1. Introduction
The manufacturing industry is an important embodiment of national strength and an important force supporting the sustained growth of the global economy. The rapid development of the new generation of information technology and advanced manufacturing technology has brought an opportunity for the transformation of the traditional manufacturing industry. At present, more and more intelligent manufacturing elements have appeared in the manufacturing industry [
1,
2]. The emergence of the computer numerically controlled (CNC) machine tool has fundamentally changed the pattern of the manufacturing industry. The CNC machine tool is widely used in the manufacturing industry with its advantages of high precision, high efficiency, and high reliability. With the increasing requirements on processing efficiency and product quality, improving the processing performance and accuracy of CNC machine tools has become an urgent problem to be solved [
3,
4,
5]. The CNC system is composed of a variety of functional modules, is the key to the normal operation of the machine tool control system, is affected by many factors in the processing process, and its stability directly determines the working state of the entire machine tool [
6]. Unpredictable changes in the machining operating environment will often lead to unexpected equipment failures, which will lead to a decline in the overall reliability of the equipment, so the use of appropriate strategies to predict and identify machine tool failures and healthy management of the operating state of the machine tool are important prerequisites for ensuring the productivity and reliability of CNC machine tools.
Prediction and health management (PHM) is a cutting-edge integrated technology, which can predict the future health state of the system based on information such as system performance, control, and operation and maintenance knowledge and data to dynamically support improved operation and maintenance decisions [
7]. Over the past decade, PHM has undergone intense research and flourished, becoming a popular interdisciplinary field in academia and industry, involving mathematics, computer science, communications, physics, chemistry, materials science, operations research, engineering, and other disciplines. In the fields of aerospace, energy, civil, chemical, process, and industrial engineering and transportation and manufacturing, PHM is recognized as an important enabling technology to improve mission service and production reliability, operational safety, equipment maintenance efficiency, and affordability [
8].
Recurrent neural networks are widely used in nonlinear time series modeling. Typical recurrent neural networks include long short-term memory (LSTM), LSTM with coupled inputs and forgetting gates, gated loop units, etc. The recurrent neural network does not need to select the number of values of the delayed input time series. These recurrent neural networks have been shown to be successful in many applications such as natural language processing, residual useful lifetime prediction, traffic flow prediction, etc. [
9]. For the rapid detection of structural anomalies, Smriti Sharma et al. [
10] proposed a real-time method based on LSTM, which uses an unsupervised LSTM prediction network for detection, and then a supervised classifier network for localization. Liu et al. [
11] proposed a hybrid real-time method for determining the start time of rolling bearing failure. Based on the dynamic 3σ interval and the voting mechanism, the startup time can be adaptively predicted. First, the LSTM neural network is used to predict the trend of the bearing’s future operation. Then, an exponential model is used to estimate its remaining useful life (RUL). Zheng et al. [
12] proposed a mechanical state prediction method for high-voltage circuit breakers based on an LSTM neural network and support vector machine (SVM). This method can accurately predict the mechanical state of HV circuit breakers, laying a foundation for realizing the predictive maintenance of the mechanical state of HV circuit breakers. By combining the LSTM architecture of deep learning methods with a glass SVM and based on training data composed entirely of healthy signals (i.e., semi-supervised), Kilian Vos et al. [
13] developed an automatic algorithm capable of identifying any abnormal mechanical behavior captured by vibration measurements.
Lu et al. [
14] proposed a RUL prediction model based on the auto-encoder gated recursive unit (AE-GRU), in which the auto-encoder (AE) extracted important features from the original data and the gated recurrent unit (GRU) selected information from the sequence to predict RUL. Zhang et al. [
15] proposed an innovative algorithm that combines a hybrid spatial and temporal attention-based gated recursive unit (HSTA-GRU) with the seasonal trend decomposition program Loess (STL) to predict more fault information from multiple time series data. Based on the graph convolutional network (GCN) and GRU models, Man et al. [
16] proposed a new GCG framework combining a GCN and GRU to extract features and predict shaft temperature. Chen et al. [
17] developed a hybrid prediction method for mechanical degradation. In this method, an algorithm based on 3r criteria was introduced to detect the initial time point of degradation, and the GRU network was used to learn the degradation characteristics based on existing data, to predict the long-term degradation trend through multiple prediction programs.
At present, how to quickly and accurately identify the faults generated during the operation of equipment has become a research hotspot in the prediction and maintenance management of mechanical equipment health status [
18]. To diagnose equipment faults timely and accurately and maintain the normal operation of the equipment, a variety of intelligent diagnosis methods have been proposed, mainly including signal processing methods [
19] and data-driven methods [
20].
With the support of an intelligent data acquisition system to obtain a large amount of original available data, data-driven fault diagnosis technology has gradually entered the research field [
21,
22]. General intelligent diagnosis and prediction methods are mainly composed of two parts, namely feature extraction and fault classification [
23]. At present, many machine learning methods have been applied to mechanical fault diagnosis such as the artificial neural network (ANN) [
24], SVM [
25], hidden Markov model (HMM) [
26], and so on.
Different from traditional machine learning methods that adopt supervised learning, unsupervised-learning-based deep learning can realize fault diagnosis when samples are scarce, providing an effective solution for fault feature diagnosis and analysis. This advantage makes unsupervised feature learning methods gradually enter the field of mechanical fault diagnosis [
27,
28]. Niu et al. [
29], for example, proposed a hybrid flexible diagnosis framework for rolling bearings based on a DBN model as a reliable and effective general method for bearing fault diagnosis. Shi et al. [
30] proposed a fault diagnosis method based on a sparse auto-encoder (SAE) for advanced feature learning and bearing fault classification, which improved diagnosis accuracy and efficiency. Liu et al. [
31] proposed a partial adversarial domain adaptive (SPADA) model based on stacked auto-encoders to solve the fault diagnosis problem in PDA, and the diagnostic performance of SPADA is superior to existing methods. In the field of unsupervised learning, the self-organizing mapping (SOM) neural network is a popular algorithm in the field of data clustering, and it is often used in the field of fault diagnosis because of its excellent effect of cluster analysis. Lu et al. [
32] proposed a gear fault intelligent diagnosis model based on the SOM neural network, which can predict the remaining service life of gear transmission systems according to state indicators. You et al. [
33] proposed a method to diagnose the converter fault of wind turbines by using the SOM method, which avoids training many samples and has high accuracy. Xiao et al. [
34] opposed a gear fault diagnosis method based on variational mode decomposition (VMD) and SOM neural networks based on kurtosis criteria, which has a good effect on gear fault diagnosis. Wang et al. [
35] proposed a fault diagnosis method based on integrated empirical mode decomposition (EEMD) time-frequency energy and SOM neural networks, and the diagnosis results of this method have good visibility.
The input of high-dimensional data may have an impact on subsequent diagnostic efficiency and accuracy. Therefore, the reduction and feature extraction of high-dimensional process data are of great significance before fault identification [
36]. Principal component analysis (PCA) is a typical method for feature extraction and data analysis, and an effective tool for dimensionality reduction analysis [
37]. Wang et al. [
38] obtained the finite sample approximate result of CDM-based PCA through matrix perturbation and obtained the final estimate of CDM-based PCA. Zhou et al. [
39] improved the diagnostic accuracy by combining PCA and contribution analysis for fault isolation.
