


Enhancing Spatial Debris Material Classifying through a Hierarchical Clustering-Fuzzy C-Means Integration Approach
Abstract
:1. Introduction
2. HAC-FCM Algorithm Establishment
3. Acquisition of Spectral Polarization Information
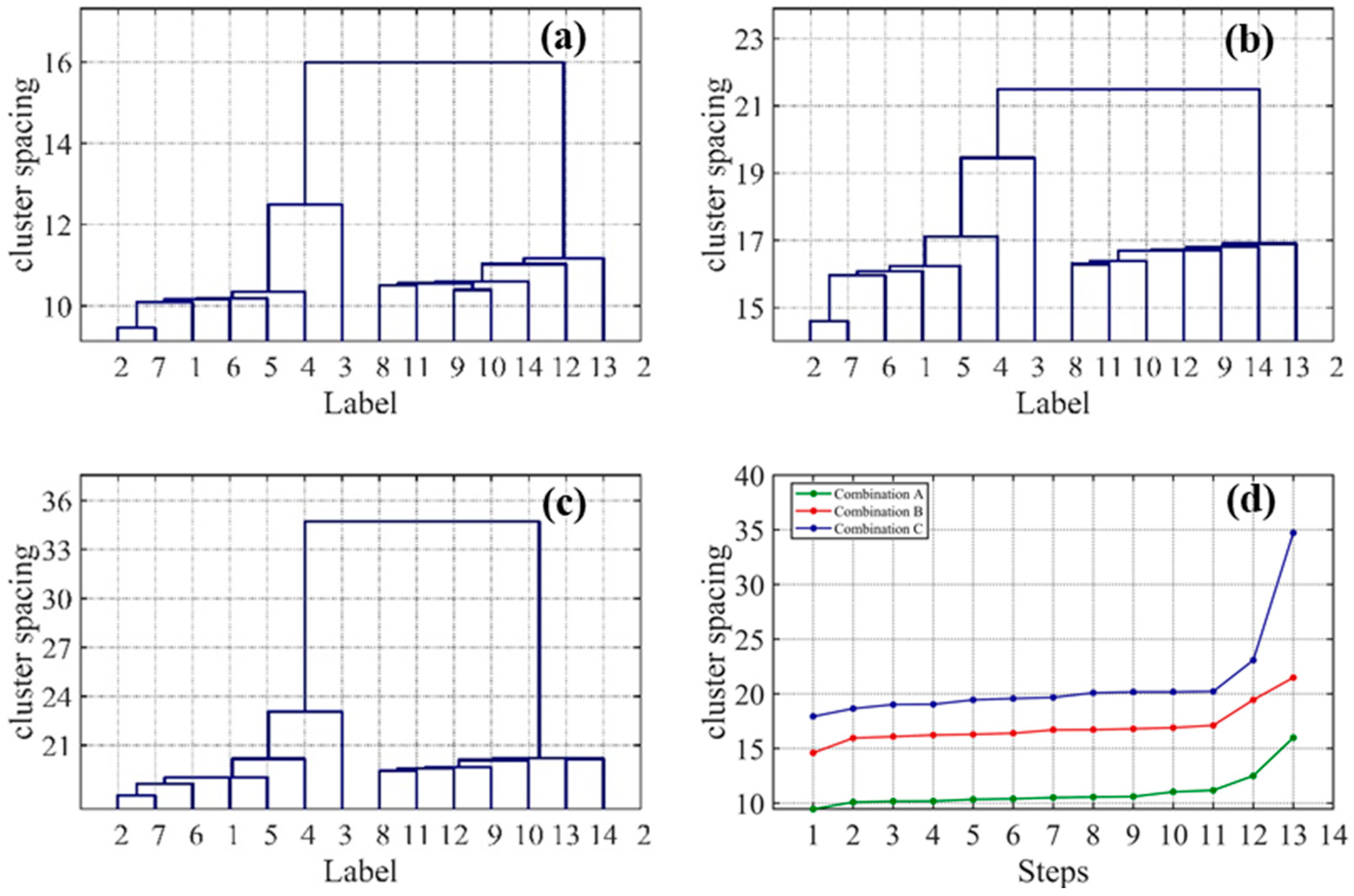
4. Results and Discussion
4.1. Clustering of Spectral Polarization Data
4.2. Spectral Polarization Image Clustering Rendering
4.2.1. Random Point Clustering of Spectral Polarization Images
4.2.2. Spectral Polarization Image Rendering
5. Discussion and Operational Applications
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liou, J.C. USA Space Debris Environment, Operations, and Research Updates. In Proceedings of the 53rd Session of the Scientific and Technical Subcommittee Committee on the Peaceful Uses of Outer Space, United Nations, Vienna, Austria, 15–26 February 2016. [Google Scholar]
- Jahirabadkar, S.; Pande, P.; R., A. A Survey on Image Processing based Techniques for Space Debris Detection. In Proceedings of the 2022 IEEE Bombay Section Signature Conference (IBSSC), Mumbai, India, 8–10 December 2022; pp. 1–6. [Google Scholar]
- Jiang, C.; Tan, Y.; Qu, G.; Lv, Z.; Gu, N.; Lu, W.; Zhou, J.; Li, Z.; Xu, R.; Wang, K.; et al. Super diffraction limit spectral imaging detection and material type identification of distant space objects. Opt. Express 2022, 30, 46911–46925. [Google Scholar] [CrossRef] [PubMed]
- Tapia, S.; Beavers, W.I.; Cho, Y.K. Photopolarimetric observations of satellites. Proc. SPIE 1990, 1317, 252–262. [Google Scholar]
- Culp, R.D.; Gravseth, I.J. Space-debris identification using optical calibration of common spacecraft materials. J. Spacecr. Rocket. 2015, 33, 262–266. [Google Scholar] [CrossRef]
- Ratliff, B.M.; Lemaster, D.A.; Mack, R.T.; Villeneuve, P.V.; Weinheimer, J.J.; Middendorf, J.R. Detection and tracking of RC model aircraft in LWIR microgrid polarimeter data. In Polarization Science and Remote Sensing V; SPIE: Bellingham, WA, USA, 2011. [Google Scholar]
- Namer, E.; Shwartz, S.; Schechner, Y.Y. Skyless polarimetric calibration and visibility enhancement. Opt. Express 2009, 17, 472–493. [Google Scholar] [CrossRef] [Green Version]
- Chun, C.S.L.; Sadjadi, F.A. Polarimetric laser radar target classification. Opt. Lett. 2005, 30, 1806–1808. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, J.; Zong, K.; Huang, L.; Zhai, L.; Zhang, Y.; Wang, H.; Zhang, N.; Cai, Y. Exact optical path difference and complete performance analysis of a spectral zooming imaging spectrometer. Opt. Express 2022, 30, 39479–39491. [Google Scholar] [CrossRef]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.P.; Tiwari, A.; Er, M.J.; Ding, W.; Lin, C. A review of clustering techniques and developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef] [Green Version]
