

PDF Malware Detection Based on Fuzzy Unordered Rule Induction Algorithm (FURIA)

College of Engineering, Alfaisal University, Riyadh 11533, Saudi Arabia
*
Author to whom correspondence should be addressed.
Appl. Sci. 2023, 13(6), 3980; https://0-doi-org.brum.beds.ac.uk/10.3390/app13063980
Submission received: 7 February 2023
/
Revised: 6 March 2023
/
Accepted: 9 March 2023
/
Published: 21 March 2023
(This article belongs to the Special Issue Advances in Cybersecurity: Challenges and Solutions)
Abstract
:The number of cyber-attacks is increasing daily, and attackers are coming up with new ways to harm their target by disseminating viruses and other malware. With new inventions and technologies appearing daily, there is a chance that a system might be attacked and its weaknesses taken advantage of. Malware is distributed through Portable Document Format (PDF) files, among other methods. These files’ adaptability makes them a prime target for attackers who can quickly insert malware into PDF files. This study proposes a model based on the Fuzzy Unordered Rule Induction Algorithm (FURIA) to detect PDF malware. The proposed model outperforms currently used methods in terms of reducing error rates and increasing accuracy. Other models, such as Naïve Bayes (NB), Decision Tree (J48), Hoeffding Tree (HT), and Quadratic Discriminant Analysis (QDA), were compared to the proposed model. The accuracy achieved by the proposed model is 99.81%, with an error rate of 0.0022.
1. Introduction
Intelligent attacks utilizing documents with malicious codes have been increasing rapidly in recent years as file transfers expand. The majority of Internet users are aware of the risk posed by execution files that are attached to emails or web pages. However, because users are unaware of the documents, they serve as an effective means of spreading malware. Because Portable Document Format (PDF)s are more flexible than other document formats, they are one of the main attack vectors among the malware that has been identified. The majority of malicious PDF documents include JavaScript or binary scripts that exploit certain security flaws and carry out destructive deeds, as explained in [1]. On the internet, there are countless billions of PDF files. Not all of them are as benign as one might expect. In actuality, PDF files may include a variety of objects, including binary or JavaScript codes. These items might occasionally be harmful. Malware software could try to infect a computer by finding a reading weakness [2]. In 2017, Adobe Acrobat Reader was found to have sixty-eight vulnerabilities. There are about fifty of them that may be used to run arbitrary codes. Each reader has certain weaknesses, and a malicious PDF file may discover a method to exploit them [3].
1.1. Reason for the Selection of PDF Files
The PDF format is one of the most widely used file types for sharing digital documents between different platforms and applications. Refs. [4,5] contain a full description of the PDF standard. A few elements make PDFs one of the preferred file types for malware authors to disseminate dangerous content. (a) PDF is extensively utilized by people in both professional and social settings. Academic papers, technical reports, design documents, and electronic receipts are a few examples of typical instances; (b) PDF is independent of platforms and operating systems (OS). A standalone PDF reader or a modern web browser can be used to access a PDF file on a Windows PC, a Linux system, or a mobile device (with a PDF viewer plug-in); (c) it is a very versatile file format. In addition to text, PDF also allows other sorts of data, such as video files, interactive forms, links to other files, JavaScript, Flash, and unified resource locators (URLs). Additionally, different encoding and compression techniques can be utilized to reduce file size, conceal important material, or both; and (d) it is stealthy and sophisticated. In general, executable files are thought to be more dangerous than PDF files. Setting a policy to prohibit staff members from downloading executable files from the internet or including them in email attachments is a common security measure, but it is uncommon to do the same with PDF documents. The enormous ubiquity and adaptability of the PDF file format also provide attackers with several opportunities to spread malware through PDF documents.
1.2. PDF-Based Malware
Phishing and exploits are the two main types of PDF-based attacks. Phishing attempts frequently appear in emails. A typical instance is a PDF delivery or purchase confirmation receipt attached to an email that seems to be from a trustworthy online store or logistics company. Apart from the social engineering techniques used to persuade recipients to open phishing PDF attachments, the text content of such emails is largely meaningless. These PDF documents are typically one page long and include social engineering elements as well as a phishing URL that leads to a suspicious website where malicious downloads, personal data collection, and other activities can be carried out. In contrast to plain-text-based phishing efforts, PDF documents include binary or a blend of binary and ASCII languages, making them harder to detect. This is one of the factors contributing to the rise in the popularity of phishing attempts based on PDFs. Its motivation is identical to that of standard phishing scams. The information that attackers collect from victims may be used by them or may be sold on the illicit market for use in the so-called shadow economy [6].
