| Control via GUI | ||||
| Reproducibility via programming | yes | yes | yes | yes |
| Single function call for output | ||||
| Report generation (not only console) | ||||
| Input of metadata through functions | yes | yes | yes | yes |
| Input of metadata through separate file | ||||
| Grading of data quality issues | ||||
| Dataset summary/overview | yes | |||
| Descriptive summary statistics | yes | |||
| Descriptive statistics graphs—univariate | yes | |||
| Descriptive statistics graphs—multivariate | ||||
| Handles string properties | yes | yes | ||
| Integrity: Structural dataset error | 1001, 1002, 1003, 100X | 1003 | 1001, 1003, 100X | |
| Integrity: Dataset combination error | 1005 | 1004, 1005 | 1005 | |
| Integrity: Value format error | 1006 | 1006, 100Y, 1007 | 1006 | 1006, 1006D, 1007 |
| Completeness: Crude missingness | 2001 | 2001 | 2001 | 2001 |
| Completeness: Qualified missingness | ||||
| Consistency: Range and value violations | 3001, 3002, 3003, 3006, 3007 | 3001, 3002, 3003, 3005, 3006, 3007 | 3001, 3003, 3006 | 3001D, 3002D, 3003D, 3006D, 3007D |
| Consistency: Contradictions | 3008, 3009 | |||
| Accuracy: Unexpected distributions | 4001D, 4002D | 4001, 4001D, 4002, 4003D, 4004D, 4005D, 400X | ||
| Accuracy: Unexpected associations | 4007D, 4008D | |||
| Accuracy: Disagreement of rep. meas. |
| Criteria | DataExplorer | dataquieR | dataReporter | DescTools |
|---|---|---|---|---|
| Explicit reference to data quality | yes | yes | ||
| Based on a data quality framework | yes [6] | |||
| Control via GUI | ||||
| Reproducibility via programming | yes | yes | yes | yes |
| Single function call for output | yes | yes | yes | |
| Report generation (not only console) | yes | yes | yes | yes |
| Input of metadata through functions | yes | yes | yes | |
| Input of metadata through separate file | yes | |||
| Grading of data quality issues | yes | yes | ||
| Dataset summary/overview | yes | yes | yes | yes |
| Descriptive summary statistics | yes | yes | ||
| Descriptive statistics graphs—univariate | yes | yes | yes | yes |
| Descriptive statistics graphs—multivariate | yes | yes | yes | |
| Handles string properties | yes | yes | ||
| Integrity: Structural dataset error | 1001, 100X | |||
| Integrity: Dataset combination error | 1004, 1005 | |||
| Integrity: Value format error | 1006D | 1006, 1008 | 1006D, 100Y, 1007 | 1006, 1006D, 100Y, 1007 |
| Completeness: Crude missingness | 2001 | 2001 | 2001 | 2001 |
| Completeness: Qualified missingness | 2002D, 2003D, 2004D, 2005 | |||
| Consistency: Range and value violations | 3001D, 3003D, 3006D | 3001, 3002, 3003, 3006, 3007 | 3001D, 3002D, 3003D, 3006D, 3007D | 3001, 3002D, 3003, 3004D, 3005, 3006, 3007D |
| Consistency: Contradictions | 3008, 3009 | |||
| Accuracy: Unexpected distributions | 4001D, 4003D, 4004D, 4005D, 4006D, 400XD | 4001, 4001D, 4002, 4002D, 4003, 4003D, 4004, 4004D, 4005, 4005D, 4006, 4006D | 4001D, 4003D, 4004D, 4005D, 4006D, 400X | 4001D, 4002, 4003, 4003D, 4004D, 4005D, 4006, 4006D, 400XD |
| Accuracy: Unexpected associations | 4007D, 4008D, 4009D | 4007D, 4008D, 4009D | 4007, 4007D, 4008D, 4009D | |
| Accuracy: Disagreement of rep. meas. | 4011, 4012, 4013 |
| Criteria | dlookr | DQAstats | ExPanDaR | explore |
|---|---|---|---|---|
| Explicit reference to data quality | yes | yes | ||
| Based on a data quality framework | yes [17] | |||
| Control via GUI | yes * | yes | yes | |
| Reproducibility via programming | yes | yes | yes | yes |
| Single function call for output | yes | yes | yes | yes |
| Report generation (not only console) | yes | yes | yes | yes |
| Input of metadata through functions | yes | |||
| Input of metadata through separate file | yes | yes | ||
| Grading of data quality issues | yes | |||
| Dataset summary/overview | yes | yes | yes | yes |
| Descriptive summary statistics | yes | yes | yes | yes |
| Descriptive statistics graphs—univariate | yes | yes | yes | |
| Descriptive statistics graphs—multivariate | yes | yes | yes | |
| Handles string properties | yes | yes | ||
