
An Intelligent Solution for Automatic Garment Measurement Using Image Recognition Technologies

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
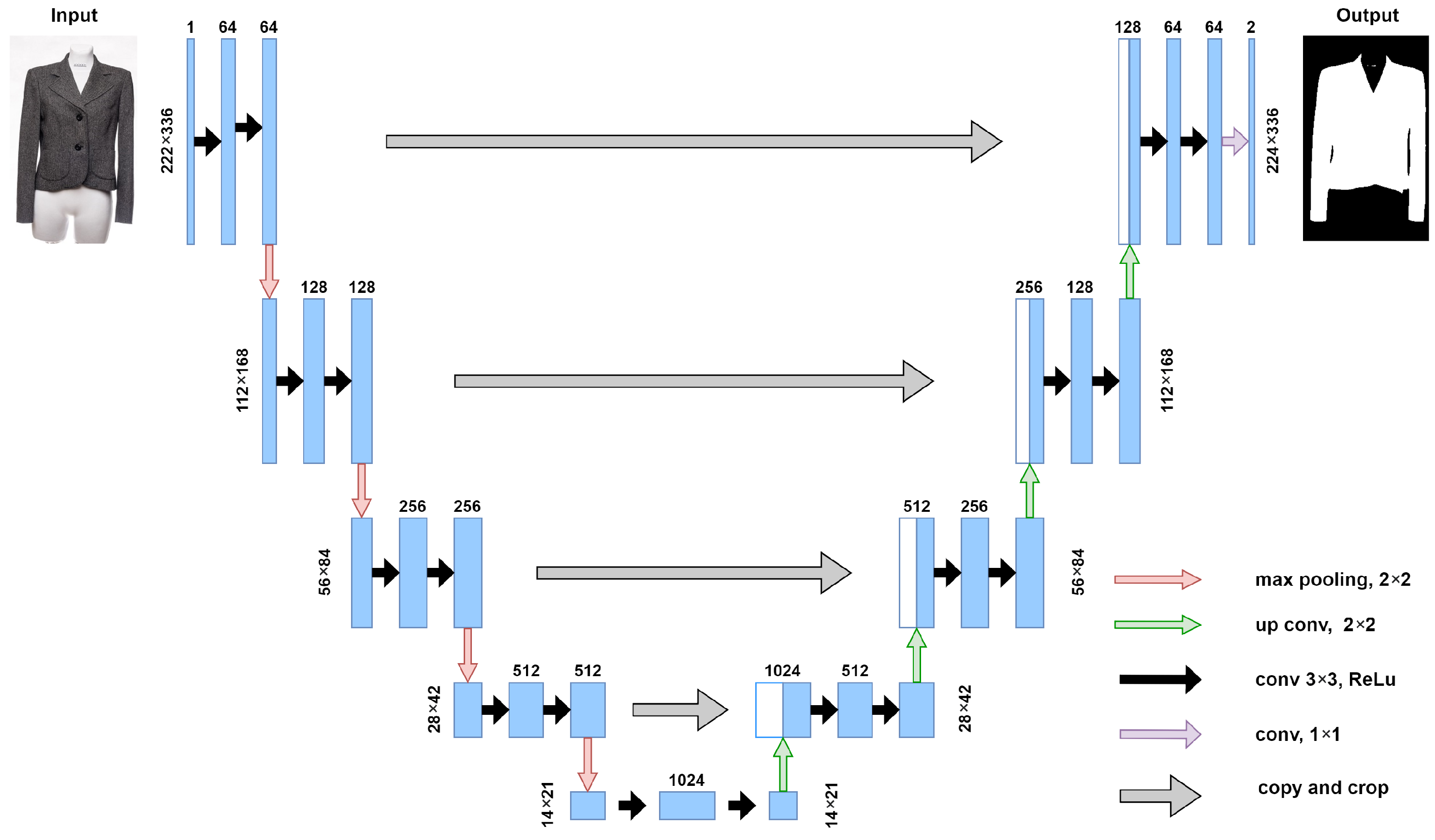
2.1. UNet Model-Based Extraction of Contours of the Garments’ Shape
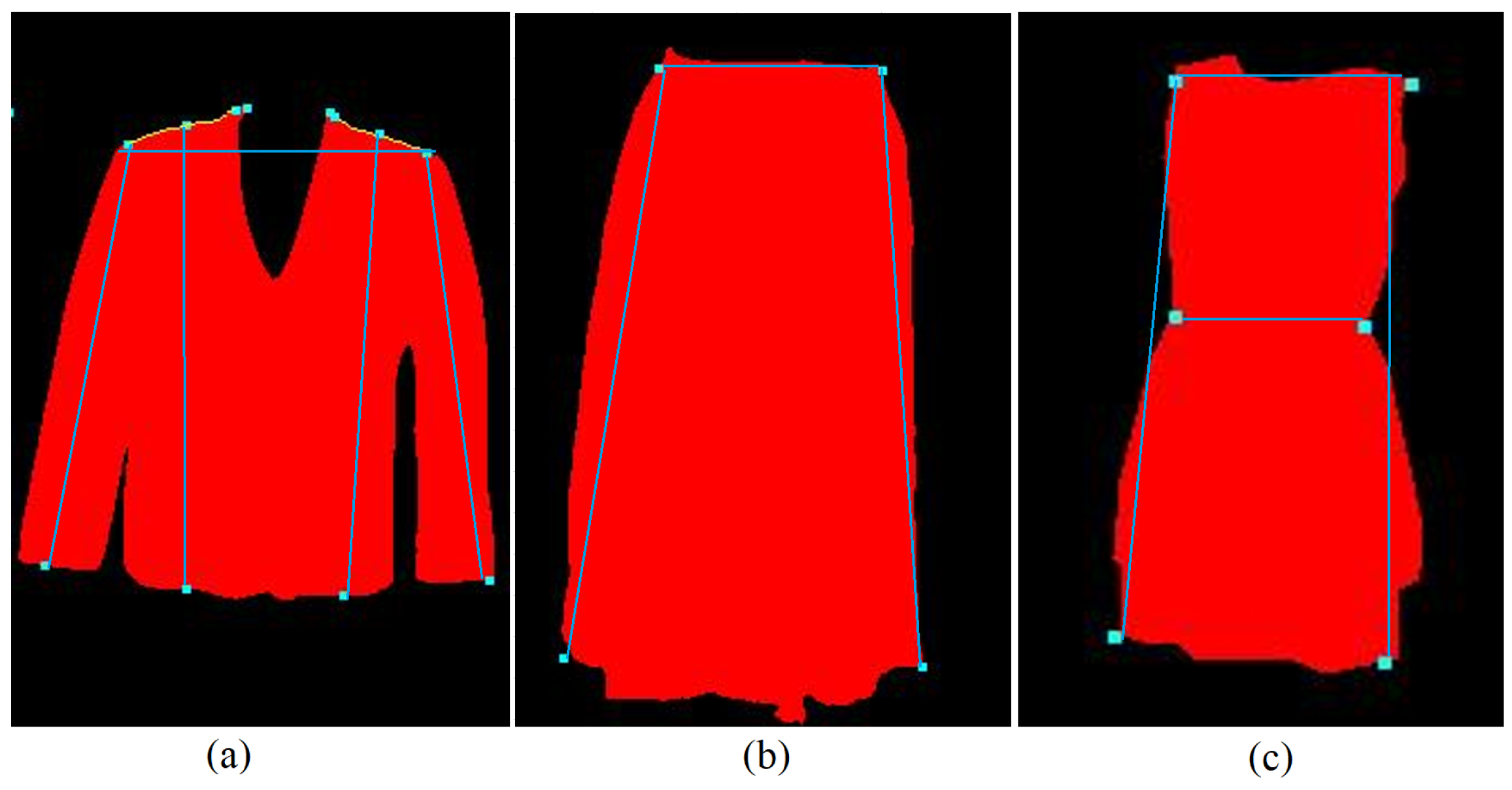
2.2. Garment Key Points Detection
- Identification of bounding box and the outermost points of the garment contour;
- Detection of garment’s angles, shapes, and changes in () coordinates;
- Key points prediction based on auxiliary algorithms that find the desired location;
- Final prediction that sets the sensitivity factor for developed algorithms to adapt to the type of the garment. Then the pixel to cm ratio is calculated and the dimensions of the garment are produced.