The PDF file format is a popular option for use in offices because of its high efficiency, dependability, and interactivity. The development of non-executable file assault technologies and attack techniques such as the advanced persistent threat has seriously jeopardized PDF’s security since malicious PDF files are the most researched infection routes in adversarial scenarios [7,8]. With the development of machine learning (ML) technology [9] in recent years, researchers have developed a variety of ML-based techniques to recognize distinct attack types related to PDF files. The technology for detecting malicious PDF files may be divided into techniques based on static analysis, dynamic analysis, and techniques based on a combination of static and dynamic analyses. Modern research has demonstrated that PDF detectors based on ML may achieve excellent accuracy with a remarkably low false positive rate (FPR) [10]. However, such a study focuses on the proposed Fuzzy Unordered Rule Induction Algorithm (FURIA) for malware detection in PDF files compared with Naïve Bayes (NB), Decision Tree (J48), Hoeffding Tree (HT), and Quadratic Discriminant Analysis (QDA). These models are compared based on some of the well-known assessment measures, including accuracy (ACC), F-measure (FM), recall, precision, Matthew’s correlation coefficient (MCC), and mean absolute error (MAE). This study has two primary objectives:
- To propose a malware detection model that will protect the systems from any harmful activity caused by PDF malware;
- To compare the findings from the suggested and existing models in use to discover a better and more effective solution for PDF malware detection.
The main contributions of this study are summarized as follows:
- We propose a FURIA-based model for the PDF malware detection;
- We analyze the outcomes of the proposed model with four well-known ML models: NB, J48, HT, and QDA;
- We do several tests on the dataset available at: http://205.174.165.80/CICDataset/CICEvasivePDFMal2022/Dataset/ (accessed on 5 February 2023);
- We disclose the intuition of the experiments using MAE, ACC, FM, MCC, precision, and recall metrics.
2. Literature Review
Several studies have been conducted on PDF malware detection using various ML and deep learning (DL) models. The use of the Portable Document Format was explained by Reum et al. [11]. They provided a comprehensive study of the JavaScript content and structure found in the XML-embedded PDF. After that, they developed a range of features, including configuration and metadata such as file size, keywords, versions, and content features, as well as encoding strategies such as keywords, names, and JavaScript-readable strings. Due to the complexity of its features and the robustness of machine learning algorithms to small modifications, adversarial examples are challenging to construct. To reduce the possibility of adversarial assaults, they also develop a recognition model utilizing black-box-style models with structure and content properties. Utilizing observable robustness features, Chen et al. [12] described how to train robust PDF malware classifiers. For instance, a classifier must always recognize PDF malware as dangerous, no matter how many pages from benign forms are placed into the document. They show how to rigorously assess a malware classifier’s worst-case behavior concerning specific robustness characteristics.
ML techniques have been used to create classifiers for PDF malware in several projects. Wepawet [13] and PJScan [14] were two earlier efforts that concentrated on the harmful JavaScript that was included in PDF malware. These tools include a JavaScript code extractor and a classifier for malicious JavaScript that can be either dynamic or static. Recent PDF malware classifiers have concentrated on structural aspects of PDF files since not all PDF malware contains embedded JavaScript and because PDF malware developers have learned several ways to conceal JavaScript codes [15]. We aim to develop cutting-edge structural feature-based classifiers in this effort. There have been studies that specifically looked at the JavaScript codes in PDFs. Features based on functions, constants, objects, methods, and keywords, as well as lexical characteristics of JavaScript scripts, were established by Khitan et al. [16]. Zhang [5] also utilized elements from the PDF structure, entity characteristics, metadata information, and content statistics, along with JavaScript features, including the number of objects, number of pages, and stream filtering information. Based on the finding that malicious JavaScript functions differ from legitimate JavaScript functions, Liu et al. [17] presented a context-aware technique. This method opens the PDF file while monitoring suspicious behavior based on JavaScript statements by passing the original code as input to the “eval” function.
In [18], Smutz and Stavrou combined the PDF parser with a random forest classifier to identify fraudulent PDF files using information gleaned from document metadata and file structure. They looked into 202 features, including /Font and /JavaScript. According to Liu et al. [17], current protections against malicious PDFs are inadequate, prone to evasion, and too computationally costly to be utilized online. They recommended leveraging static and run-time features to identify JavaScript in context. A software engineering approach was used to provide a detection method based on behavioral differences in those systems since a PDF document acts identically on different platforms [19]. A malicious document, on the other hand, will act differently depending on the platform. According to Li et al. [20], the weakness of all harmful detection methods that extract JavaScript is their dependency on 3rd-party extraction tools that precisely follow the Acrobat standard. A bigger training dataset does not always result in improved detection, according to Scofield et al. [21], and very little research has been conducted to establish the minimal size of a dataset required to achieve high detection accuracy. As a consequence, ref. [21] proposes a dynamic analysis-based detection technique.