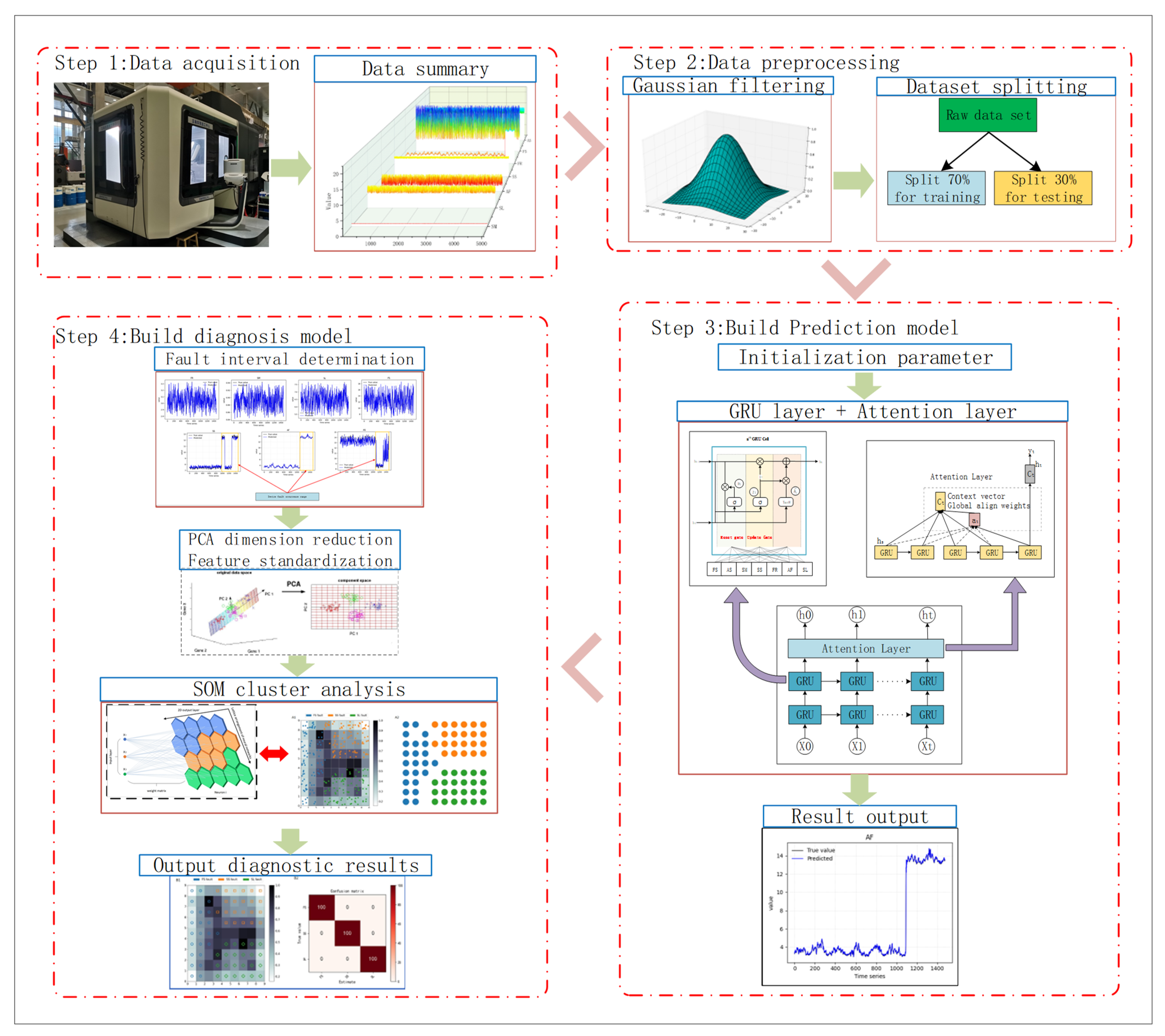
This paper presents a health management method based on an improved gated loop unit and self-organizing mapping neural network. In the fault prediction stage, the multi-layer GRU neural network prediction model is established, and the attention mechanism is introduced into the GRU neural network, which improves the long-term dependence problem of the GRU neural network, improves the model performance, and provides the explanation and interpretability. At the same time, the Nadam optimizer is used to update the model parameters, which improves the convergence speed and generalization ability of the model, making it suitable for solving the prediction problem of large-scale data. In the fault diagnosis stage, the competitive learning mechanism is used to perform cluster analysis on different kinds of data, find the winning neurons, change the weights of the connections between the winning neurons and the input layer, make similar input variables similar to the weights of the connections between the output neurons, cluster similar input variables into the same class, and output the results through the SOM competition layer. In addition, the PCA method is used to find the most important features affecting the whole from the high-dimensional features to improve the expression ability of features, reduce the complexity of training, and achieve data dimensionality reduction.
The rest of this article is structured as follows. The second part analyzes the fault of a servo drive system and determines three main fault types. The third part reviews the basic theories and techniques of LSTM and SOM and discusses their limitations. The fourth part introduces and analyzes the health management process of the machine tool servo system and introduces the Attention-MLGRU and PCA-SOM methods in detail. The fifth part introduces the process of predictive model selection and analyzes the equipment operation data set based on a health management system, including fault prediction and fault diagnosis. Finally, the conclusion is given in the sixth part.
2. Analysis
Nowadays, all countries in the world are vigorously developing advanced manufacturing technology and intelligent production equipment to improve manufacturing capacity, which is also an important way to promote economic development and improve comprehensive national strength. As a next-generation manufacturing system, intelligent manufacturing can improve quality, increase productivity, reduce costs, and improve the flexibility of manufacturing [
40]. The control system is the core component of CNC machine tools, its control performance directly affects the quality of CNC machine tool product processing and processing efficiency, and its failure rate and reliability have become important factors restricting the development of advanced manufacturing technology and equipment.
2.1. Brief Introduction of CNC System
Taking a five-axis CNC machine tool as the research object,
Figure 1 is its system frame diagram. According to the structure characteristics and actual use of a high-grade CNC system, the software and hardware of the high-grade CNC system are divided into several functional modules, including the CNC panel, spindle drive unit, feed drive unit, detection unit, electrical system, preprocessing module, monitoring, and diagnosis module.