| Algorithm 1: Pseudo-code for left and right neck line identification. | |
Left
| Right
|
3. Results
3.1. Extraction of the Contours of the Garment Shape
3.1.1. Edge Detection Techniques
3.1.2. K-Means Clustering Approach
3.2. UNet-Based Segmentation
3.3. Obtained Measurement Results
4. Discussion
4.1. Limitations
4.2. Human Measurement Error
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumar, S.N.; Fred, A.L.; Varghese, P.S. An Overview of Segmentation Algorithms for the Analysis of Anomalies on Medical Images. J. Intell. Syst. 2020, 29, 612–625. [Google Scholar] [CrossRef]
- Cao, C.; Liu, F.; Tan, H.; Song, D.; Shu, W.; Li, W.; Zhou, Y.; Bo, X.; Xie, Z. Deep Learning and Its Applications in Biomedicine. Genom. Proteom. Bioinform. 2018, 16, 17–32. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Zhu, M.; Chen, Z.; Wu, C.; Chen, B.; Li, C.; Li, L. Seismic performance evaluation of recycled aggregate concrete-filled steel tubular columns with field strain detected via a novel mark-free vision method. Structures 2022, 37, 426–441. [Google Scholar] [CrossRef]
- Wu, F.; Duan, J.; Chen, S.; Ye, Y.; Ai, P.; Yang, Z. Multi-Target Recognition of Bananas and Automatic Positioning for the Inflorescence Axis Cutting Point. Front. Plant Sci. 2021, 12, 705021. [Google Scholar] [CrossRef]
- Gui, J.; Fei, J.; Wu, Z.; Fu, X.; Diakite, A. Grading method of soybean mosaic disease based on hyperspectral imaging technology. Inf. Process. Agric. 2021, 8, 380–385. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, R.; Lin, Y.; Li, C.; Chen, S.; Yuan, Z.; Chen, S.; Zou, X. Plant Disease Recognition Model Based on Improved YOLOv5. Agronomy 2022, 12, 365. [Google Scholar] [CrossRef]
- Krishnamoorthy, N.; Prasad, L.N.; Kumar, C.P.; Subedi, B.; Abraha, H.B.; Sathishkumar, V.E. Rice leaf diseases prediction using deep neural networks with transfer learning. Environ. Res. 2021, 198, 111275. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using Deep Learning to Detect Defects in Manufacturing: A Comprehensive Survey and Current Challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef]
- Pan, C.; Schoppe, O.; Parra-Damas, A.; Cai, R.; Todorov, M.I.; Gondi, G.; von Neubeck, B.; Böğürcü-Seidel, N.; Seidel, S.; Sleiman, K.; et al. Deep Learning Reveals Cancer Metastasis and Therapeutic Antibody Targeting in the Entire Body. Cell 2019, 179, 1661–1676.e19. [Google Scholar] [CrossRef]
- Xu, Y.; Hosny, A.; Zeleznik, R.; Parmar, C.; Coroller, T.; Franco, I.; Mak, R.H.; Aerts, H.J. Deep Learning Predicts Lung Cancer Treatment Response from Serial Medical Imaging. Clin. Cancer Res. 2019, 25, 3266–3275. [Google Scholar] [CrossRef] [Green Version]
- Vidas, R.; Agne, P.T.; Kristina, S.; Domas, J. Towards the automation of early-stage human embryo development detection. Biomed. Eng. 2019, 18, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Tan, F.; Xia, Z.; Ma, Y.; Feng, X. 3D Sensor Based Pedestrian Detection by Integrating Improved HHA Encoding and Two-Branch Feature Fusion. Remote Sens. 2022, 14, 645. [Google Scholar] [CrossRef]
- Wang, J.; Yu, X.; Liu, Q.; Yang, Z. Research on key technologies of intelligent transportation based on image recognition and anti-fatigue driving. EURASIP J. Image Video Process. 2019, 33. [Google Scholar] [CrossRef]
- Gabas, A.; Corona, E.; Alenya, G.; Torras, C. Robot-Aided Cloth Classification Using Depth Information and CNNs. In Articulated Motion and Deformable; Perales, F.J., Kittler, J., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 16–23. [Google Scholar] [CrossRef]
- Nayak, R.; Padhye, R. 1-Introduction to Automation in Garment Manufacturing; Automation in Garment Manufacturing; Woodhead Publishing: Boca Raton, FL, USA, 2018; pp. 1–27. [Google Scholar] [CrossRef]
- A Report: Study of the Automatic Garment Measurement, Robocoast, Leverage from EU 2014-2020, Aarila-Dots Oy. 2019. pp. 1–13. Available online: https://new.robocoast.eu/wp-content/uploads/2020/09/Feasibility-study-Automatic-garment-measurement_Aarila-Dots.pdf (accessed on 5 February 2022).