3. Research Methodology
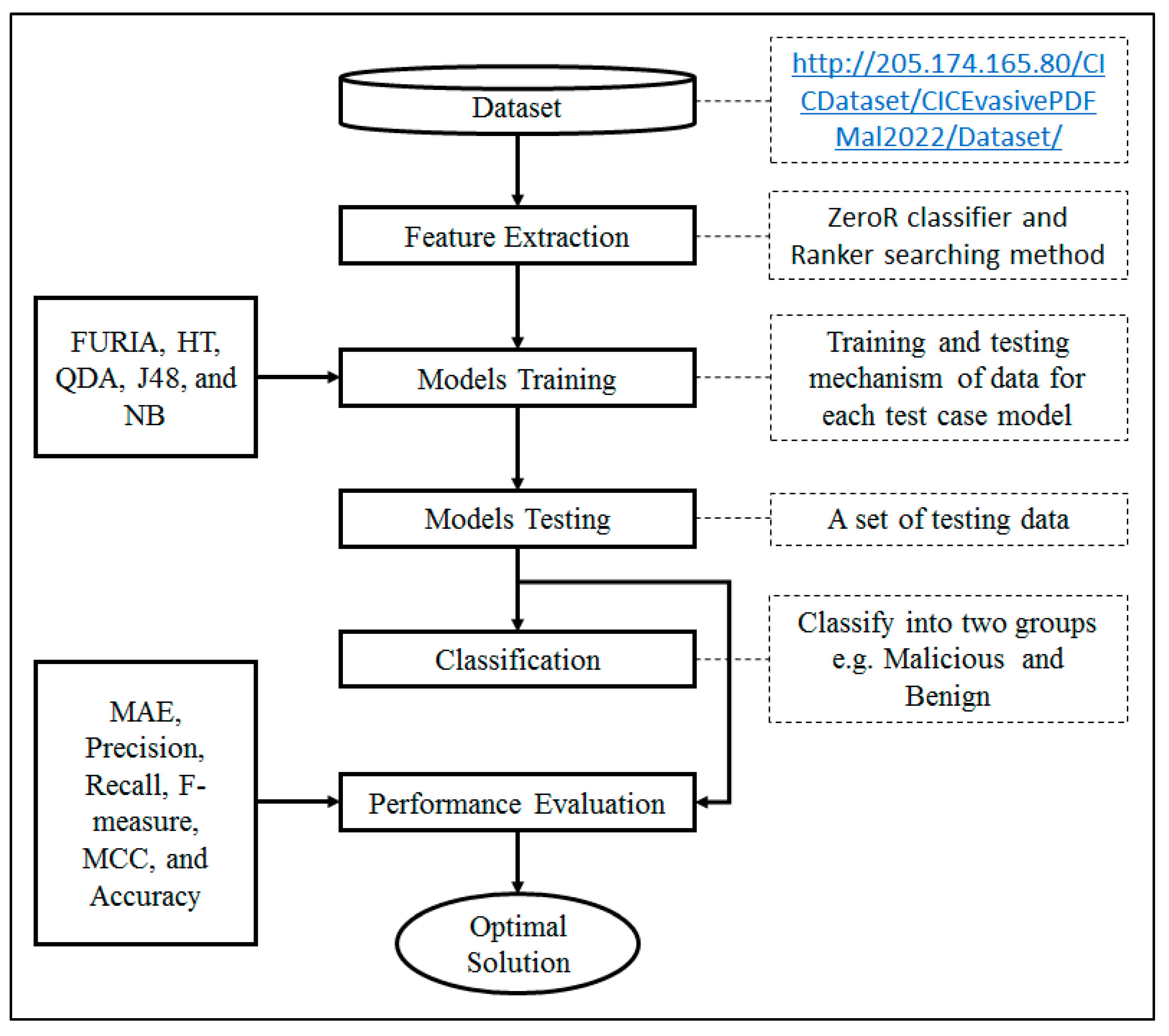
This study aims to develop a FURIA-based model for PDF malware detection. The overall research methodology is presented in Figure 1, which starts from data acquisition to comparison and performance analysis of each employed model. The dataset used in this study has been taken from the University of New Brunswick (UNB), Canadian Institute for Cybersecurity, http://205.174.165.80/CICDataset/CICEvasivePDFMal2022/Dataset/ (accessed on 5 February 2023). The dataset consists of 33 features, of which 32 are independent and 1 is dependent. The first 11 features are removed because they do not act in the analysis phase. These attributes are known as general features, including PDF size, metadata size, encryption, header, page number, text, image number, font objects, object number, number of embedded files, and the average size of all the embedded media. For extracting such features, we have used ClassifierAttributeEvaluator methods using a ZeroR classifier and the Ranker searching method. The selected features are ranked as follows:
Selected Features: 21,7,8,10,6,5,4,3,2,9,11,20,18,19,12,17,16,15,14,13,1:21.
These features are titled as: colors, startxref, pageno, ObjStm, trailer, xref, endstream, stream, endobj, encrypt, JS, XFA, launch, EmbeddedFile, Javascript, RichMedia, JBIG2Decode, Acroform, OpenAction, AA, and obj, respectively. Table 1 presents the description of each selected feature.
For model training and testing, a standard method of K-fold validation [23,24] is used. Here, the value of K is selected as 10. The performance of each employed model is evaluated using some of the standard evaluation metrics, including mean absolute error (MAE), recall, precision, Matthew’s correlation coefficient (MCC), FM, and classification ACC. These measures can be calculated as follows:
Here, the important thing is to discuss the use of MAE in this study. MAE is typically used as an evaluation metric in regression problems, where the goal is to predict a continuous numerical output. However, in some cases, MAE can also be used in classification problems to evaluate the performance of the classification model. In classification, the output is a categorical variable, so using MAE as the primary evaluation metric might not be as informative as other classification-specific metrics such as accuracy, precision, recall, F1-score, or AUC-ROC. These metrics provide a more detailed understanding of how well the model performs in terms of correctly identifying positive and negative examples. However, in some cases, using MAE in classification can provide additional insights into the model’s performance. In this scenario, MAE can be used to evaluate how far the predicted probabilities are from the true labels.