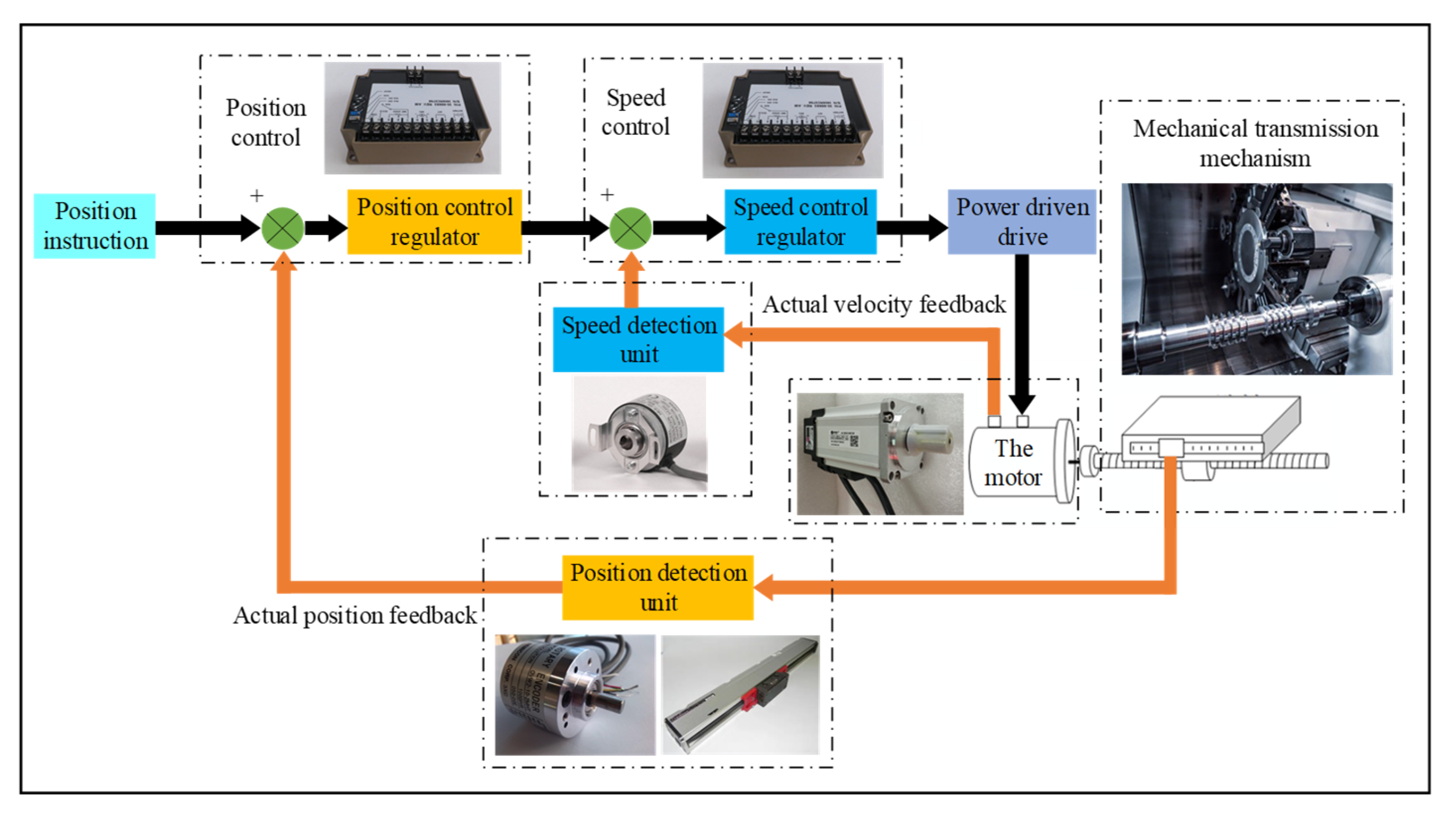
The CNC machine tool servo system mainly includes a feed servo system and spindle servo system, and
Figure 2 shows its composition and workflow diagram. The feed servo system operates mainly through the numerical control system to transmit information and control the movement of the device to achieve the speed control of feed movement, while accurately controlling the moving position of the workpiece. The CNC machine tool spindle feed servo system includes a servo motor and servo drive device in two parts, of which the spindle feed servo system is connected to the speed control system, with speed control function and positive and negative rotation function. The speed control range is wide, controlled by the CNC device, and can also be controlled by a programmable controller. At present, the common spindle feed servo system includes a DC spindle control system and AC spindle control system, and the fault types are also significantly different.
2.2. Failure Data Analysis of CNC System
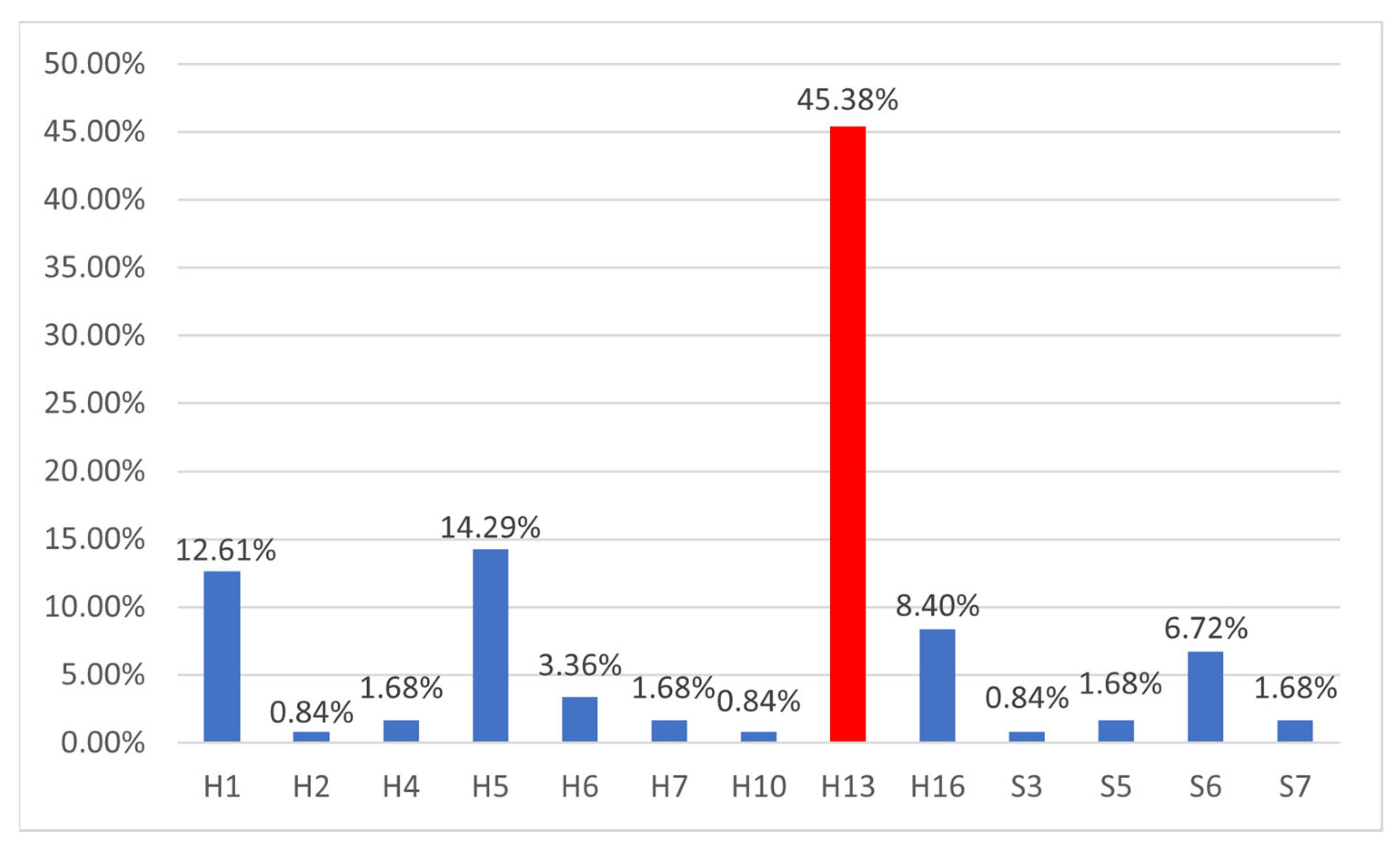
The fault analysis of a certain type of high-grade numerical control system is carried out. The fault data of the CNC machine tool with this type of CNC system are tracked and recorded for three years, and the fault data related to the CNC system are extracted from the obtained data. According to the division of function modules and faulty parts, the faulty parts of the numerical control system are statistically analyzed. The number and frequency of failures in each faulty part are shown in
Table 1 and
Figure 3.