- Xiang, J.; Dong, T.; Pan, R.; Gao, W. Clothing Attribute Recognition Based on RCNN Framework Using L-Softmax Loss. IEEE Access 2020, 8, 48299–48313. [Google Scholar] [CrossRef]
- Ihsan, A.M.; Loo, C.K.; Naji, S.A.; Seera, M. Superpixels Features Extractor Network (SP-FEN) for Clothing Parsing Enhancement. Neural Process. Lett. 2020, 51, 2245–2263. [Google Scholar] [CrossRef]
- Li, C.; Xu, Y.; Xiao, Y.; Liu, H.; Feng, M.; Zhang, D. Automatic Measurement of Garment Sizes Using Image Recognition. In Proceedings of the International Conference on Graphics and Signal Processing; Association for Computing Machinery: New York, NY, USA, 2017; ICGSP ’17; pp. 30–34. [Google Scholar]
- Brian, C.; Tj, T. Photo Based Clothing Measurements|Stitch Fix Technology—Multithreaded. Available online: https://multithreaded.stitchfix.com/blog/2016/09/30/photo-based-clothing-measurement/ (accessed on 10 February 2022).
- Cao, L.; Jiang, Y.; Jiang, M. Automatic measurement of garment dimensions using machine vision. In Proceedings of the 2010 International Conference on Computer Application and System Modeling (ICCASM 2010), Taiyuan, China, 22–24 October 2010; Volume 9, pp. 9–33. [Google Scholar] [CrossRef]
- Tailored-Garment Measuring App. 2022. Available online: https://www.thetailoredco.com/ (accessed on 4 March 2022).
- Zhou, S.; Nie, D.; Adeli, E.; Yin, J.; Lian, J.; Shen, D. High-Resolution Encoder–Decoder Networks for Low-Contrast Medical Image Segmentation. IEEE Trans. Image Process. 2020, 29, 461–475. [Google Scholar] [CrossRef]
- Hu, C.; Sapkota, B.B.; Thomasson, J.A.; Bagavathiannan, M.V. Influence of Image Quality and Light Consistency on the Performance of Convolutional Neural Networks for Weed Mapping. Remote Sens. 2021, 13, 2140. [Google Scholar] [CrossRef]
- Ge, Y.; Zhang, R.; Wu, L.; Wang, X.; Tang, X.; Luo, P. A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images. arXiv 2019, arXiv:1901.07973. [Google Scholar]
- Adaloglouon, N. An Overview of Unet Architectures for Semantic Segmentation and Biomedical Image Segmentation. 2021. Available online: https://theaisummer.com/unet-architectures/ (accessed on 9 January 2022).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Jing, J.; Wang, Z.; Ratsch, M.; Zhang, H. Mobile-Unet: An efficient convolutional neural network for fabric defect detection. Text. Res. J. 2020, 92, 30–42. [Google Scholar] [CrossRef]
- Roy, K.; Chaudhuri, S.S.; Pramanik, S. Deep learning based real-time Industrial framework for rotten and fresh fruit detection using semantic segmentation. Microsyst. Technol. 2021, 27, 3365–3375. [Google Scholar] [CrossRef]
- Wang, A.; Togo, R.; Ogawa, T.; Haseyama, M. Defect Detection of Subway Tunnels Using Advanced U-Net Network. Sensors 2022, 22, 2330. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wang, E.; Zhu, Y. Image segmentation evaluation: A survey of methods. Artif. Intell. Rev. 2020, 53, 5637–5674. [Google Scholar] [CrossRef]
- Taha, A.A.; Hanbury, A. Metrics for evaluating 3D medical image segmentation: Analysis, selection, and tool. BMC Med. Imaging 2015, 15, 29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yao, A.D.; Cheng, D.L.; Pan, I.; Kitamura, F. Deep Learning in Neuroradiology: A Systematic Review of Current Algorithms and Approaches for the New Wave of Imaging Technology. Radiol. Artif. Intell. 2020, 2, e190026. [Google Scholar] [CrossRef]
- Ding, L.; Goshtasby, A. On the Canny edge detector. Pattern Recognit. 2001, 34, 721–725. [Google Scholar] [CrossRef]