Fuzzy Unordered Rule Induction Algorithm (FURIA)
The FURIA is a new algorithm introduced by Huhn and Hullermeier that is responsible for generating fuzzy logic rules from a given database and classifying it using the obtained rules [22]. Fuzzy logic algorithms are well-known for their properties, such as classification rules that are simply understood by the reader, the capacity to analyze linguistic input, and the ability to enable expert judgment. They can also be used as a tool for classification purposes [25,26]. FURIA is the advanced version or derivative of the Repeated Incremental Pruning to Produce Error Reduction (RIPPER) algorithm. The RIPPER Algorithm is a classification algorithm based on rules. The training set is used to generate a set of rules. It is a famous rule induction algorithm. It generates fuzzy rules rather than traditional rules to replicate more flexible classification parameters. The fuzzy rules are constructed by substituting fuzzy intervals with a trapezoidal relevance function in association with the original RIPPER algorithm’s advanced rule induction approach [27].
It has an appealing feature, which is the rule’s extension. The generalization of the laws to include every option is the extension. It is a local technique that looks for information near the query. The simplest way to find the smallest generalization of a rule is to exclude those antecedents that are not met by the query [22]. The pseudo-code for a single rule, r, is shown in Algorithm 1 below, and the flowchart of FURIA is presented in Figure 2.
| Algorithm 1: Generation of single ruler [22]. |
| Let A be the set of numeric antecedents of r Compute the best fuzzification of A[i] in terms of purity |
4. Results, Analysis, and Discussion
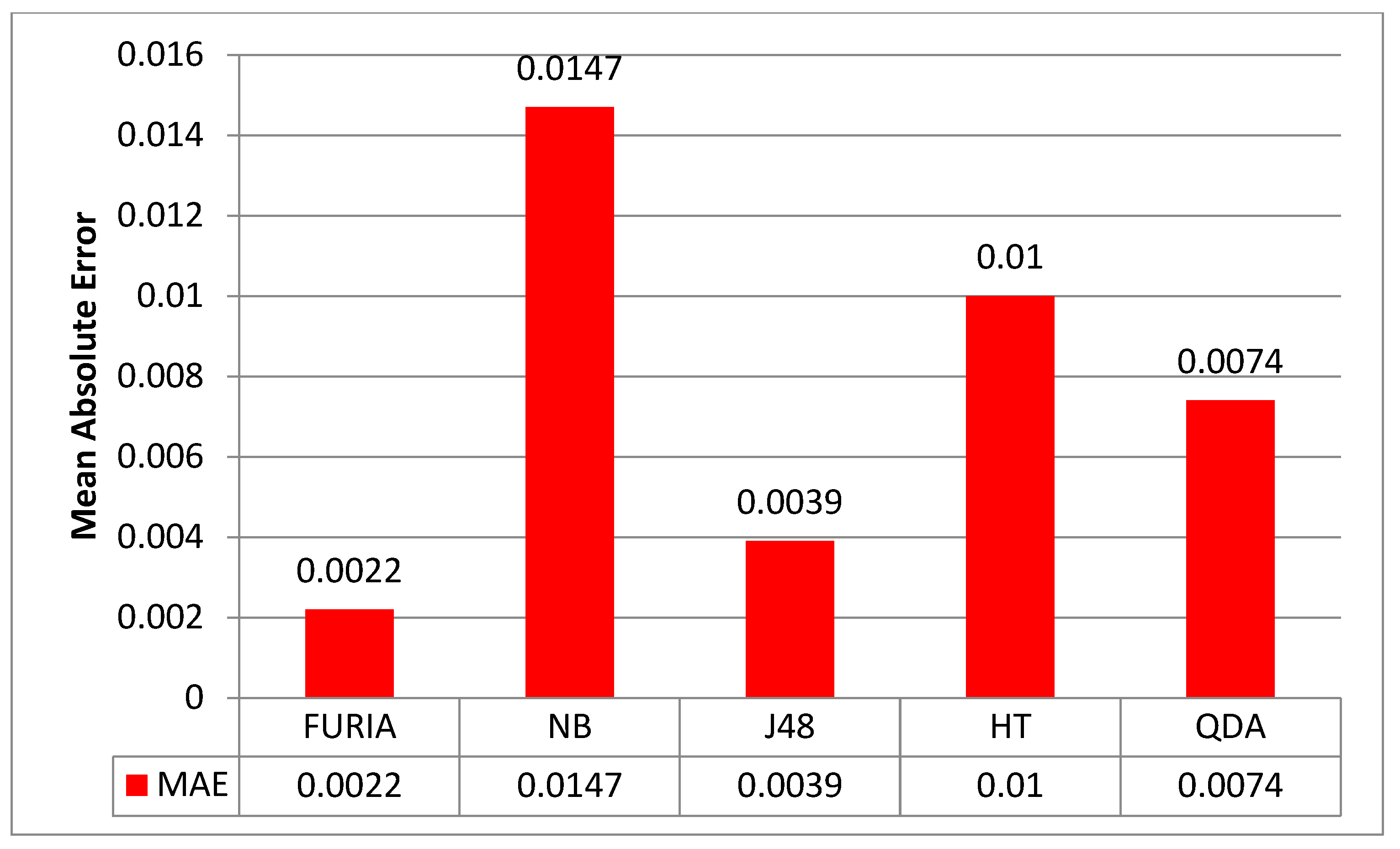
This section presents and discusses the study’s findings. A new model, namely FURIA, is presented for PDF malware detection. FURIA and other benchmarked models are evaluated using a variety of criteria, which are ACC, FM, MCC, MAE, recall, and precision. Figure 3 illustrates the true positive rate (TPR) and false positive rate (FPR) analyses of each model compared with the proposed model. These analyses show the better performance of the FURIA, with the lowest FPR and better TPR. In both situations, it can be found that NB shows the worst outcomes. Figure 4 illustrates the outcome assessed via MAE. The MAE analysis shows the better performance of the proposed model with the lowest error rate, which is 0.0022, and the worst performance of NB with an error rate of 0.0147. All these values are achieved using a confusion matrix. Confusion matrix values achieved via each model are presented in Table 2.