- Tao, Z.; Huiling, L. Clustering algorithm research advances on data mining. Comput. Eng. Appl. 2012, 48, 100–111. [Google Scholar]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Plenum Press: New York, NY, USA, 1981. [Google Scholar]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci.-UK 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Askari, S. Fuzzy C-Means clustering algorithm for data with unequal cluster sizes and contaminated with noise and outliers: Review and development. Expert Syst. Appl. 2021, 165, 113856. [Google Scholar] [CrossRef]
- Havens, T.C.; Bezdek, J.C.; Leckie, C.; Hall, L.O.; Palaniswami, M. Fuzzy c-Means Algorithms for Very Large Data. IEEE T. Fuzzy Syst. 2012, 20, 1130–1146. [Google Scholar] [CrossRef]
- Ji, B.; Hu, X.; Ding, F.; Ji, Y.; Gao, H. An effective color image segmentation approach using superpixel-neutrosophic C-means clustering and gradient-structural similarity. Optik 2022, 260, 169039. [Google Scholar] [CrossRef]
- Wu, C.; Peng, S. Robust interval type-2 kernel-based possibilistic fuzzy clustering algorithm incorporating local and non-local information. Adv. Eng. Softw. 2023, 176, 103377. [Google Scholar] [CrossRef]
- Bentabet, L.; Zhu, Y.M.; Dupuis, O.; Kaftandjian, V.; Babot, D.; Rombaut, M. Use of fuzzy clustering for determining mass functions Dempster-Shafer theory. In 2000 5th International Conference on Signal Processing Proceedings, Vols I–III; Baozong, Y., Xiaofang, T., Eds.; IEEE: New York, NY, USA, 2000; pp. 1462–1470. [Google Scholar]
- Xu, W.; Tang, C.; Xu, M.; Lei, Z. Fuzzy c-means clustering based segmentation and the filtering method for discontinuous ESPI fringe patterns. Appl. Opt. 2019, 58, 1442–1450. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Guo, X. A novel interval-valued data driven type-2 possibilistic local information c-means clustering for land cover classification. Int. J. Approx. Reason. 2022, 148, 80–116. [Google Scholar] [CrossRef]
- Yang, L.; Zenian, S.; Zakaria, R. Image Enhancement Method based on an Improved Fuzzy C-Means Clustering. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 855–859. [Google Scholar] [CrossRef]
- Wen, Y.; He, L.; Von Deneen, K.M.; Lu, Y. Brain tissue classification based on DTI using an improved Fuzzy C-means algorithm with spatial constraints. Magn. Reson. Imaging 2013, 31, 1623–1630. [Google Scholar] [CrossRef]
- Al-Saeed, Y.; Gab-Allah, W.A.; Elmogy, M. Fuzzy C-Means Based CAD Sytem for Liver Tumors Segmentation from CT Scans. In Proceedings of the 2022 18th International Computer Engineering Conference (ICENCO), Cairo, Egypt, 29 December 2022; Volume 1, pp. 44–49. [Google Scholar]
- Mohammdian-Khoshnoud, M.; Soltanian, A.R.; Farhadian, M.; Dehghan, A. Optimization of fuzzy c-means (FCM) clustering in cytology image segmentation using the gray wolf algorithm. BMC Mol. Cell Biol. 2022, 23, 9. [Google Scholar] [CrossRef]