From the statistical data, the most common part in CNC system failure is the feed drive unit, and its failure frequency is much higher that of than other parts. This shows that the servo drive system is the main component affecting the stability of the machine tool but also the key to improve its reliability.
2.3. Fault Analysis of Feed and Spindle Servo System
The fault types of CNC machine tools are diverse, including feed system, spindle servo system and auxiliary mechanism, and other parts, and any link problems will affect the normal operation of CNC machine tools. In practical applications, the servo system of CNC machine tools has a high probability of failure. Some faults can be displayed through the CRT or the operation panel alarm, some can be displayed using the hardware display on the servo unit, and some only show that the feed movement is abnormal, but there is no warning information, so such faults are more difficult to judge and bring great difficulty for subsequent maintenance and management work. In such a complex situation, it is of great significance to predict, diagnose, and eliminate various faults quickly and accurately to improve the production efficiency and machining accuracy of the machine tool.
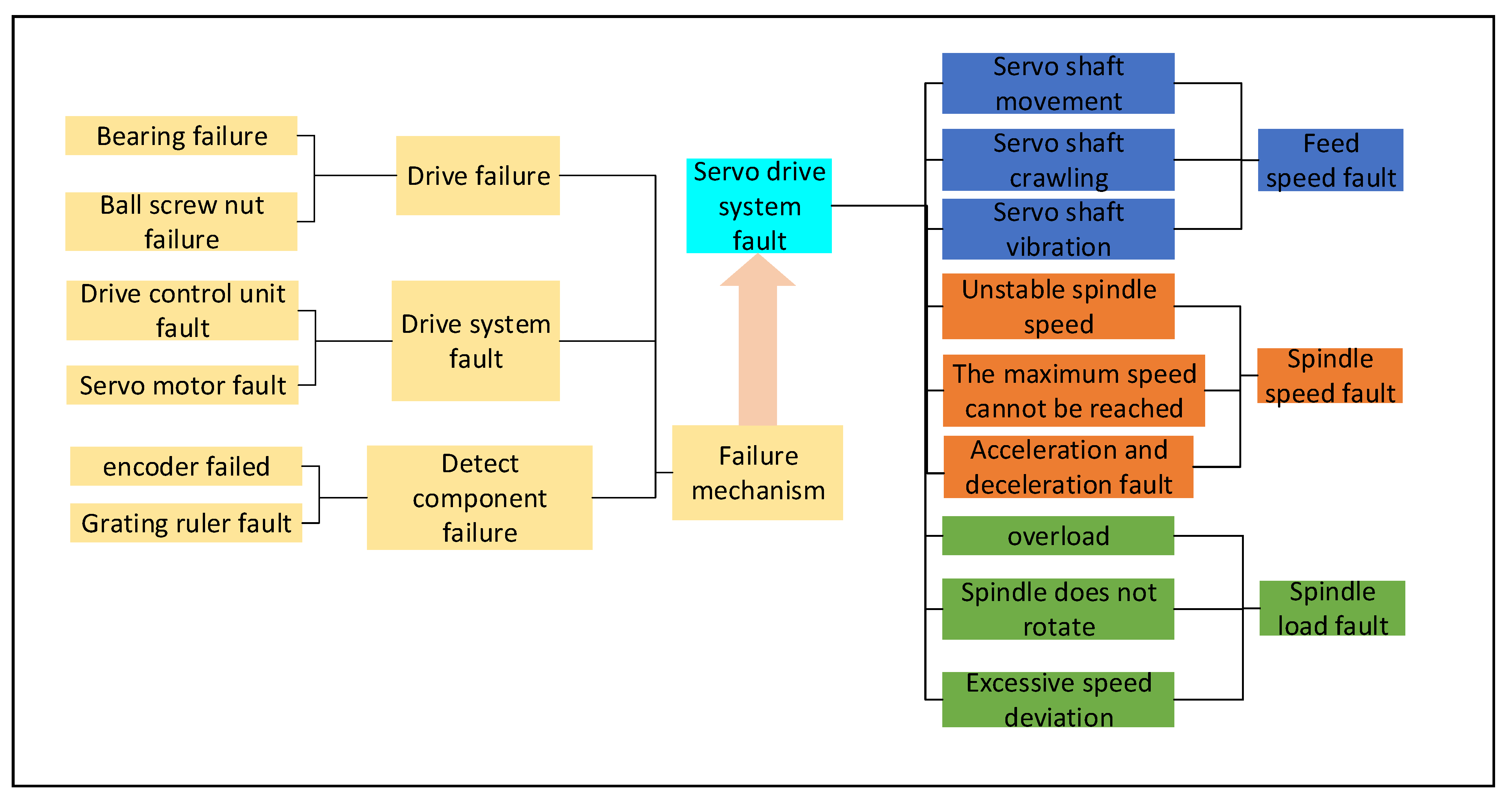
To determine and eliminate the system fault timely and accurately, a comprehensive overview of the common fault types of the existing servo drive system is made, and its fault mechanism is deeply analyzed, as shown in
Figure 4. The types of fault that occur in the servo system can include the servo shaft moving, the spindle speed becoming unstable, being unable to reach the highest speed, acceleration and deceleration failure, speed deviation being too large, etc. Some of the reasons for these failures are analyzed as follows:
Servo shaft moving: feed transmission chain has reverse clearance, servo drive gain is too large.
Servo shaft crawling: servo system gain is too low, poor lubrication of the feed transmission chain, etc.
Servo shaft vibration: the bearing of the motor is poorly lubricated, the fastening screw inside the motor is loose, etc.
The spindle speed is unstable: the tachometer generator installed at the tail of the spindle fails, the speed command voltage is poor or wrong, etc.
Cannot reach the highest speed: motor excitation current adjustment is too large, the excitation control loop is bad.
Acceleration and deceleration failure: current feedback loop setting, mechanical transmission system is poor.
Overload: excessive load, poor lubrication of the feed transmission chain, etc.
Spindle does not turn: machine load is too large, mechanical connection falls off, etc.
Excessive speed deviation: improper adjustment of setting of speed regulator or speed measurement feedback loop, etc.
The root cause of servo drive failure is explored, and it is found that it is related to the transmission device, drive system, and detection components of the machine tool. When the transmission device fails, the power of the motor and other devices cannot be transferred to the actuator, and the failure mostly occurs in the coupling, lead screw, bearing, machine tool guide, and other parts. The drive system refers to the servo motor and other driving devices, and the failure of the drive system mainly includes the failure of the drive control unit and the servo motor. The detection parts mainly include the encoder, grating ruler, and other detection parts, and the fault of the detection part is mainly manifested as the feedback data error being too large or no feedback.