| Integrity: Structural dataset error | 1003 | 1003 | ||
| Integrity: Dataset combination error | 1004D, 1005 | |||
| Integrity: Value format error | 1006D | 1006D, 100Y, 1007, 1008 | 1006D | |
| Completeness: Crude missingness | 2001 | 2001 | 2001 | 2001 |
| Completeness: Qualified missingness | ||||
| Consistency: Range and value violations | 3001, 3002D, 3003D, 3005D, 3006D, 3007D | 3001, 3002, 3003, 3005, 3006, 3007 | 3001D, 3003D, 3006D | 3001D, 3002D, 3003D, 3006D, 3007D |
| Consistency: Contradictions | 3008, 3009 | |||
| Accuracy: Unexpected distributions | 4001D, 4003D, 4004D, 4005D, 4006D, 400X | 4001D, 4003D, 4005D, 4006D, 400XD | 4001D, 4003D, 4004D, 4005D, 4006D, 400XD | 4001D, 4003D, 4004D, 4005D, 4006D, 400XD |
| Accuracy: Unexpected associations | 4007D, 4008D, 4009D | 4007D, 4008D, 4009D | 4007D, 4008D, 4009D | |
| Accuracy: Disagreement of rep. meas. |
| Criteria | funModeling | inspectdf | IPDFileCheck | MOQA 2 |
|---|---|---|---|---|
| Explicit reference to data quality | yes | |||
| Based on a data quality framework | yes [7] | |||
| Control via GUI | ||||
| Reproducibility via programming | yes | yes | yes | yes |
| Single function call for output | yes | |||
| Report generation (not only console) | yes | |||
| Input of metadata through functions | yes | yes | ||
| Input of metadata through separate file | ||||
| Grading of data quality issues | ||||
| Dataset summary/overview | yes | yes | ||
| Descriptive summary statistics | yes | yes | yes | yes |
| Descriptive statistics graphs—univariate | yes | yes | yes | |
| Descriptive statistics graphs—multivariate | yes | |||
| Handles string properties | yes | yes | ||
| Integrity: Structural dataset error | 1001, 100X | |||
| Integrity: Dataset combination error | 1004, 1005 | 1004D, 1005, | ||
| 1005D | ||||
| Integrity: Value format error | 1006D | 1006, 1006D | 1006 | |
| Completeness: Crude missingness | 2001 | 2001 | 2001 | 2001 |
| Completeness: Qualified missingness | 2005D | |||
| Consistency: Range and value violations | 3001D, 3002D, | 3001D, 3003D, | 3001, 3003, 3005, | 3001D, 3003D, |
| 3003D, 3006D, | 3006D | 3006 | 3006D | |
| 3007D | ||||
| Consistency: Contradictions | ||||
| Accuracy: Unexpected distributions | 4001D, 4003D, | 4001D, 4003D, | 4003D, 4005D, | 4001D, 4003D, |
| 4004D, 4005D, | 4004D, 4005D, | 4006D | 4004D, 4005D, | |
| 4006D, 400XD | 4006D, 400XD | 4006D, 400XD | ||
| Accuracy: Unexpected associations | 4007D, 4008D | 4007D, 4008D | ||
| Accuracy: Disagreement of rep. meas. |
| Criteria | mStats | pointblank | sanityTracker | skimr |
|---|---|---|---|---|
| Explicit reference to data quality | yes | |||
| Based on a data quality framework | ||||
| Control via GUI | ||||
| Reproducibility via programming | yes | yes | yes | yes |
| Single function call for output | yes | yes | yes | |
| Report generation (not only console) | yes | |||
| Input of metadata through functions | yes | yes | ||
| Input of metadata through separate file | ||||
| Grading of data quality issues | yes | |||
| Dataset summary/overview | yes | yes | yes | |
| Descriptive summary statistics | yes | yes | yes | |
| Descriptive statistics graphs—univariate | yes | yes | yes | |
| Descriptive statistics graphs—multivariate | yes | |||
| Handles string properties | yes | yes | ||
| Integrity: Structural dataset error | 1003 | 1001, 1002, 1003, 100X | 1003 | |
| Integrity: Dataset combination error | 1004, 1005 | 1004, 1005 | ||
| Integrity: Value format error | 1006D | 1006, 1006D, 100YD, 1007, 1007D | 1006D | |
| Completeness: Crude missingness | 2001 | 2001 | 2001 | 2001 |
| Completeness: Qualified missingness | ||||
| Consistency: Range and value violations | 3001D, 3003D, 3006D | 3001, 3002, 3003, 3005, 3006, 3007 | 3001, 3003, 3006 | 3001D, 3002D, 3003D, 3006D, 3007D |
| Consistency: Contradictions | 3008, 3009 | |||
| Accuracy: Unexpected distributions | 4001D, 4002D, 4003D, 4004D, 4005D, 4006D | 4001D, 4002D, 4003D, 4005D, 4006D | 4003D, 4004D, 4005D, 4006D | |