- Mabel Rani, A.J.; Pravin, A. Multi-objective Hybrid Fuzzified PSO and Fuzzy C-Means Algorithm for Clustering CDR Data. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019. [Google Scholar]
- Zhao, W.; Ma, J.; Liu, Q.; Song, J.; Tysklind, M.; Liu, C.; Wang, D.; Qu, Y.; Wu, Y.; Wu, F. Comparison and application of SOFM, fuzzy c-means and k-means clustering algorithms for natural soil environment regionalization in China. Environ. Res. 2023, 216, 114519. [Google Scholar] [CrossRef]
- Li, S.; Zhang, J.; Liu, B.; Jiang, C.; Ren, L.; Xue, J.; Song, Y. An Algorithm to Extract the Boundary and Center of EUV Solar Image Based on Sobel Operator and FLICM. Photonics 2022, 9, 889. [Google Scholar] [CrossRef]
- Bi, S.; Li, Y.; Xu, J.; Liu, G.; Song, K.; Mu, M.; Lyu, H.; Miao, S.; Xu, J. Optical classification of inland waters based on an improved Fuzzy C-Means method. Opt. Express 2019, 27, 34838. [Google Scholar] [CrossRef] [PubMed]
- Younès, B.; Mohamad, G.; Nistor, G. Collaborative multi-view clustering. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013. [Google Scholar]
- Ghassany, M.; Bennani, Y. Collaborative Fuzzy Clustering of Variational Bayesian Generative Topographic Mapping. Int. J. Comput. Intell. Appl. 2015, 14, 1. [Google Scholar] [CrossRef]
- Pedrycz, W. Conditional fuzzy C-means. Pattern Recogn. Lett. 1996, 17, 625–631. [Google Scholar] [CrossRef]
- Pedrycz, W.; Hirota, K. A consensus-driven fuzzy clustering. Pattern Recogn. Lett. 2008, 29, 1333–1343. [Google Scholar] [CrossRef]
- Roh, S.; Oh, S.; Pedrycz, W.; Seo, K.; Fu, Z. Design methodology for Radial Basis Function Neural Networks classifier based on locally linear reconstruction and Conditional Fuzzy C-Means clustering. Int. J. Approx. Reason. 2019, 106, 228–243. [Google Scholar] [CrossRef]
- Ding, Y.; Fu, X. Kernel-based fuzzy c-means clustering algorithm based on genetic algorithm. Neurocomputing 2016, 188, 233–238. [Google Scholar] [CrossRef]
- Ding, W.; Feng, Z.; Andreu-Perez, J.; Pedrycz, W. Derived Multi-population Genetic Algorithm for Adaptive Fuzzy C-Means Clustering. Neural Process. Lett. 2022. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. Wires. Data Min. Knowl. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Govender, P.; Sivakumar, V. Application of k-means and hierarchical clustering techniques for analysis of air pollution: A review (1980–2019). Atmos. Pollut. Res. 2020, 11, 40–56. [Google Scholar] [CrossRef]
- Ran, X.; Xi, Y.; Lu, Y.; Wang, X.; Lu, Z. Comprehensive survey on hierarchical clustering algorithms and the recent developments. Artif. Intell. Rev. Int. Sci. Eng. J. 2022, 1–46. [Google Scholar] [CrossRef]
- Dinh, D.; Fujinami, T.; Huynh, V. Estimating the Optimal Number of Clusters in Categorical Data Clustering by Silhouette Coefficient; Springer Singapore Pte. Limited: Singapore, 2019; Volume 1103, pp. 1–17. [Google Scholar]