Figure 5 presents the outcomes assessed via precision, recall, and FM. These outcomes also depict the better performance of FURIA, with a value of 0.998 for precision, recall, and FM, respectively. The HT and QDA have the same outcomes of 0.993 for recall, precision, and FM, respectively, while the NB shows the poorest performance with a value of 0.985 individually for recall, precision, and FM.
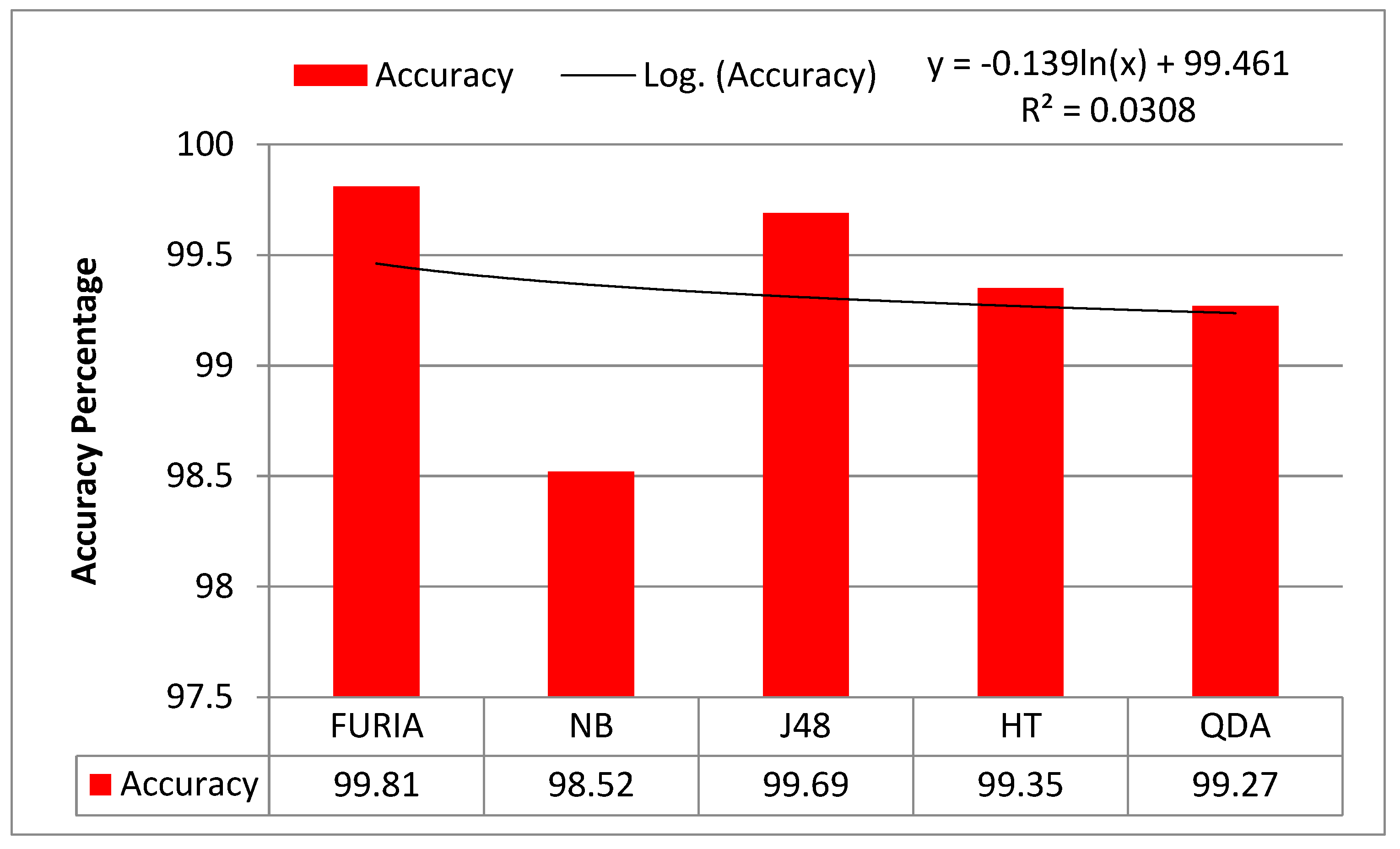
Figure 6 illustrates the evaluation of each model using R2, accuracy, and a logarithmic trendline. The logarithmic trendline, which is extremely useful when the rate of change in the data is rapidly increasing or falling and then leveling out, is the best-fit curved line. The positive and negative values can both appear on a logarithmic trendline [28]. It may be obtained as follows:
Here, “ln” is the natural logarithmic function, and a and b are constants in the equation. The following generic equations, which differ only in the most recent input, can be used to retrieve the constants:
R2, also known as the coefficient of determination, is a statistical measure that represents the proportion of variance in the dependent variable (or the outcome) that can be explained by the independent variable(s) (or the predictor(s)) in a regression model [28]. It can be calculated as:
R2 is consistently between 0% and 100%. The model does not take into consideration any fluctuation in the answer data around its mean, as shown by the 0%. 100% means that the model fully accounts for all the variability in the response data surrounding its meaning.