| Accuracy: Unexpected associations | 4007, 4007D, 4008, 4008D, 4009D | 4007D, 4008D, 4009D | ||
| Accuracy: Disagreement of rep. meas. |
| Criteria | SmartEDA | StatMeasures | summarytools | testdat |
|---|---|---|---|---|
| Explicit reference to data quality | yes | |||
| Based on a data quality framework | ||||
| Control via GUI | ||||
| Reproducibility via programming | yes | yes | yes | yes |
| Single function call for output | yes | yes | yes | |
| Report generation (not only console) | yes | yes | yes | |
| Input of metadata through functions | yes | yes | ||
| Input of metadata through separate file | ||||
| Grading of data quality issues | yes | |||
| Dataset summary/overview | yes | yes | yes | |
| Descriptive summary statistics | yes | yes | yes | |
| Descriptive statistics graphs—univariate | yes | yes | ||
| Descriptive statistics graphs—multivariate | yes | |||
| Handles string properties | yes | |||
| Integrity: Structural dataset error | 1003 | 1003 | 1003 | |
| Integrity: Dataset combination error | ||||
| Integrity: Value format error | 1006D | 1006D | 1006D | 100Y, 1007, 1008 |
| Completeness: Crude missingness | 2001 | 2001 | 2001 | 2001 |
| Completeness: Qualified missingness | 2005 | |||
| Consistency: Range and value violations | 3001D, 3003D, | 3001D, 3002D, | 3001D, 3002D, | 3001, 3002, 3003, |
| 3006D | 3003D, 3006D, | 3003D, 3006D, | 3005, 3006, 3007 | |
| 3007D | 3007D | |||
| Consistency: Contradictions | 3008, 3009 | |||
| Accuracy: Unexpected distributions | 4001, 4001D, | 4001D, 4003D, | 4003D, 4004D, | 4006D |
| 4002D, 4003D, | 4005D, 4006, | 4005D, 4006D, | ||
| 4004D, 4005D, | 4006D | 400XD | ||
| 4006D, 400XD | ||||
| Accuracy: Unexpected associations | 4007, 4007D, | 4007, 4008 | ||
| 4008D, 4009D | ||||
| Accuracy: Disagreement of rep. meas. |
| Criteria | validate | visdat | xray |
|---|---|---|---|
| Explicit reference to data quality | yes | ||
| Based on a data quality framework | |||
| Control via GUI | |||
| Reproducibility via programming | yes | yes | yes |
| Single function call for output | yes | ||
| Report generation (not only console) | |||
| Input of metadata through functions | yes | yes | |
| Input of metadata through separate file | yes | ||
| Grading of data quality issues | yes | ||
| Dataset summary/overview | yes | yes | |
| Descriptive summary statistics | yes | ||
| Descriptive statistics graphs—univariate | yes | ||
| Descriptive statistics graphs—multivariate | yes | ||
| Handles string properties | yes | yes | |
| Integrity: Structural dataset error | 1002, 1003 | 1001, 1002 | |
| Integrity: Dataset combination error | 1004 | ||
| Integrity: Value format error | 100Y, 1007 | 1006, 1006D, 1007 | 1006D |
| Completeness: Crude missingness | 2001 | 2001 | 2001 |
| Completeness: Qualified missingness | |||
| Consistency: Range and value violations | 3001, 3002, 3003, 3004, 3005, 3006, 3007 | 3001D, 3002D, 3003D, 3006D, 3007D | |
| Consistency: Contradictions | 3008, 3009 | ||
| Accuracy: Unexpected distributions | 4001D | 4003D, 4004D, 4005D, 4006D, 400XD | |
| Accuracy: Unexpected associations | 4007D, 4008D | ||
| Accuracy: Disagreement of rep. meas. |
References
- Kahn, M.G.; Brown, J.S.; Chun, A.T.; Davidson, B.N.; Meeker, D.; Ryan, P.B.; Schilling, L.M.; Weiskopf, N.G.; Williams, A.E.; Zozus, M.N. Transparent reporting of data quality in distributed data networks. EGEMS 2015, 3, 1052. [Google Scholar] [CrossRef] [PubMed]
- Kahn, M.G.; Callahan, T.J.; Barnard, J.; Bauck, A.E.; Brown, J.; Davidson, B.N.; Estiri, H.; Goerg, C.; Holve, E.; Johnson, S.G.; et al. A harmonized data quality assessment terminology and framework for the secondary use of electronic health record data. EGEMS 2016, 4, 1244. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, K.; Weiskopf, N.; Pathak, J. A Framework for Data Quality Assessment in Clinical Research Datasets. AMIA Annu. Symp. Proc. 2017, 2017, 1080–1089. [Google Scholar] [PubMed]