- Priest, R.G.; Gerner, T.A. Polarimetric BRDF in the Microfacet Model: Theory and Measurements. In Proceedings of the Meeting of the Military Sensing Symposia Specialty Group on Passive Sensors, Ann Arbor, MI, USA, 1 March 2000. [Google Scholar]
- Hyde, M.T.; Schmidt, J.D.; Havrilla, M.J.; Cain, S.C. Enhanced material classification using turbulence-degraded polarimetric imagery. Opt. Lett. 2010, 35, 3601–3603. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Zhu, J.; Liu, H.; Du, B. Expression of the degree of polarization based on the geometrical optics pBRDF model. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 2017, 34, 259–263. [Google Scholar] [CrossRef] [PubMed]
- Hyde, M.T.; Schmidt, J.D.; Havrilla, M.J. A geometrical optics polarimetric bidirectional reflectance distribution function for dielectric and metallic surfaces. Opt. Express 2009, 17, 22138–22153. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning | Symbol | Meaning |
|---|---|---|---|
| δ | scaling factor | k | the number of iteration steps |
| ε | termination criterion | K | the set of cluster indices |
| cj | center of the j cluster | m | operation’s index |
| C | cluster center matrix | N | initial data points |
| dist | distance metric function | t | the number of clusters |
| i | index variables | uij | the degree value of the j cluster that completely contains the i sample vector |
| j | index variables | U | the degree matrix of the initial sample |
| J | objective function | Xi | the data point for the index value |
| Algorithm | Total Points | Correct Points | Recognition Rates |
|---|---|---|---|
| K-means | 726 | 551 | 75.90% |
| HAC | 726 | 604 | 83.20% |
| Ours | 726 | 726 | 100% |
| Material | Silver Insulation | Golden Insulation | SR107/S781 | Aluminum Block | Iron Sheets | Background Material | Total |
|---|---|---|---|---|---|---|---|
| error points | 1 | 0 | 605 | 1314 | 3 | 0 | 1923 |
| false alarm rate | 0.0487% | 0 | 13.67% | 39.31% | 0.12% | 0 | 3.08% |
| recognition rates | 77.73% | 69.71% | 86.60% | 100% | 100% | 100% | 96.92% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, F.; Zhu, J.; Huang, L.; Li, H.; Deng, J.; Jiang, H.; Hou, X. Enhancing Spatial Debris Material Classifying through a Hierarchical Clustering-Fuzzy C-Means Integration Approach. Appl. Sci. 2023, 13, 4754. https://0-doi-org.brum.beds.ac.uk/10.3390/app13084754
Guo F, Zhu J, Huang L, Li H, Deng J, Jiang H, Hou X. Enhancing Spatial Debris Material Classifying through a Hierarchical Clustering-Fuzzy C-Means Integration Approach. Applied Sciences. 2023; 13(8):4754. https://0-doi-org.brum.beds.ac.uk/10.3390/app13084754
Chicago/Turabian StyleGuo, Fengqi, Jingping Zhu, Liqing Huang, Haoxiang Li, Jinxin Deng, Huilin Jiang, and Xun Hou. 2023. "Enhancing Spatial Debris Material Classifying through a Hierarchical Clustering-Fuzzy C-Means Integration Approach" Applied Sciences 13, no. 8: 4754. https://0-doi-org.brum.beds.ac.uk/10.3390/app13084754