- Vincent, O.R.; Folorunso, O. A Descriptive Algorithm for Sobel Image Edge Detection. In Proceedings of the Informing Science & IT Education Conference, Macon, GA, USA, 12–15 June 2009; pp. 1–11. [Google Scholar]
- Burney, S.M.A.; Tariq, H. K-Means Cluster Analysis for Image Segmentation. Int. J. Comput. Appl. 2014, 96, 1–8. [Google Scholar]
- Dhanachandra, N.; Manglem, K.; JinaChanu, Y. Image Segmentation Using K-means Clustering Algorithm and Subtractive Clustering Algorithm. Procedia Comput. Sci. 2015, 54, 764–771. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Lei, Q.; Yao, R.; Gong, Y.; Yin, Q. Image segmentation based on adaptive K-means algorithm. EURASIP J. Image Video Process. 2018, 68, 1–10. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar] [CrossRef] [Green Version]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Ma, J.; Chen, J.; Ng, M.; Huang, R.; Li, Y.; Li, C.; Yang, X.; Martel, A.L. Loss odyssey in medical image segmentation. Med. Image Anal. 2021, 71, 102035. [Google Scholar] [CrossRef]
- Qian, S.; Lian, D.; Zhao, B.; Liu, T.; Zhu, B.; Li, H.; Gao, S. KGDet: Keypoint-Guided Fashion Detection. Proc. Aaai Conf. Artif. Intell. 2021, 35, 2449–2457. [Google Scholar]
- Lu, Y. Automatically Measure Your Clothes on a Smartphone with AR, Mercari Engineering. 2022. Available online: https://engineering.mercari.com/en/blog/entry/2020-06-19-150222/ (accessed on 5 January 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UNet Model | Pretraining Dataset |
|---|---|
| UNet | DeepFashion2+ our dataset |
| UNet | Carvana + our dataset |
| UNet | our dataset |
| UNet 128 × 128 | our dataset |
| UNet 256 × 256 | our dataset |
| UNet 512 × 512 | our dataset |
| With Augmentation | Without Augmentation | |||
|---|---|---|---|---|
| UNet Model | MAX Dice | AVG Dice | MAX Dice | AVG Dice |
| UNet | 0.918 | 0.804 | 0.919 | 0.852 |
| UNet (DeepFashion2) | 0.906 | 0.857 | 0.825 | 0.824 |
| UNet (Carvana) | 0.891 | 0.835 | 0.879 | 0.827 |
| UNet 128 × 128 | 0.979 | 0.917 | 0.943 | 0.899 |
| UNet 256 × 256 | 0.976 | 0.818 | 0.922 | 0.818 |
| UNet 512 × 512 | 0.971 | 0.865 | 0.906 | 0.855 |
| Total Length | Waist | Shoulders | Sleeves | Average Error | |
|---|---|---|---|---|---|
| Dresses | 1.113 | 0.343 | 0.783 | - | 0.747 |
| Blazers | 0.903 | - | 1.826 | 0.652 | 1.127 |
| Skirts | 1.650 | 0.421 | - | - | 1.012 |
| Model | MSE Loss | Dice | Dice Loss | RMSE |
|---|---|---|---|---|
| MobileNetV2 (fixed) | 0.032 | 0.944 | 0.056 | 0.186 |
| ResNet50 (fixed) | 0.032 | 0.948 | 0.052 | 0.181 |
| MobileNetV2 | 0.009 | 0.985 | 0.015 | 0.095 |
| ResNet50 | 0.022 | 0.962 | 0.038 | 0.150 |
| DeepPose | 0.039 | 0.935 | 0.065 | 0.199 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paulauskaite-Taraseviciene, A.; Noreika, E.; Purtokas, R.; Lagzdinyte-Budnike, I.; Daniulaitis, V.; Salickaite-Zukauskiene, R. An Intelligent Solution for Automatic Garment Measurement Using Image Recognition Technologies. Appl. Sci. 2022, 12, 4470. https://0-doi-org.brum.beds.ac.uk/10.3390/app12094470
Paulauskaite-Taraseviciene A, Noreika E, Purtokas R, Lagzdinyte-Budnike I, Daniulaitis V, Salickaite-Zukauskiene R. An Intelligent Solution for Automatic Garment Measurement Using Image Recognition Technologies. Applied Sciences. 2022; 12(9):4470. https://0-doi-org.brum.beds.ac.uk/10.3390/app12094470
Chicago/Turabian StylePaulauskaite-Taraseviciene, Agne, Eimantas Noreika, Ramunas Purtokas, Ingrida Lagzdinyte-Budnike, Vytautas Daniulaitis, and Ruta Salickaite-Zukauskiene. 2022. "An Intelligent Solution for Automatic Garment Measurement Using Image Recognition Technologies" Applied Sciences 12, no. 9: 4470. https://0-doi-org.brum.beds.ac.uk/10.3390/app12094470