- Liaw, S.T.; Guo, J.G.N.; Ansari, S.; Jonnagaddala, J.; Godinho, M.A.; Borelli, A.J.; de Lusignan, S.; Capurro, D.; Liyanage, H.; Bhattal, N.; et al. Quality assessment of real-world data repositories across the data life cycle: A literature review. J. Am. Med. Inform. Assoc. 2021, 28, 1591–1599. [Google Scholar] [CrossRef]
- Weiskopf, N.G.; Bakken, S.; Hripcsak, G.; Weng, C. A data quality assessment guideline for electronic health record data reuse. EGEMS 2017, 5, 14. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, C.O.; Struckmann, S.; Enzenbach, C.; Reineke, A.; Stausberg, J.; Damerow, S.; Huebner, M.; Schmidt, B.; Sauerbrei, W.; Richter, A. Facilitating harmonized data quality assessments. A data quality framework for observational health research data collections with software implementations in R. BMC Med. Res. Methodol. 2021, 21, 63. [Google Scholar] [CrossRef]
- Nonnemacher, M.; Nasseh, D.; Stausberg, J. Datenqualität in der medizinischen Forschung: Leitlinie zum adaptiven Management von Datenqualität in Kohortenstudien und Registern; MWV Medizinisch Wissenschaftliche Verlagsgesellschaft: Berlin, Germany, 2014. [Google Scholar]
- Kandel, S.; Parikh, R.; Paepcke, A.; Hellerstein, J.M.; Heer, J. Profiler: Integrated statistical analysis and visualization for data quality assessment. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Capri Island, Italy, 21–25 May 2012; pp. 547–554. [Google Scholar]
- Golling, T.; Hayward, H.; Onyisi, P.; Stelzer, H.; Waller, P. The ATLAS data quality defect database system. Eur. Phys. J. C 2012, 72, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Fillbrunn, A.; Dietz, C.; Pfeuffer, J.; Rahn, R.; Landrum, G.A.; Berthold, M.R. KNIME for reproducible cross-domain analysis of life science data. J. Biotechnol. 2017, 261, 149–156. [Google Scholar] [CrossRef]
- Tute, E.; Scheffner, I.; Marschollek, M. A method for interoperable knowledge-based data quality assessment. BMC Med. Informatics Decis. Mak. 2021, 21, 93. [Google Scholar] [CrossRef]
- De Jonge, E.; Van Der Loo, M. An Introduction to Data Cleaning with R; Statistics Netherlands: Heerlen, The Netherlands, 2013. [Google Scholar]
- Eaton, J.; Painter, I.; Olson, D.; Lober, W.B. Visualizing the quality of partially accruing data for use in decision making. Online J. Public Health Inform. 2015, 7, e226. [Google Scholar] [CrossRef] [Green Version]
- Hripcsak, G.; Duke, J.D.; Shah, N.H.; Reich, C.G.; Huser, V.; Schuemie, M.J.; Suchard, M.A.; Park, R.W.; Wong, I.C.K.; Rijnbeek, P.R.; et al. Observational Health Data Sciences and Informatics (OHDSI): Opportunities for observational researchers. Stud. Health Technol. Inform. 2015, 216, 574. [Google Scholar] [PubMed]
- Bialke, M.; Rau, H.; Schwaneberg, T.; Walk, R.; Bahls, T.; Hoffmann, W. mosaicQA-A General Approach to Facilitate Basic Data Quality Assurance for Epidemiological Research. Methods Inf. Med. 2017, 56, e67–e73. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Petersen, A.H.; Ekstrøm, C.T. dataMaid: Your Assistant for Documenting Supervised Data Quality Screening in R. J. Stat. Softw. 2019, 90, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Kapsner, L.A.; Kampf, M.O.; Seuchter, S.A.; Kamdje-Wabo, G.; Gradinger, T.; Ganslandt, T.; Mate, S.; Gruendner, J.; Kraska, D.; Prokosch, H.U. Moving towards an EHR data quality framework: The MIRACUM approach. In German Medical Data Sciences: Shaping Change–Creative Solutions for Innovative Medicine; IOS Press: Amsterdam, The Netherlands, 2019; pp. 247–253. [Google Scholar]
- van der Loo, M.P.J.; de Jonge, E. Data Validation Infrastructure for R. J. Stat. Softw. 2021, 97, 1–31. [Google Scholar] [CrossRef]
- Huebner, M.; le Cessie, S.; Schmidt, C.O.; Vach, W. A contemporary conceptual framework for initial data analysis. Obs. Stud. 2018, 4, 171–192. [Google Scholar] [CrossRef]
- Staniak, M.; Biecek, P. The Landscape of R Packages for Automated Exploratory Data Analysis. R J. 2019, 11, 347. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Hornik, K. R FAQ. 2021. Available online: https://cran.r-project.org/doc/FAQ/R-FAQ.html (accessed on 8 March 2022).