The properties of PDF encouraged hackers to take advantage of several security flaws and circumvent security measures, making the PDF format one of the most effective attack vectors for harmful malware. Therefore, it is essential for information security to accurately recognize malicious PDF files. To this end, this study proposes a model based on FURIA for PDF malware detection. According to the analysis described in the preceding section, the proposed FURIA performs better than other employed models in terms of increasing accuracy and reducing the error rate. The accuracy percentage difference (PD) between FURIA and other applied algorithms is shown in Figure 7. This analysis shows that there is very little difference between the proposed model and the J48, which is only 0.12%, while the difference between the proposed model and the NB is greater than other employed models, which show the poorest performance of the NB as compared to the proposed model. The value of PD can be obtained using Equation (11), where x1 represents the value of FURIA and x2 represents the value of other employed algorithms.
The advantage of using FURIA is that it works well on datasets with imbalanced class distributions. If a dataset has a large number of records and the majority of those records fall into one class but the remaining records fall into other classes, the dataset is said to have an unbalanced distribution of classes [22,28]. We also have an unbalanced distribution of the data in the dataset, which is why the performance of the projected model is better as compared with other employed models.
The data obtained from the UNB are used in all of the experiments. The rest of the algorithms in use are assessed using several common assessment metrics, such as MAE, precision, FM, recall, MCC, and accuracy, along with the proposed model. The models are trained and evaluated using the 10-fold cross-validation method. The threat now is that if the dataset is changed, the new results could outperform our analysis. The findings might potentially be affected by changing the criteria for data training and testing in place of the 10-fold cross-validation, for example, by using a percentage division. Another risk is that if a new algorithm is developed and it proves to be more effective than the one we now use, the results might be improved.
5. Conclusions and Future Direction
This study proposed a FURIA-based model for PDF malware detection. The proposed model is benchmarked with some of the well-known ML models, which are NB, J48, HT, and QDA. The performances of all these models are evaluated using some of the standard assessment measures that include MAE, ACC, FM, MCC, precision, and recall on the dataset taken from the UNB repository. The overall outcome presents a better performance of the proposed model, with an accuracy of 99.81% and a lowest error rate of 0.0022. FURIA outperforms other models; however, there are some limitations of FURIA. FURIA generates a large number of rules, which can make it difficult to understand and interpret the resulting model. This complexity can also lead to longer processing times and increased computational resources. Although fuzzy rules can be more interpretable than other machine learning models such as neural networks, they can still be difficult to interpret in complex data sets, which can limit their usefulness in some applications.
The FURIA-based model outperforms other well-known machine learning models for PDF malware detection; there are several potential future directions for research. There may be opportunities to refine the model further. For example, the model’s parameters could be further optimized, or new features could be added to improve the model’s performance. It may be beneficial to explore the potential benefits of combining the FURIA-based model with other ML models. Such hybrid models have the potential to improve the overall performance of the model.
Author Contributions
Writing—original draft, S.G.; Writing—review & editing, S.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research work is supported by Alfaisal University.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jeong, Y.S.; Woo, J.; Kang, A.R. Malware Detection on Byte Streams of PDF Files Using Convolutional Neural Networks. Secur. Commun. Netw. 2019, 2019, 8485365. [Google Scholar] [CrossRef] [Green Version]
- Cuan, B.; Damien, A.; Delaplace, C.; Valois, M. Malware detection in PDF files using machine learning. In Proceedings of the ICETE 2018—The 15th International Joint Conference on e-Business and Telecommunications, Warangal, India, 18–21 December 2018; Volume 2, pp. 412–419. [Google Scholar] [CrossRef]
- Falah, A.; Pokhrel, S.R.; Pan, L.; de Souza-Daw, A. Towards enhanced PDF maldocs detection with feature engineering: Design challenges. Multimed. Tools Appl. 2022, 81, 41103–41130. [Google Scholar] [CrossRef]
- Docs, A.D. Adobe. Available online: https://opensource.adobe.com/dc-acrobat-sdk-docs/ (accessed on 21 November 2022).