The faults of the servo drive system mentioned in the above analysis can be classified into three categories according to the fault nature: feed speed fault, spindle speed fault, and spindle load fault. In the case of complex fault causes, the accurate identification of the fault category can provide help for the subsequent determination of the fault location and the formulation of maintenance plans, which is of great significance to ensure the production reliability and efficiency of CNC machine tools.
4. Proposed Method
4.1. Health Management Process Based on Attention-MLGRU and PCA-SOM Algorithms
To ensure the normal operation of a CNC machine tool servo drive system for a long time, a health management method of a machine tool servo drive system based on the Attention-MLGRU and PCA-SOM algorithms was proposed. The core of this method includes two parts, fault prediction and fault diagnosis. In the fault prediction stage, a multi-layer GRU neural network is used to predict the time sequence of the operating parameters, and the attention mechanism is introduced to establish the fault prediction model of the servo drive system. The introduction of the attention mechanism in GRU neural networks can improve the long-term dependence problem of GRU neural networks, improve model performance, handle variable-length input sequences, and provide interpretability and interpretability. This makes the model more flexible, accurate, and interpretable in sequence tasks.
In the fault diagnosis stage, the SOM neural network is used for cluster analysis, and feature standardization and PCA are introduced into the SOM neural network to establish the fault diagnosis model of the servo drive system. The fault diagnosis effect of the model is better than that of the traditional method, and it can realize the dimensionality reduction analysis of high-dimensional fault data and can accurately identify the fault characteristics of the data, which solves the problem that the fault causes of the existing CNC machine tool servo drive control system are complicated and difficult to diagnose and provides a good idea for the fault diagnosis of the CNC machine tool servo drive system and improves the operation reliability of the machine tool. The specific process of health management is shown in
Figure 8.
Step 1: Use the workshop detailed manufacturing data and process system (MDC system) to monitor the actual production status of CNC machine tools and collect data for some key production parameters.
Step 2: According to the production data of the field equipment of the MDC system, select appropriate data as the sample data set and conduct data preprocessing. The data preprocessing adopts the Gaussian filter method, and the processed data set is used as the input for fault prediction and fault diagnosis analysis.
Step 3: Fault prediction
(1) Initialization of parameters: Initialize the weight and bias of the multi-layer GRU neural network.
(2) Forward propagation: For each time step, calculate the current input and the hidden state of the previous time step, as well as the attention weight. The input sequence is weighted and summed according to the attention weight to obtain the attention-weighted representation. The attention-weighted representation is input into a multi-layer GRU, and the hidden state of the current time step is calculated.
(3) Calculate the loss: Input the hidden state of the last time step into the output layer, calculate the predicted value, and calculate the loss function according to the predicted value and the target label.
(4) Backpropagation: Calculate the gradient of the loss function to the predicted value and calculate the gradient of each parameter in the multi-layer GRU neural network through the backpropagation algorithm.
(5) Use the Nadam algorithm to update network parameters, adjust weights and bias.
Step 4: Fault diagnosis
(1) Carry out feature standardization processing for different types of input sample data sets and determine the parameters of the output layer.
(2) Establish an improved self-organizing neural network fault diagnosis model, input the feature standardized sample data set into the model, and conduct PCA dimensionality reduction to obtain the sample data after dimensionality reduction.
(3) Conduct SOM cluster analysis on the sample data after dimensionality reduction and output the cluster analysis results.
(4) Output fault diagnosis results according to cluster analysis results and determine the fault diagnosis accuracy rate.
4.2. Instructions on Data Set Creation
4.2.1. Potential Challenges in Data Set Creation
In the construction of a health management system, data are crucial, and given the reality of production, the establishment of data sets faces some potential challenges and limitations:
(1) Difficulty in obtaining data: Generally speaking, the data required for fault prediction and diagnosis may need to be obtained from multiple sources, including equipment logs, maintenance records, etc. There may be difficulties in obtaining these data at the same time, such as data access restrictions, data integration problems between devices and systems, etc., so appropriate ways are needed to obtain relevant data.
(2) Insufficient amount of data: The establishment of an effective fault prediction and diagnosis model usually requires a large amount of data to train, especially for the diagnosis of complex systems and multiple types of faults. In actual production, there may be an insufficient volume of data, which affects the performance and generalization ability of the model.
(3) Poor data quality: the actually collected data may have quality problems, such as outliers, noise, etc., which may affect the training and prediction accuracy of the model, so it is necessary to clean and preprocess the acquired data in an appropriate way to ensure the quality of the data set.
4.2.2. MDC System Overview
Intelligent monitoring plays an important role in the intelligent automation of manufacturing systems, and advanced data collection technology has been widely used to promote real-time data collection [
44]. The Manufacturing Data Collection & Status Management (MDC) system is a software and hardware solution for real-time acquisition, charting, and reporting of detailed manufacturing processes and data on the shop floor. MDC uses a variety of flexible methods to obtain real-time data from the production site (including equipment, people, production tasks, etc.), store it in databases such as Access, SQL, and Oracle, and build on the lean manufacturing management philosophy. Combined with nearly 100 kinds of special calculation, analysis, and statistical methods of the system, it directly reflects the production status of the workshop in the form of a variety of reports and charts and helps the production department of the enterprise to make scientific and effective decisions.
Figure 9 is the MDC system diagram.
The MDC system has the following characteristics when processing data:
(1) Real-time data acquisition: The MDC system can collect all kinds of data in the production process in real time, including equipment operation data, sensor data, etc. Compared with traditional data acquisition methods, the MDC system has the characteristics of automation and real time, which can greatly improve the efficiency and accuracy of data acquisition.
(2) Data consistency: By automating data collection and processing, the MDC system ensures data consistency and accuracy, avoiding errors and inconsistencies caused by manual operations and ensuring data reliability and availability.
(3) Historical data recording: The MDC system can record and store historical data to form a complete historical data record to ensure the integrity and quantity of data, which is important for fault analysis and the fault prediction model.
Using the MDC system to obtain data ensures data availability and quantity requirements are met.
4.2.3. Data Preprocessing Method—Gaussian Filter
Gaussian data filtering is a common signal processing technique used to reduce high-frequency noise in data, smooth data, and retain low-frequency information in data. Its principle is based on the characteristics of the Gaussian function, by weighted average data to achieve filtering.
The Gaussian function is a continuous distribution function in the shape of a bell curve. In data filtering, the Gaussian function is used as the convolution kernel of the filter. The convolution kernel is the core function of weighted summation of input data, smoothing input data, and reducing noise in the data. In Gaussian data filtering, the convolution kernel is determined by a standard deviation parameter. The higher the standard deviation, the higher the smoothing degree of the filter and the better the filtering effect of the data noise. In the filtering process, each point in the convolution checks data and its adjacent points are weighted to calculate the filtering value of the point.
By using Gaussian filtering, the high-frequency noise in the data can be removed to smooth the data, while retaining the low-frequency information in the data, improving the quality and accuracy of the data, so as to ensure the data quality of the data set.
4.2.4. Introduction to Data Characteristics
The MDC system is used to collect the actual running data of CNC machine tools, and some working parameters that can characterize the running state of the machine tools are analyzed, including feed speed, actual speed, spindle ratio, spindle speed, feed rate, actual feed, and spindle load, as shown in
Table 3.