- Standard ISO 8000-2:2017; Data Quality—Part 2: Vocabulary; International Organization for Standardization: Geneva, Switzerland, 2017.
- Richter, A.; Schössow, J.; Werner, A.; Schauer, B.; Radke, D.; Henke, J.; Struckmann, S.; Schmidt, C.O. Data quality monitoring in clinical and observational epidemiologic studies: The role of metadata and process information. MIBE 2019, 15. [Google Scholar] [CrossRef]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.; Horsley, T.; Weeks, L.; et al. PRISMA Extension for Scoping Reviews (PRISMA-ScR): Checklist and Explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef] [Green Version]
- Putatunda, S.; Ubrangala, D.; Rama, K.; Kondapalli, R. SmartEDA: An R Package for Automated Exploratory Data Analysis. J. Open Source Softw. 2019, 4, 1509. [Google Scholar] [CrossRef]
- Csárdi, G.; Salmon, M. pkgsearch: Search and Query CRAN R Packages; R Package Version 3.0.3. 2020. Available online: https://CRAN.R-project.org/package=pkgsearch (accessed on 18 January 2022).
- Wickham, H.; François, R.; Henry, L.; Müller, K. dplyr: A Grammar of Data Manipulation; R Package Version 1.0.7. 2021. Available online: https://CRAN.R-project.org/package=dplyr (accessed on 18 January 2022).
- Schmidt, C.O.; Richter, A.; Struckmann, S. Data Quality Concept. Available online: https://dataquality.ship-med.uni-greifswald.de/DQconceptNew.html (accessed on 9 March 2022).
- Völzke, H.; Alte, D.; Schmidt, C.O.; Radke, D.; Lorbeer, R.; Friedrich, N.; Aumann, N.; Lau, K.; Piontek, M.; Born, G.; et al. Cohort Profile: The Study of Health in Pomerania. Int. J. Epidemiol. 2011, 40, 294–307. [Google Scholar] [CrossRef] [Green Version]
- Völzke, H.; Schössow, J.; Schmidt, C.O.; Jürgens, C.; Richter, A.; Werner, A.; Werner, N.; Radke, D.; Teumer, A.; Ittermann, T.; et al. Cohort Profile Update: The Study of Health in Pomerania (SHIP). Int. J. Epidemiol. 2022, dyac034. [Google Scholar] [CrossRef] [PubMed]
- Standards and Tools for Data Quality Assessment in Epidemiological Studies. Available online: https://dataquality.ship-med.uni-greifswald.de/ (accessed on 1 October 2021).
- Hebbali, A. xplorerr: Tools for Interactive Data Exploration; R Package Version 0.1.2. 2021. Available online: https://CRAN.R-project.org/package=xplorerr (accessed on 7 March 2022).
- Priyam, A. Analyzer: Data Analysis and Automated R Notebook Generation; R Package Version 1.0.1. 2020. Available online: https://CRAN.R-project.org/package=analyzer (accessed on 7 March 2022).
- Nanji, H.; Chernbumroong, S. mdapack: Medical Data Analysis Pack; R Package Version 0.0.2. 2020. Available online: https://CRAN.R-project.org/package=mdapack (accessed on 7 March 2022).
- de Jonge, E.; van der Loo, M. editrules: Parsing, Applying, and Manipulating Data Cleaning Rules. R Package Version 2.9.3. 2018. Available online: https://CRAN.R-project.org/package=editrules (accessed on 7 March 2022).
- Nguyen, G. assertable: Verbose Assertions for Tabular Data (Data.frames and Data.tables); R Package Version 0.2.8. 2021. Available online: https://CRAN.R-project.org/package=assertable (accessed on 7 March 2022).
- Cotton, R. assertive: Readable Check Functions to Ensure Code Integrity; R Package Version 0.3-6. 2020. Available online: https://CRAN.R-project.org/package=assertive (accessed on 7 March 2022).
- Fischetti, T. Assertr: Assertive Programming for R Analysis Pipelines; R Package Version 2.8. 2021. Available online: https://CRAN.R-project.org/package=assertr (accessed on 7 March 2022).
- Marin, D.H. clickR: Semi-Automatic Preprocessing of Messy Data with Change Tracking for Dataset Cleaning; R Package Version 0.8.0. 2021. Available online: https://CRAN.R-project.org/package=clickR (accessed on 7 March 2022).