- Zhang, J. MLPdf: An Effective Machine Learning Based Approach for PDF Malware Detection. arXiv 2018, arXiv:1808.06991. [Google Scholar]
- Malware Analysis on PDF. Available online: https://scholarworks.sjsu.edu/etd_projects/683/ (accessed on 20 May 2019).
- Xu, W.; Qi, Y.; Evans, D. Automatically Evading Classifiers. In Proceedings of the 23rd Annual Network and Distributed System Security Symposium—NDSS ’16, San Diego, CA, USA, 21–24 February 2016; Volume 2016, pp. 21–24. [Google Scholar]
- Chakkaravarthy, S.S.; Sangeetha, D.; Vaidehi, V. A Survey on malware analysis and mitigation techniques. Comput. Sci. Rev. 2019, 32, 1–23. [Google Scholar] [CrossRef]
- Li, W.; Meng, W.; Tan, Z.; Xiang, Y. Design of multi-view based email classification for IoT systems via semi-supervised learning. J. Netw. Comput. Appl. 2019, 128, 56–63. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, X.; Shi, Z.; Zhang, R.; Xue, J.; Wang, Z. Boosting training for PDF malware classifier via active learning. Int. J. Intell. Syst. 2022, 37, 2803–2821. [Google Scholar] [CrossRef]
- Kang, A.R.; Jeong, Y.-S.; Kim, S.L.; Woo, J. Malicious PDF detection model against adversarial attack built from benign PDF containing javascript. Appl. Sci. 2019, 9, 4764. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wang, S.; She, D.; Jana, S. On training robust {PDF} malware classifiers. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 2343–2360. [Google Scholar]
- Cova, M.; Kruegel, C.; Vigna, G. Detection and analysis of drive-by-download attacks and malicious JavaScript code. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, CA, USA, 26 April 2010; pp. 281–290. [Google Scholar]
- Laskov, P.; Šrndić, N. Static detection of malicious JavaScript-bearing PDF documents. In Proceedings of the 27th Annual Computer Security Applications Conference, Orlando, FL, USA, 5–9 December 2011; pp. 373–382. [Google Scholar]
- Ryan, C. Automatic Re-Engineering of Software Using Genetic Programming; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2000. [Google Scholar]
- Khitan, S.J.; Hadi, A.; Atoum, J. PDF forensic analysis system using YARA. Int. J. Comput. Sci. Netw. Secur. 2017, 17, 77–85. [Google Scholar]
- Liu, D.; Wang, H.; Stavrou, A. Detecting malicious javascript in pdf through document instrumentation. In Proceedings of the 2014 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, Atlanta, GA, USA, 23–26 June 2014; pp. 100–111. [Google Scholar]
- Smutz, C.; Stavrou, A. Malicious PDF detection using metadata and structural features. In Proceedings of the 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 7 December 2012; pp. 239–248. [Google Scholar]
- Xu, M.; Kim, T. {PlatPal}: Detecting Malicious Documents with Platform Diversity. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, USA, 16–18 August 2017; pp. 271–287. [Google Scholar]
- Li, M.; Liu, Y.; Yu, M.; Li, G.; Wang, Y.; Liu, C. FEPDF: A robust feature extractor for malicious PDF detection. In Proceedings of the 2017 IEEE Trustcom/BigDataSE/ICESS, Sydney, Australia, 1–4 August 2017; pp. 218–224. [Google Scholar]
- Scofield, D.; Miles, C.; Kuhn, S. Fast model learning for the detection of malicious digital documents. In Proceedings of the 7th Software Security, Protection, and Reverse Engineering/Software Security and Protection Workshop, San Juan, Puerto Rico, 4–5 December 2017; pp. 1–8. [Google Scholar]
- Hühn, J.; Hüllermeier, E. FURIA: An algorithm for unordered fuzzy rule induction. Data Min. Knowl. Discov. 2009, 19, 293–319. [Google Scholar] [CrossRef] [Green Version]
- Naseem, R.; Khan, B.; Ahmad, A.; Almogren, A.; Jabeen, S.; Hayat, B.; Shah, M.A. Investigating Tree Family Machine Learning Techniques for a Predictive System to Unveil Software Defects. Complexity 2020, 2020, 6688075. [Google Scholar] [CrossRef]
- Khan, B.; Naseem, R.; Shah, M.A.; Wakil, K.; Khan, A.; Uddin, M.I.; Mahmoud, M. Software Defect Prediction for Healthcare Big Data: An Empirical Evaluation of Machine Learning Techniques. J. Healthc. Eng. 2021, 2021, 8899263. [Google Scholar] [CrossRef] [PubMed]
- Gasparovica, M.; Aleksejeva, L. Using Fuzzy Unordered Rule Induction Algorithm for cancer data classification. Breast Cancer 2011, 13, 1229. [Google Scholar]
- Soares, E.; Damascena, L.; Lima, L.M.; Moraes, R.M.D. Analysis of the Fuzzy Unordered Rule Induction Algorithm as a Method for Classification. In Proceedings of the Conference: V Congresso Brasileiro de Sistemas Fuzzy, Fortaleza, Brasil, 4–6 July 2018; pp. 4–6. [Google Scholar]
- Verma, L.; Srivastava, S.; Negi, P.C. Transactional Processing Systems A Hybrid Data Mining Model to Predict Coronary Artery Disease Cases Using Non-Invasive Clinical Data. J. Med. Syst. 2016, 40, 178. [Google Scholar] [CrossRef] [PubMed]
- Ukanova, Z.M.; Udun, K.G.; Lemessova, Z.E.; Hamkhash, L.K.; Alchenko, E.R.; Ukasov, R.B. Detection of Paracetamol in Water and Urea in Artificial Urine with Gold Nanoparticle @Al Foil Cost-efficient SERS Substrate. Anal. Sci. 2018, 34, 183–187. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Figure 1.