According to the seven field equipment production data collected by the MDC system, data are selected as a sample data set at a certain time interval and taken as input, as shown in
Table 4, which includes three types of fault data that can characterize the servo drive system, including feed speed, spindle speed, and spindle load. Three types of trouble-free data, including actual speed, spindle rate feed, and actual feed are included. The label value indicates the fault type of the data sample, where “1” indicates the feed speed fault, “2” indicates the spindle speed fault, and “3” indicates the spindle load fault.
Table 4 shows the fault indicators of each fault type. When the working parameters are within the target range, the servo drive system is in a normal working state; when the working parameters are beyond the target range, the corresponding fault occurs. A waterfall diagram of the running parameters of the machine tool is shown in
Figure 10.
4.3. Fault Prediction Method
4.3.1. Attention Mechanism Principle
The attention mechanism is a mechanism for weighting information at different locations in the sequence data [
45]. The introduction of the attention mechanism in the neural network model allows the model to make different attention adjustments to the input at different moments when processing the sequence data so that the key information in the sequence can be processed more flexibly. The structure of the attention mechanism is shown in
Figure 11.
The formula expression of the attention mechanism can vary according to the specific variant. The following is a general formula expression of the attention mechanism:
Given the input sequence , ,……, , the attention mechanism calculates the attention weight\alpha and the context vector c as follows:
1. Calculate attention weight:
where
is the result of the score function score, which measures the correlation of position i with other positions in the sequence.
2. Calculate the context vector:
In the self-attention mechanism, the common scoring function score has the following forms:
Product attention: ;
Additive attention: ;
Where is a learnable weight matrix and b is a learnable bias vector.
Scaled dot product attention: ;
Where d is the dimension of the input sequence.
The above formula is the general form of the attention mechanism, and the specific application scenario and model will determine the appropriate scoring function and calculation method.
The introduction of attention mechanisms in neural networks can improve the long-term dependency problem of LSTM and GRU neural networks, improve model performance, handle variable-length input sequences, and provide interpretability and explainability. This makes the model more flexible, accurate, and interpretable in sequence tasks.
4.3.2. Type of Neural Network Structure
In general, neural network structures come in many variants, including single-layer, multi-layer, and bidirectional neural network structures. In general, a single-layer neural network has a simple structure and high computational efficiency, but its learning ability is limited. A multi-layer neural network has stronger representation and learning ability, which is suitable for various complex tasks. A bidirectional neural network can make use of bidirectional dependency to provide more comprehensive context information when processing sequence data. Choosing a suitable neural network structure depends on the complexity of the task and the characteristics of the data.
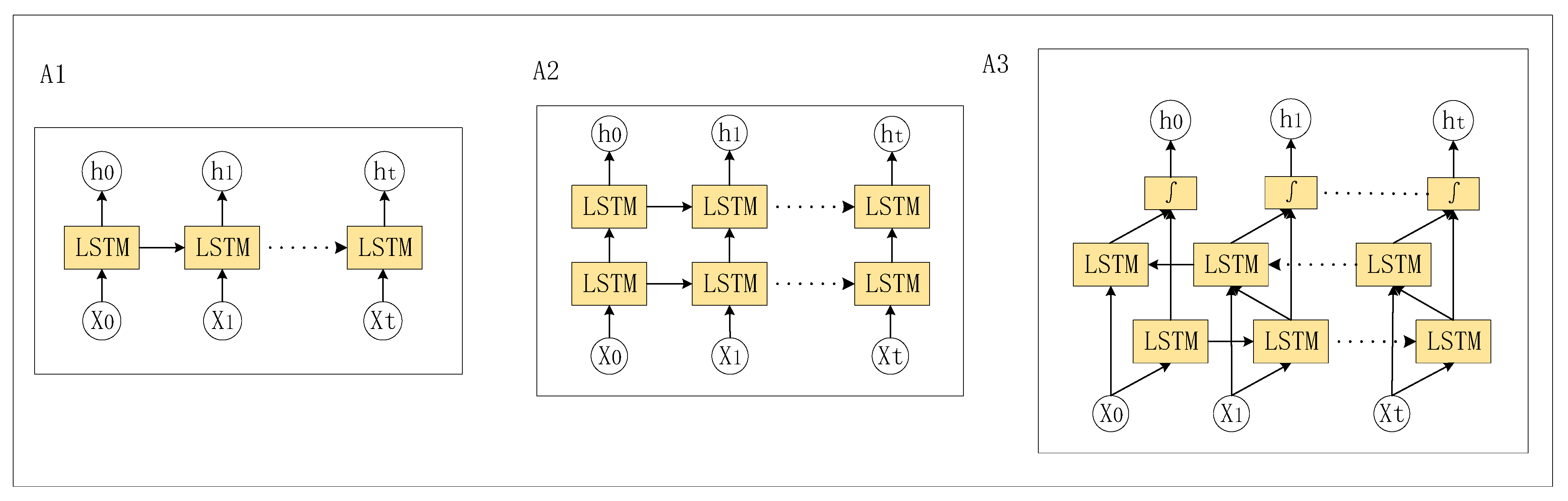
Several variants of the LSTM structure are shown in
Figure 12, including:
1. Single-layer LSTM: Also known as standard LSTM, it contains three gate control units (input gate, forget gate, and output gate), as well as a memory unit (cell state), which can conduct long-term dependency modeling of sequence data.
2. Multi-layer LSTM: A network structure composed of multiple LSTM layers. Each LSTM layer can obtain input from the output of the previous layer and increase the complexity and representation of the model by stacking multiple LSTM units.
3. Bidirectional LSTM: Based on the standard LSTM, the forward and reverse LSTM units are introduced, which can model the sequence data in both forward and backward directions at the same time to capture more comprehensive context information.
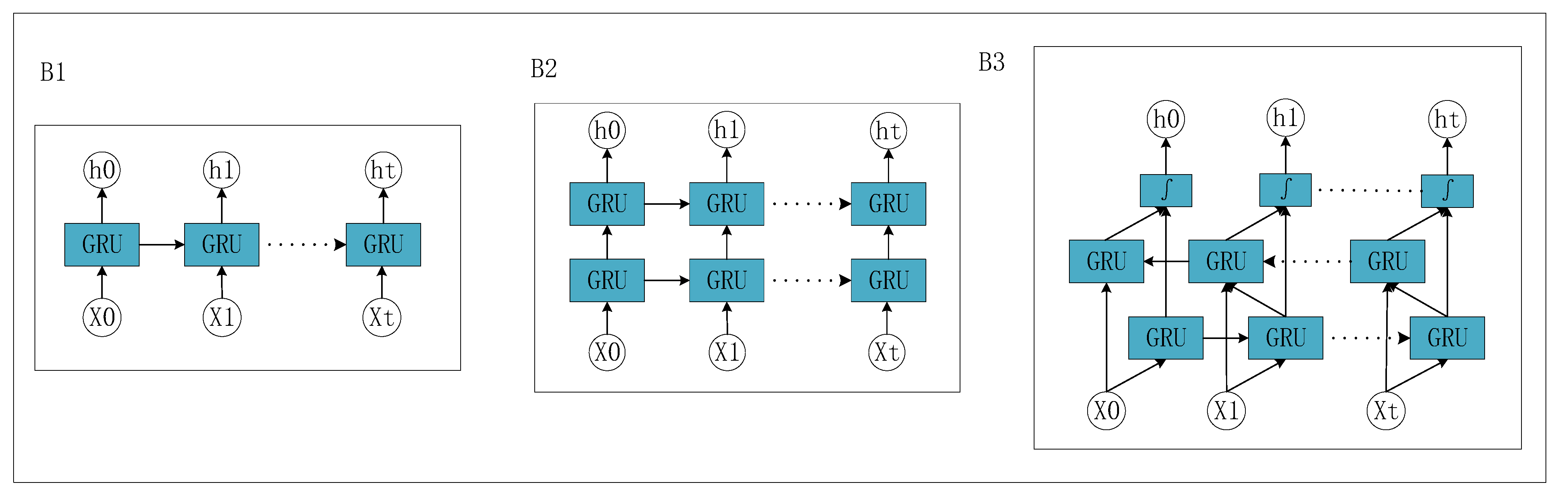
Several variations of the GRU structure are shown in
Figure 13, including:
1. Single-layer GRU neural network: The single-layer GRU neural network contains only one GRU hidden layer and, compared with LSTM, the GRU has a more simplified structure, reducing a part of the gating unit, and the number of calculations and parameters is lower. Single-layer GRUs show better performance when dealing with simple sequential tasks. The training speed is relatively fast, which is suitable for medium-scale data sets.