- Cui, B. DataExplorer: Automate Data Exploration and Treatment; R Package Version 0.8.2. 2020. Available online: https://CRAN.R-project.org/package=DataExplorer (accessed on 7 March 2022).
- Richter, A.; Schmidt, C.O.; Struckmann, S. dataquieR: Data Quality in Epidemiological Research; R Package Version 1.0.9. 2021. Available online: https://CRAN.R-project.org/package=dataquieR (accessed on 7 March 2022).
- Signorell, A.; Aho, K.; Alfons, A.; Anderegg, N.; Aragon, T.; Arachchige, C.; Arppe, A.; Baddeley, A.; Barton, K.; Bolker, B.; et al. DescTools: Tools for Descriptive Statistics; R Package Version 0.99.44. 2021. Available online: https://CRAN.R-project.org/package=DescTools (accessed on 7 March 2022).
- Ryu, C. dlookr: Tools for Data Diagnosis, Exploration, Transformation; R Package Version 0.5.4. 2021. Available online: https://CRAN.R-project.org/package=dlookr (accessed on 7 March 2022).
- Kapsner, L.A.; Mang, J.M.; Mate, S.; Seuchter, S.A.; Vengadeswaran, A.; Bathelt, F.; Deppenwiese, N.; Kadioglu, D.; Kraska, D.; Prokosch, H.U. Linking a Consortium-Wide Data Quality Assessment Tool with the MIRACUM Metadata Repository. Appl. Clin. Inf. 2021, 12, 826–835. [Google Scholar] [CrossRef] [PubMed]
- de Jonge, E.; van der Loo, M. errorlocate: Locate Errors with Validation Rules; R Package Version 0.9.9. 2021. Available online: https://CRAN.R-project.org/package=errorlocate (accessed on 7 March 2022).
- Gassen, J. ExPanDaR: Explore Your Data Interactively; R Package Version 0.5.3. 2020. Available online: https://CRAN.R-project.org/package=ExPanDaR (accessed on 7 March 2022).
- Krasser, R. explore: Simplifies Exploratory Data Analysis; R Package Version 0.8.0. 2022. Available online: https://CRAN.R-project.org/package=explore (accessed on 7 March 2022).
- Casas, P. funModeling: Exploratory Data Analysis and Data Preparation Tool-Box; R Package Version 1.9.4. 2020. Available online: https://CRAN.R-project.org/package=funModeling (accessed on 7 March 2022).
- Rushworth, A. inspectdf: Inspection, Comparison and Visualisation of Data Frames; R Package Version 0.0.11. 2021. Available online: https://CRAN.R-project.org/package=inspectdf (accessed on 7 March 2022).
- Krishnan, S.M. IPDFileCheck: Basic Functions to Check Readability, Consistency, and Content of an Individual Participant Data File. R Package Version 0.7.5. 2022. Available online: https://CRAN.R-project.org/package=IPDFileCheck (accessed on 7 March 2022).
- Bialke, M.; Schwaneberg, T.; Walk, R. MOQA: Basic Quality Data Assurance for Epidemiological Research; R Package Version 2.0.0. 2017. Available online: https://CRAN.R-project.org/package=MOQA (accessed on 7 March 2022).
- Oo, M.M. mStats: Epidemiological Data Analysis; R Package Version 3.4.0. 2020. Available online: https://CRAN.R-project.org/package=mStats (accessed on 7 March 2022).
- Iannone, R.; Vargas, M. pointblank: Data Validation and Organization of Metadata for Local and Remote Tables; R Package Version 0.10.0. 2022. Available online: https://CRAN.R-project.org/package=pointblank (accessed on 7 March 2022).
- Scheer, M. sanityTracker: Keeps Track of all Performed Sanity Checks; R Package Version 0.1.0. 2020. Available online: https://CRAN.R-project.org/package=sanityTracker (accessed on 7 March 2022).
- Waring, E.; Quinn, M.; McNamara, A.; Arino de la Rubia, E.; Zhu, H.; Ellis, S. skimr: Compact and Flexible Summaries of Data; R Package Version 2.1.3. 2021. Available online: https://CRAN.R-project.org/package=skimr (accessed on 7 March 2022).
- Dayanand Ubrangala, R.K.; Prasad Kondapalli, R.; Putatunda, S. SmartEDA: Summarize and Explore the Data; R Package Version 0.3.8. 2021. Available online: https://CRAN.R-project.org/package=SmartEDA (accessed on 7 March 2022).
- Jain, A. StatMeasures: Easy Data Manipulation, Data Quality and Statistical Checks; R Package Version 1.0. 2015. Available online: https://CRAN.R-project.org/package=StatMeasures (accessed on 7 March 2022).