Methodology workflow [22].
Figure 1.
Methodology workflow [22].

Figure 2.
FURIA algorithm flowchart [22].
Figure 2.
FURIA algorithm flowchart [22].

Figure 3.
TPR and FPR analysis of each model.

Figure 4.
Proposed model comparison based on MAE.

Figure 5.
Models comparison based on precision, recall, and F-measure.

Figure 6.
Accuracy analysis through each employed model.

Figure 7.
Accuracy percentage difference between FURIA and other employed models.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Selected features with their descriptions.
| S No. | Feature | Description |
|---|---|---|
| 1 | Obj | This might be a sign of an attempt to obfuscate. |
| 2 | endobj | Many other forms of obfuscations are supported by PDFs, including string obfuscations in hex, octal, etc. that are typically used for evasion efforts. |
| 3 | Stream | This represents the quantity of binary data sequences in the PDF. |
| 4 | Endstream | Keywords that signify the streams’ termination. |
| 5 | Xref | Size of the stream because streams may include a dangerous code. |
| 6 | Trailer | How many trailers there are in the PDF. |
| 7 | Startxref | How many keywords include “startxref,” which designates the location where the Xref table is begun. |
| 8 | Pageno | Because malicious PDF files do not care how their material is presented, they often contain fewer pages—often only one blank page. |
| 9 | Encrypt | This function indicates if a PDF file is password-protected or not. |
| 10 | Objstm | streams with other items in them. |
| 11 | JS | The proportion of Javascript-containing objects. |
| 12 | Javascript | This indicates the amount of items that include a Javascript code, the most often used feature, as is clear. |
| 13 | AA | specifies a particular response to an event. |
| 14 | OpenAction | Defines a specific action to be taken when the PDF file is opened. The bulk of common malicious PDF files have been found to use this functionality in conjunction with Javascript. |
| 15 | Acroform | Form fields in Acrobat forms, which are PDF files, offer scripting technology that may be abused by hackers. |
| 16 | JBIG2Decode | A popular filter for encoding harmful stuff is JBig2Decode. How many items have nested filters? Nested filters can make decoding more challenging and may be an indicator of evasion. |
| 17 | Richmeddia | The quantity of flash files and embedded media is indicated by the number of RichMedia keywords. |
| 18 | Launch | A command or program can be run by using the term launch. |
| 19 | EmbeddedFile | PDFs can attach or embed a variety of things inside themselves that may be exploited, such as additional PDF files, Word documents, pictures, etc. |
| 20 | XFA | Certain PDF 40 files contain XFAs, which are XML Form Architectures that offer scripting technologies that can be abused by attackers. |
| 21 | Color | In the PDF, many colors are utilized. |
| 22 | Class | Classify as malicious or benign. |
Table 2.
Confusion matrix values achieved via each employed model.
| Models | No | Yes | |
|---|---|---|---|
| FURIA | no | 8995 | 11 |
| yes | 27 | 10,953 | |
| NB | no | 8807 | 199 |
| yes | 97 | 10,883 | |
| J48 | no | 8977 | 29 |
| yes | 33 | 10,947 | |
| HT | no | 8943 | 63 |
| yes | 67 | 10,913 | |
| QDA | no | 8942 | 64 |
| yes | 82 | 10,898 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Mejjaouli, S.; Guizani, S. PDF Malware Detection Based on Fuzzy Unordered Rule Induction Algorithm (FURIA). Appl. Sci. 2023, 13, 3980. https://0-doi-org.brum.beds.ac.uk/10.3390/app13063980
AMA Style
Mejjaouli S, Guizani S. PDF Malware Detection Based on Fuzzy Unordered Rule Induction Algorithm (FURIA). Applied Sciences. 2023; 13(6):3980. https://0-doi-org.brum.beds.ac.uk/10.3390/app13063980
Chicago/Turabian StyleMejjaouli, Sobhi, and Sghaier Guizani. 2023. "PDF Malware Detection Based on Fuzzy Unordered Rule Induction Algorithm (FURIA)" Applied Sciences 13, no. 6: 3980. https://0-doi-org.brum.beds.ac.uk/10.3390/app13063980
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.