2. Multi-layer GRU neural network: The multi-layer GRU neural network contains multiple GRU hidden layers, and the output of the upper layer serves as the input of the next layer. The multi-layer structure can capture more complex sequence patterns and abstract representations, while increasing the depth and expressiveness of the network. It is suitable for processing more complex sequences, but the complexity of training and parameter adjustment is higher. More computing resources and more data are needed to avoid overfitting.
3. Bidirectional GRU neural networks: Bidirectional GRU neural networks consider both past and future contextual information. At each time step, the input sequence is passed forward and backward to the two GRU hidden layers, and their outputs are merged. Bidirectional architecture can better capture dependencies and context information in sequence data and is suitable for sequential tasks such as speech recognition, machine translation, etc., but the training time and computing resource consumption are relatively high.
Choosing a single-layer, multi-layer, or bidirectional neural network architecture requires trade-offs based on the specific task and complexity of the data set, as well as training time and computational resource constraints. The LSTM and GRU neural network structures with an attention mechanism are shown in
Figure 14 and
Figure 15.
4.3.3. Attention-MLGRU Algorithm Flow
The attention-based multi-layer GRU neural network is a recursive neural network structure that combines attention mechanisms for processing sequence data. By introducing attention mechanisms, it can automatically learn and focus on key information in the input sequence.
1. Forward propagation:
It is assumed that there is a multi-layer GRU network with an L-layer, and the attention mechanism is introduced. The calculation process of each GRU unit can be expressed as:
The reset gate of the GRU unit on level l:
The update gate of the GRU unit on level l:
The candidate hidden state of the GRU unit on level l:
where
is the input vector,
is the hidden state of layer l at the previous moment,
is the reset gate,
is the update gate, and
is the candidate hidden state.
Calculation of attention vector:
where
is the intermediate result of the attention vector,
is the attention weight,
is the attention-weighted context vector, and
is the candidate always hidden state of the l-level GRU unit.
Hidden state update:
where
is the hidden state of layer l at the current moment.
The forward propagation process of the entire multi-layer GRU neural network can be expressed as:
where
represents the GRU unit of layer l.
2. Calculate the loss function:
Use an appropriate loss function, such as the mean square error loss, to calculate the error between the predicted value and the true label.
3. Backpropagation:
According to the loss function, calculate the gradient of the loss relative to the parameter. Through the backpropagation algorithm, it is possible to calculate the gradient of the loss function to the network parameters and use the optimization algorithm (such as gradient descent) to update the parameters to train and optimize the network.
4. Parameter update (Nadam optimizer):
The Nadam optimizer uses the following formula to update parameters:
where
and
represent the first moment estimate and second moment estimate of the gradient, respectively,
represents the gradient at the current moment,
and
are adjustable hyperparameters with a general value of 0 and 0.999,
denotes the learning rate,
is a small number (such as 1 × 10
−8) used for numerical stability.
and
are deviation corrections for the first and second moment estimates of gradients used to solve the deviation problem of the Adam optimizer. By introducing the correction term of Nesterov momentum, the first moment estimation of the gradient is more accurate.
The weight parameters and bias terms in the above formula are updated according to the rules of gradient descent to minimize the loss function. The above steps are repeated for multiple rounds of iterative training until a predetermined stopping condition or convergence is reached. By using the attention mechanism and the Nadam optimizer, attention weights and learning rates can be adjusted adaptively in multi-layer GRU neural networks to optimize the updating process of network parameters.
4.4. Fault Diagnosis Method
4.4.1. Introduction to Principal Component Analysis
PCA is a standard method applied to reduction and feature extraction and is the most used linear dimension reduction method. The purpose of PCA for dimensionality reduction is to reduce the original features as far as possible to ensure that “information is not lost” and obtain the maximum data information (maximum variance) in the dimension of the projection. In other words, the original feature is projected onto the dimension with the maximum projection information, so that the information loss after dimensionality reduction is minimized [
46] and the characteristics of more original data points are retained while the data dimension is reduced.