- Comtois, D. summarytools: Tools to Quickly and Neatly Summarize Data; R Package Version 1.0.0. 2021. Available online: https://CRAN.R-project.org/package=summarytools (accessed on 7 March 2022).
- Smith, D.; Behr, K. testdat: Data Unit Testing for R; R Package Version 0.4.0. 2022. Available online: https://CRAN.R-project.org/package=testdat (accessed on 7 March 2022).
- Tierney, N. visdat: Visualising Whole Data Frames. JOSS 2017, 2, 355. [Google Scholar] [CrossRef] [Green Version]
- Seibelt, P. xray: X Ray Vision on Your Datasets; R Package Version 0.2. 2017. Available online: https://CRAN.R-project.org/package=xray (accessed on 7 March 2022).
- Csárdi, G. cranlogs: Download Logs from the ’RStudio’ ’CRAN’ Mirror; R Package Version 2.1.1. 2019. Available online: https://CRAN.R-project.org/package=cranlogs (accessed on 5 April 2022).
- Hamill, P. Unit Test Frameworks: Tools for High-Quality Software Development; O’Reilly Media: Newton, MA, USA, 2004. [Google Scholar]
- Wickham, H. testthat: Get Started with Testing. R J. 2011, 3, 5–10. [Google Scholar] [CrossRef] [Green Version]
- van der Loo, M.P.J. Monitoring Data in R with the lumberjack Package. J. Stat. Softw. 2021, 98, 1–13. [Google Scholar] [CrossRef]
- Kapsner, L.A.; Mang, J.M. DQAgui: Graphical User Interface for Data Quality Assessment; R Package Version 0.1.9. 2022. Available online: https://CRAN.R-project.org/package=DQAgui (accessed on 7 March 2022).
- Rinaldi, E.; Thun, S. From OpenEHR to FHIR and OMOP Data Model for Microbiology Findings. Stud. Health Technol. Inf. 2021, 281, 402–406. [Google Scholar] [CrossRef]
- Cheng, A.C.; Duda, S.N.; Taylor, R.; Delacqua, F.; Lewis, A.A.; Bosler, T.; Johnson, K.B.; Harris, P.A. REDCap on FHIR: Clinical Data Interoperability Services. J. Biomed. Inf. 2021, 121, 103871. [Google Scholar] [CrossRef]
- Hoevenaar-Blom, M.P.; Guillemont, J.; Ngandu, T.; Beishuizen, C.R.L.; Coley, N.; Moll van Charante, E.P.; Andrieu, S.; Kivipelto, M.; Soininen, H.; Brayne, C.; et al. Improving data sharing in research with context-free encoded missing data. PLoS ONE 2017, 12, e0182362. [Google Scholar] [CrossRef] [Green Version]
- Dinh, D.T.; Huynh, V.N.; Sriboonchitta, S. Clustering mixed numerical and categorical data with missing values. Inf. Sci. 2021, 571, 418–442. [Google Scholar] [CrossRef]
- Gao, K.; Khan, H.A.; Qu, W. Clustering with Missing Features: A Density-Based Approach. Symmetry 2022, 14, 60. [Google Scholar] [CrossRef]
- Holve, E.; Segal, C.; Lopez, M.H.; Rein, A.; Johnson, B.H. The Electronic Data Methods (EDM) Forum for Comparative Effectiveness Research (CER). Med. Care 2012, 50, S7–S10. [Google Scholar] [CrossRef] [PubMed]
- McMurry, A.J.; Murphy, S.N.; MacFadden, D.; Weber, G.; Simons, W.W.; Orechia, J.; Bickel, J.; Wattanasin, N.; Gilbert, C.; Trevvett, P.; et al. SHRINE: Enabling Nationally Scalable Multi-Site Disease Studies. PLoS ONE 2013, 8, e55811. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- van Ommen, G.J.B.; Törnwall, O.; Bréchot, C.; Dagher, G.; Galli, J.; Hveem, K.; Landegren, U.; Luchinat, C.; Metspalu, A.; Nilsson, C.; et al. BBMRI-ERIC as a Resource for Pharmaceutical and Life Science Industries: The Development of Biobank-Based Expert Centres. Eur. J. Hum. Genet. 2015, 23, 893–900. [Google Scholar] [CrossRef]
- Semler, S.; Wissing, F.; Heyder, R. German Medical Informatics Initiative: A National Approach to Integrating Health Data from Patient Care and Medical Research. Methods Inf. Med. 2018, 57, e50–e56. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bahls, T.; Pung, J.; Heinemann, S.; Hauswaldt, J.; Demmer, I.; Blumentritt, A.; Rau, H.; Drepper, J.; Wieder, P.; Groh, R.; et al. Designing and Piloting a Generic Research Architecture and Workflows to Unlock German Primary Care Data for Secondary Use. J. Transl. Med. 2020, 18, 394. [Google Scholar] [CrossRef] [PubMed]
- Hersh, W.R.; Weiner, M.G.; Embi, P.J.; Logan, J.R.; Payne, P.R.; Bernstam, E.V.; Lehmann, H.P.; Hripcsak, G.; Hartzog, T.H.; Cimino, J.J.; et al. Caveats for the Use of Operational Electronic Health Record Data in Comparative Effectiveness Research. Med. Care 2013, 51, S30–S37. [Google Scholar] [CrossRef] [Green Version]
- DeFalco, F.; Ryan, P.; Schuemie, M.; Huser, V.; Knoll, C.; Londhe, A.; Abdul-Basser, T.; Molinaro, A. Achilles: Generates Descriptive Statistics for an OMOP CDM Instance; R Package Version 1.7. 2021. Available online: https://github.com/OHDSI/Achilles (accessed on 7 March 2022).