4.4.2. PCA-SOM Algorithm Flow
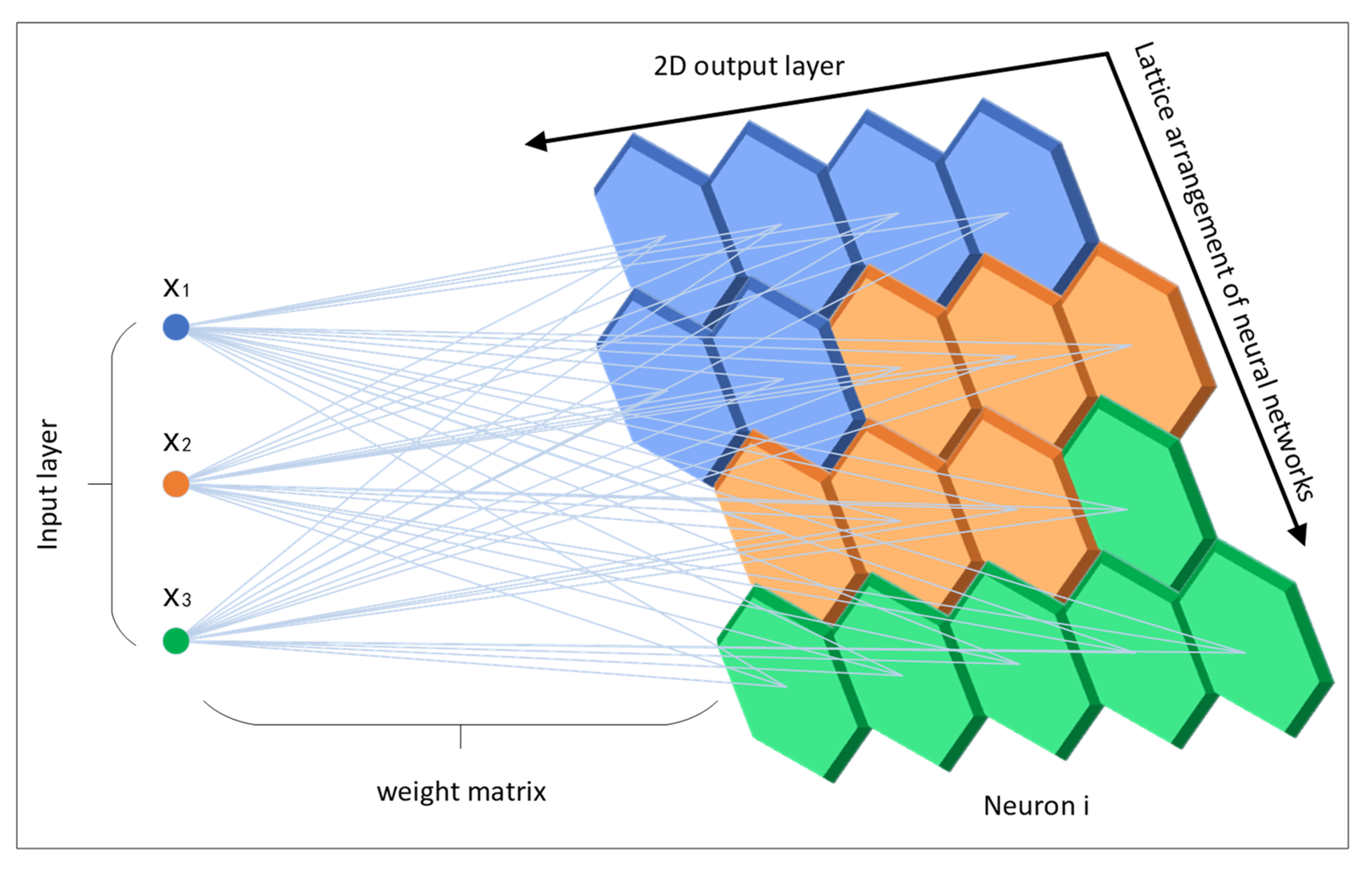
To improve the operation rate, clustering accuracy, and data processing ability of the SOM neural network, a PCA-SOM neural network is proposed by combining a PCA neural network with a SOM neural network. At the same time, feature standardization is introduced into the SOM neural network to balance the influence of different feature scales, and then the SOM neural network is further optimized. The network structure is mainly composed of an input layer and output layer. The input layer accepts high-dimensional data and transforms them into two-dimensional data visual output through a competitive learning mechanism. For the operation parameters of the equipment to be evaluated, the SOM neural network can output a two-dimensional topology after the monitoring data are processed, assuming that the number of neurons in the output layer is L. The specific algorithm process is as follows:
(1) Data feature standardization processing
Conduct feature standardization processing on the input training data matrix
, and the processed data matrix is
D:
where:
(Nxd) is the training data, where N is the number of training samples, d is the dimension of sample data, mean (
) is the mean value of matrix data, and std (
) is the standard deviation of matrix data.
(2) Determine parameters
Determine the number of nodes X and Y in the output layer:
(3) PCA dimensionality reduction
(1) Calculate the covariance matrix
According to the data matrix
D after feature standardization, the corresponding covariance matrix is calculated as
S:
(2) Calculate the eigenvalues of the covariance matrix and corresponding eigenvectors
The eigenvalues of the covariance matrix
S are decomposed, and then the eigenvalues and corresponding eigenvectors are calculated.
where:
Λ represents the diagonal matrix;
P represents the eigenvector matrix composed of corresponding eigenvectors in descending order. The largest eigenvalue and corresponding eigenvector can represent the variance and direction of the first principal component, and the smallest eigenvalue and corresponding eigenvector can represent the variance and direction of the last principal component.
(3) The original feature is projected onto the selected feature vector to obtain the new K-dimensional feature after dimensionality reduction, and
is the real-time sample vector after dimensionality reduction.
(4) SOM clustering
(1) Weight vector initialization
After PCA feature dimensionality reduction, the weight vector matrix
between the real-time sample vector
and the Lth neuron of the output layer in the period of (
) is, after n updates,
After random replication and normalization of L weight vectors in the output layer, the initial superior domain , the initial learning rate , and the initial weight vector are determined.
(2) Look for winning neurons
The real-time sample vector
after dimensionality reduction is combined with the weight vector
of each neuron in the output layer to obtain
, in which the neuron with the largest inner product
is the winning neuron. The winning neuron can be obtained by calculating the minimum Euclidean distance, so the inner product
can be improved to
(3) Adjust the winning areas
Taking the winning neuron as the center, the winning domain is adjusted to determine the winning region. A variety of distance functions can be used to determine the winning field, and common ones such as Euclidean distance functions are used in this paper.
(4) Adjust the weight value
Adjust the weight vector of all neurons in the winning domain and update the formula as follows:
(5) End the iteration
When the learning rate decays to the preset threshold, the SOM neural network can be trained and the optimal weight vector of each neuron in the output layer can be obtained.
(6) Output cluster analysis results
6. Conclusions
This paper presents a health management system based on an improved gated recurrent neural network (Attention-MLGRU) and improved self-organizing mapping neural network (PCA-SOM) and realizes the health management of a computer numerically controlled (CNC) machine tool servo drive system based on this method. The health management system mainly includes two parts, which are fault prediction stage and fault diagnosis stage.
In the fault prediction stage, the gated recurrent unit (GRU) neural network is adopted as the prediction algorithm, a multi-layer GRU neural network prediction model is established, and the attention mechanism is introduced into the GRU neural network to carry out weighted processing of information at different positions in the sequence data, which improves the long-term dependence problem of the GRU neural network and improves the model performance. It also provides interpretability and explainability. At the same time, the Nadam optimizer is used to update the model parameters, which improves the convergence speed and generalization ability of the model and makes it suitable for solving the prediction problem of large-scale data.
In the fault diagnosis stage, based on the traditional self-organizing mapping (SOM) neural network method, feature standardization and principal component analysis (PCA) are introduced into the SOM neural network data preprocessing part, which solves the problem that the traditional SOM neural network struggles to analyze large data samples and improves the accuracy and efficiency of fault diagnosis. Different from common fault diagnosis techniques, the PCA-SOM method can reduce the dimensionality of original data features, while retaining more features of original data points, which greatly improves the ability of this method to process large data samples. In addition, this method enhances the characteristics of fault data, makes fault data easy to distinguish, and solves the problem that the traditional fault diagnosis method has poor diagnosis effect when the fault characteristics are fuzzy.
It is worth noting that this method not only predicts and evaluates the difference between the fault and the health state of the machine tool servo drive system but also accurately identifies the fault type, which provides help for the follow-up maintenance work and the formulation of maintenance strategy. Finally, the validity of the health management method is tested with the equipment operation parameter data set containing fault data. The results show that the health management system can accurately predict and identify the fault information and can realize the health management of the machine tool servo drive system.
The future research direction is mainly to improve the generalization ability and recognition ability of the model. In the manufacturing industry, due to the complexity and variability of the production environment, data changes are particularly common, for example, the aging of equipment, the replacement of materials, and the fine tuning of process parameters may lead to changes in data distribution. Therefore, improving the generalization ability of the model is particularly important for fault prediction and diagnosis. At the same time, in the fault data, there may be a serious imbalance between normal samples and fault samples, which will cause the model to prefer to learn common normal patterns in the training process, while the recognition ability of rare fault modes is weak. Therefore, it is necessary to solve the problem of data sample imbalance to improve the performance of the model.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}