- Blacketer, C.; Schuemie, F.J.; Ryan, P.B.; Rijnbeek, P. Increasing trust in real-world evidence through evaluation of observational data quality. J. Am. Med. Inform. Assoc. 2021, 28, 2251–2257. [Google Scholar] [CrossRef]
- OMOP Common Data Model. Available online: http://ohdsi.github.io/CommonDataModel/ (accessed on 5 April 2022).
- Ooms, J. METACRAN. Available online: https://www.r-pkg.org/ (accessed on 9 March 2022).
- Woo, K.; Kauer, N.; Montgomery, K. dccvalidator: Metadata Validation for Data Coordinating Centers; R Package Version 0.3.0. 2020. Available online: https://CRAN.R-project.org/package=dccvalidator (accessed on 28 February 2022).




| Dimension | Domain | Indicator |
|---|---|---|
| Integrity | ||
| Structural dataset error | ||
| 1001: Unexpected data elements | ||
| 1002: Unexpected data records | ||
| 1003: Duplicates | ||
| Dataset combination error | ||
| 1004: Data record mismatch | ||
| 1005: Data element mismatch | ||
| Value format error | ||
| 1006: Data type mismatch | ||
| 1007: Inhomogeneous value formats | ||
| 1008: Uncertain missingness status | ||
| Completeness | ||
| Crude missingness | ||
| 2001: Missing values | ||
| Qualified missingness | ||
| 2002: Non-response rate | ||
| 2003: Refusal rate | ||
| 2004: Drop-out rate | ||
| 2005: Missing due to specified reason | ||
| Consistency | ||
| Range and value violations | ||
| 3001: Inadmissible numerical values (hard limits) | ||
| 3002: Inadmissible time-date values | ||
| 3003: Inadmissible categorical values | ||
| 3004: Inadmissible standardized vocabulary | ||
| 3005: Inadmissible precision | ||
| 3006: Uncertain numerical values (soft limits) | ||
| 3007: Uncertain time-date values | ||
| Contradictions | ||
| 3008: Logical contradictions | ||
| 3009: Empirical contradictions | ||
| Accuracy | ||
| Unexpected distribution | ||
| 4001: Univariate outliers | ||
| 4002: Multivariate outliers | ||
| 4003: Unexpected locations | ||
| 4004: Unexpected shape | ||
| 4005: Unexpected scale | ||
| 4006: Unexpected proportions | ||
| Unexpected association | ||
| 4007: Unexpected association strength | ||
| 4008: Unexpected association direction | ||
| 4009: Unexpected association form | ||
| Disagreement of repeated measurements | ||
| 4011: Inter-Class reliability | ||
| 4012: Intra-Class reliability | ||
| 4013: Disagreement with gold standard | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mariño, J.; Kasbohm, E.; Struckmann, S.; Kapsner, L.A.; Schmidt, C.O. R Packages for Data Quality Assessments and Data Monitoring: A Software Scoping Review with Recommendations for Future Developments. Appl. Sci. 2022, 12, 4238. https://0-doi-org.brum.beds.ac.uk/10.3390/app12094238
Mariño J, Kasbohm E, Struckmann S, Kapsner LA, Schmidt CO. R Packages for Data Quality Assessments and Data Monitoring: A Software Scoping Review with Recommendations for Future Developments. Applied Sciences. 2022; 12(9):4238. https://0-doi-org.brum.beds.ac.uk/10.3390/app12094238
Chicago/Turabian StyleMariño, Joany, Elisa Kasbohm, Stephan Struckmann, Lorenz A. Kapsner, and Carsten O. Schmidt. 2022. "R Packages for Data Quality Assessments and Data Monitoring: A Software Scoping Review with Recommendations for Future Developments" Applied Sciences 12, no. 9: 4238. https://0-doi-org.brum.beds.ac.uk/10.3390/app12094238